
基于阅读理解与图神经网络的篇章级事件抽取
2023-10-25 02:22:24张亚君谭红叶
中文信息学报 2023年8期
张亚君,谭红叶,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
事件抽取(Event Extraction)任务是从文本中检测事件类型以及识别对应的事件论元。事件抽取可以提供有价值的结构化信息,不仅能够应用到知识库构建、机器自动问答、文本摘要与生成等任务中,而且能够为金融、法律、医疗等领域提供辅助智能。因此,事件抽取受到众多学者的关注。
事件抽取分为句子和篇章两种级别的任务。以前的方法大多关注句子级别的事件抽取[1-6],即从单个句子中抽取事件及其论元。然而现实中的文本通常是由多句子构成的篇章,事件的论元分散在不同句子中,句子级别的模型不能对其进行建模。
如表1给出了篇章级事件抽取的实例。该实例是由多个句子组成的股份回购事件,该事件中的论元角色回购方 “恒逸石化”出现在第1句和第2句中,论元角色交易金额 “上限10亿元”和论元角色每股交易价格“上限15元/股”出现在第2句及第3句中。如果不考虑事件元素间的相互关系,将不能很好地针对该事件进行信息抽取。

表1 篇章级事件抽取实例
因此,许多学者开始面向篇章级的事件抽取方法进行研究[7-13]。对于事件元素候选识别,大多数模型将其当作序列标注任务来解决,如Zheng等人[8]、Xu等人[9]利用Transformer[14]对句子编码,使用条件随机场(CRF)进行序列标注,但是这类方法没有利用论元角色本身的先验信息,忽略了论元角色语义信息和论元间的重要联系。对于论元分散问题,研究者尝试利用不同方法整合跨句信息。如Yang等人[7]对关键句子识别事件类型及其对应论元,再从邻近句中寻找事件相关的论元;Zheng等人[8]将句子位置信息和事件元素信息融合,得到实体篇章级表示;Xu等人[9]通过图神经网络对句子和事件元素间的关系建模,但是上述方法仍然缺少对句内事件元素间的句法依存信息建模,对篇章级事件元素间关系建模不够全面。
为了解决上述问题,本文提出了一种基于阅读理解和图神经网络的篇章级事件抽取方法。该方法首先通过构建包含角色释义信息的问题融入先验信息,把事件元素候选识别当作阅读理解任务来解决;然后基于图神经网络对事件元素的句内直接依存关系或间接依存关系和句间相同元素关系建模,获取聚合篇章的表示;最终进行事件类型和论元分配。在百度金融数据集(DuEE-fin)上验证了本文所提方法有效性,与最好基线相比F1值提升了3.8%,取得显著效果,在中国金融数据集(ChinFinAnn)上的实验也取得了最好效果。
