
基于DNN-HMM的蒙古语声学模型结构实验研究
2023-10-25 02:20李晋益马志强刘志强朱方圆王洪彬
中文信息学报 2023年8期
李晋益,马志强,2,刘志强,朱方圆,王洪彬
(1. 内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010080;2. 内蒙古自治区基于大数据的软件服务工程技术研究中心,内蒙古 呼和浩特 010080)
0 引言
语音识别[1]相关研究开始于20世纪50年代,贝尔实验室研发出10个孤立数字的识别系统。20世纪80年代,以隐马尔可夫模型[2](Hidden Markov Model,HMM)为主的统计模型逐渐在语音识别中占据了主导地位,并成为研究和应用的主流模型,其核心框架为混合高斯-隐马尔可夫模型(Gaussian Mixed Model-Hidden Markov Model,GMM-HMM)。20世纪80年代后期,人工神经网络(Artificial Neural Network,ANN)也成为语音识别研究的一个方向,但这种浅层神经网络在语音识别任务上的效果并没有优于GMM-HMM。
2006年,Hinton使用受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)对神经网络的节点做初始化,由此产生了深度置信网络(Deep Belief Network,DBN)[3]。DBN是一种非监督贪婪逐层方法,在尽可能保留建模对象特征信息的基础上,不断拟合获得权重,在结构上的多层非线性变换使其具有更强的建模能力。2009年,Hinton和Mohamed将DBN应用在语音识别声学建模中,并且在小词汇量连续语音识别数据集上获得成功[4]。直到2011年,深度神经网络(Deep Neural Network,DNN)在大词汇量语音识别上获得成功,语音识别效果取得了突破[5]。DNN-HMM声学模型把连续多帧的语音特征拼接在一起构成高维特征作为语音识别系统声学模型的输入,充分利用当前帧的上下文信息发现声学特征之间的相关性。此后,基于深度神经网络的建模方法成为主流的声学模型建模方法。2012年11月,百度公司将DNN-HMM[6-7]声学模型应用到语音识别中,与基于GMM-HMM声学模型的汉语语音识别系统相比,词错误率降低了25%[8]。同年,微软研究院的邓力等人与加拿大多伦多大学Hinton小组合作针对大规模连续语音识别任务提出CD-DNN-HMM声学模型框架,彻底改变了语音识别原有的技术框架[9]。2014年至2015年,百度相继发布了DeepSpeech[10]和DeepSpeech2语音识别模型,DeepSpeech使用的声学模型在Switchboard英文数据集和Baidu中文数据集上的识别准确率均得到提升。2016年,科大讯飞提出了一种前馈型序列记忆网络(Feed-Forward Sequential Memory Network,FSMN)模型[11], FSMN声学模型在DNN模型的隐藏层上加入了类似LSTM模型中记忆单元的“记忆模块”,实现对历史语音信息的建模,从而让DNN模型拥有对历史信息建模的能力。
