
开放场景下短时语音说话人识别系统的优化设计
2023-10-26 06:15郭新,邓爱文,罗程方等
南京信息工程大学学报 2023年5期
0 引言
说话人识别通过分析语音中的声纹特征来确认说话人身份,实现这一任务的关键在于如何从语谱图中提取具有足够区分性的说话人特征.说话人识别具有广泛的应用场景,如智能家居唤醒、用户账号登录和电话诈骗破案等.随着电子设备性能的提升,基于深度学习的说话人识别系统性能取得显著进步,但是在开放场景下短时输入语音的识别性能还有待提高,其核心在于如何改进帧级特征提取网络、特征聚合层和损失函数3个关键技术.
帧级特征提取网络方面,主流的网络有TDNN及其变体[1-2]和ResNet结构[3].TDNN系列网络能够提取时序依赖性强的特征,ResNet结构则利用二维卷积神经网络进行特征提取,且一般特征提取网络对输入语谱的不同频率没有区别对待,但并非每个频率范围的特征信息对说话人识别系统模型的确立同等重要,实际上低频率声纹特征具有更高的贡献度[4-5].Zhou等[6]在原始ResNet结构中加入SE(Squeeze-and-Excitation)模块,有效地增强了特征通道维度上的信息交互;Yadav 等[7]则是利用基于卷积的频域和时域注意力机制来进一步增强中间特征频域和时域的信息交互性.受此启发,本文提出一种基于重加权的特征增强层及网络.
特征聚合层方面,如基于注意力机制的特征聚合层Self-Attentive Pooling(SAP)[8]和Attentive Statistics Pooling(ASP)[9].而Luo等[10]则将视频理解任务中提出的NeXtVLAD应用到说话人识别中,显著提高了模型的特征聚合效果.
损失函数设计方面,现阶段主要使用基于分类的损失函数,如AMSoftmax[11]和AAMSoftmax[12],通过在余弦角度约束的分类边界上加入间隔(margin)裕度来约束同类别特征的角度变换范围,从而提高类内特征的紧凑性,但是它们都忽视了困难样本信息对于辨别性特征学习的重要性,且本质上是根据分类任务设计的损失函数,训练时目标函数与说话人识别任务本质需求存在一定的不匹配性.
本文改进说话人识别中的两大关键技术,设计出更有效的帧级特征提取网络和使得模型训练更充分的损失函数,进一步提升基于深度学习的说话人识别模型在开放场景下短时语音的识别性能.
1 说话人识别模型基本框架
目前主流的说话人识别算法是在基于embedding向量的深度学习框架下进行训练和测试的,整体框架如图1所示.

