
基于SE-YOLO-POLY 模型的新型双源无轨电车智能识别
2023-10-31 01:06:14董宜平
南通大学学报(自然科学版) 2023年3期
董宜平,谢 达,王 兰
(1.中国电子科技集团公司第58 研究所,江苏 无锡 214035;2.无锡中微亿芯有限公司,江苏 无锡 214072;3.无锡职业技术学院 基础课部,江苏 无锡 214121)
双源无轨电车采用线网作为动力电源,同时配有动力电池组。如图1,电车在有电网的路段,借助集电杆与线网相连行驶,充电并储存电能;在无线网路段,电车可利用电池脱离线网行驶。这使得双源无轨电车更灵活、更经济、更环保。然而,双源无轨电车也存在弊端:集电杆接入线网后,在停车过程中需要将集电杆接入网络中的集电盒。传统双源无轨电车采用手动搭线,该方式不仅效率低、需要多次操作,而且易给操作员带来危险[1-4]。采用自动捕捉识别系统,可以提高识别率,减少停车搭线的时间,同时又可以保护操作员的人身安全。

图1 双源无轨电车图示Fig.1 Dual-source trolleybus vehicle diagram
目前,众多研究团队采用YOLO-V4(you only look once version 4)算法,该算法不需要构建与选取预测框,而是直接对目标物体(集电盒)的位置与类别进行预测,从而转化为求解回归问题来检测目标。该方法具有计算量小、实时性高的特点,同时也可以减少硬件开销实现快速部署[5-11]。
1 YOLO-V4 网络结构
YOLO-V4网络如图2 所示,由输入(Input)层、主干网络(Backbone)层、颈(Neck)层和头(Head)层组成。其中Input 层主要负责输入待检测的特征图像。
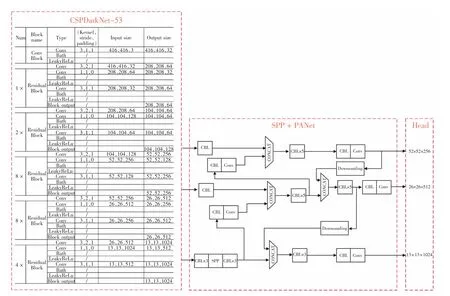
图2 YOLO-V4 网络结构Fig.2 YOLO-V4 network structure
Backbone 层以CSPDarkNet-53[12-14]作为其主干网络,利用主干网络来进行特征提取,由5 个跨阶段局部网络(cross stage partial network,CSPN)组成。5 次下采样,主干网络依次由块1 的1 次、块2 的2次、块3 的8 次、块4 的8 次、块5 的4 次堆叠组成。就是首先进行一次卷积核大小为3×3、步长为2 的卷积,该卷积会压缩输入进来的特征层的宽和高,其利用卷积不断地进行特征提取,图片的宽和高连续被压缩而通道数不断得到扩张,最终得到3个输出特征层。
Neck 层中主要包含空间金字塔池化结构网络(spatial pyramid pooling network,SPPNet)和路径聚合网络(path aggregation network,PANet),负责对主干网络提取到的特征信息进行池化和特征融合操作。
