
基于特征筛选和集成学习的轴承故障诊断
2023-11-06 05:20陈生凡郑小霞
上海电力大学学报 2023年5期
陈生凡, 郑小霞
(上海电力大学 自动化工程学院, 上海 200090)
轴承长期在复杂多变的环境中高速运转,容易发生故障[1-2],进而造成严重的经济损失,因此对滚动轴承进行故障诊断具有重要意义。在针对轴承的故障诊断研究中,一般通过小波变换、经验模态分解、变分模态分解和辛几何模态分解等时频分解方法处理信号并提取特征。但随着特征维度的增加,特征冗余、计算复杂性和诊断稳定性等问题也随之而来,因此很多学者围绕特征优选进行了研究[3]。URBANOWICZ R J等人[4]利用Relief F算法对特征进行筛选,但是该算法对噪声非常敏感。YANG S Y等人[5]将Fisher score与域间最大均值差异相结合,筛选出有利于变工况故障诊断的特征。RAM V S S等人[6]提出了一种新的特征评估和筛选方法,并对用户手臂运动识别起到很好的作用。以上方法均是对单一特征进行评估选择,没有综合考虑特征之间的组效果。张洁等人[7]考虑到特征的有效性和互补性提出了新的特征筛选策略,并对居民用电行为进行聚类分析,取得了很好的效果。
随着人工智能的发展,机器学习在轴承故障诊断中得到了广泛应用。常见的机器学习方法有支持向量机(Support Vector Machine,SVM)、K最近邻(K-Nearest Neighbor,KNN)、决策树(Decision Tree,DT)和人工神经网络等。邓平等人[8]使用SVM作为分类器,对人体运动姿态进行识别,然而SVM的分类性能受到模型超参数的影响[9-10]且优化单一模型的参数无法达到更好的诊断效果。为了解决这一问题,研究人员提出了集成学习的思路。方继辉等人[11]采用XGBoost集成许多分类回归树构造集成模型,并改进萤火虫算法对其超参数进行优化,最终实现了对燃气轮机的故障诊断。LI H等人[12]采用了AdaBoost集成方法,将多个决策树集成为一个模型,实现了风机轴承的故障诊断。但AdaBoost只能集成相同的分类器,无法集成不同质的分类器。姜万录等人[13]利用Stacking方法将多个不同质的分类器进行集成,并用于旋转机械的故障诊断,但Stacking集成框架受基分类器性能的影响,因此Stacking基分类器的选择显得尤为重要。
