
面向内存表的可动态配置预写日志框架
2023-11-16 00:51朱海铭黄向东乔嘉林王建民
计算机与生活 2023年11期
朱海铭,黄向东+,乔嘉林,王建民
1.清华大学 软件学院,北京 100084
2.大数据系统软件国家工程研究中心,北京 100084
预写日志(write-ahead logging,WAL)[1]是一种能在设备故障中保障数据库管理系统持久性和原子性的技术,所有对数据的修改都会在实际修改数据库文件之前被记录到预写日志文件中。为减少磁盘的读写(input/output,I/O)开销,数据库通常会在内存(memory)中缓存对数据的修改操作,在积累到一定量形成内存表(memory table,MemTable)后再落入磁盘,如果数据库在内存表落盘前发生故障,内存表中包含的数据就可能被丢失或损坏,预写日志的用途就是保障这部分数据的持久性和原子性。
预写日志是写入请求与磁盘交互的第一关,因此预写日志的写入吞吐能力基本决定了数据库整体的写入性能上限。因此,如何让预写日志在变化的应用负载和计算环境下充分利用磁盘的I/O 性能成为了一个至关重要的问题。一般来讲,优化I/O性能可以从以下几个方向入手[2]:(1)批量写入,增大每次系统调用写入的数据量;(2)将磁盘的随机I/O 转换为顺序I/O;(3)提高写入内存的并发度。然而在很多NoSQL 数据库的实现中,预写日志和数据库或数据分区间的对应关系是强耦合的,如LevelDB[3]中预写日志和数据库实例形成一对一关系,InfluxDB[4]中预写日志和数据分片(shard)形成一对一关系,Apache-IoTDB[5-6]中预写日志和时间分区(time partition)形成一对一关系等。这种内存表和预写日志间强耦合的对应关系恰恰无法利用上述的优化手段,限制了数据库在预写日志上针对I/O 性能进行调优的可能性。当内存表数量因应用业务或计算环境发生变更而变化时,与之耦合的预写日志的资源占用会一同发生变更,写入请求被分散到不同的预写日志上,不仅无法进行批量写入,还降低了同一预写日志中内存写入的并发度。在极端情况下(如预写日志数量达数千量级),零落分散的预写日志还会产生大量磁盘随机I/O,造成性能下降[7]。虽然当前有部分数据库系统考虑到了将预写日志与内存表解耦(如HBase[8]),但它们的解耦方式不仅无法在运行时动态调整预写日志数量,还存在着因主动触发低频数据内存表落盘而导致查询效率下降的缺陷。
针对上述问题,本文基于预写日志中的重写日志(Redo log)[9],提出了一种面向内存表的可动态配置日志框架:将预写日志和内存表解耦,内存表可以动态地被分配给不同的预写日志队列,支持可变的对应关系。预写日志模块的资源占用更易控制,当计算环境和应用负载发生变化时,能够在不重启的情况下通过简单地调整预写日志的配置来快速实现动态性能调优。框架使用内存表快照来避免现有方案中主动触发低频数据内存表落盘带来的查询性能损失,既能控制日志文件的总大小,又能保障较高的查询效率。同时,本文在使用日志结构合并树(logstructured merge-tree,LSM-tree)[10-11]的Apache IoTDB上实现了预写日志框架,并在合成的数据集和工作负载上进行了相关实验。实验结果表明:(1)与强耦合的预写日志方案相比,该框架能够更好地适配不同的计算环境和应用负载,通过调整预写日志数量获取最佳的写入性能;(2)与已有的解耦方案相比,该框架不仅能够在不重启的情况下进行动态配置,还能在几乎不影响写入效率的同时更好地保障低频数据的查询效率。
