
结合语义先验和深度注意力残差的图像修复
2023-10-29 04:20陈晓雷梁其铎
计算机与生活 2023年10期
陈晓雷,杨 佳,梁其铎
兰州理工大学 电气工程与信息工程学院,兰州 730000
图像修复指基于图像背景信息对破损区域进行重建的技术。生成对抗网络(generative adversarial networks,GAN)[1]利用生成模型与判别方法的相互博弈,并考虑全局信息,对样本进行特征提取和图像生成,具有生成目标时间短、速度快的特点,能有效地解决图像修复问题。基于GAN的双阶段图像修复网络也是该方向的代表性方法,第一阶段重建缺失结构,第二阶段利用第一阶段预测得到的结构信息指导纹理的生成。例如Nazeri 等人[2]提出的边缘连接网络(EdgeConnect),首先利用边缘生成器生成缺失图像的边缘,再利用边缘作为先验来补全图像的缺失区域。Xiong 等人[3]将模型分为两部分,首先预测前景轮廓,然后根据预测到的前景轮廓进行区域修复。李海燕等人[4]在第一阶段用一种基于可视化几何组网络模型的轻量型双向级联边缘检测网络(bidirectional cascade network,BDCN)提取图像边缘,然后基于U-Net[5]架构来还原缺失边缘。胡凯等人[6]采用边缘结构生成器对输入图像的边缘和色彩平滑信息进行特征学习,生成缺失区域的结构内容,以引导精细网络重构高质量的语义图像。
然而两阶段修复方法的性能在很大程度上依赖于第一阶段的重建结构,导致边缘或轮廓的不可靠性增加,不利于第二阶段的图像生成。针对这一缺陷,Li等人[7]提出了单阶段视觉结构渐进重建(progressive reconstruction of visual structure,PRVS)网络,在编码器-解码器中分别部署两个视觉结构重建层,以生成不同尺度的结构信息,通过将结构信息逐步融合到特征中,基于GAN 输出合理的结构。但是PRVS 倾向于生成棋盘状纹理,修复结果纹理不真实。Song 等人[8]提出利用语义分割信息对图像缺失区域进行补绘的分割预测和指导修复网络(segmentation prediction and guidance network,SPG-Net),该算法首先提取并重建图像分割图,再利用图像分割图对图像进行引导。由于分割图中包含了有用的语义信息,SPG-Net相比那些没有语义分割图的方法能够有效地提高嵌入性能。但是,不同语义的先验分布不同,不同语义区域对缺失区域像素的贡献也不同,因此以SPG-Net为代表的基于上下文的方法将不同语义统一进行映射往往会导致语义内容不真实。为了解决这一问题,本文引入多尺度语义先验,首先利用编码器和语义先验网络分别提取多尺度的底层图像特征和学习高级语义先验,得到全局上下文表示,然后将学习到的语义先验空间注入到图像特征中,从而利用语义先验指导图像缺失区域生成。除此之外,引入多尺度交叉熵损失来约束所有尺度上像素的预测类分布与目标类分布之间的距离,帮助图像补全。
现有的图像修复网络很多都设计了复杂的网络结构来提高图像修复性能,如Liu 等人[9]设计了两阶段的U-Net 作为主干网络并提出了一个连贯语义注意层来建立缺失部分特征之间的关联模型以对图像缺失部分进行预测;Liu等人[10]提出的DeFLOCNet通过一个深度编码器-解码器在空白区域上生成结构和纹理;Zhang 等人[11-12]提出了一种残差通道注意力网络和残差非局部注意力网络用于高质量的图像恢复。本文在这些工作基础上,为了能加深网络并且使网络更加关注于图像缺失区域,提出利用残差注意力和残差块构建双重残差,继而构成深度注意力残差组,不仅可以构造更深的网络,还可以利用注意力对通道信息进行自适应提取。
