
基于SK注意力残差网络的水下图像增强
2023-10-26 06:15陈海秀,刘磊
南京信息工程大学学报 2023年5期
0 引言
由于陆地资源的匮乏,海洋资源的开发利用越来越受到人们的重视[1].获取水下图像也成为海洋资源开发利用的关键.水下图像与普通图像成像不同,不同波长的光在传输过程中有不同的能量衰减率.波长越长,衰减速度越快.波长最长的红光衰减速度较快,而蓝光和绿光的衰减速度相对较慢,因此水下图像大多呈现蓝绿色偏.水下环境中微弱的暗光导致水下图像对比度低,水中悬浮物的散射导致水下图像细节模糊[2].如何解决水下图像的颜色失真、对比度低、细节模糊等问题是当前科研人员面临的主要挑战[3].
这些水下图像的解决方案可以分为两类,一类是基于传统的增强方法,另一类是基于深度学习的方法[4].
传统方法可分为两类,即基于非物理模型的增强方法[5]和基于物理模型的增强方法[6].非物理模型方法不需要考虑成像过程,这种方法主要包括直方图均衡化、灰度世界算法、Retinex算法等.直方图均衡化方法[7]能够均匀分布图像像素,在一定程度上提高了图像质量和清晰度.灰度世界算法[8],可以从图像中消除环境光的影响,增强水下图像.Fu等[9]提出基于Retinex的水下图像增强方法,在校正水下图像颜色的基础上,采用Retinex方法获得反射和照射分量,最终得到增强的水下图像.Ghani等[10]提出瑞利拉伸有限对比度自适应直方图,对全局和局部对比度增强图进行归一化处理,以增强低质量的水下图像.Zhang等[11]利用Retinex、双边滤波和三边滤波在CIELAB颜色空间对水下图像增强.Li等[12]采用最小化信息丢失和直方图分布的策略来消除水雾,增强水下图像的对比度和亮度.非物理模型的这类算法,算法简单实现速度快,但存在过度增强、人工噪声等问题.物理模型法的目标是建立退化模型,估计包含水下光和透射率的模型参数,进而反演退化过程对图像进行增强.最为经典的暗通道先验(DCP)算法[13],研究人员根据雾图像和成像模型之间的关系,得到光透射率和大气光估计值,进而对雾图像实现增强.水下图像一定程度上类似于有雾图像,因此DCP算法也被用于水下图像增强,但是此算法的应用场景非常有限.因此研究者提出专门针对水下环境的水下暗通道(UDCP)算法[14],它考虑了光在水下的衰减特性,能更准确地估计出光波在水中的透射率,实现水下图像增强.Peng等[15]提出一种水下图像复原方法,来处理水下图像的模糊和光吸收问题,该方法在大气散射模型中引入景深,采用暗通道先验的方法求解更准确的透射率,实现水下图像增强.基于物理模型的这类方法主要依赖于成像模型和暗通道先验知识[16],但由于水下环境的特殊性,导致这类方法存在局限性.
近年来,深度学习引起了广泛的关注,它的出现弥补了传统方法的不足[17].深度学习的方法可以减少水下复杂环境对图像的影响,达到更好的增强效果.基于卷积神经网络(CNN)[18]的模型和生成对抗网络(GAN)[19]的模型都需要大量成对或不成对的数据集.陈学磊等[20]提出了一种融合深度学习与成像模型的水下图像增强方法,通过对背景散射光估计,并结合成像模型进行卷积运算得到增强后的水下图像.Islam等[21]提出了一种快速水下图像增强模型(FUnIE-GAN),该模型建立了一个新的损失函数来评估图像的感知质量.Fabbri等[22]提出了一种基于生成对抗网络(UGAN)的方法,该方法增强了水下图像的细节,但UGAN使用欧氏距离损失,从而产生了模糊的实验结果.上述基于深度学习的水下图像增强算法,提升了算法的整体性能.由于水下图像严重的色偏,在算法训练稳定性,增强后图像细节、清晰度和对比度方面,仍有待进一步深入研究.