图1 基于深度学习的说话人识别模型框架Fig.1 Framework of deep learning-based speaker recognition model
训练阶段,原始语音信号经过声学特征提取模块得到声学特征.首先,将提取的声学特征输入到帧级特征提取网络中提取帧级特征序列;然后,利用特征聚合层从帧级特征序列中提取说话人的embedding向量形成语句级特征向量;最后,利用说话人标签计算损失函数来优化说话人embedding向量,使得类内距离尽可能小,类间距离尽可能大.测试阶段,将训练好模型输出的说话人embedding向量输入到后端打分模型,与注册数据库中的特征向量进行相似度打分,根据得分来判断两段语音是否属于同一个说话人.
2 基于重加权的特征增强层的帧级特征提取网络
2.1 基于重加权的特征增强层
从近几年国际大型公开的说话人识别挑战赛[13-14]中可以看到,基于梅尔频谱分析的特征如Fbank,仍然是最热门和最有竞争力的输入声学特征[15].在大多数的工作中,Fbank频域维度特征通常会被当成一个整体同等对待而没有考虑不同频率范围特征信息的重要性.然而,不同频率范围的特征信息对于说话人识别模型的性能影响是不同的[4-5].
基于此,本文提出基于重加权的特征增强层(Reweighted-based Feature Enhancement Layer,RFEL),对输入声学特征中不同频率特征赋予不同的重要性权重,RFEL的结构如图2所示.
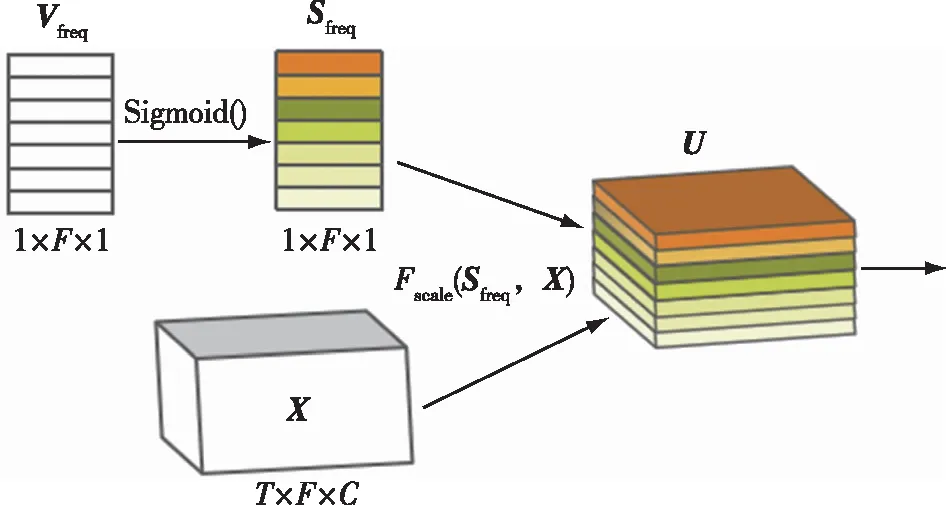
图2 基于频率重加权的特征增强层(RFEL)结构Fig.2 Structure of Reweighted-based Feature Enhancement Layer (RFEL)
从图2可知,RFEL结构是对输入特征的重要频率进行增强,它为输入特征频域维度上的每一维频率特征计算一个权重参数,并利用该权重参数与输入特征对应频率上的值相乘,得到频率重加权后的增强特征.图2中,输入特征X大小为T×F×C,这里的T表示输入特征的时域维度,F表示频域维度,C表示通道维度.Vfreq=[v1,v2,…,vF]表示频率权重向量,参数初值可任意设置,其后可以通过网络学习进行更新.向量Sfreq=[s1,s2,…,sF]是Vfreq经过Sigmoid()函数得到的向量,为的是将其权值限制在[0,1]范围内,维度均为1×F×1.Sfreq和Vfreq中每个参数是可由网络学习并更新的.
输入特征X与频率权重向量Sfreq对应频率特征权重相乘,得到频率重加权后的输出特征为U,维度为T×F×C,计算表达式如下:
U=Fscale(Sfreq,X),
(1)
其中,Fscale操作表示Sfreq中的每个权重值与输入特征X对应频率维度上的特征进行相乘.
RFEL设计目的是为了增强输入频谱特征的重要频域维度信息,让模型能够学会分析不同频率范围内特征的重要性.基于此,本文还将RFEL用到网络中进行网络中间频域特征增强.
2.2 基于重加权的特征增强网络
本文使用的是Fast ResNet-34模型结构[16].为了提高轻量化模型的特征提取能力,在Fast ResNet-34框架中加入SE[17]模块,构成Fast-SE-ResNet-34框架,可以通过注意力机制对网络中间输出特征的通道维度进行增强.
本文提出的基于重加权的特征增强网络(Reweighted-based Feature Enhancement Network,RFEN)结构如图3所示.输入的频谱特征首先经过RFEL进行频域维度特征增强,随后经过第一层卷积神经网络降采样为原来大小的一半,再输入到Fast-SE-ResNet-34框架下的4个特征提取阶段(stage)中.从图3中可以看到,RFEL可以放在每个stage中最后一个残差模块的输出之后,用来增强每个stage输出的中间特征,将最后一个stage输出的特征输入到特征聚合层中,则可提取到区分性强的说话人特征向量(embedding).

