
基于词典注入的藏汉机器翻译模型预训练方法
2023-10-25 02:22:00桑杰端珠才让加
中文信息学报 2023年8期
桑杰端珠,才让加
(1. 青海师范大学 计算机学院,青海 西宁 810000;2. 青海师范大学 藏语智能信息处理及应用国家重点实验室,青海 西宁 810000)
0 介绍
目前神经机器翻译(Neural Machine Translation,NMT)[1-3]已经成为最主流机器翻译方法,在性能上全方位超越传统短语统计翻译模型(Statistical Machine Translation,SMT)[4],并成为工业界机器翻译服务系统的标准实现方法[5],甚至研究者声称在特定领域和语言对上NMT的性能可以接近甚至超越人类的翻译水平[6]。与SMT不同的是,NMT以端到端风格的建模方式将翻译决策过程视为单个条件概率模型的参数估计过程,从而摒弃了SMT不同组件独立优化各自训练目标的建模范式。但是目前NMT卓越的性能表现是以具备大规模、高质量和多领域对齐数据为重要前提的,受制于市场规模较小、数据标注成本高昂等客观因素,现阶段藏汉机器翻译的质量距离汉英等主流语言存在巨大的差距。
在对齐数据受限的条件下,对于多数语言,单语数据的来源相对较为广泛且容易收集,研究者自然地探索了各类在NMT框架内有效利用目标端和源端单语数据的方法。其中最简单和直接的是回译方法[7],该方法利用监督式方法训练一个初始的反向模型,将目标端的单语数据进行翻译,用于扩充训练正向模型的数据。回译方法不仅能改善低资源场景下的翻译性能,同时在富资源场景中也能缓解领域适应等问题[8]。回译方法要求初始回译模型本身有较高的性能,但是在现实中很多低资源语言的对齐数据无法保证初始回译模型的性能。
近年来,受到计算机视觉研究的启发[9],在未标注的海量文本数据、高阶的分布式优化方案、强大的序列学习模型和高性能计算加速设备的共同加持下自监督式预训练(Self-supervised Pretraining)模型[10-12]激起了自然语言处理(Natural Language Processing, NLP)领域内的研究热潮。预训练模型使研究者可以不用从头训练昂贵和复杂的大规模模型,直接使用现有预训练模型在下游目标任务上结合任务自身特点进行微调,就往往可以获得比监督式训练更好的性能表现。在诸多的预训练模型中,具有代表性的包括掩码语言模型(Masked Language Model, MLM) BERT[10]、自回归语言模型(Autoregressive Language Model, ALM) GPT[13]、置换语言模型(Permuted Language Model, PLM)XLNet[14]、降噪自编码器模型(Denoising Auto Encoder,DAE)BART[15]等。