图像修复任务中经典的编码器-解码器结构在编码压缩过程中会丢失大量细节信息。为了获取更多信息,Mao 等人[13]在一组对称的编码器-解码器组中引入了密集的跳跃连接,以最大化语义提取。杨文霞等人[14]则提出基于密集连接块的U-Net 结构的端到端图像修复模型,以实现对任意模板的语义人脸图像的修复。这些方法通过增加跳跃连接的方式将编码器的每一层特征与解码器的相应层特征连接起来,但是跳跃连接结构缺乏从全尺度探索足够信息的能力。因此本文提出全尺度跳跃连接,该连接结合了来自全尺度特征的低级语义信息与高级语义信息,从而有效地将低层次特征图与高层次特征图结合起来对缺失图像进行补全。
本文的主要贡献如下:
(1)提出了语义先验网络,一种在多尺度上既能考虑局部纹理一致性又能考虑全局语义一致性的上下文图像修复模型,通过语义先验指导图像特征,并利用交叉熵损失约束像素的预测类分布与目标类分布之间的距离,从而提升图像恢复性能。
(2)提出深度注意力残差组使网络能自适应地学习较深网络中不同通道中的特征,不仅具有跨通道的学习能力,而且能够适应更深层的网络结构。
(3)采用全尺度跳跃连接将不同尺度特征图的低级细节与高级语义结合起来,从而提供多层次多尺度的语义信息。
1 本文方法
1.1 网络总体结构及工作原理
本文提出的结合语义先验和深度注意力残差的图像修复网络总体结构如图1所示,由生成器与判别器组成,其中生成器由编码器(encoder)、语义先验网络(semantic priors network,SPN)、深度注意力残差组(deep attention residual group,DARG)、解码器(decoder)和全尺度跳跃连接(full-scale skip connection,FSSC)五个模块组成。本文的图像修复网络工作流程如下:首先输入缺失图像,编码器提取多尺度图像特征,同时语义先验网络提取多尺度图像语义先验,多尺度图像特征和多尺度语义先验融合得到合成语义信息下的图像特征;然后将得到的图像特征送入深度注意力残差组进一步增强缺失区域及各个通道的特征;接着将增强后的图像特征送入解码器进行图像生成;最后将生成的图像送入谱归一化[15]马尔科夫鉴别器[16]用于生成器对抗训练,以确定输入鉴别器的是真实样本还是生成器生成的假样本。

图1 本文提出的图像修复网络Fig.1 Image inpainting network presented in this paper
本文重点研究了影响生成器总体性能的语义先验网络、深度注意力残差组、全尺度跳跃连接和约束语义先验网络的多尺度交叉熵损失,这四个模块的构成及工作原理详述如下。
1.2 语义先验网络
图像修复任务的目标在于对缺失区域的补全,为了使网络的修复结果更具有真实性并且充分地利用未缺失区域的信息内容,本文提出语义先验网络,该网络可以在预先训练的深层神经网络的监督下,学习缺失区域视觉元素的完整语义先验信息,更好地提取到图像特征,并从图像的未缺失区域中学习语义信息,利用学习到的语义信息对缺失区域进行补全。由于不同语义的先验分布不同,不同语义区域对缺失区域像素的贡献也不同,采用多尺度的语义先验来获得不同语义的先验分布和不同语义区域对缺失区域像素的贡献。首先,通过语义先验网络得到多尺度语义先验,通过编码器得到多尺度图像特征;然后,将得到的多尺度语义先验和多尺度图像特征对应相同尺度下的语义先验和图像特征进行融合;最后,将各个尺度下融合到的特征进行相融后送入深度注意力残差组进行图像恢复。
编码器的输入为带有缺失区域的图像Im,其作用为学习图像未缺失区域的图像特征Fm。在语义先验网络阶段,为了保留更多的局部结构,先对带有缺失区域的图像Im和缺失图像相应的掩码M进行上采样得到Ime和Me,将Ime和Me通道合并后的图像特征Fim作为语义先验网络的输入,语义先验网络学习输入特征Fim的语义先验Fs。因此通过编码器可以学习到多尺度图像特征Fms、Fml,通过语义先验网络可以学习到多尺度语义先验Fss、Fsl。具体计算方法如下:
在语义先验网络阶段,为了保留更多的局部结构,先对带有缺失区域的图像Im和缺失图像相应的掩码M进行上采样,将上采样后图像和掩码的通道合并后的图像特征Fim作为语义先验网络的输入,语义先验网络学习输入特征Fim的语义先验Fs。
其中,Im∈R3×H×W,M∈R1×H×W,Ups代表上采样,Concat代表通道合并,Ime∈R3×2H×2W,Me∈R1×2H×2W,Fim∈R4×2H×2W,E(∙)代表网络编码阶段,S(∙)代表网络语义先验阶段,则Fms,Fss∈R2c×H/4×W/4,Fml,Fsl∈Rc×H×W。统称学习到的语义先验为Fs,图像特征为Fm。
理论上利用学习到的语义先验Fs可以帮助图像特征Fm进行图像恢复,但是经过编码阶段得到的图像特征Fm和经过语义先验阶段学习得到的语义先验Fs关注到的是图像内容的不同方面,直接对图像特征Fm和语义先验Fs进行特征融合会影响编码器的学习过程并且干扰未缺失区域的局部纹理。空间自适应归一化模块(spatially-adaptive normalization,Spade)[17]可以根据输入图像和语义图指导合成语义信息下的图像,因此,本文采用空间自适应归一化模块Spade 根据学习到的语义先验来指导图像特征Fm合成语义信息下的图像,对图像缺失区域进行生成,从而帮助恢复全局和局部的内容。具体来说,Spade首先用非参数实例归一化IN[18]对输入图像特征Fm进行归一化,然后从语义先验Fs中学习两组不同的参数,对图像特征Fm执行空间像素仿射变换,计算方法如下:
其中,Spade为空间自适应归一化模块,γ和β为从语义先验Fs中学习到的两组参数,IN代表实例归一化。
将多尺度图像特征Fms、Fml和多尺度语义先验Fss、Fsl通过式(3)和式(4)融合后可得多尺度语义信息下的图像特征
为了对多尺度语义先验阶段所有尺度上像素的预测类分布与目标类分布之间的距离进行约束,引入多尺度交叉熵损失,并通过各个损失项不同的加权得到网络的总损失,具体细节见1.5节。
语义先验网络工作流程如下所示:
输入:缺失图像Im与掩码M。
输出:语义先验与编码器的融合特征Fm′。
1.3 深度注意力残差组
对于图像修复网络来说,深层残差网络能更好地利用通道特征,灵活地处理缺失区域与未缺失区域的信息。注意力机制可以告诉模型需要更关注哪些内容和哪些位置,从而加强模型的性能,其中通道注意力可以通过考虑通道之间的相互依赖性来自适应地重新调整特征。协调注意力(coordinate attention)[19]作为一种新型通道注意力不仅能捕获通道间的信息,还能捕获方向感知和位置感知的信息,帮助模型更加精准地定位和识别感兴趣的目标。因此本文引入深度注意力残差组,使生成器网络不仅能更加关注到图像的缺失区域,而且能自适应地学习各个通道的特征,专注于更有用的通道特征并构建更深层的网络。
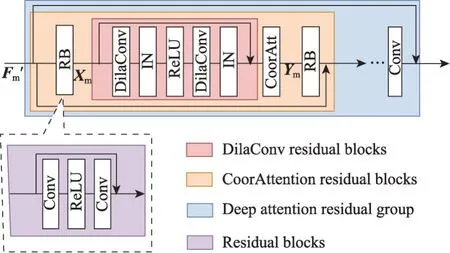
图2 深度注意力残差组Fig.2 Deep attention residual group
其中,RB为残差块,HDCRB为膨胀卷积残差块,HCA为协调注意力块,HCARB为注意力残差块,HConv为3×3卷积,HDARG为深度注意力残差组。
实验发现在深度注意力残差组中引入太多的残差块会导致网络训练不稳定,因此本文在残差块相加前引入一个卷积来使网络训练更加稳定。
利用注意力残差块和深度注意力残差组构成残差中的残差,能够使网络适应更深层的结构。深度注意力残差组内部的长连接和注意力残差块内部的短连接都可以将丰富的信息通过恒等映射向后传播,保证了网络中信息的流动。
