
基于深度学习和持续同调的LiDAR 林下滑坡提取①
2023-11-16 10:57:16贺跃光姜风航苗则朗包志轩易南洲
矿冶工程 2023年5期
贺跃光, 姜风航, 苗则朗, 包志轩, 易南洲
(1.长沙理工大学交通运输工程学院,湖南 长沙 410004;2.中南大学地球科学与信息物理学院,湖南 长沙 410083;3.湖南省水利水电勘测设计研究总院,湖南 长沙 410119)
卫星遥感技术可快速获取区域影像,实现滑坡灾害分析。 但在森林覆盖区,传统光学、微波遥感技术主要获取植被的林冠高程信息,难以消除植被覆盖的影响。 机载激光雷达是一种主动式对地观测系统,通过LiDAR 点云技术穿透植被,利用滤波算法有效去除地表植被点云,直接获取真实地表形态特征,客观反映林下滑坡信息,为林下滑坡提取领域提供有力的技术支持[1-2]。 深度学习是数据驱动方法,需要大量训练数据才能有效地识别对象;而滑坡数据通过实地勘探和目视解译以小区域形式生成,提供的数据量较少;持续同调(Persistent Homology)虽在图像分割方面得到重视[3-7],但在滑坡提取领域尚未得到充分应用。 本文提出一种基于深度学习与持续同调的滑坡提取方法,通过LiDAR 点云技术构建高分辨率数字地形模型(DTM),并以其衍生产品作为数据源,制作研究区先验滑坡样本,导入Res-Unet 网络模型中训练,得到滑坡图像分割结果;然后通过引入持续同调理论,对滑坡进行拓扑特征描述,提取曲率因子,依照持续同调理论检测滑坡拓扑特征;最后综合深度学习和持续同调结果,依照一定准则对研究区进行分析判别,获取林下滑坡提取结果。
1 研究区与数据处理
1.1 研究区概况
如图1 所示,实验以美国华盛顿州风河实验森林(Wind River Experimental Forest)为研究区,其海拔268~1389 m,经纬度54.77° ~54.90°N,121.77° ~122.1°W,面积241.68 km2。 该地区位于美国华盛顿州南部,夏季温暖干燥、冬季凉爽潮湿,年降水量约2225 mm,地层岩性以玄武岩和安山岩为主,且地层常被火山泥石流及其喷出物覆盖,包含冷杉、铁杉、银杉等多种植被,具有多样性,从光学影像上难以直接获取林下滑坡信息。
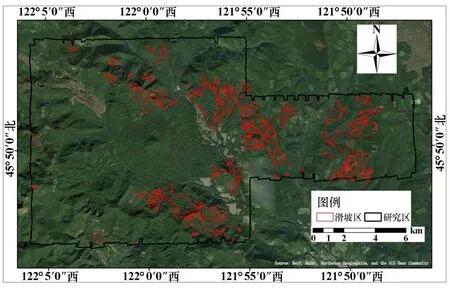
图1 滑坡区与研究区
1.2 LiDAR 数据处理
采用美国国家生态观测网络(The National Ecological Observatory Network,NEON)提供的LiDAR点云数据[8]为数据源。 先验滑坡信息源于美国地质调查局收录的美国本土滑坡编目数据库[9]。 通过机载LiDAR 技术获取点云数据,利用渐进三角网滤波算法将点云数据分为地面点和非地面点,然后使用插值法将地面点云数据生成所需DTM 影像。 内插方法主要包括反距离加权法、克里金插值和自然领域插值,其中反距离加权法插值精度更高[10]。 将地面点云以不规则三角网形式构建TIN 网,通过反距离加权法进行插值输出高分辨率DTM 栅格影像。
1.3 制作深度学习样本
采用DTM 影像及其衍生产品包括坡度影像、山体阴影构成的三通道影像制作样本数据,其中DTM 栅格影像为5 m 空间分辨率。 根据先验滑坡信息,对影像进行裁剪。 最终样本数据集包含215 幅滑坡影像(正样本)、83 幅非滑坡影像(负样本)以及对应的标签影像。
