
概念漂移下的系统日志在线异常检测模型
2023-11-02 12:37吕宗平梁婷婷顾兆军刘春波
计算机应用与软件 2023年10期
吕宗平 梁婷婷,2 顾兆军 刘春波 王 双 王 志
1(中国民航大学信息安全测评中心 天津 300300)
2(中国民航大学计算机科学与技术学院 天津 300300)
3(南开大学人工智能学院 天津 300071)
0 引 言
系统日志是由监控系统基于程序代码预设条件下自动产生的富含大量描述系统(如分布式系统、操作系统)状态信息的事件集合[1],能够如实地记录所有信息系统的系统状态和行为[2]。在这些大型分布式系统中产生的日志大多数情况下可以看作动态达到的流式数据。与传统数据相比,这类日志数据具有动态性、无序性、无限性、突发性和体积大等特点。首先,大批量的日志数据源源不断地涌入,将这些日志数据完全存储下来几乎不可能;其次,数据具有时间属性,带有表示事件发生的时刻的时间戳信息;最后,样本分布、样本的特征可能随时间变化,呈现动态变化的特点[3]。传统中通过手工检查是不切实际的,目前,针对自动日志解析,学术界和工业提出了许多数据驱动方法,包括频繁模式挖掘(SLCT,及其扩展的聚类方法LogCluster)、迭代分区(IPLoM)、层次聚类(LKE)、最长公共子序列计算(Spell)和解析树(Drain)等[4]。网络日志分析对网络安全管理具有重要意义,但现有的网络日志分析系统具有无法处理海量日志数据、采用离线模式和处理时延较长等弊端[5]。结合自动日志解析实现一个高效且实时的基于系统日志的异常检测算法具有重要的理论意义和实际应用价值。
然而,由于动态变化和非平稳环境中发生的概念漂移或模型老化,动态生成的日志会导致传统异常检测算法的性能严重下降[6]。已有的基于离线学习的日志异常检测模型如支持向量机、逻辑回归、决策树[7]和模糊核聚类[8]等,概念不随新的日志数据的分布而改变,这些算法无法完全正确地识别异常事件,因此会做出模糊的决策。所以,基于离线学习的日志异常检测算法面临着概念漂移问题,在系统剧烈变化的环境下表现为性能降低。在面对动态中产生的概念漂移问题时,大多算法选择重训练(Retrain)来解决。Retrain是一种模拟增量学习的机器学习算法,每当有新的数据出现时,Retrain就丢弃以前的模型,将新的数据与以前的数据合并,并在这个数据上学习新的模型。但是Retrain没有考虑同一类日志的差异或日志之间的不一致性,没有能够根据数据分布变化或新日志与以前日志的关系随着时间动态更新以往经验的机制。同时,由于数据集不断增大,Retrain需要一个相当大的训练集来代表所有可能的正常行为,这需要日志完整地下载和识别标注,从日志产生到检测结束具有较大的时间跨度,不能及时地检测出系统异常,对系统内存资源的消耗非常大。
