
基于知识图谱的风电机组诊断系统构建与应用
2023-10-26 08:35陈新财巩晓赟韩东洋刘华杰
郑州大学学报(工学版) 2023年6期
陈 宏, 陈新财, 巩晓赟, 韩东洋, 刘华杰
(1.郑州大学 机械与动力工程学院,河南 郑州 450001;2.哈密职业技术学院 机电系,新疆 哈密 839099;3.郑州轻工业大学 机电工程学院,河南 郑州 450000)
风能是目前最重要的清洁能源,它的可再生性促进了风力发电技术的高速发展。由于大型风电机组所处地区偏远、环境恶劣,在安装运行中会出现大量故障,影响机组安全运行[1],对其故障进行快速排查定位可缩短维修时间,提升运行效率,减少经济损失。
目前智能故障诊断方法总体可分为基于模型和基于数据驱动2类。基于数据驱动的方法需要全面监测数据并提取相关特征,特征的准确程度决定了诊断的精度。胡澜也等[2]根据数据采集与监控系统(SCADA)的运行数据,结合LightGBM方法构建的故障识别模型对于处理重叠故障具有更好的性能。温竹鹏等[3]提出小波变换和二维密集连接扩张卷积神经网络的方法,提升了故障特征的提取能力和诊断精度。此类故障诊断方法依赖于庞大故障数据集,具有一定适用性。但其诊断结果由于缺少知识支撑和诊断过程,解释机制有一定局限性[4]。
知识图谱的概念最早由谷歌公司提出,并逐步成为现在的研究热点,在各个领域都能体现其价值[5],例如在灾害应急、医学[6]等领域。在机械故障诊断领域中,基于知识图谱的方法可快速帮助定位故障源、缩短排查故障原因的时间,其过程具有良好的可解释性和逻辑性,因此引起了研究人员的广泛关注。Wu等[7]基于半自动实体抽取方法,对非结构化历史运维数据进行规则化和结构化,实现故障预测与快速定位。郭恒等[8]采取“数据+模型+知识”方法,融合、存储了大量非结构化数据,构建了维修性知识图谱。对于越复杂的结构系统,知识抽取与融合越关键。吴闯等[9]通过搭建知识管理模型,基于知识图谱构建了智能问答系统,提供了可靠的数据支撑。
本体是一种提升共享性与重用性的语言规范[10],用来表达结构化和逻辑相关的知识,被广大研究学者引入到知识库构建中。根据实际问题探讨对知识的合理分层结构[11],设计者与用户共识度越高,本体库泛用性就越高。周亮等[12]基于本体方法构建故障树,根据JESS推理机对SWRL规则的推理,可实现系统故障的快速定位。Hodkiewicz等[13]将本体应用到FMEA工业数据中并提取概念与逻辑,提升机器可读性,通过OWL-DL推理最终故障影响。
