
基于低秩稀疏表达的弹性最小二乘回归学习
2023-10-26 08:48:30武继刚李妙君赵淑平
郑州大学学报(工学版) 2023年6期
武继刚, 李妙君, 赵淑平
(广东工业大学 计算机学院,广东 广州 510006)
最小二乘回归(least squares regression,LSR)是统计学理论中一种典型的数据分析工具,通过最小化实际值和预测值的差值平方和来学习投影矩阵。基于LSR已经研究出了许多经典模型,但是,传统的LSR模型存在3个主要问题。
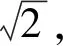
第2个问题是基于LSR的方法对噪声的敏感性。在实际应用中,由于图像在获取、发布或传输过程中受到噪声的干扰[7],导致同一个类别的训练样本和测试样本之间的差异可能很大。对于噪声数据的分类问题,适当地降低类边距通常可以有更好的分类精度。Peng等[8]使用negative ε-dragging技术来确定不同类别之间的适当边距。赵雯等[9]提出的判别低秩表示(discriminative low-rank representation,DLRR)算法可以在遮挡的训练样本中分离出相对干净的图像。Bao等[10]提出了基于松弛局部保持回归(relaxed local preserving regression,RLPR),使用了L2,1范数替代损失函数的LF范数。Fang等[11]将原始数据分解为一个“干净”的分量加上稀疏的噪声分量,使用了一个稀疏项来补偿回归误差,这有助于在回归过程中抑制噪声的干扰。杨章静等[12]提出一种基于潜在子空间去噪的学习图像分类方法(denoising latent subspace based subspace learning,DLSSL),在原始空间和标签空间中间引进一个潜在子空间,将学习分成了2个过程,对样本先进行降噪处理,然后使用潜在子空间中的“干净”数据进行回归分类。
第3个问题是传统的LSR没有过多关注样本之间的相关性和标签的类内紧凑性,这会破坏数据的基础结构并导致过拟合问题。ICS_DLSR[3]在最小二乘回归模型中引入了类间稀疏性约束,使转换后的样本在每个类别中具有共同的稀疏结构,有效地利用样本之间的相关性。基于低秩表示(low-rank representation,LRR)的模型很容易捕获数据的全局结构。钟堃琰等[13]提出对通过ε-dragging技术所得的松弛矩阵施加低秩约束,可以提高其类内紧凑性,保证了回归标签的类内相似性。Chen等[14]将Fisher判别准则和ε-dragging技术集成到一个模型中提出了Fisher判别最小二乘回归模型(fisher discriminative least squares regression,FDLSR),Fisher准则可以提高松弛学习过程中松弛标签的类内紧凑性和相似性。在FDLSR中还证明了DLSR的本质是基于L2范式的支持向量机的松弛版本。