其中BERT和XLNet语言模型是Transformer[3]的编码器,能对语言序列进行双向的表示学习,主要用于序列的语义理解。GPT 使用了Transformer的解码器,结合已生成的解码片段和当前时刻的输入,以自回归的方式逐词生成目标序列,而BART模型可以视为结合BERT和GPT泛化的预训练模型,与BERT和GPT不同的是,BART模型采用序列到序列的建模方式,使用单个Transformer模型对编码器端完成各类加噪操作的输入序列在解码器端完成重构,通过降噪自编码为优化目标,完成整个解码器和编码器的联合预训练,然后在下游的目标任务上通过标注数据进行微调,非常适合于机器翻译和知识问答等采用编码器-解码器构架的建模任务。BART是针对单一语言(英语)的预训练,而随后提出的mBART[16]则是将BART的建模方式扩展到多语言场景下,完成多语言模型的预训练。同样是采用BART训练目标的M2M-100[17]更是进一步扩大了所覆盖的语言种类,支持100个语言之间的多对多翻译。对于藏文这种低资源语言而言,多语言预训练是一个非常具有吸引力的设想,因为除了支持多语言翻译外,M2M-100级别的大规模预训练模型本身能够有效支持通用语义知识的迁移。但是mBART和M2M-100的训练都没有包含藏文。本文旨在探索训练BART风格的藏汉翻译预训练模型的有效方法,为后续的藏语多语言翻译课题提供研究基础。
BART在预训练过程中主要学习当前输入语言的表示和分布,缺乏双语对齐监督信号的直接参与,没有显式地学习语言对之间的映射关系。这种预训练方式不利于平行资源匮乏的藏汉语言对的预训练效果。考虑到双语词典是重要的先验知识来源,人类语言学习者在学习一门新语言时,往往会借助双语词典探索所要学习的语言,通过词典建立新语言和其他已掌握的语言之间的关联。人类翻译人员也会使用双语词典推敲用词、查询专业词汇,以改善翻译工作的质量。此外,受到跨语言交流过程中使用混合语言往往能够增加沟通效率[18]这一现象的启发,本文提出了一种基于双语词典注入的藏汉预训练翻译模型的训练方法,即基于词典注入的藏汉机器翻译预训练模型(Pretrained Translation Model with Dictionary Injection, PTMDI)。通过构建较大规模的双语词典,然后利用词典对大规模的藏汉单语数据进行跨语言数据注入,以降噪自编码为训练目标完成藏汉机器翻译模型的预训练。词典的数据注入如表1所示。

表1 词典的数据注入样例
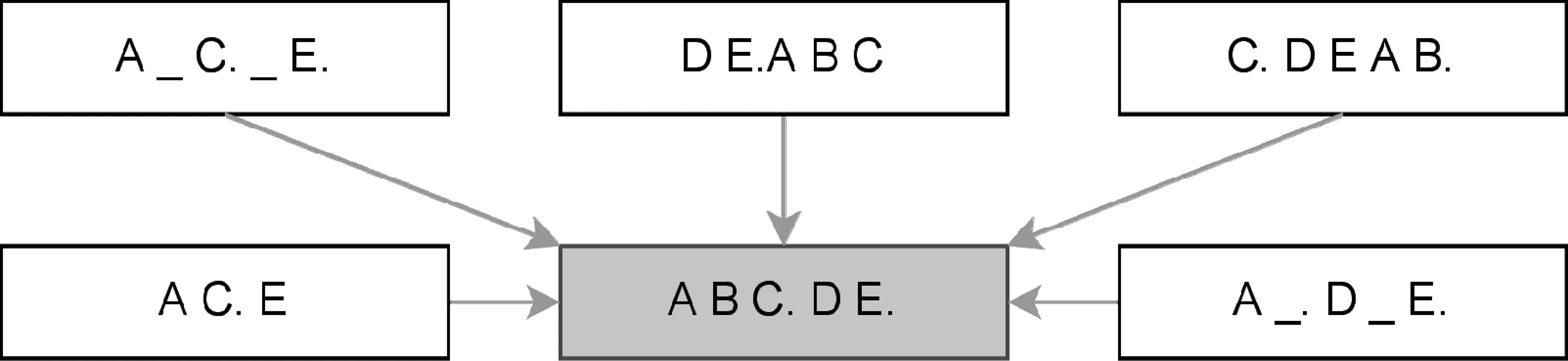
图1 BART的加噪方法示意图