对于故障树模型,综合多方面的领域知识以及参数信息是提升实用性的关键,现阶段部分学者对故障树的研究还未结合知识图谱进行拓扑分析,因此本文提出以故障树为基础的知识图谱构建方法。基于双向长短期记忆网络(BiLSTM)、条件随机场(CRF)及BERT预训练模型的方法对非结构化数据进行实体信息抽取,并通过改进模型的结构,达到更好的抽取效果。在此基础上,构建条件故障树,实现故障知识结构化,结合FMECA进行信息完善,通过Protégé软件对知识本体化,利用知识融合提升共享性。最后使用Neo4j数据库进行展示,为风力发电机智能故障诊断系统的构建提供数据支持。
1 知识图谱的构建方法
对于中大型风力发电机,由于故障信息非结构化,其维修案例中也多为专业人员总结,内容繁杂,采取<实体,关系,实体>三元组的形式可直观、形象化表达知识系统,如图1所示。
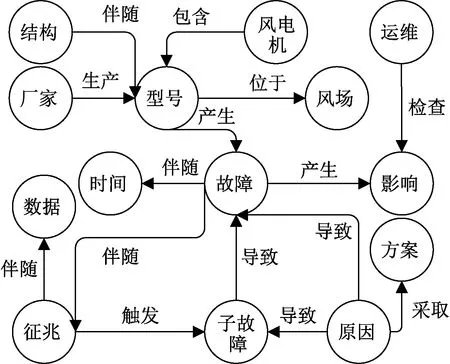
图1 三元组结构
1.1 构建流程
知识图谱的构建方法主要有自顶向下和自底向上2种[14],本文采用自底向上的方法构建风力发电机故障知识图谱,主要包括故障知识抽取,知识数据结构化与本体化,具体构建流程如图2所示。
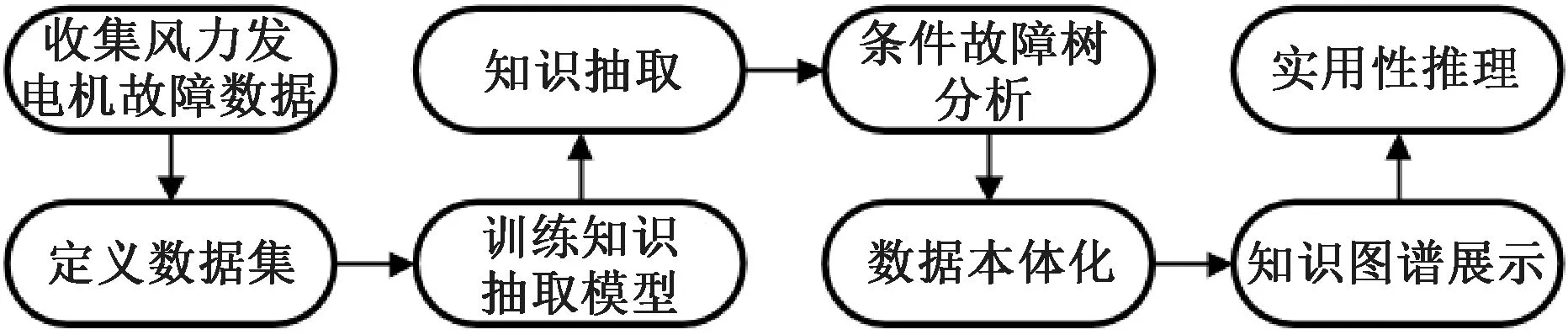
图2 风力发电机知识图谱构建流程
1.2 基于模型抽取知识
对文本数据进行知识抽取是构建知识图谱的重要步骤。常晓莹等[15]对BiLSTM-CRF模型进行了详细解读,在垃圾分类任务中取得了一个很好的效果,但是对于语义越复杂的数据领域,模型效果就越差。近年来,BERT模型被提出,由于其强大的语义特征提取能力,研究学者开始将BERT模型应用于数据挖掘[16]。
1.2.1 BERT-BiLSTM-CRF模型简介
传统LSTM是单向结构,其中遗忘门与输入门负责筛选有用的信息,并通过输出门以及记忆细胞的乘积输出,由于该模型无法同时分析文本上下文信息,故引入BiLSTM模型,其核心思想是采取双向LSTM,对同一时刻的输出合并,因此,每一个时刻都有对应的前向与后向信息。CRF模型采用softmax分类器,负责处理相邻标签的依赖关系,减少错误标签顺序的预测,优化序列,提升预测结果的准确性,相应地弥补了BiLSTM的缺点。
BERT模型通过双向Transformer可更好地捕捉语句中的双向关系,提取文本的语义特征与关系特征并转化为词向量传入下一层,借助预训练的优势来减轻实体命名识别任务的下游任务,提升识别效果。图3为BERT模型结构图,其中Ei指输入的字或词,Ti指预测结果,Trm为 Transformer 模型。
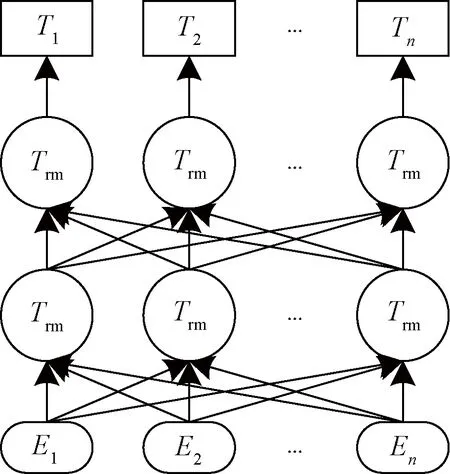
图3 BERT模型结构图
采取BIO(B为实体的开始,I为实体的中间或结束,O表示非实体)策略,共定义了7类标签(功能系统、故障特征、故障原因、故障现象、故障影响、维修方法、机械结构),进行模型训练后,以未标注数据中故障原因标签(reason)预测为例,BERT-BiLSTM-CRF结构如图4所示。利用BERT模型的语言表征提取优势,将该模型与BiLSTM进行输出拼接,使向量蕴含了更丰富的语义特征,增强BERT-BiLSTM-CRF模型的实体识别效果。