因此,本文提出一种基于低秩稀疏表达的弹性最小二乘回归学习(low-rank sparse representation based elastic least squares regression,LRSR-eLSR)模型。引入半灵活性的回归目标矩阵,将0-1目标松弛为更可行的变量矩阵,为不同类别的样本提供合适的边距,并且不会轻易破坏回归目标的结构。同时,为了避免结构信息的丢失,引入低秩约束来学习具有判别性的投影矩阵,捕获数据不同类别的底层结构。除此之外,引入了具有行稀疏性的误差项,可以从噪声或损坏的数据中稳健地提取特征。模型的流程如图1所示。
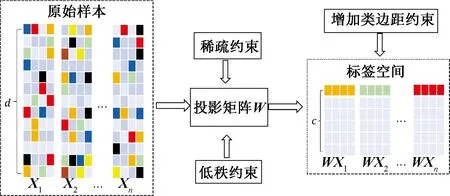
图1 模型框架图
1 相关工作
X为来自c个类别的n个训练样本的训练集,X=[x1,x2,…,xn]∈Rd×n,其中d为每个样本的特征维数。LF范数、L2,1范数和核范数的计算分别为
(1)
(2)
‖X‖*=∑i|σi|。
(3)
式中:XT为矩阵X的转置;σ为矩阵的奇异值。
1.1 最小二乘回归(LSR)
最小二乘回归的目标是学习一个将训练数据转换为二进制标签空间的最优投影矩阵,常见函数表示为
(4)
式中:W∈Rc×d为投影矩阵;β>0为正则化参数。Y为对应于数据集X的0-1标签矩阵,定义如下:如果训练样本xi来自第k个类别,则列向量yi的第k个元素为1,其余元素为0,Y=[y1,y2,…,yn]∈Rc×n。
将式(4)中的第1项看作损失函数,第2项表示广泛使用的L2正则化,用来避免过拟合。
1.2 重定向最小二乘回归(ReLSR)
ReLSR的核心思想是通过关注相对值,直接从数据中学习回归目标矩阵,能够提高多分类的性能。模型在学习过程中对目标矩阵进行直接优化,约束每个样本其真类和假类目标之间的差值应大于1,将其表达为一个优化问题,如式(5)所示:
(5)
式中:H为目标矩阵;en为全为1的行向量;b为偏差向量。
ReLSR在学习的过程中会对H重复更新,初始化H可以令H=Y。ReLSR的目标矩阵是通过只关注不同类别对应的相对值来学习的,以保证大多数数据点的正确分类。
1.3 基于低秩类间稀疏性的半灵活性目标最小二乘回归(LIS_StLSR)
LIS_StLSR与ReLSR一样,都是在学习中更新目标矩阵,但是,LIS_StLSR采用半灵活性的回归目标矩阵与低秩类间稀疏约束相结合,学习到目标矩阵可以保证对每个数据点的正确分类的要求有很大的限制并且不会破坏回归目标原有的结构,不会影响到下一次迭代训练中的回归性能。LIS_StLSR的目标函数如(6)式所示:
(6)
式中:Z为低秩表示矩阵;‖WXZi‖2,1为低秩类间约束项。
LIS_StLSR通过训练样本的“干净”表示来实现类间关系,使得共享同一标签的投影样本保持共同的稀疏结构,同时,利用训练样本的低秩表示进行类间稀疏学习。
2 本文模型
2.1 提出问题和新的回归模型