针对现有算法增强的水下图像存在颜色失真、细节特征丢失和关键信息模糊的问题,本文在生成对抗网络基础上,改进了生成器结构,引入了残差模块和SK(Selective Kernel)注意力机制.残差模块能够减少编码器和解码器之间的特征丢失,提取更多的图形细节特征,增强图像细节和校正图像颜色.SK注意力机制能够使网络动态融合不同尺度大小的特征图,从而增强图像的关键信息.采用参数修正线性单元(PReLU)来提高网络在训练过程中的拟合能力.通过对比实验、消融实验、细节实验和应用测试实验表明,本算法在主观视觉和客观评价指标层面均有良好表现.
1 生成对抗网络原理
生成对抗网络是一种深度学习模型[19].本文在此基础上进行改进,实现了水下图像增强.生成对抗网络包含两个模型:生成器模型G和判别器模型D.生成器将生成的虚假图像发送到判别器,而真实图像也发送到判别器.判别器判断输入的虚假图像和真实图像,将真实图像判断为“1”,将虚假图像判断为“0”[19].GAN的数学模型可表示为
Eh~Ph[log(1-D(G(h)))],
(1)
式中:V(G,D)为GAN的最终优化目标;E为数学期望;f为真实的图像;h为失真的图像;Pf为真实的数据分布;Ph为失真图像h下的数据分布;G(h)为生成器增强得到的图像;D(f)为判别器对真实图像和生成图像的判定.GAN模型框架如图1所示.

图1 生成对抗网络框架Fig.1 GAN framework
生成器和判别器交替迭代训练,相互博弈,最终达到纳什均衡状态.此时,将失真的水下图像输入生成器,就可获得增强的水下图像.针对水下图像颜色失真、细节特征丢失和关键信息模糊的问题,本文在GAN基础上改进网络.
2 本文方法
2.1 生成器网络模型
本文算法的生成器结构如图2所示,整体类似于U-Net[23].主要包括编码器、解码器、残差模块[24]和SK(Selective Kernel)注意力机制[25]4个部分.为了缓解编码器的低层特征和解码器的高层特征之间的细节特征丢失,采用残差模块,从而使增强后的图像细节纹理特征更清晰.为了更好地增强图像关键信息,动态融合不同尺度的特征图,引入了SK注意力机制,在每个残差模块间加入SK注意力机制.首先,输入水下图像到编码器,编码器的前3层由卷积层、BN层和PReLU层组成,对图像进行下采样操作,减小特征图的大小.接着输入到残差模块和SK注意力机制,提取更多的细节特征信息和关键信息.然后解码器对图像进行上采样操作,恢复真实图像大小.

图2 生成器网络结构Fig.2 Generator network
在卷积层的设计中,采用参数修正线性单元(PReLU)[26]来代替修正线性单元(ReLU)[27].
参数修正线性单元可以提高网络在训练过程中的拟合能力.参数修正线性单元和修正线性单元在式(2)中表示.
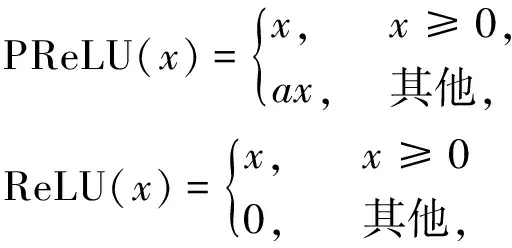
(2)
其中x是神经网络图中上每个位置的特征值,a是可变参数.与修正线性单元(ReLU)相比,参数修正线性单元(PReLU)避免了x为负时梯度变为零权重不再更新的现象,使得网络训练更加稳定.
2.2 残差模块
水下图像在下采样过程中可以缩小特征图的大小,减少参数的数量和计算量,但是会丢失图像的空间位置和细节.为了减少下采样过程中的图像细节损失,引入了残差模块[24].编码器特征是低级特征,解码器特征是高级特征,2个不相融的特征直接融合会存在语义差异,因此添加残差模块,可以在2个特征融合前达到相同的深度,以便平衡编码器和解码器之间的语义差异,达到增强水下图像细节特征的效果.
残差模块(ResPath)包含2个卷积(Conv)和2个激活(PReLU)操作.原来的3×3卷积不会直接传输到第2层卷积,而是通过一个1×1卷积添加到连接中,引入了更多的非线性,减少了细节特征丢失.残差模块的具体结构如图3所示.

