
中国心力衰竭患者死亡风险预测模型的系统评价
2023-11-01 10:33:28贾盈盈崔念奇胡欢婷尤敏袁天漫胡婧妮董铭琦宋剑平
中国循环杂志 2023年10期
贾盈盈 崔念奇 胡欢婷 尤敏 袁天漫 胡婧妮 董铭琦 宋剑平
目的:系统评价中国心力衰竭患者死亡风险预测模型。
方法:检索The Cochrane Library、PubMed、Embase、Web of Science、中国知网、维普网、万方数据库和中国生物医学文献数据库中发表的相关文献,检索时间均为数据库建库至2022年12月1日。2名研究员独立筛选文献、提取数据并评价纳入模型的偏倚风险和适用性。
结果:共纳入20项研究,包含96个预测模型。逻辑回归模型、支持向量机模型、Cox比例风险回归模型是研究人员常用的建模方法,N末端B型利钠肽原、年龄、血尿素氮、NYHA心功能分级、体重指数是模型中常纳入的预测因子。18项研究开展了模型内部验证,其ROC的AUC为0.675~0.920,仅4项研究开展了模型外部验证,其AUC范围为0.700~0.873。结局报告方面,多项研究未清晰报告预测因素的定义、模型拟合、模型呈现方式等关键信息。方法学质量方面,20项研究所建模型的适用性均良好,模型分析领域高偏倚风险是导致所有模型总体偏倚风险高的主要原因。
结论:中国心力衰竭患者死亡风险预测模型的建模质量较差,模型的临床应用效果有待验证。未来,研究人员可根据心力衰竭疾病亚型开发针对性风险预测模型,建模前全面纳入患者的基线特征、生物学标志物等预测因素,建模时严格遵循预测模型偏倚风险评价工具、多变量预测模型透明报告指南开发高质量模型及全面报告研究结果。
心力衰竭(HF)是各种心脏疾病的晚期阶段,其具有高发病率、高死亡率和高经济负担的特点[1]。70岁以上人群中心力衰竭的患病率可上升至10%以上,4年死亡率达50%,严重者1年死亡率高达50%[2-3]。因此,开发及改进心力衰竭患者死亡风险分层工具、及时评估和预测患者的死亡风险尤为重要。跟着指南走心力衰竭模型(GWTG-HF)和慢性心力衰竭全球Meta分析风险评分模型(MAGGIC)是目前应用较广的评估工具,但其均基于传统统计模型仅利用某时间点的数据预测患者预后风险,无法捕获变量间的多维相关性、无法动态预测患者的死亡风险[4-6]。机器学习模型能处理海量、多维度、非结构化的数据,可揭示多个变量间的作用和关系,其为精准预测心力衰竭患者死亡风险提供了有效手段[7-9]。尽管心力衰竭患者死亡风险预测模型取得了一定进展,但医护人员尚不确定应在何种临床环境中为哪类患者推荐哪种模型。此外,研究发现基于欧洲或美国人群开发的模型不能良好的预测中国心力衰竭人群的死亡风险[10-11]。因此充分评估我国开发的心力衰竭预测模型的质量、性能及其适用性至关重要。综上所述,为筛选高危心力衰竭患者,本研究系统评价中国心力衰竭患者死亡风险预测模型,以期为中国心力衰竭患者死亡风险预测模型的构建、完善、应用提供依据。
