
面向医疗问答系统的大语言模型命名实体识别方法
2023-10-29 04:20孙晓虎党佳怡赵海燕
计算机与生活 2023年10期
杨 波,孙晓虎,党佳怡,赵海燕,金 芝+
1.北京林业大学 信息学院,北京 100083
2.国家林业和草原局林业智能信息处理工程技术研究中心,北京 100083
3.北京大学 计算机学院,北京 100871
4.高可信软件技术教育部重点实验室(北京大学),北京 100871
近年来,医疗领域的信息化建设不断推进,各种电子病历系统、医学影像系统、药物信息系统等医疗信息管理系统层出不穷。而在这些系统中,医疗命名实体识别(medical named entity recognition,MNER)是非常重要的一环。MNER 是指通过对医学文本进行分析,自动识别出其中涉及到的疾病、药物、治疗方式等医学实体,并将其分类和标注,以便更好地管理和利用这些数据。
医疗领域的命名实体识别方法主要经历了3 个阶段,分别是基于规则的方法、基于传统机器学习的方法和基于深度学习的方法。基于规则的方法首先需要制作全面涵盖医疗领域的中文医学名词词典,通过与之相适应的匹配算法完成医疗命名实体识别,词典的规模和质量是影响识别结果的关键因素。例如:杨锦锋等人[1]在医生的参与和指导下,构建了规模较大、质量较高的标注语料库;Wang等人[2]建立的肿瘤相关的语料库对识别肿瘤相关的信息有明显的效果。基于规则的方法还需要对待处理的文本进行分析并构建规则模板,之后在同类型文本上使用特定规则模板,通过模式匹配的方法实现命名实体识别。例如:Quimbaya等人[3]提出了一种基于规则和字典的医疗命名实体识别方法;Gorinski 等人[4]通过对比实验证明基于规则的方法可以非常有效地进行医疗实体识别并进一步提高机器学习方法的准确率。
基于传统机器学习的方法在医疗领域实体识别的应用较为广泛。例如:Zhang 等人[5]提出了一种无监督的生物医学命名实体的方法,在该领域取得了不错的效果;McCallum等人[6]提出了一种基于条件随机场的命名实体识别方法。
但是,传统的基于规则或模板的MNER 方法需要专业人员创建大量的模板和规则,不仅耗费大量时间和人力,而且没有办法解决医疗领域知识不断迅速更新的问题。
近年来,随着深度学习技术的不断发展,以深度学习为基础的MNER算法越来越受到研究人员的关注。例如:Santos等人[7]利用CNN(convolutional neural network)来捕获词序列的语义信息,识别出医疗命名实体;Xu 等人[8]提出一种将预训练语言模型BERT(bidirectional encoder representations from transformers)和双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)、条件随机场(conditional random fields,CRF)模型相结合应用于生物命名实体识别的模型;Su等人[9]利用全局归一化的思路来进行命名实体识别,可以无差别地识别嵌套实体和非嵌套实体。
但是,深度学习方法通常使用固定大小的窗口或卷积核来处理文本,这就要求处理的文本是连续的,限制了其处理非连续和嵌套实体的能力。此外,深度学习模型通常需要大量的标注数据来训练,以便有效地学习实体识别任务,而在医疗领域因大规模标注数据非常昂贵和耗时,标注数据的稀缺性可能限制了深度学习方法的性能。
例如:图1中基于传统机器学习技术的实体识别方法对于“真菌性和过敏性肺炎应该如何治疗?”这一问题只能识别出来“过敏性肺炎”,对于“体温较前下降了很多应该如何治疗?”这一问题识别不出实体。
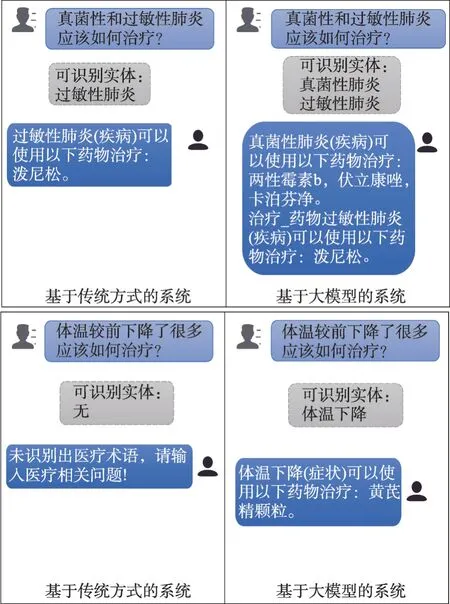
图1 传统机器学习与大语言模型的识别效果对比Fig.1 Comparison of recognition effects between traditional machine learning and large language models
但是,大型语言模型能够捕捉文本中的上下文信息,并通过上下文来推断实体的边界和类型,这有助于识别出文本中的非连续实体。并且ChatGPT(chat generative pre-trained transformer)可以进行迁移学习,从其他领域的文本中学习到的知识可能有助于处理医疗文本中的实体。通过实验发现,大语言模型可以识别出医疗文本的嵌套实体和非连续实体,并将它们转化为规范化的医疗实体。为此,本文提出了一种基于大语言模型进行医疗命名实体识别的方法,并与传统机器学习方法进行比较。使用大语言模型ChatGPT,提出了一种输入的格式,包括要识别的实体类型列表、具体的需求指令和规定输出格式的指令等。将实体识别的结果应用到医疗问答系统中的知识图谱,能够得到最终的医疗问题的答案。
本文的主要贡献包括如下三点:
(1)提出了一种基于大语言模型的实体识别方法(named entity recognition method of large language model,NERLLM),该方法首先需要对数据集进行预处理,按照规定的指令格式,将问题输入到ChatGPT中,然后将输出的内容进行分类,根据不同的分类进行分析。