图3 残差模块Fig.3 Residual path module
2.3 SK注意力机制
SK注意力机制[25]中的SK是Selective Kernel的缩写,表示选择性融合不同尺度大小的卷积核.SK注意力机制结构如图4所示,由Split、Fuse和Select 3部分组成.在Split部分分别对输入图像进行3×3和5×5的卷积操作,得到U1和U22个特征图.Fuse是计算2个卷积核权重的部分,将两者的特征图按元素求和,然后沿着H和W维度求平均值,得到一个C×1×1的一维向量,权重信息表示了各个通道信息的重要性.其公式为
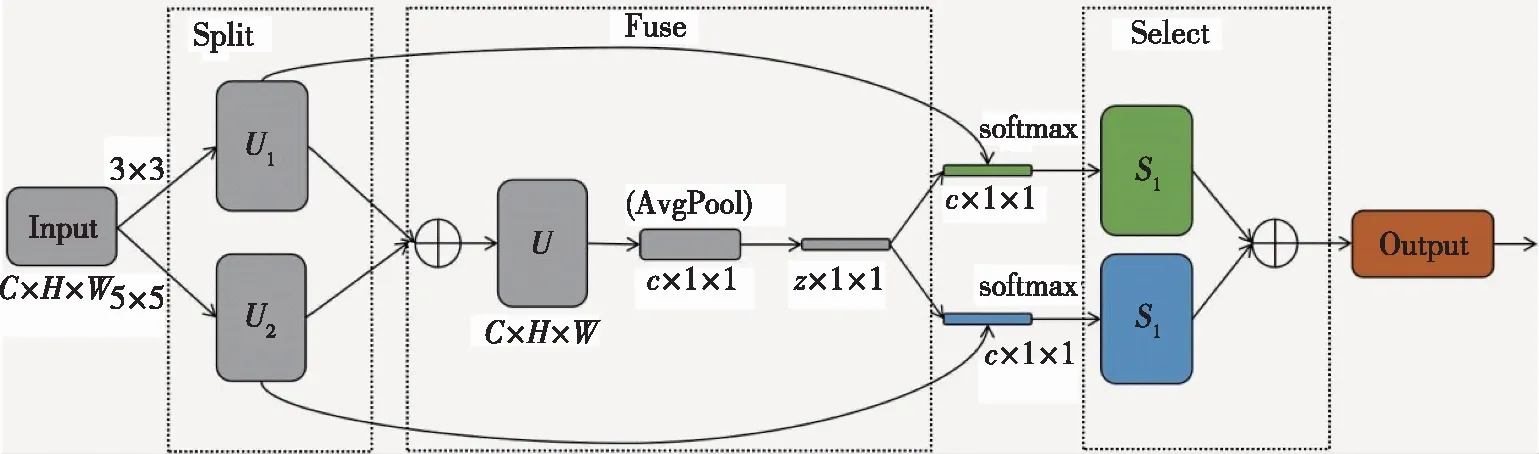
图4 SK注意力机制结构Fig.4 SK attention structure
U=U1+U2,
(3)
其中U是通过全局平均池化(AvgPool)生成的通道统计信息.接着采用一个线性变换,将原来的C维信息映射成Z维信息,然后分别使用2个线性变换,从Z维变成原来的C维,这样就完成了信息通道维度的提取.Select部分通过softmax函数进行归一化,计算出每一个channel对应的权重分数,并将权重应用到特征图上,最后将2个新的特征图进行信息融合得到最终的输出图像.输出图像对比于输入图像,经过信息通道的提炼,融合了更多的关键信息,增强了图像关键信息.
2.4 判别器模块
该算法中使用是马尔可夫判别器[22].判别器网络中,前4层都使用3×3的卷积核,通过4层卷积核实现下采样,减小特征图大小.D网络的前4层卷积层之后是BN层和LeakyReLU激活层.使用4个卷积层将256×256×6的输入(真实和生成的图像),转换为16×16×1的输出,最后取输出矩阵的均值作为真或假的输出.判别器网络如图5所示.