传统的最小二乘回归模型使用了严格的二元标签矩阵作为目标矩阵。从几何学的角度,不同类别样本的距离应该要尽可能大,而同一个类别的样本之间的距离尽可能小,学习到的回归目标更具有判别力,可以增加回归模型的灵活性。不同于DLSR使用ε-dragging技术放松标签矩阵,模型通过对真假类别之间的学习目标实施约束直接从数据中学得回归目标,并引入一个稀疏误差项E以放松标签矩阵。将上述表达为一个优化问题,如式(7)所示:
(7)
式中:λ1和λ2均为正则化参数。
与0-1矩阵Y相比,目标矩阵H可以直接从数据中学习,可以更准确地测量回归误差。为了在学习过程中捕捉数据相关的底层结构,根据低秩最小化的性质,对式(7)中转换矩阵W使用LF范数,同时添加低秩约束。构建的目标函数为
(8)
式中:λ3为正则化参数;rank(·)表示矩阵的秩。
由于秩函数的离散性,式(8)是一个非凸非光滑问题,所以很难求解,根据文献[15],将秩函数替换为核范数正则化可以得到上述优化问题的凸松弛形式,对式(8)重新构造:
(9)
考虑求解问题,对式(9)中的核范数利用公式转化为LF范数进行统一求解,根据文献[5]中的Theorem 1,对于任意的矩阵W,可以得到:
(10)
由式(9)和式(10),可以得到最终的目标函数,如式(11)所示:
(11)
2.2 模型求解
对目标函数(式(11))使用ADMM算法[16]进行优化求解,其增广拉格朗日函数为
(12)
式中:C为拉格朗日乘子;μ>0为罚参数。
对于式(12),在其他参数固定的情况下交替求解W、E、H、A和B。具体解决步骤如下。
步骤1 更新W。固定E、H、A和B,可以通过最小化以下目标来获得W。
(13)
式(13)中,通过将L(W)相对于W的导数设置为零,可以获得最佳W。即
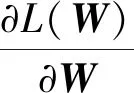
(14)
由式(14)可以得到W的最优解为
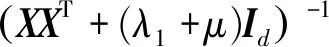
(15)
式中:Id表示维数为d的单位向量。
步骤2 更新E。固定其他参数,令U=WX-H,可以通过最小化以下基于L2,1范数的目标函数来获得E。
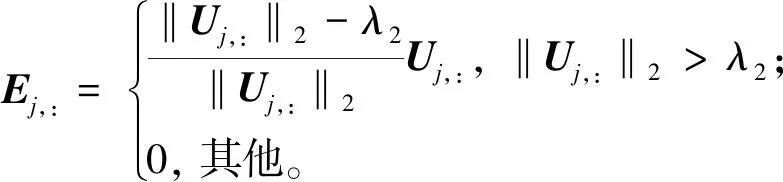
(16)
式中:Ej,:和Uj,:分别表示E和U的第j行向量。
步骤3 更新A。固定其他参数,通过对A进行求导,令导数为0,可以得到A的闭式解为
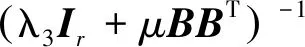
(17)
步骤4 更新B。固定其他参数,通过对B进行求导,令导数为0,可以得到B的闭式解为
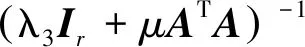
(18)
步骤5 更新H。令S=WX-E,公式如下所示:
(19)
