
基于Transformer和卷积神经网络的代码克隆检测
2023-10-26 08:35贲可荣杨佳辉
郑州大学学报(工学版) 2023年6期
贲可荣, 杨佳辉, 张 献, 赵 翀
(海军工程大学 电子工程学院,湖北 武汉 430033)
代码克隆是软件开发中的常见现象。在软件开发和演化的过程中,程序员通过复制和粘贴代码段,或者使用框架、复用设计模式和自动工具生成代码等方式加速软件开发。以上操作导致代码库中存在2个及以上相同或相似代码段的现象称为代码克隆[1]。开源社区中的代码克隆可以提高开发效率,但是也会导致缺陷传播,降低系统的可靠性。代码克隆检测技术目的在于自动检测软件系统中克隆的代码,可以帮助开发人员和管理者及时发现代码克隆造成的缺陷,更好地保证软件质量。
根据相似程度的不同,Bellon等[2]将代码克隆分为4种类型,从type1到type4,代码相似程度逐渐降低,检测难度也逐渐增加。传统的代码克隆检测方法基于人工定义的规则,对专家经验依赖程度较高。基于深度学习的方法能够自动学习出代码的特征,摆脱“特征工程”的难题,减少人工分析成本。Hindle等[3]认为编程语言和自然语言一样,具有重复性和可预测性,能够被机器理解和分析。受Hindle等[3]工作的启发,许多学者将代码作为自然语言来处理。例如早期的Nicad方法[4]通过对比2个代码行中最长相同序列来检测代码克隆,该方法在文本层面进行分析,不能检测type4类型的克隆。基于词法的克隆检测中,代码被表示为token序列。CClearner[5]将程序的单词分为8种类型,针对每个类型比较2个代码片段的词频序列,得到8维向量送入神经网络中训练。尽管代码和自然语言有很多共性的特征,都是由一系列单词组成,但是代码具有更清晰的逻辑、丰富且复杂的结构,且标识符之间存在长距离依赖,将代码视作自然语言或者token序列进行处理容易丢失信息。
抽象语法树(abstract syntax tree,AST)是基于抽象语法结构将源代码转换为树结构的表示形式。研究表明,基于AST表征的模型明显优于基于序列表征的模型[6-8]。CDLH模型[6]使用基于树的长短期记忆网络(tree-structured long short-term memory,Tree-LSTM)遍历AST,为了提高效率,使用特定的哈希函数对代码向量进行哈希处理,比较散列向量之间的汉明距离来识别代码克隆。为了解决子节点数目可变的问题,将AST转换为全二叉树。Zeng等[9]基于递归自动编码器(recursive autoencoder,RAE)模型提出了加权递归自编码器(weighted recursive autoencoder,WRAE),利用WRAE分析AST,提取程序特征并将函数编码成向量。该方法在输入之前利用二叉树生成规则将AST转换成了完满二叉树。