在规模分别为6.9M和5.2M句子规模的藏汉单语数据、500K句对的藏汉平行数据和314K词条双语词典的数据设定下,本文中的PTMDI模型在藏汉和汉藏翻译方向的测试集上的BLEU值比BART这一强基准模型分别高出2.3和2.1,充分证实了本文所提出的预训练方法在藏汉机器翻译任务上的有效性。
综上,本文的贡献为:
(1) 考虑到双语词典能在预训练过程中提供有效的监督信号,同时受跨语言交流中使用混合的多语言词汇能提高沟通效率这一现象启发,提出一种利用藏汉双语词典和藏汉单语数据进行词典注入的机器翻译预训练方法,即PTMDI;
(2) 在通过与包括监督式Transformer、回译、BART的性能对比实验,证实本文提出的PTMDI方法在测试数据集上比各类基准模型均有大幅性能提升;
(3) 由于使用了藏汉双语词典,本文提出的PTMDI模型适用于翻译模型的领域适应问题,能够借助领域词典和单语数据学习平行数据中缺乏的翻译知识。
1 相关工作
近年来,随着人工智能领域技术的迅猛发展和日益密切的跨语言交流需求,藏汉机器翻译技术取得了长足发展。和其他低资源机器翻译研究课题一样,藏汉机器翻译的研究集中在致力于在平行数据资源受限的条件下探索提高机器翻译性能的方法。其中包括优化藏汉翻译模型的词表大小和分布[20-21],利用大规模单语数据进行迭代式回译[22]、迁移学习[23]、融合藏文多层次先验特征[24]、融合目标端语言模型的方法[25]等。此外,还有一些与藏文预训练语言模型相关的研究工作,比如中国少数民族预训练语言模型CINO[26]。该模型使用了XLM-R[27]风格的预训练方法,是至迄今为止规模最大的支持藏文的公开跨语言预训练语言模型。CINO虽然只在文本分类任务上进行了测试和验证,由于该模型可以进行跨语言的表示,所以可以用于初始化藏汉机器翻译的解码器、编码器或者整个模型的参数。
2 方法
2.1 NMT
给定源端句子x={x1,…,xN}和目标端句子y={y1,…,yM},NMT将句子级别的翻译概率建模问题转换为词级别的条件概率的积,如式(1)所示。
(1)
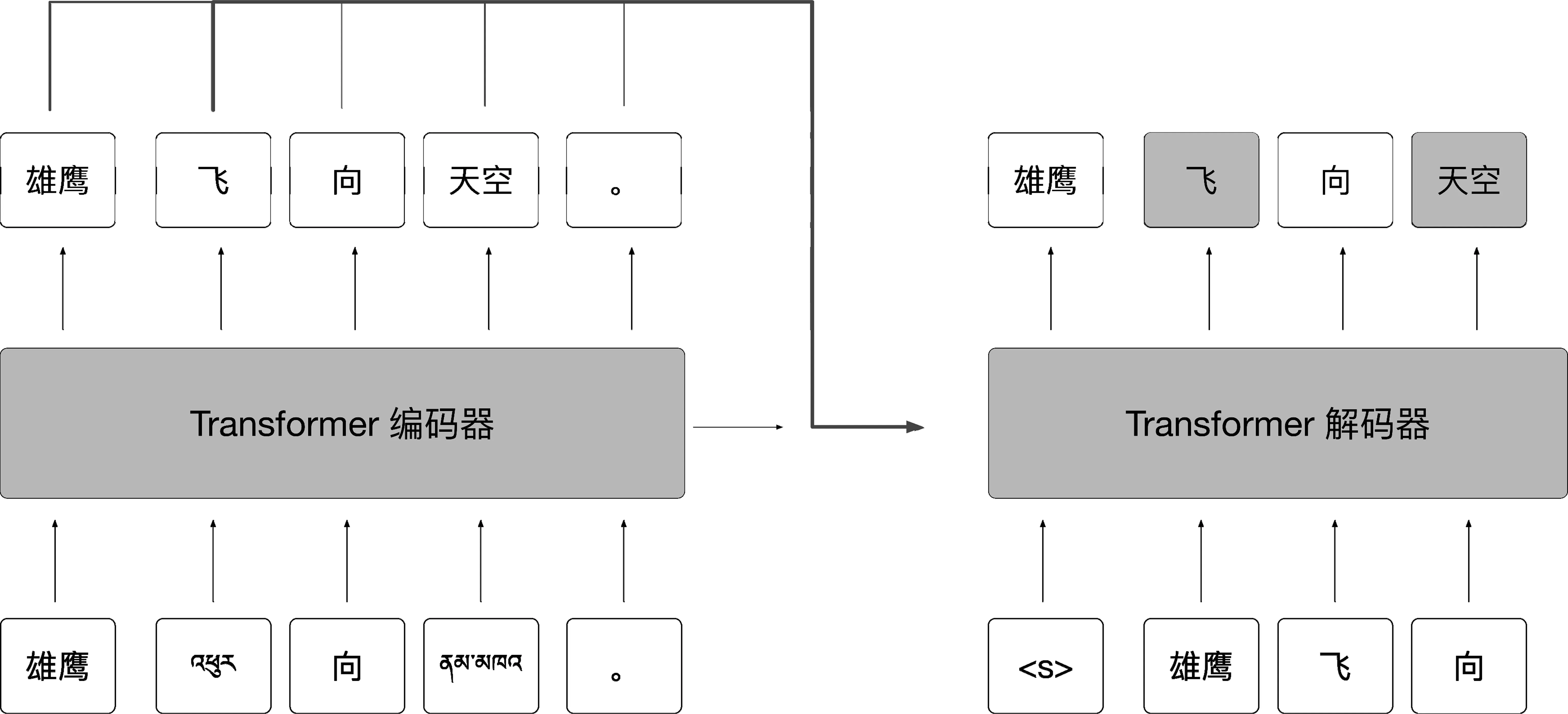
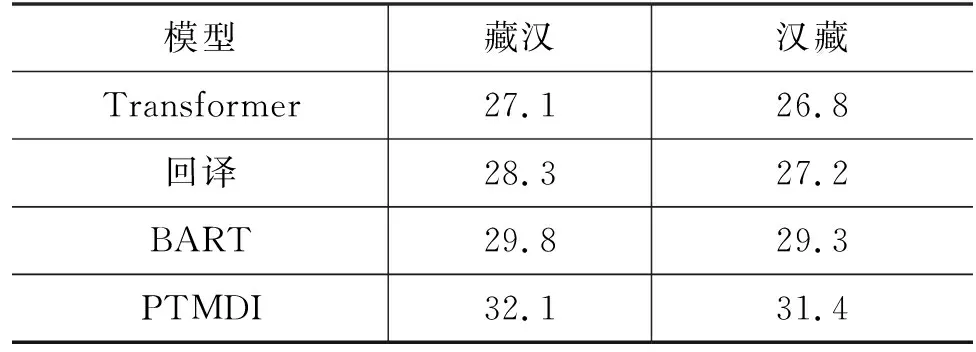
其中,θ为模型所要估计的参数,y 类BERT掩码语言模型能够对序列的双向上下文表示进行建模,但是其训练是按照分类任务进行的,即将编码器的输出输入到Softmax层预测被掩码的词在整个词表上的概率分布。类GPT自回归模型和传统的语言模型的训练方式一致,即通过当前已生成序列的信息预测下一个词。