
基于语义分割的沥青路面裂缝智能识别
2023-10-24 10:09:22杨燕泽王萌刘诚徐慧通张小月
浙江大学学报(工学版) 2023年10期
杨燕泽,王萌,刘诚,徐慧通,张小月
(1.北京交通大学 土木建筑工程学院,北京 100044;2.中路高科交通检测检验认证有限公司,北京 100088)
截至2021 年末,全国公路通车总里程达到528.07 万 km,是1984 年末的5.7 倍,其中高速公路通车量达16.91 万 km,总里程规模位居世界第一.沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90%[1-2].随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务.传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3].根据现行《JTG 5210-2018公路技术状况评定标准》[4]以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5],对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏.裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一.不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6].交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7-9].
深度学习方法是计算机在无人工干预的情况下自主学习对象的特征.卷积神经网络(convolutional neural network,CNN)也被证明是计算机视觉领域中先进的技术,在应用上主要分为3 类[10]:图像分类、目标检测、语义分割.其中语义分割方法能够根据图像的纹理、场景和其他高层语义特征得出图像本身需要表达的信息,因此在裂缝检测中,语义分割能够在像素级别分割出裂缝的本身形态,有利于裂缝参数的量化计算[11].
众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率.翁飘等[7]提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度.李刚等[12]提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度.陈泽斌等[13]基于自建路面裂缝数据集,运用改进后的U-net 模型实现对路面裂缝图像自动识别并验证其识别精度.阙云等[14]为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net 网络模型为基础的路面裂缝语义分割算法.Zhang 等[15]基于提出 CrackNet-R 递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别.Xiang 等[16]提出新的路面裂缝检测方法,是基于端到端(endto-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征.Yang 等[17]提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝.
针对沥青路面裂缝检测的相关领域,仍存在以下问题:1)大多路面裂缝识别的研究并未区分具体路面场景,针对沥青路面研究及应用少,普通路面主要分为水泥混凝土、沥青路面,两者图像背景特征差别大,混合检测会影响自动识别结果的精度;基于语义分割的裂缝检测研究多分布在混凝土结构表面[18-21],针对沥青路面场景下的应用研究较少.2)缺乏公开沥青路面裂缝数据集.训练卷积神经网络需要大量标签样本,分割数据集获取难度高,虽然已有学者开展沥青路面裂缝识别相关研究,但是公开数据集仍然较少,裂缝标签样本数据匮乏.3)缺乏针对沥青路面裂缝智能识别及量化的整体解决方案.对于裂缝自动识别的研究通常是基于文章中的特定数据集、网络结构开展,多数方法及模型尚未开源不便于实用,因此很难对不同研究进行复现,得到统一的性能评估.基于裂缝提取结果,满足实际应用需求的裂缝参数自动量化研究开展较少.
基于以上问题,提出适用于沥青路面裂缝、基于语义分割的智能识别及量化的整体解决方案.通过对开源的语义分割方法进行优化,得到兼顾效率及精度的沥青路面裂缝自动识别模型,便于实际应用需求.为了满足不同训练需求,分别针对较大规模数据集及较小规模数据集提供优选方案及对应模型.基于北京六环高速公路沥青路面,建立沥青路面裂缝分割数据集 R-Crack,对提出的智能识别方案进行应用检验.通过对比分析人工、自动化检测方式获得的裂缝参数量化结果,为沥青路面场景下的裂缝自动化检测实践提供参考依据.
1 基于深度学习的语义分割方法
Csurka 等[22]提出语义分割(image semantic segmentation,ISS),目标是图像中的每个像素进行分类,并将其标记为不同的语义类别.与传统的图像分割相比,ISS 的特点是为图像中的目标加上一定的语义信息[11].在沥青路面检测中,对裂缝目标进行像素级的分割,有利于裂缝参数(长度、宽度)的计算.常用语义分割算法的优势及存在的问题总结如表1 所示.

表1 常用语义分割算法总结[11]Tab.1 Summary of common semantic segmentation algorithms
2 语义分割模型对比研究
对语义分割算法的统一性能评价仅在包含多类目标的公开数据集(例如PASCAL VOC2012[23]、COCO[24]、Cityscapes[25])上开展过.在对裂缝自动识别的众多研究中,模型的评估通常是基于特定的数据集、网络结构等开展,并且多数方法及模型尚未开源,不便于实用,因此很难对不同研究进行复现,从而得到统一的性能评估.基于相同的实验室条件,综合考虑数据集规模、网络结构、损失函数种类的影响,开展针对沥青路面裂缝,基于开源语义分割方法的对比研究,得到一套兼顾效率与精度的沥青路面裂缝自动识别模型的优选方案.
2.1 数据集信息
选用公开沥青裂缝分割数据集 CRACK500 和GAPS384[17,26],裂缝分别来自天普大学主校区沥青路面和德国沥青路面,数据集信息及示例如表2和图1 所示.表2 中N为图片数量,R为分辨率,Bit 为位深度.将原始图像及标签图划分成训练集、验证集和测试集.如表3 所示.由于2 个数据集裂缝图像特点存在差异,为了保证测试的公平性,从2 个数据集中分别挑选约60 张共同作为试验测试集.