由于程序的复杂性,AST的结构通常又大又深,尤其是嵌套结构,这样容易产生梯度消失问题,导致AST丢失从远程节点到根节点携带的一些语义信息。为了简化和提高效率,直接将AST视为二叉树或者将AST转换为二叉树,这种做法破坏了源代码的原始语法结构,削弱了神经网络模型捕获真实语义的能力。为了克服上述基于AST的神经网络的局限性,Zhang等[10]提出了ASTNN,将每个大型的AST分割成许多语句树序列,在保留原始代码语义的基础上解决了梯度消失问题。词向量训练器将每一个语句树都编码成向量送入双向门控循环单元(bidirectional gated recurrent unit,BiGRU)中,生成代码片段的向量表示。Meng等[11]在ASTNN模型的基础上进行改进,特征提取阶段用BiLSTM替换原本的BiGRU,新增加一个注意力网络层提取代码特征。
在特征提取阶段,现有的大部分模型都使用基于循环神经网络(recurrent neural network,RNN)的时间序列模型。2017年,谷歌团队[12]提出了完全基于自注意力的深度学习模型——Transformer。相较于RNN,自注意力支持高度的并行化,并且还能轻松地实现长期上下文建模。
1 代码克隆检测方法
本文提出一种基于Transformer和卷积神经网络(convolutional neural network,CNN)的代码克隆检测(Transformer and CNN based code clone detection,TCCCD)方法。TCCCD方法的总体架构如图1所示。基于AST的表征方式能够实现源代码的抽象表示,优于基于token的表征方式。为了解决AST过大带来的梯度消失问题,先将代码解析成AST,同时保留源代码的语法结构。本文借鉴ASTNN切割AST的思想,将一段代码的AST切割为小型语句子树,其中,语句子树由先序遍历得到的语句节点序列构成,蕴含代码结构和层次化信息。每一组语句树通过语句编码器编码成向量,送入神经网络中。在神经网络设计方面,现有的模型大多使用基于RNN的时间序列模型,当2个相关性较大的时刻距离较远时,会产生较大的信息损失。本文使用Transformer的Encoder部分提取代码的全局信息,Transformer能够直接对输入序列之间的更长距离的依赖关系建模。作为补充,使用CNN捕获代码的局部信息,学习出蕴含词法、语法和结构信息的代码向量表示。计算两段代码向量的欧氏距离表征语义关联程度,训练一个二元分类器检测代码克隆。
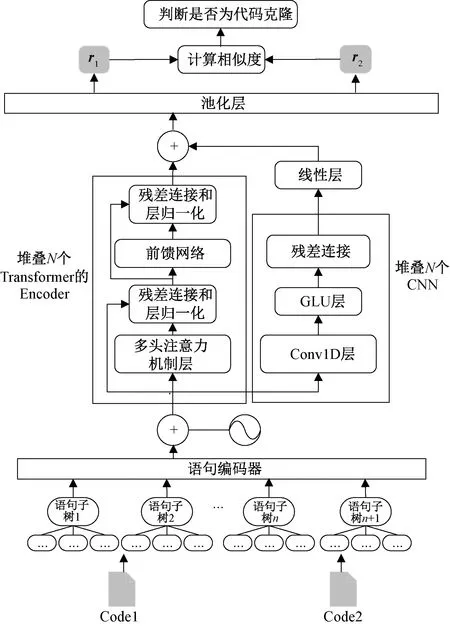
图1 TCCCD的总体架构
1.1 分割AST,编码语句树序列
首先,面向函数粒度,使用现有的语法分析工具,将代码解析为AST。为了防止AST规模过大而导致梯度消失问题,不能直接将AST作为模型的输入,而是按照语句粒度对AST进行切割。