SPPNet 网络作为整个YOLO-V4 的池化层,架构如图3 所示。首先,对最后一层的特征信息进行3次卷积;然后,对卷积后的特征信息进行最大池化操作。网络中使用了1×1、5×5、9×9、13×13 共4种不同尺度的卷积核来进行最大池化操作。由13×13×1024 的图像转换为13×13×2048 的图像,可有效分离上下层的特征信息,从而极大地增加感受野。
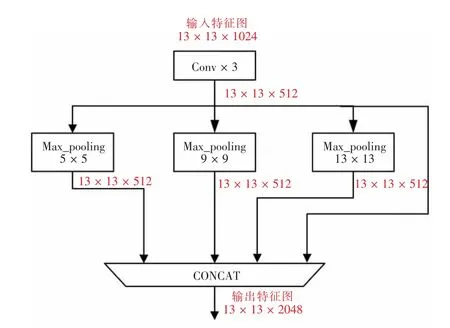
图3 SPPNet 架构Fig.3 SPPNet structure
PANet 被用来进行参数聚合,主要由卷积、上下采样、特征融合以及堆叠所构成的循环金字塔组成,是一种可以自上而下和自下而上的双向融合网络。其在最下层和顶层特征之间增加了一条自适应特征通道,可以使整个YOLO-V4 网络中的不同特征层之间充分融合。
Head 层为YOLO-V4 网络的输出层,采用大小为3×3 和1×1 的卷积核来进行两次卷积操作,并对每个特征层所生成的3 个预测框进行判别,判断其中是否含有所需要检测的特征信息,然后进行非极大值抑制和先验框的调整,从而获得最终的预测框。
2 YOLO-V4 网络的损失计算
YOLO-V4 在网络架构中,对偏移量进行了约束,防止因边框的中心在目标的随机位置而导致训练不能收敛。图4 所示为边框网络模型,其中:cx和cy分别表示中心的横、纵坐标;pw和ph分别表示锚点的宽度和高度;σ(tx)和σ(ty)分别代表预测框的中心点与横、纵坐标的距离;tw和th分别代表预测框的偏离度,即尺度缩放。最终得到预测的坐标偏移横坐标bx、纵坐标by、宽度bw和高度bh,其中scale为分割块的大小。
例如,学生可以根据第二次笔记中记载的有关“蛋白质”专题的知识,进行蛋白质概念图的建构。学生在分析解决一定量的遗传题之后总结遗传题分析手段(方法)有两种: 通过遗传图解分析与通过系谱图分析等。
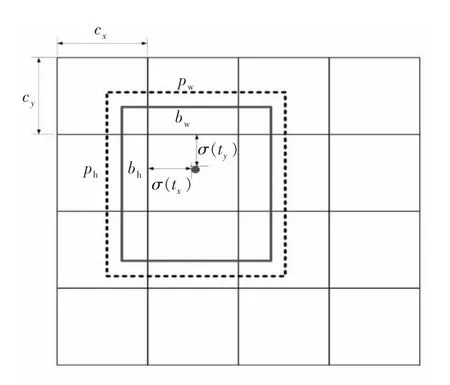
图4 边框网络模型Fig.4 Border network model
YOLO-V4 基于图像栅格作为单元进行检测。在目标检测网络中考虑重叠面积、中心点距离、长宽比,测量预测框和真实框之间的交并比(intersection over Union,CIOU),计算公式为
其中:a 为权衡的参数;v 为衡量长宽比一致性参数;w 和h 分别为预测框的宽和高;wgt和hgt分别为真实框的宽和高;av 为惩罚关键因子;b 为预测框值;bgt为人工标注框值;LCIOU为位置损失;IoU 为监测准确度,其值由预测框对角线与真实框对角线决定。
计算尺度为13×13×1024、26×26×512、52×52×256 的3 组不同特征图的预测损失值步骤:通过训练得到9 个先验框并放到3 个尺度上,每个尺度下的特征图的每个网格单元,都会被分配到当前尺度下的3 个先验框;识别物体以识别框的形式输出,与地面实况匹配的先验框计算坐标误差、置信度误差(标记为1)和分类误差;其他的先验框只计算置信度误差(标记为0)。采用YOLO-V4 进行目标识别如图5 所示。

图5 YOLO-V4 识别框Fig.5 YOLO-V4 identify the box