图3 基于重加权的特征增强网络结构Fig.3 Structure of Reweighted-based Feature Enhancement Network (RFEN)
随着网络加深,输出每个点的特征都与周围点特征存在大量信息交互,致使频率特征高度相关,并且部分频率特征在降采样过程中被转换到通道维度,此时再使用RFEL对频率特征进行细粒度分析会比较困难.因此,在设计基于多层RFEL的帧级特征提取网络时考虑每个stage后RFEL是可选的,本文在实验部分验证了模型在不同stage后加入RFEL后的效果,从而找到最优的网络模型结构.
3 组合损失函数
损失函数是为了训练能够让模型提取出区分性强的说话人特征的一组参数.文献[18-19]提出先用Softmax损失函数预训练再使用度量学习损失函数微调模型的策略;文献[20-22]提出基于Triplet loss的困难样本对挖掘策略;文献[23]将基于小样本学习的原型网络损失引入说话人识别任务中;文献[16]使用查询集与类中心之间的距离度量计算方式,将原始的欧氏距离替换成基于余弦相似度的距离度量,取得了优异的效果.
3.1 基于误分类样本挖掘的分类损失函数
误分类样本就是原本属于类A的样本,被误分类到类B中.误分类样本大多是难样本,是比较考验模型识别能力的样本.误分类样本对于提高模型特征区分能力有着至关重要的作用.
基于误分类样本挖掘的分类损失函数MVSoftmax表达式如下:
(2)
式中:e为自然常数,s为超参数(scale);x表示当前样本经过最后一层分类层的特征表示,即为当前说话人embedding;y表示当前训练样本真实类别标签;wk表示网络最后一层分类层的参数向量,k∈{1,2,3,4,…,K},K表示每批训练集中说话人总数;θwk,x表示参数向量wk和当前输入特征x之间的角度值;cos(θwk,x) 表示参数向量wk与当前输入特征x之间的余弦相似度;f(m,θwy,x)表示增加了间隔(margin)参数后的余弦相似度函数.
需要注意的是式(2)中的Ik,它是二值指示函数,表达式如下:

(3)
也就是说,当样本x与真实说话人类别对应参数向量wy之间的余弦相似度大于和非标签说话人k对应参数向量wk之间的余弦相似度时,说明样本x没有被误分类到说话人k中,此时函数Ik=0,否则Ik=1.
式(2)中,h(t,θwk,x,Ik)是一个用来对误分类类别进行加权的函数,可以表示为
h(t,θwk,x,Ik)=est(cos(θwk,x)+1)Ik,
(4)
其中,t≥0是预先设置的超参数,当t=0时,基于误分类样本损失函数就变为普通的基于间隔的损失函数.当Ik=0,即没有误分类时,h(t,θwk,x,Ik)=1;当Ik=1,有被误分类时,h(t,θwk,x,Ik)>1,这表示当前样本被误分类为类别k时,会进一步加大样本与类别k分类边界之间的间隔,使得说话人特征度量空间中当前样本特征与说话人类别k特征更加可分.
3.2 基于原型损失的度量损失函数
在小样本学习框架下,训练集和测试集都会被分为两个不重合的子集,即支持集和查询集,用xs和xq分别表示经过特征提取后的支持集和查询集样本中的说话人特征向量,原型损失函数便是小样本学习框架下的损失函数.基于余弦相似度的原型损失函数见文献[10,24],它可表示为

(5)
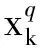
3.3 组合损失函数
分类损失函数能够优化的是样本与分类层参数向量之间的关系,属于实例—代理之间的关系,能够在训练阶段为模型提供较稳定的收敛曲线,而度量损失函数优化的是样本与支持集中真实样本的类中心向量之间的度量关系,属于实例—实例之间的关系.而说话人识别模型实质就是实例—实例之间的关系,度量函数更加符合说话人识别任务的实际应用场景.
文献[15,24]使用分类损失和度量损失的组合函数,本文将其进行优化升级,将难样本挖掘的分类损失函数融入其中,得到的组合损失函数如下:
LSR=LMV+αLAP,
(6)
其中:α为可学习的权重系数,可训练;LMV是基于难样本挖掘的分类损失函数;LAP是基于余弦相似度的原型度量损失函数;LSR代表说话人识别的组合损失函数.
4 实验结果及分析
4.1 实验设置
本文实验均在Ubuntu18.04.3 LTS、64 位系统下进行,所采用的深度学习框架是PyTorch,输入声学模型为80维的Fbank,实验中所有模型均使用Adam优化器进行训练,权重衰减率设置为5e-5,初始学习率为0.005,batch size大小设为256.数据集为VoxCeleb1,共包含1 251个说话人的153 516条音频,语音时长总计352 h,其中训练集包含1 211个说话人,测试集包含40个说话人.基准模型[10]为基于Fast-SE-ResNet34、NeXtVLAD特征聚合层和AMSoftmax loss+Augular Prototypical loss组合损失函数的模型.
4.2 评价指标
说话人识别任务中最常用的性能评估指标为等误率(Equal Error Rate,EER)和最小检测代价函数(Minimum Detection Cost Function,minDCF).
等误率EER定义为错误拒绝率FRR与错误接受率FAR相等时的错误率,EER越小说明系统的性能越好.表达式为
EER=FRR=FAR,
(7)
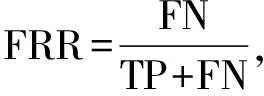
(8)

(9)
式中,FN 、TP、 FP和 TN所代表的含义如表1混淆矩阵所示.