1 资料与方法
1.1 文献检索
全面检索The Cochrane Library、PubMed、Embase、Web of Science、中国知网、维普网、万方数据库和中国生物医学文献数据库中发表的相关文献,检索时间均为数据库建库至2022年12月1日。采取主题词与自由词结合的方式构建检索表达式,并追溯纳入文献的参考文献以补充相关文献。中文检索词:“心力衰竭”、“死亡”、“死亡率”、“预测”、“预测模型”“预测因素”、“ROC曲线”、“曲线下面积”等。英文检索词:“heart failure” 、“cardiac failure”、“mortality”、“case fatality rate”、“mortality rate”、“predict”、“prediction model”、“prognostic model”、“area under curve”、“roc curve”等。
(2)混凝土底板对组合梁的变形具有一定的抑制作用,但温度应力在某些部位仍然较大,所以应当重视组合箱梁温度效应对结构安全的影响。
1.2 纳入与排除标准
纳入标准:(1)研究对象:中国心力衰竭患者;(2)研究内容:心力衰竭患者死亡风险预测模型的构建或验证研究;(3)结局指标:仅以死亡为结局指标;(4)研究类型:包括队列研究、病例对照研究和横断面研究。排除标准:(1)动物实验、会议摘要及综述;(2)无法获取全文;(3)只分析心力衰竭患者的死亡危险因素,但未构建预测模型;(4)未描述建模的具体过程。
1.3 文献筛选与方法学质量评价
文献筛选、数据提取、偏倚风险评价均由2名研究员独立完成并交叉核对,当结果不一致时,咨询第3名研究员协助判断。2名研究员根据纳入排除标准严格筛选文献,使用预测模型系统评价数据提取清单(CHARMS)提取数据,提取内容包括数据来源、预测因素评估方式、缺失数据处理方法、分类变量的处理方法等数据[12]。采用预测模型偏倚风险评价工具(PROBAST)从研究对象、预测因素、结果和分析4个领域评估模型的偏倚风险,从研究对象、预测因素、结果3个领域评估模型的适用性,最后依据“短板理论”综合各领域评价结果,对模型的偏倚风险和适用性做出整体评价[13]。
2 结果
2.1 文献检索结果及一般特征