目前少数民族语言的语音识别研究主要集中于少数民族地区的高校和科研机构。蒙古语语音识别的研究单位主要为内蒙古大学和内蒙古工业大学等。内蒙古大学于2015年展开了基于DNN深度神经网络的蒙古语语音识别的研究,利用78小时的蒙古语语料库构建了8层深度的DNN-HMM 声学模型,相较于传统的GMM-HMM蒙古语声学模型,语音识别系统的词识别准确率最高达到 87.63%,识别准确率得到了提升[12]。2017年,内蒙古大学以蒙古语音素作为声学建模粒子,构建了LSTM-HMM蒙古语声学模型,其蒙古语语音识别的词错率降低至 8.94%[13]。2018年,内蒙古工业大学使用310句的小规模蒙古语语料库构建了GMM-HMM蒙古语声学模型以及DNN-HMM蒙古语声学模型,实验发现基于DNN-HMM的蒙古语语音识别比与基于GMM-HMM的蒙古语语音识别词错率降低了1.33%[14],进一步证明DNN-HMM声学模型相较GMM-HMM声学模型的优越性。
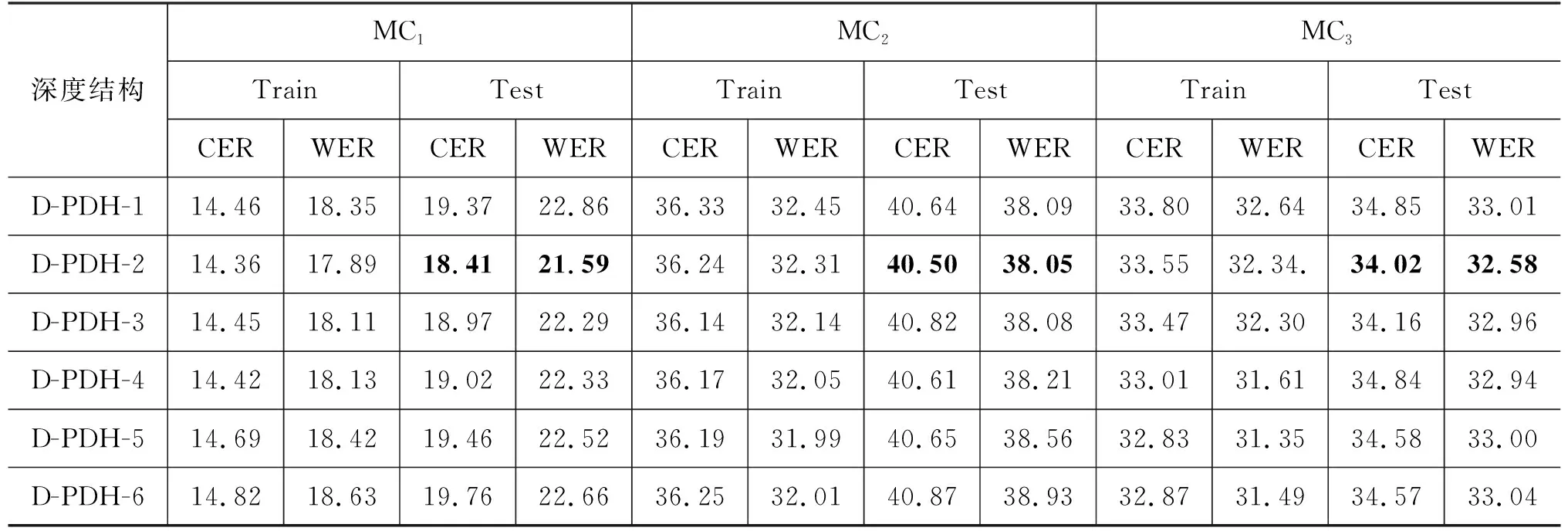
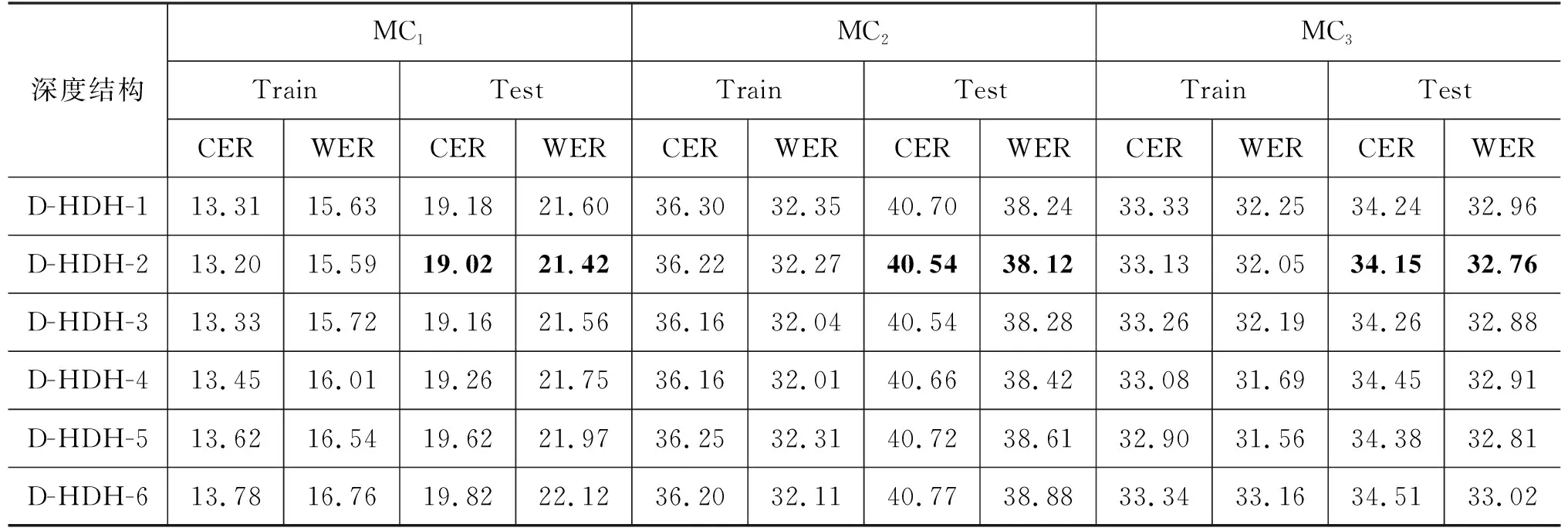
在使用蒙古语语料库构建DNN-HMM声学模型的过程中,DNN-HMM结构(深度、宽度)对蒙古语声学建模的影响以及蒙古语语料库规模与DNN-HMM声学模型的关系是未知的。本文通过调整DNN-HMM的结构[15-16],提出Rectangle DNN-HMM、Trapezoid DNN-HMM、Polygon DNN-HMM和Hourglass DNN-HMM四种结构的DNN-HMM蒙古语声学模型。通过深度结构实验和宽度结构实验得知:深度为6层的Polygon DNN-HMM结构适合蒙古语声学模型建模。随着语料库规模的增大,适当增加声学模型的宽度,能够进一步降低CER和WER。
本文第1节介绍了DNN-HMM声学模型的建模原理和训练算法。第2节对Rectangle DNN-HMM、Trapezoid DNN-HMM、Polygon DNN-HMM和Hourglass DNN-HMM四种不同结构的DNN-HMM声学模型进行介绍。第3节对实验设置、数据准备、实验方案和评价指标进行说明。第4节对收敛性实验、模型深度结构实验和模型宽度结构实验的实验结果进行分析。第5节得出本文结论。
1 DNN-HMM声学模型建模原理
DNN-HMM混合模型应用于语音识别中,HMM用来描述语音信号的动态变化[17],DNN用来估计观察特征的概率[18]。
1.1 DNN-HMM声学模型
在DNN-HMM声学模型的建模过程中,O=o1,o2,o3,…,ot表示声学特征序列,组成句子的单词序列为W=w0,w1,w2,…,wn,由此可以建立一个准确计算后验分布P(O|W)的声学模型,具体计算过程如式(1)所示。
P(O|W)≈

(1)
其中,s∈[1,t]代表HMM状态序列,P(s1)和ASt-1St分别是由HMM决定的初始状态概率和状态转移概率。P(st|ot)是DNN计算得出的每个状态的后验概率,P(st)是状态的先验概率。
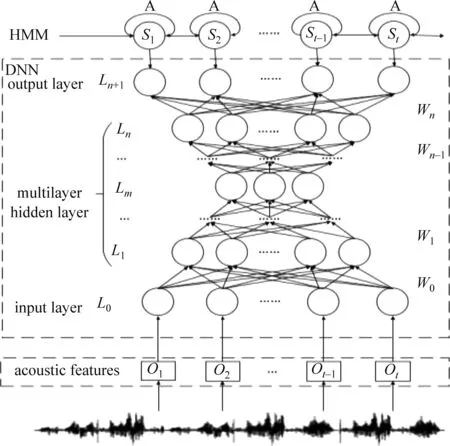
DNN-HMM声学模型由三部分组成,声学特征、DNN和HMM,其模型结构如图1所示,o1,o2,…,ot-1,ot表示声学特征序列。DNN由输入层L0,多层隐藏层L1,…,Ln,以及输出层Ln+1构成,其中W0,…,Wn表示DNN各层之间的连接矩阵。在HMM中,s1,s2,…,st-1,st表示隐藏状态,A表示状态转移概率。

图1 DNN-HMM声学模型结构
1.2 声学模型训练