将式(19)分解为n个独立的子问题求解得到H的最优解,每个子问题都对应H这一行的学习,则每个子优化问题可以表示为
(20)
式中:k表示行的真类索引;i表示在h中最大值的索引。
更新式(20)为
(21)
步骤6 更新C和μ为
(22)
式中:ρ和μmax均为数值很小的正参数。
根据上述求解过程可以得到学习的投影矩阵W,对任何测试样本y,其投影样本为Wy,使用最近邻分类器对其进行分类。
2.3 计算时间复杂度
LRSR-eLSR模型的主要耗时是在逆矩阵的运算上,式(13)中的时间复杂度为O(d3);式(14)的时间复杂度为O(r3);式(15)的时间复杂度为O(r3)。对于矩阵的加、减、乘,计算成本可以忽略不计。因此,本文所提出的方法的主要计算成本是O(t(d3+2r3)),其中t表示迭代次数。
3 实验结果与分析
将本文模型与其他算法进行比较,包括LRDLSR[17]、FDLSR[14]、SALPL[15]、CDPL[18]、DLSR[1]、ReLSR[4]和SN-TSL[19]。所有实验均在MATLAB R2018b中进行,操作系统为Windows 10。
3.1 数据集
Extended Yale B数据集:由38人提供的2 414幅图像,每个类别有59~64个正面图像,具有不同的照明。实验中使用的所有图像都提前调整为32×32像素。然后从每个类随机抽取10、15、20、25张图像作为训练集,其余样本作为测试集。
LFW数据集:包含了1 680个在无约束条件下拍摄对象的13 000多张人脸图像。在这个实验中,使用了一个包含86个人共1 251张图像的子集,每个受试者只有10~20张图像。在实验中,将图像尺寸调整为32×32像素,随机选择每个受试者的5、6、7、8张图像作为训练样本。
COIL-20数据集:包含了20个物体,每个物体有72个灰色图像,这些图像是从不同方向拍摄的。在实验中,对每个图像进行下采样,使其具有32×32像素,从每个类随机抽取10、15、20、25张图像作为训练集。
MNIST数据集:一个包含0~9的手写数字数据集,该数据集包含60 000个用于训练和10 000个用于测试的图像,图像尺寸为28×28像素。在实验中,从每个类随机抽取40、60、80和100张图像作为训练集。
3.2 结果与分析
实验重复执行10次并记录平均准确率。对于二分类问题,样本将根据真实类别与学习器预测类别组合为4种情况,如表1所示。

表1 二分类混淆矩阵表
准确率Acc是一个分类性能的检测指标,表示在所有的样本中被分类模型预测为正确的样本数量所占的比例,如式(23)所示[20]:
(23)
式中:TP表示待检测样本属于正类并且分类模型也将待检测样本预测为正类;TN表示待检测样本属于反类并且分类模型也将待检测样本预测为反类;FP表示待检测样属于反类但是分类模型将待检测样本预测为正类;FN表示待检测样本属于正类但是分类模型将待检测样本预测为反类。其中FP和FN都是分类模型预测不正确的情况。