纳入研究共报告了96个死亡风险预测模型。研究对象方面,8项研究针对心力衰竭一般人群建模,其中Wang等[14]所建立的动态半径均值分类模型(DRM)的预测性能最佳。3项研究针对急性心力衰竭人群建模,其中张剑等[27]建立的Cox模型性能最佳。3项研究针对慢性心力衰竭人群建模,其中杨弘等[30]建立的加权随机森林(WRF)模型性能最佳。建模方法方面,使用频率前三的建模方法为逻辑回归(LR)模型、支持向量机(SVM)模型、Cox模型,其余研究采用决策树(DT)、随机森林(RF)、梯度提升机(GBM)等方法建模。此外,部分研究优化基础建模方法,如将Cox模型优化为极限学习机Cox模型(ELM Cox模型)、最小绝对收缩和选择运算符Cox模型(Lasso Cox模型)、弹性网络Cox模型(E-net Cox模型)。缺失数据处理方面,仅12项研究报告了数据是否缺失和(或)缺失数据的处理方法,其中5项研究直接排除缺失数据的病例[11,17,22,24,28],4项研究采用缺失森林(Miss forest)填补缺失数据[20,24,26,30],其余研究采用众数填充法、均值填充法、多元回归填充等方法填补缺失数据[11,29,31]。预测因素方面,模型中出现频次3次及以上的预测因素有N末端B型利钠肽原(NT-proBNP)、年龄、血尿素氮(BUN)、NYHA心功能分级、体重指数(BMI)、左心室射血分数(LVEF)、舒张压、血红蛋白、血清钠、合并糖尿病、血肌酐、血管紧张素转换酶抑制剂、总胆红素、血清钾、心肌梗死病史、瓣膜性心脏病、心率、白蛋白、中性粒细胞、利尿剂、β受体阻滞剂、肾功能不全、尿酸、肺部疾病。校准度方面,3项研究采用霍斯黙-莱梅肖拟合优度检验(Hosmer-Leme show)检验(P>0.05)[17,24-25],2项研究提供了校准曲线图[10,18],3项研究报告了模型的布里尔分数(brier)评分[11,20,22],其余研究未报告模型的校准度。模型区分度方面,除2项研究外其余研究均报道了模型的区分度[15-16],模型内部验证的AUC范围为0.675~0.920,模型外部验证的AUC范围为0.700~0.873,模型预测性能良好,具体纳入模型的预测性能见表2。
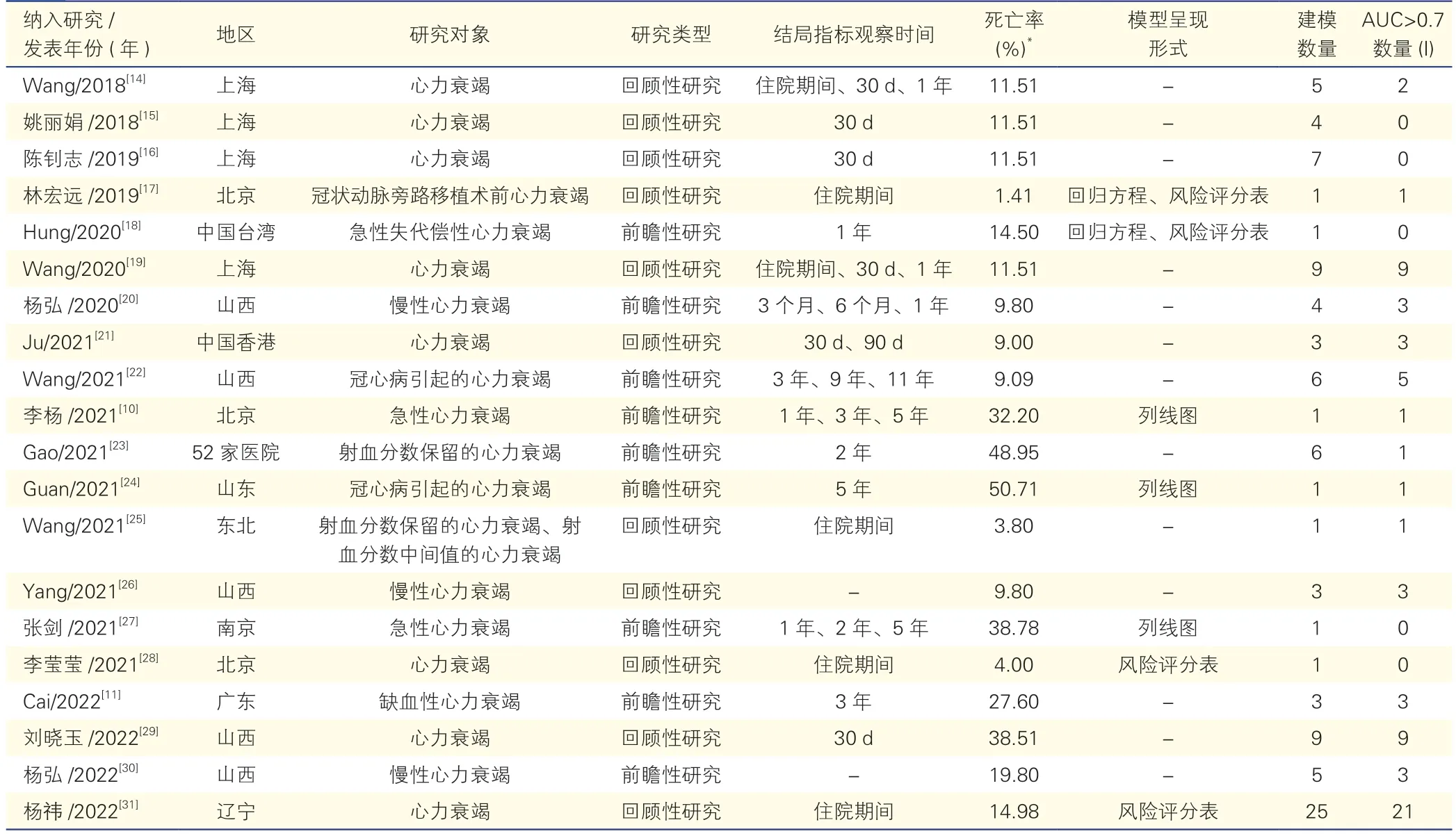
表1 纳入模型的基本特征
2.2 心力衰竭死亡风险预测模型的构建情况
检索数据库共获得1 136篇相关文献,去重后剩余1 059篇,通过阅读文献题目和摘要,排除与研究主题不相关文献1 019篇,再阅读全文,排除不能获取原文1篇、缺少建模数据1篇、仅分析危险因素未建模13篇、小于2个预测因子4篇,研究对象不符合1篇,最终纳入20篇文献。中国心力衰竭患者死亡率范围为1.41%~50.71%,纳入文献的基本特征见表1。