DNN-HMM声学模型的训练[19-20]过程主要包含DNN、HMM和状态先验概率分布prior。DNN-HMM和GMM-HMM共享音素绑定结构,因此使用训练集S训练一个GMM-HMM模型,得到hmm,将训练数据和状态进行强制对齐。利用GMM-HMM中的hmm创建状态到音素的映射featerToSenoneIDMap,并生成用于训练DNN的特征到音素的映射对featureSenoneIDPairs。接着将GMM-HMM声学模型转换为DNN-HMM声学模型,生成在DNN-HMM中使用的隐马尔可夫模型HMM。用特征到音素的映射对估计得到音素的先验概率Prior并训练DNN。最后将Prior与DNN、HMM相结合,共同构成DNN-HMM声学模型。其主要的训练步骤见算法1。

2 DNN-HMM蒙古语声学模型结构设计
通过调整DNN-HMM蒙古语声学模型中DNN隐藏层的深度和宽度来改变DNN-HMM蒙古语声学模型的结构,从而提出了Rectangle DNN-HMM(RDH),Trapezoid DNN-HMM(TDH)、Polygon DNN-HMM(PDH)和Hourglass DNN-HMM(HDH) 四种不同结构的DNN-HMM蒙古语声学模型。下面分别对四种结构的DNN-HMM蒙古语声学模型进行介绍。
2.1 Rectangle DNN-HMM
在Rectangle DNN-HMM蒙古语声学模型结构中,DNN多层隐藏层的形状为矩形,如图2所示,其中DNN由输入层L0、输出层Ln+1,以及形状为矩形的n层隐藏层L1,…,Ln组成,n层隐藏层各层之间的宽度是相等的,即widthL1=…=widthLn。W0、W1、…、Wn表示各相邻层之间的参数数量。
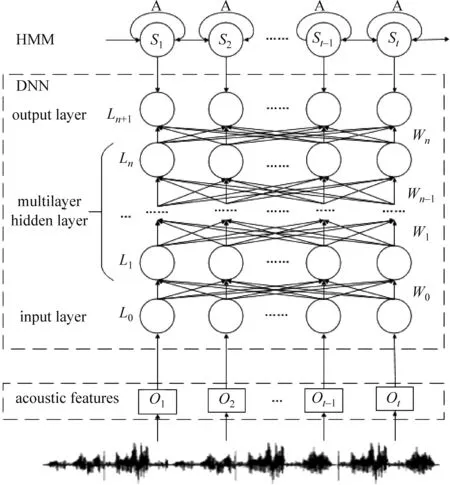
图2 Rectangle DNN-HMM模型结构
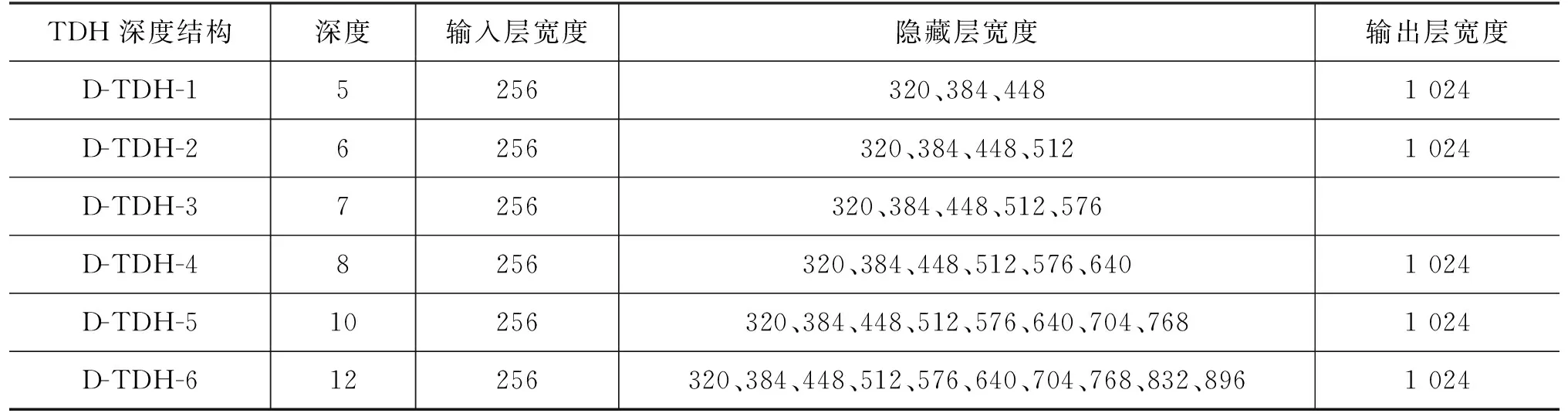
2.2 Trapezoid DNN-HMM
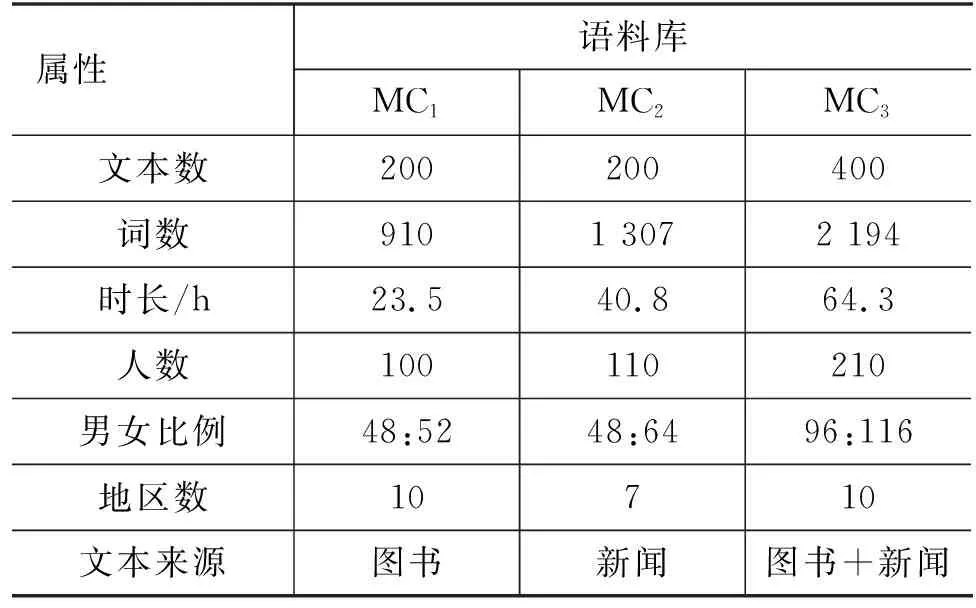
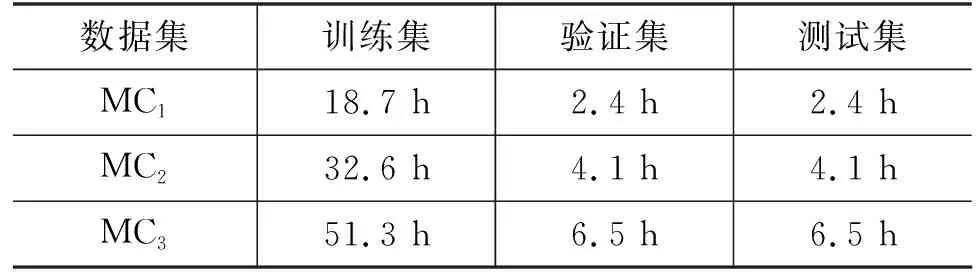
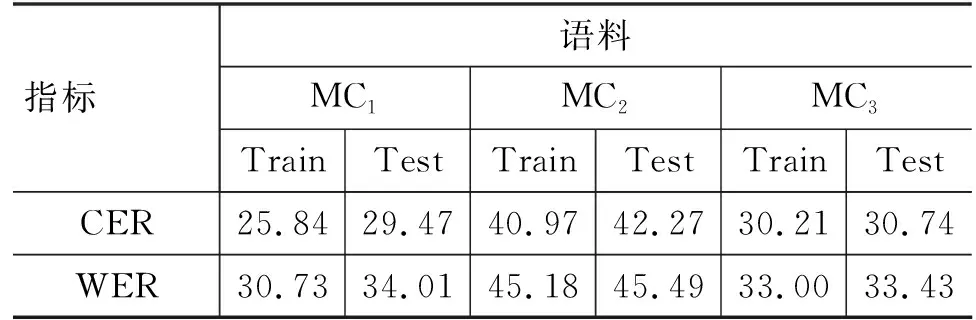
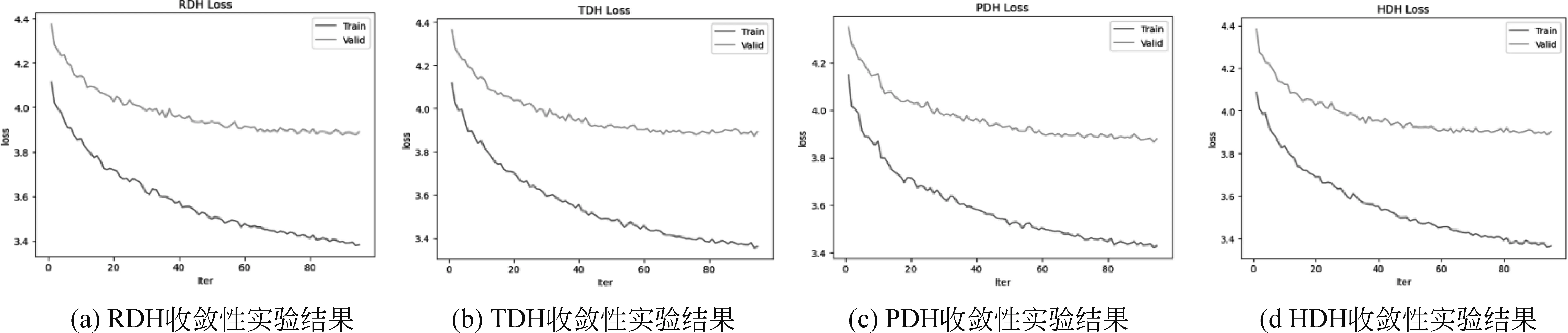
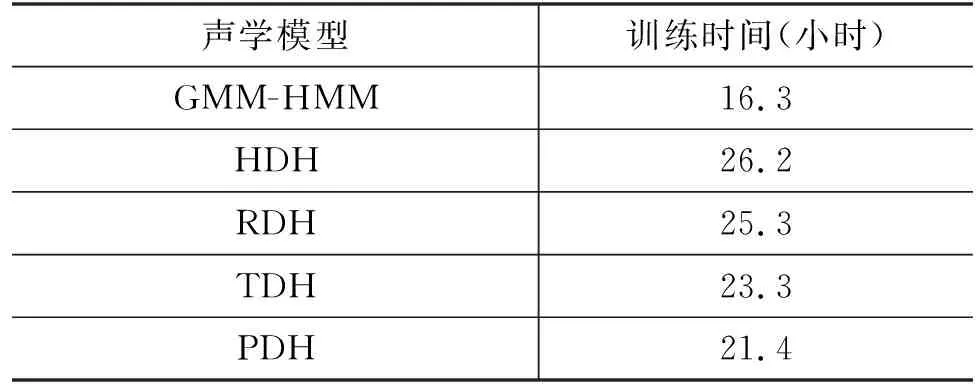
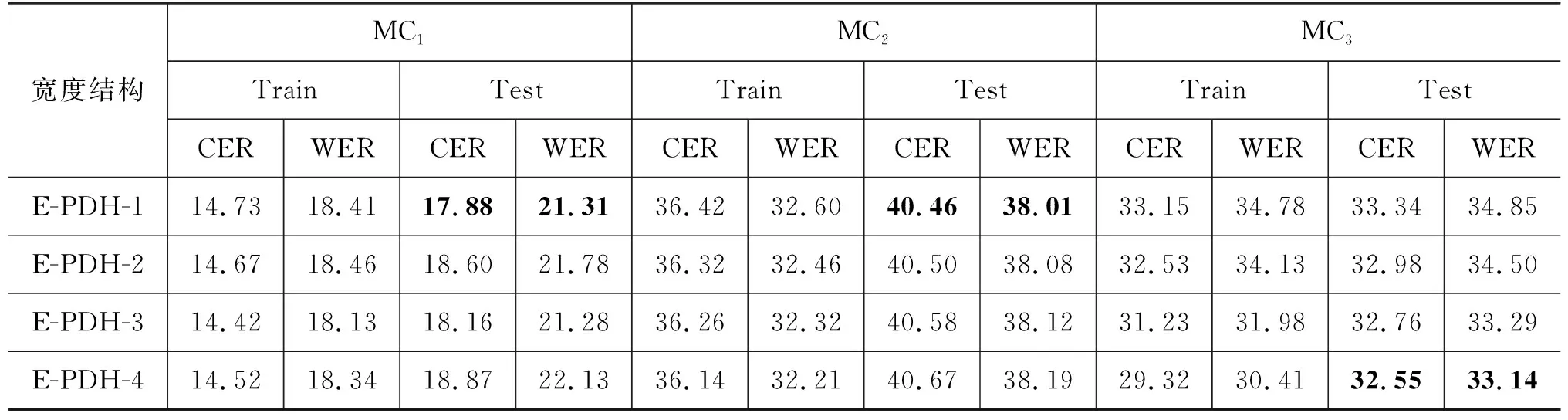
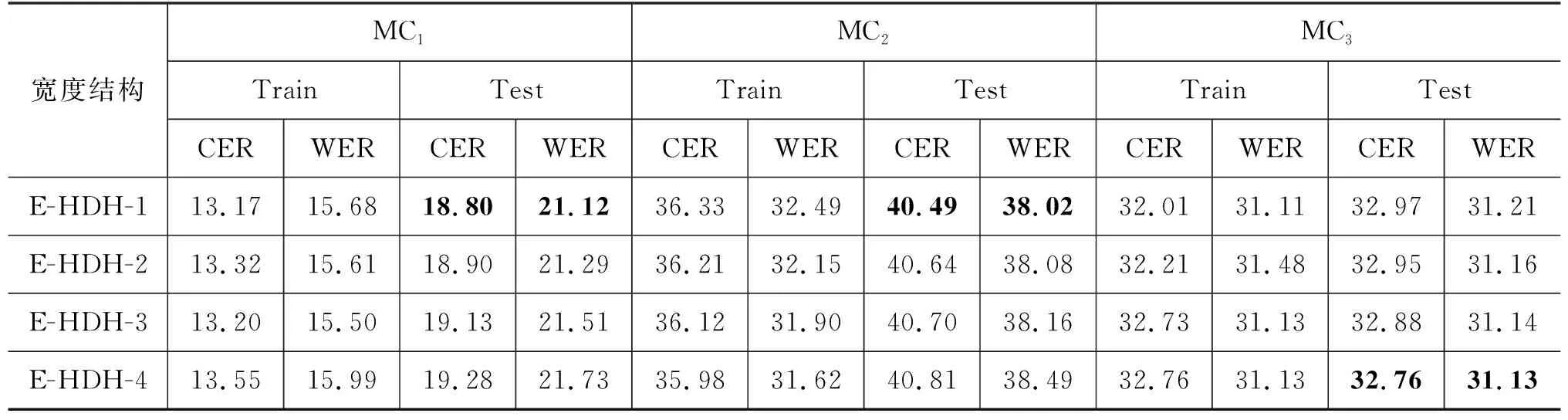
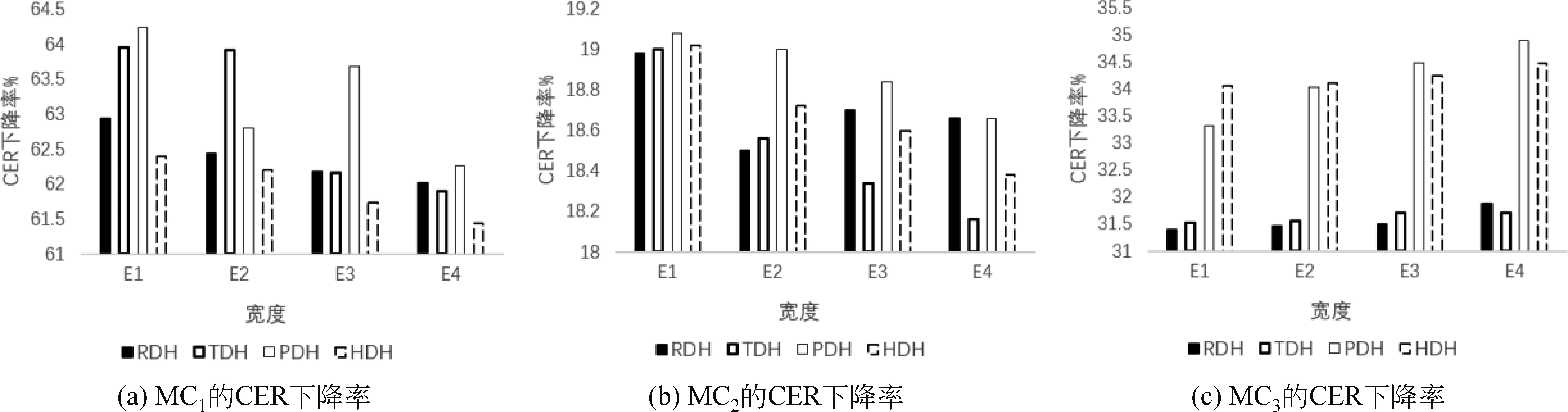
在Trapezoid DNN-HMM蒙古语声学模型结构中,DNN多层隐藏层的形状为倒梯形,如图3所示,DNN由输入层L0、输出层Ln+1,以及形状为倒梯形的n层隐藏层L1,…,Ln组成,n层隐藏层各层的宽度从L1到Ln逐步递增,即widthL1<… 图3 Trapezoid DNN-HMM模型结构 在Polygon DNN-HMM蒙古语声学模型结构中,DNN多层隐藏层的形状为六边形,如图4所示,DNN由输入层L0、输出层Ln+1,以及形状为六边形的n层隐藏层L1,…,Lm,…,Ln组成,n层隐藏层中间层Lm的宽度最宽,并且从Lm开始向两端递减,位于隐藏层两端的L1和Ln层的宽度相等,并且是隐藏层中宽度最小的层,即widthLm>…>widthL1且widthLm>…>widthLn,同时widthL1=widthLn、…、widthLm-1=widthLm+1。