AST经过先序遍历,得到语句节点的集合S,将MethodDeclaration视为一种特殊的语句节点,故S′=S∪{MethodDeclaration},集合S′中的每一个节点都对应代码中的一条语句。对于嵌套语句C,C={FuncDef,While,DoWhile,Try,For,If,Switch},定义一系列独立节点P={block,body}。其中,block用于拆分嵌套语句的头和主体部分;body用于方法声明。对于所有的语句节点s,s∈S′,将s的后代定义为D(s)。节点d∈D(s),如果s和d之间存在一条路径通过节点p,p∈P,表明节点d被节点s中的一条语句包含,则称节点d为节点s的子语句节点。那么,以s为根的语句树是由s及其所有后代节点D(s)组成。按照语句树的定义,构造函数递归地创建语句树,并将其依次添加到语句树序列中。语句树序列的顺序蕴含了代码结构的层次化信息。
针对分割得到的语句树序列,将每棵语句树编码成向量。首先,经过Word2Vec训练符号嵌入向量,得到初始输入;其次,遍历语句树,并递归地将当前节点的符号作为新的输入进行计算,同时计算其叶子节点的隐藏状态。对于非叶子节点来说,以节点n为例:
(1)
式中:xn表示节点n的one hot向量;We表示预训练好的词嵌入矩阵。
(2)
式中:Wn∈Rd×k表示权重矩阵;C表示子节点的个数;hi为叶子节点的隐藏状态;bn表示偏置;σ(·)为激活函数;h表示更新后的隐藏状态。
由于每棵语句树子节点的个数不一致,计算叶子节点的隐藏状态时,为了利用矩阵运算进行批处理,使用ST-tree的动态批处理样本的算法[10]。
如式(3)所示,经过最大池化,可以得到每一个语句树最后的向量表示et,其中,N表示语句树的节点个数。
et=[maxhi1,maxhi2,…,maxhik],i=1,2,…,N。
(3)
1.2 Transformer的Encoder捕获全局信息
在RNN中,由于信息是沿着时刻逐层传递的,因此,当2个相关性较大的时刻距离较远时,会产生较大的信息损失。虽然引入了门控机制,如LSTM、GRU等,可以部分解决这种长距离依赖问题,但是它们的记忆窗口也是有限的。CNN善于捕获局部特征,如果想要捕获远距离特征,需要增加网络深度。Transformer完全基于自注意力,能够直接建模输入序列之间更长距离的依赖关系。综合考虑Transformer的性能与参数量,本文使用Transformer的Encoder提取全局的特征。
Transformer的Encoder部分捕获全局信息主要包含以下5个步骤。
步骤1 位置编码。输入为经过词嵌入后的张量,故只需对输入进行位置编码,位置编码的方法为
PE(pos,2i)=sin(pos/10 0002i/d);
(4)
PE(pos,2i+1)=cos(pos/10 0002i/d)。
(5)
X表示经过词嵌入后得到的张量,将词嵌入与位置编码相加,可以得到经过位置编码后的输出Y:
Y=X+PE(X);
(6)
步骤2 将向量Y作为输入,送入多层注意力机制层。注意力函数是基于3个矩阵(Q、K、V)同时计算的。
(7)
步骤3 通过残差连接和层归一化,使矩阵运算维数一致。将网络中的隐藏层归一化为标准正态分布,加快模型的训练速度和收敛速度。
Y′=Y+YAttention;