1 相关工作
本文调研了多个使用LSM-tree 的存储系统,包括LevelDB、InfluxDB、Apache IoTDB、HBase等。
LevelDB中预写日志和数据库实例个数相耦合,每个数据库实例对应一个预写日志。当写入请求增多时,预写日志很容易成为性能瓶颈,必须通过增加数据库实例个数来提高写入速度,而过多的数据库实例又会产生大量磁盘随机I/O,造成写入效率下降,可配置性差。
InfluxDB中预写日志和数据分片个数耦合,每个正在写入的数据分片都会有自己对应的预写日志文件。和LevelDB相比,InfluxDB的预写日志管理粒度更细致,因此更容易因计算环境和应用负载变更暴露性能问题,当数据分片数量增加时,内存占用和I/O任务数会同时线性增加。
Apache IoTDB 和InfluxDB 类似,其预写日志和正在写入的数据文件个数耦合。除了存在与Influx-DB相同的问题外,IoTDB在开启时间分区功能后,由于其不恰当的预写日志内存管理机制,系统甚至可能因为发生内存溢出(out of memory,OOM)而进入不可用状态,开启时间分区后的系统可用性较差。
HBase虽然考虑了预写日志与内存表的解耦,但其实现的解耦方案不够彻底,且带来了查询效率降低、文件合并(compaction)[12]开销大的隐患。在当前实现中,Hbase包含多个HRegionServer,每个HRegion-Server 包括HRegion 和HLog(对应预写日志)两部分,每个HRegion 中包含多个MemStore(对应内存表),系统启动时可以指定HLog 实例的个数,每个HRegion 在创建时被固定地分配一个HLog 实例,在系统运行时永不变更。这样的解耦方案主要有两个缺点:首先,由于HRegion和HLog之间的关系在运行时是固定的,当系统启动后,HLog 的个数无法变更,计算环境和应用负载变化后只能通过重启系统来调整预写日志;其次,HBase将多个MemStore的数据集中管理,当某个MemStore中的数据积累过慢时,预写日志很容易占用大量的磁盘空间。为了避免历史数据的大量累积,HBase 会通过触发这些MemStore 的落盘来删除历史数据。由于这些MemStore通常保存着低频数据,这样粗放的管理方式会导致磁盘上产生很多小文件,不仅会大幅降低查询效率,还加重文件合并的负担。
因此,本文提出的预写日志框架需要解决以下三点问题:(1)将预写日志与数据库逻辑模型、分区配置等解耦;(2)可在运行时动态配置预写日志,无需停机重启;(3)在保障读写性能的同时,使日志的磁盘占用总量可控可治。
2 预写日志框架
2.1 架构概述
如图1所示,每个预写日志队列包含一个阻塞队列、两个缓冲区、多个日志数据文件(.wal 文件)和一个日志控制文件(.ctrl文件)。
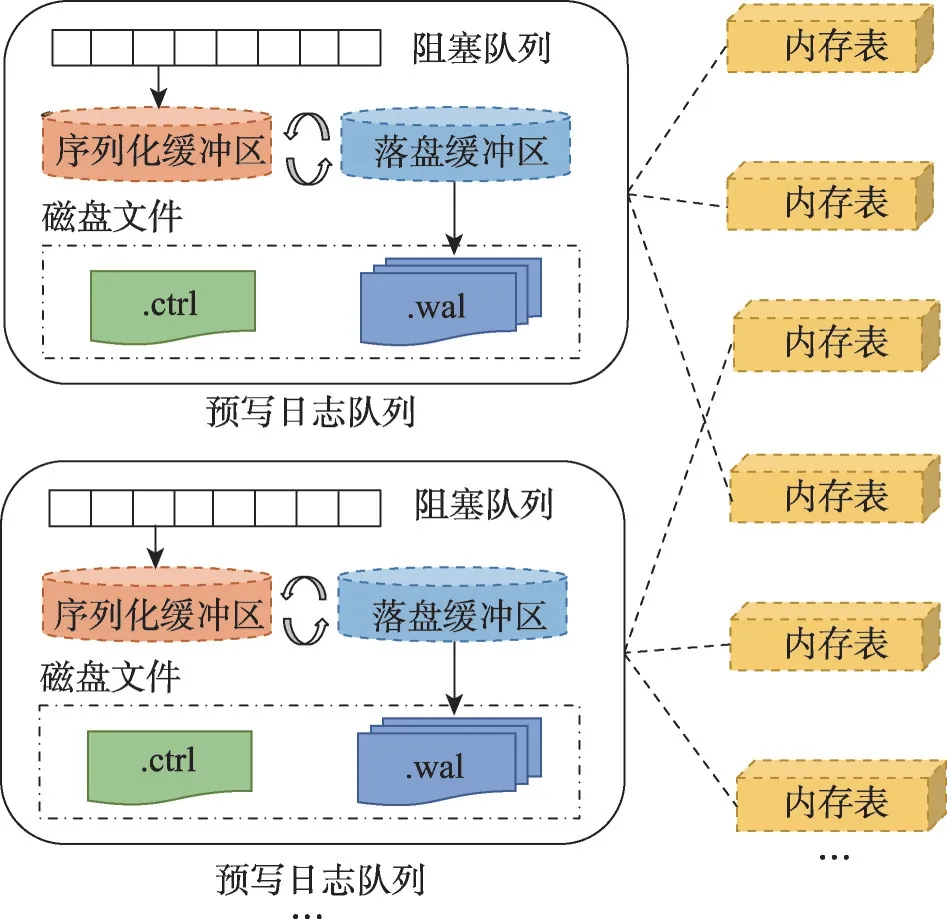
图1 预写日志框架架构Fig.1 Architecture of write-ahead logging framework
(1)阻塞队列。为了增大每次系统调用写入的数据量,使用阻塞队列缓存内存表的数据项。序列化任务从队列中批量取出数据项,序列化至缓冲区后落盘至预写日志文件中。
