
基于双注意力CrossViT的微表情识别方法
2023-10-26 06:15:40冉瑞生
南京信息工程大学学报 2023年5期
0 引言
微表情是人们试图隐藏自己真实情绪时不由自主泄露出来的面部表情,即使是专业演员也很难伪装.除了日常生活中普通的面部表情,在某些情况下,情绪也会以微表情的形式表现出来.与普通的面部表情相比,微表情的持续时间仅有1/25~1/3 s[1],并且参与的肌肉运动强度很微弱[2].因此,微表情可以被视为推断人类情绪的可靠线索之一,这使得它们在司法系统、刑侦审讯和临床诊断中得到广泛应用.
由于微表情识别的广泛应用性,近年来,研究者开展了大量的研究.这些研究主要分为基于传统机器学习的方法和基于深度学习的方法.在传统机器学习方法中,特征提取是影响算法性能的关键.局部二值模式(LBP)[3]是一种特征提取算法,它根据当前像素值对相邻像素进行阈值处理,有效地描述了图像纹理特征.此后,针对微表情识别任务还提出了多种LBP算法,如三正交局部二值模式(LBP-TOP)[4]和六交叉点局部二值模式(LBP-SIP)[5].Huang等[6]提出一种积分投影方法,将形状属性与时空纹理特征相结合,实现了微表情识别的判别时空局部二元模式(SLBP).此外,还存在两个时空描述符:主方向平均光流(MDMO)[7]和人脸动态图(FDM)[8].Liu等[9]进一步将MDMO纳入经典的图正则化稀疏编码中,生成了稀疏MDMO特征.马浩原等[10]提出平均光流直方图(MHOOF),提取相邻两帧间感兴趣区域的HOOF特征以检测峰值帧,将峰值帧和起始帧的MHOOF特征用于微表情识别.Liong等[11]提出了双加权定向光流(Bi-WOOF)特征描述符,将光流幅值和光学应变大小作为权值,生成人脸区域各块的方向直方图进行微表情识别.
传统方法需要繁琐的手工特征设计,而且微表情识别的准确率低.考虑到深度学习在面部表情识别中取得的良好表现,研究人员开始试图将深度学习应用于微表情的识别任务.Quang等[12]首次将胶囊网络(CapNet)[13]应用于微表情识别模型中,该模型设计简单,所需的训练数据很少,并且具有很强的鲁棒性.Lai等[14]则通过在VGG网络中添加残差连接,增加网络深度的同时也缓解了梯度消失的问题,在该研究中还使用了空洞卷积替换传统卷积,扩大感受野的同时也能够捕捉多尺度的上下文信息.Wang等[15]在ResNet网络上进行改进,在网络中添加微注意力提升模型对面部区域的关注,从而提升识别的精度.Liong等[16]提出一种利用光流特征进行微表情检测和识别的方法,它可以更好地表现精细、微妙的面部运动.在此基础上,Liong等[17]进一步提出了浅三流三维CNN(STSTNet),并利用光流特征训练网络.这些研究表明,由于微表情数据集样本数量小,浅层神经网络更适合于微表情识别任务.此外,Verma等[18]也试图通过递增的方式提取更显著的表情特征,来捕捉面部区域每个表情的微观层面特征.Khor等[19]引入长期循环卷积网络(ELRCN)模型用于微表情识别,该模型通过结合深度空间特征学习模块和时间特征学习模块对微表情特征进行编码.
目前主流的微表情识别算法一般是采用卷积网络提取特征.Zhao等[20]提出6层CNN网络进行特征提取.Khor等[21]提出一个轻量级的双流浅层网络,其网络整体由CNN组成.Zhi等[22]将CNN与LSTM串联起来,直接处理不同时长的微表情序列.
Transformer是一种主要基于自注意力机制的深度神经网络,最初应用于自然语言处理领域.受到Transformer强大的表示能力的启发,研究人员开始提出将Transformer扩展到计算机视觉任务.Ma等[23]首次将Transformer架构应用到表情识别中,在该网络中首先使用ResNet18提取输入图像的特征图,最后再放入多层Transformer编码器中进行分类.Zhang等[24]提出SLSTT网络,该网络结构将微表情序列光流特征送入到Transformer编码器中,通过LSTM架构对时间和空间特征融合后进行分类.刘忠洋等[25]基于注意力机制进行多尺度特征融合,证明了多尺度特征融合在图像分类上的有效性.
Chen等[26]提出一种双分支的Transformer分别提取不同尺度特征以及基于CrossAttention的融合机制融合不同分支的特征.对于视觉Transformer,通过改进自注意力机制能够有效提升网络的性能.Huang等[27]扩展了传统的自注意力机制,以确定注意力结果和查询结果的相关性.杨春霞等[28]提出的基于BERT与注意力机制融合的模型,表明Transformer架构在关于情感分析任务中有较好的表现.受上述文献启发,本文对于注意力机制进行了改进,以提升微表情识别精度.
Huang等[27]研究表明,Transformer编码器中的自注意力机制所提取的特征中包含了一些冗余和无用的特征信息,在微表情领域,这些冗余和无用的特征信息不利于后续的微表情识别任务.另外,由于微表情是一种面部运动幅度很低的情感表达,传统的卷积神经网络难以捕捉到这些细微的特征.而人们最近提出的多尺度网络较传统卷积网络能够捕捉更加细微的特征信息[25-26],以获得更加丰富的特征信息用于微表情识别.基于此,本文将交叉注意力多尺度ViT(CrossViT)网络进行改进并应用到微表情识别上,实验表明提出的方法取得了较好的识别效果.本文的贡献有如下几点:
1) 本文所提出的模型较早地将CrossViT网络应用到微表情领域,证明了其在微表情识别上的有效性;
2) 本文对CrossViT网络中原有的注意力机制进行了改进,提出了DA(Dual Attention)模块,该模块扩展了传统交叉注意力机制,确定注意结果和查询之间的相关性,以保留网络中有用的特征信息,从而有效提升了网络的识别性能;
3) 本文所提出的模型在CASME Ⅱ、SMIC和SAMM 三个数据集上均取得了良好的识别性能,验证了本文模型在微表情识别上的有效性.
1 相关工作
1.1 光流特征
微表情识别的早期研究方法主要是基于手工特征的传统机器学习方法.这些手工特征是利用设计好的特征提取算子提取对应的特征,并将特征送入SVM等分类器进行微表情分类.手工特征提取的方法可以分为两种:第一种是基于表观特征的方法,该方法考虑到图像的像素之间的关系并进行相应特征的提取,可以得到微表情序列的动态纹理信息,如LBP[3]、LBP-TOP[4]等;第二种是基于几何特征的方法,该方法考虑到图像局部特征区域和特征点的位移和形变,进行相应的特征提取.光流特征是一种基于几何特征的特征提取方法,其基于光流的特征描述符推断不同帧之间的相对运动,能为微表情识别捕获微表情连续帧之间的时间特征.
光流特征中的光流是指空间运动物体在观察成像平面上的像素运动的瞬时速度.其特征提取是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算相邻帧之间的运动信息,通过TVL1光流法可以计算出微表情序列中起始帧和峰值帧之间的水平和垂直光流矢量.光流应变代表的是人脸运动变化强度,能够作为加权方案,以突出每个光流的重要,从而减少了小强度的光流噪声.每个像素点的光流应变可以通过计算水平和垂直的光流矢量的平方和进行计算.
1.2 CrossViT
CrossViT是将两个不同分支的图像标记,通过交叉注意力进行类标记融合.CrossViT的整体网络架构如图1所示.该网络主要是由K个多尺度Transformer编码器(图1中黄色区域)组成,将光流特征图送入到2个不同尺度的分支中.

