
基于人物特征增强的拟人句要素抽取方法研究
2023-10-25 02:22:20王素格
中文信息学报 2023年8期
李 婧,王素格,2,陈 鑫,王 典,李
(1. 山西大学 计算与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3. 山西财经大学 金融学院,山西 太原 030006)
0 引言
拟人作为最常见的修辞格之一,是将事物人格化,把原来不具有人动作和性格的事物比作和人一样的模样,在我们的日常交流和文学作品中常有意识或无意识地使用。例如,童话故事里的动物、植物能讲话。拟人的三要素为本体、拟人词、拟体[1]。本体: 被描写和说明的事物,事物本身不是人,但是具有人的特点。拟人词: 用来描绘人物特点的词语,如“夜空中的小星星在对你微笑”中拟人词为“微笑”。拟体: 与本体相对,就是人。由于拟人的修辞方式具有增强表达力,并生动刻画所描述对象的特点,常被用于散文的写作中,将物体、动物、植物、思想或抽象概念等比拟为人,将事物人格化,使其具有人的动作、思想或情感。在近年的高考语文散文类鉴赏题中,多有涉及拟人句的考查。以2020年浙江省高考语文第10题为例。
原文: 穿过小城,一片暮霭中,波塔波夫终于走到了房子跟前。小心翼翼地打开小门,可是小门还是咯吱地响了一声。花园仿佛抖动了一下。树枝上有雪花簌簌飘落,沙沙作响……
问题: 赏析文中画线部分的语言特点。
部分参考答案: 语言具有诗化风格。如通过“花园仿佛抖动了一下”的拟人化描写,表现波塔波夫内心的情感波澜,情景交融,充满诗意。
根据上述部分参考答案,如果能抽取拟人句中的本体和拟人词,不仅可以帮助解答鉴赏类问题,还可以进一步了解作者或主人公想表达的思想感情。
本文基于多任务学习,提出基于人物特征增强的拟人句要素抽取方法。该方法主要包含三个部分: 表示增强、要素抽取及关系检测。具体地,在表示增强部分,将人物特征词融入句子的表示中;要素抽取部分利用条件随机场,确定标签之间的前后依赖关系;关系检测部分使用自注意力机制,建模字间的关系。为了实现拟人句的要素抽取和关系检测部分间的信息交互,使用要素同步机制和关系同步机制。在创建的拟人数据集中进行<本体,拟人词>抽取的实验,结果表明本文提出的模型性能优于其他比较模型。
1 相关工作
对于要素抽取,研究者们利用多任务学习方法,通过在相关任务间共享表示信息,提升模型在原始任务上的泛化性能。由CRF[2]可以有效学习输出标签之间的前后依赖关系,近些年在自然语言处理领域中得到了广泛使用。Huang等人[3]提出了一系列基于长短时记忆(LSTM)的序列标注模型,并首次将BiLSTM-CRF模型应用于NLP基准序列标记数据集,证明了此模型可以有效地利用过去和未来的输入特征,对于CRF层,使用句子级的标记信息,使方法具有较强的鲁棒性,而且对嵌入词的依赖性也小。但有关拟人句要素抽取的相关研究目前较少,赵琳玲[1]通过对拟人修辞手法的分析,发现拟人句中包含显著的人物特征,因而提出了基于人物特征的拟人句判别及要素抽取方法,但仅对拟人句中的本体进行了抽取,并没有对拟人词进行抽取且未判断二者存在的二元关系。
