
基于深度可分离卷积和Transformer的关键点检测方法
2023-10-21 06:10常方园于文年
电子设计工程 2023年20期
常方园,于文年
(1.武汉邮电科学研究院,湖北武汉 430074;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
人体姿态识别技术广泛应用于智慧课堂、医疗健康、人机交互等众多自动化领域,姿态识别技术可以用于实现高质量的人机交互体验,还可以用于实现行为预判功能,通过对当前的行为进行分析,推测目标在下一时间轴的若干行为。
传统的姿态识别方法是基于图模型的方法,通过将身体部位表示为树状结构的图形模型来建模它们的空间相关性,从而预测身体关节的位置。DeepPose[1]模型利用卷积神经网络(Convolutional Neural Network,CNN)来提取目标关节点坐标信息,将2D 人体姿态识别任务中经典的图像处理和模板匹配问题转化为使用卷积神经网络进行图像特征提取和关键点坐标回归的问题。随后,出现了基于热图[2]、卷积姿态机(Convolutional Pose Machines,CPM)[3]以及AlpahPose[4]等一系列深度学习方法来处理人体姿态识别问题。
1 网络构建
1.1 MobileNet结构
传统的神经网络,如VGG[5]、ResNet[6]等的参数主要集中于卷积层,在卷积阶段浪费了大量的资源,不利于在移动端集成。MobileNet[7]网络将传统的卷积用深度可分离卷积代替,大幅降低网络卷积层的参数量和计算量,减少网络复杂度,进而提高运行速度。MobileNet-v1 的网络结构如表1 所示,其中,Conv 表示标准卷积,Conv dw 表示深度可分离卷积,s1 表示步长为1。
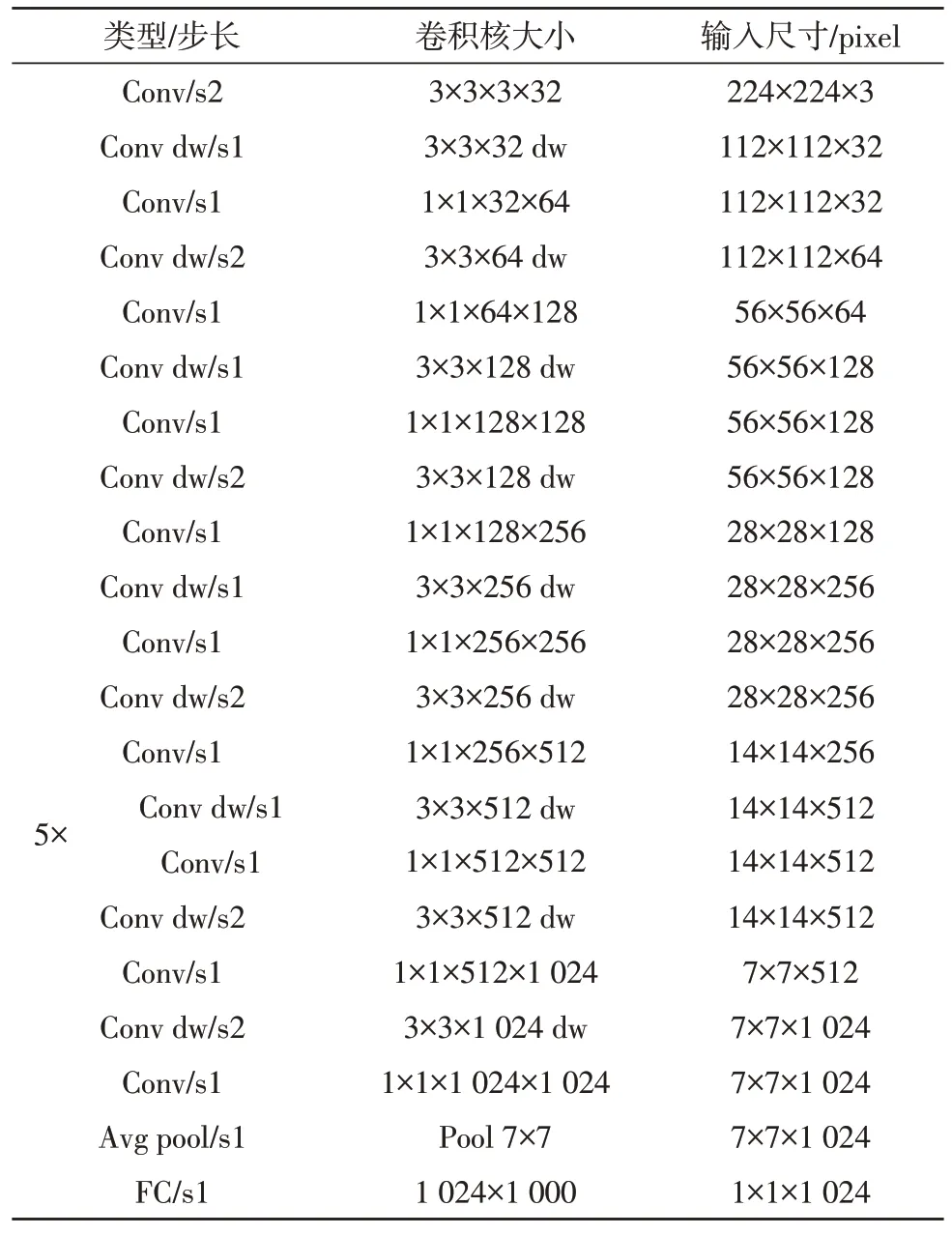
表1 MobileNet网络结构