(8)
Y″=LayerNorm(Y′)。
(9)
步骤4 通过前馈层和2个线性映射层,使用激活函数来生成向量Yhidden。
Yhidden=σ(Linear(Linear(Y″)))。
(10)
步骤5 进行残差连接和层归一化,得到最终向量C1。
Y′hidden=Yhidden+Y″;
(11)
C1=LayerNorm(Y′hidden)。
(12)
1.3 CNN捕获全局信息
根据文献[13-15]的研究,CNN和self-attention在特征信息的提取上存在差异。self-attention焦点在全局上下文中决定在哪里投射更多的注意力,而CNN更多地关注所输入的局部特征信息。不同的模型和结构通常会学习到不同的特征[16],Transformer与CNN可以互补[17]。
借鉴ConvS2S[18],选取其中的卷积块结构,利用级联一维卷积获得代码行局部特征信息。如式(13)所示,每个卷积层包括一个一维卷积、一个门控线性单元(gated linear unit,GLU)和一个残差连接。
F=Y+GLU(Conv(Y))。
(13)
式中:Y表示CNN的输入,为经过词嵌入层和位置编码得到的向量,与Transformer的Encoder共享。Conv表示一维卷积层,其卷积核大小常设置为3。
最后,为了使卷积层输出的特征向量C2与上文中的向量C1具有相同维数,增加一个线性层网络:
C2=Linear(F)。
(14)
1.4 融合Transformer的Encoder和CNN学习到的特征
将Transformer的Encoder学习到的全局上下文特征与CNN学习到的局部代码特征表示相融合,相比以往的方法大多只用到单个模型学习代码特征,本文方法能充分挖掘代码信息。
Z=Concat(C1,C2)。
(15)
如式(15)所示,通过矩阵连接将2个特征向量进行合并,得到代码表示向量Z,相当于将CNN部分嵌入Transformer的Encoder中,通过设置layer的大小,可以实现Transformer的Encoder部分与CNN的堆叠。
考虑到不同语句的重要性直观上是不相等的,例如,ForStatement语句中的API调用可能包含更多的函数信息,因此,使用最大池化来捕获最重要的语义。该模型最终生成一个向量r∈R2m,它被视为代码片段的向量表示。
1.5 计算两段代码向量的相似度
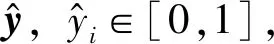
(16)
式中:Wo∈R2m×M为权值矩阵;bo为偏置。
二元交叉熵被用作损失函数。
(17)
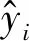
(18)
式中:δ为阈值。本文实验将δ设为0.5[10-11]。如果相似度阈值高于0.5,得到预测值为True,将代码对标识为克隆。
2 实验与结果分析
2.1 实验数据与评测指标