BART将类似BERT具有双向表示能力的构架作为编码器学习加噪序列的表示,而将类似于GPT的自回归构架运用于解码器,用于逐词生成原始未加噪的序列。其训练的优化目标为在整个训练集D上加噪序列片段与原始序列片段的似然概率,即: (2) 其中,N(x)表示加噪函数,BART在预训练过程中采用了多个加噪方法,包括:①词的遮蔽; ②句子顺序扰动; ③文档转换; ④词删除; ⑤序列片段替换等,这些加噪方法的示意如图1所示。 PTMDI的预训练沿用了BART加噪并重构的建模方法,但是与BART不同的是PTMDI中词典注入代替了各类加噪方案。词典的注入不仅能起到加噪的作用,同时也在客观上要求编码器学习跨语言的联合表示。本文在完成词典注入的单语数据上进行预训练之后,在规模为500K的平行数据上进行微调。具体的预训练和微调的示意图如图2和图3所示。考虑到收集的双语词典的词条大部分为名词,在进行词典注入时优先替换单语数据中的名词,同时保证被替换的词的数量不超过整个句子词长度的15%。 图2 预训练过程 图3 微调过程 因为编码器需要学习藏汉两种语言的表示,需要模型有更大的学习容量,所以本文中使用了解码器更深的网络构架。此外,编码器的表示和理解性能相对而言比解码器的自回归生成和掩码自编码性能,对翻译最终表现有更加重要的影响[28],因而在多语言机器翻译任务中研究者有使用较深的编码器、较浅的解码器的应用实践[29],在翻译性能不退化的前提下,提高翻译速度。 PTMDI训练方法能通过注入词典的方式进行翻译模型的预训练,因为词典的对齐特性使得模型在预训练阶段就开始进行跨语言的信息交互,学习跨语言信息的关联。此外,这种词典注入方式使得离散的词典特征能够很好地整合到端到端序列学习的连续过程中,是一种在机器翻译模型中有效融合先验知识的方法。考虑到相较于特定领域内的对齐数据,领域词典和领域单语数据比较容易获取和收集,所以PTMDI也是一种能以较为低廉的代价进行机器翻译领域适应的方法,尤其是适用于藏汉语言对这样的低资源机器翻译任务。 3.1.1 词典 为使藏汉双语词典涵盖较为广泛的领域,尤其是学习到受限的藏汉对齐文本之外的翻译知识,本文使用藏汉、汉藏、藏英、英藏四个方向的双语词典资源和利用统计词对齐工具FastAlign[30]在藏汉平行数据中获取的藏汉对齐词表。其中所有词典数据中只提取有单个释义的词条。另外,对于藏英、英藏词典,先将英文通过Google在线翻译系统翻译为汉文,然后再进行筛选处理;对于统计对齐词表设定筛选的词,对齐概率阈值为0.3;若有多个超过该阈值的对齐词表项,则随机选择。词典词源的统计信息见表2,藏汉和汉藏词典的领域包括日常用词、法律、生物、化学、医疗、数学、计算机等,藏英和英藏词典则主要是日常用词。对如表2所示的总计384 654个筛选的词条进行正则化和去重处理之后,最终获得 314 500 个独立词条。 