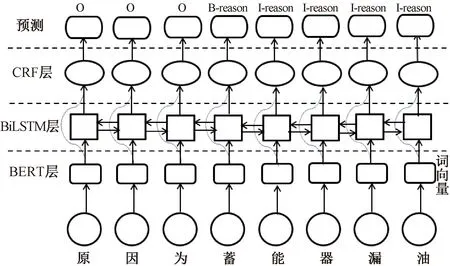
图4 BERT-BiLSTM-CRF网络结构图
本文以近几年的中大型风力发电机故障分析案例为数据集,其格式如表1所示。

表1 故障数据集格式示例
按照数据类别设置标签名称,使用BIO标注数据集后,将所有数据整合为一个文件,按8∶1∶1划分训练集、测试集以及验证集,以此为数据集进行模型测试,采用F1值评估,其计算公式如下:
(1)
式中:P为精确度;R为召回率。
1.2.2 改进模型
本文的模型环境基于Python的keras框架搭建,为提升模型的识别效果,采用以下优化方案:①训练中保存最优模型时,将指标从token准确率替换为标签识别完整的准确率;②添加学习率衰减策略,当训练次数epochs未完成且F1值不再提升时,衰减当前学习率,将学习率降低至原来的1/10;③分层设置学习率,由于BERT模型特性,学习率要维持小的量级,而BiLSTM模型不适用,故扩大学习率至原来的500倍,减轻训练负担;④添加对抗训练,在BERT的embedding-token层添加扰动来构造一些对抗样本,交付模型预训练,提高模型在对抗样本上的鲁棒性,提升泛化性能,扰动量设为0.5。与传统模型进行实验对比(采取相同数据集),结果如表2所示。
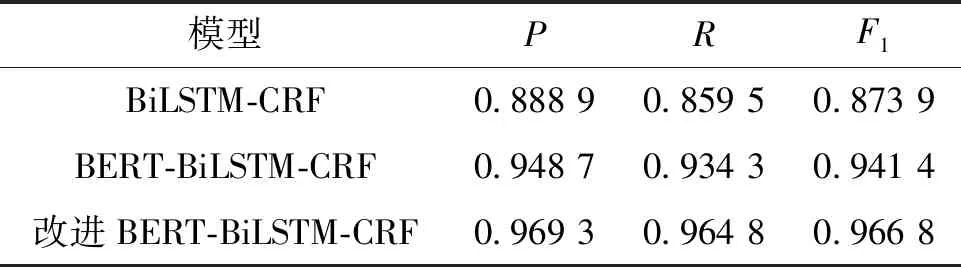
表2 模型效果对比
故BERT-BiLSTM-CRF改进模型在风力发电机故障知识领域满足实体识别的一致性要求且效果良好,可用于故障知识抽取,为自动构建故障知识图谱提供了模型支持。
2 知识结构化
2.1 条件故障树
风力发电机组中的液压刹车系统包括气动刹车和机械刹车。本文以液压刹车系统故障为例,对传统故障树加入故障征兆并展开分析,如图5所示。表3为故障树各个节点对应的事件名称。

表3 液压刹车系统故障树事件
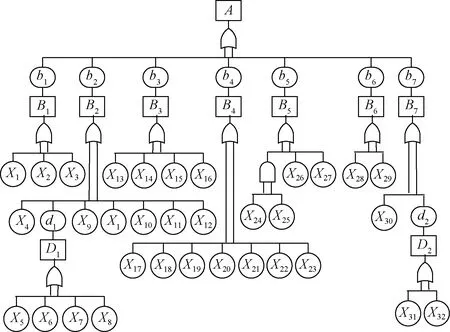
图5 液压刹车系统故障树分析
该故障树包含1个顶事件、32个底事件与9个中间事件,顶事件用A表示,底事件用Xi表示,中间事件用Bm与Dn表示,可得出最小割集:{X1}、{X2}、{X3}、{X4}、{X5}、{X6}、{X7}、{X8}、{X9}、{X10}、{X11}、{X12}、{X13}、{X14}、{X15}、{X16}、{X17}、{X18}、{X19}、{X20}、{X21}、{X22}、{X23}、{X24·X25}、{X26}、{X27}、{X28}、{X29}、{X30}、{X31}、{X32}。布尔代数表达式为A=X1+X2+X3+X4+X5+X6+X7+X8+X9+X10+X11+X12+X13+X14+X15+X16+X17+X18+X19+X20+X21+X22+X23+X24·X25+X26+X27+X28+X29+X30+X31+X32。