图1 CrossViT网络架构Fig.1 CrossViT network architecture
1) La分支对粗粒度的特征块进行操作,在该分支中,将原始光流特征图作为特征块输入,然后将特征块扁平成一维向量后通过投影函数得到更大的嵌入向量,并经过M个Transformer编码器进行特征提取;
2) Sm分支对细粒度的特征块进行操作,在该分支中,输入光流特征图被划分成4个大小相同的特征块,将每个特征块扁平成一维向量后通过投影函数得到更小的嵌入向量,并经过N个Transfomer编码器进行特征提取,其中M>N.
经过2个分支Transformer编码器提取的粗粒度与细粒度的特征信息送入到交叉注意力(CrossAttention)模块进行L次信息交互以获得更丰富的类标记,最后将2个分支的类标记拼接后输出,将得到的特征信息输入到分类器.
交叉注意力是CrossViT的重要模块,它是在自注意力的基础上提出的一种注意力机制.交叉注意力最早是用于Transformer的编码器和解码器的连接.不同于自注意力,交叉注意力能够将不同尺度、不同模态的特征进行关联,提升模型的性能.近年来,CrossViT在多尺度图像分类上取得成功,证明了交叉注意力机制可以处理不同形式的内容,并且能够融合不同尺度的数据.
考虑到微表情是细微的面部运动,将光流特征图划分为不同尺度的图像特征图,大尺度的图像特征图表示了微表情高层的语义信息,小尺度的特征图表示微表情低层的细节信息,将不同尺度的特征信息融合,有利于获得更丰富的特征表示.网络中的视觉Transformer相较于卷积神经网络具有全局感受野,并且其中的查询、键和值都依赖于输入数据,因此其具有自适应权重聚合的特性,能够获得更好的特征表示.
2 双注意力CrossViT
2.1 双注意力模块
CrossViT网络的最大特点是利用交叉注意力模块实现不同尺度的特征交互,获得更有代表性的特征信息.然而CrossViT原有的交叉注意力模块虽然能够将不同尺度的信息进行交互,但是交互后保留了很多无用的特征信息,不利于之后的图像分类任务.
本文对CrossViT的交叉注意力模块进行了改进,在该模块中额外增加一个注意力机制,改进的模块能够过滤掉无用的注意力结果,只保留有用的注意力结果,从而提升了微表情识别的精度.提出的双注意力模块(DA)如图2:用不同大小的方块表示不同尺度的特征块,用不同大小的圆圈表示粗粒度和细粒度的类标记.由Tranformer编码器输出的粗粒度的特征块和类标记和细粒度的特征块作为DA模块的输入,具体来说,La分支首先将自身的类标记与Sm分支的特征块连接在一起,如下式所示:

图2 DA模块Fig.2 Dual attention module

(1)
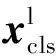

(2)
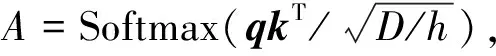
(3)
式(2)中,Wq,Wk,Wv∈RC×(C/h)是可学习的参数,D表示嵌入的维度,h是注意力头的数量.由于本模块只在查询中使用类标记,因此DA注意力操作中的注意结果A的计算和内存复杂度是线性的,使得整个操作过程更加高效.本文与注意力机制一样,使用多个注意力头,并且将其表示为多头双注意力模块(MDA).而为了扩展注意力机制,过滤掉无用的注意力结果,q向量经过线性变换和Sigmoid函数激活之后得到指导向量q′,该向量对注意力结果A进行指导,过滤掉无用的注意力结果后得到新的值向量v′.

(4)
DA(x′l)=q′v′,
(5)

(6)
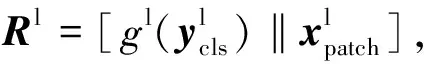
(7)
式(6)、(7)中,fl(·)和gl(·)是维度对齐的投影函数和反投影函数.
DA模块能够对来自La分支和Sm分支的信息进行充分融合,并且能够对注意力结果进行筛选只保留有用的特征信息,以进行后续的下游任务.如图3所示,本文将图1中的多尺度Transformer编码器(黄色区域)中的交叉注意力模块替换成DA模块,从而得到双注意力多尺度Transformer编码器.

图3 双注意力多尺度Transformer编码器Fig.3 Dual attention multi-scale Transformer encoder
2.2 双注意力CrossViT
本文在保持原CrossViT其他结构没有改变的基础上,将多尺度Transformer编码器里面的交叉注意力结构(CrossAttention)直接替换为本文提出的DA模块,以进行微表情识别.双注意力模块(DA)对于注意力结果能够进行有效的筛选,只保留有用的注意力结果.考虑到CrossViT的交叉注意力模块会对多尺度的特征信息进行交互,将会产生多个注意力结果.为了保留有用的注意力结果,本文将CrossViT中的交叉注意力模块替换为双注意力模块,从而提出了双注意力CrossViT,该网络有效提升了微表情识别的精度.
3 基于双注意力CrossViT的微表情识别
本文将上述提出的双注意力CrossViT架构用于微表情识别任务.由于双注意力CrossViT机构能将输入光流图划分为不同的尺度,多尺度的特征信息交互能够得到更丰富的特征表示,并且能够对信息交互的过程无用的特征信息进行筛选,从而能够得到更具有代表性的特征信息,以提高最终微表情识别的精度.基于双注意力CrossViT的微表情识别架构如图4所示,该架构总体分为3个部分:

图4 基于双注意力CrossViT的微表情识别架构Fig.4 Micro-expression recognition architecture based on dual attention CrossViT
1)对微表情数据集中的微表情序列进行预处理,预处理包括微表情原始样本序列的人脸裁剪和人脸对齐,并通过峰值帧定位算法定位出微表情序列中的峰值帧;
2)对微表情样本的起始帧和峰值帧进行光流计算,将得到的水平、垂直光流矢量及光流应变进行融合得到光流特征图;
3)将光流特征图输入到双注意力CrossViT网络中进行特征提取,之后通过Softmax进行微表情分类.
4 实验结果与分析
本文所有实验均在一台安装了Ubuntu 18.04.4操作系统的服务器上进行,CPU的型号为Intel(R) Core(TM) i7-10700 CPU @ 2.90 GHz,内存为16 GB,GPU的型号为NVIDIA 3090,显存大小为24 GB,CUDA版本为10.0.实验数据设置如下:批处理大小为256,最大轮次数为800,学习率取值为0.000 5,使用Adam优化器来优化模型.
4.1 数据集
本文使用3个独立数据集验证网络的分类性能,分别是CASME Ⅱ[29]、SMIC[30]和SAMM[31].3个独立数据集分类种类不一致,为了消除其种类不一致所造成的误差,需要对3个数据集进行预处理.
首先针对CASME Ⅱ数据集,其一共有5种情感类型,因此本文不使用其标签类型为‘others’的样本数据,将‘Repression’和‘Disgust’样本标签统一划分为标签‘Negative’.然后针对SAMM数据集,其一共有8种情感类型,本文将‘Fear’、‘Anger’、‘Disgust’、‘Sadness’以及‘Contempt’统一划分为标签‘Negative’,并且不使用标签为‘Other’的微表情样本.
为了验证数据集在不同性质数据集上的泛化能力,本文还使用了3个独立数据集抽样选择的融合数据集.本文使用MEGG(The Second Facial Micro-Expression Grand Challenge)提出的融合数据集划分规则,将从3个数据集抽样出一定比例的数据集样本,其样本抽样的情况如表1所示.

表1 融合数据集抽样
4.2 评估指标
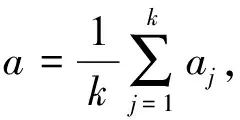
由于3个独立微表情数据集以及融合数据集都存在数据严重不平衡的问题,可以通过UF1和UAR这两个指标减少类不平衡的偏差,从而更好地衡量算法的性能.其中,UF1通过计算每个类别F1-Score的平均值确定,其计算公式如下:
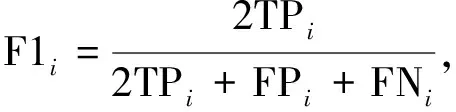
(8)

(9)
其中:TPi,FPi和FNi分别是微表情数据集中类别i的真阳性、假阳性和假阴性的数量;C是当前微表情数据的类别数量.UAR通过计算每个类别的平均准确率除以类数进行确定,其计算公式如下:

(10)
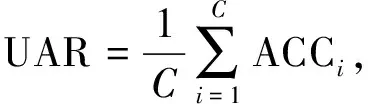
(11)
其中,Ni为类别标签i的样本总数.
4.3 对比实验
为了验证双注意力CrossViT网络在微表情识别上的有效性,本文在3个独立微表情数据集及融合数据集上进行了广泛的实验,并且和目前微表情领域的其他主流方法进行对比.本文的基准方法为LBP-TOP,其他方法(ATNET、CapsuleNet、SA-AT、STSTNet)为主流的深度学习方法.从表2可以看出,在融合数据集上,双注意力CrossViT网络的UF1指标达到了0.727 5,UAR指标达到了0.727 2,比基准方法分别提高了0.139 5和0.148 7.在CASME Ⅱ、SMIC、SAMM数据集上,相比于基准方法,本文网络的性能均有明显的提升.对比实验中主流的深度学习方法,改进的CrossViT网络也有明显的优势.在融合数据集和SMIC、CASME Ⅱ数据集上,双注意力CrossViT网络相较于其他方法达到了最好的性能,在SAMM数据集上,也取得了较好的性能表现,仅次于CapsuleNet.由于视觉Transformer需要大量的数据样本才能取得最好的性能,而SMIC和SAMM数据集样本数量较少,所以相较于其他数据集性能表现不太优秀.
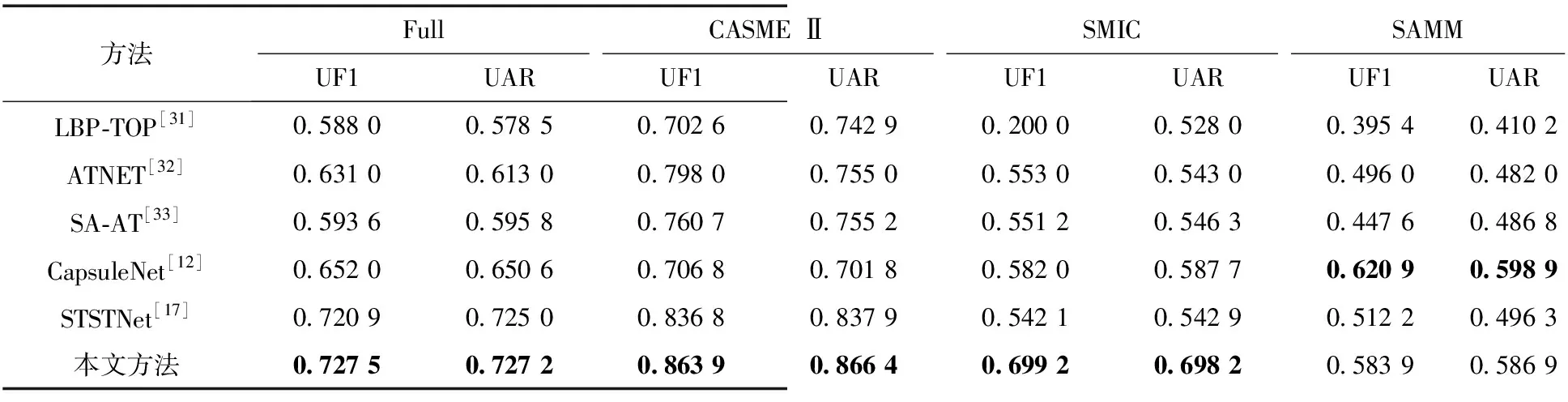
表2 对比实验结果
为了更好地对本文所提方法的有效性进行分析,在融合数据集和3个独立数据集上构造混淆矩阵,如图5所示.可以看出所提方法在CASME Ⅱ数据集的分类性能相较于其他3个数据集,其分类性能最好.由于SMIC数据集未标记实际峰值帧位置,因此峰值帧定位算法定位出的峰值帧位置与其实际峰值帧位置存在误差,并且SMIC数据集也存在分辨率低、帧数低的问题,因此其分类表现在4个数据集中是最差的.另外对于SAMM数据集,其数据集类别不平衡,消极类别在整个数据集中的样本数量最大,导致所提方法对于‘消极’标签的分类性能相较于其他两个分类标签表现更好.在融合数据集中,‘消极’标签的分类结果也是表现最好的.