1.4 全尺度跳跃连接
为了使网络可以更好地利用网络空间不同阶段的图像特征信息,减少编码部分下采样过程中所造成的部分信息丢失,并结合未缺失区域进一步提取缺失部分的信息,本文在编码器-解码器部分增加了全尺度跳跃连接,该连接结合了来自全尺度特征的低级语义信息与高级语义信息,从而将低层次特征图(包含图像的边界)与高层次特征图(包含图像的纹理与细节)结合起来对图像缺失区域进行修复。
全尺度指解码器的每一层都融合了来自编码器的较小和相同尺度的特征图以及来自解码器的较大尺度的特征图。将编码器各个尺度卷积后的图像特征分别设为Fel、Fem和Fes,解码器各个尺度的图像特征分别设为Fdl、Fdm和Fds,则经过全尺度连接后解码器各个尺度的图像特征可利用以下公式计算得到。
引入全尺度跳跃连接后网络能捕获全尺度下的细粒度细节和粗粒度语义,从而能获取更多的上下文信息对图像的缺失区域进行修复。
1.5 损失函数
损失函数包括用于图像缺失区域修复和语义先验的损失项。本文利用重建和对抗性损失来训练整个网络模型,利用多尺度交叉熵损失来约束语义先验。输入缺失图像经过修复网络模型修复后的图像为Imer:
其中,Ipre为经过生成器得到的预测图像,Igt为真实图像,M为二值掩码,⊙代表Hadamard乘积。Imer为将经过修复网络的预测图像与真实图像相结合生成的图像。
(1)重建损失。对于重建损失Limg,本文对重建图像使用L1损失,以更关注缺失区域的内容:
其中,n、i、j均为256。
(2)对抗性损失。利用对抗性损失Ladv来训练网络以生成更可信的局部细节:
其中,D代表判别器。
(3)多尺度交叉熵损失。对于语义先验,采用多尺度交叉熵损失来约束所有尺度上像素的预测类分布与目标类分布之间的距离,用来惩罚每个尺度上的像素每个位置的偏差:
其中,Lss(Ss,Sss)为在Sss,Ss∈R2c×H/4×W/4下经过上采样得到的交叉熵损失,Lsl(Sl,Ssl)为在Ssl,Sl∈Rc×H/2×W/2下经过上采样得到的交叉熵损失,Ups代表上采样,i表示语义先验图Ss、Sl中的每个像素。
(4)总损失。语义先验的总损失为交叉熵损失在多个尺度上的加权和:
其中,α1和α2均为0.5。
(5)网络总损失。网络的总损失被定义为上述多尺度重建损失、对抗性损失和多尺度交叉熵损失的加权和:
其中,λ1、λ2和λ3分别为重建损失、对抗性损失和多尺度交叉熵损失的权重,通过实验确定λ1=1.0,λ2=0.1,λ3=0.1。
2 实验结果及分析
2.1 模型实现
本文使用Pytorch 来实现所提出的网络结构,对训练集总数的1/2 采用水平翻转来增强数据。使用10个epoch训练网络,batchsize等于2,并使用动量参数为0.9 和初始学习率为0.001 的Adam 优化器。本文实验是在一台装载AMD R5 CPU 和RTX 3060 Laptop GPU的计算机上完成的。
2.2 训练与测试
本文采用CelebA-HQ 数据集与Paris Street View数据集来评估本文模型,数据集信息如下:
CelebA-HQ数据集[20]:CelebA-HQ总共包含30 000张图像,每张图像都包括了脸部特征点(landmark)、人脸属性(attribute)等信息,每张图像的分辨率都是1 024×1 024,本文使用27 000张用于网络训练,3 000张用于网络测试。
Paris Street View数据集[21]:巴黎街景数据集包含了足够的结构信息,比如窗户、门和一些巴黎风格的建筑,图像分辨率为936×537。巴黎街景数据集由15 000 张图像组成,本文使用14 900 张进行网络训练,100张图像进行测试。