设底事件的Xi的发生概率为Pi,且底事件之间相互独立,故障树中“或”门概率公式计算见式(2),“与”门概率公式计算见式(3),顶事件发生概率为每个最小割集发生概率之和。
(2)
(3)
根据故障树中不同底事件的重要程度不同,通过概率重要度和关键重要度来分析。其概率重要度表示底事件发生概率的变化对顶事件发生概率的影响程度[17],公式计算见式(4)。关键重要度表示底事件发生概率的变化率所导致的顶事件发生的变化率,公式计算见式(5)。
(4)
式中:αi为底事件Xi的概率重要度;θ(P)为顶事件的发生概率;Pi为底事件Xi的发生概率;θ(1iP)为底事件Xi发生时顶事件发生的概率;θ(0iP)为底事件Xi未发生时顶事件发生的概率。
(5)
式中:βi为底事件Xi的关键重要度。
将实际案例中故障数据Xi与Pi代入上述公式,通过故障树分析可得出液压刹车系统故障的发生概率,以及每个底事件的重要度参数。
2.2 FMECA理论应用

表4 FMECA表单示例
3 知识本体化
构建本体是提升知识库共享性的基础,采取本体的表示方法能够精确定义领域知识的概念、内在关系与属性,基于该方法,将知识用以下模型表示:
〈C,AC,AR,R,E,T〉。
(6)
式中:C为本体类的集合;AC为类属性的集合;AR为关系属性的集合;R为本体关系的集合;E为实例的集合;T为公理的集合。
针对故障知识进行本体类定义,可表示为
C={C1,C2,C3,C4,C5,C6,C7,…}。
(7)
式中:C1为功能系统类概念;C2为故障特征类概念;C3为故障原因类概念;C4为维修方法类概念;C5为故障影响类概念;C6为故障现象类概念;C7为机械结构类概念。
针对故障知识进行本体关系定义,可表示为
R={R1,R2,R3,R4,R5,R6,…}。
(8)
式中:R1为功能系统类与故障现象类的关系;R2为功能系统类与机械结构类的关系;R3为故障现象类与故障原因类的关系;R4为故障现象类与故障影响类的关系;R5为故障原因类与维修方法类的关系;R6为故障现象类与故障特征类的关系。
面试前的那天晚上,我呆在自己的房间里,穿上了那件白色的衬衫,灰色的短裙和海蓝色的鞋子。我就在那儿,一动不动地站在衣橱的镜子前,心里嘀咕着:这个女孩真的是我么?我不禁笑了,可一想到明天的面试将决定我的命运,笑容顿时消失了。
以下为关系的语义示例:
(1)R1=Rhas_phenomenon(C1,C6) 表示某功能系统发生了某个故障现象;
(2)R2=Rhas_structure(C1,C7) 表示某功能系统由某些结构组成;
(3)R3=Rhas_reason(C6,C3) 表示导致某故障现象的有某些原因;