W0、W1、…、Wn表示各相邻层之间的参数数量。 在Hourglass DNN-HMM蒙古语声学模型结构中,DNN多层隐藏层的形状为沙漏形,如图5所示,DNN由输入层L0输出层Ln+1,以及形状为沙漏形的n层隐藏层L1,…,Lm,…,Ln组成,n层隐藏层中间层Lm的宽度最小,从中间层Lm开始向两端递增,位于隐藏层两端的L1和Ln层的宽度相等,并且是隐藏层中宽度最大的层,即widthLm 图5 Hourglass DNN-HMM模型结构 使用蒙古语语料库构建不同结构的DNN-HMM蒙古语声学模型时,采用单卡GPU进行训练。实验硬件环境如表1所示,包括GPU的配置详情、硬盘和CUDA的版本号。 表1 实验硬件环境 在Kaldi平台进行实验时[21],选用音素作为建模单元来构建DNN-HMM蒙古语声学模型,每条语音的采样率为16 000Hz,特征提取使用梅尔频谱倒谱系数(Mel Frequency Cepstrum Coefficient MFCC)技术。MFCC提取特征的参数设置如下:三角滤波器40个,声学特征维度40维,倒谱数量为40,低截止频率40Hz,高截止频率-200Hz。在训练DNN网络时,超参数的设置如表2所示,每个Batch_Size有512个语音帧,解码时每次解码8帧,每个语音帧左右各10个语音帧上文和下文,HMM的状态数共2 500个,训练的过程中不使用i-vector。 蒙古语语料库(Mongolian Corpus MC)分为三类[22],如表3所示,MC1是从蒙古语图书中摘取200条文本进行100人转录,共23.5h。MC2是从中国新闻网(蒙语版)中选取200条文本进行110人转录,共40.8h。MC3是MC1和CM2的集合,共64.3h。MC1、MC2、MC3的总时长依次相差约20h。 表3 蒙古语语料库信息 在DNN-HMM声学模型训练过程中,数据集按照8∶1∶1的比例分为训练集、验证集和测试集,如表4所示。 表4 数据集划分 在实验过程中,DNN-HMM蒙古语声学模型使用音素作为建模单元,选用字错率(Character Error Rate,CER)用来评价蒙古语声学模型对音素预测的准确率。CER指已知标注文本与解码的结果,将解码结果中错误字符的累计个数除以标注中总的字符数,如式(2)所示。 其中,i表示字符插入错误(Insertion,i),d表示字符删除错误(Deletion,d),s表示字符替换错误(Substitute,s),n表示总字符数。 选用词错率(Word Error Rate,WER)用于评价蒙古语语音识别的准确率。WER指已知标注文本与解码的结果,将解码结果中错误词的累计个数除以标注中总的词数,如式(3)所示。 其中,I表示词插入错误(Insertion,I),D表示词删除错误(Deletion,D),S表示词替换错误(Substitute,S),N表示总词数。 实验使用MC1、MC2、MC3三种不同规模的蒙古语语料库作为数据集来构建DNN-HMM蒙古语声学模型,包括收敛性实验、深度结构实验和宽度结构实验。 (1) 收敛性实验保证RDH、TDH、PDH和HDH四种结构的DNN-HMM蒙古语声学模型在训练时收敛,从而保证深度结构实验和宽度结构实验的有效性。 (2) 深度结构实验在确定DNN-HMM模型宽度的基础上,使用MC1、MC2、MC3三种不同蒙古语语料库构建RDH、TDH、PDH和HDH四种不同深度结构的DNN-HMM蒙古语声学模型。 (3) 宽度结构实验在深度结构实验的基础上确定深度结构,使用MC1、MC2、MC3三种不同蒙古语语料库构建RDH、TDH、PDH和HDH四种不同宽度结构的DNN-HMM蒙古语声学模型。 使用MC1、MC2、MC3三种蒙古语语料库构建GMM-HMM蒙古语语音识别模型在训练集和测试集上的词错率和字错率,如表5所示。 表5 GMM-HMM实验结果 本实验使用MC1、MC2、MC3三种不同规模的蒙古语语料库,构建了RDH、TDH、PDH和HDH四种结构的DNN-HMM蒙古语声学模型,通过收敛性实验、深度结构实验和宽度结构实验得出评价蒙古语声学模型对音素预测准确率的CER和评价蒙古语语音识别准确率的WER。以下是实验的结果与分析。 在构建DNN-HMM声学模型的过程中,收敛性实验能够证明模型收敛且没有过拟合,从而保证后续实验结果的有效性。该实验选用MC2语料库训练四种声学模型时的损失变化趋势,验证模型的收敛性,四种声学模型均为深为6层,输入层为256层,输出层为1 024层的RDH(隐藏层:640、640、640、640)、TDH(隐藏层:376、496、616、736)、PDH(隐藏层:576、736、576、256)和HDH(隐藏层:736、576、576、736)结构,其收敛性实验结果分别如图6中的(a)、(b)、(c)、(d)所示,四者在训练集上的损失均下降并趋于稳定,同时验证集的损失在一定程度的下降后同样趋于平稳,这表明四种结构DNN-HMM蒙古语声学模型在训练过程中收敛;验证集的损失大于训练集的损失,表明四种DNN-HMM声学模型没有过拟合。 图6 MC2构建四种声学模型的收敛性实验结果 在使用MC2语料库构建不同蒙古语声学模型时,GMM-HMM和四种DNN-HMM声学模型的训练时间如表6所示。受深度神经网络的影响,DNN-HMM声学模型的训练速度比GMM-HMM声学模型更慢;在DNN深度确定的情况下,受隐藏层宽度的影响,四种DNN-HMM声学模型的神经元数量从大到小依次为HDH、RDH、TDH、PDH,随着神经元数量增加,模型的训练时间也会随之增加。 表6 蒙古语声学模型训练时间 在模型深度结构实验中,根据输入声学特征的维度,设定输入层的宽度为256,输出层的宽度为1 024。将RDH、TDH、PDH、HDH四种结构中多层隐藏层的宽度进行限定,即保证四种声学模型特有的结构不发生变化,同时将宽度对模型结构的影响降到最低,使深度成为主要的影响因素,进行模型深度结构实验。深度结构实验中训练集的CER、WER与验证集的CER、WER通过对比,证明模型不存在过拟合现象,保证了实验的有效性。RDH不同深度(Deep)的模型结构如表7所示,深度分别为5、6、7、8、10、12层,隐藏层宽度为640的矩形结构。如D-RDH-1表示隐藏层宽度为640,深度为5层的RDH蒙古语声学模型。 表7 RDH深度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同深度RDH蒙古语声学模型的过程中,三种MC的训练集、测试集在RDH声学模型上的CER和WER如表8所示。 