假设输入特征图F 的大小为DF×DF×M,卷积过程中步长和填充为1,其中,DF为特征图的宽度,M为特征图的深度,采用标准卷积经过N个大小为DB×DB×M的卷积核B 后,生成大小为DF×DF×N的特征图G,此过程所需的计算量可以用式(1)表示。
深度可分离卷积将标准卷积分为两步,首先,进行深度卷积,获得和原图像深度相同的特征图,然后,经过1×1 的逐点卷积生成特征图。其中,逐点卷积过程中不改变特征图的特性,只增加了通道数。同样大小的特征图F 经过深度可分离卷积(第一个卷积核为DB×DB×1 输出特征图大小为DF×DF×M,第二个卷积核为1×1×M)得到的特征图G 为DF×DF×N所需的计算量可以用式(2)表示。
假设DB=3,由式(3)可以看出,相对于传统的标准卷积,深度可分离卷积的计算量大幅下降,MobileNetv1 计算量仅为标准卷积计算量的1/9~1/8。
1.2 Transformer
Transformer[8]最初用于机器翻译,基于Transformer的模型,如BERT[9],通常在大量数据上进行预训练,然后对较小的数据集进行微调。近年来,Transformer结构和自注意力机制[10]逐渐在计算机视觉领域崭露头角,开始应用于图像分类[11]、目标检测[12]、语义分割[13]等领域。
Transformer 是一个完全依赖于自注意力机制来计算其输入和输出表示而不使用序列对齐的循环神经网络或卷积神经网络的转换模型。如图1 所示,Transformer 主要由编码和解码两个部分组成。
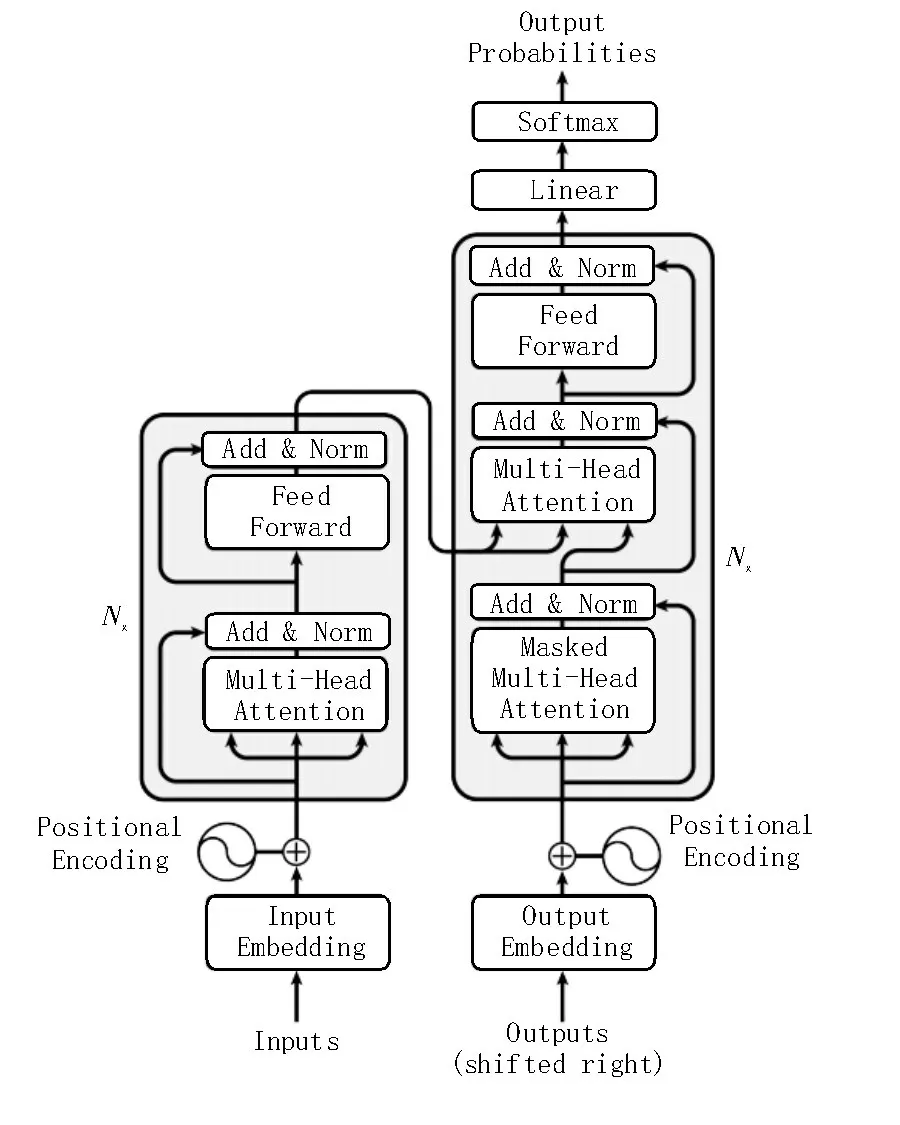
图1 Transformer结构
Transformer 的核心为多头自注意力机制,多头注意力机制由自注意力组成。自注意力机制的出现减少了处理高维输入数据的计算负担,同时还能够使系统更专注于找到输入数据和输出数据间的有用信息,进一步提高输出的质量。多头自注意力机制就是每个自注意力计算出一个结果矩阵,然后将N个结果矩阵拼接起来,乘以权重矩阵得到最终矩阵。
1.3 文中方法