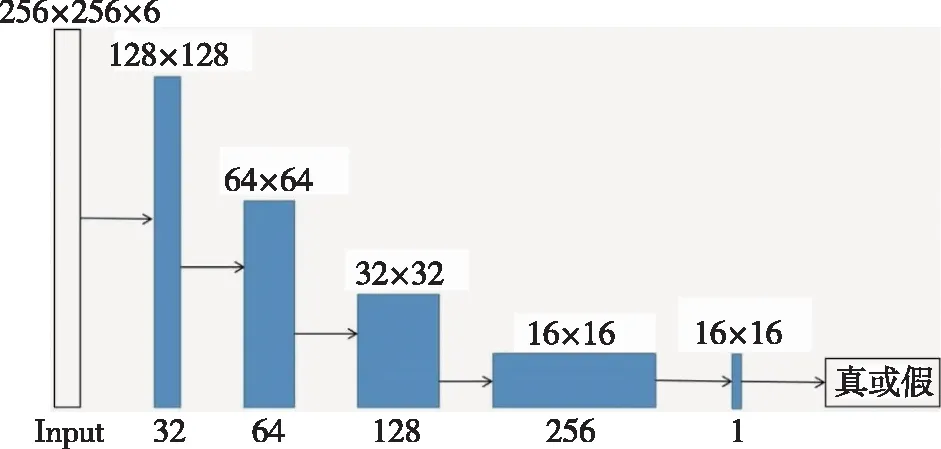
图5 判别器网络Fig.5 Discriminator network
2.5 损失函数
生成器通过判别器输出的判别数据连续反向传播,并在两者之间交替优化.损失函数是卷积神经网络的优化准则,根据不同的优化目标设置不同的损失函数.根据优化目标,本文算法定义了3个损失函数.
1)对抗损失:
Ladv(G,D)=EX~Y[logD(y)]+
EX~Y[log(1-D(x,G(x)))],
(4)
式中:Ladv(G,D)是生成器和判别器的最终优化目标;x为输入数据;y为参考数据;E表示期望;G表示生成器;D表示判别器;X表示真实数据的概率;Y表示伪数据的概率,它为生成器提供泛化功能.
2)L1损失:除了对抗性损失外,本文算法还引入了L1损失,保证了生成图像与真实图像内容的一致性.损失如下:
L1=E[‖IC-G(ID)‖1],
(5)
其中:IC为真实图像;ID是水下失真的图像.如果L1损失是唯一的优化目标,那么像素空间中像素的平均值将导致生成的图像中出现模糊伪像.
3)针对L1损失导致生成图像中模糊的问题,本文还引入了感知损失函数[28].感知损失基于卷积神经网络提取生成图像的特征映射和目标图像的特征映射之间的差异[28].使用感知损失可以减少高频特征丢失造成的损失.增强的图像细节纹理更接近真实图像.感知损失的定义如下:
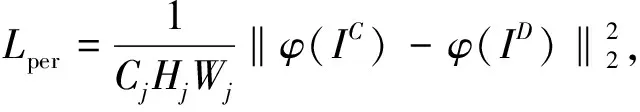
(6)
其中,Cj表示网络的第j层,CjHjWj表示第j层特征映射的大小,φ是预训练VGG19网络的最后一个卷积层提取的高级特征[28].
Ltotal=Ladv+αL1+βLper,
(7)
其中α和β分别是L1损失函数和Lper感知损失函数的权重.
3 实验结果与分析
3.1 实验设置
本文的实验配置环境是Intel i5 10400F处理器,2.4 GHz主频,16 GB内存空间和GTX3060 GPU.采用Pytorch编程框架.本文选择Adam作为优化器[29],并将学习速率设置为0.000 2,批大小为1,式6中L1损失的权重α为100,感知损失的权重β为100.采用EUVP[21]数据集对网络进行训练.EUVP是一个大规模数据集,由underwater_dark、underwater_imageNet和underwater_scenes 3部分组成.其中underwater_dark是一个包含成对的灰度图像和彩色图像的水下图像数据集,Underwater _imageNet和underwater_scenes都是包含成对的彩色低质量图像和高质量图像的水下图像数据集.从EUVP数据集中随机选取5 000对图像进行算法训练,8对图像进行算法测试.
3.2 对比实验
为了更好地验证算法的有效性,本文分别对合成数据集和真实数据集进行验证,采用应用测试实验、细节对比实验和消融实验进一步验证网络的增强效果,并从主观和客观指标评价2个方面进行效果分析.各种对比算法包括:3种传统方法(文献[8,14-15]);3种深度学习方法(文献[20-21,30]).