为了减少在线中概念漂移对日志异常检测算法的产生的影响,本文提出了一种能够基于置信度动态增量更新的在线日志异常检测模型(COP)。首先根据时间顺序模拟了Hadoop分布式文件系统HDFS日志生成环境。之后提出用于计算统计值p值的一致性度量模块,在此基础上设置一个基于置信度的校准集,在滑动窗口步长范围内的日志数据将根据校准集得到可靠的标签。仅训练一次数据时,数据的传递就变得相当重要。COP根据时间的推移不断将可信的日志数据、一致得分反馈到这个校准集,根据p值更新校准集。这个校准集将作为之前日志的概要来计算后续滑动窗口中日志数据检测的依据以计算p值。经实验验证,本文提出的COP异常检测算法能够达到与重训练异常检测算法相当的性能检测结果,平均检测时间为181.417秒,大大降低了检测时间。
1 概念漂移
根据应用场景的不同可以将异常检测分为离线异常检测(又称为批处理)和在线异常检测。在线异常检测顾名思义即为结合在线学习的异常检测方法也被称为增量学习或适应性学习,是指对一定顺序下接收数据,每接收一个数据,模型会对它进行检测并对当前模型进行更新,然后处理下一个数据。基于在线学习的异常检测方法满足一些实时性要求较高的日志分析系统需求。针对流数据的在线异常检测算法通常在PCA[9]、隔离森林[10]等基础上使用梯度增量算法对损失进行优化,或者与LSTM[11-12]等深度学习结合。但是深度学习训练和检测过程耗时长,不适用于在线中需要快速响应的环境中。这些异常检测方法都可以得到不错的实验效果,但随着时间的推移,面对爆炸式涌现且多变的数据,建立一个持续且不会退化的能够实时学习的模型仍然存在困难。
概念漂移问题通常是指输入数据和目标变量随时间变化的关系。数据分布的变化使得基于数据的旧模型与基于新数据的不一致,有必要对模型进行定期更新[13]。在动态变化的环境中,非平稳的数据的基础分布可能会随着时间的推移而动态变化,如图1所示。概念漂移设置中的一般假设是变化意外地发生并且是不可预测的,尽管在某些特定的现实世界情况下,可以提前知道与特定环境事件的发生相关的变化,但是针对漂移的一般情况的解决方案需要针对特定情况的解决方案。在时间序列演变过程中需要能够根据高层特征的变化作出自适应的调整,获得对新生成类别的鉴别。

图1 经过一段时间后数据发生概念漂移现象
