
基于贝叶斯MCMC 方法的城市建筑供热能耗基准
2023-10-24 10:09那威邴佳乐刘品妍
浙江大学学报(工学版) 2023年10期
那威,邴佳乐,刘品妍
(1.北京建筑大学 环境与能源工程学院,北京 100044;2.北京建筑大学 建筑与城市规划学院,北京 100044)
我国民用建筑终端能耗和碳排放分别占全国总量的21.2%和21.6%,其中北方城镇建筑供热能耗占建筑终端能耗已近1/4,是建筑领域实现“双碳”规划目标的重点领域.德、英、美、丹麦等国已经应用整体能效法对建筑能耗进行管控,而我国目前仍处于向能耗限额法和整体能效法的过渡阶段[1].建筑能耗限额、整体能效分析是建筑能耗基准分析的基础环节.不同时空尺度建筑实际能耗与能耗基准之间的对比,可以作为建筑设计、建造及运行阶段用能情况的评估方法[2].建筑能耗基准分析已成为现阶段建筑全过程节能优化领域的研究热点.
建筑能耗预测分析方法对能耗基准指定的支撑显得尤为重要.大量学者开展对建筑能耗预测模型、方法和模式的研究及应用实践.在国家、省级区域尺度上,德国通过VDI 3807 标准统计全国调查样本的分类建筑实际能耗概率,概率分布中前四分位数、中位数作为能耗标准值和指导值[3].英国、澳大利亚等国实施的EEBPP 项目、step to benchmark energy use 项目采用样本数据调查和统计分析结合方法确定建筑基准能耗[2,4].在单体建筑、街区等尺度上,部分学者提出利用物理正演模拟、正向模型仿真来描述建筑能耗与建筑特征参数之间的“目标-特征”关系[5],采用物理仿真模型和计算流体力学技术结合的能耗模拟引擎和工具,如DOE2[6]、Energy Plus[7]、Design Builder[8]等;另一部分学者提出数据驱动的黑箱或反向模型描述上述数学联系,建立神经网络[9]、广义线性回归[10-11]、人工智能[12]等黑箱模型,通过带有建筑特征和能耗响应数据的建筑仿真样本或建筑实际样本对模型进行训练及校验,如支持向量机(support vector machines,SVM)[13]、决策树和随机森林等基于树的模型[14-15]、人工神经网络(artificial neutral network,ANN)[16]等.部分学者结合物理正演和数据驱动算法[17]提出白、黑箱模型结合的混合模型,如阻容(RC)热网络模型等[18-19].上述建筑能耗预测方法用于城市尺度建筑能耗基准分析,仍存在一些不足之处:一方面我国研究中仍缺乏自上而下的统计模型来计算能耗基准所需的数据基础,统计数据存在时空分辨率较低的问题,在统计口径、范围、完整性和准确性方面仍存在诸多争议[20-22];另一方面通过自下而上的模型发现,若采用物理正演模型,模型构建中所需建筑形态等建模基础信息量较大且通常难以获得,建模难度高[23].若采用数据驱动模型或者混合模型,在训练模型采用仿真样本时,数值仿真建模和求解所需计算资源和时间成本通常过高[5],采集样本和建模所需的基础信息量、建模难度、计算资源和时间成本有所下降[24-25].因此,如何在城市尺度建筑样本数量和维度有限的情况下,降低校准模型有限输入和不确定性对预测性能的影响,仍是目前待解决的问题.
本研究针对有限样本和输入不确定性的处理及计算效率优化,提出基于贝叶斯框架的混合效应模型.将热力站供热能耗强度监测数据作为测试样本集,并利用马尔科夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)方法进行重要性采样,对特征空间实现全局搜索以推断模型以及超参数峰值概率的分布,寻找指定建筑特征的预测能耗全局最优解邻域,以最大程度考虑城市尺度全局建筑特征的供热能耗分布,将模型EUIH 点估计和区间估计结果作为能耗基准确定依据.
1 能耗预测模型构建
对比典型能耗预测模型的所需信息量、建模难度、样本量、计算资源和时间成本,如图1 所示,图中圆形面积大小代表相应模型所需的样本量.城市尺度建筑能耗预测和校准的主要挑战是如何在建筑样本有限、输入不确定和建模难度、求解计算资源和时间成本条件下构建合理模型并求解.
