
基于ChatGPT的电信诈骗案件类型影响力评估
2023-10-29 04:20裴炳森
计算机与生活 2023年10期
裴炳森,李 欣,吴 越
中国人民公安大学 信息网络安全学院,北京 100038
随着社会的不断发展,科学技术的不断进步,犯罪形式和犯罪手段也在不断变化,在各类犯罪中,电信诈骗犯罪是发案最高、损失最大、群众反映最强烈的突出犯罪。电信诈骗犯罪严重侵害人民群众的财产安全,严重侵蚀了社会诚信根基。然而,当前对电信诈骗的反制措施往往是基于经验和案例进行分析的,存在一定的局限性,较为主观和片面,并且缺乏自适应性,缺乏对案件因素的量化评估。针对多变的电信诈骗犯罪手段和不断改进的作案方式,对不同案件类型进行综合评估有助于及时全面了解各类犯罪手段的威胁程度和影响力,捕捉新型犯罪手段的出现和发展趋势,将有限的资源重点投入到最具威胁和危害的领域,提高资源的利用效率,并用量化数据驱动反诈工作的决策,为反诈工作提供客观科学的依据,提高反诈工作的针对性和有效性。
为了更好地利用文本内的非结构化数据,通常选择使用知识图谱进行知识存储,可由于电信诈骗领域的相关案件数据较少,如果使用传统的深度学习模型进行知识抽取,会面临数据不足等的问题,难以充分学习到领域内特定的知识,同时还存在很大的过拟合风险,导致在真实的场景中应用效果不佳。而且使用传统的深度学习模型构建知识图谱需要进行实体和关系的标注,然后在专业领域这类小样本中,标注数据的获取和准确性存在一定的困难。
针对上述问题,本文提出以下解决方案:
(1)本文通过使用ChatGPT根据电诈案例文本构建案件知识图谱,以解决当前在电信诈骗领域因小样本引发的构建知识图谱困难等问题,使用ChatGPT构建知识图谱不需要对数据进行标注和训练模型,使用ChatGPT 强大的通用语言理解能力并结合问题模版对问答内容进行限制即可得到高质量的知识图谱,从而达到使用ChatGPT 较低成本完成知识抽取与构建知识图谱的目的,将其应用在电信诈骗领域,可以完成数据分析统计、类案推理、串并案分析等。
(2)本文根据电信诈骗案件的案发时间、涉案金额、涉案事主人数三个因素,提出确定案件类型的影响因子的计算方法,以实现对不同案件类型的影响力评估,并根据各个类型案件的影响力针对性、科学性提出反诈措施与方案。与传统的基于人工经验和规则的方式相比,计算影响因子的方法更加准确全面、综合多种案件因素,不仅仅局限于单一的规则,而且各类案件的影响力评估数据,给公安民警提供了一种更科学客观的指标,能够帮助实现对案件发案趋势的把控,对人民群众进行精准宣传与防范,从根源打击电信诈骗。
1 相关工作
1.1 大语言模型技术探究
ChatGPT是由OpenAI设计、训练和发布的一种语言模型。它以问答的形式完成各种任务,接受文本输入,理解自然语言,并生成响应,模拟人类对话。在各个自然语言处理子任务中表现出色。相较于其他大型语言模型,ChatGPT拥有更丰富的知识体量,涵盖了自然科学、社会科学、人文历史等多个领域的知识。
ChatGPT 是在GPT3.5[1]的基础上经过微调而来的,微调过程中引入了RLHF(reinforcement learning from human feedback)技术,通过将人类日常对话的语言习惯嵌入模型,并引入人类的价值偏好,使得模型输出与人类意图对齐。微调过程包括预训练、监督微调、设计奖励模型和反馈优化四个步骤[2]。
由于ChatGPT 的功能强大且具有良好的交互效果,社会各个领域都在积极探索其应用,将其出色的对话生成能力融入各种应用场景中。桑基韬等人[3]根据ChatGPT 的对话对象和定位将其应用分为四个层次:数据生成器、知识挖掘工具、模型调度员和人机交互界面。在模型调度员层面,ChatGPT作为连接模型的中介或底层模型,与其他机器学习模型协同工作,以满足用户需求。这种应用主要集中在多模态领域,如微软提出的Visual ChatGPT[4]、MM-ReAct[5]和HuggingGPT[6]等,这些模型通过让视觉模型与ChatGPT协同工作来完成视觉和语音任务。
除了ChatGPT 以外,许多类ChatGPT 的大模型也同样在自然语言处理的各个方面展现了较好的效果。LLaMA[7]是一个从7 billion 到65 billion 参数的基础语言模型集合,该模型在数以万亿计的token 上进行训练,并表明有可能完全使用公开的数据集来训练最先进的模型,而不需要求助于专有的和不可获取的数据集。清华提出了一种基于自回归空白填充的通用语言模型(general language model,GLM)[8],在整体基于Transformer 基础上做出改动,其在一些任务上的表现优于GPT3-175B。
1.2 知识图谱构建
构建知识图谱的目的是从各类结构化或非结构化数据中抽取出符合知识图谱模式的知识,并以三元组形式表示(<实体,关系,实体>或<实体,属性,属性值>)。在这过程中,涉及实体抽取和关系抽取等技术,用于从非结构化文本中提取知识。通过知识抽取,可将信息转化为可计算和理解的形式,为知识图谱的构建和应用提供基础和支持。