应对概念漂移的方法可以分为全局替换方法和局部替换方法。全局模型中的自适应方法,比如逻辑回归模型,需要模型的完全重构,这是对漂移最根本的反应。删除一个完整的模型,从头开始一个新的模型,比如本文中作为对比实验的逻辑回归Retrain。但是许多情况下更改只发生在数据空间的某些区域,所以可以通过调整模型的某些部分,结合统计学习一致性度量的方法,抵抗在线异常检测中存在的概念漂移。已有的基于自适应微簇的任意形状进化数据流聚类算法,设计递归的微簇半径更新机制,自适应地搜索微簇半径的局部最优值[14]。
当给定算法的原始分数作为一致性度量的决策标准时,需要认识到传统算法通常使用固定阈值判断标签。从原始分数建立的阈值缺乏选择背景和意义。将原始分数与p值相结合可以提供清晰明了的统计意义。p值能够以标准化的范围(0~1)量化地观察到漂移,而不需要考虑底层基础算法[15]。
2 实验模型
2.1 模型框架
如图2所示,实验模型总体上主要包括日志预处理、一致性度量和在线一致性增量检测三个步骤。在线学习模型基于时间的推移,使用滑动窗口存储固定数量的最近的日志数据。首先将窗口内的原始非结构化日志文本转变为结构化日志;再通过特征提取转化为一致性度量模块可接收的输入数据;接下来使用一致性度量映射出的一致性得分计算p值,并进行一致性预测以及校准集的更新。
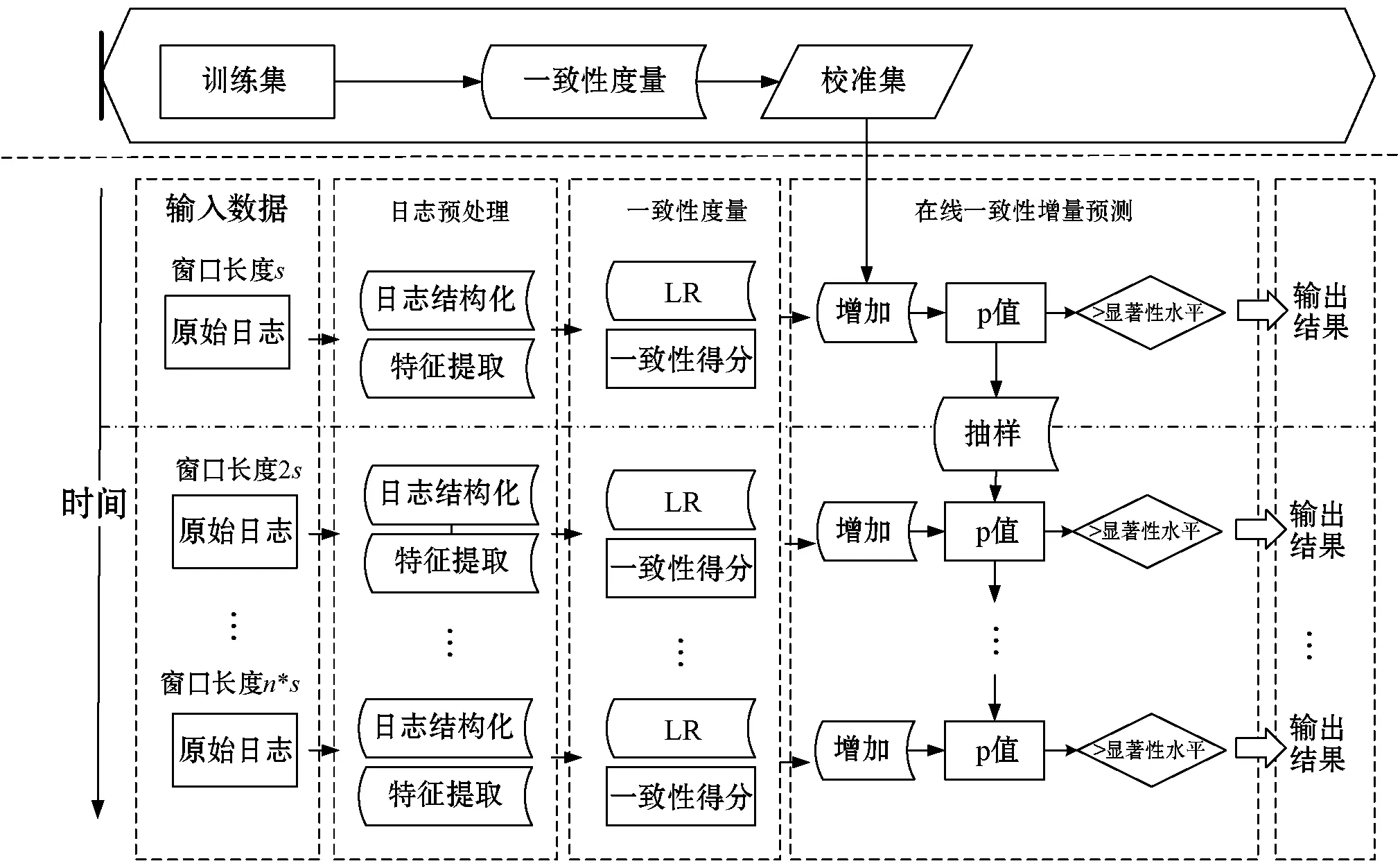
图2 模型框架
2.2 日志预处理
日志预处理部分包括日志解析和特征提取两个步骤。原始的非结构化日志文本由时间戳和日志文本组成,不能直接输入在线学习模型进行异常检测。在通过日志解析成结构化日志之后,使用特征提取的方法转换为特征矩阵,用于后续的异常检测。
图3详细说明了日志预处理中日志解析和特征提取的步骤。如1.1节中提到的,日志解析的目的是将原始的非结构化日志文本数据转化为结构化的常量与变量的对应关系模板。在日志解析后,进一步将日志事件编码为特征向量,进而形成特征矩阵,以便应用在基于日志的异常检测算法中。特性提取将使用会话窗口技术来计算日志事件出现的次数,并形成一个特征矩阵。

图3 原始日志转换为结构日志
2.3 一小时日志数据分析
使用最开始的一个小时的日志数据建立模型,根据置信度分布估计显著性水平。例如,图4(a)为所有正常日志数据出现次数与p值的关系,正常的日志数据置信度大多集中在0.901 013 25。图4(b)中异常数据p值大多接近于0,但大部分集中在0.000 141 713至0.027 634 096之间。这说明正常日志数据与异常日志数据很大程度上区别度很高。保存一小时内的数据集中所有的正常数据组成校准集,作为接下来在线一致性预测的经验。
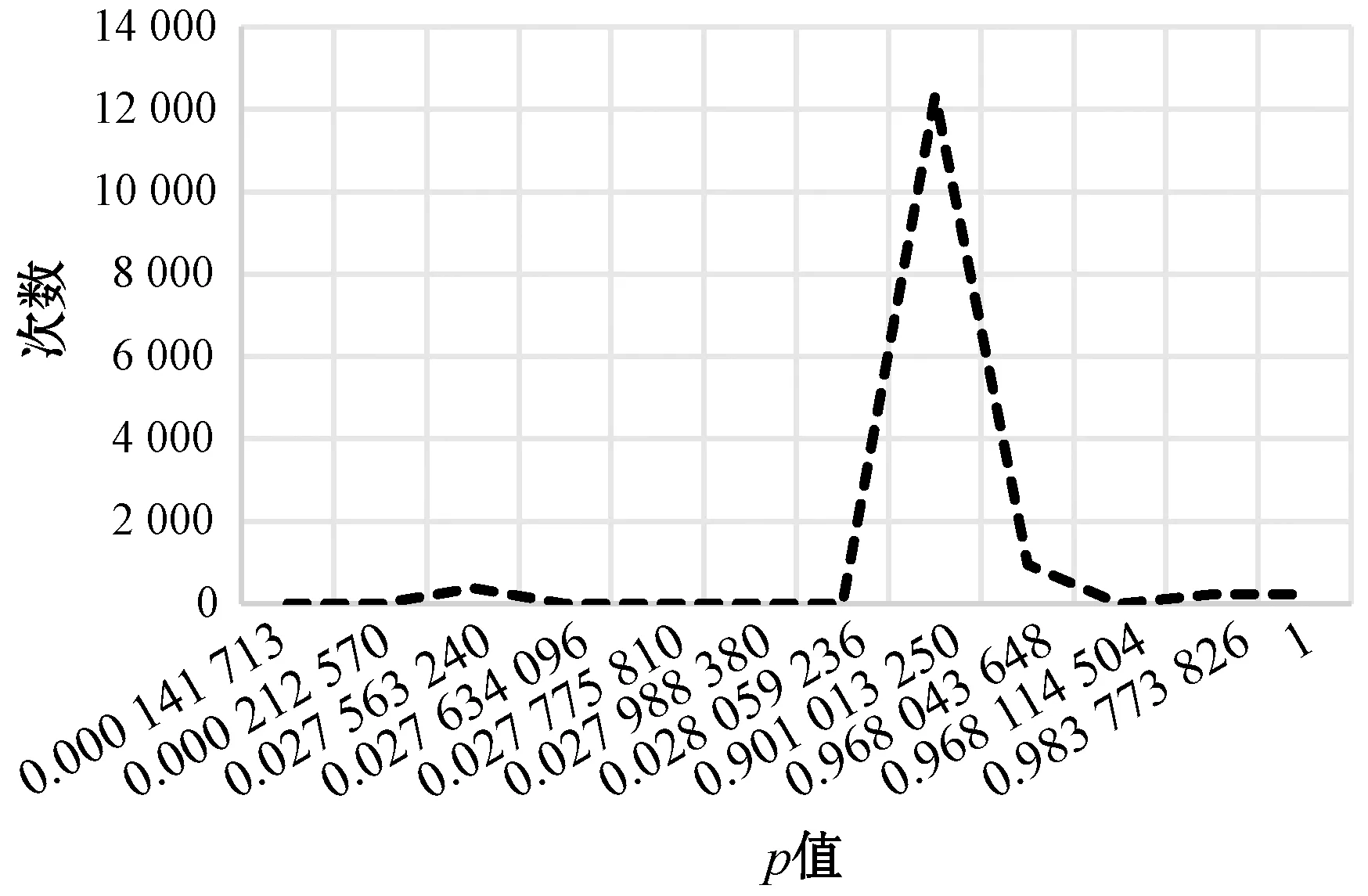
(a) 正常日志数据
2.4 一致性度量