1.1 建筑能耗预测模型框架
在建筑使用过程中,供热能耗影响因素众多且庞杂,因素作用效应各异,受采集样本缺乏、反映建筑或热力站能耗特征的数据维度不足的训练数据限制,难以充分观察全部能耗因素及其数据水平.将供热能耗影响因素尽然纳入建模过程,且需考虑建模中难以观测的遗漏变量、采集范围
抽样偏差、采集数据偏误等数据不确定性对模型准确性的影响.根据已有数据库的数据量和数据维度情况,参考能耗预测[26-30]和循证医学领域[31-35]类似多因素、少样本、因素异质性、不确定性和因素效应耦合下建模的探索.本研究构建了基于贝叶斯框架建筑能耗预测的混合效应概率模型,模型框架为一种采用随机待估超参数的分层、变截距、变斜率、广义线性固定效应的数据驱动模型,目标函数为
式中:yf(x) 为建筑EUIH 的观测数据,x为建筑特征相关的输入变量, θ 为模型调整超参数(θm,b,εf)向量,yr(x,θr) 为建筑EUIH 的预测值,ym(x,θ) 为模型固定效应结构项,b(x) 为模型个体特质效应项,εf为模型预测的独立随机误差.
模型中固定效应结构项利用现有数据库中的有限数据维度信息,反映出建筑共性解释变量对能耗的真实效应量,包括城市气候、建筑分布、建造状况和样本的供热服务建筑规模共4 个维度数据.1)样本的建筑建造状况维度相关解释变量.输入样本热力站所服务居住建筑的建造节能水平,根据居住建筑所采用的节能设计标准情况(非节能或采用30%、50%、65% 居住建筑节能设计标准)采用哑变量分别带入.2)城市气候维度相关解释变量.本研究根据样本供暖期的供热需求,输入反映热力站当地供暖期室外气温和供热天数的综合参数,采用样本供暖期度日数为解释变量之一.供暖期度日数指标是样本室内基准18 ℃与采暖期室外平均温度之间的温差,乘以当年采暖期延续时间(d).3)城市建筑分布维度相关解释变量.根据不同建造水平的建筑在城市建筑中的分布状况,输入指定建造状况建筑相关热力站样本占样本热力站总数占比.4)样本的供热服务建筑规模维度相关解释变量.输入热力站样本服务居住建筑的供热面积.
模型中个体特质效应项反映了难以识别或观测的潜变量对样本能耗的效应,包括建筑人员活动和行为变化、建筑用能设施设备配置和使用建筑建造水平等潜变量的相关效应.模型中调整超参数为模型待估参数,区别于频率学派极大似然估计(maximum likelihood estimation,MLE)等算法将模型待估参数视为固定值.在贝叶斯推断中,模型固定效应结构项及个体特质效应项的待估参数均为随机参数.在后续计算中,通过样本数据训练,应用贝叶斯推断和MCMC 采样推断出上述参数的后验概率分布.实际样本数据提供直接、原始的建筑能耗与不确定性因素之间的关系,纳入建筑实际运行中很多非理想的因素,模型输出反映输入不确定性的随机效应,包括观测误差、采样偏误和其他参数异质性因素.该模型通过寻找具有峰值概率的点估计表示参数估计值的可信度和不确定性,用以控制目标预测分布的特征.
为了消除原始连续型变量之间因性质、量纲、数量级等属性的差异而带来的影响,采用自然对数映射方式将模型变量转化为无量纲的标准化数值,从而在不改变变量特征的同时,使得不同变量的效应大小具有可比性.上述混合模型中基于贝叶斯框架的模型对数映射为
1.2 后验分布构建
根据贝叶斯原理,模型利用观测数据,并将似然分布和先验分布结合,推断、构建模型的后验分布函数.将模型调整超参数视为随机参数[28,36-37],观测数据和建筑特征相关参数视为模型输出和输入的随机变量,基于贝叶斯原理的后验分布函数为
式中:P(θ|y) 为模型超参数后验分布;P(y|θ) 为模型观测数据的似然分布;P(θ) 为模型超参数先验分布;P(y) 为观测数据的边缘分布,该值是与参数θ无关的标准化常数,可以忽略P(y) 的具体数值.
通过搜索P(θ|y)P(θ) 的峰值概率值,从而确定后验分布的峰值概率值,最大后验(maximum a posteriori, MAP)估计为
极大似然估计(maximum likelihood estimation,MLE)或MAP 均使用点估计来推导后验分布,但是MLE 的不确定性由渐近特征决定,在计算过程中不纳入先验信息,完全利用样本统计量估计总体参数.若是MAP 估计的先验分布设定为均匀分布,则MAP 的估计结果将与MLE 的估计结果相同,即
城市尺度建筑能耗模型的预测和校准过程往往会有数据不足的问题[38].MLE 估计的渐近特性将导致当观测数据不足时不能很好地利用有限的数据,从而容易导致过拟合和一类误差问题[36-37].因此,提出在贝叶斯框架下与MAP 估计相结合的建模方式是提高有限样本信息利用以及提高预测效果的关键改进.