1 相关工作
事件抽取是自然语言处理领域的一项基本任务,一直受到研究者的关注。
之前大多学者关注的是句子级别的事件抽取。例如,基于深度学习方法,Chen等人[1]使用卷积神经网络流水线模型,分别进行触发词识别和论元识别;Nguyen等人[2]使用循环神经网络联合模型同时提取触发词和论元;Xiao等人[3]通过图卷积网络来对图信息进行建模,从而联合抽取多个事件触发词和论元;Du等人[5]以问答的方式端到端地提取事件。但上述方法都是针对单句进行事件抽取,很难满足篇章级事件抽取的需求。
近期篇章级事件抽取成为研究热点。该任务主要面临两个挑战: ①事件论元分散在不同的句子中; ②一个篇章中可能包含多个事件。针对这两个挑战,Yang等人[7]从中心句识别事件类型及其论元,并从相邻句中分别找到事件的其他论元填充到事件记录表中;Zheng等人[8]提出的端到端DOC2EDAG模型,使用Transformer来融合句子和事件元素的表示,生成有向无环图实现事件抽取。Xu等人[9]提出GIT模型,通过卷积神经网络,对句子和事件元素间的关系进行建模,生成带有追踪器的有向无环图进行事件抽取。Yang等人[10]提出的DE-PPN模型,通过限制记录查询的数量来并行生成事件记录。Huang等人[11]提出的SCDEE模型基于图注意力网络,利用事件元素关联和句子关联构建图表示。Huang等人[12]使用深度价值网络(DVN)捕捉跨事件依赖,同时进行事件元素抽取、事件共指和事件元素共指。最近Zhu等人[13]提出的基于剪枝完全图的端到端PTPCG模型,以非自回归的方式加速对事件记录的解码,取得了有竞争力的效果。但上述方法仍存在篇章级事件元素间关系建模不全面的问题,因此本文通过句法依存信息有效对篇章级事件元素关系进一步建模。
机器阅读理解作为一种通用方法[15],成为处理不同问题的范式。许多自然语言处理任务的基本技术,如关系抽取[16]、命名实体识别[17]、事件抽取[5-6]、指代消解[18]等,都可以通过使用阅读理解方法取得很好的效果。但是Du等人[5]和Liu等人[6]提出的阅读理解模型针对的是句子级别的事件抽取,因此本文通过构建问题,使用BERT编码[19]基于序列标注方式来回答句子中的事件元素答案,有效利用角色先验信息,同时提取篇章级文档中论元角色的所有事件元素。