(2)将实体识别的结果作为输入放入到医疗问答系统中,利用医疗问答系统中的知识图谱,来进行推理分析,从而获得相应问题的答案。
(3)在三个典型的医疗数据集上进行了实验,研究结果表明,基于大语言模型的MNER 方法在医学文本中具有较高的准确性和泛化能力,并且具有识别非连续实体和嵌套实体的能力,能够较好地应用在医疗问答系统中。
1 相关工作
命名实体识别方法主要包括基于规则的方法、基于传统的机器学习方法和基于深度学习的方法。
1.1 基于规则的方法
基于规则的方法需要对待处理的医疗文本进行分析并建立规则模板。如Kim 等人[10]提出在对话输入中使用Brill 规则推理方法,该工作实现了一个基于Brill 的词性标注器自动生成方法;Hanisch 等人[11]提出了ProMiner,在生物医学领域,它通过采用规则模板和近义词词典来识别生物医学文本中的各种实体;Chen等人[12]在传统的机器学习模型外,附加规则模板来抽取模型不能识别的实体;Gorinski 等人[4]通过对比实验证明基于规则的方法可以非常有效地进行医疗实体识别,并进一步提高机器学习方法的准确率。
基于规则的方法优点是便于维护,缺点是需要大量人力和时间成本投入,规则的可移植性也较差。
1.2 基于传统机器学习的方法
利用传统机器学习方法,可以对实体进行识别,其中主要包括有监督的实体识别和无监督的实体识别。
在有监督的学习过程中,实体的识别问题被转换成了序列标注或者多类别分类问题。给出了带标注的数据样本,分别设计了不同特征来代表各个训练的样本。在此基础上,采用机器学习方法对未知数据进行建模,并对其进行特征提取。特征向量表示是对文本的抽象,其中单词由一个或多个布尔值、数值或标称值[13-14]表示。共有三大类特征:第一类是单词级特征,具体包括大小写[15]、形态学[16]、词性标签[17];第二类是列表查找特征[18-21],具体包括维基百科地名录和数据库地名录;第三类是文档和语料库特征[22-25],具体包括本地语法和多次出现。这三大类特征已被广泛用于各种基于监督学习的NER系统。
基于上述三类特征,人们提出了大量的机器学习方法与命名实体识别任务进行结合,包括隐马尔可夫模型(hidden Markov model,HMM)[26]、决策树[27]、最大熵模型[28]、支持向量机(support vector machine,SVM)[29]和条件随机场[30]。Bikel等人[31-32]提出了Identi-Finder 系统,该系统首次将HMM 应用在命名实体识别任务上。McNamee 等人[33]使用大量特征来训练SVM分类器,从而进行实体的抽取。由于基于SVM的命名实体识别方法不能够考虑上下文信息,Mc-Callum等人[6]将CRF应用到命名实体识别中,取得了显著的效果。在此基础上,Krishnan 等人[25]将两个CRF 应用到命名实体识别中,他们将第一个CRF 的输出利用在第二个CRF 中。通过调研表明,CRF 已经被广泛应用于命名实体识别任务中,并且取得了很好的结果。
无监督的实体识别方法主要用到的是聚类[13]。该类方法根据上下文相似度,从群集中抽取出一个命名实体。该方法的核心思路是利用词源、词形以及在大规模语料库上的统计信息,对命名实体进行推理。Collins 等人[34]首先使用两个分类器识别实体的边界,然后利用一个分类器进行实体类型的识别,提供了一种实体识别的思路。同样,Etzioni等人[35]通过人工编写规则模板从Web 中进行无监督的、独立于领域和面向可伸缩的实体自动化匹配。
Nadeau 等人[36]提出一种无监督方法,可应用于地名录的构建和命名实体消歧。此外,Zhang 等人[5]根据生物医学领域相应实体类型的句法和词法特征提出了一种无监督的方法。这两种模型将监督学习替代为术语、语料库统计和浅层句法知识。实验结果表明,这两种无监督学习方法在两个主流生物医学数据集上具有较高的识别效率和普适性。
1.3 基于深度学习的方法
基于深度学习的方法利用大规模高质量标注过的语料进行模型训练,再利用模型完成对命名实体的识别,基于深度学习的方法在医疗命名实体识别上相较于基于词典的方法和基于规则的方法表现出较好的实用性和可移植性。它不仅可以较好地解决中文电子病历文本的非规范性和专业性造成的命名实体识别困难的问题,而且在特殊医疗命名实体识别上表现优异。
随着深度学习技术的发展,由于其在命名实体识别任务上的优异表现,迅速成为研究热点。从最初以长短期记忆网络(long short-term memory,LSTM)为代表的单向循环神经网络(recurrent neural network,RNN)到以BiLSTM为代表的双向RNN网络,从基本的卷积神经网络(CNN)到其变种迭代膨胀卷积(iterated dilated convolution neural network,IDCNN)[37],从类似CRF 这样的单一模型到诸如BiLSTM+CRF[8]的多模型融合,人工参与工作量不断减少,识别精度也不断提高。Santos 等人[7]利用CNN 来捕获词序列的语义信息,识别出医疗命名实体。