从识别图可以看出,YOLO-V4 的识别框为矩形框,无法完全契合集电盒边缘。由于车辆行驶过程中会出现路面不平整、两侧车轮气压不同、摄像头安装出现偏差等现象,集电盒安装在线网也无法做到和地面完全水平,这就导致集电盒和摄像头会有视觉偏差。采用识别框的形式无法准确定位到摄像头到集电盒的水平距离存在偏差,导致集电杆无法并线网。
3 网络改进
3.1 SE 网络结构
压缩和激励网络(squeeze and excitation network,SENet)如图6 所示,包括压缩和激励两个过程,其中,Ftr为卷积结构,X 和U 分别为输入与输出。通过学习各个通道之间的相关性,来学习多通道间的注意力,利用注意力机制来加强特征图通道间的信息,以此来增强主干网络的特征提取能力。该模块会略微增加计算量,但可达到更好的预测效果。
SE 块在卷积结构之后接入,首先进行全局平均池化(global average pooling,GAP)。基于通道的全局信息来计算通道权重,计算公式为
其中:GAP 得到的向量为z;un表示u 中第n 个二维矩阵。其次是激励操作,一个类似于循环神经网络中门的机制,通过参数w 来为每个特征通道生成权重,方便呈现建模的特征通道间的相关性。得到压缩的1×1×N 的表示后,加入一个全连接层,对每个通道的重要性进行预测。得到不同通道的重要性后,作用激励加到之前的特征图的对应通道上,再进行后续操作。
图7 是残差网络加入SE 模块之后的SEResNet 模块。输入的特征图X 进入到SE 模块,首先进入残差操作,利用GAP 得到每个特征图的全局特征表示数据,并进入到降维全连接操作。SE 模块默认系数为r,再进入第2 个全连接恢复通道维度,经过Sigmoid 函数进行分配得到通道特征权重,最后与输入X 的特征图相乘,获得带系数的输出特征图。
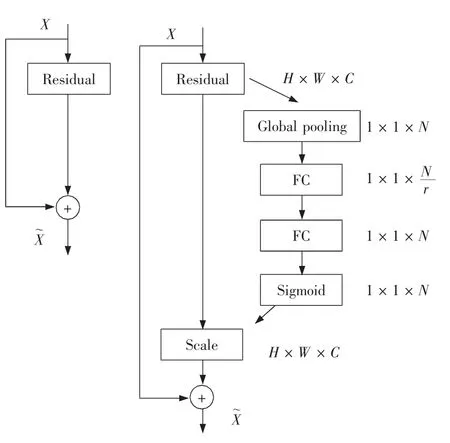
图7 SE-ResNet 模块Fig.7 SE-ResNet module
3.2 POLY 网络结构
超列将像素点对应的激活网络特征进行串联,进行目标的细粒度定位;同时进行分割,通过训练标定后的模型可以有效提取物体轮廓。图8 表示将不同层的低尺寸的特征图2 倍上采样后与下个尺寸特征图进行融合,以此类推,统一各特征图大小至与输入图像大小相同,运用阶梯式,将不同尺度的单个输出尺度合成,使得输出更加平滑。
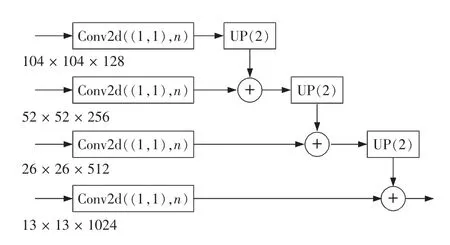
图8 超列和上采样Fig.8 Hypercolumn and upsampling
3.3 SE-YOLO-POLY 网络结构
如图9 所示,改进网络采用基于CSPDarkNet的结构。为提高特征值提取能力,在残差网络结构中嵌入了挤压与激励模块。以一个输入为208 ×208×64 的特征值为例:

图9 改进网络结构Fig.9 Improved network structure
1)对输入特征值进行压缩,通过GAP 压缩成1×1×64 的维度;
