
NLP和知识图谱技术在钢铁电商用户分类场景的应用
2023-11-14 13:05沈海伦
宝钢技术 2023年5期
沈海伦
(欧冶云商股份有限公司,上海 200942)
在电商企业中,用户类型的识别是用户画像的基础,对精准营销具有重要意义。用户类型识别在消费品电商中通常会根据用户的购买行为、点击次数、页面留存、登录地址等信息进行分析,以用户偏好作为聚类。钢铁采购行为并不受采购员的偏好影响,而是根据图纸设计、生产周期、物料比例等要求进行规范操作,这种采购行为是一种高度标准化的、理性的行为。因此钢铁电商平台的用户分类模型需要结合行业自身特点进行设计。
在钢铁行业中通常会将用户分为3种类型:钢厂、钢贸商、终端企业。钢铁电商平台上游承接钢厂,下游触达终端企业,同时也为钢贸商提供服务,在整个产业链中提供批量钢材采购、物流与便捷支付和融资模式的市场角色[1]。
准确对钢铁电商平台的用户进行分类,可以带来以下优势:①帮助钢厂更加贴近需求端,了解终端市场的个性化需求;②提高交易质量,帮助终端企业买到价格合适、质量有保障的钢材;③为钢贸商提供技术服务,提升钢材的流通效率;④ 通过个性化的营销手段,吸引更多的企业上平台采购,帮助平台提高竞争力与影响力。
1 钢铁电商用户分类痛点及NLP、知识图谱技术发展现状
1.1 钢铁电商用户分类现状和痛点
钢铁电商平台对用户进行分类需要借助大量行业专家完成,常见流程为:人工阅读用户信息,根据经验对公司名称、注册信息等进行分类,简单计算交易的买入卖出量,用关键词打标签,之后根据判定结果结合电话回访或线下走访确定用户类型。
该方法的痛点在于公司信息的筛选对判定人员能力要求比较高,只有熟悉行业的专家才有能力进行甄别;且交易统计的颗粒度比较粗,仅计算买入卖出量,没有进一步提取它们的特征;此外人工判断效率较低,一个熟练的市场人员每人每天只能排查数十家企业,而电商平台的用户通常在百万到千万级别,完全依靠人工的方式耗时长、成本高。同一个人不同时间,或不同人之间判定的标准不够统一,分类的一致性不高。
钢铁电商平台需要一种使用机器替代人工批量对用户分类的方法,提高效率的同时保持分类的一致性。
1.2 NLP技术发展现状
NLP(natural language processing,自然语言处理)是近年来人工智能领域研究中的一个重要方向,是一门融语言学、计算机科学、数学于一体的科学。通俗地讲,自然语言处理技术主要是让机器理解人类自然表述的语言。
NLP技术包含了语法模型、规则匹配、映射表的使用等。近年来,深度学习模型得到快速发展,类似BERT[2]、GPT等预训练模型提供了易于使用的通用框架,尤其是BERT的出现无疑是NLP技术里程碑式的发展,多头的注意力机制和双向encoding让BERT的无监督训练更有效,并且使得BERT可以构造更宽的深度模型[3]。
基于BERT预训练模型的文本分类技术在工业领域已实现了一些应用,如在安全生产事故多标签分类任务中,将事故案例标记为物体打击、车辆伤害等20类事故类别之一;碰撞、爆炸等15种伤害方式之一;防护、保险等装置缺乏或缺陷等4大类不安全状态之一;操作失误等13大类不安全行为之一,共有52个标签[4]。说明在专业领域,通过合理构建模型及准备训练集可以取得预期效果。
1.3 知识图谱技术发展现状