图1 训练裂缝数据集的示例Fig.1 Example of training crack datasets
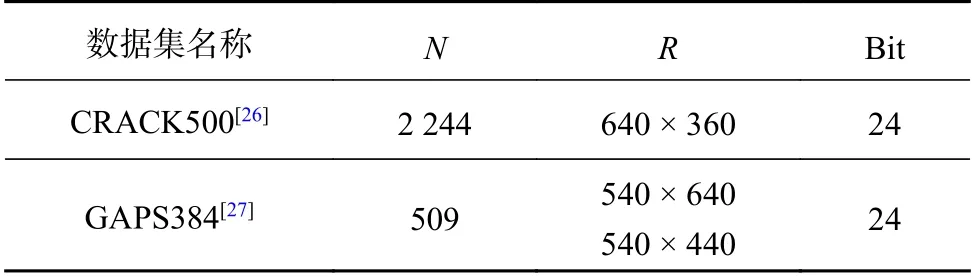
表2 训练裂缝数据集的基本信息Tab.2 Basic information of training crack datasets
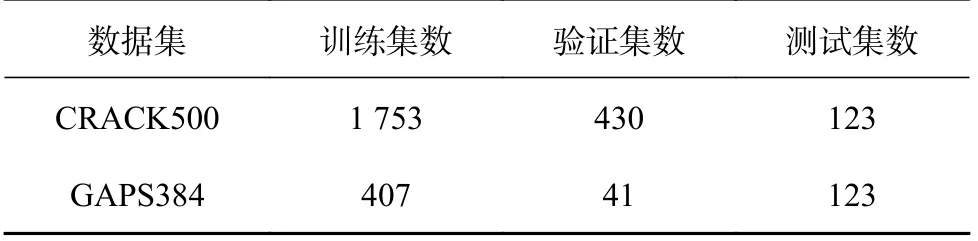
表3 语义分割比选试验的数据集划分情况Tab.3 Dataset partitioning of semantic segmentation comparison experiments
2.2 对比方案设计
选择表1 所示的4 种语义分割算法U-Net、DeeplabV3、PSPNet、DeeplabV3+,同时综合考虑数据集训练规模、算法种类、训练网络种类及深度、训练损失函数的影响,开展沥青路面裂缝自动化检测模型的对比研究如图2 所示.
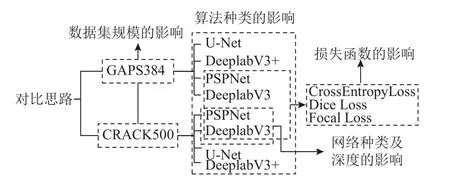
图2 语义分割模型的对比方案Fig.2 Comparative schemes for semantic segmentation models
2.3 试验参数设置
模型训练的硬件设备是基于实验室的Linux操作系统,采用的是PyTorch-1.9.1 深度学习框架、CUDA10.2 和python3.8 的运行环境,在NVIDIA Tesla V100-SXM2-16GB 上完成网络的训练与测试.优化算法选择随机梯度下降法[27](stochastic gradient descent, SGD)来最小化目标函数D,批量大小(batch-size)设置为16,迭代训练共400 次.在训练过程中,学习率根据训练情况动态调整,采用Poly 指数变换策略[28],使得学习率不断衰减.在本试验中,初始学习率为0.001,控制曲线形状的权重值W为0.9.
式中: lrnew为 新的学习率; lrbase为 基准学习率;epoch为迭代次数;Emax为最大迭代次数;W值为控制曲线的形状(通常大于1)、人为设定的超参数.
1)模型训练流程及各关键步骤的逻辑关系如图3 所示.对输入的数据集通过统一的预处理,增广数据及特征信息.2)采用统一数据集格式完成对不同算法的训练,训练迭代完成后.3)得到的语义分割模型,并在测试集上检验训练效果.

图3 语义分割模型训练的流程图Fig.3 Flowchart of semantic segmentation model training
2.4 评估指标
为了衡量不同语义分割模型的作用及贡献建立混淆矩阵,其中TP 为模型预测是裂缝且真实值也是裂缝的像素个数、FP 为模型预测是裂缝但是真实值不是裂缝的像素个数、FN 为模型未预测是裂缝但是真实值是裂缝的像素个数、TN 为模型未预测是裂缝且真实值的确不是裂缝的像素个数.基于TP、FP、FN、TN,采用模型评价指标包括交并比(intersection over union, IOU)、准确率Acc、召回率Re、F1 分数、精确率Pr[5],其定义及计算公式如表4 所示.

表4 试验评估指标的汇总Tab.4 Summary of evaluation indicators for experiment
3 试验结果及分析
在训练结束后,各数据集基本信息如表5 所示.表中加粗部分的模型为较小规模数据集.由于分割数据集构建成本大,缺乏足够的数据量,而且不同研究所采用的数据集规模不一,需要考虑数据集规模对模型训练的影响.将训练数据集大于1 000 张的CRACK500[17]作为较大规模数据集,小于1 000 张的GAPS384[26]作为较小规模数据集,通过分别训练及测试,考虑不同的训练因素(网络结构、损失函数),针对较大规模数据集及较小规模数据集分别提供优选方案及对应模型.