表2为Extended Yale B人脸数据集上不同方法对比的结果。显然,在人脸数据集上,当样本数量为15、20、25时,本文算法取得了最佳的分类结果。
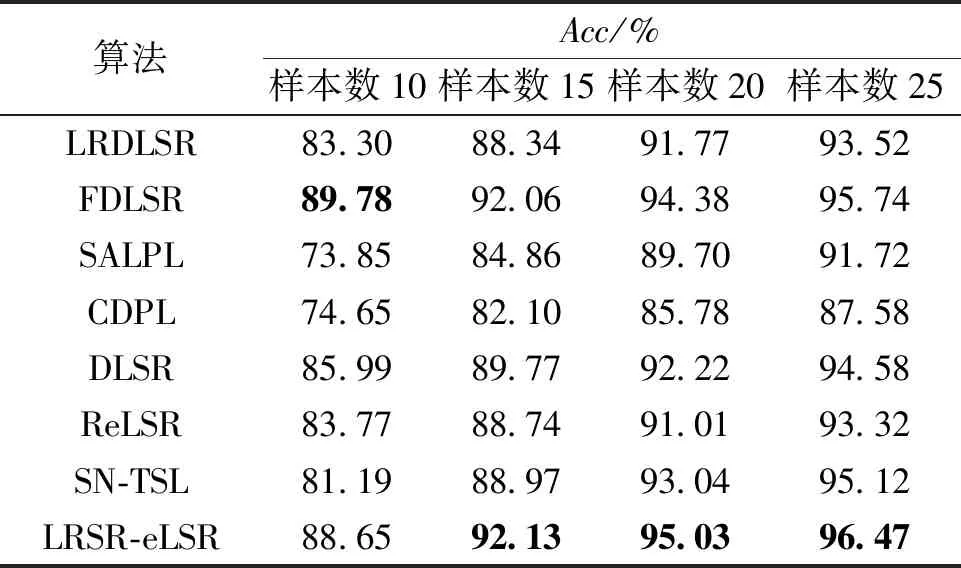
表2 Extended Yale B上不同方法的平均分类准确率
表3为LFW人脸数据集上不同方法的对比结果。由于LFW数据集是一个很难进行图像分类的数据集,使用不同分类方法获得的平均准确率都相对不高,当样本数量为6、7、8时,LRSR-eLSR的性能较好。
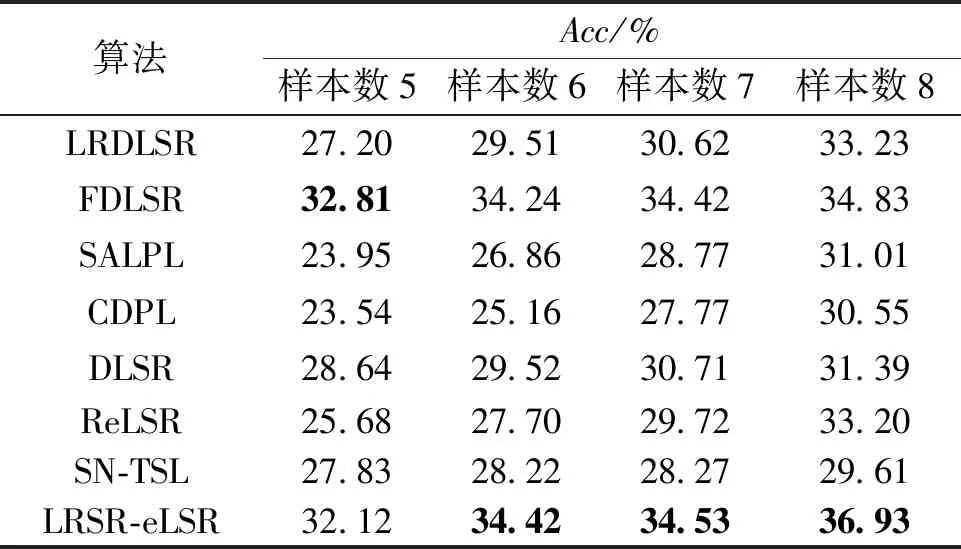
表3 LFW数据集上不同方法的平均分类准确率
表4为在COIL-20物体数据集上不同方法对比的结果。由结果可以分析,提出的模型获得了比其他方法好的分类结果。因此,LRSR-eLSR在解决客观识别任务方面有很大的潜力,这证明了模型对于对象分类任务的有效性。
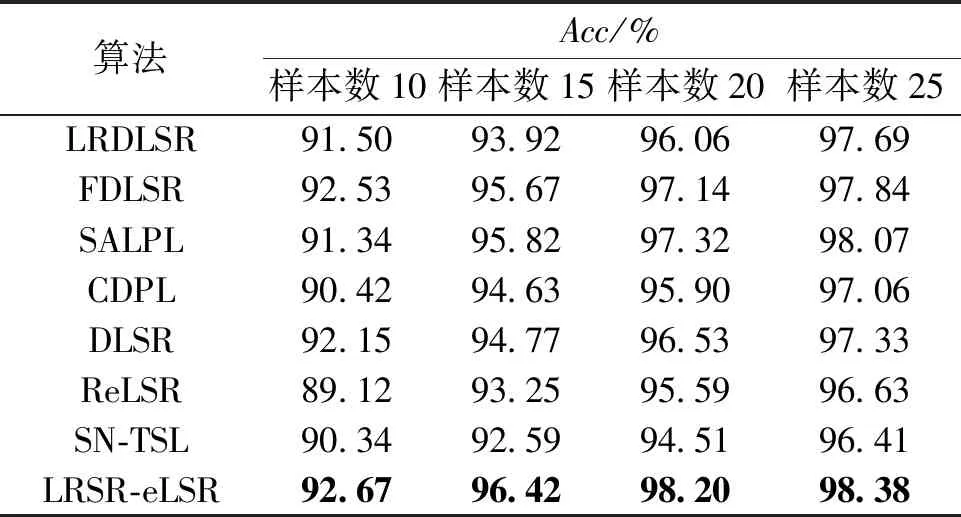
表4 COIL-20上不同方法的平均分类准确率
表5为在MNIST手写数字数据集上不同方法对比的结果。可以发现,与其他方法相比,LRSR-eLSR可以提供更好的结果。
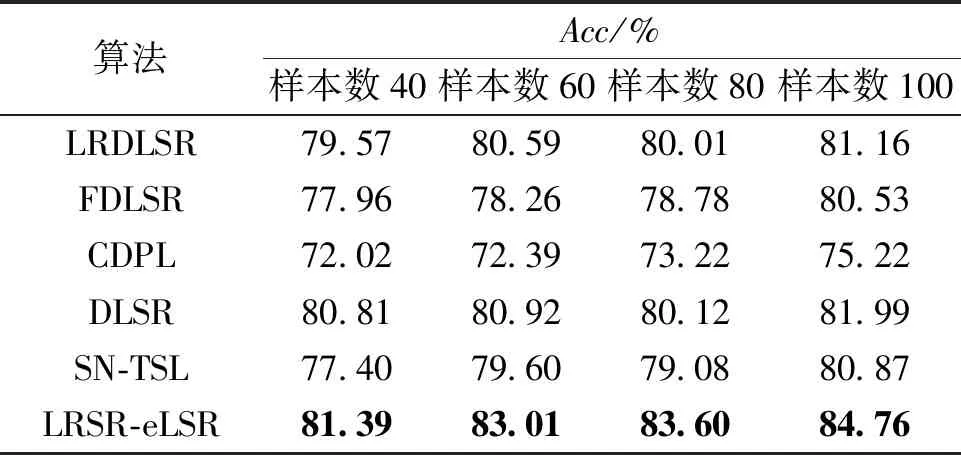
表5 MNIST上不同方法的平均分类准确率
在Extended Yale B、LFW和COIL-20这3个数据集上,对比基于松弛标签方法的DLSR和ReLSR,LRSR-eLSR可以学习更具判别力的变换。因为DLSR和ReLSR只关注于扩大类间距,而不关心缩小类内距离。与DLSR和ReLSR不同,本文方法通过引入半灵活性的回归目标H,使得模型在数据中直接学习矩阵。
3.3 参数灵敏度分析
在本文方法中,参数λ1、λ2和λ3需要进行灵敏度分析,用于平衡相应约束项。λ1用于避免投影W的平凡解;λ2用于松弛标签矩阵,以自适应地拟合变换后的数据;λ3保证了数据底层结构。首先,定义一个候选集{10-5,10-4,10-3,10-2,10-1,100,101,102};其次,在Extended Yale B数据集上,分析LRSR-eLSR算法的λ1、λ2、λ3对Acc的影响。
实验采用控制变量法确定λ1、λ2、λ3的最佳参数组合。例如,为了确定λ1的敏感度,先令λ2=1,λ3=1,得出不同λ1的值对Acc的影响。为了确定不同参数组合的最优值,将其中一个参数固定为之前单个参数选择阶段的最优值,并使用网格搜索算法观察另外2个参数在候选集范围内变化时Acc的变化。