基于上述研究,本文利用辛几何模态分解(Symplectic Geometry Mode Decomposition,SGMD)对信号进行分解后,提取时域、频域和时频域特征组成混合特征向量,综合考虑区分度、冗余度、关联度和域间最大均值差异等因素提出新的特征筛选策略,并筛选出有利于变工况故障诊断的特征。本文将Boosting和Stacking算法相结合,提出了一个新的集成学习故障诊断模型,从而提高故障诊断准确率。
1 特征筛选
传统的特征筛选方法一般是对高维特征向量中每一个向量进行评分,然后根据经验选出其中评分较高的前几个特征向量,但上述方法没有考虑到特征之间的关联度,而且最优特征的数量无法确定。本文提出了一种综合特征筛选(以下简称“综合筛选”)策略如下:首先,根据特征关联度对特征进行分组,将相似的特征分为一组;然后,从每组特征中选出评分最高的特征组成候选特征子集;最后,从特征子集中不断选取最大的特征加入最优特征子集,并进行综合评分,直到子集综合分数低于阈值后完成筛选。
1.1 特征关联度
利用皮尔逊相关系数[14]作为关联度指数,将具有高关联度的特征进行分组,并根据评分进行特征的初步筛选。特征x和特征y的关联度指数计算公式为
(1)
式中:ρxy——特征x和特征y的关联度指数,范围为[-1,1],ρxy越趋近于1则表示x与y越相关;
cov(x,y)——特征x和特征y的协方差;
σx、σy——特征x和特征y标准差。
1.2 单一特征评分函数构造
由于不同特征向量的分类准确率和跨域故障诊断准确率会有所不同,因此需要对特征向量进行筛选。本文从特征有效性和适合迁移两方面构造单一特征评分函数。
为了体现不同特征对分类的有效性,需要对每个特征都进行评价。将区分度指标定义为完全区分的样本个数占全部样本个数的比重。不同特征的区分度如图1所示。

图1 不同特征的区分度
对于k分类的特征可以构造出k×k的区分度矩阵D为
(2)
(3)
式中:dij——同一特征下第i类和第j类的区分度;
nij——两类不能区分的特征数量;
ni、nj——第i类和第j类的特征数量。
对于同类区分度的计算,结果越聚合则说明区分度越低。引入平均距离计算同类特征聚合程度Sj为
(4)
式中:n——样本总数;
xji——第j类的第i个样本;
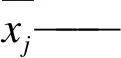
引入最大均值差异(Maximum Mean Discrepancy,MMD)[15]来衡量特征的可迁移性。MMD常用于衡量不同工况之间特征的分布差异。其值越大则说明不同工况的分布差异越大,不适合特征迁移;反之,则更适合迁移。MMD的公式为
(5)
式中:M——最大均值差异;
Xs、Xt——源域和目标域;
ns、nt——源域和目标域的样本数量;