深度学习样本数量越多,泛化能力越强,样本数量不足或样本质量不够好时,需对样本进行数据增强。实验采用马赛克(Mosaic)数据增强法对样本集进行处理。 如图2 所示,选取4 张样本做随机裁剪、旋转、缩放和翻转等处理,进行拼接,并将其作为新样本加入样本集。 此外,通过随机裁剪,扩容样本数据集,提高了模型鲁棒性。
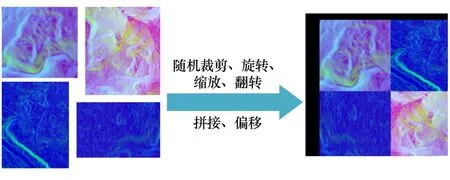
图2 马赛克数据增强
2 实验方法
2.1 Res-UNet 滑坡图像分割
UNet 模型的结构类似对称的U 形,简单、高效,适合进行小样本集训练。 其前半部分为编码部分,通过卷积层卷积处理,用ReLU 激活函数激活,并使用最大池化层增大感受野,压缩特征图;后半部分为解码部分,通过多次采样将特征图恢复至原图像尺寸。 为实现不同层级的特征融合,利用编码特征对解码特征进行细节补充。
传统UNet 网络中的低层和高层特征存在语义差异,直接拼接会出现特征缺失等情况,不利于模型学习。 实验添加残差模块,叠加卷积层的输入与输出,增加短路连接,形成残差学习,补充卷积过程中损失的特征信息,增强模型训练过程中梯度的反向传播。 如图3所示,残差模块的输出结果H(x)可分为直接映射x和残差F(x)两部分,公式为:
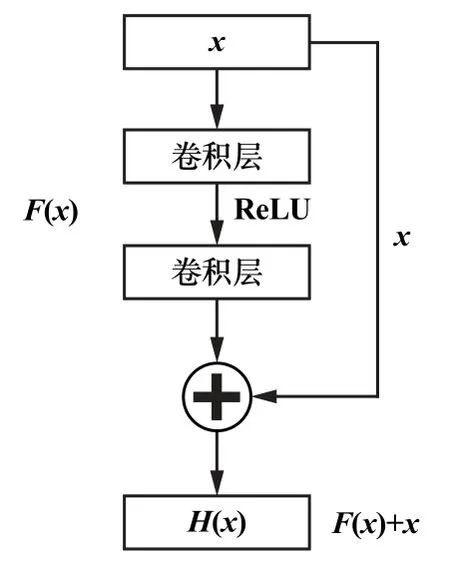
图3 残差模块
残差模块通常包含多个卷积操作,将卷积后的特征图与直接映射x相加得到新的特征图。 模型在网络训练中直接学习拟合的残差映射F(x),使所学滑坡特征更准确,并保证滑坡特征信息的完整性,Res-UNet结构如图4 所示。
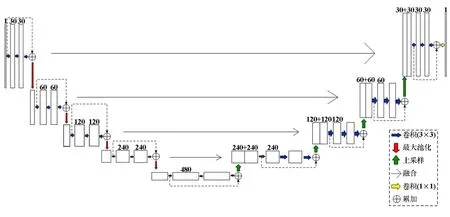
图4 Res-UNet 结构
模型训练算法为随机梯度下降算法,训练过程中使用网格搜索来调整模型超参数,用Adam 优化器计算和调整权重。 利用不同卷积核采样可获得体现滑坡纹理的浅层特征,在网络深层卷积结构中获取从类别上有较好区分度的深层语义特征。 UNet 模型的损失函数选择基于二分类交叉熵损失函数,计算公式为:
式中Tloss表示模型的交叉熵损失,其值越小,模型预测效果越好;P表示样本像素的真实分布,取值0 或1;Q表示样本像素的预测分布,取值范围从0 到1。
Res-UNet 模型输出结果为一张图像,其像素值对应滑坡的预测概率。 设定阈值,将滑坡图像二值化,获得滑坡分割结果。
2.2 林下滑坡持续同调特征
拓扑学不考虑物体的形状和大小,而关注其位置关系,主要工具是持续同调。 通过计算数据集在不同尺度下的拓扑特征,能更真实地反映空间特征,在多尺度下持续出现的拓扑特征通常被认为是数据的真实特征,反之则被认为是误差。 通过计算单纯复形拓扑特征的存在时间,分析数据集的同调性质。
山脊可以凸显滑坡体的“持续”形状特征,为提取滑坡拓扑特征,首先识别山脊。 山脊常位于地面起伏变化较大的位置,数学上与地形曲面拟合函数的导数有关,表现为滑坡表面粗糙度或曲率的变化。 地形曲面拟合函数f(x,y)为:
式中x,y为局部坐标;a,b,c,d,e,f均为拟合函数的系数,通过最小二乘法从DTM 影像中拟合得到。
利用地形曲面函数的参数与局部坐标点计算该点处的最小曲率Kmin和最大曲率Kmax,并计算其平均值即可获得平均曲率Kmean,提取研究区山脊:
以曲率标准差为阈值检索并提取山脊,经离散化后提取图像边界上离散点坐标,以行表示点序,以列记录坐标,构建离散点集,进行持续同调运算,并选择Alpha 复合形作为持续同调中的单纯复形。