2 模型与方法
本文模型结构如图1所示,主要包含: 事件识别、事件元素候选识别、图结构、论元分配等4个模块。各模块的主要功能如下:
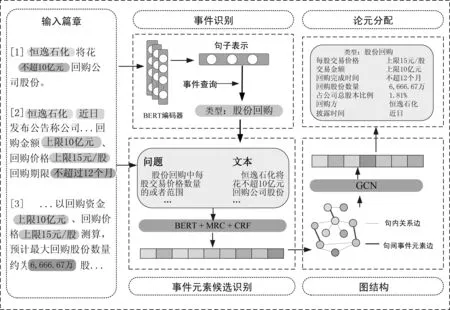
图1 本文所提模型框架示意图
(1) 事件识别模块: 通过BERT得到句子编码,并进行多标签分类以识别事件类型。
(2) 事件元素候选识别模块: 通过结合事件对应的论元角色信息,根据不同模板构建问题,基于阅读理解方法预测出篇章中的事件元素片段。
(3) 图结构模块: 使用图神经网络对篇章级事件元素间的关系建模,得到事件元素的特征表示。
(4) 论元分配模块: 通过特征相似度构建事件元素组合,对组合分配事件类型,对论元角色分配事件元素。
2.1 事件识别
由于一个篇章可以有多个不同类型的事件,所以我们把事件识别作为多标签分类任务,利用整个篇章的表示来进行事件分类。
u=BERT(s)
(1)
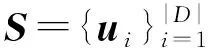
其中事件查询向量Q∈T×dm和W*∈2×dm是可训练参数,T表示事件类型的数目,P为篇章表示,R为事件类型的概率分布。
通过argmax函数取R中的每行最大值索引位置形成事件识别的最终结果列表Otype,计算如式(4)所示。
事件类型检测的损失函数如式(5)所示。

2.2 事件元素候选识别
该模块通过阅读理解的方式来进行事件元素候选识别。输入是事件类型识别结果Otype,输出是实体集合E。
对于识别到的事件oi,(oi∈Otype),利用该事件类型已知的角色信息(事件类型及其对应论元角色示例如表2所示),具体使用以下3个模板构建问题。

表2 事件类型及其论元示例
模板1直接使用论元角色作为问题,如披露时间、发行价格。
模板2基于论元角色及其所属的类型(时间、地点、数量和其他)形成疑问句作为问题。
模板3利用论元角色的详细语义信息形成问题。
具体示例如表3所示。
根据不同模板构建问题q后,分别结合篇章D中的每一句话s作为预训练模型BERT的输入。具体输入形式如式(6)所示。
input=[CLS]+q+[SEP]+s+[SEP]
(6)
对输入input通过预训练模型BERT得到对问题和文本的表示,计算如式(7)~式(8)所示。