一致性度量方法指测量样本和已知标签数据集之间的一致性程度的方法,给出的结果是一致性得分,代表了样本与待测数据集之间的一致性程度[16]。检测系统的模型匹配算法可以看作是一致性度量方法,其计算结果可以作为一致性得分。
经过日志预处理之后得到特征矩阵,输入一致性度量函数中得到一致性得分。选取逻辑回归算法作为实值得分函数计算得分。逻辑回归具有实施简单、建模高效的优点,它的计算量小、存储资源占用低,可以在大数据场景中使用。逻辑回归通过计算被测样本异常概率的方式进行分类。例如,当设置0表示正常,1表示异常,设置检测固定阈值为0.5。当逻辑回归检测出的概率小于阈值时,那么数据标签设置0;如果逻辑回归检测出的概率大于阈值时,那么数据标签为设置1。传统阈值不能动态适应概念漂移,本文提出的异常检测日志的一致性得分将反馈到相应的分数集,作为后续检测的已有经验来应对不断动态变化的数据产生环境。
对于日志样本l*,训练日志数据集D以及在训练集中相同标签的数据序列L,根据一致性度量方法得到的实值得分函数A计算一致性得分a,得分a表示当前新的日志样本与之前日志数据的一致性程度。在本文中实值得分函数A由逻辑回归算法给出,得到的是被测样本异常的概率,其计算式为:
a(l*)=AD(L,l*)
(1)
式中:滑动窗口内数据序列L,某时刻日志数据li,在预先已经获得的数据集序列D中提取出来的所有正常数据组成的校准集Cali∈{c1,c2,…,ci},通过实值得分函数可以得到当前数据的预测得分,如式(2)所示。
ai=AD(Cali,li)
(2)
2.5 在线一致性增量检测
通过得分计算p值来评估新的日志样本与之前的日志样本的相似性,式(3)为p值的计算过程。通过计算当前得分与校准集中得分的百分位。统计校准集中所有大于ai的日志个数并除以总样本个数n。
(3)
使用p值建立一个新的检测记录分数的数据和前面的正常分数之间的联系,这将避免算法造成的错误决定从而能够忽略内部细节和实现算法的影响。
为了能够使用尽量少的数据来获得尽量好的性能,不重复训练异常检测模型,通过结合置信度动态更新训练中得到的校准集来对抗在线中的概念漂移。根据式(4),显著性水平ε将会给出一个过滤后的检测集,通过一致性预测给出置信度conf。
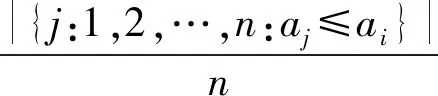
(4)
当置信度越高,则意味着更高的可信度。当ε=0.02时,conf=0.98,则有98%的可信度得到以下结论:当某条日志样本数据的p值小于显著性水平0.02时,那么该条日志样本数据有低于0.02的概率与校准集的不一致程度相同或者更不一致。换句话说我们有小于0.02的把握相信该条数据不是异常的。