知识图谱的构建可采用自底向上和自顶向下两种方式。自底向上方式基于已有知识库,通过采集新事实将其添加到知识库中,逐步扩展和更新知识图谱。自顶向下方式从零开始构建新的知识图谱,收集和整理相关领域的数据,将其转化为三元组形式并存储为知识图谱。
实体抽取技术又称命名实体识别,这一技术主要涉及到基于规则、基于统计机器学习、基于深度学习三种抽取方法。当前常常使用深度学习的方法[9-12]对文本中实体进行抽取,在很多实体识别抽取的任务上都取得了较好的结果。关系抽取技术主要是根据文本中上下文确定实体之间的关系,关系抽取任务是完成信息抽取任务的基础,常见的方法是流水线学习和联合学习。流水线学习[13-15]是指在实体抽取的基础上完成关系抽取,联合学习[16]是指实体和关系在同一模型中进行抽取的方法。然而现有的知识图谱构建方法在针对小样本数据的情况下,知识抽取模型的效果不佳,通常不能很好地适用专业领域。
知识图谱的构建存在一定困难,当前常见的抽取方法中,基于模式或规则的匹配方法较为依赖人工标注的语料,因此泛化性较低;基于机器学习的方法以数据为中心,构造数据特征,但是依旧依赖大量的人工设计,而且这种方法针对大量的离散特征只能使得模型得到局部最优解,无法深挖数据中的隐藏信息;基于深度学习的方法是利用神经网络通过进行监督学习训练模型,提高模型对文本中实体、关系、事件的抽取准确率,但是这种训练模型的方式针对特定领域需要进行模型的再次训练和微调,较为浪费算力和时间,而且前文提到的构建电信诈骗领域的知识图谱中面对的各个挑战,给深度学习的模型训练和预测带来了一定难度。
1.3 现有反诈措施制定方法不足
传统的反诈措施通常依赖于人工经验和基于规则的系统,但随着诈骗手段和方式的不断演变,这些方法已经不足以满足研判的需求。传统方法对于新型诈骗手段和方式的识别能力较弱,无法及时更新数据以保持准确性和实时性。此外,传统方法容易受到主观偏见的影响和个人经验和案例的限制,只能考虑部分因素,无法全面客观地分析诈骗行为,导致研判结果的片面性和不完整性。传统方法和规则还缺乏自适应性,无法适应新型诈骗手段和方式的变化,需要手动更新和调整,增加了维护成本并降低了响应速度。
除基于人工经验和案例规则的反诈措施之外,还存在一种利用国家反诈中心APP进行诈骗风险预警劝阻。然而,使用国家反诈中心APP 也存在一些问题。使用该程序需要用户主动下载和使用,这对于特定人群存在限制和依赖性,无法全面覆盖所有用户和场景。国家反诈中心APP的预警劝阻功能也是基于预设规则和规定的,同样可能存在主观性、片面性和缺乏自适应性等问题。同时,国家反诈中心APP 的预警劝阻主要基于诈骗过程中的资金流动进行,虽然在应对电信诈骗方面起到了积极作用,但它本质上是一种响应性措施。因此,随着诈骗手段和方式不断演变和更新,仅依靠事后干预是不够的。更有效的是分析案发趋势,采取综合性的预防措施,从源头上防止诈骗行为的发生,降低公众遭受电信诈骗风险。
1.4 使用大语言模型进行图谱构建的优越性
使用大语言模型进行数据预处理与使用深度学习的模型相比,不用制定较为复杂的时间相关词语库,也不用训练模型对不同的时间表示方式进行理解,而是直接使用大模型强大的语义理解能力对时间信息进行处理,这样既能保证准确率,同时又简便了数据预处理流程。
使用大语言模型完成抽取任务与使用深度学习模型相比,具有较为明显的优势。其中最为明显的一点就是直接使用大模型已经训练好的各项能力,在通用领域知识基础上完成抽取任务,不需要使用标注数据进行模型训练,并且整个使用过程也相对较为灵活,可以通过更改问题的模版实现对抽取任务的约束;其次,与使用训练好的模型进行抽取相比,问答的这种形式为实体、事件、关系之间的联合建模提供了一种非常自然的方法;再次,多轮问答的这一形式能够展现抽取的逻辑与过程,而且随着多轮问答进程,可以逐步获得下一轮需要的实体;最后,使用大模型完成抽取任务与使用模型训练从效果上看,最大的优势在于使用时,问题查询对于想要识别的关系类别编码了重要的先验信息,这类信息能够潜在地解决现有抽取任务模型中所不能解决的远距离实体对、关系跨度重叠等问题。
2 电信诈骗案件类型影响评估方法
知识图谱的构建过程,可以简化为将非结构化的文本抽象成事实三元组的过程。针对现有方法存在的问题与不足,本文结合Li等人[16]把实体和关系联合抽取的任务当作一个多轮问答问题进行处理的思想,使用ChatGPT 作为工具,抽取文本中的各类实体、关系、事件以及各类属性属性值等,并且在抽取中融入标签,对开放领域的ChatGPT加以限制,从而达到让其选择正确标签作为标注的目的。
通过构建好的知识图谱将不同类型的案件文本内容结构化,借助知识图谱的形式存储案件内容便于统计案发时间、涉案金额、涉案事主人数等评估案件影响的实体属性,根据计算公式将不同案件类型的影响表现为抽象具体数值,以便于直观分析不同案件类型的趋势与特性。