3.2.1 水下合成数据集增强效果分析
水下合成图像的测试数据集选自EUVP[21]数据集中的部分,本文算法与其他方法的比较如图6所示.图6显示了通过几种方法增强的水下图像,这些合成图像来自不同的场景.文献8算法(GW)是最常用的颜色平衡算法,颜色平衡算法可以在一定程度上消除环境光的影响获得原始图像,同时也带来了颜色的变化.文献[8]算法处理后的图像存在一定程度的红移现象.文献[14]为水下暗通道先验算法(UDCP),虽然该方法保留了图像的纹理特征,但由于大气光成分的存在,增强后的图像比原图像有更严重的蓝绿色偏.文献[15]算法(IBLA)处理的图像颜色饱和度过高,加重了颜色色偏.与传统方法相比,深度学习的方法增强的图像清晰度更好.文献[20]算法(Combining Deep Learning and Image Formation model)是一种融合图像成像模型和卷积神经网络的方法,在一定程度上提高了图像的亮度和清晰度,但同时产生了绿色色偏,且在图像边缘产生绿色伪影.文献[21]算法(Funie-GAN)增强了图像的真实色彩和清晰度,图像亮度也有了很大的提高,但一定程度上出现了红色偏差.文献[30]算法(CycleGAN)是一个无监督的网络,不需要成对的数据集,但增强的图像颜色背景较暗图像模糊,并且图像中存在蓝绿色偏差.与其他方法相比,本文提供的算法明显提高了图像的颜色、对比度和关键细节信息,在各种场景中的表现比较稳定.

图6 各算法在合成数据集上的增强效果对比Fig.6 Comparison of enhancement effect between various algorithms on synthetic datasets
本文选择结构相似性指数(SSIM)[31]、水下图像质量评价指标(UIQM)[32]、水下彩色图像评价指标(UCIQE)[33]和信息熵(IE)[34]4种指标进行客观评价.SSIM可以判断增强的图像和参考图像的相似度,SSIM值越接近于1表示增强后的图像与参考图像更接近[31].UIQM是专门针对无参考图像的水下图像评价指标,指标越大增强效果越好[32];UCIQE是水下色彩图像评价指标,主要包括图像颜色色度、饱和度和对比度,其值是图像颜色色度、饱和度和对比度的线性组合,值越大表示图像的清晰度、饱和度和对比度越好.从表1中可知本文算法增强后的图像在UIQM、UCIQE、IE和SSIM上指标均优于其他算法,说明本文算法增强的图像清晰度、对比度和细节特征更好.传统的水下图像增强方法与深度学习的方法相比效果略差.
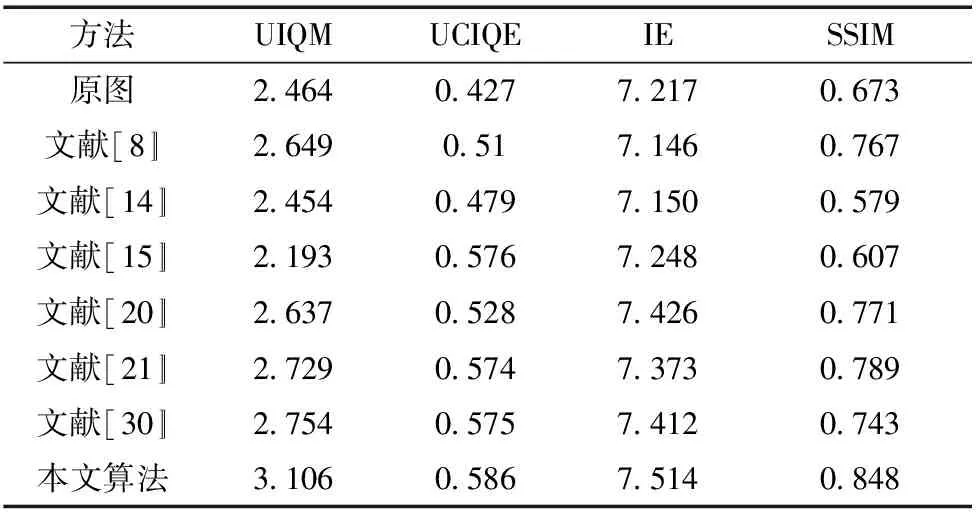
表1 合成水下数据集参考指标的评价结果
3.2.2 水下真实数据集增强效果分析
本文算法在真实水下图像上的增强效果如图7所示,真实水下测试图像分别选自模糊场景和蓝绿色场景.传统方法(文献[8,14-15])在增强模糊场景
和蓝绿色场景时,图像的清晰度有所提高,但图像分别出现了红色、绿色和蓝色色偏.深度学习方法(文献[20-21,30])一定程度上去除了雾感影响,但是都出现了颜色色偏,只有本文算法增强后的图像清晰度、色彩饱和度高,在模糊场景、蓝色场景和绿色场景中都能清晰地修复图像细节特征信息,图像颜色得到校正.