φ——再生核Hilbert空间中的非线性映射函数。
综上,一个特征的类间区分度越大、类内区分度越低以及不同域差异越小,则该特征的评分就越高。
定义k分类特征的评价函数F为
(6)
式中:s(D)——矩阵D所有元素的和。
1.3 特征子集综合评分
特征子集不仅要考虑到特征的有效性和关联度,还要考虑维度的影响[16]。随着维度的增加,特征评分会有一定程度的提高,但分类器的计算量和学习时间也会相应增加。针对这一问题,本文给出特征子集评价函数p的公式为
(7)
式中:e-m——维度代价因子;
m——特征子集的维度;
Fi——第i个特征的评分。
设置阈值为0.1,当p<0.1时,完成特征筛选。特征筛选流程如图2所示。

图2 特征筛选流程
2 基于集成学习的故障诊断模型
2.1 AdaBoost集成方法
AdaBoost是一种基于Boosting集成算法改进的集成学习方法,通过将相同的弱分类器不断迭代集成一个强分类器。在第1次迭代中,基于相同权重D0的训练集训练一个弱分类器hi,并根据其分类器效果获取弱分类器的权重αi;然后,根据αi更新下一次训练集的权重Di+1;最后,将所有弱分类器的结果加权,得到最终的分类结果。
(8)
式中:εi——误差。
样本权重Di的更新公式为
(9)
式中:ηi——归一化因子;
yi——实际标签结果;
hi——分类器输出结果。
通过加权得到强分类器H,公式为
(10)
2.2 Stacking集成方法
Stacking通过结合多个不同基础模型的预测结果来训练元模型,再利用元模型来得到更准确的预测结果。
Stacking集成模型一般分为两层。第1层利用不同的基分类器预测同一数据集的分类结果,然后将预测结果作为第2层的输入,并继续训练,进而得到最终结果,以达到提高模型泛化能力和分类准确率的目的。但Stacking的分类结果容易出现过拟合,因此需要对第1层的基分类器进行交叉验证。
Stacking基分类器的5折交叉训练过程如图3所示。其中,model表示分类模型,将训练集分为5折其中4折用于训练模型,1折用于预测,重复5次;Train表示训练集;Predict表示预测的结果;Testlab表示在训练好的模型下目标域的预测结果。
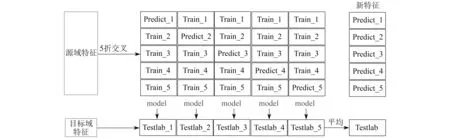
图3 Stacking基分类器5折交叉训练过程
2.3 集成学习故障诊断模型