如算法1中所示,随着时间的推移更新校准集。将新检测出的正常的一致性得分和置信度反馈给原有的校准集,并通过简单随机抽样的方法更新原有校准集,防止校准集随着时间的推移不断扩大造成内存不足,消耗p值计算时间。与Retrain相比,大大减少了对数据存储空间的要求,提升了时间效率。利用能够测量日志之间的p值,建立新日志与前日志之间连接的反馈机制的在线异常检测。
算法1增量更新校准集。
输入:滑动窗口中数据集Xn;日志校准集Xcali;显著性水平ε。
输出:检测后对应窗口中日志数据的标签y_pred;更新后的校准集Xcali。
1. aXn=A(Xn);
2. aCali=A(Xcali);
3. p=P(aXn,aCali);
4.ifp>ε:
5. y_pred_N=N with Conf;
6.else:
7. y_pred_A=A with Conf;
8. 增加aXnTo aCali;
9. 抽样aCali
10.returny_pred,aCali
传统一致性预测的时间复杂度主要来源于建模和检测两个部分。当计算一个新的日志数据样本相对于训练集的p值为例,检测的时间较短可以忽略不计。假设建模的时间复杂度为On,训练集大小为n,计算单个样本的p值时需要得到n+1个数据样本的一致性得分,所以计算一个新样本相对于一个标签的p值的算法复杂度为(n+1)×On。但由于COP中建模由一小时内的校准集(大小为m,m< 由于预处理是通过正则匹配快速解析日志文本,所造成的时间耗损较低,训练过程所使用的日志数据量较小,避免了因为训练而造成的较大的时延。综上所述,COP能够满足在线检测的要求。 所有实验运行在64位Windows 10操作系统上(工作站处理器为i7-6700,3.4 GHz,内存16.0 GB),Python 3.7编程环境。 系统日志数据集[6]采用香港中文大学的Hadoop分布式文件系统日志数据集HDFS进行模拟在线环境。该数据集共1.58 GB,11 197 705个原始日志,复杂且能够模拟一个动态环境[2]。此数据集共近39小时原始日志数据。模拟在线环境时,取第一个小时内所有原始数据(OneHou-HDFS)进行日志分析,通过专家领域专家手动标记,共188 723条日志,特征提取后生成14 771条日志序列,其中异常数据659条,正常数据14 112条。系统异常包括对文件存储块的增加,移动和删除操作异常,如表1所示。 表1 数据集时间信息 在2.3节中可以观察到当传统检测算法在面对概念漂移问题时会存在显著的性能下降,使模型无法做出准确的决策。本文通过p值动态更新校准集的方式在线检测系统日志,能够成功抵抗在线检测中的概念漂移,达到Retrain时的性能水平。 