知识图谱(knowledge graph)以结构化的形式描述客观世界中概念、实体及其关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。知识图谱作为计算机科学的一个研究分支,在电商行业也有应用案例。
知识图谱的数学基础——“图论”,在1736年由数学家欧拉提出。图论中的图是若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线代表相应的两个事物间具有这种关系[5]。
随着知识图谱技术的发展,对数据库工具也提出了更高的要求,以往使用关系型数据库求两个集合间的笛卡尔积效率较低,查询多层关系时代码复杂。为解决这些痛点而开发的图数据库在易用性和计算效率两方面都得到提升,使基于知识工程的复杂推理(图推理)和基于图论的信息流计算(图计算)得以广泛应用,也使业务专家能使用较低的成本构建推理和分析模型用于真实业务。
2 钢铁电商用户类型分析
2.1 钢铁电商用户类型及特征
针对钢铁电商3类不同用户即钢厂、钢贸商、终端企业,可以制定不同的营销策略。
钢厂:指生产钢铁材料并对外销售的企业(如宝钢、鞍钢、首钢等);
钢贸商:指转卖钢铁材料赚取差价和服务费的企业;
终端企业:指使用消耗钢铁材料用于制造产品的企业(如海尔、格力、大众等)。
在实际业务中,钢厂是集中度较高、行业特征非常明显的企业,在钢铁电商平台注册时即有专业营销人员对接服务,此外也可通过对比钢厂名录进行辨识,通常不存在辨识难度;而钢贸商和终端企业无法直接辨识,需要行业专家根据经验判断[6]。
企业名称特征分析:对某电商平台人工已验证的公司信息样本进行分析,发现终端企业的企业名称具有比较典型的特征,如“浙江东海煤机有限公司”“烟台市电缆厂”“沈阳泰达环保设备制造厂”等。
交易行为特征分析:以热轧钢卷或冷轧钢卷为例,钢厂生产出的钢铁材料大多都具有唯一的标识,这个标识被称为捆包号。根据钢材捆包的流转特征,所有平台用户的交易行为都可以抽象分类为如图1所示的3种类型。
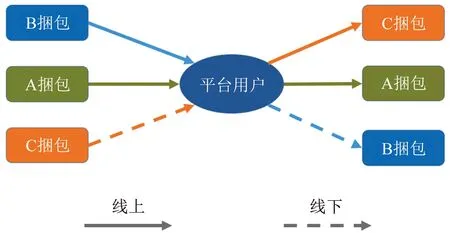
图1 钢铁电商平台用户交易行为特征分析Fig.1 Analysis of user transaction behavior characteristics on steel e-commerce platforms
A路径:该捆包被平台用户买入后再度卖出,可以定义为是一笔转手贸易。
B路径:该捆包在线上买入后不再卖出,是捆包流转路径的终点。捆包在平台上消失了,从数据的角度来看,通常这个捆包被认为是消耗掉(使用)。
C路径:该捆包来源于线下,是线上路径的起点。线下钢铁捆包的来源常见的有几种可能:钢厂期货订单转线上销售,钢厂的现货转线上销售,钢贸商库存调剂转线上销售等,是一种供应行为。
2.2 终端企业与钢贸商的特征分析
终端企业与钢贸商在两个维度上具有比较明显的特征差异:一是它们对钢材的处理方式,即采购钢材后是偏向消耗使用还是偏向转手倒卖。根据钢铁平台用户3分类的定义可以看出,终端企业采购钢材后偏向用于制造产品(消耗),而钢贸商采购钢材后更加偏向转手倒卖赚取差价。二是它们的公司名称大多具有明显的特征,比如当公司名称包含“制造”“机械制造”“电缆厂”“设备生产”等词语时,该公司很有可能是终端企业,但当名字包含“进出口”“贸易”“商贸”“工贸”时,该公司更有可能是钢贸商。