(2)缓冲区。为增加并发度,从物理上将缓冲区分为大小相等的两块,分别用于序列化和落盘。存在两类后台线程,序列化线程负责将数据项序列化到序列化缓冲区中,磁盘同步线程负责将落盘缓冲区同步到磁盘。当序列化缓冲区需要落盘时,序列化线程会阻塞直至落盘缓冲区落盘成功,然后交换两个缓冲区,清空已落盘的缓冲区用于保存新的序列化数据,最后通知磁盘同步线程将序列化好的缓冲区落盘。
(3)日志文件。预写日志的数据项和控制项分开存储,便于重启时快速恢复控制信息。一个预写日志队列下会有多个日志数据文件和一个日志控制文件,日志数据文件存储一个或多个内存表中的数据项,日志控制文件存储内存表的创建和落盘信息。
预写日志的个数可灵活配置,内存表被动态地分配给不同的预写日志队列,形成可变的对应关系,即一个预写日志队列可以处理任意数量内存表的预写日志。
2.2 日志数据文件和日志控制文件
日志数据文件保存数据项二元组
日志控制文件保存内存表的相关信息,包括内存表的编号、落盘的目标文件和其初始数据项所在日志数据文件的编号。其中主要包含以下两种日志信息类型:(1)
数据项和信息项的落盘顺序必须满足以下条件:(1)只有在
重启恢复时先读取日志控制文件,确定需要恢复的内存表(有创建信息但无落盘信息),然后读取日志数据文件,过滤出待恢复的数据项,将数据项重新组成内存表后落盘即可。
2.3 日志数据文件的删除
(1)理想情况。如图2(a)所示,在理想的删除流程下,只需要比较所有未落盘内存表初始数据项所在文件的编号,获取其中最小的文件编号,然后删除该编号前的所有无效日志数据文件即可。
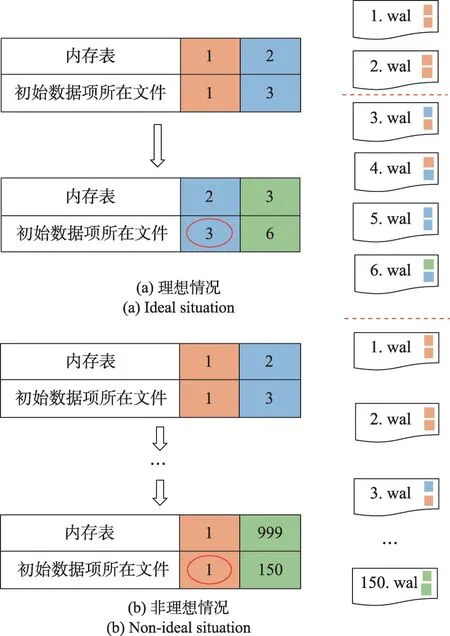
图2 日志数据文件删除Fig.2 Logging data file deletion
(2)非理想情况。单个数据文件中包含一个或多个内存表的数据,因此在非理想情况下(如图2(b)所示),只要有一个内存表未落盘,那么这个数据文件就无法被删除。因此,如果存在内存表数据积累过慢的情况,那么预写日志就会占用大量磁盘空间。HBase 采用主动触发内存表的落盘来释放预写日志的磁盘占用,但是这种额外触发落盘的行为会大幅降低查询效率[13],因此本文考虑通过在预写日志中引入内存表的快照来避免小内存表的落盘。对内存表做快照后,其全量信息被保存在最新的日志数据文件中,通过更新初始数据项所在的文件编号就可以安全地删除大量积累的旧日志数据文件。由于做快照和正常写入流程一样使用预写日志队列的缓冲区进行序列化,不会产生额外的内存开销。
此外,预写日志文件的磁盘占用和内存大小正相关,当内存表占用的内存总量上升时,其对应的预写日志磁盘占用也会上升,因此单纯使用磁盘占用大小来触发数据表的快照是不合适的。本文通过计算日志数据文件中有效信息的占比来控制预写日志的磁盘占用,每次滚动数据文件时计算有效信息占比,当占比低于给定阈值时,主动触发内存表的快照释放文件占用,进而清理无效文件减少磁盘占用。其中,有效信息占比的计算方式为sizememory/(sizememory+sizedisk),这里可以直接使用内存大小指代磁盘大小,因为内存表大小sizememory与其磁盘占用大小sizedisk间存在固定的放缩比γ,即sizedisk=γ×sizememory。计算sizememory值可以通过对当前所有内存表的大小直接求和获得。计算sizedisk需要额外给每个日志数据文件维护一个内存统计值,该统计值记录了日志数据文件从开始写入到封口期间所有落盘内存表的大小之和,这样就可以将对sizedisk的计算转换为对当前所有日志数据文件的内存统计值的求和。