本文中使用准确度(Accuracy)、精确度(Precision)、召回率(Recall)和F-Score对在线模型进行性能上的评估,通过检测时长评估模型的检测速度。 本文通过混淆矩阵中TP、TN、FP和FN,根据式(5)-式(7)计算准确度、精确度和召回率。 (5) (6) (7) 精确度的提高说明误报率较低,正常日志极少被错误地检测为异常日志;召回率的提高说明漏报率较低,异常日志极少被错误地检测为正常日志。 加权调和平均数F-Score对是基于精确度和召回率定义的,是对精确度、召回率的一种权衡,定义为: (8) 式中:β为参数,当β=1时,称为F1,此时认为精确度与召回率同等重要;当β<1时,则认为精确度比召回率重要;当β>1时,则认为精确度不如召回率重要,此时另β=2得到F2。精确度和召回率评估时,理想情况下做到两个指标都高当然最好,但在实际中需要根据具体情况做出取舍,例如异常检测时,由于检测出对系统不利的异常更加重要,所以在保证精确度的条件下,尽量提升召回率。 如第1节中提到的,在给定的数据流上检测时,可以考虑分类精度的变化,如准确度、召回率和F-Score,来观察概念漂移问题。在基于系统日志的异常检测中,实时到达的日志数据样本引起的概念漂移反映在算法的召回率和精确度的降低上。在解决在线异常检测中的概念漂移之前,本文将数据集模拟为一个动态环境,使用训练集拟合的模型检测了测试集日志数据,使用逻辑回归作为异常检测函数时的异常检测结果。 如图5所示,在面对概念漂移问题时,数据集的召回率最多会降低60%以上,意味着更少的异常被检测出来,精确度、F-Score也都出现了不同程度的降低。该算法无法在急剧变化的环境下及时地做出准确的决策。概念漂移的出现意味着恶意行为模式已经开始发生迁移,在实际生产环境中,概念漂移问题是无法完全避免和修复的,但是,可以在最大程度上对概念漂移做出适应,限制概念漂移的范围。 图5 传统检测算法在HDFS数据集上的评估结果 设置逻辑回归(Logistic Regression,LR)异常检测和Retrain实验作为对比实验。仅使用逻辑回归算法训练全部日志数据集中第一小时内的数据并建模。之后每一个窗口内的日志数据都使用这个模型进行异常检测。很明显,LR模型的检测来源仅为一小时的日志数据,没有抵抗概念漂移的能力。如图6所示,LR的精确度平均为0.921。LR的时间复杂度主要为初次建模时间Om,由于COP计算p值与更新校准集的时间复杂度较低,与LR的之间整体性能相差不多,所以本次对比实验中没有展示LR与COP的时间开销对比结果。 图6 COP、LR和Retrain的实验性能 Retrain中随着时间的推移,每新接收一个窗口的日志数据块,都需要将之前已经存储的所有日志数据合并,将之作为训练集。