图2为在Extended Yale B数据集上调整单个参数时LRSR-eLSR的Acc曲线。图3为在Extended Yale B数据集上不同参数组合时LRSR-eLSR的Acc曲线。由图2、3可知,λ1稳定性差,其最大值为1,说明不需要对模型过多施加避免平凡解的项。λ3比较稳健,其值对模型的Acc影响较小。因此,首先固定参数λ3的值,通过选择λ1和λ2的不同组合计算LRSR-eLSR模型的Acc,可以获得这2个参数的最佳组合;其次,采用相同的方法从参数λ3的候选参数集中找到最佳值;最后,应用λ1、λ2、λ3的最佳参数组合运算10次,得到平均分类准确率Acc。实验发现,当参数λ1∈[10-1,101]、λ2∈[100,102]时,LRSR-eLSR模型性能较好。
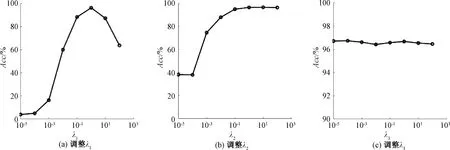
图2 调整单个参数时LRSR-eLSR的Acc
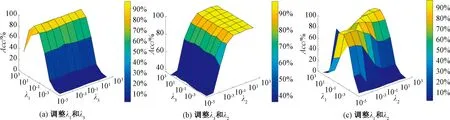
图3 不同参数组合时LRSR-eLSR的Acc
3.4 消融实验
为了评估所提出模型中每一项的有效性,从Extended Yale B、LFW、COIL-20和MNIST数据集中分别选取25、8、25、100个样本作为训练样本,其余的样本作为测试样本进行消融实验。将所有实验重复10次,取平均值,结果如图4所示。其中,LRSR-eLSR(λ1)表示设置模型中的λ1=0,即模型没有矩阵W的LF范数项;LRSR-eLSR(λ2)表示设置模型中的λ2=0,即模型中少了系数误差项E;LRSR-eLSR(λ3)表示设置模型中的λ3=0,即模型少了低秩约束项。
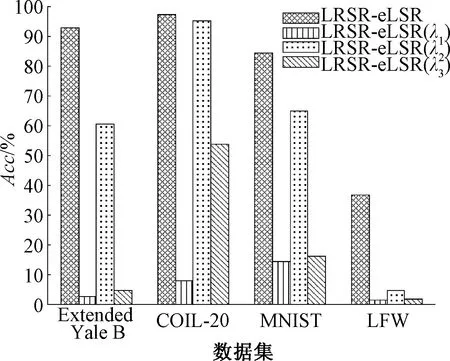
图4 LRSR-eLSR在4个数据集上的消融实验结果对比
由图4可知,LRSR-eLSR(λ1)和LRSR-eLSR(λ3)的性能比LRSR-eLSR差得多。这表明所提出的LRSR-eLSR极大地受益于矩阵W的LF范数项和低秩约束项。LF范数具有防止过拟合的作用,追求低秩回归标签有助于学习更多的判别投影,从而显著提高最终分类性能。
4 结论
本文提出了一种基于低秩稀疏表达的弹性最小二乘回归学习模型(LRSR-eLSR)。该模型通过对回归矩阵增加弹性约束扩大不同类别之间的差值,以构建放松的标签矩阵。此外,对转换矩阵添加了稀疏性约束和低秩约束,使回归目标具有稀疏性和低秩性,在保持数据的低秩结构的同时防止过拟合。在不同任务的公共数据集上的实验结果表明,相对于现有的最小二乘回归变体的方法,本文方法具有优异的性能。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
数学物理学报(2017年5期)2017-11-23 07:51:31
中国校外教育(下旬)(2017年8期)2017-10-30 17:32:36
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学物理学报(2017年3期)2017-07-01 16:18:48
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:06