2.1 电信诈骗相关语料的获取
构建电信诈骗领域知识图谱的基础是获取相关语料,本文构建的电信诈骗领域语料库TFCs(telecom fraud corpus),包括电信诈骗案例(telecom fraud cases,TFC)以及反诈措施(anti-telecom fraud measures,ATCM)。图1为电信诈骗语料库数据结构展示。

图1 电信诈骗语料库数据结构展示Fig.1 Data structure display of telecom fraud corpus
TFC中的语料主要来源于两方面:一方面是从裁判文书网中找到的电信诈骗有关的刑事犯罪判决书相关案例;另一方面是在公安一线工作中收集到的各类电诈案例。从公安一线中收集到的各类电诈案例主要来源于对基层所队的实地调研,案例文本语料包含了问讯笔录、简要案件经过、接出警记录等诸多文书,且各类文书对其中涉及到的个人隐私信息,如家庭住址、银行卡号、身份信息等均已进行脱敏处理。其中本文构建的电诈领域知识图谱主要使用简要案件经过进行知识抽取。
虽然裁判文书与公安一线案例两类案件事实文书都包含了电信诈骗的典型案例信息,但是两类文本的行文风格有很大不同,裁判文书中的文字内容偏向于格式化,而从公安一线收集到的电诈案例口语化较为严重,因此如果使用普通深度学习模型进行抽取任务,将面临较大挑战。
电信诈骗典型案例语料总计1 680 条,其中来自裁判文书网中的语料和公安一线工作中的语料各840条,各类语料中案发时间从2020年1月至2023年2月。并且针对TFC中的各种电信诈骗案例语料,本文采用公安部刑侦局发布的网络诈骗分类体系,将其分为仿冒身份类、购物类、利诱类、虚构险情类、日常消费类、钓鱼木马病毒类、其他新型违法类7 个大类,60 个具体手段。相应的反诈措施ATCM 也就是针对60个具体手段的防范方法以及被骗后的处置措施。图2为语料库内各类案件类型统计结果展示。
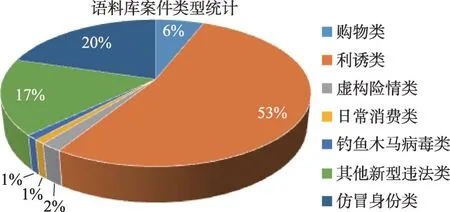
图2 语料库内案件类型统计Fig.2 Case type statistics in corpus
虽然使用ChatGPT 对文本语料进行知识抽取成本较低,不需要使用标注数据训练模型,但是为了从客观上验证ChatGPT 抽取知识的能力,从电信诈骗案例语料库中随机选取了来自裁判文书网的文本语料100 篇,来自公安一线的案例文本数据100 篇,请公安专业民警、学警进行实体、关系、事件的人工标注,作为知识抽取的标准,以便在后续实验中比较ChatGPT与深度学习模型的抽取效果。
2.2 总体方法流程
电信诈骗领域知识图谱的构建及应用包括数据预处理、各类知识抽取技术、不同案件类型影响因子与针对性反诈措施的选取等。具体评估方法如图3。

图3 电诈领域案件类型影响评估Fig.3 Assessment of case types'impact in field of telecommunications fraud
首先,构建电信诈骗领域知识图谱前需要对文本语料TFCs进行数据预处理,完成数据清洗,其目的主要是将文本中较为口语化的时间信息转化为标准时间格式,以便后续对文本中的时间信息进行抽取。
进行数据预处理后,首先确定实体类型和关系类型,并随机抽取部分文本,使用不同的问答模版利用ChatGPT 借助问答的方式对文本语料根据实际需要进行知识抽取,通过比较不同模版的抽取效果,确定抽取的问答模版。最终使用确定的问答模版对全部文本语料完成实体抽取、关系抽取、事件抽取、时间抽取等知识抽取任务。完成知识抽取后,使用图数据库Neo4j,结合抽取结果,构建电信诈骗领域的知识图谱。
在这些工作的基础上,根据使用ChatGPT 构建的电诈领域知识图谱,提出结合案发时间、涉案金额、涉案事主人数三个因素,评估不同案件类型的影响因子,刻画案发趋势和发案特征,以便有针对性地提出反制措施和预防方法。
2.3 ChatGPT在电诈领域抽取任务中的应用
2.3.1 ChatGPT进行数据预处理
由于收集到的部分电信诈骗典型案例语料文本口语化较为严重,直接对文本进行处理可能会导致效果较差,影响构建出的电信诈骗领域知识图谱的质量,在构建图谱前需要对文本数据进行预处理。
本文根据构建案件知识图谱的任务,主要是对文本中时间节点进行预处理,由于构建案件知识图谱需要识别各类案发时间、转账时间等,而文本中时常存在着“第二天”“三天后”这样的时间节点,因此需要对此类文本进行格式统一,使用ChatGPT 进行时间格式统一的模版为:“‘语料……’请把其中的所有时间信息替换成标准的年月信息,使时间信息更具体。”具体实现的结果展示如图4。

图4 文本预处理结果展示Fig.4 Display of text preprocessing results