根据训练集数据拟合逻辑回归模型之后,对当前窗口内的日志数据序列检测异常。Retrain是一种模拟增量学习的批处理方法,显而易见的优点是能够训练过去所有的已有知识形成新的模型,如图6(c)中所示,Retrain平均准确度在三种算法中最高,达到0.996。但是其他检测结果表现较差,Retrain并不能高效地抵抗概念漂移的出现。新的概念漂移发生点可能会淹没在旧的知识里,对于概念漂移反应较慢。同时它对时间和空间消耗也比较大,平均时间损耗为687.143 s。计算过程需要当前时间节点之前的全部的数据下载存储。LR只能依靠最开始的模型来预测,导致它的精确度和准确度较三者中最低。而COP模型可以通过训练少部分的知识,根据置信度更新校准集的方式达到和Retrain相近的性能结果,平均精确度、平均召回率以及平均F-Score为均为三者最高水平。同时COP在时间上表现优越,大大降低了检测时间。 根据2.3节中对前一小时的数据分析,发现异常类日志数据的p值集中在0.000 141 713~0.027 634 096之间。所以实验中将显著性水平可以选择设置为0.002左右。显著性水平与最终决策相关,若将ε设置高于0.02,那么会有更多正常事件被误判为异常事件。在更新校准集的时候,校准集中所代表正常的p值会越来越少,可以判断为正常事件的置信度会越来越高,初期表现在检测精度的降低和召回率以及F-Score的提升上。但是随着时间的推移,越来越多的正常事件会被判断为异常事件,导致完全抛弃了过去的模式,到第5个窗口时就已经几乎完全检测不到正常日志序列,检测精确度仅为0.024,这种现象被称为灾难性的遗忘。但是也不能将ε设置过低,当ε=0.000 2时,几乎不会有任何异常被检测出来,从第一个窗口开始异常样本数量只有6个,随着时间的推移,异常样本接近于零。具体检测性能表现为精确度的提升以及召回率和F-Score的降低。 本次实验中将显著性水平设置ε=0.002。图7表示COP、LR和Retrain在准确度、精确度、召回率和F-Score的对比实验结果。COP的整体性能与LR和Retrain的实验相比相对平稳。如图7(a)中所示,Retrain由于数据量大,模型的准确度表现与COP模型相比趋向平稳,COP与LR模型检测准确度随着时间的推移存在波动。图7(b)中Retrain在22个窗口之前均低于LR与COP的精确度,但是从第22个窗口开始,之后的窗口随着时间推移经验积累到一定程度之后模型拟合越来越精准,Retrain的精确度开始回升之后稳定在0.97左右。LR的检测精确度最低为0.453,这意味着在第22个窗口中出现了模型判断模糊的正常日志数据,发生了概念漂移。