1.3 先验分布的构建
先验分布P(θ) 为模型中超参数的客观特征,通常根据经验判断方式给定,相关研究认为对先验分布的不同设定将影响后验分布的计算过程,但是否会造成贝叶斯估计结果的显著差异仍有争论[39-40].在模型超参数的先验分布设定中采用无信息先验.无信息先验等模糊先验与信息先验相比,未对后验分布推断进行约束,使得超参数的推断处于可以接受的范围内[36-37].通过模糊先验归一化,可以适应观测数据存在信息缺失、信息弱或稀疏的情况.模型中超参数 π1、π2、π3、π4和π0的先验分布均设定为高斯分布G(0,1×10-6) ;超参数b的先验分布设定为伽马分布 Ga(αf,βf) ,其中形状参数 αb、尺度参数 βb均设为1 ×10-3;模型误差 εf为精度因子 σf的函数,精度因子 σf的先验分布设定为 Ga(1×10-3,1×10-3) ,具体计算式为
1.4 MCMC 重要性采样和推断
模型超参数的联合后验分布P(θ|y) 整合了先验信息和观测数据的似然信息,通常具有较复杂的函数形式,如式(3)所示,几乎无法求出并从其分布中进行直接采样.采取MCMC 方法从后验分布P(θ|y) 中进行重要性采样,当生成的马尔科夫链达到收敛时,用所获得平稳分布作为所求联合后验分布的估计结果[28,36],MCMC 方法流程如图2 所示.
重要性采样中采用梅特罗波利斯-黑斯廷斯(Metropolis Hastings,MH)算法生成3 条马尔可夫链[28,36].在MH 算法中采用细致平衡条件Jt(θ∗|θ(t-1))=Jt(θ(t-1)|θ∗)推出平稳分布,获取所需重要性样本的分布即为所求后验分布.该算法的主要流程为
1)获取 θ(0),给参数向量赋初值.
2)获取 θ(t),第t步迭代抽样中给参数向量赋值的步骤:从建议概率分布Jt(θ∗|θ(t-1)) 中采样,获得新候选参数向量 θ∗;从均匀分布中采样随机数u服从[0,1]上的均匀分布.引入并计算接受率 αLC为
3)判断是否接收新候选向量参数 (接受转移的新候选向量参数时αLC>u,拒绝转移的新候选向量参数时αLC<u)得:
该算法通过完成指定迭代次数并判断马尔科夫链达到收敛后结束[28,36],从而使遍历马尔可夫链的极限分布收敛于平稳分布.
2 训练集数据来源
模型训练集包括北京市223 个居住建筑热力站随机采集样本,样本来自北京某大型热力公司,该公司采用热力站供热的民用建筑面积为950 hm2,共有热力站总量5 875 个.模型训练集样本按照样本EUIH 值区间、样本中居住建筑所采用居住建筑节能设计标准的分布情况见表1,其中S为样本量,Sp为样本量占比,A为样本供热面积,Ap为样本供热面积占比.
本研究通过热力站能耗监测系统自动抄表数据库中汇总的逐时能耗数据,将年供热能耗强度的数据进行整理,包括2017、2018、2019 年共3 年供暖季,同时采集接入相应热力站的建筑相关特征数据.考虑到数据采集设备可能存在运行异常等情况,造成所采集的数据存在异常值和缺失值,为了保证样本数据质量,采用 3σ 准则[41]对数据异常值进行剔除,采用拉格朗日插值法[42]对数据缺失值进行插补.
3 模型收敛判断与验证
3.1 模型收敛判断
通过马尔科夫链蒙特卡洛(MCMC)方法模拟重要性采样,获得的样本可用前提是马尔科夫链达到收敛,收敛性可以通过计算并检查潜在尺度缩减因子Rˆ (部分文献称为bgr(Brooks-Gelman-Rubin)指标)进行判断[43-44].当模拟开始时,M条马尔科夫链在N个样本中,进行连续并随机采样,利用每条链的轨迹图来检查和设定退火时间Nburn-in以去除退火内的迭代,跳过不稳定阶段.在每条链划分为2 个阶段,M+M链中均有(N-Nburn-in)/2的时间间隔,若是M+M链在2 阶段中,迭代结果差异已经达到设定精度要求,则说明该链趋于平稳,迭代N次已经足够,否则迭代应继续进行.所需迭代次数根据因子Rˆ 确定,因子Rˆ 降至1.1 时停止迭代,当达到1.0 时的效果最佳,经验认为链中迭代数应至少超过5×(M+M)[36,45].