对于实体关系抽取,已有很多的研究工作。早期方法[4-5]将实体抽取和关系抽取视为两个独立的子任务,在抽取所有实体后,采用管道方法进行关系分类。为了在两个子任务之间建立桥梁,实体和关系的联合抽取模型已经引起了研究者的广泛关注。在抽取模型中,通常使用标记策略构建实体和关系之间的连接。其中,NovelTagging模型[6]将实体类型和关系角色作为标签的不同部分,再将联合抽取任务建模作为单个序列标注问题,缺点是不能处理重叠的情况。作为改进,文献[7-9]执行了多轮标记过程,从而缓解重叠的问题。Seq2Seq方法接收非结构化文本作为输入,并直接将实体-关系三元组解码为顺序输出。这种简洁的方法符合人类的注释过程,即注释者先读句子,理解句子的意思,然后按顺序指出实体-关系对。CopyRE模型[10]是基于Seq2Seq的联合抽取方法,通过两个具有复制机制的对应实体生成关系,但只能生成实体的最后一个字。因此,CopyMTL模型[11]应用多任务学习框架抽取多字实体,解决了CopyRE模型生成实体不完整的问题。由于拟人句中的本体和拟人词之间存在一定的隐式语义关系,若直接使用实体关系抽取方法,则不能将本体和拟人词进行准确的抽取。例如“月亮那么明媚又充满哀伤”,该句子中的本体是“月亮”,拟人词是“哀伤”。为了解决此问题,本文基于多任务学习,提出了一种基于人物特征增强的拟人句要素抽取模型。
2 拟人句语料库和特征词库构建
2.1 拟人句语料库构建
由于目前没有开放的拟人句数据集,所以我们人工构建数据资源。数据来源于高中语文课文、查字典网、散文吧网站以及全国部分省市的高考语文真题,具有一定的代表性。通过筛选和标注处理,构建了4 283条拟人句的数据集。
标注过程中,由三名同学同时标注相同的数据。对于同一待标注句,检验三人的标注结果,当至少两人标注一致时,则数据入库;否则三人共同讨论,确定一致结果。
2.2 拟人特征词库构建
对于一个拟人句,拟人词是用来描绘人物特征的词语,将人物特征细分为人物的情感、动作、神态、性格、外貌和其他特征六类,通过对拟人数据进行人物特征统计,统计结果和人物特征示例如表1所示。
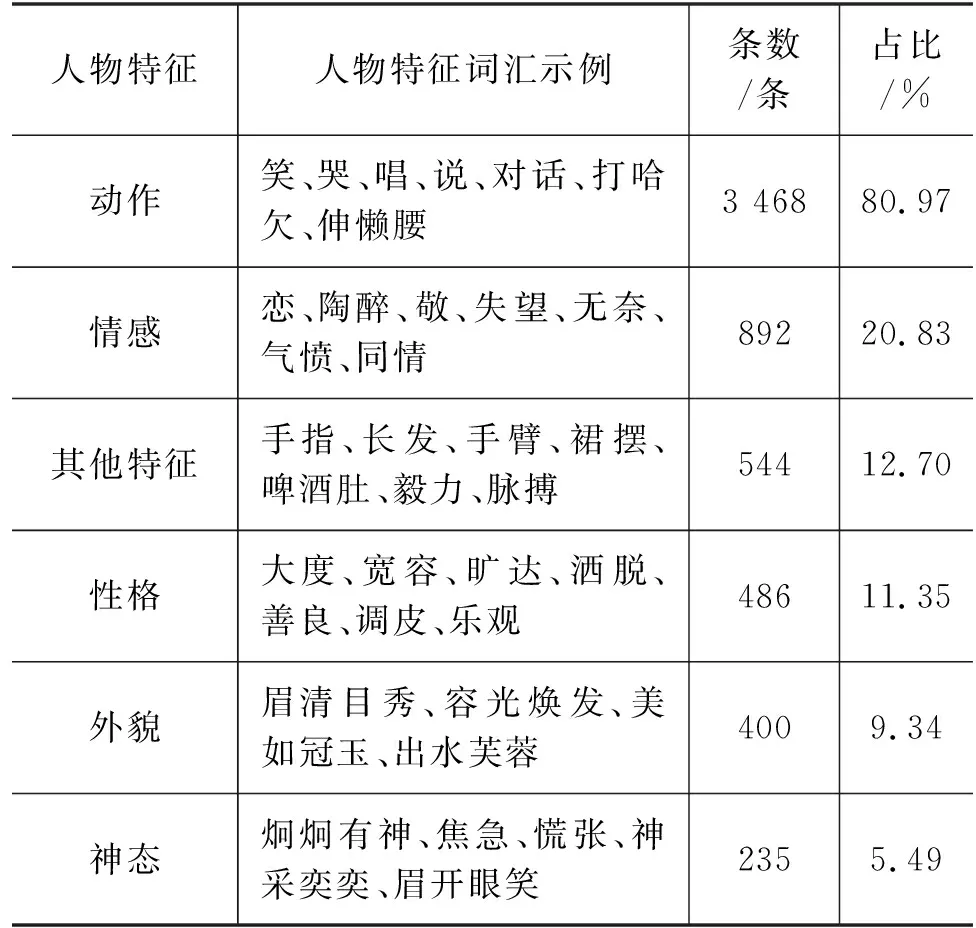
表1 拟人数据统计结果和人物特征示例