表8 RDH深度结构实验结果 (单位: %) TDH不同深度(Deep)的模型结构如表9所示,深度分别为5、6、7、8、10、12层,隐藏层宽度的限定范围为[320,896]且相邻层宽度相差64的倒梯形结构。如D-TDH-1表示隐藏层宽度为384,512,640,深度为5层的TDH蒙古语声学模型。 表9 TDH深度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同深度TDH蒙古语声学模型的过程中,三种MC的训练集、测试集在TDH声学模型上的CER和WER如表10所示。 表10 TDH深度结构实验结果 (单位: %) PDH不同深度(Deep)的模型结构如表11所示,深度分别为5、6、7、8、10、12层,隐藏层中间位置宽度大于两端且相邻层宽度相差128的六边形结构。如D-PDH-1表示隐藏层中心位置宽度为512、深度为5层的PDH蒙古语声学模型。 表11 PDH深度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同深度PDH蒙古语声学模型的过程中,三种MC的训练集、测试集在PDH声学模型上的CER和WER如表12所示。 表12 PDH深度结构实验结果 (单位: %) HDH不同深度(Deep)的模型结构如表13所示,深度分别为5、6、7、8、10、12层,隐藏层中间位置宽度小于两端且相邻层宽度相差128的沙漏形结构。如D-HDH-1表示隐藏层中心位置宽度为384,深度为5层的HDH蒙古语声学模型。 表13 HDH深度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同深度HDH蒙古语声学模型的过程中,三种MC的训练集、测试集在HDH声学模型上的CER和WER如表14所示。 表14 HDH深度结构实验结果 (单位: %) 在宽度结构实验中,限定RDH、TDH、PDH、HDH四种结构的DNN-HMM声学模型的深度为6层,宽度结构实验中训练集的CER、WER与验证集的CER、WER通过对比,来证明模型不存在过拟合现象,保证了实验的有效性。 RDH不同宽度(Extend)的模型结构如表15所示,E-RDH-1、E-RDH-2、E-RDH-3、E-RDH-4深度均为6层,它们的隐藏层宽度分别为384、512、640、768。例如表15中E-RDH-1表示隐藏层宽度为384,深度为6层的RDH蒙古语声学模型。 表15 RDH宽度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同宽度RDH蒙古语声学模型的过程中,三种MC的训练集、测试集在RDH声学模型上的CER和WER如表16所示。 表16 RDH宽度结构实验结果 (单位: %) TDH不同宽度(Extend)的模型结构如表17所示,E-TDH-1、E-TDH-2、E-TDH-3、E-TDH-4分别是深度为6层的倒梯形结构,它们隐藏层宽度的增长率分别为40、80、120、160。例如表17中E-TDH-1表示隐藏层宽度增长率为40,深度为6层的TDH蒙古语声学模型。 表17 TDH宽度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同宽度TDH蒙古语声学模型的过程中,三种MC的训练集、测试集在TDH声学模型上的CER和WER如表18所示。 