表1 混淆矩阵
minDCF指标计算时考虑了实际使用过程中两种错误事件发生的代价,以及真实说话人和冒充者的先验概率,选择阈值使得DCF最小时的值为minDCF.计算表达式为
minDCF=Cfa×FAR×(1-Ptarget)+
Cfr×FRR×Ptarget,
(10)
其中,Cfa和Cfr分别表示错误接受样本和错误拒绝样本的权重,Ptarget和1-Ptarget分别表示真实说话人和冒名顶替者出现的先验概率,minDCF越小表示系统的风险系数越小,模型性能越好.
4.3 RFEL有效性实验
本节实验主要验证所提出RFEL的有效性,实验结果如表2所示.

表2 基于输入声学特征增强的频率重加权层实验结果
另外RFEL还可以放在帧级特征提取网络中增强网络中间特征的频域特征,不同stage下RFEL组合消融实验结果如表3所示.

表3 不同stage下RFEL组合的消融实验结果
从表2中可看出,多层RFEL结构的性能都超过基准模型.表3中,组合4 的EER为2.49%,minDCF为0.244,与基准模型(EER为2.73%,minDCF为0.298)相比,EER相对降低了8.8%,minDCF相对降低了18.12%,获得最好的性能指标,所以RFEL的数量和位置选择极其重要.
4.4 组合损失函数有效性实验
为验证组合损失函数的有效性,组合函数参数α与基准模型[10]中的参数一致,均设定为1.
由表4可知,使用MVSoftmax和AP组合损失函数后模型的EER比基准模型平均降低了12.45%,minDCF平均降低了14.09%.实验结果表明,使用基于误分类样本分类损失和小样本学习框架损失的组合损失函数训练的模型性能最好.
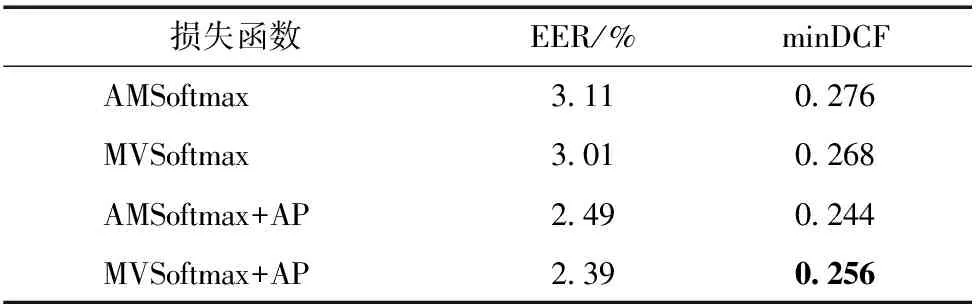
表4 损失函数对比实验结果
4.5 短时语音鲁棒性实验
不同音频时长下的测试实验结果如表5所示.

表5 不同音频时长下的EER测试实验结果
从表5中可以看出,在所有音频时长测试条件下,本文提出的模型均比基准模型的识别性能要好,尤其是对于短时音频(1~2 s)场景,ΔEER的值大于使用整段音频的测试场景,说明本文提出的改进方法能够进一步提升模型在短时语音下的性能.
5 结束语
本文针对开放场景下短时语音的说话人识别系统进行优化,对说话人识别架构中的特征提取网络和损失函数进行优化改进.通过一种基于重加权的特征增强层来增强特征表达,并将其嵌入到网络中来改善说话人特征提取网络中间特征的区分性表示.此外,还将人脸识别中的基于误分类样本损失函数首次引入到说话人识别领域,和原型度量损失函数融合进行模型的训练,解决了分类损失函数与说话人识别本质需求不匹配和度量函数对采样策略依赖性强的问题,大大提升模型的识别精度.实验结果表明,改进后的说话人识别模型性能更加优异.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
今日农业(2019年15期)2019-01-03
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