从表1中可以看出,将人物特征归纳为六个方面,从不同的角度对人物的特点进行描述。同时,对拟人句进行分析发现,存在一个拟人句包含多种人物特征的情况,例如“冬天对自己的创造很是得意,欢呼雀跃着,在雪原上嬉戏玩耍。”在此拟人句中,“得意”属于人物神态,“欢呼雀跃”“嬉戏玩耍”属于人物动作,从多角度对“冬天”进行了人物特征描写。根据对拟人句的人物特征统计结果,发现80.97%的拟人句中包含人物动作,其次是人物情感、其他特征、人物性格。因而,体现了人物特征在拟人句中的重要性。
在已构建的拟人数据集上,总结出较为常见的人物特征词汇1 586个,利用哈工大的《同义词词林扩展版》和WordNet进行同义词查找,对特征词汇进一步扩充,使词库尽可能多地包含相关词汇,最终构建有2 480个词汇或短语的人物特征词库即为DF,其中,人物特征词库包含表1中提到的六种人物特征,同时词汇带有褒、贬不同含义,覆盖面广,几乎涵盖了文学作品中常用到的人物特征,对于更准确地进行拟人句要素抽取,具有一定的辅助作用。
3 拟人句要素抽取方法
在拟人句中,本体和拟人词之间存在一定的隐式语义关系,这两个要素可以同时存在,但两者之间不一定存在二元关系。例如“宁静的夜晚,只有那天上的星星在窃窃私语,一排排柳树倒映在水中,欣赏着自己的容貌。”在该句子中存在两个本体——“星星”和“柳树”,三个拟人词——“窃窃私语”“欣赏”“容貌”,若按照一般的要素抽取方法仅将本体和拟人词抽取,难以找到两个本体分别对应的拟人词,因此,为了解决这个问题,本文提出基于人物特征增强的拟人句要素抽取方法。在要素抽取时将其看作序列标注问题,采用BIO标注方法产生五种标记,其中B-T和I-T分别表示本体的首部和中部,B-P和I-P分别表示拟人词的首部和中部,O没有任何含义。同时,通过建模字间的关系,最终推理出<本体,拟人词>,完成拟人句要素抽取。
<本体,拟人词>抽取任务的目标,是从给定句子S中获得本体与拟人词构成的集合C={
在该模型框架中,表示增强部分将人物特征词作为特定领域的特征引入编码层,与BERT得到的上下文表示向量进行结合,得到句子的增强表示的特征。要素抽取部分和关系检测部分用于提取本体、拟人词以及判断二者存在的二元关系。此外,还使用了一个同步单元实现要素抽取部分和关系检测部分之间的信息交互。整体模型需要多个递归过程,最后采用一个推理层捕获<本体,拟人词>。
3.1 表示增强部分
表示增强部分是指人物特征增强后的编码层。由于预训练模型的编码倾向于捕获一般文本表示,但缺乏领域知识。为了弥补相关领域信息的不足,在编码层中加入了人物特征进行增强。
输入序列与已构建好的人物特征词库DF进行检索,找到所有可能构成人物特征的子序列。将X[i:j]定义为X的子序列,X以xi开始,以xj结束,再利用掩模矩阵MD表示人物特征。其中第i行和第j列的元素mij表示子序列X[i:j]是否为人物特征的表达式。

(1)