预训练模型和迁移学习方法引入后,模型对语义的理解更进一步,首先在语料充足的领域上通过监督学习训练出一个通用的预训练模型,然后迁移到像实体识别这样的特定领域的语言任务上。比如从Word2vec 到GloVE(global vectors for word representation),再到BiLSTM、BERT 以及以RoBERTa(robustly optimized BERT pretraining approach)[38]为代表的BERTology 系列,这些预训练模型依次出现,在优化升级过程中不断提高了命名实体识别的精度。Wang等人[39]首先使用RoBERTa-wwm(RoBERTawhole word masking)进行编码,然后利用CNN 提取汉字特征,最后将多语义特征输入到BiLSTM+CRF中从而实现实体识别。Hu等人[40]提出了一种基于协同决策策略的新型深度医疗命名实体识别方法,该方法可以识别在线健康专家问答环境中的标准和非标准医疗实体。Hofer等人[41]采用XLM-RoBERTa模型进行命名实体识别,并对英文数据的命名实体识别跨语言模型进行了微调。
深度学习方法通常使用固定大小的窗口或卷积核来处理文本,这限制了其处理非连续和嵌套实体的能力。并且,深度学习模型通常需要大量的标注数据进行模型的训练,而在医疗领域标注数据的稀缺性会限制深度学习方法的性能。随着大语言模型的出现,有效解决了标注数据不足的情况,因为大型语言模型是由大量的数据训练而成,能够捕捉文本中的上下文信息,并通过上下文来推断实体的边界和类型,这有助于识别出文本中的命名实体。目前有一些基于大语言模型做命名实体识别的研究,例如:Zheng等人[42]将命名实体识别任务分解为实体跨度提取和实体类型确定两个子任务,然后利用大语言模型逐步解决问题。Wei 等人[43]将零样本信息提取任务转化为具有两阶段框架的多轮问答问题,借助ChatGPT的强大功能,在关系抽取、命名实体识别和时间抽取这三个信息提取任务上广泛评估原文提出的框架方法。Polak 等人[44]提出了ChatExtract,该方法由一组经过设计的提示组成,这些提示既可以识别带有数据的句子,提取数据,又可以通过一系列后续问题确保数据的正确性。Wang 等人[45]提出了GPT-NER,该方法首先将序列标记任务转换为大语言模型可以轻松完成的生成任务,然后提出了一种自我验证策略,通过向大语言模型询问自己识别出的实体是否属于标记的实体标签,有效地解决大语言模型的“幻觉”问题。
2 方法
系统整体框架如图2所示,该系统包括数据预处理、实体识别、意图识别、知识图谱查询和回答生成五部分。用户的输入文本为整个系统的输入,经过系统的五个部分处理,最后以系统生成的回答作为输出。
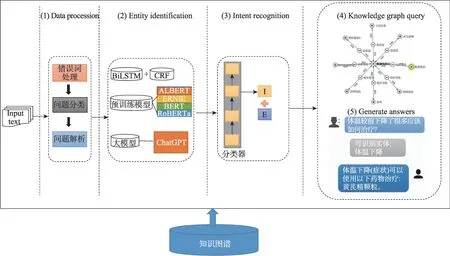
图2 系统框架图Fig.2 System framework diagram
2.1 数据预处理
数据预处理主要完成对输入数据的处理。在问答系统的日常使用中,用户有时候因为手误或者相关知识的欠缺,输入的文本可能会出现错误,例如“小儿氨酚那敏颗立”其中“颗粒”被误写。针对这种情况,需要进行错误词的处理。处理后的语句,系统会将其进行问题分类。这一工作是为了方便第三部分的意图识别和槽位填充,然后对识别出来的问题进行解析。
其中错误词处理,在实验训练阶段,使用人工处理的方式,主要方式是人工针对数据集中的错误词进行改正。在系统中,增加了的相应的错误词表对用户输入进行更改。
2.2 命名实体识别
命名实体识别主要实现对输入文本的实体抽取。在自然语言处理中,实体识别指的是将文本中的特定实体(如人名、地名、组织机构名等)标记或识别出来。对于医疗问答系统,需要识别出用户输入文本中的疾病、症状和药物等实体。命名实体识别可以帮助更好地理解文本,并且可以用于后续的语句意图识别和方便进行链接知识图谱的查询。
大语言模型可以较好地应用于实体识别任务。由于大语言模型通常使用的是预训练加微调的方式进行训练,可以充分利用大规模的文本数据对实体识别任务进行建模。
在具体实现上,一种常见的方法是将实体识别任务看作一种序列标注(sequence labeling)问题,将每个输入的单词作为模型的输入,并输出相应的实体类别。大语言模型通常采用Transformer 架构,通过堆叠多层Transformer 编码器来学习输入句子中各个位置之间的关系,从而更好地捕捉上下文信息。同时,还可以引入自注意力机制(self-attention),使得模型能够更好地处理长文本输入和序列中的依赖关系。
2.2.1 输入与输出
输入是一个由N个字组成的序列,也叫作“符号”。结果就是一个词,它最有可能被放在一个词的后面。以GPT模式为基础的各种应用,例如对白、事例、事例产生等,都采用了这个输入-输出模式:先给出一系列的输入,然后得出下一个词。
在NERLLM里,给定ChatGPT一些提示,让其按照提示返回答案,在具体的实验中,规定提示的模板分为以下四部分:
1.待识别的医疗文本。
2.要识别的实体类型列表。
3.具体的需求指令。
4.规定输出格式的指令。
例如,待识别的医疗文本为“流行性感冒应该吃什么药”,规定输入为:
给定的句子为:“流行性感冒应该吃什么药”
给定的实体列表为[疾病,症状,治疗方式,药物,检查]
在这个句子中,可能包含了哪些实体和实体类型
按照字典的形式给出,两个key 值分别是“实体”和“实体类型”
由于ChatGPT 具有一定的随机性,即使给出返回格式为字典的指令,它也不像机器学习方法能够返回规范化的结果,经过统计,ChatGPT 会返回8 种格式的结果,如表1所示。

表1 ChatGPT的返回格式Table 1 Return format of ChatGPT
针对ChatGPT 返回结果不规范的问题,将返回的结果重新输入到ChatGPT,并且再次给出更加具体的规定返回格式的指令,该指令如下所示:
返回json格式,例如:[{'实体':'','实体类型':''},{'实体':'','实体类型':''}]
具体的ChatGPT输入例子如下所示:
实体:流行性感冒,感冒
实体类型:疾病,疾病
返回json格式,例如:[{'实体':'','实体类型':''},{'实体':'','实体类型':''}]
2.2.2 编码和向量化
GPT 的第一个步骤就是把所有的字集合起来,形成一个词汇库,这样就可以给每一个字赋值。最后,可以把每一个字转化成一个单独的点编码向量,在这个向量中,只有指数i的维数是1,其他的维数都是0。ChatGPT是利用字节对编码(byte pair encoding,BPE)的符号化来实现高效的编码。这表示词汇表内的“单词”并非全词,而只是文字中频繁出现的一群字符。
GPT使用的向量维度是50 257,这是一个非常大的向量,它的大多数内容是0,但是这样的设定太浪费空间,为了解决这个问题,模型使用一个自动复制函数:一个接受长度为50 257 的1 和0 向量,并输出长度为n的数字向量的神经网络。
2.2.3 解码
假设下游任务的标注数据为C,其中每个样例的输入为x=x1,x2,…,xn构成的长度为n的文本序列,与之对应的标签为y。获取通过GPT3模型训练得来的最后一层的最后一个词对应的隐含层输出
紧接着将该隐含层输出通过一层全连接层变换,来预测最终的标签。
其中,Wy∈Rd×k表示全连接层权重(k表示标签个数)。最终,通过优化以下损失函数来进行具体任务优化:
2.2.4 其他模型
BiLSTM+CRF方法,对输入的文本进行编码,将单词映射到词嵌入空间,以便模型能够理解每个单词的语义,利用两个方向的LSTM 层,分别从前向和后向扫描输入序列,以捕获上下文信息,添加一个CRF 层,它用于建模标签之间的依赖关系。CRF 考虑了整个序列的标签分布,以确保生成合理的实体边界。CRF层的转移矩阵表示从一个标签到另一个标签的可能性。
本文也选取四种预训练模型(BERT、ALBERT、ERNIE、RoBERTa)作为与本文模型进行对比的方法,输入文本经过错误词处理,问题分类和问题分析后会输入各预训练模型,对于各预训练模型处理得到的结果,无需像2.2.1 小节对于输出部分介绍的那样进行人为处理,因为其本身就能对模型结果进行解码和实体边界的划分,达到预期输出的要求。
2.3 知识图谱
系统中查询使用到的知识图谱,为北京大学提供的中文医疗问答知识图谱[46]。知识图谱中包含的实体类型有疾病、症状、检查、药物、病原体和治疗方式。
该知识图谱,将以往的实体三元组进行关系抽取,抽取出29 种关系,将关系直接设为图谱的节点。这样设计可以避免传统知识图谱三元组(<实体1,关系,实体2>)的弊端,举一个例子,假如感冒必须同时吃布洛芬、阿司匹林和三九感冒灵才能治好,仅用三元组的形式可以表示为:
<感冒,药物治疗,布洛芬>
<感冒,药物治疗,阿司匹林>
<感冒,药物治疗,三九感冒灵>
但这样没有办法表示出“同时吃布洛芬、阿司匹林和三九感冒灵才能治疗感冒”,只能表示出“感冒可以吃布洛芬”“感冒可以吃阿司匹林”“感冒可以吃三九感冒灵”。
对关系进行抽象后,可以用图3所示的形式表示“感冒必须同时吃布洛芬和阿司匹林才能治好”并且可以很清晰地表示出多路方法的查询,如“感冒的检查方式”,根据图4的表达,可以很清楚地看到两种检查方式。

图3 知识图谱实例1Fig.3 Knowledge graph example 1
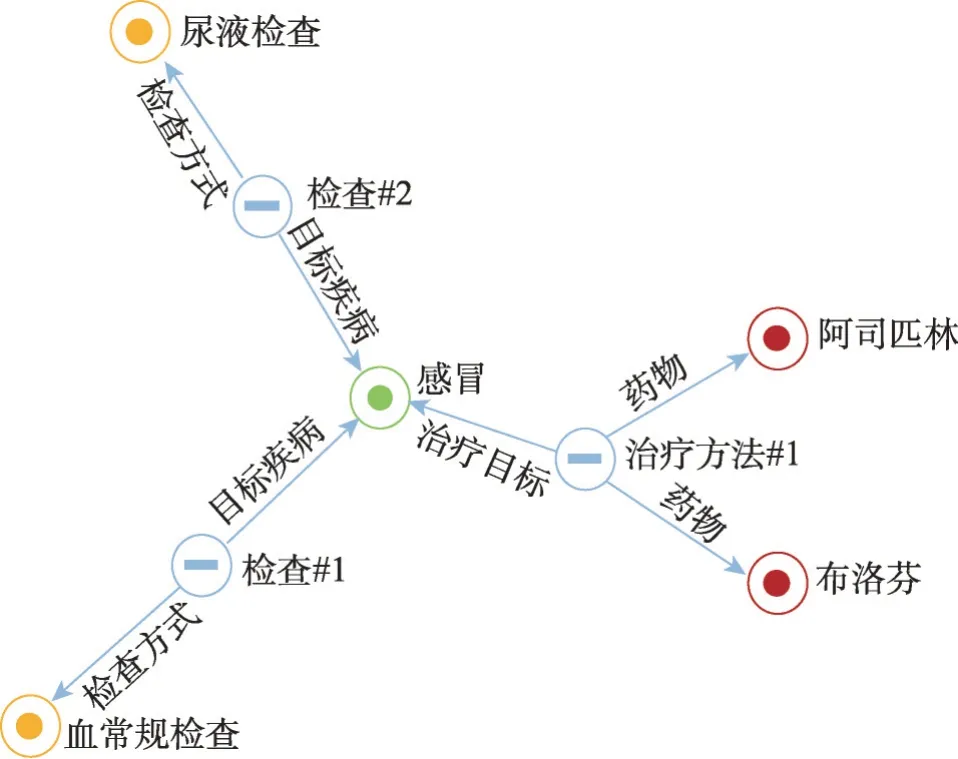
图4 知识图谱实例2Fig.4 Knowledge graph example 2
在系统的意图识别模块,将意图与知识图谱的关系进行映射连接,关系对应如表2所示。

表2 对应关系映射表Table 2 Correspondence mapping table
3 实验
3.1 研究问题
为了验证实验的效果,提出以下3个研究问题:
RQ1:大语言模型和传统方法在实体识别上的效果对比如何?
RQ2:数据集的质量,对大语言模型实体识别的影响是怎样的?
RQ3:实体识别的效果对整个问答系统的效果是怎样的?