(4)R4=Rhas_influence(C6,C5) 表示某故障现象具有某些故障影响;
(5)R5=Rhas_advice(C3,C4) 表示某故障原因可采取的维修建议;
(6)R6=Rhas_character(C6,C2) 表示某故障现象具有某些故障特征。
在风力发电机诊断知识中的本体模型中,AC为类概念的附加属性,例如ID属性,每个节点在知识图谱中的ID唯一。AR为关系概念的附加属性,例如type属性是对复杂的关系概念分类、名称标识等。E为实例的集合,例如对发电机实例化:双馈异步类型、3 150 kW功率等。T为公理集合,例如传递、等价、继承等约束,是知识推理的基础。通过Protégé软件开发领域知识本体,如图6所示为“故障现象”概念类的部分展开图。其 Hermit推理机可对本体所有概念类进行语义一致性检验,确保模型的一致性。
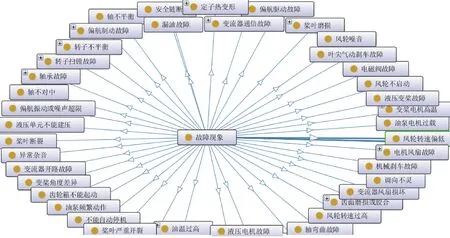
图6 风力发电机故障知识本体
3.1 知识融合
由于领域内专家、设计者和工作人员等对知识的认同存在差距,故本体异构性也会影响知识的共享性,需通过本体之间映射关系计算邻近概念的相似度。本文引入一种知识融合的方法,在本体概念之间对字符串相似度进行计算,设概念1为字符串y,概念2为字符串z,相似度计算公式为
(9)
式中:γ为调节系数,随两概念的相似字符个数增大而增大;K为两概念中相同字符数量;L为概念1存在而概念2不存在的字符数量;M为概念2存在而概念1不存在的字符数量;N为两概念的总字符数量。
由于语义相似的同时可能存在知识结构差异,因此还需引入结构相似度,最终确定概念之间综合相似度。具体融合过程如图7所示。
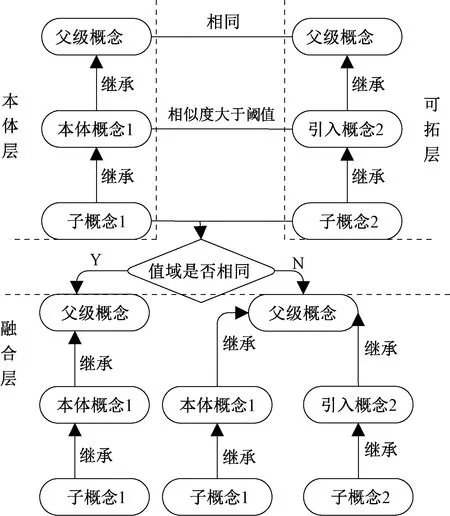
图7 知识融合过程
3.2 Neo4j图数据库
Neo4j图数据库由节点、关系以及属性组成,相比于传统的关系型数据库而言,图数据库可直接表达数据的关联特性,可存储大量多源异构的数据,节省存储空间。
由于Protégé的数据存储为owl文件,不易作为软件开发的数据基础,于是将owl本体数据通过Rdf2rdf模块转化为RDF文件,导入Neo4j,生成具有良好开发性的知识数据,图8所示为图谱的部分展开图。
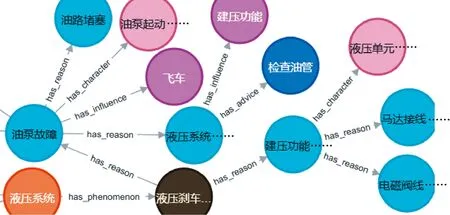
图8 风力发电机知识图谱展示
4 案例分析
4.1 案例推理
2013年10月,某风电场中某台FD70B/1500型机风力发电组(采用液压系统制动)频繁报液压系统压力低故障,查询机组监控设备后得知液压系统的油泵及电机频繁启动,且机组中主轴制动器和偏航制动器电机在非工作状态下约20 s启动一次。维修人员的非目的性排查流程为①检查液压系统的油管,不存在泄漏点;②更换油泵电机,系统压力值正常但未解决;③检查滤芯堵塞问题;④更换蓄能器,系统压力值正常且稳定,通过测试蓄能器性能,最终确定原因为蓄能器的隔膜破裂导致漏气。