2.3.2 ChatGPT进行知识抽取
虽然ChatGPT 在通用领域具有类人的能力,但是在电信诈骗领域,直接进行知识抽取的效果不尽如人意,因此需要根据语料进行部分限制,以确保更好利用ChatGPT的能力,更准确地对语料中的实体、关系、事件、时间进行抽取。
使用ChatGPT 完成抽取任务需要固定的模版从语料中抽取信息,但是模版的设计关系到抽取的质量,使用不同的模版ChatGPT 生成的答案也不尽相同,因为模版中包含的信息同样能够作为ChatGPT的一部分知识帮助完成信息抽取,所以应该将部分标签融入问题的模版中,下面是几种效果不同的问题模版:
模版1“‘语料……’请将上面话语抽取成构建知识图谱的信息。”
模版2“‘语料……’请根据上面的文字,判断事件类型属于仿冒身份类、购物类、利诱类、虚构险情类、日常消费类、钓鱼木马病毒类、其他新型违法类的哪一类,并且抽取出文中涉及到的各类实体、实体之间的关系等,其中抽取出来的关系应当包括但不限于亲戚关系、朋友关系、从属关系、上下级关系、假冒关系、亲密关系、同伙关系、资金流入关系、资金流出关系、利用关系、雇佣关系、客户关系、关联关系、诈骗关系。”
模版3Q1:“‘语料……’请根据上面的文字回答下面的问题。这个文本讲述的是电信诈骗还是反诈措施?”A1:“……”
Q2:“这个文本中涉及到的电信诈骗案例属于仿冒身份类、购物类、利诱类、虚构险情类、日常消费类、钓鱼木马病毒类、其他新型违法类中的哪一类案件?”A2:“……”
Q3:“请简要概括一下文本中的案件事实?”A3:“……”
Q4:“请抽取出文本中的各个实体,实体的类型应该至少包括:案发时间、案发地点、受害者、诈骗方式、交易媒介、诈骗工具、诈骗犯、涉案金额、作案手段等”A4:“……”
Q5:“请根据文本抽取出来实体之间的关系,并将头实体、关系、尾实体以表格的形式表示出来,其中关系应当包括但不限于亲戚关系、朋友关系、从属关系、上下级关系、假冒关系、亲密关系、同伙关系、资金流入关系、资金流出关系、利用关系、雇佣关系、客户关系、关联关系、诈骗关系”A5:“……”
使用多轮问答的形式完成语料的各类抽取任务时,能够较为明显看出详细的问题模版对抽取任务的准确率有较为明显的提高,这是因为ChatGPT 在人工交互方面表现虽然优秀,但是在利用其作为抽取任务的工具时却需要ChatGPT 输出固定格式的内容,因此使用固定的问题模版可以让ChatGPT 在性能和输出格式的准确性上达到最优的平衡。使用不同问题模版进行抽取的效果比较详见本文3.2节。
2.3.3 电诈领域知识图谱的存储
在使用ChatGPT 完成文本的抽取任务后,需要使用Neo4j数据库保存抽取到的事件、实体、关系、时间,形成可视化的知识图谱。Neo4j是一种基于图的数据库,它能够使用图形数据模型来存储和处理数据,并支持Cypher 语句进行知识图谱的修改查询操作。图5为构建好的部分知识图谱。
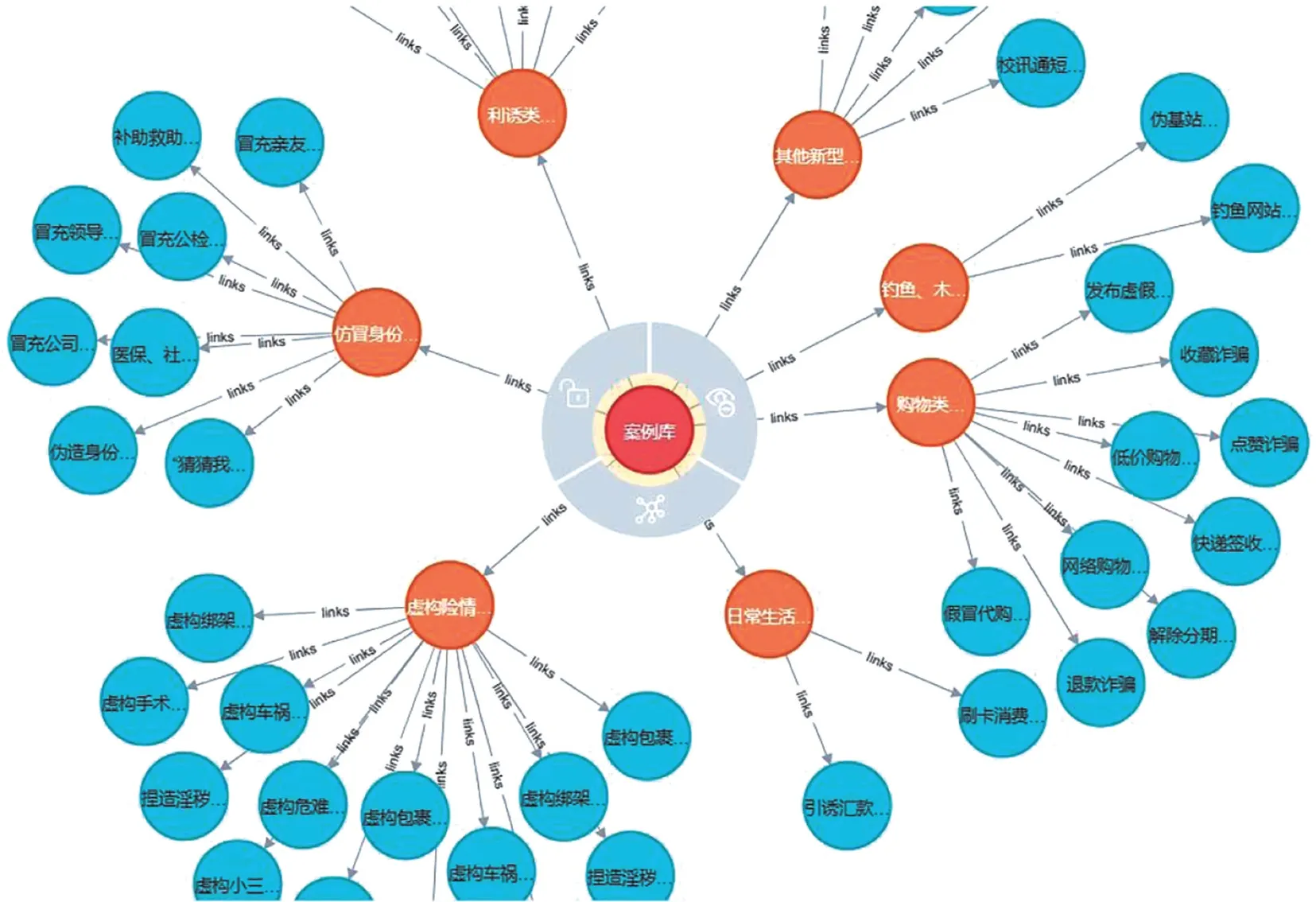
图5 构建好的部分知识图谱Fig.5 Part of constructed knowledge graph
2.4 案件类型影响因子评估方法
由于人力、物力等方面的限制,反诈需要针对最为紧要、造成经济损失最大、危害范围最广的进行着重宣传,提高人民群众的防范意识,因此需要对不同类型案件对案发趋势和发案特征进行研究。由于各类案件要素,如案发时间、涉案金额、涉案事主人数等能够较好地刻画发案特征,借助知识图谱存储结构化知识的形式可以对案件要素等实体进行快速统计分析。
首先对案件要素通过相关分析法和因素分析法进行定性分析,即分析案件要素之间是否存在关系,案发时间、涉案金额、涉案事主数量三个因素如何体现同一案件类型的案件影响与发案特征。分析可得:涉案金额越多,证明此类案件诈骗手段较为奏效;涉案事主数量越多,证明此类诈骗方式对多数群众较为通用;对案发时间这一因素来说,发案如果集中在某一特殊节点证明诈骗方式与特殊时间节点或特殊事件有关,如果没有明显时间特征可能是诈骗手段的成功率受时间影响较小。
其次将各类案件要素对案发趋势和发案特征的作用具象化,抽象为具体权重数值。借助电信诈骗知识图谱,分析案件类型与案件的各类实体,统计涉案金额、涉案事主人数、案发时间等各种案件要素,并且邀请反诈专家和警务人员以打分的方式为案件要素对案件影响的贡献大小进行合理的赋值,将案件要素对案件影响抽象为具体的权重。
随后根据抽象的各类案件要素权重数值进行分析拟合,研究权重变化的客观规律,确定案件要素对案发趋势发案特征的影响因子计算方法,并对拟合的函数和客观事实进行一致性检验。
对专家打分权重进行极大似然估计和归一化操作进行拟合,得出拟合函数展示权重变化趋势如下:
其中,ω是某一类型案件的综合影响因子,n代表此案件类型的所有案件,ω1是涉案事主人数分因子,N代表涉案人数,单位是“十人”,ω2是涉案金额分因子,A代表涉案金额,单位是“百万元”,ω3是案发时间分因子,Δti是指某一案件案发时间至指定时间的时间差,单位为“年”,指定时间一般选择为半年,β、λ是计算影响因子的超参数,一般设为1。
通过分析可得影响因子计算函数拟合效果较好,能够展示出基本的变化趋势:当涉案金额与涉案事主人数越多时,影响因子越大,证明越应当被重视,可是当金额和事主人数达到一定程度时,影响因子逐渐增长缓慢,且恒小于1,这样能在一定程度减弱异常数据对评估案件的影响;对案发时间这一因素来说,当案发时间越近时,影响因子越大,就某一具体案件类型而言,在半年时间范围内,距离统计时间节点越近发生案件越多,影响因子越大,如果发生案件较多,且发案与时间关系不大,则其影响因子会收敛于平均值0.56,因为这一数值是影响因子计算公式在(0,0.5)这一区间的定积分平均值。
3 实验结果展示与分析
计算ChatGPT 抽取到的结果和当前抽取效果较好的无监督知识抽取模型的准确率、召回率、调和平均值F1,并对这些结果进行比较,分析结果。表1为数据集标注后的实体、关系数量统计展示。

表1 数据集标注结果统计Table 1 Statistics of dataset labeling result
3.1 评价标准
在各类知识抽取过程中,被广泛使用的评价指标有准确率、召回率以及调和平均值F1,知识抽取结果分类的正确与否共有四种组合,分别是:预测为正例的正样本TP,预测为正例的负样本FP,预测为负例的正样本FN,预测为负例的负样本TN,这四种关系能够用混淆矩阵展示,表2为混淆矩阵展示。
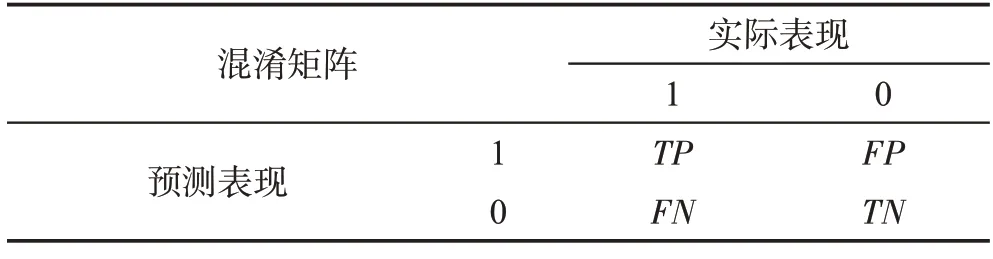
表2 混淆矩阵Table 2 Confusion matrix
准确率是指在预测为正例的样本中,正样本所占比例,计算公式如下:
召回率是指在正样本中,预测为正例所占的比例,计算公式如下:
F1 是指用来衡量二分类模型精度的一种方法,这个指标综合了召回率和准确率,并且可以设置准确率和召回率所占的比重,以平衡当准确率和召回率冲突时的模型衡量方法,具体计算方法如下:
3.2 ChatGPT抽取任务评估与不同模版选择
在前文中提到了使用ChatGPT 作为知识抽取工具时的3种不同问题模版,分别是:模版1粗略问答;模版2单轮详细问答;模版3多轮详细问答。虽然可以直观感受出3 个模版的抽取效果,但是严谨起见,仍对不同模版的抽取效果进行了量化比较,具体结果见表3。
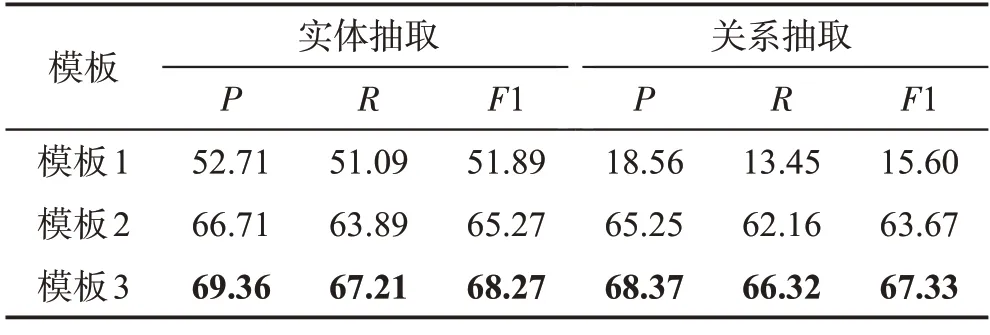
表3 不同模板抽取结果统计Table 3 Statistics of different template extraction results 单位:%
通过比较不同模版抽取文本内容的准确率、召回率以及调和平均值,能够明显看出,模版2、3 与模版1 相比,实体抽取F1 提升了超过14 个百分点,关系抽取F1 提升了超过48 个百分点,效果有显著提升,这是因为在模版中增加了抽取的相关信息,给各类抽取任务提供了抽取范式,同时约束了抽取的结果,避免了同义词不易归一化的问题。关系抽取之所以能够出现明显提升,主要是因为对14 种关系类型进行了定义,在模版2、3 中对回答的内容进行限制。根据对模版2 抽取结果和模版3 抽取结果的比较,可以看出使用多轮问答的形式具有一定优势,主要原因是在多轮问答中前面问题的答案可以作为下一个问题回答的提示,强化了回答逻辑,因此在接下来的比较中,使用模版3 抽取知识的准确率进行比较。
3.3 实体抽取结果展示
因为电信诈骗领域专业性较强,标注数据较少,而且本文没有使用标注数据训练模型,所以比较模型主要选取部分无监督模型和远程监督模型对文本进行知识抽取,以比较各类方法的抽取效果。但是针对一些较为常见的非小样本任务,如人名识别、地点识别等,为进一步体现使用ChatGPT的先进性,使用较为成熟的实体抽取作为比较模型。
3.3.1 实体抽取基线模型
在实体抽取的子任务中,由于本文设计的是利用ChatGPT 完成抽取命名实体,文本中的命名实体主要包括诈骗犯、受害者、案发地点、涉案金额、交易媒介等,其中诈骗犯、受害者都是人名,案发地点是地名,因此可以使用较为成熟的中文人名、地名识别抽取模型作为对比模型,对ChatGPT而言,虽然抽取结果中展示了实体类型,即“诈骗犯:张某”这种数据类型,但是在计算识别准确率时,不对诈骗犯和受害者两种类型进行区分,统一计算是否识别正确人名,而具体人名对应的是诈骗犯还是受害者可以通过关系抽取中的准确率得出。
在比较抽取效果时,本文选择了在命名实体识别中表现良好的模型,使用部分标注好的TFC 电信诈骗案例文本对已训练好的模型进行微调,使各类模型在本文的数据集中能展现较好效果。参与比较的传统深度学习模型具体包括:
(1)Bi-LSTM-CRF模型[17]:此模型结合LSTM(long short-term memory networks)和CRF(conditional random fields)的优点,既能够学习到样本到标注之间的映射关系,同时还注意到了标注之间的关系,这一模型通过开源数据集进行训练,以预测文本中文字对应的标签,再根据标签提取出文本中实体,这一模型在诸多数据集中都取得了较好的效果,在很多命名实体识别的研究中,这一模型都被用作基线模型。
(2)BERT-CRF模型[18]:此模型与Bi-LSTM-CRF原理类似,使用了BERT(bidirectional encoder representation from transformers)作为训练CRF的发射矩阵,在命名实体识别的相关研究中,都有不俗的表现。
(3)FGN(fusion glyph network)模型[19]:这一模型融合字形网络用于中文命名实体识别,并通过融合机制添加额外的交互信息,使用汉字内部的信息辅助进行命名实体识别的任务,此模型在诸多命名实体识别数据集中都取得了很好的效果。
(4)LEMON(lexicon memory)模型[20]:这一模型基于片段对中文命名实体进行识别,增加了基于字典的记忆,并将汉字和单词的特征结合起来,更好地表示特征,此方法在公开数据集上也都取得了较好的效果。
(5)MECT(multi-metadata embedding based crosstransformer)模型[21]:这一模型基于多元数据,利用汉字的结构信息,更好地捕捉汉字的语义信息,来提高中文命名实体识别的性能。
除了传统的深度学习模型,还有许多类ChatGPT大语言模型,在一些任务中也表现出了较好的性能,因此本文也针对一些类ChatGPT 模型进行知识抽取的效果比较,对比的大语言模型包括:
(1)华为盘古NLP大模型[22]:华为盘古的NLP大模型是超千亿参数的中文预训练大模型,并且其更注重针对中文语言的优化,兼顾自然语言的理解与生成能力,在多项任务中表现优秀。
(2)阿里通义千问大模型:阿里的通义大模型具有强大的语言理解能力,并融合多模态知识,从而提供高效的生成能力。
为了避免因不同问答模版产生的抽取效果差异,对大模型的问答均采用模版3,在模版中尽可能引导模型生成正确答案。
3.3.2 结果展示
使用对比模型和使用ChatGPT 作为工具抽取实体的效果如表4。

表4 各类实体抽取方法结果展示Table 4 Display of results of various entity extraction methods 单位:%
通过将ChatGPT 作为工具抽取实体的效果与较为成熟、效果较好的深度学习模型进行比较,发现效果近似,在公安一线电信诈骗案件中,ChatGPT 的抽取效果略好于使用深度学习模型进行抽取的效果,F1 的值高了1.67 个百分点,这可能是因为在公安一线中收集到的电信诈骗案例口语化严重,深度学习模型训练数据接受的是固定格式的文本,书面用语较多,对口语化文本不能完全做到普适,但是ChatGPT的训练数据较广,不拘泥于表达方式,因此在收集到的一线案例文本中抽取结果没有ChatGPT 好。其他如盘古、通义千问这类大语言模型在未经训练的情况下完成抽取任务虽然也有较好的表现,但是效果和ChatGPT相比,仍存在一定不足:在裁判文书网案例中,华为盘古模型的效果比ChatGPT 差2.24 个百分点,阿里通义千问模型的效果比ChatGPT 差1.85个百分点;在一线实战案例中,华为盘古模型的效果比ChatGPT 差3.59 个百分点,通义千问的效果比ChatGPT 差1.58 个百分点。因此就实体抽取任务来看,选择ChatGPT进行抽取效果较好。
3.4 关系抽取结果展示
3.4.1 关系抽取基线模型
(1)GraphRel 模型[23]:这一模型是一种端到端的关系提取模型,使用图卷积网络(graph convolutional networks,GCN)联合学习命名实体和关系,其构建了一个线性从属结构提取文本的顺序特征和区域特征。
(2)CopyRL 模型[24]:这一模型针对其他模型中没有考虑句子中关系事实提取顺序的问题,将强化学习应用到一个序列到序列的模型中,取得了较好的关系抽取效果。
(3)CASREL模型[25]:即层叠式指针网络(CASREL)模型,它主要解决重叠三元组问题,即同一句子中的多个关系三元组共享相同的实体。其引入了一种新的视角来重新审视关系三元组提取任务,并提出了一种新的级联二进制标记框架(CASREL)。不将关系视为离散标签,而是将关系建模为将主题映射到句子中的对象的函数,实验表明,此模型在关系抽取中也取得了较好的效果。
为了减少训练数据集对模型效果的影响,可以使用部分标注数据对模型进行微调,以适配除了传统人工智能深度学习模型,本文还对华为盘古、阿里通义千问两种大语言模型的关系抽取效果进行测试,并与ChatGPT的抽取效果进行比对。
3.4.2 结果展示