代码克隆检测使用的数据集包括OJClone和BigCloneBench,这2个数据集已被许多研究人员用于代码相似性检测和克隆检测[6,10-11]。OJClone数据集的标签分为2类;BigCloneBench数据集的标签分为5类,分别表示类型1至类型4的代码克隆,其中类型3的代码克隆分为强3型和中度3型。
数据集基础信息如表1所示。对于OJClone数据集,7 500个代码段组合可以得到超过2 800万个代码对,随机选取50 000个代码对构成实验数据集。对于BigCloneBench,59 688个代码段组合可以得到超过600万个真代码克隆对和超过26万个假代码克隆对。随机抽取了20 000对假代码克隆对,抽取中度3型和类型4代码克隆对共20 000对,类型1、类型2和强3型数量较少,均小于20 000对,以上全部加入实验数据集中。2个实验数据集中的数据均以3∶1∶1的比例随机划分为训练集、验证集和测试集。

表1 代码克隆检测数据集
代码克隆检测常使用混淆矩阵来评估模型的性能。所有指标的计算方式为
(19)
式中:Precision表示精度;Recall表示召回率;TP表示被分类系统识别为克隆的克隆对数量;FP表示被识别为克隆的非克隆对的数量;TN表示被识别为非克隆的非克隆对的数量;FN表示被识别为非克隆的克隆对的数量。
2.2 实验环境与参数设置
本实验的硬件环境为Inter(R)Core i7-8700K CPU、NVIDIA GeForce GTX 1080 Ti(discrete graphics)、RAM 32.00 GB。软件环境为Anaconda 3.6.0、Pycharm 3.4.0、Pytorch 1.6.0。使用pycparser解析C代码、Javalang解析Java代码得到AST;使用Word2Vec得到词嵌入表示;AdaMax为优化器。
经过反复多次实验,调整模型参数,直至得到性能最优的模型。详细的模型参数如下:Encodedimension为128;Embeddingdimension为128;Hiddendimension为256;Epoch为15;Batchsize为32;Numberofhead为8;Kernelsize为3;Numberofencoderblocklayer为6;maxlength为512;δ为0.5。
2.3 实验结果
2.3.1 模型结构分析
为了分析模型结构对代码克隆检测的影响,验证TCCCD中融合2个网络后提取特征的能力更强,设计了3种神经网络结构进行代码克隆检测比较,即TCCCD、CNN及Transformer的Encoder。
在OJClone数据集上进行实验,图2展示了经过每一轮训练之后,3个神经网络结构在OJClone验证集上的损失曲线。图3展示了3个神经网络结构在OJClone数据集上检测代码克隆的精度、召回率和F1值。可以看出,使用Transformer的Encoder和CNN相结合的结构,即TCCCD,相对于其他2个结构收敛速度更快。经过1轮训练之后,TCCCD在验证集上的损失值就降低到了0.126 8。在15轮的训练过程中,TCCCD每一轮验证损失值均低于另外2个网络结构。经过15轮训练之后,TCCCD结构的精度为98.9%,召回率为98.1%,F1值为98.5%。3个评价指标值均高于其他2个网络结构。