3.2 数据集
在3 个中文医疗数据集上进行实验,如表3 所示。它们分别是中文医疗信息处理挑战榜(Chinese Biomedical Language Understanding Evaluation,CBLUE)中的CMeEE(https://tianchi.aliyun.com/dataset/95414)和IMCS-NER(https://tianchi.aliyun.com/dataset/95414)以及ChineseBLUE 中的cMedQANER(https://tianchi.aliyun.com/dataset/81513?spm=a2c22.28136470.0.0.1726cc93snEzMC)。
CMeEE中文医疗对话数据集将医学文本命名实体划分为九大类,包括:药物(dru)、医疗程序(pro)、疾病(dis)、医学检验项目(ite)、科室(dep)、临床表现(sym)、医疗设备(equ)、身体(bod)、微生物类(mic)。该数据集训练集数据15 000条,验证集数据5 000条,测试集数据3 000 条。标注数据总字数达到220 万,包含47 194 个句子,938 个文件,平均每个文件的字数为2 355。数据集包含7 085 种身体部位、4 354 种医疗程序、504 种常见的儿科疾病、12 907 种临床表现等9大类医疗实体。
IMCS-NER 中文医疗对话数据集训练集样本2 472 条、验证集样本833 条、测试集样本811 条。共包含5类命名实体,分别是:症状、药物、药物类别、检查、操作。标注方式采用BIO三位字符级标注,其中B-X代表实体X的开头,I-X代表实体的结尾,O代表不属于任何类型。
cMedQANER 中文医疗数据集由中国社区问答标记,共包含疾病、治疗方式、药物等10类实体,训练集1 673条、验证集175条、测试集215条。
数据集中的训练集用于训练文中复现模型的参数,测试集用于验证模型的效果,验证集的作用是通过监控模型在验证集上的性能,在模型性能达到最佳时停止训练,避免过拟合,从而提高模型的泛化能力。
3.3 评价指标
命名实体识别的可量化评价指标有3个,分别是准确率(Precision,简记为Prec)、召回率(Recall,简记为Rec)和F1-Score(简记为F1)值。其中,准确率衡量命名实体识别模型正确识别实体的能力,召回率衡量命名实体识别模型识别整个语料库中全部实体的能力,F1取两者的调和平均值。
设模型正确识别的相关实体数为TP,模型错误识别的不相关实体数为FP,模型未识别的相关实体数为FN,则:
3.4 实验相关参数设置
本文利用了HMM[26]、CRF[30]、Lattice LSTM[47]、BiLSTM+CRF[8]等模型,以及包括ALBERT(a lite BERT)、ERNIE(enhanced representation through knowledge integration)、BERT、RoBERTa 在内的预训练模型和大语言模型ChatGPT 进行实验,实验参数如下所示。
对于RQ1,比较了HMM[26]、CRF[30]、Lattice LSTM[47]、BiLSTM+CRF[8]和GlobalPointer[9]5 种传统机器学习实体识别方法。对于BiLSTM+CRF,python 版本为3.6,pytorch 工具包版本为1.8.1。在训练的过程中,采用Adam优化算法进行参数优化,初始学习率设置为0.01。同时,为了防止过拟合化,采用early-stop和dropout 策略,并通过梯度裁剪来解决梯度爆炸问题。具体实验参数设置如表4所示。

表4 本文方法实验参数设置Table 4 Parameter configurations of proposed approach
GlobalPointer 中采用BERT 对输入进行向量化,在此基础上,将BERT 替换为RoBERTa、ERNIE 和ALBERT 进行实验,在Hugging Face 调用,直接使用原有模型的参数。