利用额外的Transformer编码器计算输入句子的人物特征的特定表示。该层包括两个子层,一个多头自注意力机制和一个前馈网络,每个子层后面都有一个残差连接和层规范化。融合了人物特征信息的特征掩蔽编码器的最终输出表示为HD。最后,将HL和HD进行加权平均,得到人物特征增强表示HEncoder。
HEncoder=γHL+(1-γ)HD
(2)
其中,γ为加权参数。在这项工作中,采用了γ=0.5。
3.2 要素抽取部分
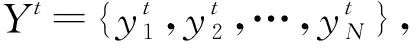
(3)
(4)

预测序列Yt的概率计算如式(5)所示。
(5)

3.3 关系检测部分
由于本体和拟人词之间的二元关系结构可以是一对一,也可以是一对多,甚至是多对多。因此,考虑到本体和拟人词之间关系的复杂性,采用自注意力作为关系检测部分,根据句子的上下文信息动态地建模字间关系,而不受时序限制。
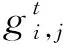
(6)

(7)
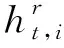
在最后一步t中,通过最大化似然概率,进一步将监督信息引入到Gt的计算中,如式(8)所示。
(8)
其中,标准关系矩阵Z由元素zi,j组成,关系概率p(zi,j|xi,xj)计算如式(9)所示。
(9)
其中,zi,j=1表示第i个字与第j个字之间存在关系,反之亦然。有了这些监督信息,可以引导注意力更有效地捕捉字间的关联。
3.4 同步单元

3.4.1 要素同步机制

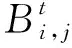
3.4.2 关系同步机制
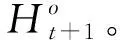
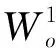
3.5 联合学习
为了同步学习要素抽取部分和关系检测部分,将各自的损失函数进行融合。对于要素抽取部分,给定标准标签序列Y,最后一步最小化负对数似然损失函数如式(16)所示。
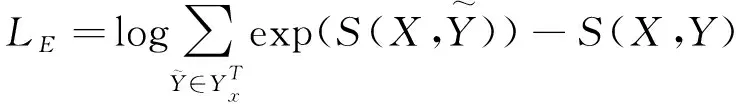
(16)
对于关系检测部分,将标准注释转换为一个one-hot矩阵,其中0表示没有关系,1表示两个字间存在二元关系。最小化最后一步预测分布与标准分布之间的交叉熵损失如式(17)所示。
(17)
将这两部分结合,构建整个模型的损失目标如式(18)所示。
L(θ)=LE+LR
(18)
3.6 推理层
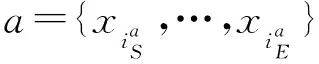

(19)
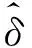
4 实验
4.1 参数设置与评价指标
本文采用精确率P、召回率R和F1值作为评价指标。