本研究模型构建和相关算法采用R 语言和R2winbugs 程序包编写和实现.计算中共进行30 000 次迭代,其中退火去除初始10 000 次迭代,根据达到平稳分布后的样本对模型中的参数进行估计.以超参数 π4为例,图3 为3 条马尔科夫链迭代过程的潜在尺度缩减因子轨迹,t为迭代步数,左轴为 π4的潜在尺度缩减因子,D为马尔科夫链中采样80%分布区间的标准化宽度,可见退火10 000次迭代后该因子迭代中低于1.1 且接近1.0.
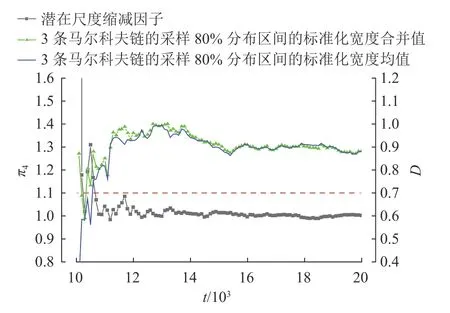
图3 潜在尺度缩减因子轨迹Fig.3 Trace of potential scale reduction factor
图4为3 条马尔可夫链的迭代轨迹,可见3 条马尔科夫链的轨迹历史明显重叠.上述结果显示3 条马尔可夫链的重要性采样已收敛,模型中其他超参数均具有相似收敛特征.
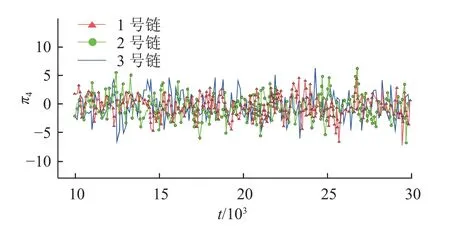
图4 3 条马尔可夫链迭代轨迹图Fig.4 Trace plot of 3 Markov chains in iterations
3.2 模型验证
采用预测残差自相关性检验验证模型,以评估所构建模型描述输入和输出关系的可靠性.图5为模型参数估计中3 条马尔可夫链残差自相关函数, ACF 为自相关函数,L为迭代滞后阶数.可见迭代过程中3 条马尔可夫链的自相关函数均呈现明显向零值震荡衰减趋势,说明残差已与历史输入独立.
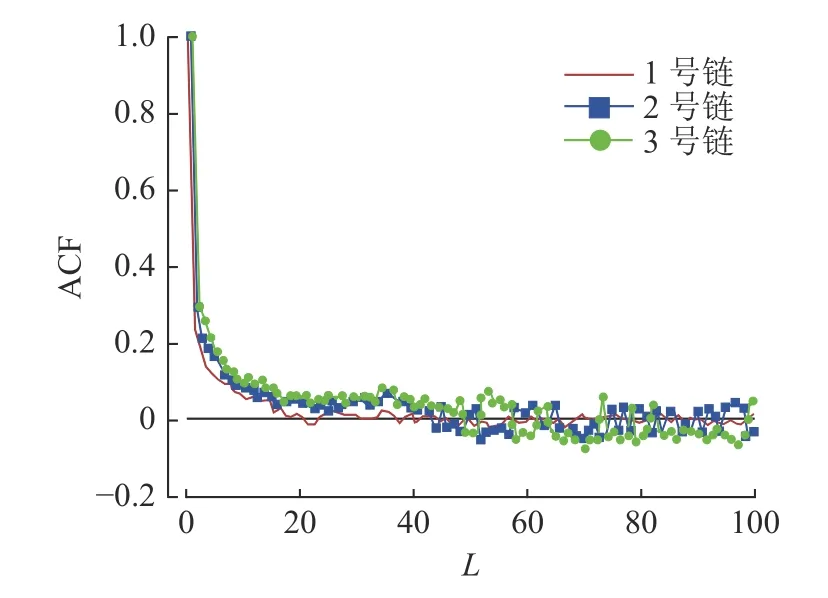
图5 模型参数估计中3 条马尔可夫链残差自相关函数Fig.5 ACF of residuals of model from 3 Markov chains
进一步利用新测试集数据对模型进行泛化能力测试.通过获取模型训练集数据相同数据渠道,随机采集2017—2019 年北京市48 座居住建筑热力站能耗监测数据为测试集样本.图6 为测试集热力站能耗EUIH 的观测值和预测值对比,图中下轴为EUIH 的观测值,左轴为EUIH 的预测值;短虚线和长虚线分别为模型5%和10%的绝对百分比误差.