AdaBoost将多个相同的弱分类器集成为一个强分类器,具有准确率高且不容易过拟合的优点,但该方法只能集成相同的分类器;Stacking则能够集成不同类型的分类器,充分发挥各种分类器的优点,但其分类准确率过于依赖基分类器的分类准确性。基于此,本文将AdaBoost和Stacking相结合来构成集成模型。首先,用AdaBoost将SVM、KNN和DT进行集成,构成3个Stacking的基分类器。然后,利用逻辑回归作为元分类器构成最终的集成学习故障诊断模型(以下简称“集成模型”)。集成模型如图4所示。
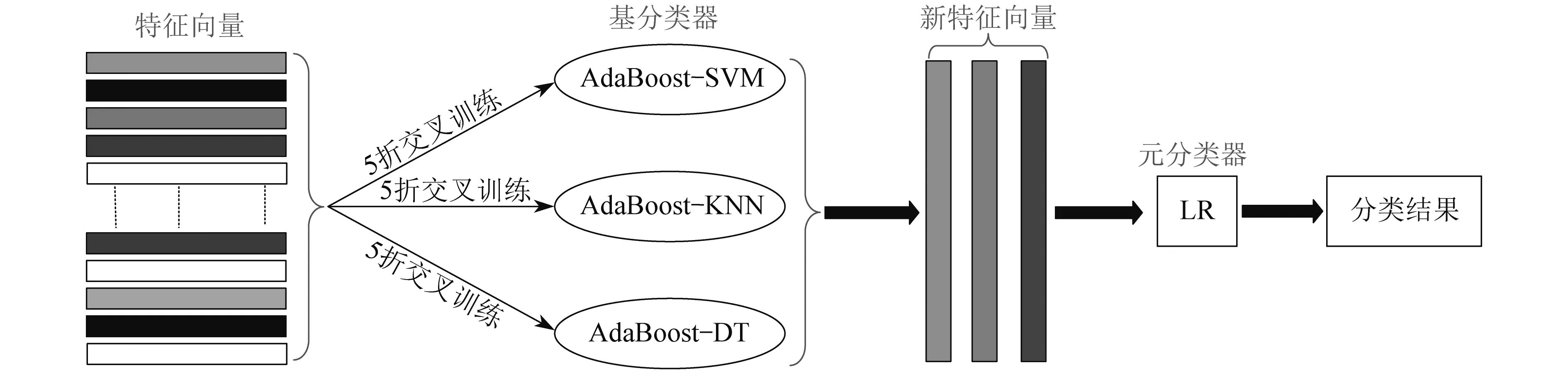
图4 集成学习故障诊断模型
3 实验与分析
3.1 实验数据说明
本文选用西储大学滚动轴承数据,轴承型号为6205-2RSJEM SKF型深沟球轴承,采集1 730 r/min、1 750 r/min和1 772 r/min转速下的3个数据集,并分别记为A、B、C。其中,每个数据集采样频率均为 12 kHz,包含内圈故障、外圈故障和滚动体故障3种故障类型。每种故障类型又分别包含3种不同单点损伤直径(0.177 8 mm、0.355 6 mm、0.533 4 mm)故障。与正常状态合计共10种类别,每种类别200个样本,共2 000个样本。
3.2 特征筛选
对源域和目标域2个域的信号采用辛几何模态分解[17],并计算前2个辛几何分量的最大值、最小值、平均值、峰峰值、绝对平均值、方差、标准差、峭度、偏度、均方根、波形因子、峰值因子、脉冲因子、绝对均方根、裕度、频率均值、重心频率、频率均方根、频率标准差和排列熵作为特征向量。然后,按顺序将40个特征进行编号和评分,并进行关联度分析,结果如图5所示。

图5 特征评分和特征关联度分析结果
将关联度大于0.9的特征组合在一起,并从每组中选出评分最高的特征。初步筛选结果如表1所示。
通过初步的筛选,从40个特征中筛选出18个特征作为候选特征。将候选特征逐一加入到最优特征子集中,得到不同数量下特征子集的综合评分,并根据评分筛选出3、11、12、14、16、20、31、36组成最优特征子集。不同数量下特征子集的综合评分如图6所示。
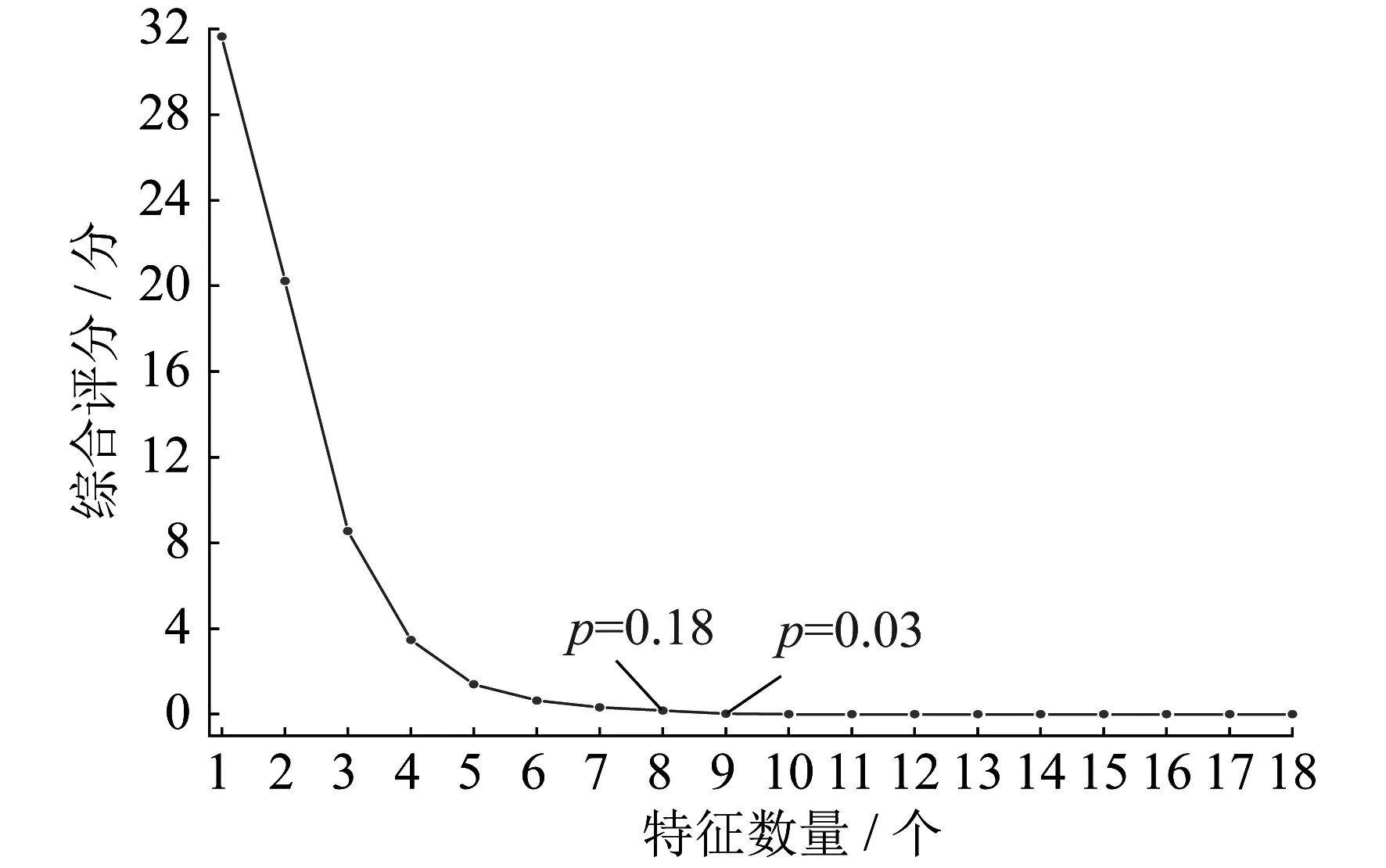
图6 不同数量下特征子集的综合评分
为验证本文所提策略的有效性,选用传统的特征筛选方法Relief和mRMR与本文所提出的综合筛选方法进行对比。采用t分布随机邻居嵌入(t-SNE)降维方法,将原始特征与各种方法筛选的结果以二维散点图的形式呈现,结果如图7所示。
由图7可以看出,原始特征不仅在不同类别间不易区分,而且不同域之间的分布也存在一定的差异。传统的特征筛选方法Relief和mRMR能将不同类别区分开,但在不同域之间差异依旧存在。本文所提出的综合筛选方法所筛选出的特征,不仅使不同类别间较易区分,而且相同类别在不同域的差异也有所降低。这证明本文的筛选策略更有利于变工况故障诊断。