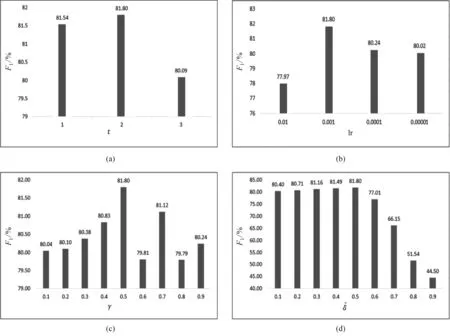
图2 部分超参数对实验性能的影响

4.2 对比方法介绍
为了验证本文提出方法的有效性,将其与如下基线方法进行对比实验。
BERT+CH[1]该模型采用BiLSTM-CRF的方法抽取拟人句中的本体。编码层分为两部分,一是使用BERT得到上下文向量表示,二是微调BERT,将segmentid参数设置为是否为人物特征,采用1或0表示,拼接二者。但此模型没有对拟人词以及要素存在的二元关系进行进一步研究。
W+F[15]该模型的Embedding层为每个词的向量和词性特征的拼接。此模型是对比喻句中的要素进行识别和抽取,现用于拟人句识别。
SDRN[14]: 该模型研究的是方面意见对抽取(AOPE)任务,目的是成对地提取方面和意见表达。
BERT+CH+SDRN(B+C+S) 将上述BERT+CH和SDRN方法进行结合,在SDRN的编码层中微调BERT,将segmentid参数设置为是否为人物特征,采用1或0表示。
SDRN+SMHSA[16](S+S) 该模型将SDRN模型中关系检测部分换为SMHSA模型中的多头自注意力的方法。SMHSA的主要任务是联合实体和关系抽取,得到关系三元组。
4.3 实验结果与分析
利用第3节提出的模型以及4.2节介绍的对比模型,在已构建的拟人数据中进行对比实验,结果如表2所示。
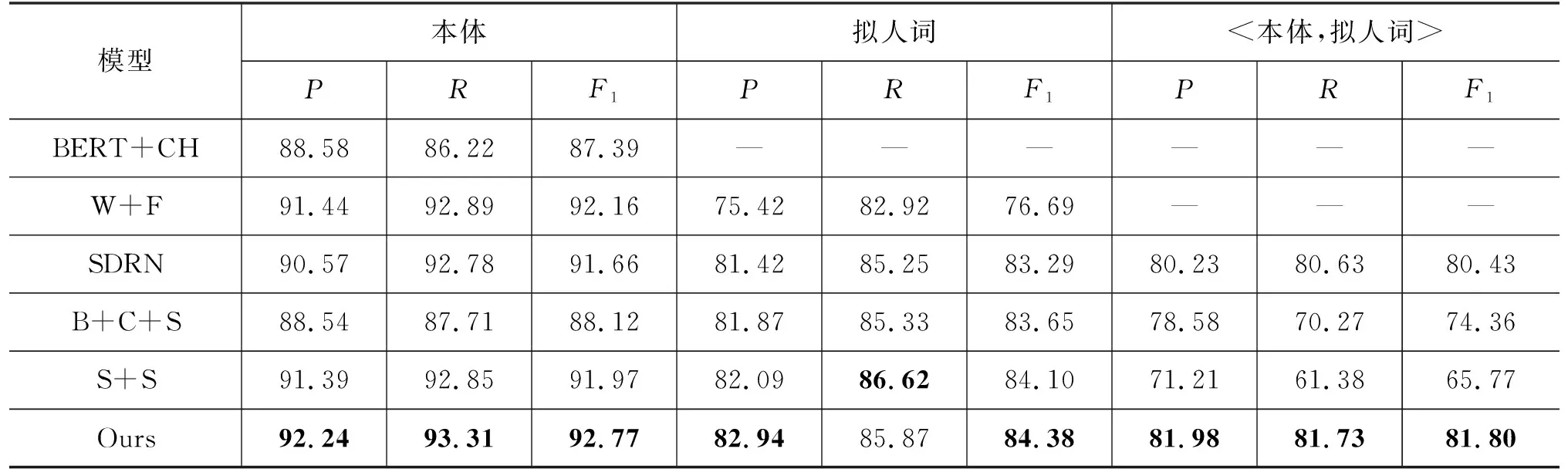
表2 六种方法的对比实验结果 (单位: %)
由表2实验结果可以看出:
(1) 与其他模型进行比较,本文提出的模型在<本体,拟人词>抽取任务的F1值达到了目前最优,验证了本文使用联合学习方法对<本体,拟人词>的抽取是有效的。
(2) 由于本文的模型是对SDRN模型进行的改进,因此,本文所提出的方法与SDRN的结果比较。在<本体,拟人词>抽取的任务上,本文提出的模型比SDRN,在P值、R值、F1值上分别提高了1.75,1.10,1.37个百分点,验证了在编码层中加入人物特征进行增强,弥补了预训练模型在编码时对相关领域信息获取不足的问题。
(3) 由于之前的工作并没有对<本体,拟人词>抽取进行研究,而SDRN在很大程度上解决了判断两者间存在二元关系的问题,这说明自注意力机制有助于学习句子内部要素间相关联的依赖关系。BERT+CH+SDRN模型将BERT编码中的sigmentid进行修改,改变了上下文的语义。SDRN+SMHSA模型的要素抽取部分使用的是SDRN实体识别部分,而关系检测部分则采用SMHSA模型中抽取实体关系任务的方法,导致实验结果不理想,其原因是在拟人句中本体和拟人词的关系不同于实体间的关系,利用该方法存在关系无法判别的问题。而我们的模型使用了自注意力机制。