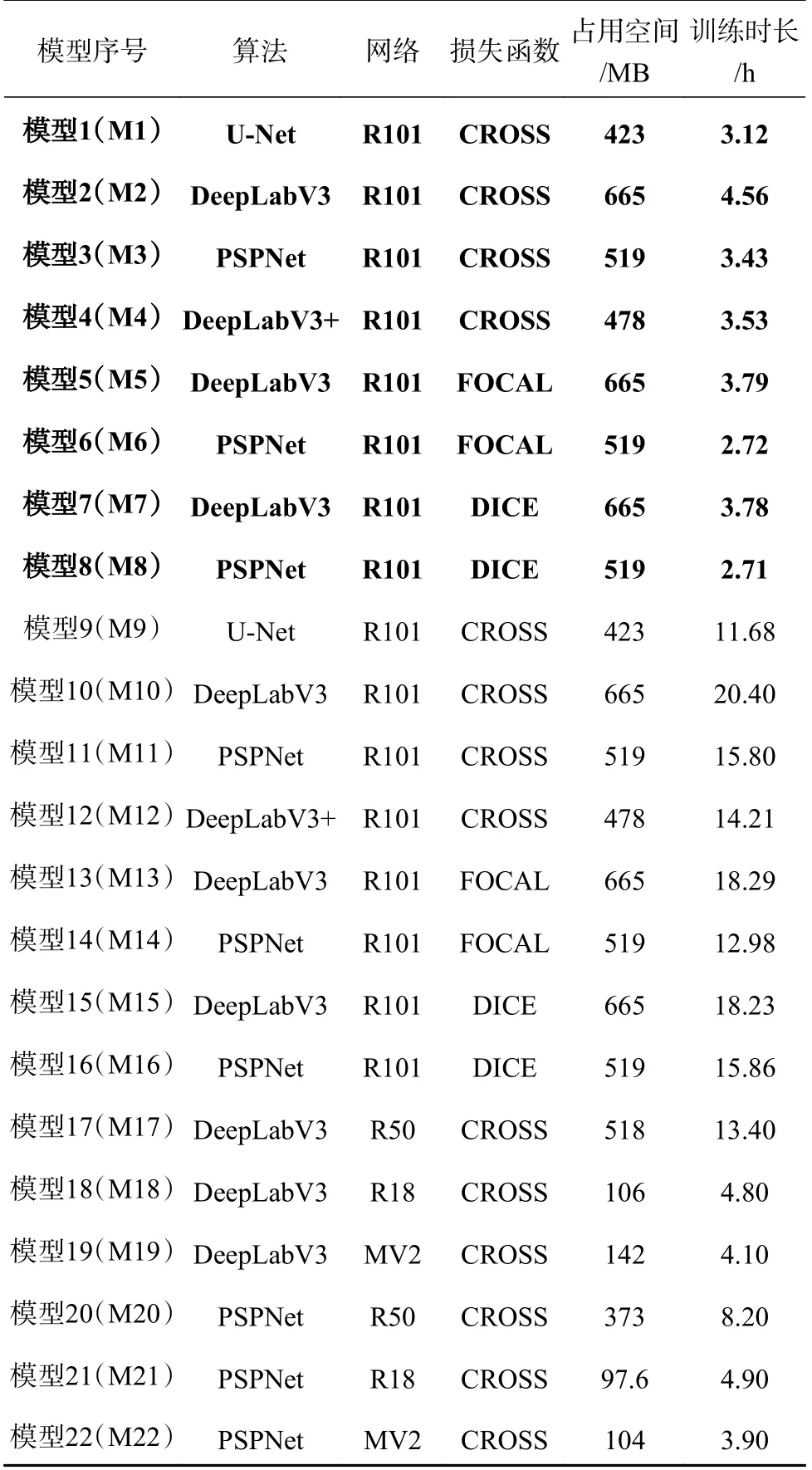
表5 训练模型的基本参数Tab.5 Basic parameters of training model
3.1 训练数据集规模及算法的影响
在不同数据集规模下,不同算法训练得到的模型1~4 和9~12 的损失函数曲线及准确率曲线,如图4 所示.随着迭代次数增加,模型损失函数值均随迭代次数不断下降,没有出现过拟合、欠拟合的情况,表明试验超参数选择合理.模型3、4、11、12 训练过程稳定,特点在于准确率高,损失函数值低,特征学习能力强.PSPNet 和DeepLabV3+算法在模型学习中,调用金字塔模块,兼顾裂缝目标物浅层和深层的特征融合,促进局部信息的上下文的获取.
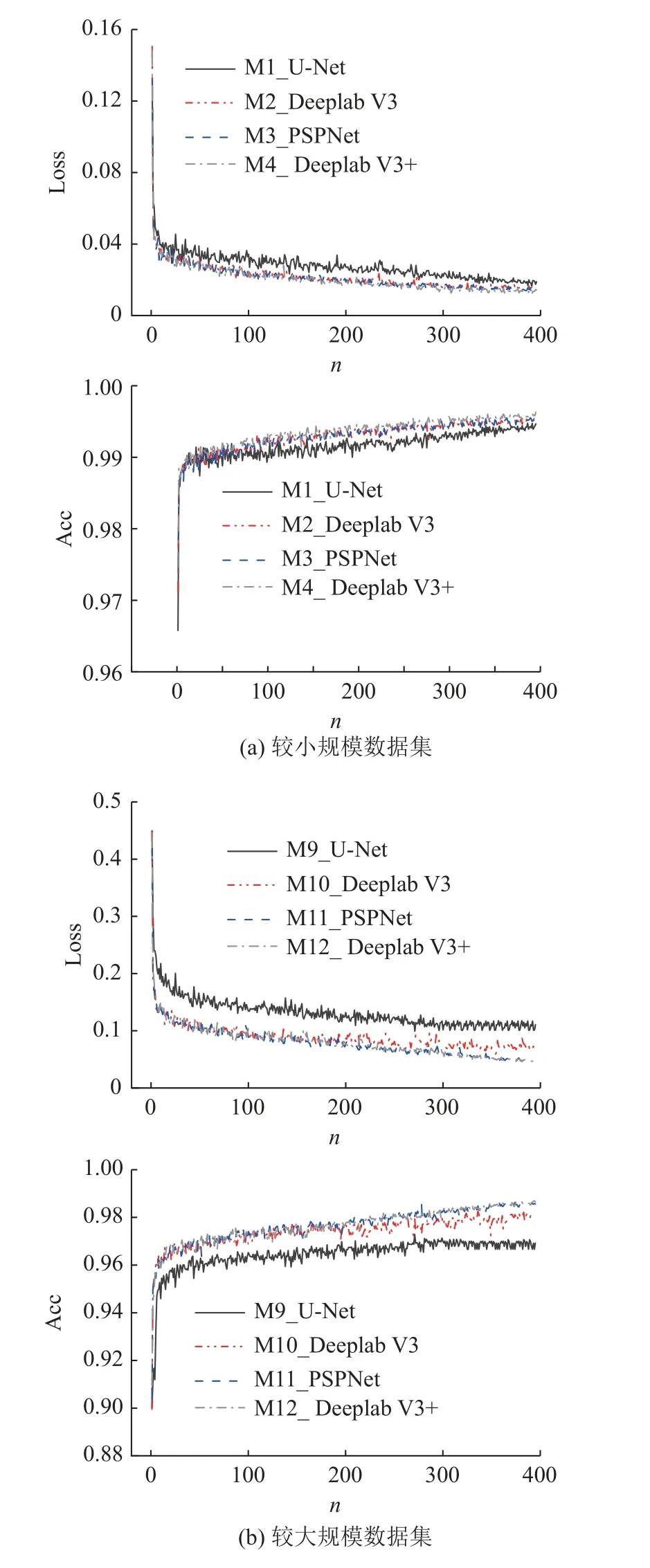
图4 不同算法模型的准确率和损失曲线Fig.4 Accuracy and loss curves of different algorithm models
在训练结束后,模型测试结果对比如表6 所示.模型1~4 的交并比、准确率、F1 分数远大于模型9~12,说明较大规模的数据有助于模型的表征学习,从而提高裂缝的预测精度.模型1、9 测试交并比最低,分别为57.78%和69.59%,表明裂缝的预测结果图与原标签图重合度最低,这是由于U-Net 在获取图像的上下文信息和保证定位准确性上是不兼得的,因此识别效果较差.模型3、4 及11、12 的准确率、F1 分数均较高且相差不大.在图像的所有像素点中,准确率最高为86.76%,表明最高有86.76%的像素被正确预测.在保证精度的前提下,模型3、11 的FPS 值最大,分别为0.85、0.71 帧/s.PSPNet 算法得到的模型在检测精度和效率上有较好的性能.