使用ChatGPT 大语言模型,采用其中的textdavinci-002 模型,它可以理解并生成自然语言或代码,并且与text-davinci-003 类似的能力,但使用监督微调而不是强化学习进行训练,当没有上下文示例、零样本的时候,text-davinci-002 在零样本任务完成方面表现更好。从这个意义上说,text-davinci-002 更符合人类的期待。为了探究本文提出的方法是否适用于其他大语言模型,在Llama2-13B 模型上进行同样的实验,查看实验效果。
对于RQ2,是基于对3 个典型的数据集进行分析,发现其中存在少量质量较差的数据,主要分为以下3类:
(1)数据集标注不全。例如“水肿”“静脉充血”“血红蛋白下降”等实体没有标注出来。
(2)实体标注不完整。例如“喉咙疼痛”原始数据集只标注出“疼痛”,具体哪里疼痛却没有标注出。
(3)实体标注错误。例如“肿瘤”原始数据集标注的是症状类型,实际上应该是疾病类型。
针对这种情况,在RQ2对应的实验中,对没有更正的数据集和更正后的数据集,进行了实体识别对比实验。
对于RQ3,采用基于规则的方法识别出问题的意图,结合ChatGPT识别出的实体,通过关系链接将意图链接到知识图谱中的具体关系,最后查询出答案。
4 实验结果及分析
4.1 对RQ1的回答
在3 个数据集上,复现了5 个实体识别方法,分别是HMM[26]、CRF[30]、Lattice LSTM[47]、BiLSTM+CRF[8]和GlobalPointer[9],其中,GlobalPointer 中采用BERT对输入进行向量化,在此基础上,将BERT 替换为RoBERTa、ERNIE 和ALBERT 进行实验,共8 组实验。在下面的表中,GlobalPointer简写成GP,括号内的内容表示对输入进行向量化的预训练模型,实验结果如表5所示。
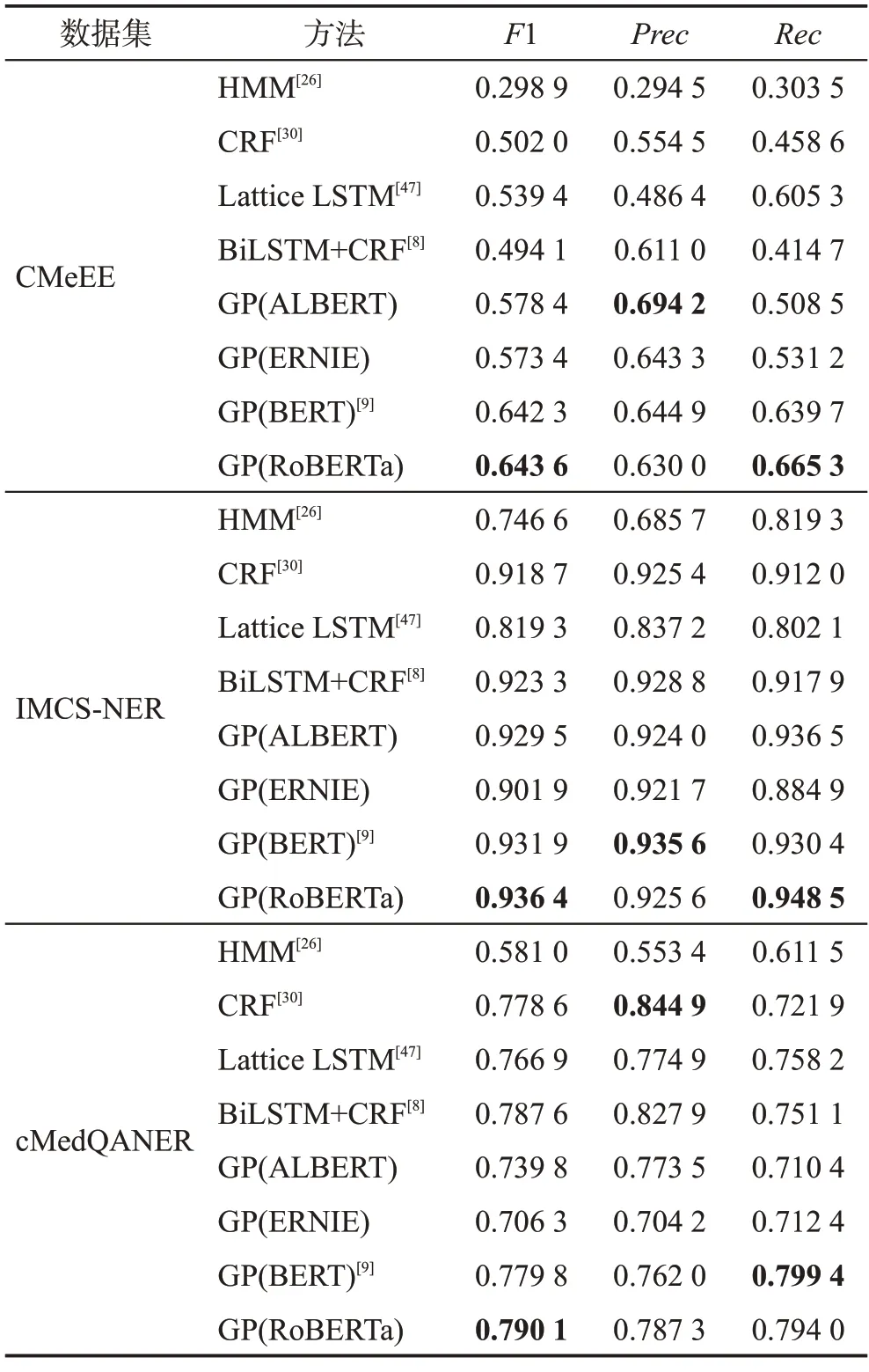
表5 机器学习方法的比较Table 5 Comparison of machine learning methods
从表5可以看出,预训练模型RoBERTa在3个数据集上的F1 都是最高的,它的效果与BERT 相差不大;在Recall 评价指标上,RoBERTa 在CMeEE 和IMCS-NER数据集上的表现是最好的,分别能够达到66.53%和94.85%,在cMedQANER 数据集上能够达到79.40%,仅比最好的BERT 相差0.005 4;这表明RoBERTa 模型在医疗命名实体识别任务中具有更好的泛化能力,能够识别出更多的实体。在Precision评价指标上,RoBERTa 和BERT 在IMCS-NER 和cMedQANER 两个数据集的效果比其他方法好。综上所述,RoBERTa 和BERT 预训练模型具备识别出更多医疗实体的能力,并且在IMCS-NER 和cMedQANER数据集上识别得更加精确,说明RoBERTa和BERT 比其他预训练模型更加适合做医疗命名实体识别任务。
复现的方法在数据集CMeEE、IMCS-NER 和cMedQANER上的loss曲线图分别如图5~图7所示。
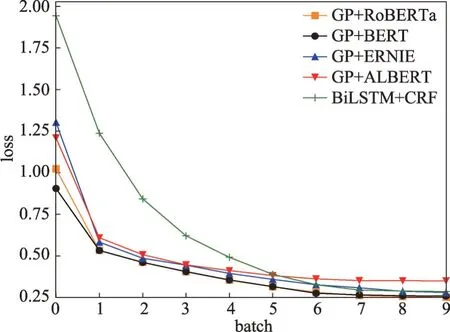
图5 CMeEE数据集上的loss曲线图Fig.5 Loss curve graph on CMeEE dataset
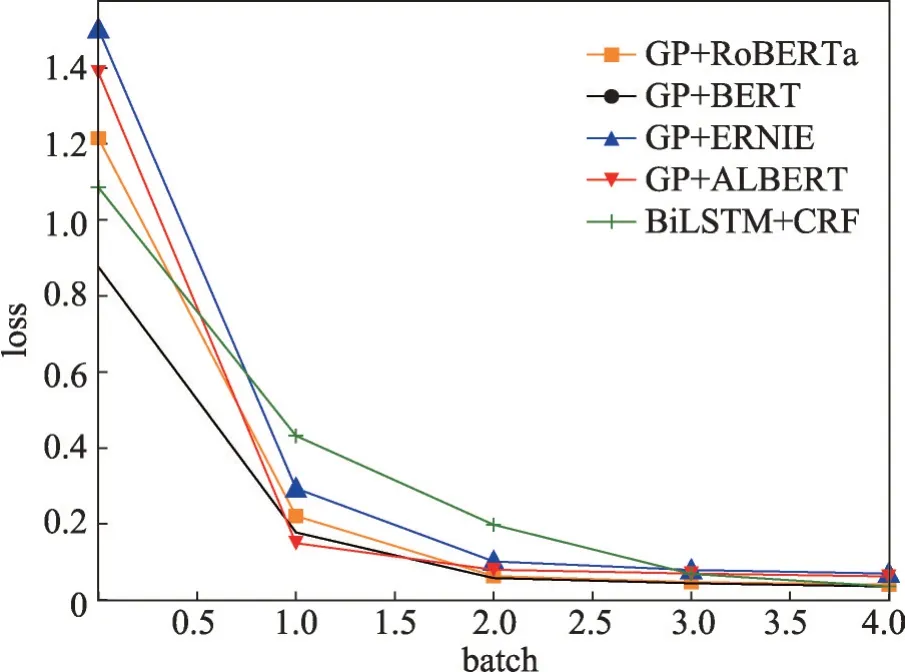
图6 IMCS-NER数据集上的loss曲线图Fig.6 Loss curve graph on IMCS-NER dataset
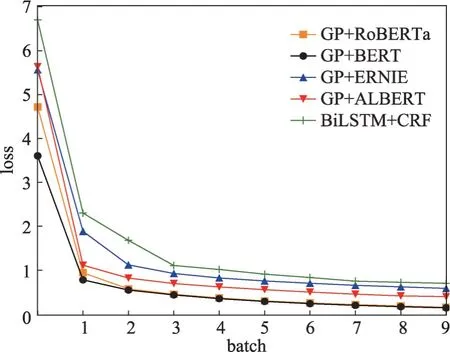
图7 cMedQANER数据集上的loss曲线图Fig.7 Loss curve graph on cMedQANER dataset