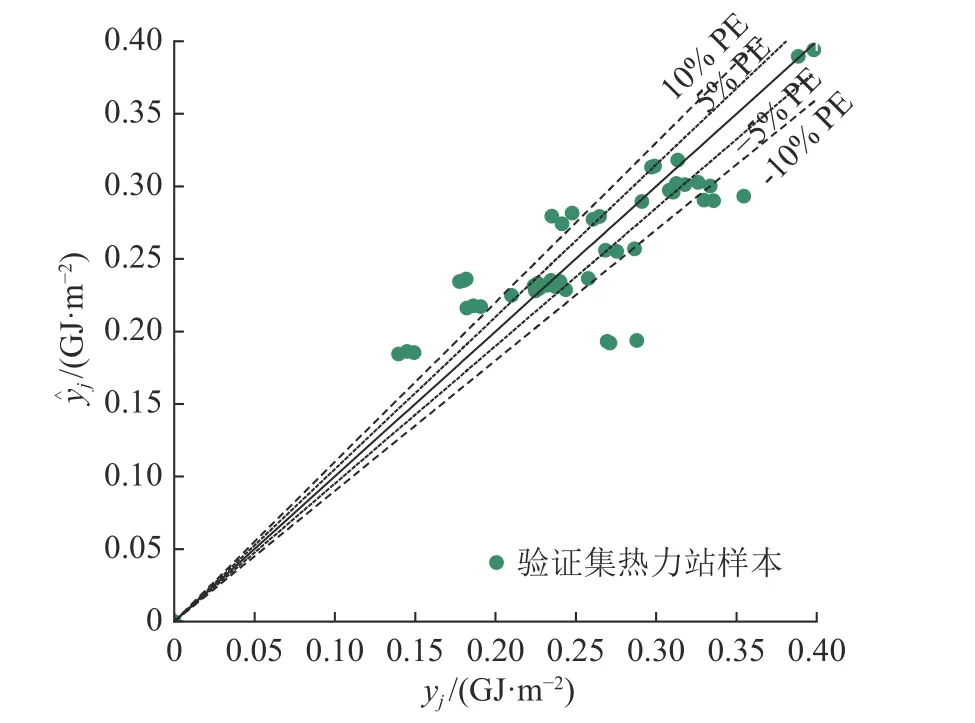
图6 测试集热力站能耗EUIH 的观测值和预测值对比Fig.6 Comparison between metered EUIH with calibrated EUIH for heating substation samples in validation dataset of model
参考关于广泛用于评估能耗校准模型和预测模型的ASHRAE 指南14-2004 标准[46],采用绝对百分比误差(percentage error, PE)、归一化平均偏差(normalized mean bias error, NMBE)、均方根误差(root mean sqnare error, RMSE)和均方根误差变异系数(cofficient of variation root mean squaren error, CVRMSE)等预测精度统计评估指标进行误差分析,即
式中:RMSE 为指标衡量观测值与预测值之间的偏差;CVRMSE 为衡量观测值与预测值之间的无量纲偏差;NMBE 为衡量观测值与预测值之间的归一化偏差,上述3 个指标数值越小说明预测精度更高;yˆj为样本EUIH 预测值, 单位为GJ/m2;yj为样本EUIH 观测值, 单位为GJ/m2;Nt为测试集样本总数;y¯j为测试集样本EUIH 观测值均值, 单位为GJ/m2.
预测精度指标公式结果显示NMBE 为0.4%,RMSE 为0.034,CVRMSE 为13.1%,模型的CVRMSE和NMBE 指标已经明显低于ASHRAE 指南14-2014标准中建议CVRMSE 限值(15%)和NMBE 限值(5%),说明本研究模型进行居住建筑热力站EUIH预测具有较强鲁棒性和泛化能力.