计算持续同调过程中点集的拓扑特征,将滑坡在几何上的拓扑特征转化成了代数上的拓扑特征,并以山脊拓扑特征来指代滑坡。 为选择合适的拓扑特征,以存在时间和产生时间为阈值:存在时间指拓扑特征从形成到消失的时间段,即特征持续时间;产生时间指特征形成的时间,即特征首次出现的时间(如图5 所示)。

图5 滑坡的持续同调特征提取流程
2.3 结合深度学习和持续同调的滑坡特征提取
如图6 所示,结合持续同调方法提取的滑坡拓扑信息和深度学习分割得到的滑坡区域,通过计算深度学习分割的滑坡区域中滑坡拓扑面积所占比例,设置阈值为0.3,对研究区进行判定,视达到阈值的滑坡区为实验提取的滑坡区域。
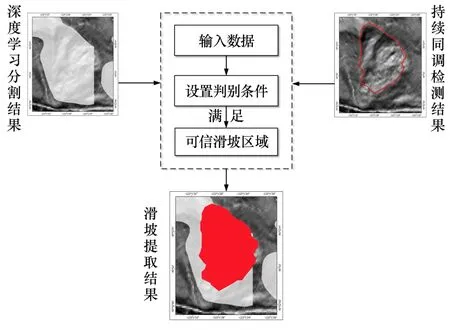
图6 提取可信滑坡区域
3 实验结果与分析
3.1 局部滑坡示例
滑坡提取局部示例见图7,其中左侧为应用Res-UNet 模型分割滑坡的结果,可见采用深度学习进行滑坡提取可行。 然而该方法容易出现过拟合情况,使部分平缓区域被误判为滑坡,仅采用改进的UNet 模型进行滑坡提取并未达到实验目的。 图7 右侧为应用持续同调原理获取的滑坡拓扑特征,将其与深度学习提取结果相叠加,可发现持续同调圈定滑坡范围效果较好。
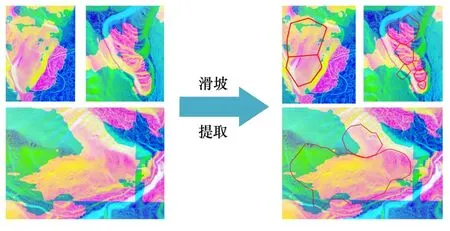
图7 滑坡提取局部示例
3.2 评价指标及分析
从研究区中选取3 个区域,将提取滑坡数据与已知滑坡信息叠加,计算混淆矩阵,作为计算各种评价指标基础,结果如图8 所示。
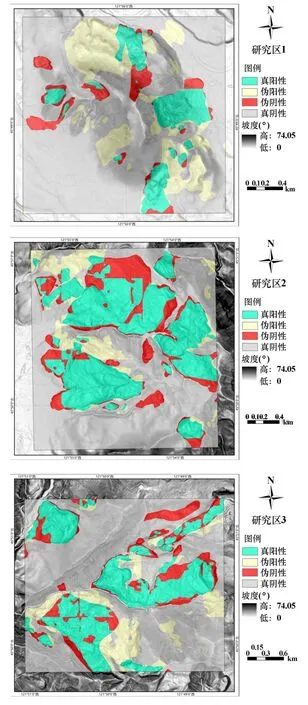
图8 各研究区分析结果
选择准确度(Accuracy)、精度(Precision)、召回率(Recall)和F1值对滑坡提取结果进行精度评价。 计算公式为:
式中TP表示真阳性,标签为滑坡时的滑坡面积;FP表示伪阳性,标签为非滑坡时的滑坡面积;FN表示真阴性,标签为滑坡时的非滑坡面积;TN表示伪阴性,标签为非滑坡时的非滑坡面积。
表1 为精度评定结果。 实验提取的准确度均值为79.7%,精度均值为63.1%,召回率均值为70.2%,F1均值为65.5%,所用方法达到预期精度。 可以看出,基于深度学习和持续同调的滑坡提取方法整体提取效果较理想,能准确识别研究区内的大部分滑坡。
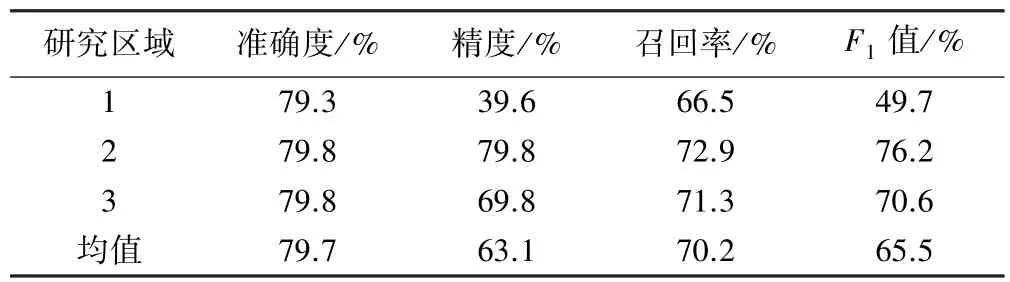
表1 预测结果精度评价
4 结 语
1) LiDAR 技术具有较强的植被穿透能力,滤波后的地面点云能较精确地反映地表信息,基于LiDAR 技术的滑坡提取研究可有效捕捉真实地表信息,达到对植被茂密地区进行林下滑坡提取的目的。
2) 采用深度学习和持续同调相结合的滑坡提取方法进行林下滑坡提取,对3 个区域进行定量分析,准确度均值为79.7%,精度均值为63.1%,召回率均值为70.2%,F1均值为65.5%,表明结合Res-UNet 和持续同调的方法提取效果较理想,能准确识别研究区内的大部分滑坡。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
河北地质(2021年1期)2021-07-21 08:16:08
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北方交通(2016年12期)2017-01-15 13:52:59
水利科技与经济(2016年6期)2016-04-22 05:07:30
山东青年(2016年3期)2016-02-28 14:25:50