表2 词典资源统计表 3.1.2 双语数据 与英文等具有显式的词分隔符不同,如藏文和汉文如果直接使用纯粹基于频率统计的子词分词方法,将可能会生成大量在语言学上无实际意义的子词结构,这一现象对藏文这种拼音文字尤其明显。在低资源的机器翻译任务设定中,这些冗余的子词使得机器翻译模型需要学习额外的构词规律,在客观上加大了模型的学习负担。除了低资源机器翻译任务之外,涉及汉文、日文、朝鲜文等语言的富资源机器翻译任务中一般也采用先分词再学习子词的数据预处理流程[31]。本文中数据的预处理也是采用了这种策略,汉文分词使用了jieba(1)https://github.com/fxsjy/jieba分词工具进行分词,藏文分词采用了文献[32]提出的藏文分词方法。对文本进行分词处理之后使用Sentence-Piece(2)https://github.com/google/sentencepiece[33]进行子词学习。为了过滤平行数据中的噪声样本,本文通过fasttext(3)https://github.com/facebookresearch/fastText[34]中的语言标识模型去除藏文句子中的汉文和汉文句子中的藏文,同时也删除了数据样本中的非Unicode字符。本文限制了对齐句对的最大长度为120个词,同时剔除了藏汉词长度比大于4的句对。通过去重方法保证训练集、验证集和测试集没有交集。最终的藏汉平行数据规模如表3所示。 表3 平行数据和单语数据规模 3.1.3 单语数据 由于用于微调的平行数据主要是新闻领域的,为了更加有效的模型训练,本文在收集藏语和汉语的单语数据时也使用了新闻领域的数据。单语数据的主要来源是各类藏文新闻网站和这些网站对应汉文网站的对应栏目,以完成数据更好的领域适配。单语数据的预处理方式和平行数据的预处理方式是一致的,也是先分词,再学习子词。在进行正则去噪、去重等预处理之后,最终保留的藏文和汉文单语数据的规模分别为6.9M和5.2M。 本文中所有模型的训练和测试都是基于Fairseq(4)https://github.com/pytorch/fairseq/[35]框架实现的,使用了4张Nvidia Quadro P1000 GPU。基准模型中纯监督式模型和回译模型使用了6层的Transformer编码器和解码器;藏文和汉文的词表大小分别为8K和9K。PTMDI 模型使用了10层的Transformer编码器和6层的Transformer解码器,编码器共享了藏语和汉语的词表,解码器使用了独立的对应目标语言的词表。