4 模型结果分析
以北京市223 个居住建筑热力站随机采集样本的2017、2018、2019 年共3 年供暖季逐时EUIH数据为基础,结合本研究构建的模型和能耗预测方法,使用重要性采样达到平稳分布后的迭代样本,推断模型中参数和EUIH 的联合后验分布.图7为模型中参数后验分布计算结果,其中左轴为模型参数的后验分布概率密度ρ,下轴 π0~π4为模型结构项解释变量固定效应弹性系数计算结果, π0~π4分别为-6.852、0.495、0.170、-0.512、0.484;b1~b3为个体特质效应项潜变量固定效应弹性系数计算结果,b1~b3分别为0.047、0.039、0.037,分别对应居住建筑热力站样本2017、2018、2019 年潜变量固定效应情况.π0~ π4、b1~b3的计算结果与式(2)联合,进一步推断出样本所在北京市居住建筑EUIH的联合后验分布替代模型.北京市不同居住建筑群采用该联合后验分布替代模型快速预测EUIH值,通过图7 的参数计算结果与式(2)同时获得EUIH 的峰值概率期望值和不同可信区间阈值.
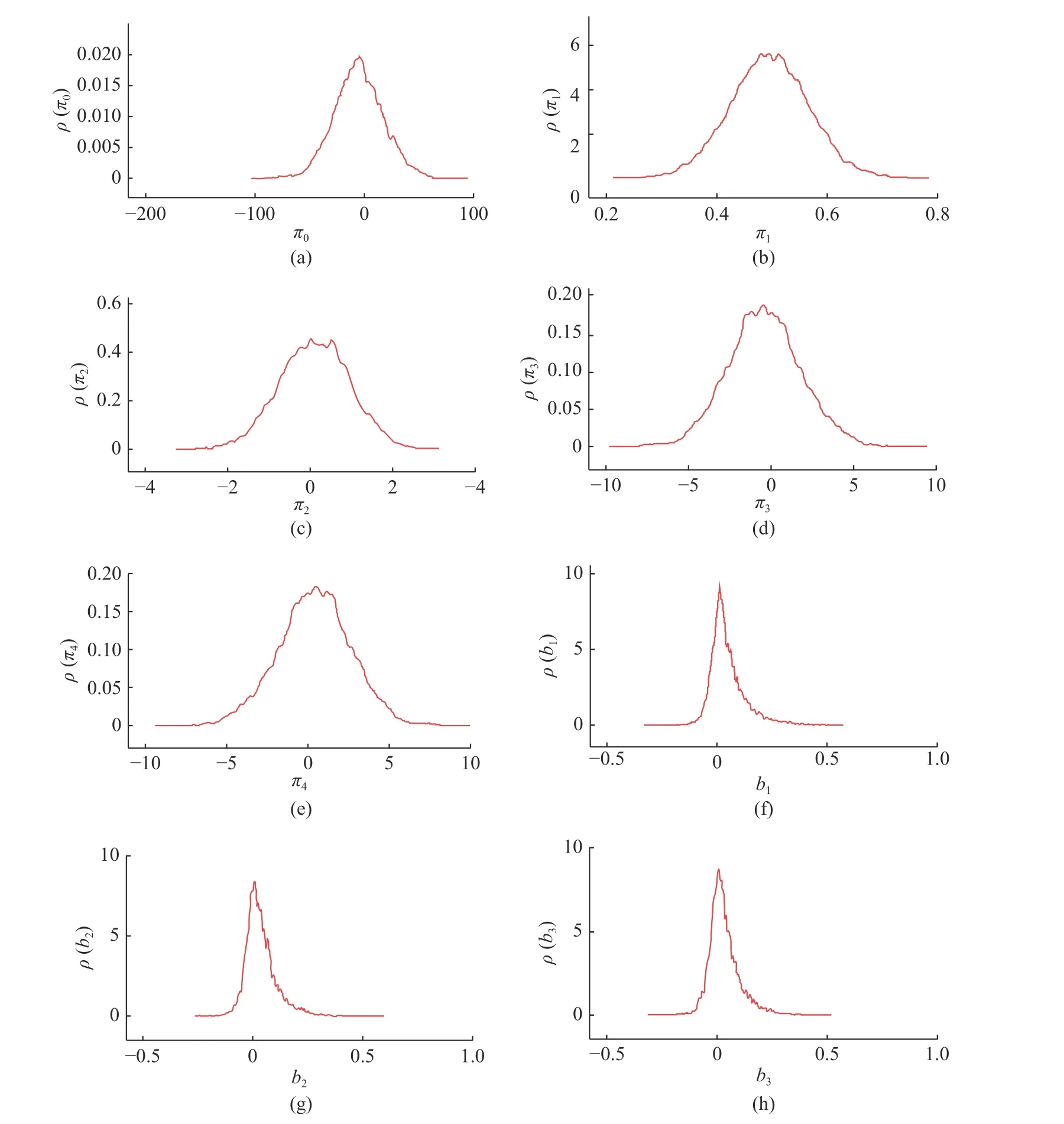
图7 混合效应模型参数后验分布Fig.7 Posterior distributions of parameters in mixed effects model
图8 为北京市居住建筑EUIH 的联合后验分布计算结果,左轴为EUIH 基准值EUIHB(GJ/m2),右轴为蒙特卡洛标准误差E(GJ/m2),下轴为年份.联合后验分布具有峰值概率的EUIH 期望值,可以设定作为北京市居住建筑EUIH 的基准值,2017、2018、2019 年EUIH 基准值分别为0.194、0.192、0.193 GJ/m2.