监控训练过程中的损失函数值,随着训练的进行,损失函数逐渐减小,CMeEE、IMCS-NER 和cMedQANER 数据集分别在第7 轮、第3 轮和第5 轮的loss值趋于稳定或不再减少,表示模型已收敛。
由于人工标注和访问ChatGPT 接口成本较高,cMedQANER 数据集采用全集进行实验,CMeEE 和IMCS-NER 各从中抽取100 条数据。由于这两个都是中文多轮医疗问答数据集,里面包含了很多噪声语句,例如“你好”“谢谢帮助”和“再见”等。在抽取时先对整个数据集进行分层处理,针对每一层进行随机抽样,根据具体数据集的情况,进行了长度筛选,去除文本长度小于6 个中文字符的样本(日常问候语等不包含实体和明确意图的数据),从而组成测试集。在随机抽取的测试集上的实验结果如表6所示。
从表6 可以看出,在F1 评价指标上,ChatGPT 在CMeEE 数据集上的表现是最好的,在IMCS-NER 和cMedQANER 两个数据集上效果不如传统机器学习的方法,主要有以下两点原因:(1)IMCS-NER是一个多轮对话数据集,里面包含了大量的不存在医疗实体的数据;(2)IMCS-NER 和cMedQANER 这两个数据集存在大量标注错误、标注不全和标注不完整的问题,降低了实验的结果。因此在RQ2 中将标注错误的数据进行人工纠正,并且进行实验。在Recall评价指标上,ChatGPT 在CMeEE 和cMedQANER 两个数据集上的表现比传统机器学习方法好,说明像ChatGPT 这样的大语言模型比RoBERTa 和BERT 预训练模型具有更强的泛化能力,大语言模型能够更加充分地挖掘文本中的语义信息,对于文本中有错别字的情况,大语言模型可以很好地识别,因此能够识别出更多的医疗实体,随之带来的是精确率的下降。另一个导致精确率降低的原因是:这两个数据集是多轮中文医疗对话数据集,随机抽取出来的测试集中包括一些不包含医疗实体的对话文本。综上所述,ChatGPT 具备识别医疗命名实体的能力,在数据集标注准确的情况下,能够比传统机器学习方法识别出更多的医疗实体。
从表6的最后两组实验可以看出,采用本文的方法,在3 个评价指标上,大语言模型Llama2 比ChatGPT低2~5个百分点,因此本文提出的方法同样适用于像Llama2 这样的大语言模型,但是由于Llama2 的模型大小是13 billion,导致识别效果不如ChatGPT。
4.2 对RQ2的回答
针对数据集标注不全、标注不完整和标注错误3类问题,本文根据国际疾病分类(international classification of diseases,ICD)标准,人工进行数据集的补全和纠错,根据从原始数据集中随机抽取的结果,共更正了416 条数据。数据集更正后的医疗实体识别效果如表7所示。
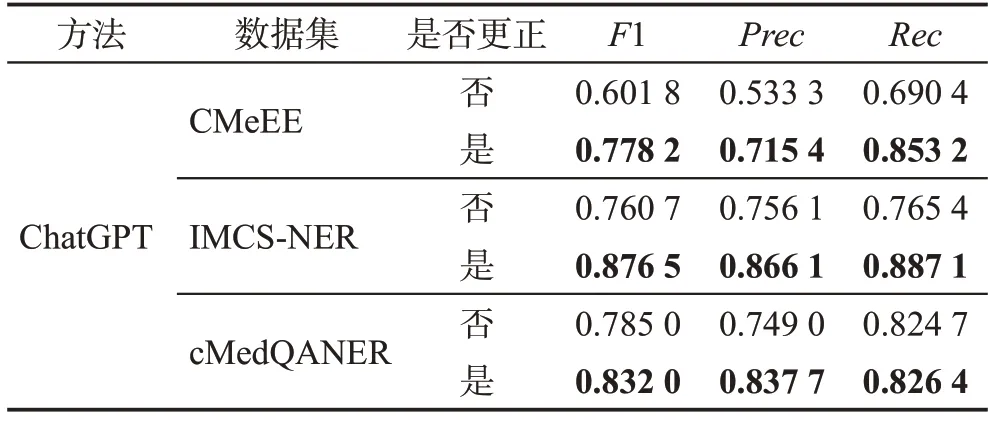
表7 数据集进行更正后的识别效果Table 7 Recognition effect after correcting dataset
在RQ1 的实验中,针对实验中的结果进行了分析,发现原始数据集在标注上有较多的错误,有的实体还未标注,或者实体属于非连续性和嵌套实体,这些情况传统机器学习方法并未很好地识别出来,但ChatGPT识别出来了,因此降低了实验得分。针对数据集做了人工的更正后,再次进行实验,由表6和表7的结果可以看出,在数据集进行更正之后,各个数据集上的实验效果得到了明显的提升,并且明显高于其他机器学习方法,这表明数据集的质量对实体识别的效果有很大影响。综上所述,ChatGPT在CMeEE、IMCS-NER 和cMedQANER 数据集上能够识别出更多的医疗实体,在医疗实体丰富的文本上,ChatGPT比传统机器学习方法更加适合做医疗命名实体识别任务。另外,ChatGPT 相较于其他传统机器学习方法,在高得分的情况下,还能够识别出非连续性实体和嵌套实体,应用在对话系统中,会得到更好的效果。