使用对比模型和使用ChatGPT 作为工具抽取关系的效果如表5。

表5 各类关系抽取方法结果展示Table 5 Display of results of various relationship extraction methods 单位:%
根据表5中数据进行分析,可以直观看出大语言模型在关系抽取任务中效果好于深度学习模型,这主要是由于在使用大语言模型进行抽取时,问题模版中约束了可能出现的关系类型,另外由于小样本的限制,即使使用部分标注数据对深度学习模型进行了微调,模型仍然无法在电信诈骗案例文本语料中表现完整的效果;就相同模型的抽取效果而言,对裁判文书网案例文本的抽取好于对一线实战案例文本抽取的效果,主要是因为裁判文书网文本的语言较为规范,隐式关系较少;在大语言模型中,ChatGPT的抽取效果与其他两种模型相比,F1 值均高出超过5个百分点。
综合各类深度学习模型、大语言模型、ChatGPT进行实体抽取和关系抽取的效果,可以得出使用ChatGPT构建知识图谱的精度较高的结论,而且使用ChatGPT构建知识图谱成本较低,优越性明显。
3.5 影响因子评估
在确定好各类案件类型的影响因子计算方式之后,需要证明其可行性和准确性。本文对七类电信诈骗的影响因子根据收集到的资料进行了计算,并绘制了影响因子变化折线图,对2020 年至2023 年的不同诈骗类型案件以半年为单位时间,从2020 年1月起进行统计分析,金额影响因子和事主人数影响因子的参数β、λ均选取为1,统计各类影响因子并进行展示。图6~图9 分别展示了各类型案件各分影响因子和综合影响因子的时间变化趋势,图中横坐标为时间节点,2020.1 代表2020 年1 月1 日,2020.6代表2020年6月30日,纵坐标为影响因子大小。

图6 各类型案件案发时间影响因子随时间变化趋势Fig.6 Time-varying trend of time of occurrence of various types of cases

图7 各类型案件涉案金额影响因子随时间变化趋势Fig.7 Time-varying trend of amount involved in various types of cases

图8 各类型案件涉案事主人数影响因子随时间变化趋势Fig.8 Time-varying trend of the number of victims involved in various types of cases

图9 各类型案件综合影响因子随时间变化趋势Fig.9 Time-varying trend of comprehensive impact factors of various types of cases
根据影响因子的变化趋势图进行分析,可以准确了解电信诈骗各个诈骗手段的变化与发展。
根据各类影响因子及其综合分析,利诱类案件的案发时间影响因子集中在0.56 附近,这说明在广泛样本下,利诱类案件几乎持续发生,而且利诱类的涉案金额和涉案事主人数影响因子持续保持极高的水平,均接近1。
购物类案件的涉案金额和涉案事主人数影响因子呈现类似于弧形的形状,在2020 年初和2022 年末呈现较高的影响因子,出现这类现象的主要原因是在2020 年初和2022 年末由于新冠疫情,出现大量虚假贩卖口罩、防护服等防护措施的购物类诈骗案件,在其余时间购物类诈骗发生较少。
仿冒身份类案件从涉案金额和涉案事主人数两方面看,在2021年年中前,涉案金额和涉案事主相对较多,但是自2021年年中后,随着公安民警的反诈宣传,民众对于此类诈骗方式套路的熟悉,防范意识的提高,此类诈骗手段较难奏效,因此涉案金额和涉案事主人数也同样有所下降;从案发时间这一因素分析,可以发现此类案件的案发时间这一因素具有周期规律性,分析其内在原因为:“6.18”与“11.11”这两个购物时间节点,是冒充为客服、快递服务人员等购物相关身份的高发时期,由于“6.18”距离统计截止时间6月30日比“11.11”距离统计截止时间1月1日近,案件时间影响因子出现前半年比后半年高,但是都高于定积分平均值0.56的情况。
虚构险情类、钓鱼木马类、日常消费类三种案件类型,由于案件样本较少,根据案发时间的影响因子可以看出波动较大,数据随机性较强。从涉案金额和涉案事主人数两个因素分析,虚构险情类上当受骗的事主人数较多,结合实际分析,此类犯罪手段针对的多是老年人,利用老年人爱护孩子的心理实施诈骗,钓鱼木马类的涉案事主虽然人数较少,但是针对的大部分是公司高管、企业主等,因此涉案金额较多。
根据影响因子分析,可以看出其他新型违法类在2021 年初时,在涉案金额和涉案事主人数两方面出现了较为明显的增长,而且案发时间影响因子也从原来的变化较大收敛在0.56 附近。究其原因,主要是因为自2021年起,裸聊诈骗案件频发,给人民群众的财产安全带来了极大的威胁。