其中,U∈n×d,n为整个输入的长度,d为向量的维度。
由于一个论元角色可能对应多个不同的论元(如高管变动事件中,高管姓名角色通常对应多个不同的论元),因此,不同于计算答案开始和结束位置的阅读理解任务(即抽取类阅读理解任务),得到句子序列表示s′后,利用条件随机场(CRF)对每个字符进行BIO序列标注,来预测句子的标签。
使用论元对应的角色作为标签,结合CRF来得到损失Lner,具体计算如式(9)所示。
其中,ys是篇章D中句子s的黄金标签。在解码阶段,我们使用维特比算法使用最大化概率解码预测序列得到事件元素标注结果,从而识别出对应位置的片段,构成事件元素集合E。
2.3 图结构
我们通过图神经网络对篇章D中的事件元素构建异构图G,建模篇章级表示。
为了获取事件元素间的关系,我们构建了两种边:
(1)句内关系边如果一个句子中两个事件元素存在直接或者间接的依存句法关系时,则在两个事件元素间构建连边。这是因为如果事件元素间存在直接的依存关系,或者存在多跳的间接依存关系,则这些事件元素很可能属于同一事件。
(2)句间事件元素边如果同一个事件元素出现在多个句子中,则在该事件元素间构建连边。构建句间事件元素边有助于从全局角度对长距离论元进行建模。
构建异构图G之后,使用多层图卷积网络来建模事件元素间的交互。具体运算如式(10)所示。

2.4 论元分配
该模块对得到的事件元素进行组合,并对这些组合匹配事件类型,对组合中的事件元素分配论元角色。我们使用与Zhu等人[13]类似的论元角色分配方法,具体包含两个步骤:
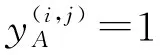

(11)

(2) 对组合匹配对应的事件类型,对组合中事件元素分配论元角色。将识别到的事件类型oi,(oi∈Otype)与组合集C执行笛卡尔积,得到所有的事件类型组合对{
训练损失计算如式(12)所示。
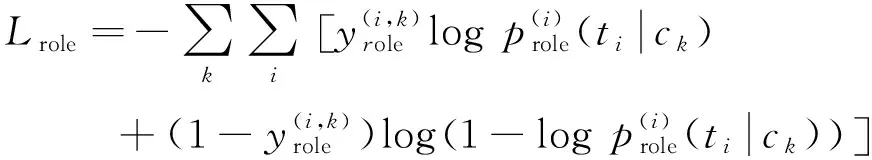
(12)
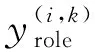
3 实验结果与分析
3.1 数据集与实验设置