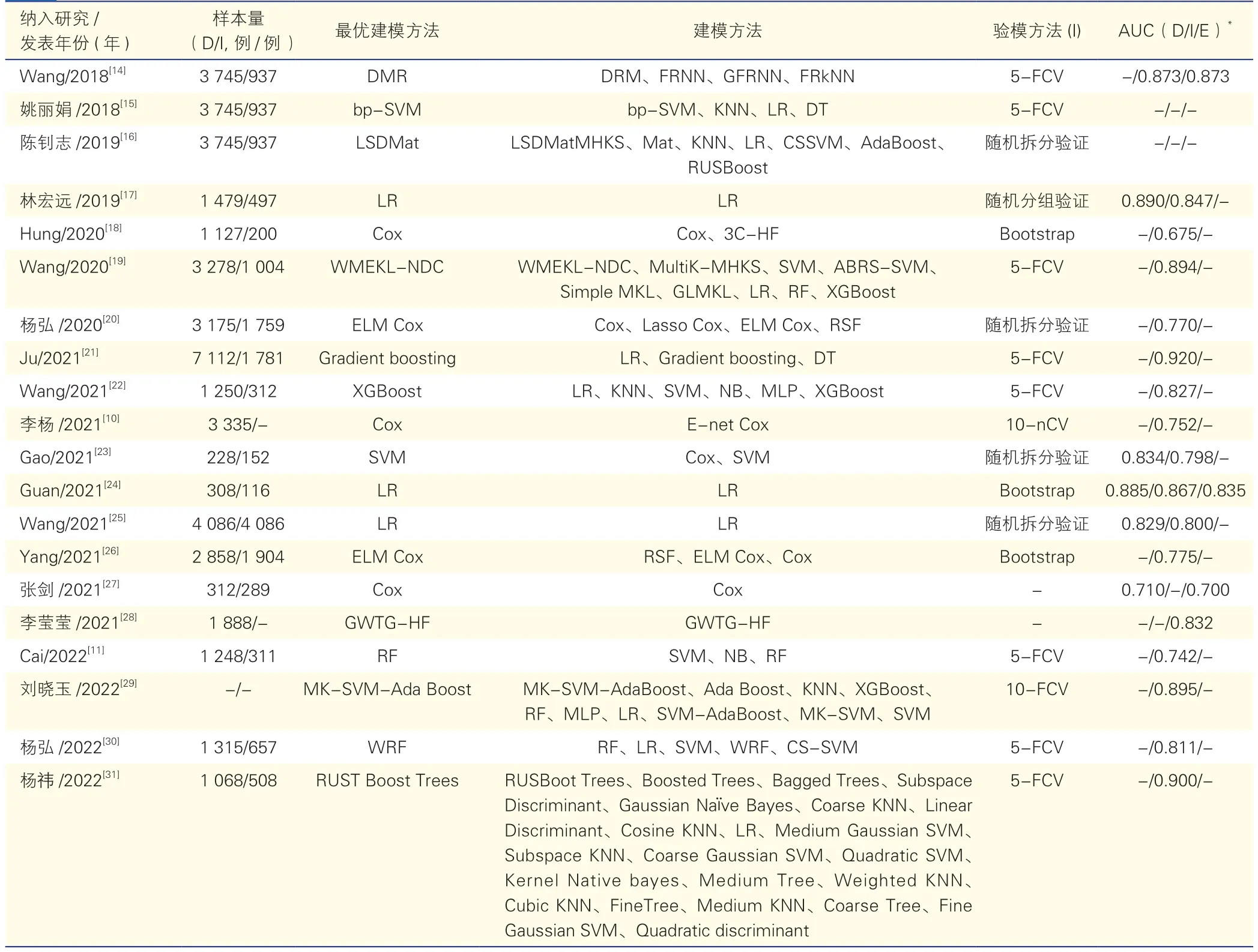
表2 纳入模型的预测性能
2.3 偏倚风险与适用性评价
国内外不同心力衰竭死亡风险预测模型间性能的比较:建模方法方面,国内外研究均常采用LR模型、Cox模型、SVM模型建模,另外,国外还常采用RF模型、DT模型、神经网络模型等方法建模[4,33-34]。模型验证方面,国内外大部分模型均未开展模型外部验证,模型的预测性能有待验证[4,9,33]。模型评价指标方面,尽管区分度、校准度、模型的临床效用均是预测模型评价的重要参数,但国内外模型主要报告了模型区分度,仅有少部分研究报告了模型校准结果等信息[9]。模型预测性能方面,国内外多项研究均显示机器学习模型的预测性能通常优于传统统计模型[4,9]。预测因素方面:尽管国内外建模的人群与方法存在差异,但NT-proBNP、年龄、BUN、LVEF、舒张压、血红蛋白、血清钠、合并糖尿病均是模型中常纳入的预测因素[4,34]。此外,心力衰竭生物学标志物指南指出半乳糖凝集素-3、可溶性生长刺激表达基因2蛋白(sST2)等生物标志物是心力衰竭患者预后风险分层的重要物质[35]。但本研究纳入的20项研究中仅Gao等[23,35]的研究将sST2作为预测因素纳入模型。分析其原因可能是多项研究基于回顾性研究设计建模从而遗漏了重要的预测因素。因此,未来建模时应开展大样本前瞻性研究,建模前全面纳入与心力衰竭预后相关的预测因素。
3 讨论
1.4 统计学分析 采用SPSS19.0统计软件,各血清标记物中位数倍数均经体重等因素校正。孕周组间比较采用t检验,P<0.05为差异有统计学意义。
本研究纳入的所有模型均为高偏倚风险。预测因素方面,开展多中心研究、未全面纳入各类预测因素、预测因素筛选方法不当等原因均会造成高偏倚风险。未来建模前应全面纳入患者的人口统计学特征、实验室检查结果、影像学数据、生物标志物等各类预测因素,统一预测因素的定义与评估方式,合理筛选变量[13]。结局报告方面:部分研究未报告模型呈现结果可能会限制模型的推广与应用[10,17-18,24,27-28,31]。且心力衰竭是具有长期潜伏特性的慢性疾病,其预后分析也会涉及不同阶段的再入院和死亡情况。因此,未来的研究可开发动态预测模型以监测中长期死亡风险,并严格按照多变量预测模型透明报告指南全面报告研究结果[32]。分析方面,由于直接排除数据缺失病例、连续变量和分类变量处理不当等因素导致模型高偏倚风险,因此未来建模时应严格遵循指南开发模型。