图5 混淆矩阵Fig.5 Confusion matrices
为了验证实验参数设置对于算法稳定性的影响,本文在3个独立微表情数据集上通过设置不同的迭代次数进行实验,如图6所示,迭代次数设置在200到800之间时,算法的UF1和UAR指标曲线较为平稳,而且实验结果中两个指标的值高于表2中的主流算法的指标.
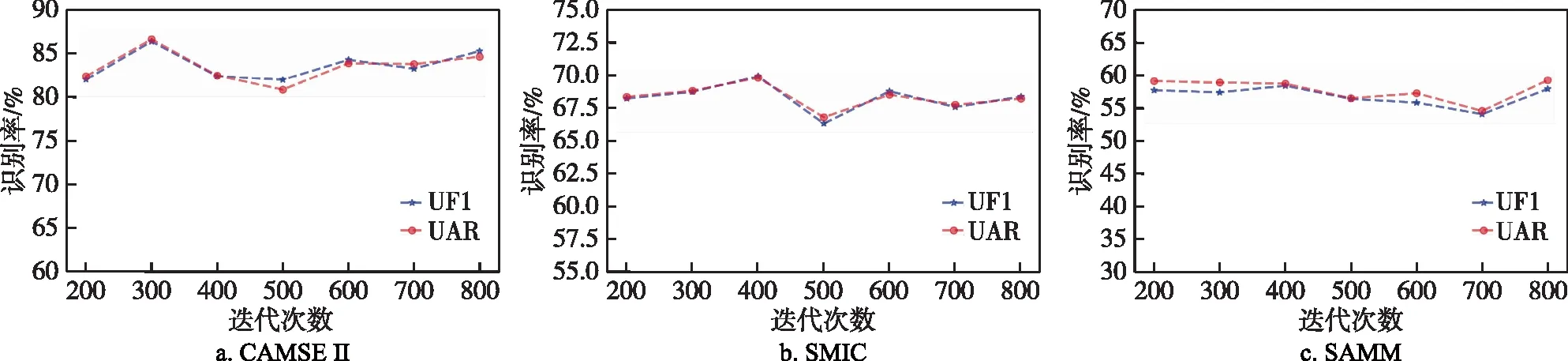
图6 迭代次数对网络识别率的影响Fig.6 Influence of iteration times on network recognition rate
由于CrossViT的La分支主要用于提取特征信息,Sm分支只是提供补充信息,因此2个分支中的不同分块数量会影响算法识别性能.为了验证CrossViT 2个分支的不同分块数量对于算法识别性能的影响,本文在3个独立数据集上进行实验,实验结果如表3所示.从表3可知,不同的分块情形,CAMSE Ⅱ数据集的UF1和UAR指标分布在0.8左右,SMIC数据集的UF1和UAR指标分布在0.6左右,SAMM数据集的UF1和UAR指标分布在0.5左右,3个独立数据集中,当La分支分块数量为1且Sm分支分支分块数量为4时,其实验结果最好.

表3 分块数量实验结果
4.4 消融实验
为了验证所提出的DA模块在CrossViT网络中的有效性,本文进行了针对DA模块的消融实验.实验细节是使用CrossViT原有的交叉注意力模块和本文所提出的DA模块进行比较,分析2个模块在融合数据集上的识别精度.实验结果如表4所示,本文提出的DA模块能够保留最有用的注意力结果,最终获得更好的特征表示.在融合数据集上,DA模块的UF1的指标为0.727 5,UAR的指标为0.727 2,性能较CrossViT原有的交叉注意力模块均有提高.

表4 消融实验结果
5 结束语
本文基于CrossViT为主干网络,对网络中的交叉注意力模块进行改进,提出了双注意力模块,实现了不同尺度的光流图像的特征融合并保留了有用的注意力结果,有效地提升了微表情识别的准确率,并且将起始帧到峰值帧的水平和垂直光流矢量及光流应变融合为光流特征图,通过多尺度的特征提取进行微表情分类.本文在3个独立数据集上和融合数据集上使用LOSO交叉验证法验证模型,实验结果表明,本文的方法在识别性能上相较于目前的主流深度学习方法都有了较为明显的提升.
未来的工作重点可以从以下方面进行提升:当前的微表情数据集规模小,应该使用GAN、迁移学习等网络进一步提升微表情数据集的规模;当前的数据集样本数量不平衡,应该进一步提升在样本类别不平衡情况下的网络识别精度.
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电光与控制(2018年10期)2018-10-13 08:19:00
数学物理学报(2017年5期)2017-11-23 07:51:31
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
中国铁道科学(2014年6期)2014-06-21 06:35:32
新课程学习·中(2013年3期)2013-06-14 05:55:20