2.4 在Apache IoTDB中的实现
SSTable 是LSM-tree 中的关键数据结构,用于保存一块连续的数据,所有写请求在写入预写日志后再写入内存中的SSTable,这就构成了本文中预写日志和内存表之间的对应关系。因此,只需要在任意一个基于LSM-tree实现的数据库管理系统中实现本文提出的框架,就能验证该框架的有效性。
本文选取Apache IoTDB 实现了预写日志框架。Apache IoTDB是基于LSM-tree实现的,一体化收集、存储、管理与分析物联网时序数据的开源时序数据库管理系统[14]。在Apache IoTDB 中,每个时间分区拥有一个内存表,预写日志和内存表一一绑定,当内存表数量因计算环境和应用负载发生变更而变化时,预写日志的资源占用随之产生波动,很容易发生内存溢出和性能下降。在实现该框架后,预写日志和内存表解耦,可针对不同计算环境和应用负载灵活调整出最佳实践方案,下面将用实验证明该结论。
3 实验分析
本章首先验证了不同应用负载和计算环境下,预写日志队列数量对写入性能的影响,证明框架能够在不同场景下找到最佳的配置方案。其次,设计实验对比为低频内存表做快照和直接刷盘相比读写性能的差异,证明与现有方案使用的刷盘策略相比,本文提出的快照策略能够在几乎不影响写入效率的同时更好地保障查询速度。
3.1 实验环境与数据
本节的所有实验都使用一台配置如表1 的服务器,并使用时序数据库性能测试工具IoTDBBenchmark[15]统计写入和查询的效率。在同一台服务器上部署IoTDB-Benchmark 和Apache IoTDB,使用IoTDB-Benchmark 生成数据集,为每个内存表创建40 000 条时间序列(40 个设备,每个设备下1 000 个测点),并在每条时间序列内写入10 000个数据点。

表1 实验环境Table 1 Experimental environment
3.2 不同应用负载和计算环境写入性能对比
本实验通过变化内存表数量模拟不同的应用负载,通过固态硬盘(solid state disk,SSD)和机械硬盘两种设备模拟不同的计算环境。分别在25 个内存表(占用4 GB内存,对应图3(a))、50个内存表(占用8 GB 内存,对应图3(b))、100 个内存表(占用16 GB内存,对应图3(c))下对写入性能进行测试,统计每秒写入的数据点数,以耦合方案(25、50、100 个预写日志队列)下的写入性能为基线对比不同队列数量下写入性能的差异。
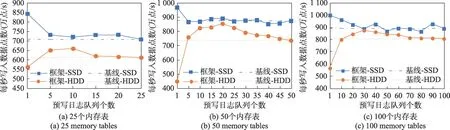
图3 不同应用负载和计算环境下写入性能对比Fig.3 Write performance comparison under different application loads and computing environments
实验结果如图3 所示,最大性能提升如表2 所示。在使用SSD 的场景下,多队列的写入性能近似相同,只有使用1 个队列时的写入性能最佳,性能较耦合方案分别提升了约19%、11%、12%。在使用HDD 的场景下,大多数场景的写入性能均好于耦合方案的写入性能,其中分别是使用10、25、30 个预写日志队列的写入性能最佳,性能较耦合方案分别提升了约8%、16%、8%,甚至能够逼近相同配置下使用SSD 的写入速度。综合来看,在不同场景下,使用预写日志框架可以找到比耦合方案更优的预写日志配置方案。此外,结合三种场景来看,当应用负载(内存表数量)发生变化时,动态调整预写日志队列个数的方式能够适应不同应用负载,实现性能调优。这一点可以从使用HDD 的计算环境下看出,当内存表个数在25、50、100 之间变化时,只需在10、25、30 之间调整预写日志队列的数量,就可保障最佳的写入性能,可见该框架对动态性能调优的帮助。