若根据城市管理不同实际需要,将不同可信区间上下限EUIH 数值设定作为能耗准入值或限定值、先进值或引导值[47],如95%可信区间上下限、上下四分位数等.以2018 年为例,95%可信区间上下限、上下四分位数由高至低分别为0.163、0.180、0.201、0.233 GJ/m2,即2018 年EUIH 引导值为0.163 GJ/m2(反映优秀、更低的能耗强度),约束值为0.180 GJ/m2(反映良好、较低的能耗强度),基线值为0.192 GJ/m2(反映一般、平均的能耗强度).
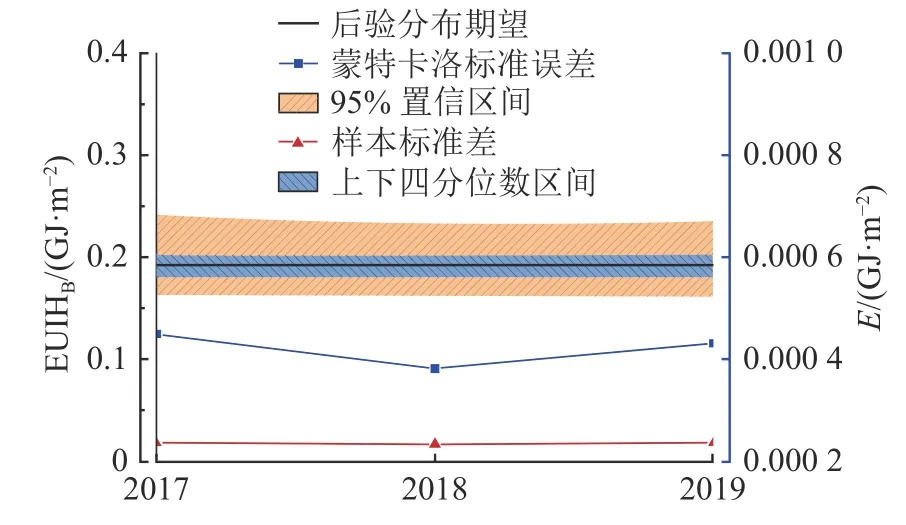
图8 北京市居住建筑EUIH 的联合后验分布Fig.8 Joint posterior distribution for EUIH of residential buildings in Beijing
同一年度、同一城市的居住建筑区域样本的EUIH 值与上述基准值进行对比,差值反映出该建筑区域的能耗水平与所在城市正常能耗水平的差距.该基准值与同一年度、其他国家或城市的居住建筑EUIH 相关基准进行对比,差值反映出北京市居住建筑供热节能潜力.图9 为北京市与其冬季环境温度相近的国际能源署成员国(包括美国、韩国、日本、法国、德国、加拿大、丹麦、芬兰、瑞典、乌克兰、比利时、匈牙利等国家)城市居住建筑EUIH 基准值对比,从2010—2018 年国际能源署成员国城市居住建筑EUIH 基准值呈明显下降趋势,说明供热节能水平和节能效果提升;与北京市2018 年居住建筑EUIH 基准值相比,北京市基准值明显低于绝大多数国际能源署成员国,说明北京市居住建筑供热节能潜力较小.