4.3 对RQ3的回答
将ChatGPT 识别出来的实体应用到医疗问答系统上,采用自己构建的问答数据集,该数据集共225条,每条数据由医疗问题和问题答案组成,包含治疗、相关导致和检查等类型的问题,部分问题中包含嵌套实体和非连续性实体,问题的答案通过百度和智慧问诊系统获得,问答结果如表8所示。
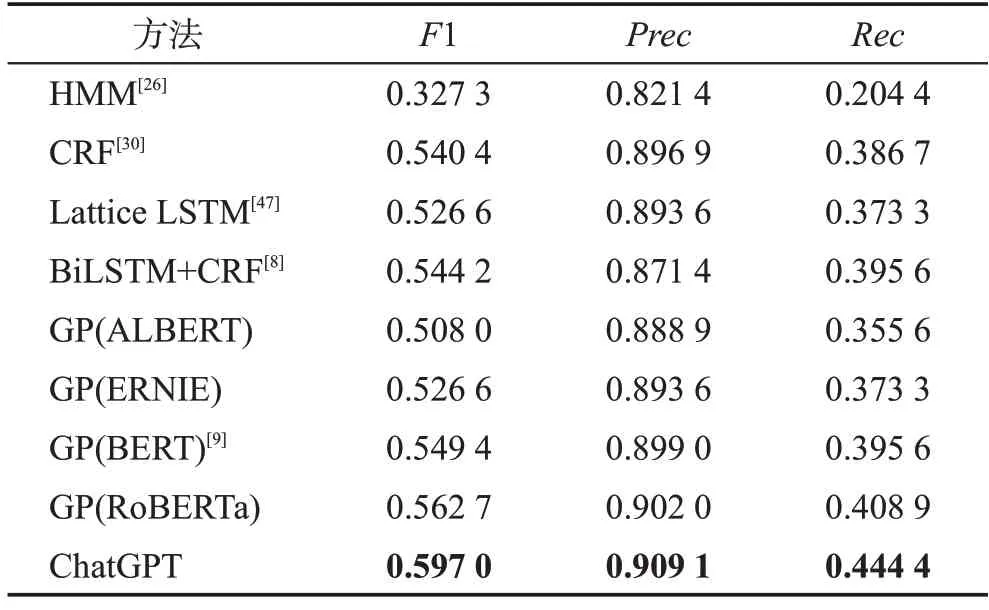
表8 问答结果Table 8 QA result
从表8可以看出,将ChatGPT识别出来的实体应用到医疗问答系统里,在3个评价指标值上相较传统机器学习方法有明显提升,这表明ChatGPT 能够识别出更多的并且更加适用于医疗问答系统的实体。综上所述,ChatGPT不仅在中文医疗实体识别上有较好的效果,应用到系统中也有较好的效果。
4.4 实验进一步讨论
(1)输入形式对大语言模型实体识别有影响
在实验过程中,首先可以发现大语言模型实体识别中输入和输出对识别效果影响较大。对于输入的文本,需要给定预期输出的格式,但大语言模型返回的输出格式还是具有多样性,这样就会导致不适用于下游任务,需要进行处理,否则会有许多的实体遗漏,造成结果的不准确。比如在最开始使用ChatGPT完成实体识别任务的时候,并没有对输出格式进行规定,这样得到的结果五花八门,格式也较为混乱,因此对ChatGPT 输出的结果进行了人为的规定,例如表1中所提到的8种格式。
(2)数据集的质量对结果有影响
在针对RQ1 的实验中,发现数据集的质量存在问题,并且影响实验结果。主要体现在两方面:
一方面,数据集中有些实体标注错误,有些实体并未标注出来。例如:“患者的神经细胞质中发现内基小体”,在原始数据集中,“内基小体”并未标注出来,这类情况在一定程度上影响整个实验结果,因此人为对数据集进行了更新,修正了这部分错误。
另一方面,数据集中存在着错别字以及语序混乱的情况。例如“氨酚黄那敏颗粒”,原始数据集给出的是“氨酚黄那敏科利”,错别字对模型识别的时候有一定的影响,模型就只能识别出“氨酚黄那敏”,这样该实体并没有识别完全。
对数据集进行更新并再次进行了实验,实验结果证明了利用大语言模型识别出的医疗实体应用在医疗问答系统上更具优势。
(3)大语言模型对识别非连续性实体、嵌套实体效果好
通过对ChatGPT 问答结果的分析,发现大语言模型具有识别非连续性实体、嵌套实体的能力。
对于嵌套实体,例如在“它能应对各种原发及继发性肾脏疾病”这一医疗文本的识别中,传统的机器学习方法只能识别出“原发及继发性肾脏疾病”,但是大语言模型可以识别出“原发性肾脏疾病”和“继发性肾脏疾病”两个实体。
对于非连续性实体,例如“体温较前已在下降了”,传统的机器学习方法未能识别出实体,但是大语言模型可以识别出“体温下降”这个实体。
这两种情况在日常的医疗问诊对话里经常出现,因此将大语言模型应用到医疗问答系统中更具优势。
5 总结与展望
本文首先分析了以往医疗文本实体识别问题的局限性。为解决医疗文本实体识别存在非连续实体和嵌套实体识别的问题,提出了大语言模型的实体识别方法。该方法首先需要对医疗文本进行预处理,然后使用大语言模型,使得能够识别其中的非连续实体和嵌套实体。其次,大语言模型实体识别的输出没有统一的格式,为此进行了分类和分析。提出的大语言模型实体识别方法在三个公开的数据集上有着优秀的表现,实验结果表明了方法的有效性。
由于大语言模型的训练数据是通用领域的数据,没有专业领域的数据,导致大语言模型对医学领域的问题回答不专业或不准确,未来考虑使用医疗领域的语料微调目前的大语言模型,例如Llama2、miniGPT和GPT4等,进一步优化任务表现。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国卫生(2016年1期)2016-11-12
中国卫生(2016年1期)2016-11-12
中国卫生(2016年1期)2016-01-24