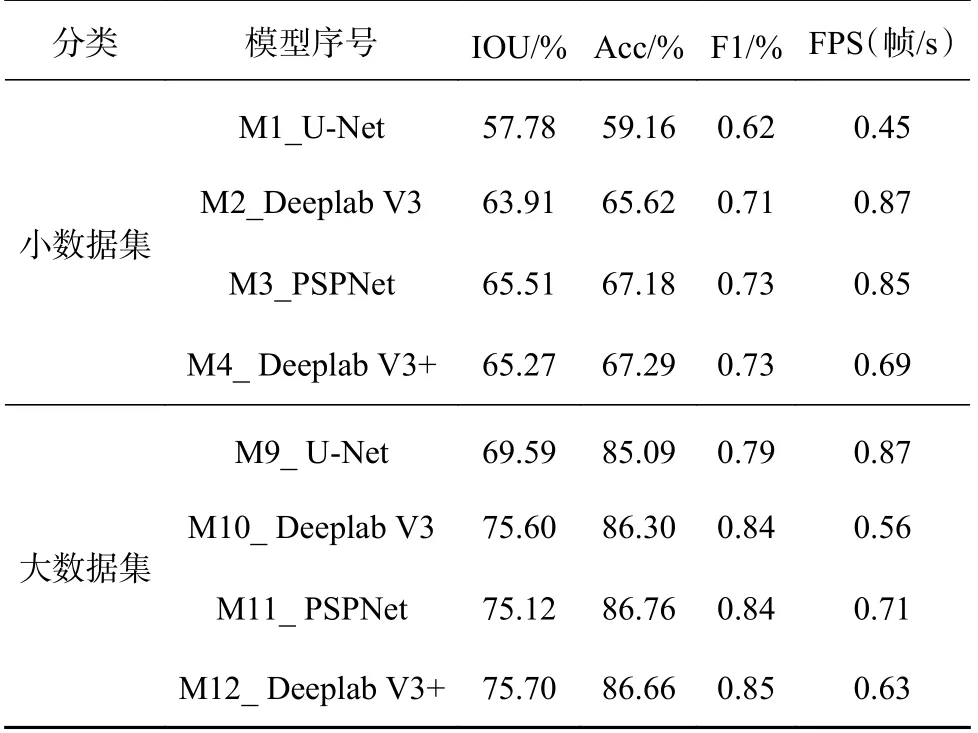
表6 不同算法模型的测试结果Tab.6 Test results of different algorithm models
在裂缝可视化结果中,将模型9、12 分割结果的误识别(FN)、漏识别(FP)面积进行对比,如图5 所示,在测试集上准确率最高的模型12 “FN+FP”总面积比准确率最低的模型9 小得多,表明DeepLabV3+漏识别、误识别像素点更少,分割结果与人工标签图更吻合,分割效果更好.图中中间部分FN 为被误识别为背景的实际裂缝区域,上下部分FP 为被识别在裂缝范围内实际没有裂缝的区域.模型9~12 的裂缝分割结果可视化结果如图6所示,通过对比,模型11、12 分割出的裂缝,边缘轮廓更精确,连续性更好,表明DeepLabV3+和PSPNet 对沥青路面裂缝的分割确实有更好的效果.

图5 模型9、12 模型分割结果误识别(FN)、漏识别(FP)面积对比Fig.5 Area comparison of false identification (FN) and missing identification (FP) of model segmentation results
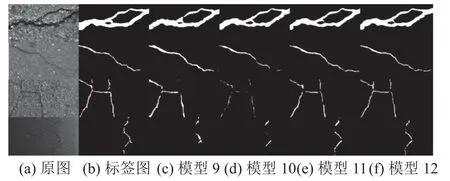
图6 模型9~12 裂缝分割结果可视化Fig.6 Model 9~12 visualization of crack segmentation results
通过批量对比模型9~12 在检测集中其余所有的裂缝分割结果图,得到分割结果中产生FP 区域(模型预测为裂缝但是真实值不是裂缝的像素个数)的2 个主要原因.1)裂缝周围部分区域存在类似于裂缝的划痕、树枝阴影、标线等特征物被模型误识别.2)模型对于裂缝目标边缘的分割不够精确,导致识别到的裂缝稍宽于实际裂缝,产生误识别的裂缝像素.
3.2 不同损失函数的影响
选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal 损失函数(focal loss)[29-30]分别作为模型训练的损失函数,对比训练及测试结果.选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal 损失函数(focal loss)[29-30]分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2 个概率分布间的损失函数;骰子损失函数由Dice 系数衍生而来,是一种区域相关的损失函数;Focal 损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数.