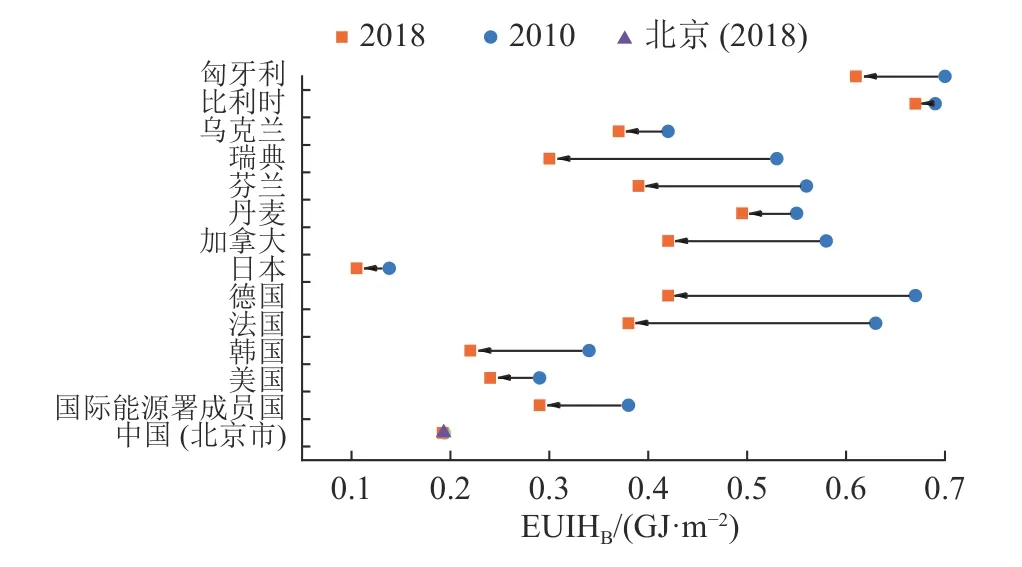
图9 国际能源署成员国与北京的居住建筑EUIH 基准值对比Fig.9 Comparison of benchmark of EUIH for residential building between city of IEA number countries and Beijing
5 结 论
本研究提出一种基于自下而上数据驱动模型的建筑能耗预测和校准方法,并在建筑样本数据有限、输入不确定性强、建模复杂度和计算成本限制下,推断城市尺度建筑能耗高概率分布点、区间及联合后验分布,以确定城市尺度建筑供热能耗强度基准.
1)系统综述对比目前建筑能耗预测模型构建、求解和应用中所需建模信息量、建模难度、样本量、计算资源和时间成本,指出城市尺度数据驱动建筑能耗预测领域现有的研究差距和适合于解决建筑样本有限、输入不确定等问题的模型形式.
2)开发贝叶斯框架的混合效应模型,采用城市气候、形态、建筑功能等特征指标为模型输入,采集2017—2019 年北京市223 座居住建筑热力站能耗监测数据为测试集样本训练模型.通过MCMC方法进行重要性采样,并推断出模型超参数峰值概率分布,预测城市尺度建筑供热能耗强度(EUIH)的精度指标NMBE 为0.400%,RMSE 为0.034,CVRMSE 为13.100%,验证所提模型具有较强鲁棒性和泛化能力.
3)基于贝叶斯框架的混合效应模型和MCMC方法平稳分布后迭代样本,推断城市尺度建筑供热能耗强度(EUIH)的联合后验分布,EUIH 点估计和区间估计结果为确定城市建筑供热能耗基准提供依据.
4)北京市2017、2018、2019 年EUIH 基准值分别为0.194、0.192、0.193 GJ/m2.与其冬季环境温度相近的国际能源署成员国EUIH 基准值对比,北京市基准值明显低于绝大多数国际能源署成员国,说明了北京市居住建筑供热节能潜力较小.
本研究中的贝叶斯框架混合效应模型描述了输入不确定性对模型输出的影响,模型输入、输出、模型中的超参数等均以贝叶斯学派概率方式而不是固定值的方式进行描述,允许在一定值域范围内变化,从而数值上包含了模型输入在观测误差影响、设备使用状态、人员活动行为变化、建筑建造水平和功能差异等不确定因素对模型输出影响.在所提模型中,有以下几个方面存在局限性:共轭先验函数的形式和初值设定、似然分布函数的形式和初值设定、贝叶斯框架优化、模型输入优化、实际数据颗粒度差异优化、重要性采样的方式效度等.在建模过程中,若是将建筑人员活动等不确定因素的数据作为相关解释变量,则需要使用全贝叶斯、经验贝叶斯模型和推理方法来改善模型结构和结果.
猜你喜欢
工程数学学报(2020年3期)2020-07-06
成都信息工程大学学报(2019年3期)2019-09-25
长治学院学报(2019年2期)2019-07-24
自动化学报(2017年5期)2017-05-14
数理化解题研究(2017年4期)2017-05-04
雷达学报(2017年6期)2017-03-26
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