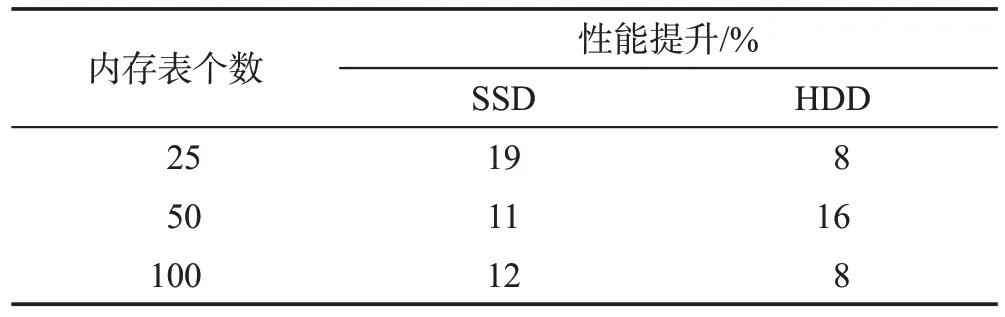
表2 最大性能提升百分比Table 2 Maxperformance improvement percentage
3.3 低频内存表处理方案对比
本实验使用1 个预写日志队列,并格外增加了1个内存表用于进行低频数据写入,从而模拟低频内存表造成预写日志文件堆积的情况。以现有方案采用的刷盘策略作为基线,通过统计读写操作的平均耗时,对比本框架提出的快照策略和现有方案使用的刷盘策略对读写性能的影响。查询共包括以下10种类型:精确点查询(Q1)、范围查询(Q2)、带值过滤的范围查询(Q3)、带时间过滤的聚合查询(Q4)、带值过滤的聚合查询(Q5)、带值过滤和时间过滤的聚合查询(Q6)、分组聚合查询(Q7)、最近点查询(Q8)、倒序范围查询(Q9)、倒序带值过滤的范围查询(Q10)。
实验结果如图4所示。从图4(a)可以看出,虽然本框架提出的快照策略耗时略大于现有方案使用的刷盘策略,约慢1.08%,差异较小,但是结合图4(b)可以看出,得益于不主动触发内存表落盘,本框架提出的快照策略对查询的收益是较大的,各类查询均快于现有方案使用的刷盘策略,可降低2%~20%的查询耗时。可见,快照策略能够在几乎不影响写入效率的同时更好地保障数据的查询效率。
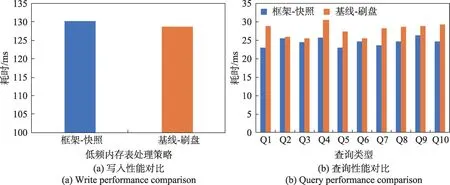
图4 快照策略和刷盘策略的性能对比Fig.4 Performance comparison between snapshot strategy and flush strategy
4 结束语
本文提出了一种面向内存表的可动态配置日志框架,能够将预写日志和内存表解耦,能针对不同计算环境和应用负载动态调整预写日志队列个数,实现动态性能调优。为了验证预写日志框架的有效性,本文基于Apache IoTDB实现了该框架,并设计了相关实验。实验证明该框架能够动态适配不同计算环境和应用负载,通过调整预写日志数量保障最快的写入性能。
计划在未来从以下几个方面进行改进:(1)使用增量快照替代全量快照。通过增量快照来避免因同一内存表被多次快照而导致的写放大(write amplification)问题[16]。(2)实现内存表的智能分配。基于数据写入频率对内存表进行分类,让写入频率相似的内存表共享预写日志队列,更智能地管理预写日志及其磁盘文件大小。
猜你喜欢
天津科技(2022年5期)2022-05-31
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
网络安全和信息化(2018年9期)2018-03-03
信息安全研究(2018年1期)2018-02-07
网络安全和信息化(2017年12期)2017-11-08
网络安全和信息化(2017年3期)2017-03-10
网络安全和信息化(2015年11期)2015-03-17
发明与创新(2015年21期)2015-02-27