对于来自CelebA-HQ 数据集和Paris Street View数据集的图像,本文将其分辨率统一调整为256×256。掩码部分采用的像素规格为中心区域为128×128 的白色掩码和掩码比率为10%~20%、20%~30%和30%~40%的白色随机掩码。
为了验证本文算法的有效性,本文对Paris Street View 数据集采用中心掩码,对CelebA-HQ 数据集采用中心掩码和随机掩码,选用峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)和L1 Loss作为评价指标进行定量比较。
PSNR是基于对应像素点间的误差,即基于误差敏感的图像质量评价;SSIM 是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性;L1 Loss 是为了确保像素级的重建精度,可以保留颜色和亮度。PSNR和SSIM值越高,表示网络性能越好,L1 Loss值越低,则表示网络性能越好。
2.3 实验结果与对比分析
本文方法对CelebA-HQ数据集与Paris Street View数据集在中心掩码上对PSNR、SSIM 和L1 Loss 值进行了比较。对CelebA-HQ数据集在不同比例掩码上对PSNR、SSIM 和L1 Loss 值进行了比较。本文将提出的方法与图像修复领域先进的PRVS(progressive reconstruction of visual structure)、DSNet(dynamic selection network)[22]、RFR(recurrent feature reasoning)[23]和RN(region normalization)[24]算法进行了客观指标比较与主观修复结果比较,其中PRVS、DSNet 和RN均为基于GAN的修复方法,RFR为基于CNN的修复方法。不同修复方法在CelebA-HQ 和Paris Street View数据集的客观指标实验结果见表1和表2,不同方法在CelebA-HQ和Paris Street View数据集的主观修复结果见图3~图5。

表1 不同数据集上中心掩码修复结果对比Table 1 Comparison of center mask inpainting results on different datasets
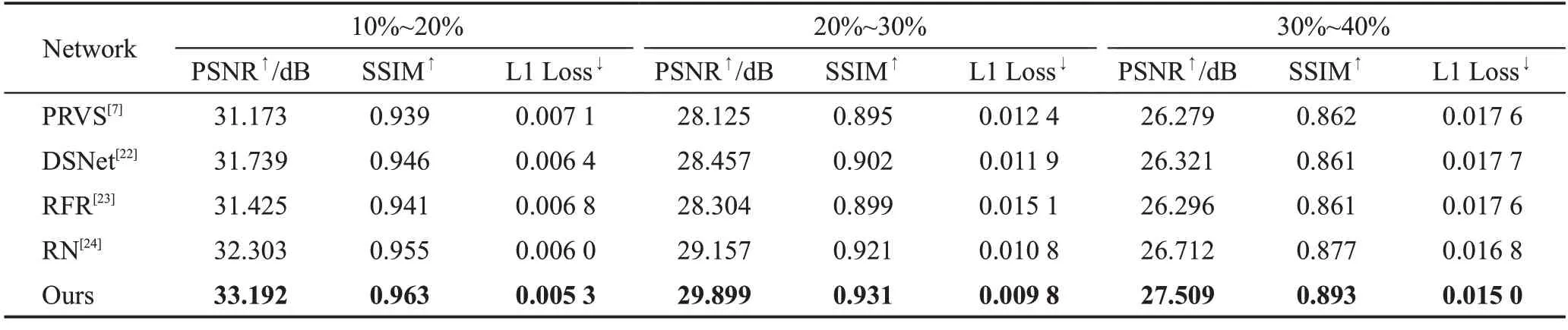
表2 不同数据集上随机掩码修复结果对比Table 2 Comparison of random mask inpainting results on different datasets

图3 CelebA-HQ数据集上中心掩码修复结果Fig.3 Inpainting results of center mask on CelebA-HQ dataset
2.3.1 客观实验结果及对比分析
从表1结果可见,在CelebA-HQ数据集上,PRVS、DSNet、RFR 和RN 四种方法中PRVS 的PSNR 和SSIM 最高,L1 Loss 最低。本文方法相较于PRVS 在CelebA-HQ 数据集上PSNR 和SSIM 分别提高0.493和1.2%,L1 Loss 减少0.09%。在Paris Street View 数据集上,PRVS、DSNet、RFR 和RN 四种方法中RN 的PSNR 和SSIM 最高,L1 Loss 最低,本文方法相较于RN 在Paris Street View 数据集上PSNR 和SSIM 分别提高0.545和0.8%,L1 Loss减少0.1%。