对于关键点位置的预测仅为编码任务,它将原始图像信息压缩成一个紧凑的关键点位置表示,所以该文仅采用编码结构来进行关键点定位。模型主要包含三部分:基于卷积的主干网络提取低维图像特征、Transformer 编码器来捕捉特征向量之间的空间交互、预测关键点热图结构。
对于主网络保留MobileNet-v1 的部分网络层,并加入了残差结构来提取低维图像特征。给定一个输入图像的大小为I∈R3×HI×WI,假定主网络的输出的空间结构图像特征为Xf∈Rd×H×W。然后将图像扁平化为一个序列X∈RL×d,其中,L=H×W,将这个d维的序列送入Transformer 结构中。数据输入后加入位置信息进行嵌入,Transformer 使用了固定的位置编码来表示绝对位置信息,位置信息的计算如式(4)-(5)所示,其中,dmodel的值设置为256。
自注意力机制将经过位置编码后的序列X∈RL×d通过矩阵WQ,WK,WV∈Rd×d转换为Q∈RL×d,K∈RL×d,V∈RL×d矩阵,自注意力的计算过程如式(6)所示。
自注意捕捉并揭示了这些预测对每个图像位置的总贡献,这种来自不同图像位置的贡献可以通过梯度来反映。通过计算导数hi∈RK(K为关键点类型数)关于最后一个注意层输入序列位置j的xj,具体分析了图像位置j处的xj如何影响预测位置i的激活hi的关键点热图。最后一个注意层作为一个聚合器,它根据注意点获取所有图像的值,并在预测的关键点热图中形成最大的激活。
该文采用8 个自注意力机制组成多头自注意力机制。将N个自注意力机制计算出来的结果矩阵拼接起来,乘以权重矩阵W即可得到最终结果矩阵,具体计算过程如式(7)-(8)所示。
若模型训练过程中图像的大小不匹配,则采用4×4 的转置卷积进行上采样以获得尺寸相同的特征图,最后,用一个1×1 卷积来预测K种关键点热图。对于传统的基于CNN 的方法,它们也使用热图激活作为关键位置,但由于CNN 的深度和高度非线性,人们无法直接找到预测的可解释模式。基于Activation Maximization(AM)[14]的方法可能会提供一些方法,但需要额外的优化成本来学习。