3 技术方案设计与实施
3.1 方案框架
基于以上分析,设计一套同时考虑公司名称分类和交易行为计算的模型,可以实现对用户类型进行辨识的目的。
在对公司名称进行分类时,采用文本分类技术进行终端企业与钢贸商的分类。常见的文本分类技术有基于关键词的文本分类和基于深度学习的文本分类两种实现方式[7]。由于深度学习技术可以考虑文本中所有文字的权重,对于未学习过的文字也可以给出一定程度的判断,具有比较优秀的泛化能力,所以本研究选择深度学习模型进行文本分类。
仅使用公司名称进行文本分类预测企业类型的准确率还不高[8],需要结合交易行为进行综合判断。采用知识图谱技术用节点和关系表达出企业之间的钢卷捆包流转关系,可以计算出各家企业的钢材交易特征值。
最后通过规则模型对公司名称分类和交易行为计算的结果进行综合判断,给出对平台用户分类的最终结果。详细技术框架如图2所示。
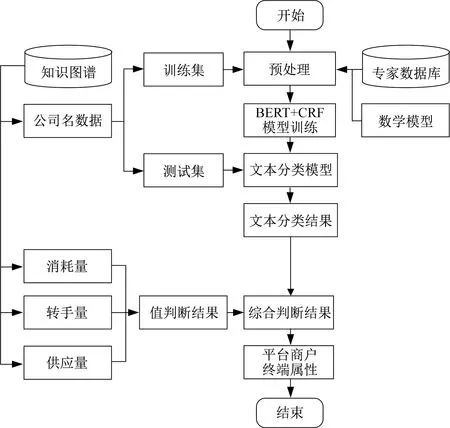
图2 技术方案流程图Fig.2 Technical solution flowchart
3.2 实施步骤
步骤一:数据准备。
本研究使用的数据均为某钢铁电商平台内部数据,属于非公开数据集。数据包括如下内容:
(1) 已经过验证标注的公司名称3 200条,作为深度学习分类模型的训练集。
(2) 5 891条待预测公司的工商注册企业名称,使用训练后文本分类模型进行公司名称分类。
(3) 5 891家待预测公司一个自然年内的交易数据约100万条,作为知识图谱建模数据。
步骤二:基于深度学习的文本分类模型建设。
使用基于BERT的多标签文本分类模型,GPU选择英伟达2080Ti,训练集共3 200条已标注样本,其中终端企业样本1 054条,钢贸商样本2 146条,模型训练时间2 365 s。
训练完成后用测试集进行验证,测试集包含1 112条数据,其中标注为钢贸商973条,标注为终端企业139条。验证结果如表1所示。

表1 公司名分类模型精度Table 1 Accuracy of company name classification model
使用该模型对5 891家待预测公司名称信息进行分类并记录结果。
步骤三:基于知识图谱技术的公司交易行为计算。
交易知识图谱建模的方式参考了电力系统的建模经验[9],从关系型数据库中获取原始交易数据,利用数学模型对数据进行清洗计算构建交易知识图谱,最后使用图数据库工具Neo4j存储实体和关系。
在知识图谱建模中每个节点表示一家公司,节点与节点间的每条关系代表一次钢铁交易订单,关系上的属性包括了钢材品类、规格、成交量等。交易图谱样例如图3所示。

图3 交易图谱样例Fig.3 Example of trading knowledge graph
对于平台上的每笔交易进行特征计算并分类:
(1) 转手行为:数据特点为入度和出度的关系中捆包号相同,提取该关系并统计重量,定义为“转手量”。
(2) 消耗行为:数据特点为一个捆包只有入度没有出度,提取该类关系并统计重量,定义为“消耗量”。
(3) 供应行为:数据特点为一个捆包只有出度没有入度。提取该类关系并统计重量,定义为“供应量”。
使用Cypher语句编写图算法[10],在图数据库中遍历所有公司节点和关系,计算出所有公司的特征值并记录结果。典型样例如表2所示。