表2 中10%~20%、20%~30%、30%~40%分别代表随机掩码比率。如表2 所示,在掩码比率为10%~20%时,不同方法的实验结果相差较大,随着掩码比率的增大,不同方法的实验结果差距逐渐缩小。在随机掩码修复实验中PRVS、DSNet、RFR 和RN 四种方法中RN 的PSNR 和SSIM 最高,L1 Loss 最低。本文方法相较于RN 在CelebA-HQ 数据集上在随机掩码为10%~20%时PSNR 和SSIM 分别提高0.889 和0.8%,L1 Loss 减少0.07%;在随机掩码为20%~30%时PSNR 和SSIM 分别提高0.742 和1.0%,L1 Loss 减少0.1%;在随机掩码为30%~40%时PSNR和SSIM分别提高0.797和1.6%,L1 Loss减少0.18%。
2.3.2 主观实验结果及对比分析
不同方法的修复结果在CelebA-HQ 数据集上采用中心掩码的主观视觉比较如图3所示。其中(a)gt为真实图像,(b)input 为缺失图像,(c)PRVS、(d)DSNet、(e)RFR 和(f)RN 分别代表不同方法的修复结果,(g)Ours 为本文方法的修复结果。可以看到PRVS、RFR 及RN 的修复结果都有不同程度上的模糊,本文方法相比这些方法更加清晰。DSNet与本文方法的修复结果视觉差异较小,将在图6进行局部放大后再进行深入对比和分析。
不同方法的修复结果在Paris Street View数据集上采用中心掩码的主观视觉比较如图4 所示。可以看出,本文算法的修复结果在被遮挡的窗户部分相比其他算法可以明显看到窗户的轮廓,其他方法的修复结果窗户的轮廓相对不清晰。

图4 Paris Street View数据集上中心掩码修复结果Fig.4 Inpainting results of center mask on Paris Street View dataset
不同方法的修复结果在CelebA-HQ 数据集上采用随机掩码的主观视觉比较如图5所示,从上到下的三行掩码比率分别为10%~20%、20%~30%和30%~40%。在掩码比率为10%~20%时,所有方法都可以对缺失区域进行较好的补全。在掩码比率为20%~30%时,其他方法对人物脸部的右下方区域的补全都有若干的缺失与模糊,本文方法能对人物脸部的右下方区域进行较完整的补全。在掩码比率为30%~40%时,PRVS、RFR和RN能明显地看到未补全区域,本文方法与DSNet修复结果相比无明显的差异。
2.3.3 主观实验结果局部对比分析
从图3~图5 主观实验结果及对比分析中可以看到,本文方法相比PRVS、RFR及RN的主观修复结果有较明显的改善与提升,但是与DSNet的修复结果视觉差异较小,因此本文将DSNet与本文方法的实验结果进行了局部放大对比,如图6所示。
图6中(a)gt、(b)gt(local)、(c)DSNet(local)和(d)Ours(local)分别为整体真实图像、局部真实图像、局部真实图像的DSNet 修改结果和本文方法修复结果。其中绿色框部分表示真实图像的缺失部分,蓝色框表示真实图像与DSNet 和本文方法修复结果的差异部分。第一行实验结果,本文方法的修复结果整体上比较模糊,DSNet 整体上比较清晰,但是和原始图像相比,本文方法在关键细节的修复上更加接近原图,比如对人物鼻梁、鼻孔和右侧咬肌的修复。第二行实验结果,DSNet修复结果整体上依然比本文方法清晰,但是DSNet 出现了原图没有的线条和纹理,且没有修复出字母A。第三行实验结果,两种方法的修复结果主观视觉无明显差异。第四行实验结果,人物右侧脸颊上的纹理,本文修复结果好于DSNet,其余区域两种方法的修复结果主观视觉无明显差异。第五行实验结果,两种方法的修复结果主观视觉无明显差异。总体而言,本文方法修复结果好于DSNet修复结果。
2.4 模型训练