本文采用的是百度发布的金融领域篇章级事件抽取数据集DuEE-fin[20]和中国金融数据集ChinFinAnn[8]。DuEE-fin数据集包含11 900个篇章,事件类型包括股东减持、股东增持、企业收购、企业融资、股份回购等13种事件类型。其中测试集是在线评估的(1)https://aistudio.baidu.com/aistudio/competition/detail/46/0/task-definition。ChinFinAnn数据集包括32 040个篇章,涉及股份冻结(EF)、股份回购(ER)、股份减持(EU)、股份增持(EO)、股份质押(EP)等5类金融领域股权活动事件。实验中训练集、验证集、测试集的比例为8∶1∶1。
预处理使用斯坦福发布的自然语言处理工具Stanza对数据分词、依存句法分析等进行预处理。
实验设置使用BERT-base-Chinese预训练语言模型进行事件检测和事件元素候选识别,使用与Zhu等人[13]相同的词汇表。使用Adam优化器,学习速度为5e-4,最小批次大小为64,进行100个epoch的训练,并在验证集上选择F1得分最高的检查点在测试集上进行预测,其中DuEE-fin在线评测得出测试集分数。
3.2 实验结果
3.2.1 对比实验
实验中,选取的基线模型主要有:
DCFEE[7]包含两个模型。DCFEE-O只从一个文档中提取一条记录,而DCFEE-M在单句抽取的基础上得到包含大多数事件及其论元,再从中心句的邻近句中进行论元补全。其事件元素候选识别使用BiLSTM+CRF进行。
Doc2EDAG[8]将记录构造为论元链(DAG),并使用自回归方法提取最终结果。其事件元素候选识别通过Transformer+CRF进行。
GIT[9]是Doc2EDAG的变体,利用GCN图神经网络进一步对事件元素进行编码,并在DAG生成中添加更多特征。
PTPCG[13]是Doc2EDAG的快速轻量级改进模型。在事件元素候选识别阶段,该方法通过正则表达式来匹配更多的金额、日期、比率实体来增强识别效果,使用BiLSTM+CRF进行序列标注实现识别。
实验采用具体评价指标为: 准确率P(Precision)、召回率R(Recall)和F1值。
事件抽取整体结果如表4和表5所示(结果使用模板3来构建问题)。
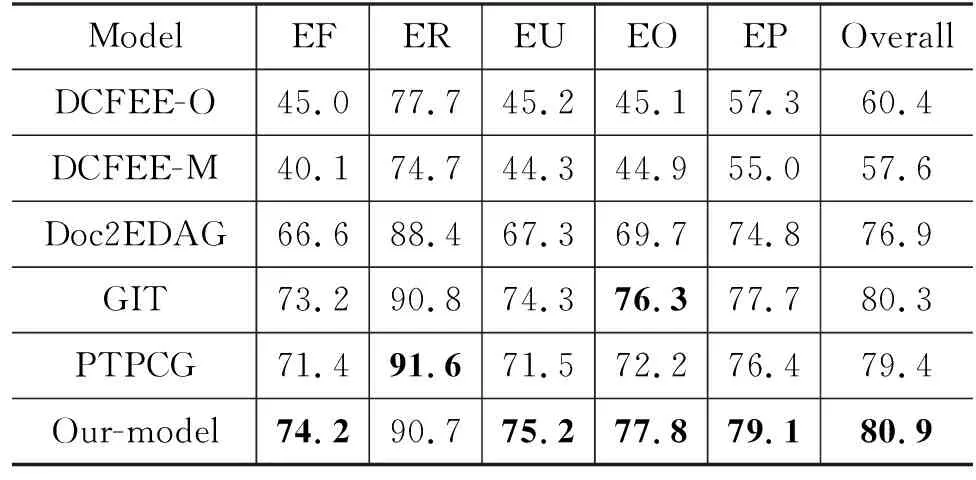
表4 ChinFinAnn事件抽取整体实验结果 (单位: %)
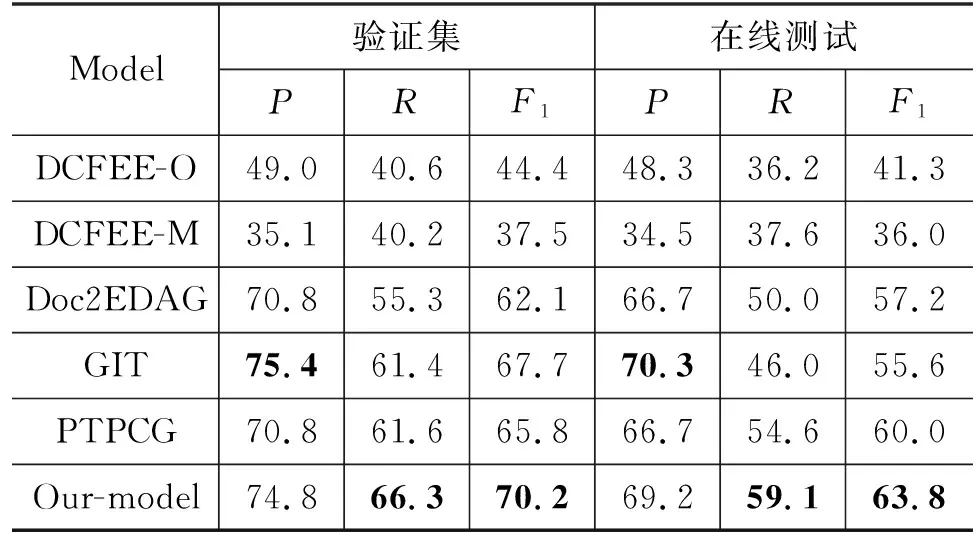
表5 DuEE-fin事件抽取整体实验结果 (单位: %)