训练结束后,损失函数、准确率曲线如图7 所示,测试结果如表7 所示.在小数据集上,模型2、3 的训练准确率更高,表明运用交叉熵损失函数模型训练效果更好,检测精度更高.在大数据集上,模型10、11、13、14 训练效果相近,运用交叉熵损失函数和Focal 损失函数都获得了较好的训练及检测效果.但模型7、8、15、16 训练曲线整体波动幅度大,且准确率较低,表明不论在大数据集上还是小数据集上,使用骰子损失函数训练的模型学习效果较差,训练过程不稳定且学习不充分.从原理上看,由于交叉熵函数是对所有样本的损失函数值求平均,而骰子损失函数在裂缝检测的应用中(“背景”和“裂缝” 2 类像素),小目标“裂缝”作为正样本,一旦有部分像素预测错误,便会导致骰子损失函数值发生大幅度的变动以及梯度的剧烈变化.由于模型没有得到充分的学习,交并比与其他模型相比低3%~6%,识别结果与标签图重合度低.
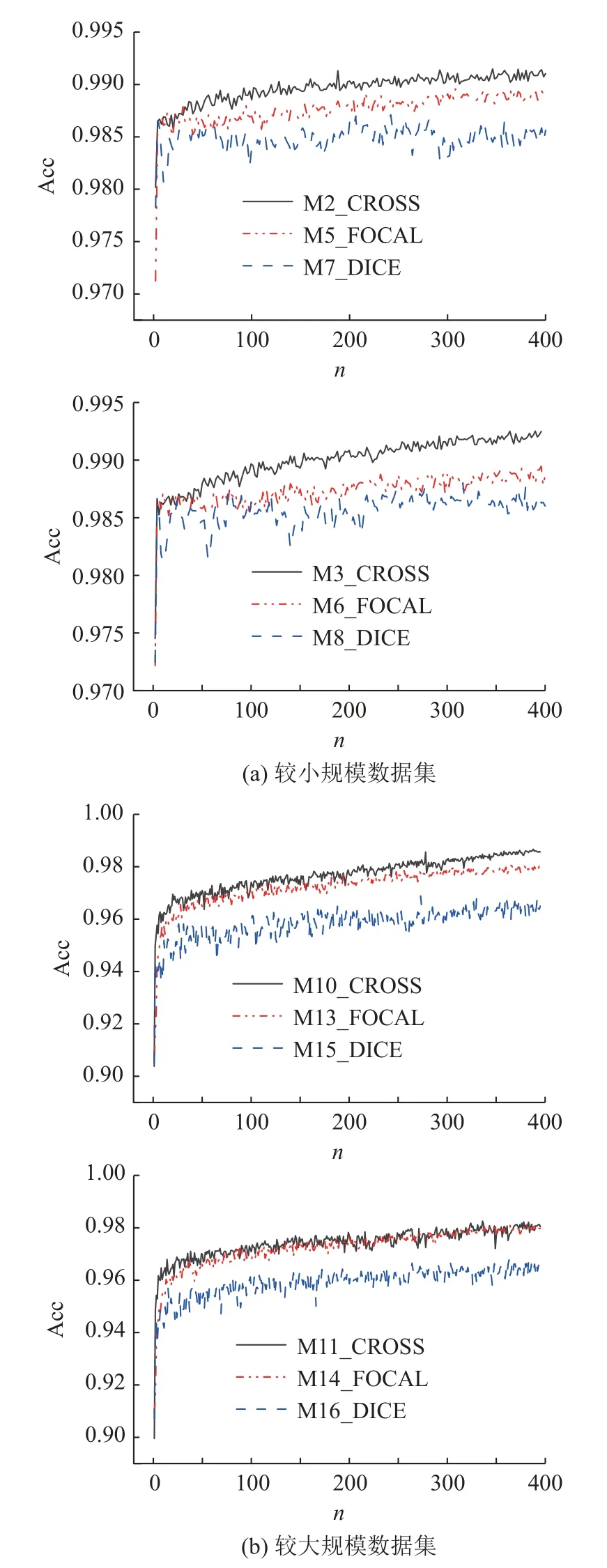
图7 不同损失函数模型的准确率曲线Fig.7 Accuracy curves of different loss function models
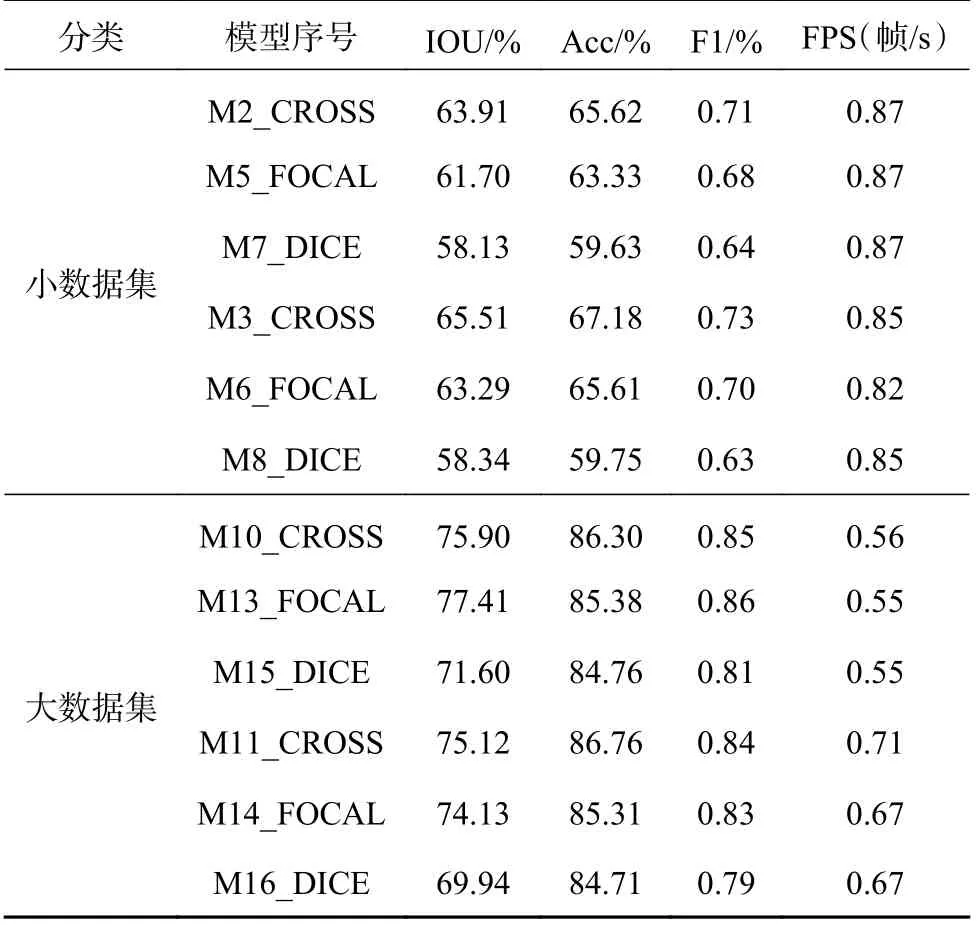
表7 不同损失函数模型测试结果Tab.7 Test results of different loss function models
3.3 不同网络深度及种类的影响
裂缝检测任务首要满足的应是模型识别精度,选择3.2 节中精度更高的交叉熵损失函数作为对不同网络深度及种类影响研究中的不变量,由于较小规模数据集训练所得的模型识别精度低,因此不再进一步开展不同网络深度及种类的影响研究.ResNet[31]是深度学习领域十分常用的特征提取网络,由何凯明团队于2015 年提出.它主要通过构建残差块解决了堆叠式的传统深层网络带来的模型识别准确度“退化”问题.在裂缝自动化检测的实际应用中,大多数会使用移动或者嵌入式设备,因此对轻量级网络的研究十分必要.Google 团队在2018 年提出深度可分离卷积网络MobileNet V2[32],引入线性瓶颈 (linear bottleneck)和逆残差 (inverted residual)来提高网络的表征能力,在计算量与内存占用上远小于标准卷积.