为了对水下真实图像增强效果的质量进行客观评价,本文选取UIQM、UCIQE和IE 3个指标进行分析.由于水下真实图像没有参考图像,所以没有选取SSIM等评价指标.如表2所示,本文算法增强后的图像在清晰度、色彩饱和度和信息熵含量上都优于其他算法,其中本文算法中的UCIQE指标远高于其他算法,并且得分均匀.从得分上看,深度学习的方法比传统方法增强的效果更好.综上所述,本文算法能够实现多种场景的增强任务,有着出色的泛化性能.

表2 真实水下数据集非参考指标的评估结果
3.3 消融实验
为了更好地验证残差模块和SK注意力机制对增强效果的影响,进行了消融实验,分别验证去除残差模块(ResPath)和SK注意力机制对评价指标的影响.实验结果如表3所示.

表3 去除各个模块对增强效果的影响
从表3可以看出,去除残差模块的图像UIQM、UCIQE和IE指标得分比去除SK注意力机制的图像指标分别低0.126、0.033和0.024.同时去除残差模块和SK注意力机制的指标得分是最低的.采用残差模块和SK注意力机制的算法指标得分是最高的.
3.4 细节对比实验
为了验证SK注意力机制对图像关键信息的增强效果,进行了细节对比实验.
图8a是原始图像,图8b是去除SK注意力机制增强后的图像,图8c是本文算法增强后的图像.通过对图像中细节部分放大分析,发现去除SK注意力机制的图像,细节增强效果较差,细节模糊.采用了SK注意力机制的本文算法,增强后的细节效果优于没有SK注意力机制的算法,关键细节信息更清晰.说明SK注意力机制能够动态融合不同尺度的特征图,提取图像的关键信息,增强图像关键信息.

图8 细节对比Fig.8 Detail comparisons
3.5 应用测试实验
本文采用Canny边缘检测[35]和SIFT特征点检测与匹配[36]来检验本文算法的增强效果.如图9所示,通过本文方法恢复的图像比原始图像检测到更多的边缘信息,边缘信息越多代表着细节特征越多.说明残差模块能够减少特征图在下采样过程中的特征丢失,增强了图像细节特征,校正了图像颜色,更好地保留了图像内容.通过SIFT特征点匹配实验可以发现,原始图像匹配到的特征点是5个,增强后图像匹配到的特征点38个,多于原图33个,说明了SK注意力机制能够动态融合不同尺度的特征图,提取图像关键信息.从这两组应用测试中,进一步验证了残差模块和SK注意力机制在水下图像增强上的作用.