从整体实验结果可以看出,本文模型在DuEE-fin数据集上召回率R和F1值均取得了最好的分数,在线测试中,比次优模型PTPCG的召回率和F1值分别提高4.5%和3.8%,说明利用论元角色的先验信息和篇章级事件元素间关系对系统性能提升有明显作用。尽管准确率略P低于GIT模型,但是取得了和其他模型性能具有竞争力的效果。模型在ChinFinAnn数据集上整体性能上(Overall)效果最好,并且在4类事件中取得了最高值。
事件元素候选识别结果如表6和表7所示。在DuEE-fin数据集上除了与基线模型比较,Our-model-mrc将预训练语言模型BERT作为编码器进行序列标注,不使用阅读理解框架效果就得到了明显的提升,说明预训练语言模型的有效性,Our-model在此上基础上使用阅读理解方式,通过引入论元角色的先验信息,使得模型更加聚焦文本中的事件元素,取得了最好的效果。在ChinFinAnn数据集上。本文提出模型也取得了最好的效果。
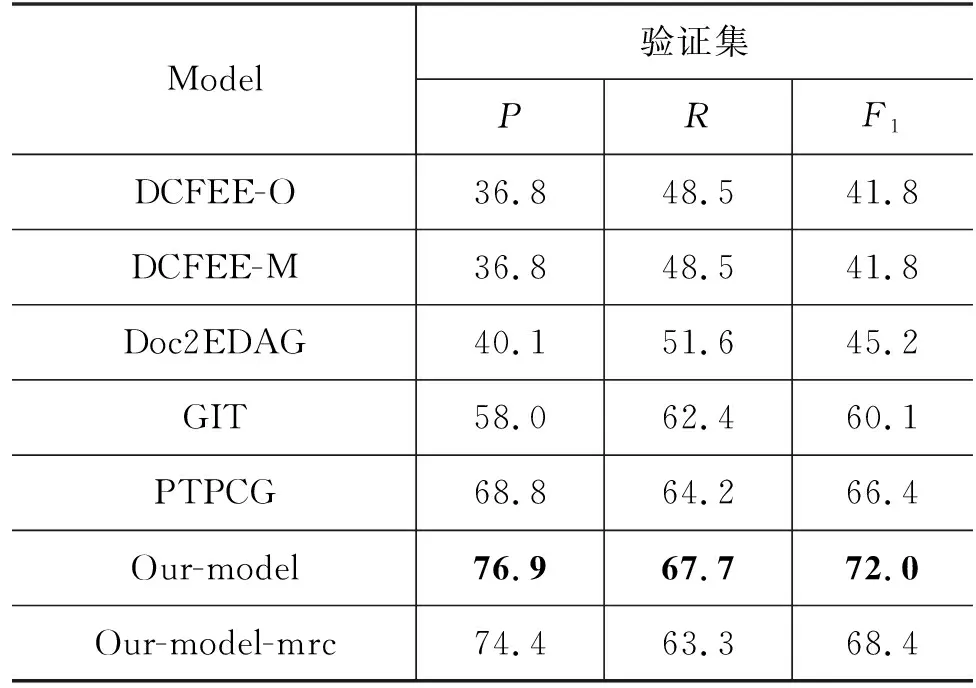
表6 DuEE-fin事件元素候选识别结果 (单位: %)

表7 ChinFinAnn事件元素候选识别结果 (单位: %)
3.2.2 消融实验
我们在DuEE-fin数据集上深入分析不同问题模板、图神经模块及其不同边对性能的影响。
不同问题模板对性能的影响在验证集上的实验结果如表8所示。模板1的问题生成策略只考虑了论元本身的语义信息,但是不同事件中相同的论元角色的语义可能有着很大的区别。模板2对论元角色的类型进行进一步描述,使得模型能够聚焦文本中事件元素的类型。模板3使用自然语言的形式对不同事件类型中的论元角色语义进行描述,使得模型更准确地聚焦与问题相关的事件元素,实验结果表明模板3的效果更好。
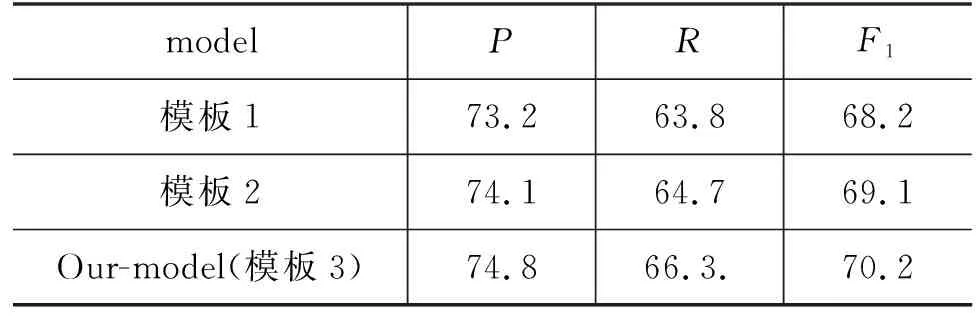
表8 不同问题模板对性能影响 (单位: %)
图神经模块及其不同关系边对系统性能的影响在验证集上的实验结果如表9所示。结果表明图模块有着重要作用,完全去除图模块降低1.6%的性能,表明图模块能够聚合篇章级信息表示。去除句内依存关系边,系统性能降低1%;去除句间事件元素关系边,系统性能降低0.8%。说明了两种关系边对篇章级事件抽取的有效性。
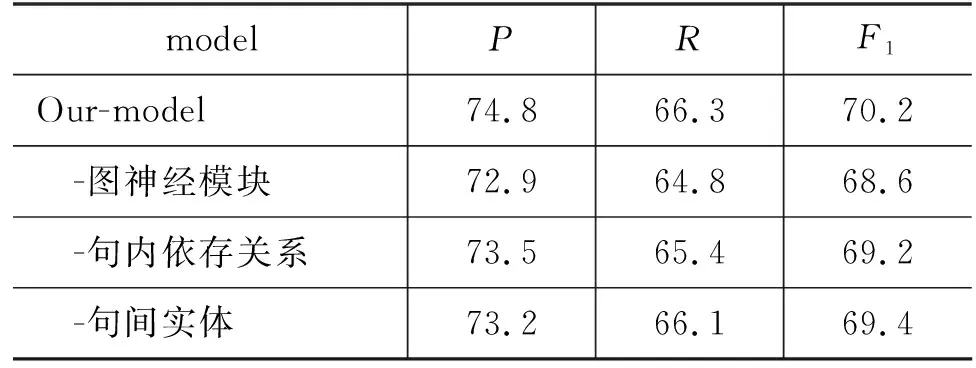
表9 图神经模块对性能影响 (单位: %)