基于知识驱动时,提取案例中存在的故障征兆,在Neo4j图数据库中查询,得出所属故障现象,并推理下一层事件,根据危害性分析参数排查原因。如图9所示,提供了故障诊断路径与设备结构,辅助维修人员快速定位故障源。
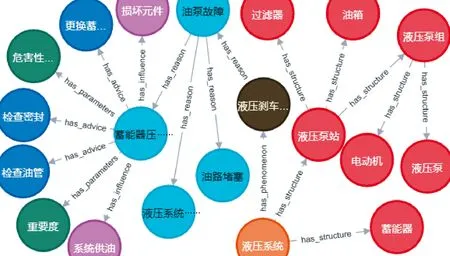
图9 知识图谱推理结果
4.2 方法比较
数据库类型可分为关系型数据库与图数据库,基于故障树分析建立关系型数据库:以故障原因与故障现象为例,一个故障现象可对应多个原因,一个原因可对应多个故障现象,需建立如图10所示的双向关联表,外键用于单向关联。
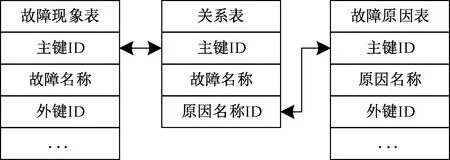
图10 双向关联表
该存储方式存在以下缺点:①当故障树需要拓扑更多维度的知识时,会建立更多更复杂的表,难以清晰地表示关系,且维护困难;②基于存储数据形式的问题很难直接通过数据表来表达知识之间的逻辑关系,不利于知识重用;③该数据库使用SQL语言操作,专业性强,工作人员难以直接将经验转化为计算机语言存储。
而Neo4j图数据库可高效地表达知识结构:①不需要建立复杂关联表,只需针对知识节点信息创建;②面对多源异构的数据,可清晰地建立逻辑关系;③使用Cypher语言驱动,逻辑编写简单、可读性强,非编程人员也可快速掌握。
5 结论
由于风力发电机故障维修知识缺乏管理与利用,技术资源无法有效重用,为了避免资源浪费,本文研究了风力发电机故障知识图谱的构建方法:①在故障域的海量数据中,通过训练并改进得到效果良好的BERT-BiLSTM-CRF模型,该模型用于知识提取;②对故障实体构造故障树结构并进行分析,添加推理条件,提供故障排查的技术支持;③通过Protégé对故障数据本体化与结构化,检验语义一致性,提升知识库的共享性;④通过 Neo4j图数据库提升数据的读写性能,为诊断系统的软件开发提供了良好的数据支撑。最后,通过风力发电机事故案例证明,基于条件故障树分析方法所构建的知识图谱具备快速定位故障源的能力,为智能问答系统奠定了基础。
猜你喜欢
哲学分析(2023年4期)2023-12-21
中学生数理化·八年级物理人教版(2023年6期)2023-05-25
少先队活动(2020年12期)2021-01-14
中国音乐学(2020年4期)2020-12-25
中成药(2017年3期)2017-05-17
山东工业技术(2016年15期)2016-12-01
领导科学论坛(2016年9期)2016-06-05
文学教育(2016年27期)2016-02-28
少年科学(2014年2期)2014-02-24
卷宗(2013年6期)2013-10-21