不同建模方法间模型预测性能优劣的比较:9项研究比较了机器学习模型与传统统计模型的优劣,其中7项研究显示机器学习模型的预测性能优于传统统计模型[15,19,21-23,29-30],2项研究显示机器学习与传统统计模型相结合的ELM-Cox模型性能最佳[20,26]。以上结果表明机器学习模型应用前景广阔。未来构建机器学习模型时可使用模型可解释性框架,进一步提高其可信度。
20项研究建立的模型均为高偏倚风险,所有模型适用性良好。研究对象方面,10项研究排除了全部或部分资料不全的病例,导致研究对象选择性偏倚风险增加[11,17-18,22,24-26,28-29,31]。预测因素方面,10项研究因采用多中心研究或研究未使用盲法等因素导致高偏倚风险[11,14-16,18-22,30]。结局方面,2项研究未报告预测因素与结局指标测量的时间间隔,偏倚风险不清楚[26,30],其余研究均清晰报告了结局指标的定义、测量方法,偏倚风险低。分析方面,Gao等[23]的研究未报告模型中预测因素的筛选方法,偏倚风险不清楚,其余研究因仅基于单因素分析与多因素分析筛选预测因素、未报告数据是否缺失或缺失数据处理方法不当、未开展模型外部验证等原因导致高偏倚风险。
本研究的局限性:由于不同研究间的异质性较大,本研究仅开展了定性分析;中国心力衰竭死亡风险预测模型均为高偏倚风险,研究人员可能会高估模型的预测性能;此外,本研究排除了包含再入院等复合结局指标的研究,可能会导致选择偏倚。
研究1组研究对象CEA、CA242、CA199三项指标水平均明显高于研究2组和对照组(P<0.05);研究2组研究对象CEA、CA242、CA199三项指标水平均明显高于对照组(P<0.05)。见表1。
综上所述,中国心力衰竭患者死亡风险预测模型的预测性能有待验证。未来建模时应严格遵循指南开展前瞻性、大样本试验,建模前全面纳入相关的预测因素,并加强预测模型的外部验证和临床应用研究。
唯才式的偏爱就是教师钟爱一些聪明、各方面能力强,尤其是各科成绩优良的孩子,在每次的考试中都能给老师长脸,也是老师取得成绩的法宝,这些孩子可是老师的心肝宝贝。
利益冲突:所有作者均声明不存在利益冲突
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
中国宝玉石(2019年5期)2019-11-16 09:10:20
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
冰雪运动(2016年4期)2016-04-16 05:54:56
现代防御技术(2014年6期)2014-02-28 18:26:29