AM 能够最大限度地激活一个特定神经元的输入区域,激活的最大位置为关键点的位置。如式(9)所示,神经元在热图的i*位置的激活hi*被最大激活,i*代表一个关键点的真实位置。
假设模型用参数θ*进行了优化,并预测了一个特定关键点的位置为i(在热图中的最大位置)。这些位置J,其元素j与i具有较高的注意力得分(≥δ),是对预测有显著贡献的依赖关系。J可由式(10)表示,其中A∈RL×L是最后一层注意力层的注意力图,同时也是θ*和I的函数。该文通过Transformer将AM 扩展到基于热图的定位,并且优化在训练中隐式完成不需要额外的开销。
2 实验结果与分析
2.1 数据集及实验环境
该文采用开源的COCO 数据集进行模型的构建,COCO 数据集有91 类,包含18 GB 的训练集数据,验证图像有1 GB 和6 GB 的测试图像。训练集用于模型拟合,验证集用于训练过程中,在训练几次完整数据集后进行评估,测试集则用于评价模型的性能。
训练数据集中人目标位置标签和目标关键点标签是数据的原始特征,如图2 所示。这些特征并不适合直接应用到姿态识别中,因此需要从数据的原始特征中提取出姿态识别有效特征。该实验需要一块RTX2080TiGPUs,torch 版 本为1.6.0,torchvision 为0.7.0,CUDA 为10.1,python 为3.6.5。
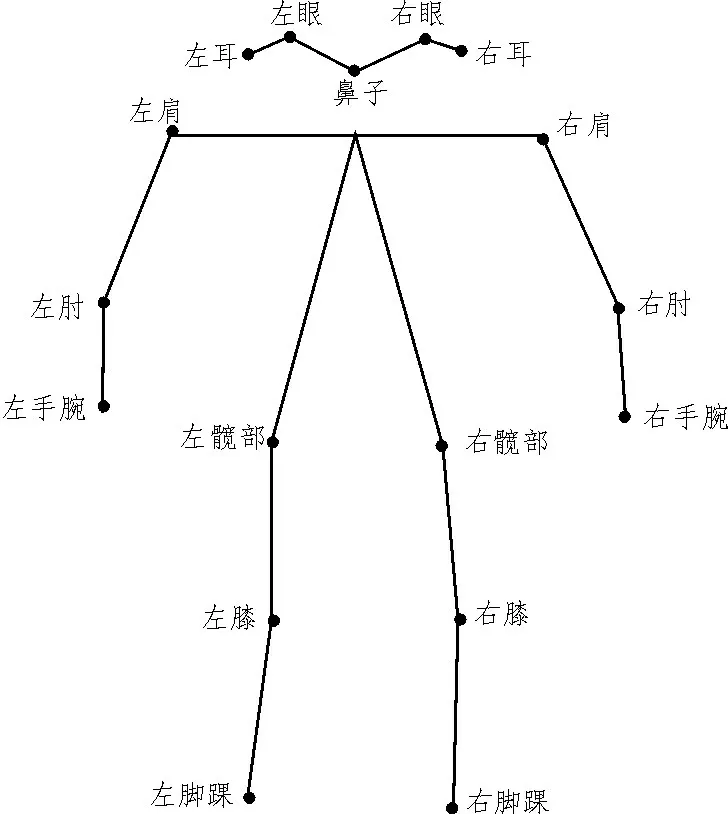
图2 姿态数据原始特征
2.2 实验设计
该文将输入图像进行数据处理将大小固定为256×192,生成的特征图的大小设置为64×48,编码结构的层数为4,Relu 作为激活函数。
在COCO 数据集上进行训练,迭代次数设置为230 次,选用Adam(设置初始学习率为0.000 1,指数衰减率β1和β2分别设置为0.99 和0.0)作为优化器。