选用ResNet101、ResNet50、ResNet18 以及更轻量化的MobileNetV2[32-33]4 种网络结构开展对比研究,训练损失函数、准确率曲线如图8 所示,模型测试结果如表8 所示.在相同的试验条件下,运用不同种类和深度的网络进行模型训练,获得不同的训练效果.随迭代次数增加,模型18、21 分别与模型10、17 和模型11、20 相比,训练准确率低,损失函数值高,更深的特征提取网络(ResNet50、ResNet101)能够让模型获取更好的训练效果.原因是网络深度的增加能够增加网络的非线性映射次数,使得网络能够提取具有更好判决信息的特征,从而提升模型性能.简单地增加网络的深度并不会自动提高模型的精度,例如模型10、17 和模型11、20,分别采用50 层的ResNet 网络和101 层ResNet 网络,但准确率与损失函数值接近,训练效果相差不大.因此在数据集数量小且条件有限的情况下,运用浅层网络例如ResNet-50、ResNet18,也能达到较好的训练效果.模型19、22 与其他模型相比,训练速度最快,内存占用少.此外,在对测试集图像的推理中,分别达到了3.50 和4.56 帧/s 速度,远快于其他模型.表明采用轻量级的深度可分离卷积网络MobileNetV2 训练得到的模型,在损失一定精度的同时,训练时间、检测速度以及内存占用等方面均占有较大优势,能够满足实时检测的场景需求.

图8 不同网络结构的准确率和损失曲线Fig.8 Accuracy and loss curves of different network structures
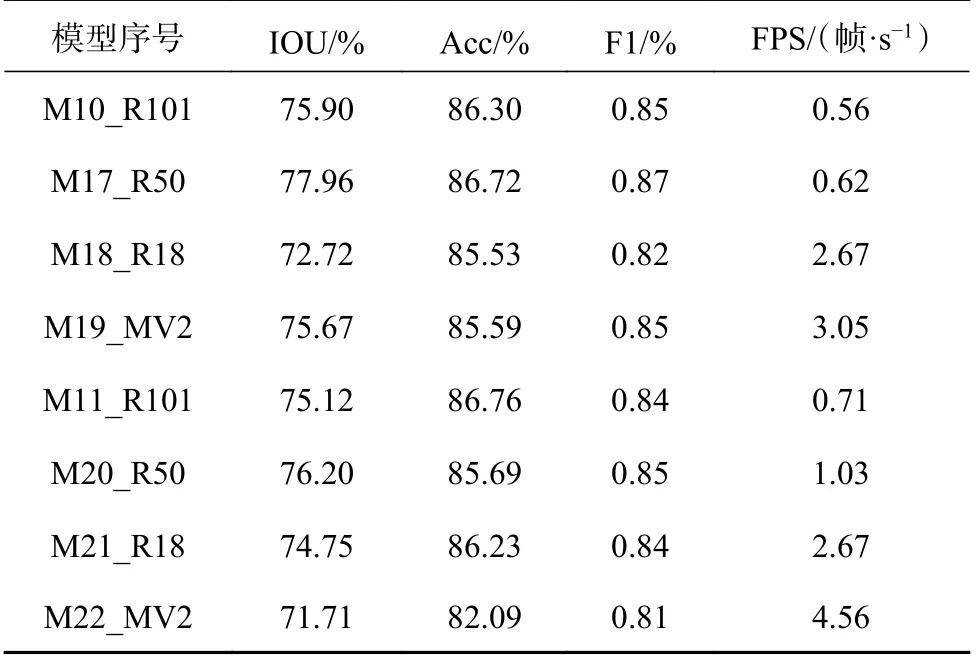
表8 不同网络结构模型的测试结果Tab.8 Test results of different network structure models
3.4 语义分割模型优选方案
基于对比结果,提出分别适用于较大规模数据集及较小规模数据集的优选智能识别方案及对应模型如图9 所示,供高速公路等场景下沥青路面裂缝的自动化检测实践提供参考.在没有计算资源等条件的限制下,检测精度最高的两个优选方案模型分别是DeepLabV3+_R101_CROSS 和PSPNet_R101_CROSS.