所有模型解码器和编码器的嵌入维度为512,编码器和解码器的前馈网络的维度为2 048,使用了Adam优化器进行参数优化,初始学习率设置为0.001,学习率衰减函数选用了平方根倒数,批处理大小为4 096个词,所有的模型都训练了60轮次。 表4列出了纯监督式Transformer模型、回译模型、BART和PTMDI模型在测试集上的最终BLUE的测定值。从表中可以看出,本文中的PTMDI模型比BART这一强基准模型在藏汉和汉藏翻译任务上BLEU值分别高出2.3和2.1,用实证方法证实了PTMDI在藏汉机器翻译任务上的有效性。此外从图4中模型在验证集上的BLEU变化和图5中训练过程中的损失变化,可以得知PTMDI模型有更好的收敛特性,证实了模型在预训练阶段就通过词典学习双语映射关系确实能够帮助提高微调过程中模型的学习能力。 图5 各个模型的训练损失变化 表4 各个模型在测试集上 BLEU 值 从表5可以看出,在测试集样例中的专业词汇“食用菌”和“羊肚菌”在PTMDI模型中被较为准确地译出,且译文更加流畅。 表5 测试集中的译文样例 除了验证模型在双语数据的领域有良好性能之外,本文还对其他跨领域场景下的性能进行了测试,如表6所示的是测试所有模型在计算机科学领域表现的一个样例,从该译文样例中可以发现比如汇编、编译器等双语平行数据中不存在的词条也被准确翻译出来。说明PTMDI确实在预训练过程中挖掘了先验的双语词典内的翻译知识。 表6 跨领域的译文样例 本文受到双语交流中混和语言能有效增进交流这一现象启发,利用多个领域的藏汉双语词典和百万句子级别的藏汉单语数据,以BART风格降噪自编码为训练目标,通过在单语数据中有效注入词典,进行藏汉跨语言模型的预训练,并在已有藏汉平行数据上进行微调。经过广泛的实验验证,本文中的方法比BART强基准模型在测试集上的BLUE值在藏汉和汉藏方向上分别提高2.3和2.1。结合利用更大规模的单语数据,更加准确有效的词典注入方式,混合BART和词典注入的训练方法,应该可以更进一步提高藏汉翻译的性能,我们将在未来的工作中继续进行研究和探索。此外,本文方法能为后续一到多、多到一、多到多等藏文多语言翻译课题提供可靠的研究基础。2.2 机器翻译预训练模型
2.3 词典注入的藏汉机器翻译模型预训练方法

3 实验
3.1 数据设定
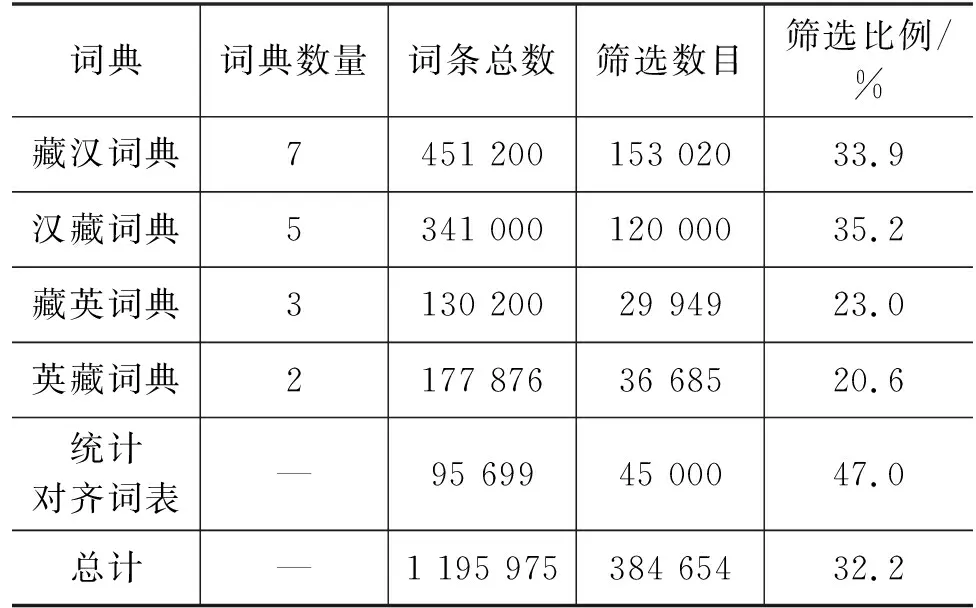

3.2 模型设定
3.3 实验结果



4 总结
猜你喜欢
客联(2022年4期)2022-07-06 05:46:23
黄河之声(2022年4期)2022-06-21 06:54:52
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
西藏科技(2015年12期)2015-09-26 12:13:51