一直不变的LR模型将这些处于边界上的正常数据误报为异常数据,导致准确度降低。但是由于COP设置动态反馈的校准集能够保持新的知识不断更新,抵抗了窗口中发生的概念漂移,将精确度提升至0.79。图7(c)中COP模型召回率相对LR和Retrain来讲较稳定。LR在第7个窗口中召回率相较之前有所降低,出现将异常的数据判断为正常数据的情况。本文提出的COP模型能够通过控制显著性水平区分正常数据和异常数据,减少了漏报数量,提升了召回率。图7(d)和(e)表示精确度与召回率的综合结果F-Score,COP整体表现相对LR和Retrain较好。图7(f)中,在检测时间上,Retrain的平均时间损耗687.144 s,是COP模型的近四倍,COP模型大大提升了时间效率。 (a) 三种算法准确度对比 针对目前大型在线系统自动化异常检测的需求,本文提出了一个能够根据置信度在线增量更新的系统日志异常检测模型。它将当前的日志数据与之前的日志数据联系起来,有效地缓解动态环境中概念漂移的问题。通过Hadoop分布式文件系统HDFS日志数据按照时间顺序模拟实时动态的日志生成环境,COP模型可以高效地检测数据集中的异常,得到与重训练在精确度、召回率等相近的检测结果,并降低检测时间。 但是显著性水平的选择很大地影响了检测精确度和召回率。如何更加准确地选择合适的显著性水平来增加模型的鲁棒性,将成为接下来需要研究的问题。未来的工作可以进一步使用无监督机器学习算法以及深度学习算法,同时测试更多数据集来拟合更多复杂环境下的异常检测,从而达到不依赖数据标记完成分布式系统和平台背景下的在线日志异常检测的目的。3 算法实现
3.1 实验环境
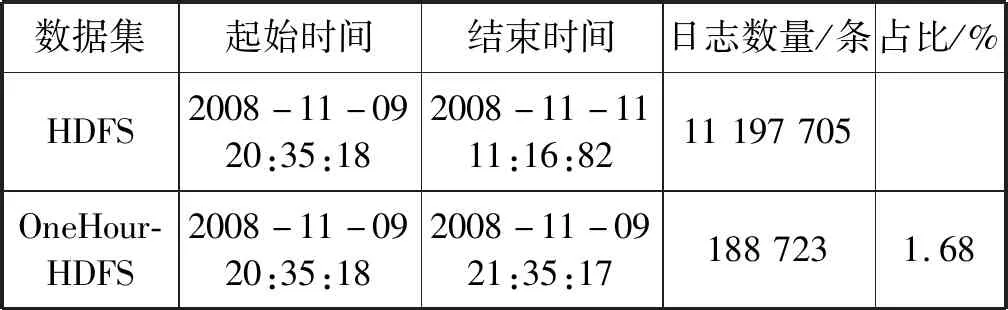
3.2 实验室数据集
3.3 评估指标
3.4 概念漂移识别
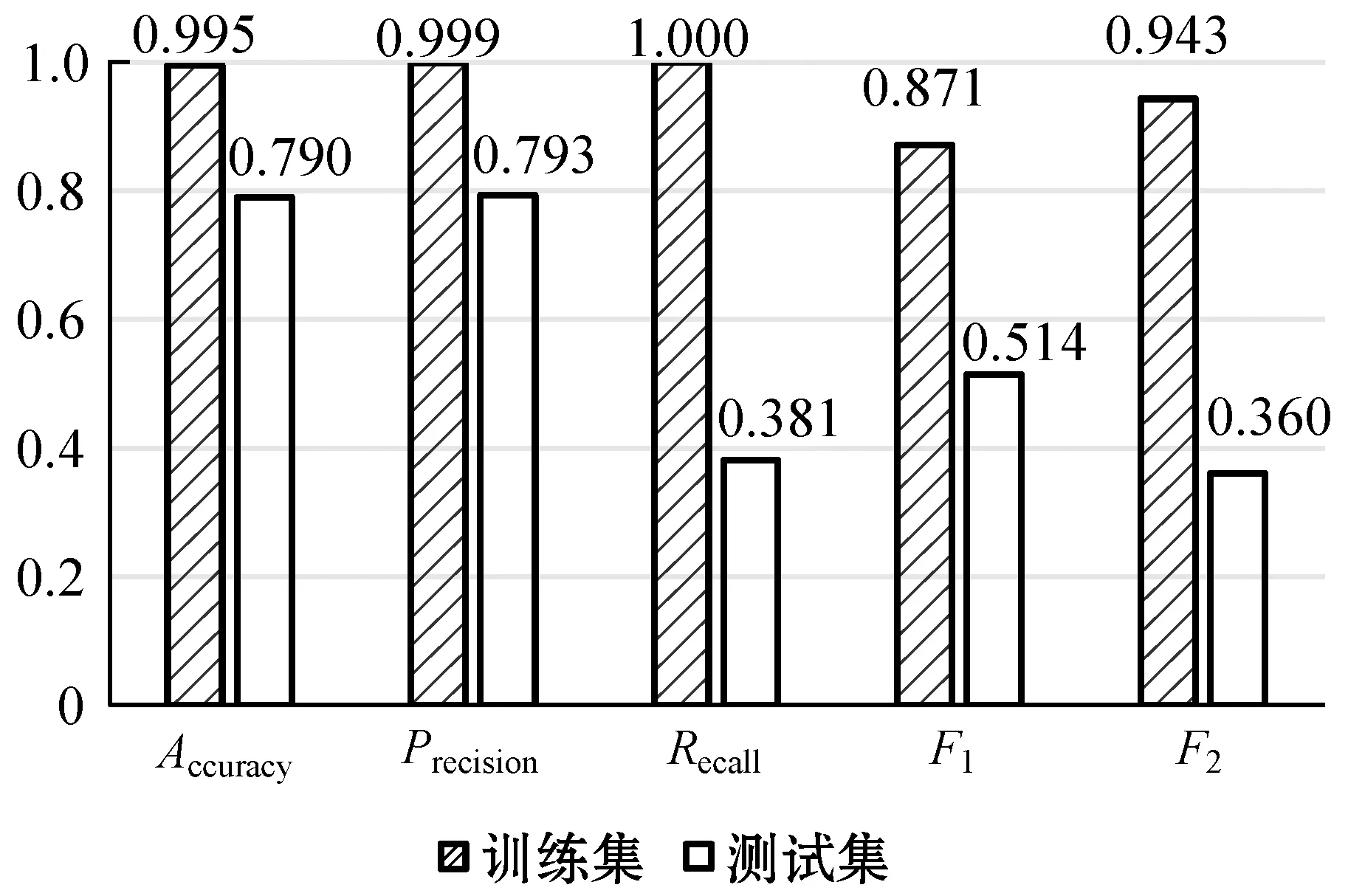
3.5 实验结果分析


4 结 语
猜你喜欢
公民与法治(2022年5期)2022-07-29
华人时刊(2021年13期)2021-11-27
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
云南教育·中学教师(2020年11期)2021-01-07
心声歌刊(2020年4期)2020-09-07
山东煤炭科技(2020年1期)2020-03-06
小学生(看图说画)(2017年6期)2017-11-06
燕山大学学报(2015年4期)2015-12-25
电子设计工程(2014年19期)2014-02-27