4 基于语义分割模型的应用检验
基于北京六环高速公路检测车数据,构建裂缝分割数据集R-Crack.对提出的智能识别解决方案在实际的沥青路面裂缝上开展应用检验.并基于检验结果及实际检测需求,完成裂缝参数的量化与对比分析.
4.1 沥青路面裂缝智能识别应用整体方案
沥青路面语义分割的裂缝自动化识别及量化整体解决方案如图10 所示.利用裂缝数据集进行语义分割模型训练,将所得模型应用于已有路面数据的检测中,分析测试结果及裂缝参数的量化结果、精度及效率是否满足实际工程需求.若是满足,所得模型可以用于生产检测;若是不满足,则需要通过改进算法、数据集质量及规模等方式循环优化模型,直到满足为止.
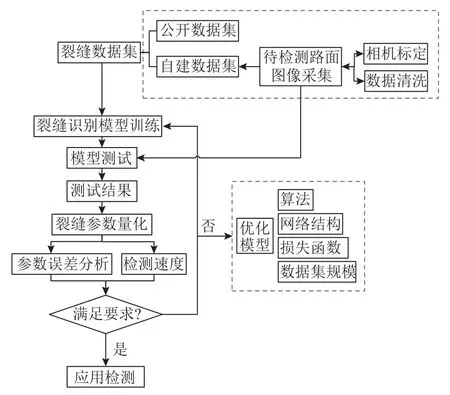
图10 沥青路面裂缝自动化识别及量化整体解决方案的流程图Fig.10 Flowchart of integrated solution for automatic identification and quantification of asphalt pavement cracks
4.2 沥青路面裂缝数据集构建
在语义分割模型的训练过程中,模型的训练质量与预测结果的准确率与所选数据集质量息息相关[23].公开的路面裂缝分割数据集如CRACK-500、GAPS 等[17,26],图像数量少,需要采用旋转、镜像等图像处理操作来增广数据集.由于不同地区拍摄条件、路面环境不同,同样是沥青路面,但裂缝特征存在明显差异.因此本文针对现有公开数据集不足的问题,结合北京六环高速公路的实际数据,制作沥青路面裂缝分割数据集R-Crack,数据集构建流程如图11 所示,收集共有路面采集车原始图像有4 479 张,通过540 p×640 p(长宽分配根据实际裂缝形态确定)的滑动窗口滑动筛选并裁剪出形态不一、且包含不同特征物的裂缝,得到共 468 张清晰的裂缝图像.通过图像标注软件Labelme 制作人工标签,人工判断并选取较为准确的裂缝区域,对于裂缝的边缘像素,本着“疑有从无”的原则进行添补,得到更为精确的裂缝标签,保证检测精度.将裂缝像素标记为255,背景像素标记为0,得到自制沥青路面裂缝数据集R-Crack,数据集标注结果如图12 所示.
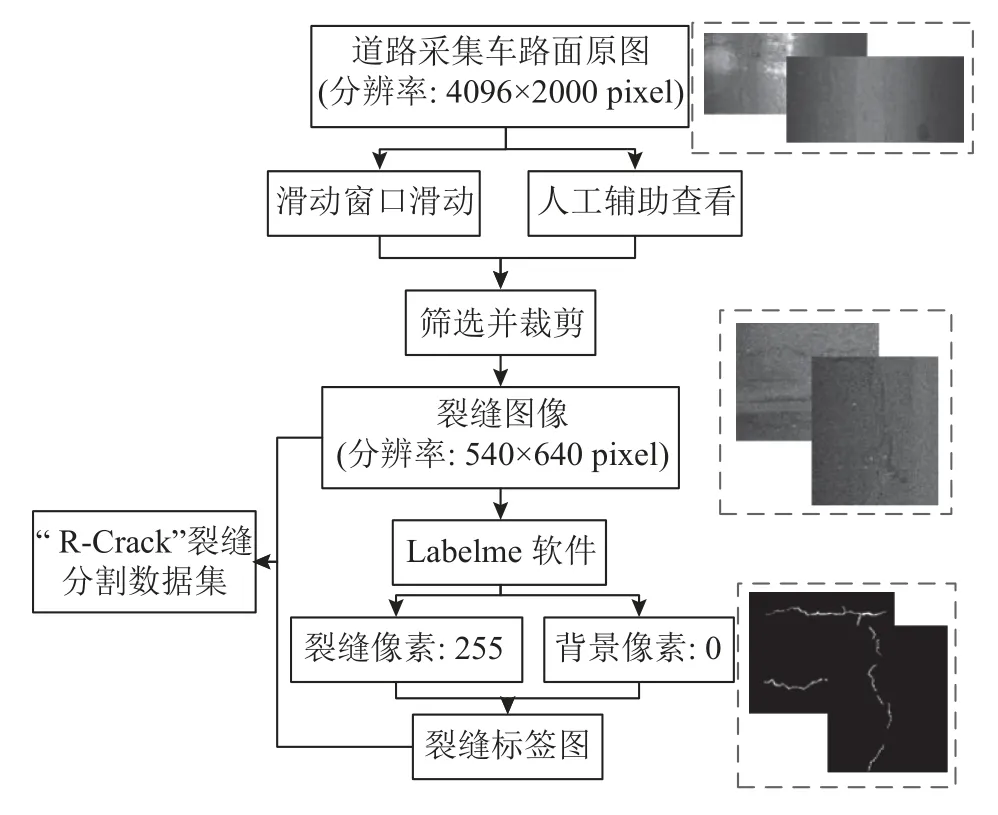
图11 沥青路面裂缝分割数据集R-Crack 构建的流程图Fig.11 Flowchart of asphalt pavement crack segmentation dataset R-Crack construction

图12 “R-Crack”数据集标注示例Fig.12 Example of "R-Crack" dataset annotation
4.3 裂缝参数计算
基于实际应用需求,对识别结果进行参数量化的计算与分析,包括提取裂缝中轴骨架、裂缝长度、宽度的计算.