2)经过FC 全链接层,将特征维度降低到输入的1/16,使得特征值被压缩成1×1×4 的维度;
3)经过ReLu 激活后,再通过一个FC 全链接层升回到原来1×1×64 的维度;
4)通过Sigmoid 获得一个0~1 之间的归一化权重,并加到每个通道的特征值上;
5)与输入进行检测操作,使各个通道权重与输入对应通道进行二维矩阵相乘。
采用较多的非线性,可以更好地拟合通道间的复杂相关性。挤压与激励模块的引入增加了使用空间和通道信息,使预测的准确率进一步提升,同时减少了硬件消耗。各个输出网络采用轻量级的梯度上采样的结构,避免了K-mean 聚类[15-18]。
4 训练和实测结果
4.1 双源无轨电车结构
双源无轨电车主要由线网、双集架、车上摄像头、视频处理单元、电池、发动机及其控制部门组成,如图10 所示。车辆启动后判断双集架是否搭载在线网上。没搭载则切换到电池提供动力,将车辆停在集电盒附近,通过传感器摄像头捕捉图像,并通过视频控制单元进行自动识别并控制双集架并网。双源无轨电车在线运行期间,电池充电,可用于支持以后的离线操作。
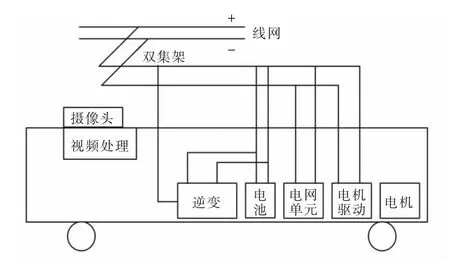
图10 双源无轨电车动力系统和视觉系统Fig.10 Dual-source trolleybus power system and vision system
4.2 训练过程
4.2.1 训练模型
如图11 所示,通过集电盒下摄像头得到双源无轨电车的不同环境和路况情况下的数据。选取部分图片作为训练集,并进行网络标注,即用软件和手动进行图片标定后,对训练集进行模式转换。将视觉目标分类格式转换为文本文件,包含连框中心点的x 坐标与图片的宽度比值、y 坐标与图片的高度比值、连框的宽度与图片宽度比值、连框的高度与图片高度比值的格式,以及各个点和多边形顶点的扇区网格。网格的中心与目标边界框的中心重合。然后每个扇区检测特定顶点的极坐标,不存在顶点的扇区产生0 的置信度。通过物体的顶点情况和物体面积计算出摄像头和集电盒的角度偏差,得到距离。

图11 网络标注Fig.11 Network labels
搭建SE-YOLO-POLY 环境并编译成功。网络编辑配置文件,创建训练数据集和测试数据集,安装英伟达的并行架构计算软件后,利用3060 显卡进行GPU 训练。
4.2.2 运算结果
集电盒的大小不一致、高度不一致、拍照角度不一致等,同时在环境中存在光线不同、天气干扰、背景多变、遮挡和阴影等干扰,导致识别的集电盒出现异动的形变和尺寸变化。
对不同场景下的基于CSPDarkNet-53 主干网络的4 个模型测试,数据对比如表1 所示。其中改进模型在准确性(F1 score)上有明显提升,优于深层的YOLO-V4 网络和轻量化(Tiny)网络,平均精度上也明显优于前两种网络。权重大小仅为63 MB,可以较好地部署到移动等低功耗要求设备中去,从而减少缓存和算力消耗,同时识别准确度和运算速度有明显提升。