值得说明的是,本文使用联合学习模型的参数是在训练时仅考虑了<本体,拟人词>抽取的关系F1值达到最高,因此,仅仅抽取本体或拟人词的性能指标不是最佳。
4.4 消融实验
为了验证模型各个部分的性能,将模型中去掉部分信息进行消融实验。
-feature: 表示将人物特征融合去掉后的模型。
-ESM: 将模型中的要素同步机制(ESM)去掉,只保留全连接层更新关系隐藏表示。
-RSM: 将模型中的关系同步机制(RSM)去掉,并采用全连接层更新拟人词隐藏表示 。
-ESM-RSM: 将模型中的要素同步机制(ESM)和关系同步机制(RSM)均去掉。
上述四种方法与本文的模型在拟人数据中的比较结果如表3所示。
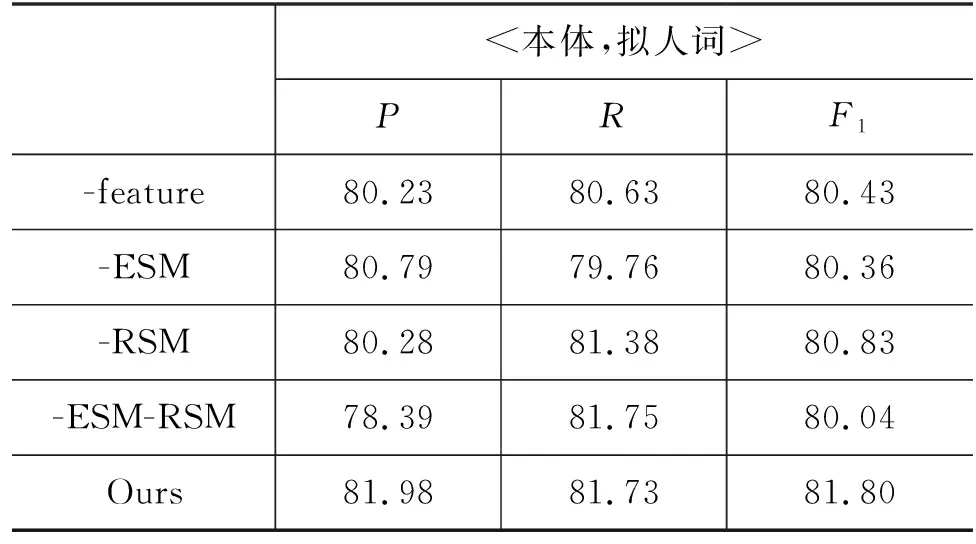
表3 <本体,拟人词>抽取消融实验对比结果 (单位: %)
由表3实验结果可以看出:
(1) -feature、-ESM和-RSM在<本体,拟人词>抽取任务的评价指标F1上均有所下降。其中,-feature与本文模型的性能相比下降明显,说明具有人物特征增强的编码层对<本体,拟人词>抽取任务是有效的,在一定程度上弥补了一般编码层对相关领域信息不足的问题。
(2) -ESM-RSM是所有方法中最差的,说明使用ESM或RSM,对模型的整体都是有帮助的,且两个同时使用的性能优于只使用一个。特别是ESM的贡献略大于RSM。另外,在这种同步机制的作用下,我们的模型优于其他基线方法。
5 总结
针对拟人句的本体和拟人词抽取问题,本文提出了基于人物特征增强的拟人句要素抽取方法。首先通过表示增强部分将人物特征词作为特定领域的特征引入编码层,与BERT得到的上下文表示向量进行结合,得到能够增强表示的特征。其次,使用要素抽取部分和关系检测部分,同时提取本体、拟人词和二者存在的二元关系。此外,还用同步单元实现后两个部分之间的信息交互。经过多个递归过程后,最后采用推理层捕获<本体,拟人词>,并与其他模型进行对比实验。实验表明,人物特征增强和多任务学习的共同采用提高了本文所提出方法的有效性。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
中国音乐学(2020年4期)2020-12-25 02:58:06
快乐语文(2020年15期)2020-07-06 02:55:18
中国外汇(2019年18期)2019-11-25 01:41:54
快乐语文(2019年12期)2019-06-12 08:41:54
快乐语文(2018年27期)2018-10-20 07:12:50
小学生学习指导(低年级)(2018年6期)2018-05-25 01:42:23
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