根据业务经验设计规则判定模型:
供应量≤消耗量 且 转手量÷消耗量<0.1时,是一种供货少、转手少、消耗多的特征,常见于终端企业,返回判定值1;
供应量>消耗量 或 转手量÷消耗量≥0.1时,是供应量大或是转手量大的特征,常见于钢贸商,返回判定值0。
步骤四:综合判定。
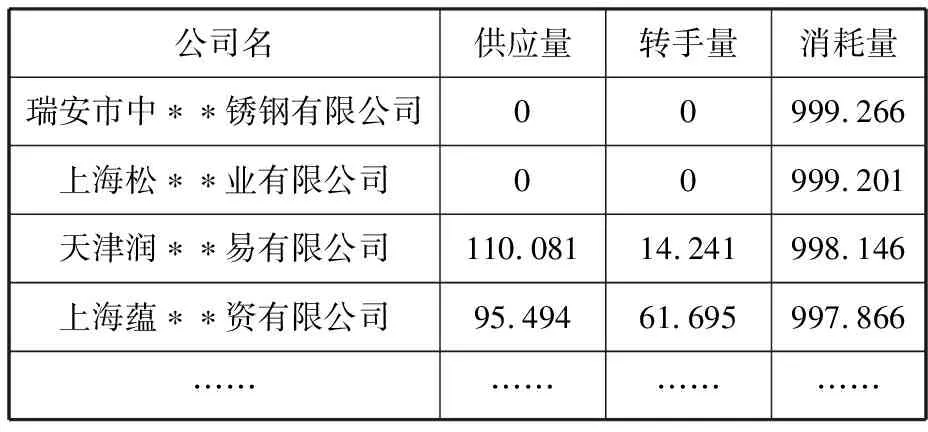
表2 平台用户某一自然年内计算结果(样例)Table 2 Calculation results of platform users within a certain natural year (sample) 单位:t
对公司名称分类和交易行为计算的结果进行综合判定:
(1) 当交易行为判断结果为1,且公司名称判断结果为“终端”时,综合判定为“终端”;
(2) 当交易行为判断结果为0,且公司名称判断为“钢贸商”时,综合判定为“钢贸商”;
(3)当交易行为判断结果为0,公司名称判断结果为“终端”;或交易行为判断结果为1,公司名判断结果为“钢贸商”时,综合判定为“待确认”,由行业专家进行人工确认。判定规则如表3所示。

表3 综合判断规则Table 3 Comprehensive judgment rules
4 实施效果
模型从5 891家用户中辨识出3 188家终端或贸易商,占总量的54.12%。其中贸易商2 261家,终端用户927家;另有2 703家需要人工确认,人工确认的比例为45.88%。模型可以减轻专家超过50%的工作量。
公司业务单元对预测清单进行了抽检回访,以验证模型的实际效果,准确性评价公式为:准确率=(回访正确的数量÷预测数量)×100%。
抽检520家预测为贸易商的用户,准确率为84.81%;抽检703家预测为终端企业的用户,准确率99%。
模型预测结果如表4所示。经评估本模型在确保一定识别精度的前提下,可以有效地减轻专家的工作量。营销团队通过精准定位终端企业,用相对更低的成本提高了优质客户的转化率,在实际业务中得以推广应用。此外该模型也可根据业务的需求进行灵活调整,只需要修改模型内综合判定规则的阈值指标,即可快速调整进行个性化的定制,以适用于不同的需求。
5 结语
本研究将先进的NLP和知识图谱技术应用于钢铁电商的真实业务中,实现了对钢贸商和终端企业进行自动辨识的功能,节省人工与时间成本。同时,模型设计了双重校验的方式,弥补单一技术的不足,提高分类判定的准确性,为同类业务场景提供了解决思路。此外,模型易于理解,数据可解释性高,各个模块充分解耦,可以根据业务需求进行灵活的调整,实现了用人工智能技术为传统业务赋能。
猜你喜欢
阅读(高年级)(2022年10期)2022-11-11
少先队活动(2020年12期)2021-01-14
小学生作文(低年级适用)(2019年5期)2019-07-26
财会学习(2018年24期)2018-09-19
航空世界(2018年12期)2018-07-16
中成药(2017年3期)2017-05-17
军事文摘·科学少年(2016年8期)2016-11-02
领导科学论坛(2016年9期)2016-06-05
商(2016年7期)2016-04-20
财经界(学术版)(2015年11期)2015-03-19