2.4.1 训练过程损失曲线
训练过程中G_L1_Loss 和G_Loss 曲线如图7 与图8 所示。其中Paris-center、CelebA-HQ-30~40、CelebA-HQ-20~30、CelebA-HQ-10~20和CelebA-HQcenter 分别代表Paris Street View 数据集使用中心掩码训练网络、CelebA-HQ数据集使用30%~40%、20%~30%、10%~20%的随机掩码比率和中心掩码训练网络。本文对网络训练了10 个epoch,取每个epoch 的平均损失作为当前epoch 的损失值,由图7 和图8 可以看到,随着网络训练的epoch 数增加,网络的G_L1_Loss和G_Loss逐渐降低并趋于收敛。

图7 训练过程G_L1_Loss曲线Fig.7 G_L1_Loss curve in training process
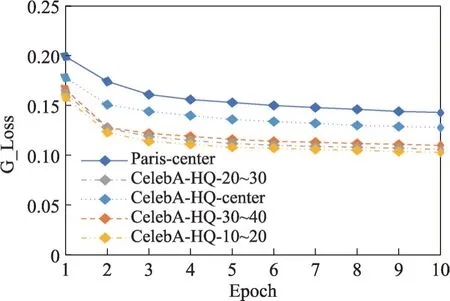
图8 训练过程G_Loss曲线Fig.8 G_Loss curve in training process
2.4.2 相关技术指标迭代曲线
本文采用CelebA-HQ 数据集中的3 000 张图像对每个epoch 保存的模型进行验证从而得到每个epoch的PSNR、SSIM和L1 Loss迭代曲线,如图9~图11所示。可见随着epoch数量的增加,PSNR和SSIM逐渐增加并趋于收敛,L1 Loss逐渐降低并趋于收敛。
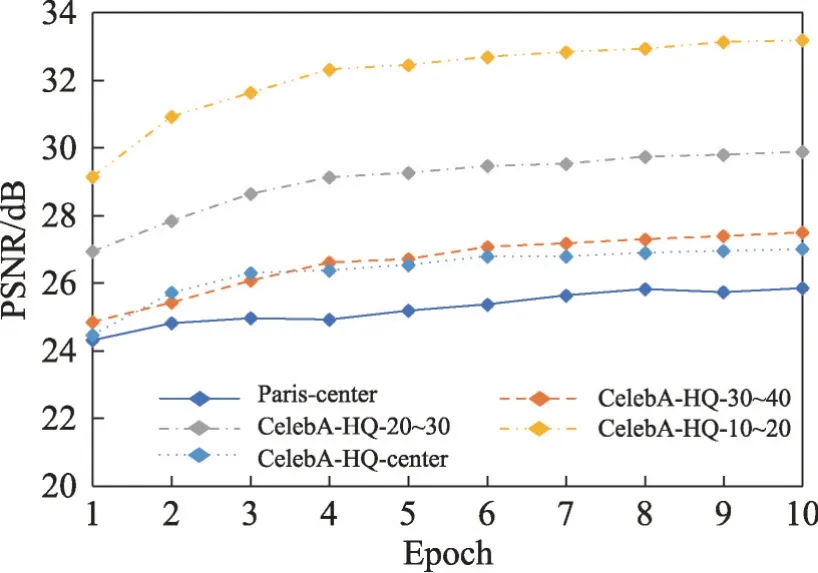
图9 PSNR迭代曲线Fig.9 PSNR iteration curve
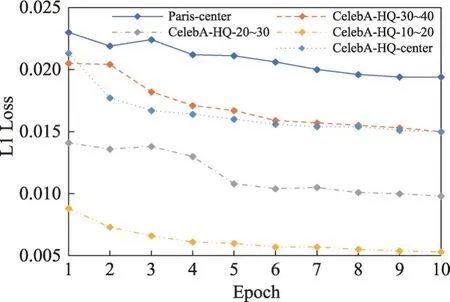
图11 L1 Loss迭代曲线Fig.11 L1 Loss iteration curve
2.5 消融实验
2.5.1 各个模块的消融实验
本文在CelebA-HQ和Paris Street View数据集上使用中心掩码进行消融实验,以编码器-解码器组成的生成器为基础网络(Baseline),分别在基础网络上添加不同的模块来验证各个模块的有效性,√表示使用该模块,×表示不使用该模块。实验结果如表3所示,实验结果增幅如表4 所示,其中SPN 代表语义先验,Muloss 代表多尺度交叉熵损失,DARG 代表深度注意力残差组,FSSC代表全尺度跳跃连接。
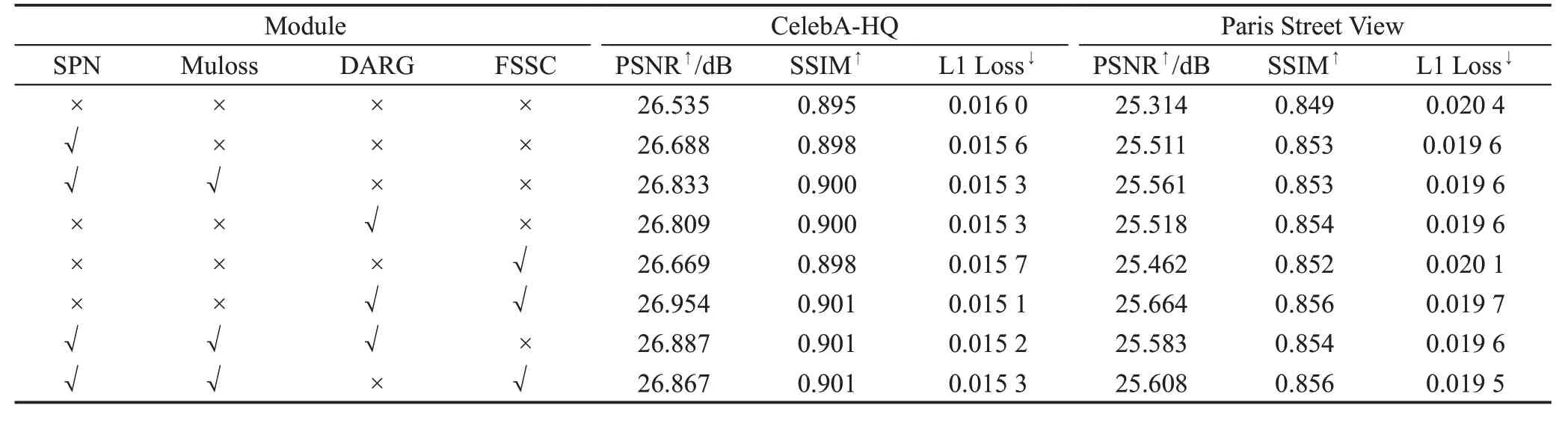
表3 两个数据集上各个模块的实验结果Table 3 Experimental results of each module on two datasets

表4 两个数据集上各个模块的实验结果增幅Table 4 Increase of experimental results of each module on two datasets
从表4可以看到,在基础网络中加入每个模块后PSNR和SSIM都有所增加,L1 loss都有所减少,证明了在基础网络上增加各个每个模块对网络都有所提升,证明了每个模块的有效性。
2.5.2 语义先验与编码器多尺度融合消融实验
为了验证语义先验与编码器多尺度融合的有效性,在CelebA-HQ 数据集上采用中心掩码进行消融实验。在编码器-解码器组成的生成器中加入深度注意力残差组(DARG)和全尺度跳跃连接(FSSC)作为基础网络,对语义先验与编码器融合后的两个尺度图像特征分为三种情况进行消融实验,分别为和表示将两个不同尺度的图像特征融合到同一尺度。实验结果如表5所示。
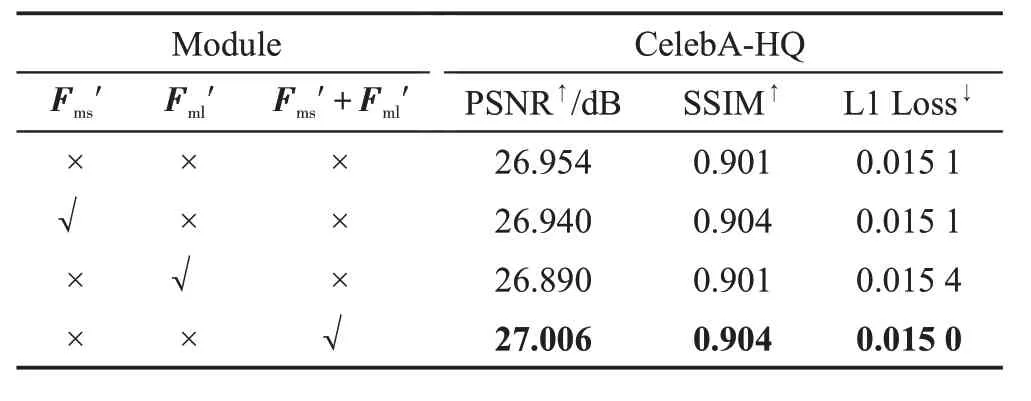