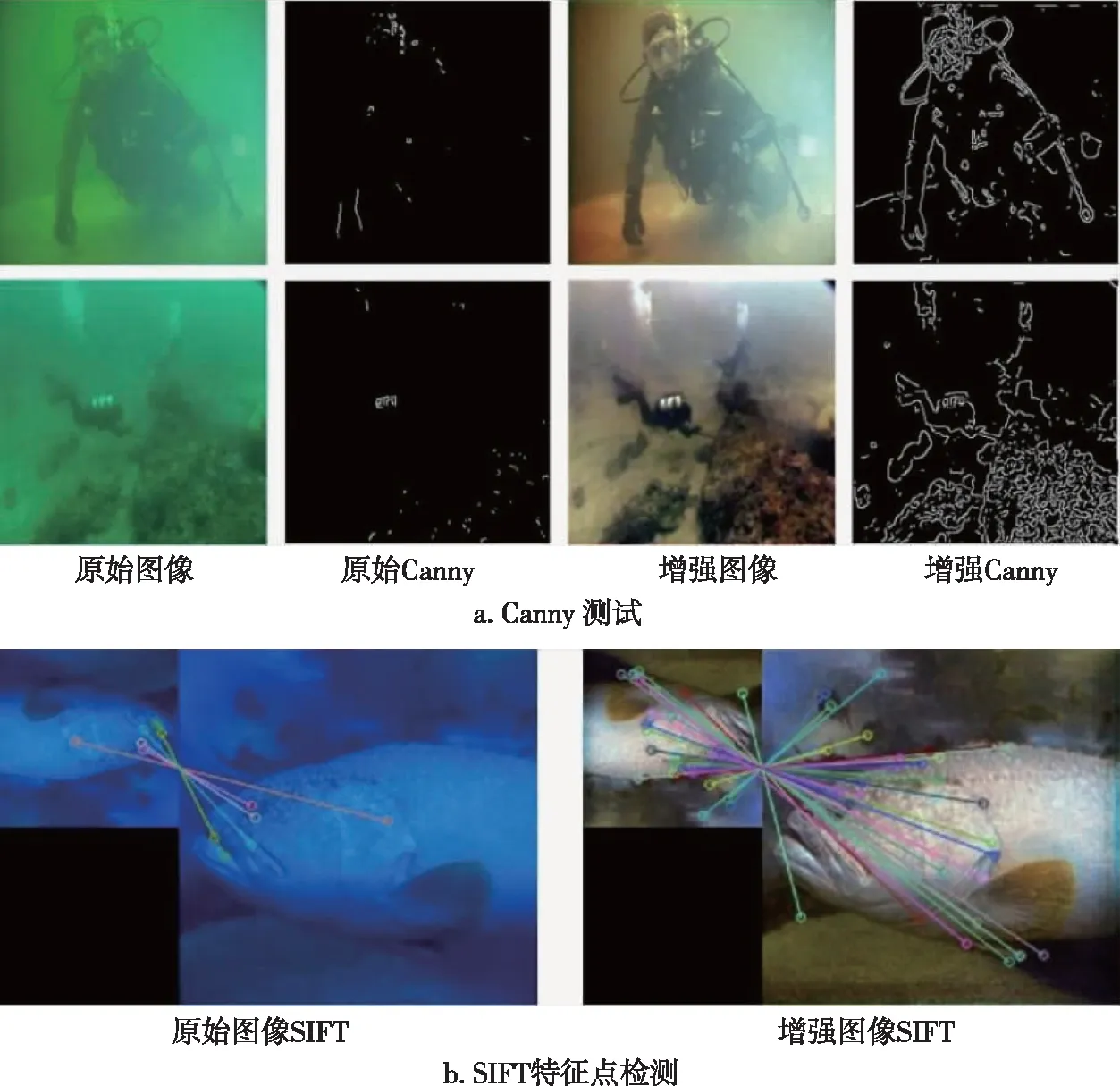
图9 应用测试实验Fig.9 Application tests
4 结论
本文提出了一种基于SK注意力残差网络的水下图像增强算法.为了减少编码器与解码器的细节特征丢失,在编码器和解码器间加入残差模块.为了使网络可以动态融合不同尺度的特征图,产生更好的关键信息增强效果,在每个残差模块后加入SK注意力机制.采用参数修正线性单元,避免了梯度为零的现象,提高了网络的拟合能力.在合成数据集上的实验结果,本文算法指标均高于其他算法指标,其中UIQM、UCIQE、IE和SSIM分别至少提高0.352、0.011、0.088和0.059.在真实水下图像数据上其指标UIQM、UCIQE和IE分别至少提高0.262、0.043和0.014.本文算法在两种数据集上均高于其他算法,说明算法的有效性.在真实水下图像数据集上对残差模块和SK注意力机制分别进行消融实验,本文算法比去除残差模块和SK注意力机制的算法,在UIQM、UCIQE和IE指标上分别提高了0.556、0.091和0.213.采用合成数据集训练网络,没有考虑真实水下环境的特殊因素,生成的图像在一定程度上与真实水下图像是有误差的.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国生物医学工程学报(2019年5期)2019-07-16
北京航空航天大学学报(2017年3期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