表18 TDH宽度结构实验结果 (单位: %) PDH不同宽度(Extend)的模型结构如表19所示,E-PDH-1、E-PDH-2、E-PDH-3、E-PDH-4分别是深度为6层的六边形结构,其中隐藏层中间层的宽度大于两边的隐藏层,中间层的宽度分别设为456、512、640、768,左右两层均按160递减。例如,表19中E-PDH-1表示隐藏层最大宽度为456,左右两层按160递减,深度为6层的PDH蒙古语声学模型。 表19 PDH宽度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同宽度PDH蒙古语声学模型的过程中,三种MC的训练集、测试集在PDH声学模型上的CER和WER如表20所示。 表20 PDH宽度结构实验结果 (单位: %) HDH不同宽度(Extend)的模型结构如表21所示,E-HDH-1、E-HDH-2、E-HDH-3、E-HDH-4分别是深度为6层的沙漏形结构,隐藏层中间位置宽度小于两端且相邻层宽度相差160。如表21中D-HDH-1表示隐藏层中心位置宽度为384,深度为5层的HDH蒙古语声学模型。 表21 HDH宽度结构 在使用MC1、MC2、MC3三种蒙古语语料库构建不同宽度HDH蒙古语声学模型的过程中,三种MC的训练集、测试集在RDH声学模型上的CER和WER如表22所示。 表22 HDH宽度结构实验结果 (单位: %) 为了对宽度结构实验和深度结构实验进行分析,本节提出错误下降率(Error drop rate)公式,如式(4)所示,其中Error可以表示CER或WER,base表示CER和WER的基准,实验中两者的base均设置为50%。 4.4.1 深度结构实验分析 选择50%的CER作为声学模型的评价基准,对深度结构实验结果进行分析,训练集的CER、WER均小于测试集的CER、WER,这表明模型不存在过拟合现象,由此可以保证整体实验的有效性。MC1、MC2、MC3作为测试集在不同深度的蒙古语声学模型下CER的下降率如图7中的(a)、(b)、(c)所示,模型深度从6层开始,随着深度的增加,三种语料库的CER下降率以50%为基础整体降低呈降低趋势,即CER随着深度的增加而增加。分析得出三种MC在6层PDH结构的声学模型下CER最低。 图7 三种蒙古语语料库在深度不同的四种蒙古语声学模型上的CER下降率 选择50%的WER作为语音识别的评价基准,三种MC测试集在不同深度的蒙古语声学模型下WER的下降率分析结果如图8中的(a)、(b)、(c)所示。当深度大于6层时,随着模型深度的增加,WER下降率最高的声学模型结构与CER下降率最高得声学模型结构相同,均为6层PDH结构。 图8 三种蒙古语语料库在深度不同的四种蒙古语声学模型上的WER下降率 4.4.2 宽度结构实验分析 在深度结构实验的基础上,确定模型的深度为6层,宽度(Extend)从小到大分为E1、E2、E3、E4四种,选择50%的CER作为基准来观察三种MC测试集在不同宽度的蒙古语声学模型下CER的下降率。MC1、MC2、MC3在宽度不同的蒙古语声学模型下CER下降率的分析结果如图9的(a)、(b)、(c)所示,随着宽度的增加,MC1、MC2的CER下降率均呈下降趋势,相同宽度下MC2的CER下降率远小于MC1,但MC3的CER下降率呈上升趋势。