表5 语义先验与编码器多尺度融合的实验结果Table 5 Experimental results of multi-scale fusion of semantic priors and encoder
从表5的实验结果可以看到,在基础网络上加入语义先验与编码器融合后的图像特征后网络的PSNR减少0.014,SSIM增加0.003,L1 Loss没有改变;加入语义先验与编码器融合后的图像特征后网络的PSNR 减少0.064,SSIM 没有改变,L1 Loss 增加0.000 3;在基础网络上加入语义先验与编码器多尺度融合后的图像特征后PSNR 和SSIM 分别增加0.052 和0.003,L1 Loss 降低0.000 1。证明了语义先验与编码器多尺度融合对图像修复网络更有效,对图像修复后的结果更好。
2.5.3 全尺度跳跃连接与跳跃连接的消融实验
为了验证全尺度跳跃连接的有效性,在CelebAHQ数据集上采用中心掩码对全尺度跳跃连接(FSSC)与跳跃连接(SC)进行消融实验,跳跃连接是指直接将编码器-解码器的相应尺度进行连接。以编码器-解码器组成的生成器为基础网络,在基础网络上分别添加全尺度跳跃连接与跳跃连接进行消融实验;并在基础网络上加入由语义先验、多尺度交叉熵损失和深度注意力残差组组成的DSM分别与全尺度跳跃连接和跳跃连接进行消融实验,实验结果如表6所示。
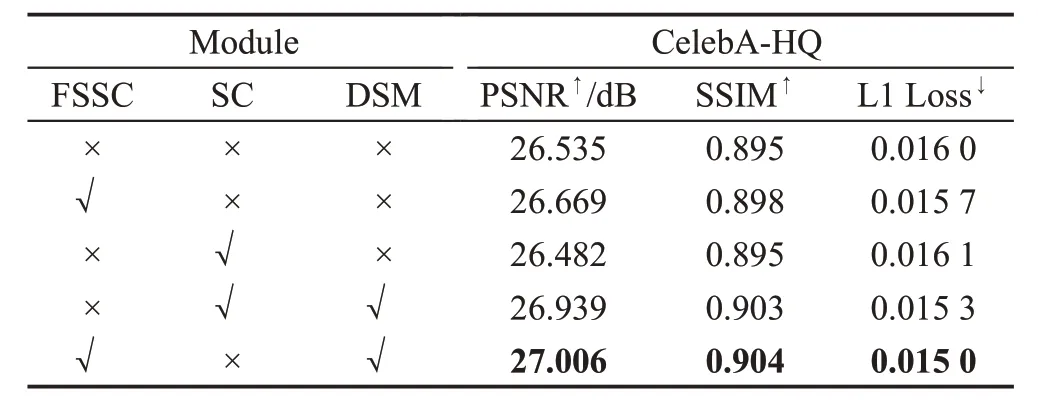
表6 全尺度跳跃连接与跳跃连接的实验结果Table 6 Experimental results of full-scale skip connection and skip connection
从表6的实验结果可以看到,在基础网络上加入全尺度跳跃连接后PSNR 和SSIM 分别增加0.134 和0.003,L1 Loss 减少0.000 3;在基础网络上加入跳跃连接后相比基础网络PSNR 反而减少0.053,SSIM 没有改变,L1 Loss 反而增加了0.000 1;基础网络上加入语义先验、多尺度交叉熵损失、深度注意力残差组和跳跃连接后PSNR 和SSIM 分别增加0.404 和0.008,L1 Loss 降低0.000 7;基础网络上加入语义先验、多尺度交叉熵损失、深度注意力残差组和全尺度跳跃连接的PSNR 和SSIM 分别增加0.471 和0.009,L1 Loss 降低0.001。由实验结果可知全尺度跳跃连接比跳跃连接的PSNR 和SSIM 更高,L1 Loss 更低,证明了加入全尺度跳跃连接比跳跃连接对图像修复网络更有效。
3 结束语
本文提出了结合语义先验和深度注意力残差组的图像修复网络。通过语义先验网络学习缺失区域视觉元素的完整语义先验信息,更好提取图像特征,并从图像的未缺失区域中学习语义信息;深度注意力残差组使网络专注于更有用的通道特征并构建更深层的网络;全尺度跳跃连接可以更好利用网络空间不同阶段的图像特征信息,从而对缺失区域补全。实验表明,该网络模型在主观和客观上的实验结果都优于目前代表性先进方法的修复结果,得到的修复图像更具真实性,并且与真实图像更加相似。后续工作将进一步优化图像修复网络模型,使网络模型更加轻量化,重建速度更快。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
通信学报(2019年5期)2019-06-11
成都信息工程大学学报(2018年3期)2018-08-29
通信技术(2018年3期)2018-03-21
自动化学报(2017年5期)2017-05-14
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
浙江大学学报(工学版)(2015年4期)2015-03-01