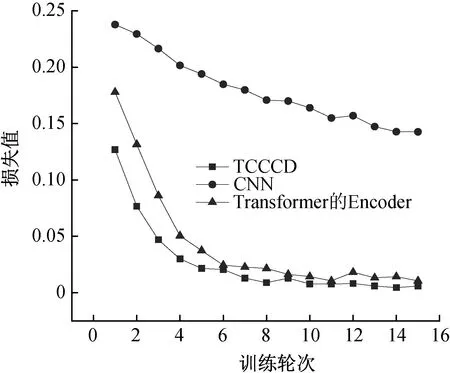
图2 不同神经网络结构在OJClone验证集上的损失曲线
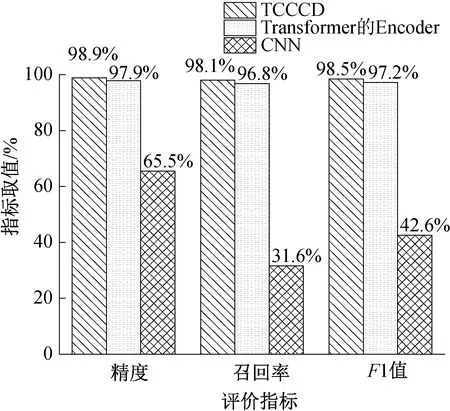
图3 不同神经网络结构在OJClone检测代码克隆结果
表2展示了不同神经网络结构在数据集BigCloneBench上对4种不同类型的代码克隆检测结果,其中,BCB-T1、BCB-T2、BCB-T4分别代表数据集BigCloneBench中的类型1、类型2、类型4,BCB-ST3和BCB-MT3分别代表数据集BigCloneBench中的强3型和中度3型。实验表明,在4种类型的代码克隆中,TCCCD方法精度、召回率及F1值均为最高。TCCCD相对于使用Transformer的Encoder部分或者CNN提取代码特征有优势,可以提高检测精度,同时降低误报率和漏报率。且TCCCD在识别BCB-T1和BCB-T2中2个代码片段的相似性方面都非常有效,因为除了不同的标识符名称、注释等,这2个代码片段几乎相同。而在其他代码克隆类型中,TCCCD检测效果稍有下降,尤其在BCB-T4中,检测精度可以达到99.3%,召回率却只有91.2%,F1值也只有93.8%。说明检测的假阳性率较高,有一些语义上相似的代码对并不属于代码克隆对。
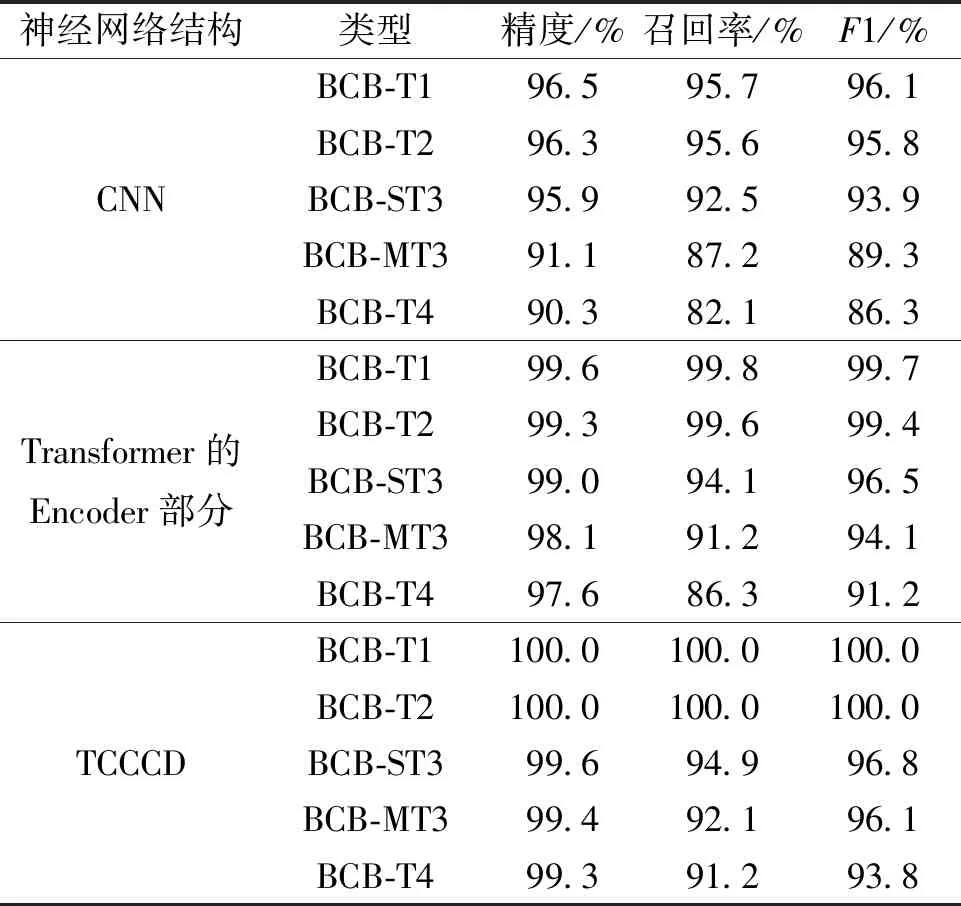
表2 不同神经网络结构在BigCloneBench数据集上对4种不同类型的代码克隆检测结果
实验表明,Transformer的Encoder部分和CNN学习到了不同的代码特征,2个网络相结合提取特征的能力更强。
2.3.2 各方法在2个数据集上的检测结果对比
表3展示了各模型在OJClone数据集上检测代码克隆的结果。可以看到,RAE和CDLH方法的精度和F1值都比较小,均低于60%。这是因为RAE基于token序列进行编码,无法有效学习到代码的结构特征。OJClone是由学生提交的编程题构造而来,一般很少引用第三方库,通常会定义i、j、k等没有意义的变量名。因此,CDLH虽然是基于AST,依旧会丢失很多词汇信息,只能捕获一些语法信息。ASTNN、At-BiLSTM、TCCCD检测代码克隆的效果较好,精度、召回率和F1值均高于90%。3种方法都基于语句子树进行编码,说明将大型AST切割成语句子树的方法有助于模型学习代码的结构信息、语句级的词法和语法信息。TCCCD在各项度量指标上均高于其他任何一个模型。在检测精度上,TCCCD与ASTNN均具有最高值98.9%;在召回率上,TCCCD比ASTNN高5.4百分点,比At-BiLSTM高2.8百分点,达到了98.1%;在F1值上,TCCCD比ASTNN高3百分点、比At-BiLSTM高出2.5百分点,达到了98.5%。Transformer的Encoder部分和CNN相辅相成,可以学习出融合代码全局信息和局部信息的稠密向量表示。TCCCD能提取到更多的词法、语法和结构信息来衡量代码的相似性。