表1 不同网络模型测试结果Tab.1 Test results of different network models
在YOLO-V4-Tiny 和SE-YOLO-POLY-Tiny模型训练过程中,损失函数如图12 所示,其中横坐标表示迭代次数,纵坐标表示损失函数值。
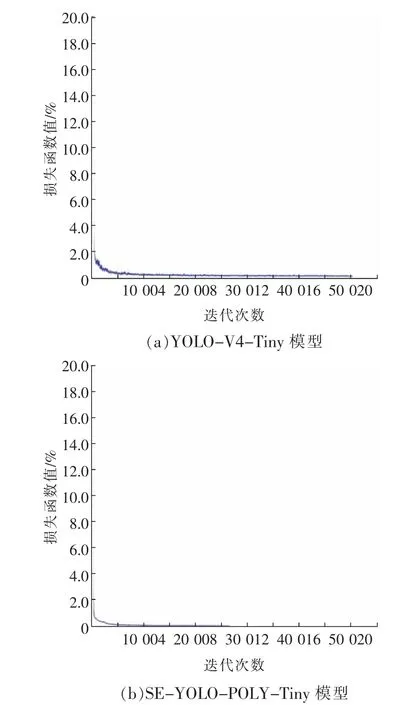
图12 YOLO-V4-Tiny 和SE-YOLO-POLY-Tiny 训练结果Fig.12 YOLO-V4-Tiny and SE-YOLO-POLY-Tiny training results
从图12 中可以看出,改进型SE-YOLO-POLYTiny 的损失函数值在500 次迭代后收敛较快,从4 000 次开始趋于平均,说明所选取的网络模型相对合理。而传统的YOLO-V4-Tiny 算法在50 020次后趋于收敛。改进后模型比传统网络模型收敛速度更快,趋于稳定后损失函数值更小,识别精度更高。
4.3 路测结果
将两种网络模型分别装在双源无轨电车的图像控制器中,对同一摄像头采集的照片进行识别和分割,得到图13。

图13 路上实测图Fig.13 Test results of the real environmental
集电杆能否搭载在线网上是判断成功与否的标准。由于线网上的集电盒有一定坡度,误差在200 mm以内可以识别。基于北京6 路汽车路线进行实际测试。整条路线一共有8 个集电盒点,测试结果如表2所示,所提供的SE-YOLO-POLY-Tiny 网络的成功率接近100%,测试精度明显好于传统网络。
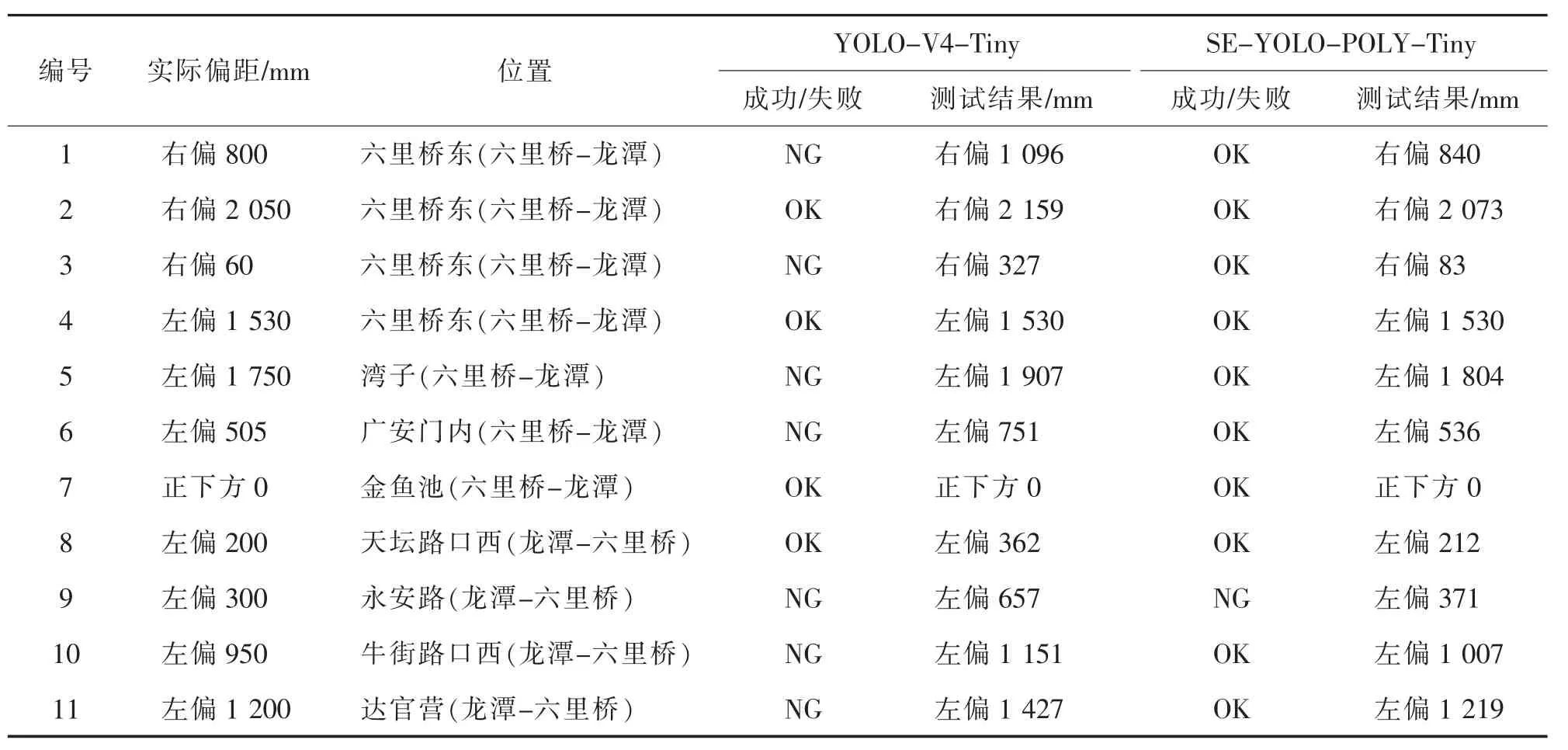
表2 六路两种测试结果Tab.2 Two test results comparison of bus No.6
5 结论
在双源无轨电车智能识别场景下,采用SEYOLO-POLY 模型结构的算法明显优于传统的YOLO-V4 算法。通过物体识别框和语义分割两种方式,解决了双源无轨电车集电盒识别应用上的技术难题,有效提高了训练速度和精度。通过提高训练和实际部署,面对复杂环境,进行了双源无轨电车实际路上测试。测试结果表明,本文所提出的改进SE-YOLO-POLY 模型识别精度优于传统网络,可以在双源无轨电车中进行大规模部署。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28 06:14:40
汽车工程师(2021年12期)2022-01-18 06:02:43
自动化学报(2018年2期)2018-04-12 05:46:16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
导航定位学报(2015年2期)2015-06-05 09:27:38
汽车维修与保养(2015年8期)2015-04-17 03:32:59
中国医学科学院学报(2010年6期)2010-03-25 13:58:24