3.3 基于集成学习的变工况故障诊断
在完成特征筛选之后,综合筛选的特征仍会存在一些类别较易混淆,因此利用集成学习模型进行故障诊断。
为了验证集成学习模型的实用性,本文共设置6个迁移任务,分别为A→B、A→C、B→A、B→C、C→A、C→B。
对6个迁移任务分别采用SVM、KNN、DT与集成模型进行故障诊断实验。故障诊断准确率如表2所示。

表2 不同模型下6个迁移任务的故障诊断准确率 单位:%
由表2的故障诊断结果可以看出,6个迁移任务中集成模型的准确率均高于单一模型。集成模型的平均准确率相较于单一模型分别提高了3.72%、3.45%、7.24%。这说明集成模型能够进一步提高故障诊断的准确性。
现实中采集到的轴承信号往往存在大量噪声,为了进一步验证集成模型的性能,在原始的振动信号中加入不同信噪比的高斯白噪声模拟现实故障信号。对添加噪声的信号进行辛几何模态分解并提取特征,通过综合特征筛选后,采用SVM、KNN、DT和集成模型进行故障诊断。不同信噪比下各模型故障诊断平均准确率如图8所示。
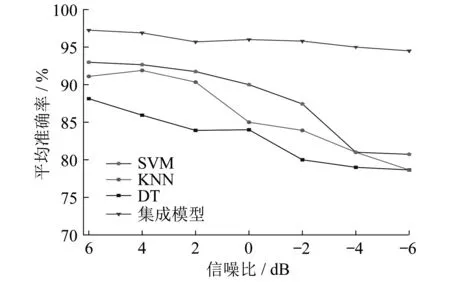
图8 不同信噪比下各模型故障诊断平均准确率
根据表2和图8的结果可知,加入噪声后所有模型的故障诊断准确率都有所下降。随着噪声信噪比的降低,单一模型的准确率快速下降,但本文所提出的集成模型则较为稳定,准确率保持在94%~98%之间。这说明集成模型不仅有较高的故障诊断准确率,而且还有一定的鲁棒性。
4 结 语
本文针对变工况条件下风机轴承故障诊断准确率低的问题,提出了一种基于特征筛选和集成学习的轴承故障诊断方法。通过实验证明,本文提出的特征筛选策略所筛选出的特征相较于传统方法更有利于变工况分类;在相同的特征集下,集成学习模型相较于单一模型有较高的故障诊断准确率,且在不同噪声下表现也更为稳定。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国校外教育(2019年12期)2019-04-15
江淮论坛(2018年4期)2018-08-24
水利科技与经济(2017年12期)2017-04-22
福建中学数学(2016年5期)2016-11-29
心理学探新(2015年3期)2015-12-27
电源技术(2015年11期)2015-08-22
都市丽人(2015年4期)2015-03-20