4.3.1 裂缝骨架提取 采用Zhang-Suen 迭代算法[34]得到裂缝中轴骨架如图13 (a)所示,将连通区域细化成像素的宽度如图13 (b)所示,有利于进行裂缝参数的具体量化.
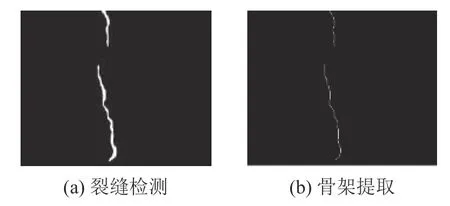
图13 裂缝骨架提取的示意图Fig.13 Sketch map of crack skeleton extraction
4.3.2 裂缝长度计算 裂缝长度的计算参考文献[35]中的像素统计法,对于局部曲率大、反复折叠的裂缝,利用骨架线的像素总和计算裂缝长度,要比利用骨架线上某几个点之间的距离之和计算更为准确.
4.3.3 裂缝宽度计算 裂缝宽度的计算采用“最大内切圆”的计算方法.当输入裂缝分割二值图像后寻找裂缝边缘,输出图像中按照真实的情况建立等级关系的所有轮廓.对轮廓内的区域像素化,进而得到裂缝轮廓内每一个像素点与边缘的距离,采用二分法搜索这些距离中符合条件的点作为内切圆圆心,遍历所有像素点中的最大值,其内切圆的直径就是该条裂缝的最大宽度,通过遍历图片中的所有裂缝得到最大裂缝宽度,运用这种方法可以完成对简单裂缝和复杂裂缝的宽度计算.其中应用二分法搜索内接圆半径的方法如图14,基本步骤是对每一个像素点.1) 确定小半径SR(OA),其所形成的的圆在轮廓内(含切);2) 确定大半径BR(OB),其所形成的的圆在轮廓外;3) 不断迭代BR 和SR,使得|BR-SR|≤a(a 为设定的精度值);4) 停止迭代,得到轮廓内最大内切圆半径.
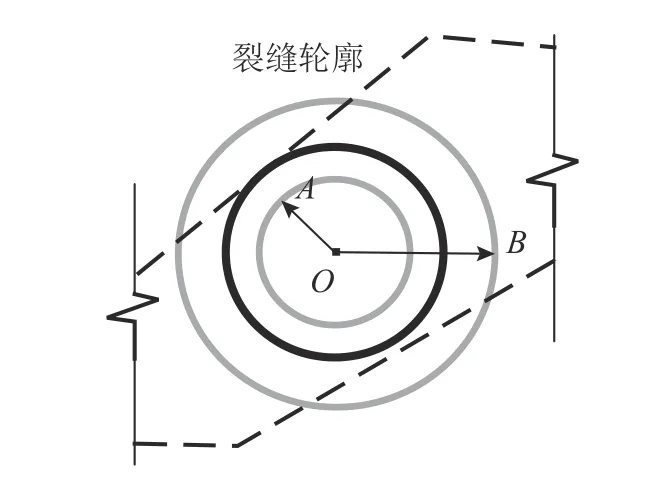
图14 最大内切圆裂缝宽度计算原理的示意图Fig.14 Schematic diagram of calculation principle of maximum inscribed circle crack width
4.4 语义分割模型应用检验
基于图9 中所得沥青路面裂缝自动化检测优选模型方案,在R-Crack 上进行测试,结果如表9所示.运用所提的优选模型对沥青路面裂缝的识别可以达到83.45%的准确率,能够相对准确地对实际路面裂缝进行像素级别的检测,其中不同环境及形态的裂缝检测结果结果如图15 所示.

图15 北京六环沥青路面裂缝检测结果Fig.15 Crack detection results of sixth ring road in Beijing

表9 优选模型的应用检验结果Tab.9 Application test results of optimized model
基于前述裂缝参数计算方法,自R-Crack 的应用检测结果中随机选取裂缝检测结果作整体误差分析如图16 所示,m为图像序号,Δ为与人工相比的绝对误差像素值.结果表明,自动化检测得到的裂缝参数与人工标签图相比,裂缝长度平均相对误差为2.84%,宽度为2.39%,满足实际检测应用需求,表明提出的语义分割优选模型在实际沥青路面检测的应用实践及量化上具有可行性.

图16 裂缝参数自动化提取绝对误差Fig.16 Extraction results of crack skeleton
5 结 语
综合考虑数据集规模、算法种类、网络种类及深度、损失函数类型的影响,针对较大规模、较小规模数据集分别提供模型训练的优选方案,得到兼顾效率与精确度的语义分割模型,提出适用于沥青路面裂缝、基于语义分割的智能识别及参数量化的整体解决方案.基于北京六环高速公路沥青路面,构建裂缝分割数据集“R-Crack”,对提出的智能识别方案进行应用检验,并自动量化裂缝参数(裂缝长度、宽度).通过对比分析人工及自动化检测方式获得的裂缝参数计算结果,说明利用本研究优选方案可以相对准确地完成实际沥青路面裂缝检测,验证了提出的自动化方法在实际沥青路面裂缝检测工作中应用的可行性.
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
开放教育研究(2020年2期)2020-03-31 01:54:14
工程与建设(2019年2期)2019-09-02 01:34:18
今日农业(2019年15期)2019-01-03 12:11:33
现代语文(2016年21期)2016-05-25 13:13:44
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
大连民族大学学报(2015年2期)2015-02-27 08:28:11
河南科技(2014年11期)2014-02-27 14:09:53
城市道桥与防洪(2014年4期)2014-02-27 07:25:49