2.3 结果分析
将基于MobileNet 和Transformer 生成的人体关键点进行关键点连接,得出姿态估计如图3 所示。该文先用HRNet-w32[15]和ResNet-50[16]进行实验,由表2 可以看出,ResNet 网络模型比HRNet 的参数量少,但HRNet 比ResNet 的性能好。将提取特征的MoileNet 网络与HRnet 和ResNet-50 网络进行比较,其中关键点检测与定位均采用Transformer 中的编码结构,表2 表明使用了MobileNet 特征提取器的方法在参数量和浮点数运算量均少于HRNet 和ResNet,但性能却与HRNet 和ResNet 相差不超过1%。

图3 人体姿态估计
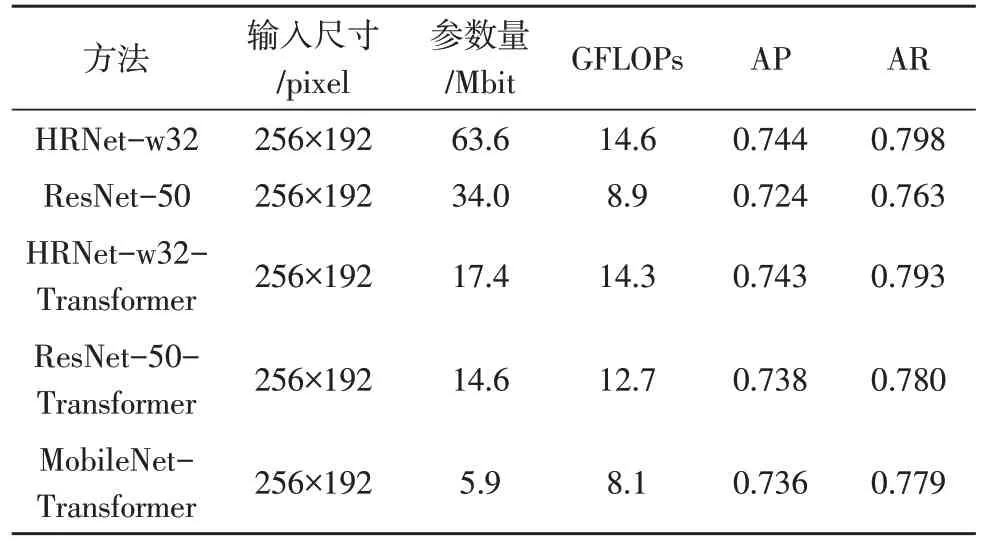
表2 COCO验证集上的效果
3 结论
该文提出一种结合MobileNet 网络结构和Transformer 编码器对人体关键点定位的方法,使用深度可分离卷积代替标准卷积作为特征提取器,在网络中还设计了具有残差连接的细化结构来提取浅层信息。与传统的方法相比,既选择了深度可分离卷积来减少参数量,又选择了Transformer 的编码器结构进行关键点检测,在保持轻量化的同时又利用了Transformer 并行结构特点,使得模型的训练速度更快。实验结果表明,该模型具有较小的参数量,较高的识别准确率和识别效率,可应用到智能视频监控系统中,结合目标检测、识别以及人体姿态估计算法,判断视频监控覆盖范围内所有人体目标姿态。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
摄影之友(2016年12期)2017-02-27
摄影之友(2016年8期)2016-05-14
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
阅读(中年级)(2009年11期)2009-04-14