3.2.3 案例分析
为了进一步说明本文所提方法的效果,表10中的实例展示了两个股票减持事件,其中论元角色包括减持方、交易完成时间、披露时间等。基于LSTM+CRF的PTPCG模型没有识别出股票代码(“430630”“1019370”)和股票简称(“福莱转债”),而本文模型能正确识别是因为通过阅读理解模型加入了论元角色的先验信息。PTPCG模型没有正确识别出减持方“阮泽云”对应事件中的披露时间“7月13日晚间”,而本文模型对句子2进行依存关系连边如图2(灰色部分为候选事件元素识别结果)所示,其中“7月13日晚间”通过(“7月13日晚间”“称”“占”“收到”“通知”“女士”“女士”“阮泽云”)多跳有向依存关系与“阮泽云”建立连边,有效建模属于同一事件的事件元素。PTPCG模型没有正确识别减持方“阮泽云”对应事件中减持部分占总股份比例,而本文通过图结构的句间候选元素边,有效建模“阮泽云”与“1019370”“7.03%”的长距离关系。

图2 实例句内依存信息
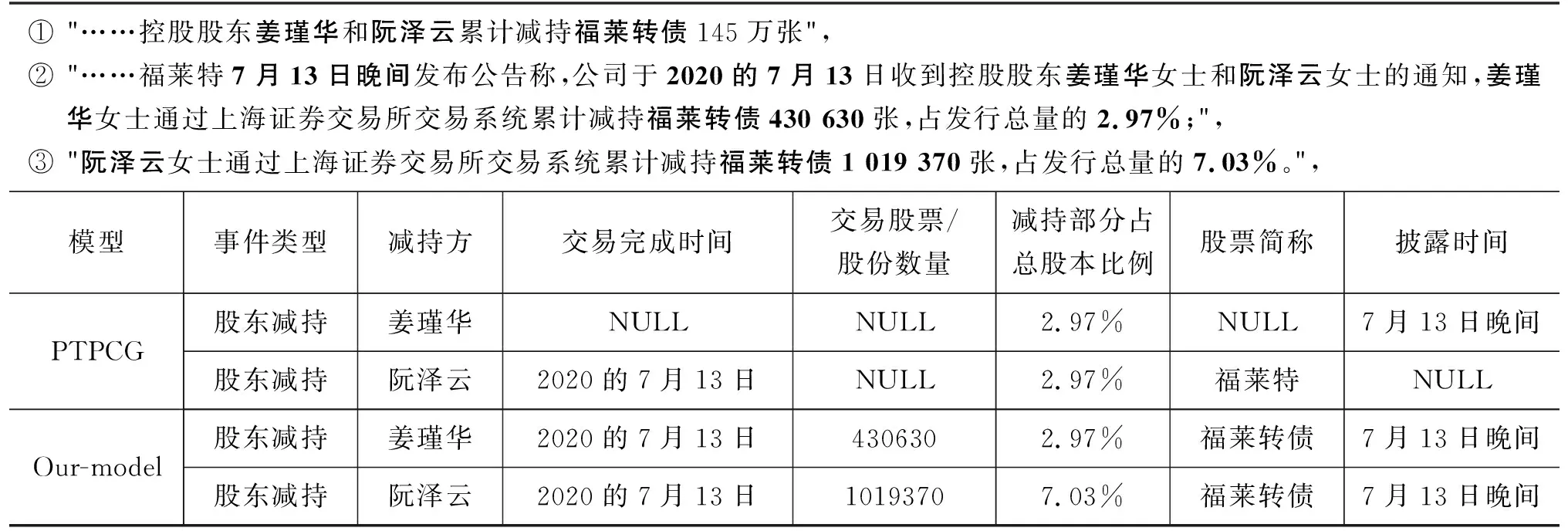
表10 实例分析
4 结束语
为了在篇章级事件抽取中有效利用论元角色的先验信息,获得篇章级的事件元素表示,本文尝试使用阅读理解框架来进行事件元素候选识别,通过不同的问题构建模板形成问答,从而引入论元角色的先验信息,在上下文中回答相应的问题抽取事件元素;然后通过图神经网络进行篇章级聚合表示,在句内利用句法直接依存关系或者间接依存关系、句间事件元素联系构边。实验结果证明了方法的有效性。
虽然阅读理解方式做篇章级事件元素抽取有着更好的效果,但由于对每个事件论元角色构建问答,导致样本数量扩充,使得运行效率低下。样本构建、运行效率和将阅读理解作为统一框架将是下一步的研究方向。
猜你喜欢
建材发展导向(2022年23期)2022-12-22 07:30:02
建材发展导向(2022年12期)2022-08-19 02:33:10
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
中国房地产业(2016年24期)2016-02-16 06:10:20
中国卫生(2015年9期)2015-11-10 03:11:10
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