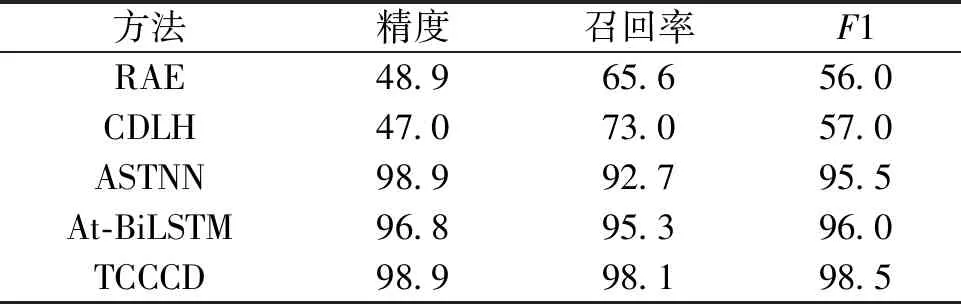
表3 各方法在OJClone数据集上的实验结果
表4展示了各方法在BigCloneBench上的检测结果。
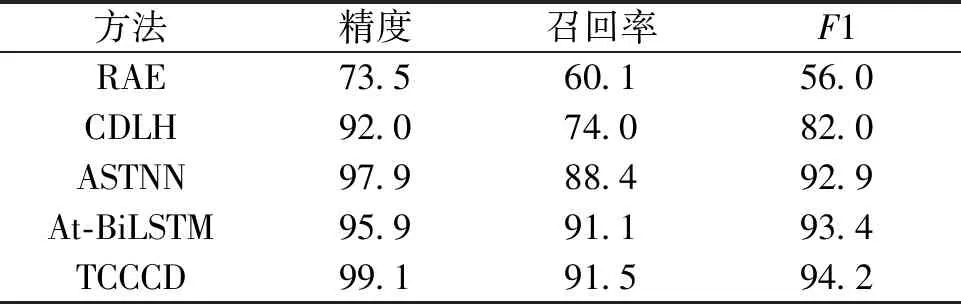
表4 各方法在BigCloneBench数据集上的实验结果
由于BigCloneBench包含4种代码克隆类型,所以最终的结果是根据4种类型的代码对数量加权计算得来。相较于OJClone数据集,RAE和CDLH方法检测效果均有提升,RAE的检测精度由48.9%提升到了73.5%,CDLH的检测精度由47.0%提升到了92.0%。这是由于BigCloneBench是从真实项目中挖掘到的,实现同一个问题时往往会用到相同的第三方库的类以及Java基础类。而ASTNN、At-BiLSTM、TCCCD检测效果稍有下降,原因是类型4的代码对占代码克隆对总数的一半以上。而类型4为语义相似的代码克隆对,有一些语义上相似的代码对并不属于代码克隆,致使假阳性率升高,使得召回率和F1值均有所降低。虽然上述3个方法在BigCloneBench上检测效果略有下降,但还是优于RAE和CDLH方法。
在检测精度上,TCCCD为99.1%,比ASTNN高出1.2百分点,比At-BiLSTM高出3.2百分点;在召回率值上,TCCCD比ASTNN高出3.1百分点、比At-BiLSTM高出0.4百分点;在F1值上,TCCCD比ASTNN高出1.3百分点,比At-BiLSTM高出0.8百分点,达到了94.2%。相比之下,TCCCD可以实现更高检测精度,同时降低误报率。
3 结论
本文构建了基于Transformer和卷积神经网络的代码克隆检测模型——TCCCD。为了解决AST过大带来的梯度消失问题,同时保留源代码的语法结构,将AST切割为多个语句子树。在神经网络设计方面,本文将注意力模型与CNN相结合来提取代码特征。TCCCD使用Transformer的Encoder来提取代码的全局信息,由于Transformer与卷积神经网络形成互补,再利用CNN模型,捕获代码的局部信息,进而学习出蕴含词法、语法和结构信息的代码向量表示。本文方法在OJClone和BigCloneBench数据集上进行评测,并与代表性代码克隆检测方法进行比较,精度、召回率、F1值均有提升。实验结果表明,该方法能够有效检测代码克隆。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
数学物理学报(2017年5期)2017-11-23
语文知识(2014年4期)2014-02-28
新课程学习·中(2013年3期)2013-06-14