根据各类影响因子综合分析,可以制定针对性的反诈措施,例如针对高发频繁,给人民群众带来极大经济损失的利诱类案件,可以加大宣传力度,做好反诈措施;针对老年人易上当受骗的虚构险情类诈骗方式,可以对其进行定点反诈宣传,防患于未然;针对各类精英人士经常中招的钓鱼木马类诈骗方式,可以通过对其宣传常见木马的传播方式进行诈骗方式的根源阻断;在出现紧俏资源短缺时,需要对人民群众针对性地进行购物类诈骗的反诈宣传,提醒群众们购买紧俏物品时认准正式资质,不贪图小便宜,谨防电信诈骗。综合来看,需要针对当前案发较多,造成损失较大的利诱类与其他新型违法类电信诈骗进行常态化反诈宣传,及时关注重点人群的资金流动与社交信息;针对其他诈骗类型,应当注意其发案的规律性,及时预计犯罪分子的犯罪手段,提出反制防范措施。
4 总结与展望
4.1 总结
本文通过使用ChatGPT 的强大语言理解能力,处理电信诈骗案件的相关文本,完成数据预处理、电信诈骗领域知识图谱构建等工作,并根据构建的电信诈骗领域案件图谱,对各类诈骗方式进行发案时间、涉案金额、涉案事主人数等因素的综合研判,以便做出针对性的反诈宣传决策。
本文提出的使用ChatGPT 进行数据预处理和知识抽取以完成知识图谱的构建方法,与传统的训练深度学习模型完成构建任务相比,不需要标注训练数据,减少了因专业领域语料不足而训练深度学习模型不够理想的问题,而且对语料较少的电信诈骗领域而言,使用通用语言模型部署更为快速,不需要利用深度学习的方法对模型进行训练,避免了耗费大量的时间和资源,为及时研判电信诈骗案件的趋势,针对性提出反诈措施,做好群众反诈工作提供了可能。而且使用ChatGPT 完成少样本数量下的各类文字处理与理解工作给解决公安等特殊垂直领域需求提供了一种可能的解决方法。
另外,本文还针对当前电信诈骗案件高发的形式,提出根据案发时间、涉案金额、涉案事主人数三个因素研判反诈策略的方法,提出影响因子以判断不同案件类型的发案趋势,根据影响因子可以针对性地提出反诈措施,以实现对资源的分配优化,提高反诈工作效率,提高公众对较为广泛诈骗类型的认知和防范意识。
4.2 展望
本文同样存在一些局限,在使用ChatGPT 完成数据预处理、构建知识图谱的过程中,虽然使用了不同的模版进行尝试,但是离完全利用通用语言模型的强大语言能力仍然存在一定距离;另一方面,使用ChatGPT仍然依赖于输入的数据,针对专业的电信诈骗文本领域而言,抽取知识的准确率依旧受其本身语料的质量、覆盖范围和相关性限制。而且使用ChatGPT完成知识抽取,生成的都是自由形式的自然语言,缺乏结构化的固定文本,即使对输出格式在问题模版中做了要求,提取到的知识也仍存在部分冗余,需要再次进行清洗和处理。
而且使用ChatGPT 处理文本还存在着一些原生性风险。由于训练数据的限制以及实现ChatGPT 的细节并未公开,使用ChatGPT 处理文本会导致潜在偏见与倾向性。为了解决这类问题,可以在后续研究中建立多样化的训练数据,引入人工干预和监督机制,并加强审查机制,以确保根据案件文本内容生成更为准确的知识图谱,避免因偏见对犯罪的判断产生影响。另外,使用ChatGPT处理数据时,即使已经对案例文本数据进行了脱密处理,但是仍然存在着数据泄露的风险与可能。在今后的研究中,可以在数据脱密处理以及模型本地部署等方面进行研究,以减少数据泄露的风险。
除了在构建知识图谱中存在局限性,在利用知识图谱对电信诈骗不同类型案件进行分析研判时,本文方法也同样存在一定的局限性,由于对案件的相关分析受限于语料的质量与数据的体量,导致分析影响因子变化趋势仅能得出部分广泛性结论,针对具体地点、具体时间节点的不同案件影响力分析仍存在不足,而且在得到案件影响力的变化趋势之后,仍然需要进行人为分析,反诈决策的研判与分析仍存在一定主观因素。因此在后续的研究中,可以增强分析数据的深度,对某一具体地点的案件文本进行分析处理,深入挖掘电信诈骗的犯罪手段变化趋势,更具有针对性地提出电信诈骗防范预防措施;同时也可以扩大分析数据的广度,发现更广泛、更具有代表性的犯罪方式变化趋势,尽早预测犯罪分子的犯罪手段,提前进行反制。除此之外,还可以对分析数据的方法进行完善,当前的分析仍是基于案件影响力的评估进行人工分析,在后续研究中,可以在案件影响力评估的基础上自动分析案件变化趋势,利用智能算法发现隐藏规律,更好地打击犯罪。
猜你喜欢
今日农业(2021年12期)2021-11-28
今日农业(2021年5期)2021-11-27
文萃报·周二版(2021年22期)2021-07-19
人民周刊(2021年11期)2021-07-09
海外华文教育(2016年1期)2017-01-20
中国防伪报道(2016年10期)2016-11-21
中国防伪报道(2016年10期)2016-11-21
公民与法治(2016年15期)2016-05-17
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