分析得出,MC1、MC2适合使用E1宽度的PDH结构构建蒙古语声学模型,而MC3适合使用E4宽度的PDH结构构建蒙古语声学模型。随着MC规模的增加,适当增加宽度可使对应语料库构建的语言识别模型CER下降。 图9 三种蒙古语语料库在宽度不同的四种蒙古语声学模型上的CER下降率 选择50%的WER作为基准来观察三种MC测试集在不同宽度的蒙古语声学模型下WER的下降率。MC1、MC2、MC3在宽度不同的蒙古语声学模型下WER下降率分析结果如图10中的(a)、(b)、(c)所示。随着宽度的增加,MC1、MC2的WER下降率呈下降趋势,而MC3的WER下降率呈上升趋势。随着模型宽度的改变,CER和WER的下降率保持一致,即随着MC规模的增加,适当增加宽度可使对应语料库构建的语音识别模型WER下降。 本文提出了RDH、TDH、PDH和HDH四种不同结构的蒙古语声学模型,并在20h、40h和60h三种规模的蒙古语语料库上分别实现了构建。在CER和WER的变化趋势一致的情况下,得到以下结论: ①采用以上三种规模的蒙古语语料库分别构建了三个GMM-HMM蒙古语声学模型,在CER、WER上均高于对应的RDH、TDH、PDH和HDH模型,即DNN-HMM蒙古语声学模型在识别率上优于GMM-HMM蒙古语声学模型。②在使用同等规模蒙古语语料库构建DNN-HMM声学模型时,深度为6层的PDH结构优于其他结构,表明6层PDH声学模型能够更好地学习蒙古语语音特征。③当语料库的规模从20h增加到60h的过程中,通过适当增加声学模型的宽度,能够使模型学习到更加丰富的语音特征,从而降低蒙古语语音识别系统的CER和WER。 然而,本文提出的四种DNN-HMM声学模型仅使用蒙古语音素作为建模单元进行建模。在未来的研究中,需要使用英语、汉语等不同语言进行四种声学模型的建模实验对比,确定DNN-HMM声学模型结构与不同语言之间的关系;使用字符和词等不同的建模单元进行建模,进一步确定DNN-HMM声学模型结构与不同建模单元之间的关系。
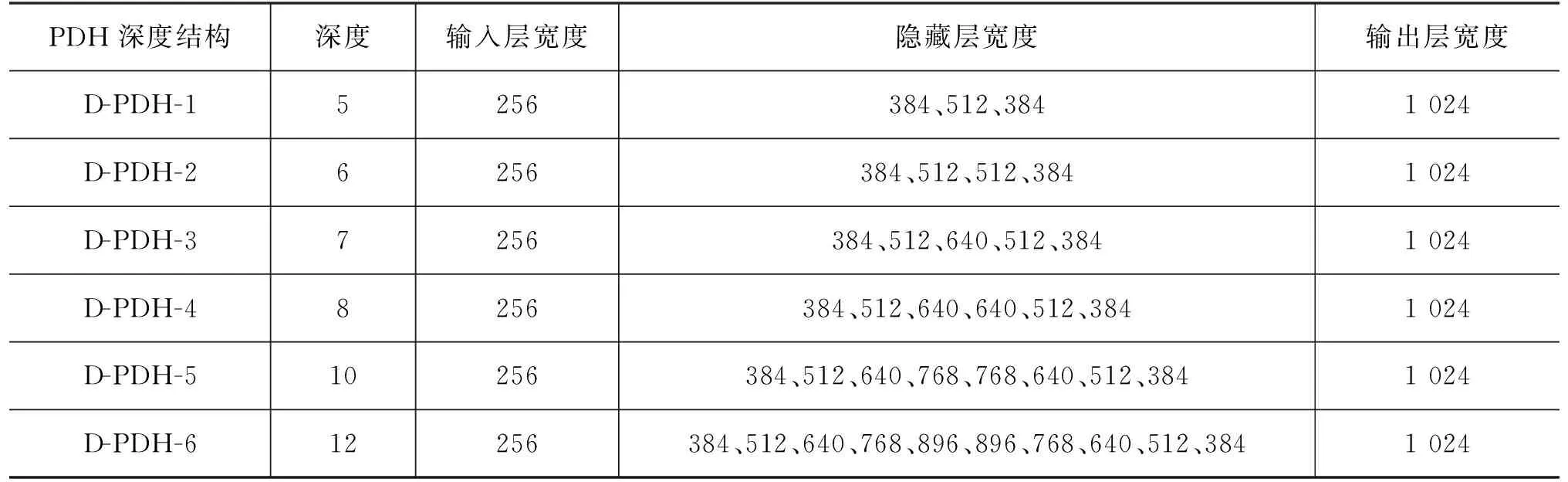
2.3 Polygon DNN-HMM
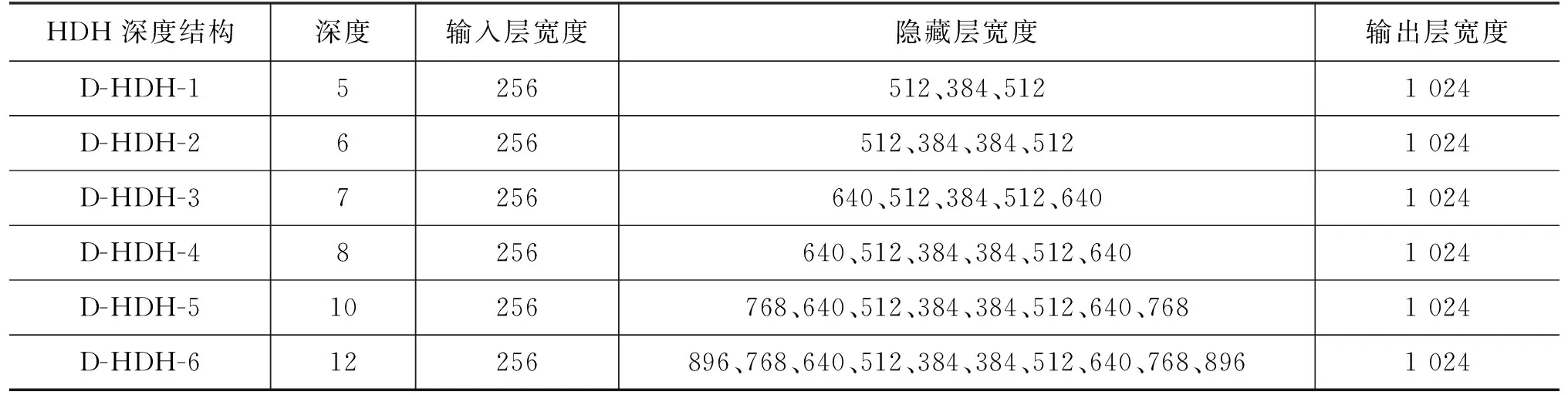
2.4 Hourglass DNN-HMM
3 实验
3.1 实验设置
3.2 数据准备
3.3 评价指标
3.4 实验方案
4 实验结果与分析
4.1 收敛性实验
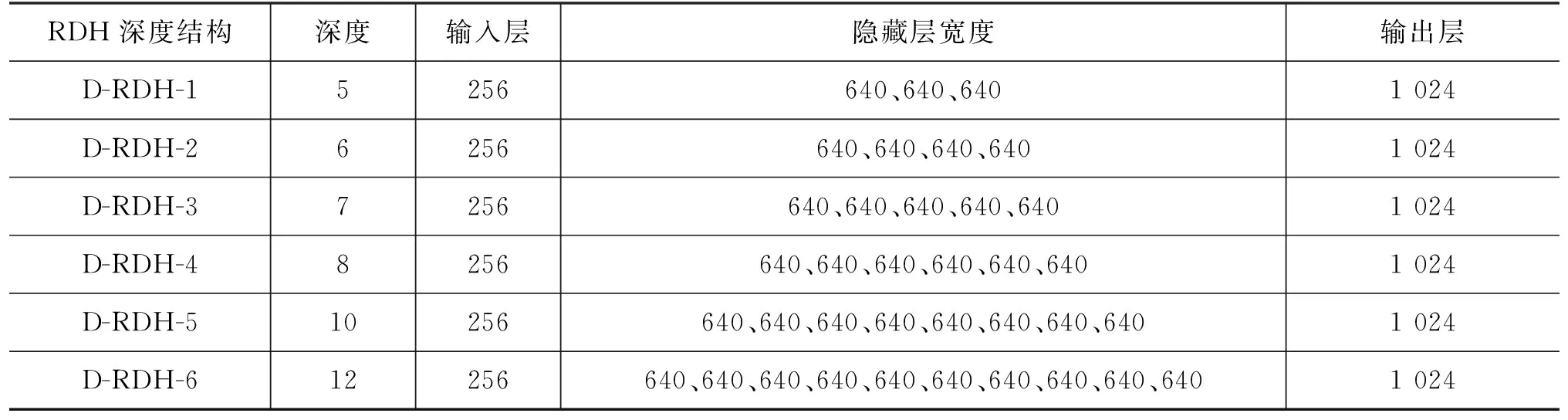
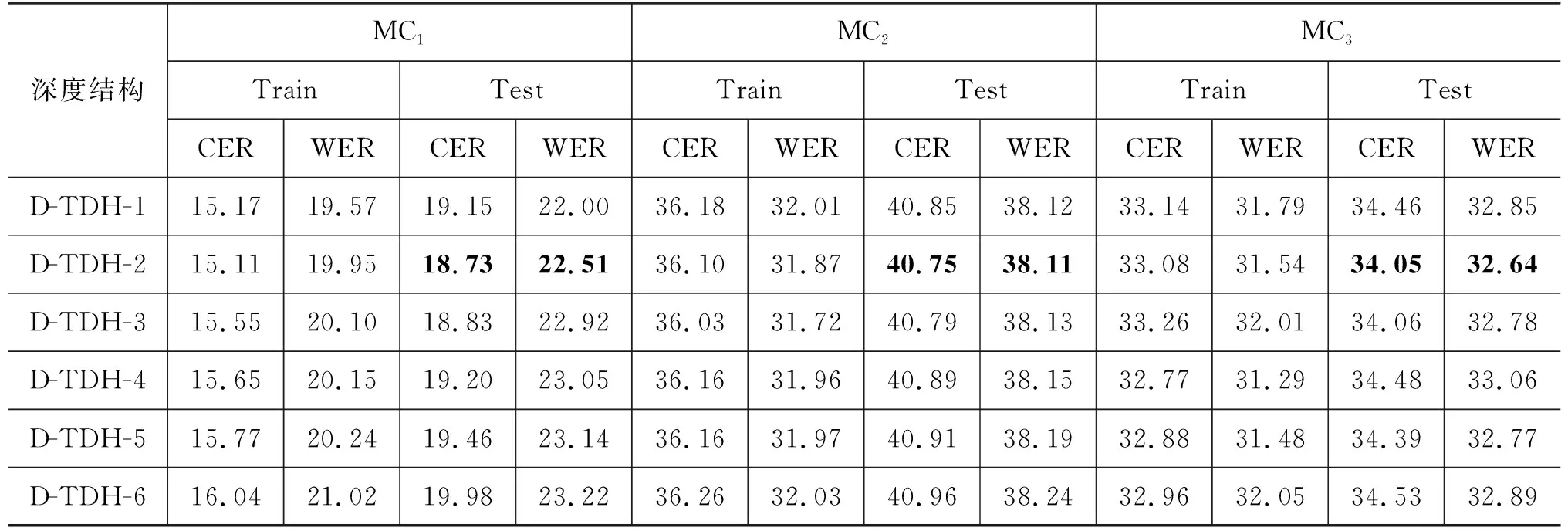
4.2 模型深度结构实验

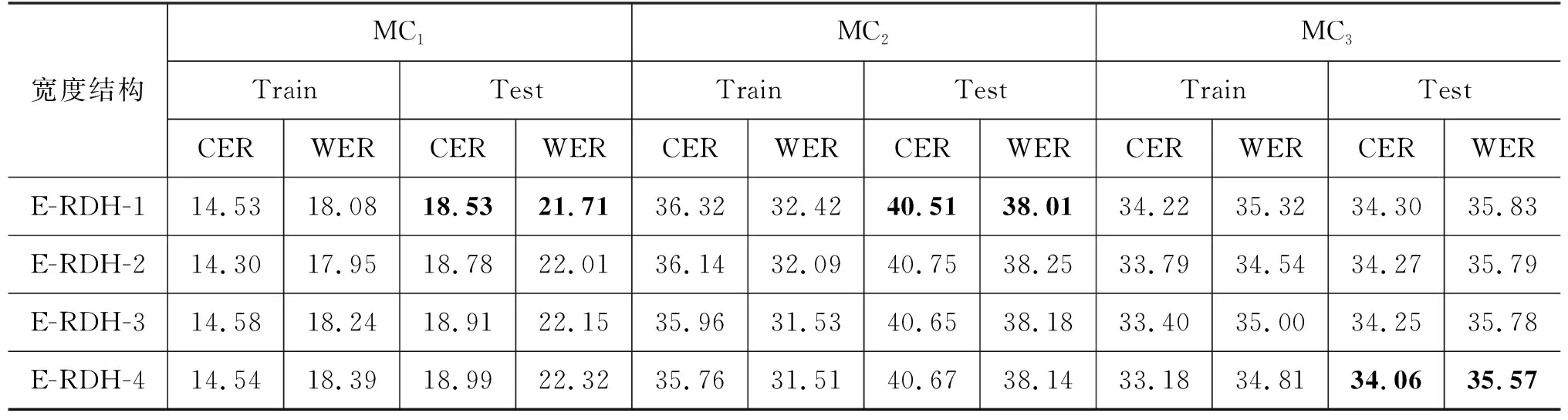
4.3 模型宽度结构实验





4.4 分析


5 结论
猜你喜欢
西部蒙古论坛(2022年2期)2022-07-12家庭影院技术(2020年6期)2020-07-27蒙古学问题与争论(2020年0期)2020-03-29天津外国语大学学报(2020年1期)2020-03-25家庭影院技术(2019年1期)2019-01-21家庭影院技术(2018年11期)2019-01-21家庭影院技术(2018年10期)2018-11-02赤峰学院学报(蒙文哲学社会科学版)(2018年1期)2018-04-25卫拉特研究(2016年0期)2016-12-06语言与翻译(2015年4期)2015-07-18
