
基于分布式存储和并行计算的海量舆情数据分析方法研究
2023-10-21 06:10邱国婷
电子设计工程 2023年20期
邱国婷
(西安航空职业技术学院,陕西西安 710089)
随着计算机技术与通信网络的持续发展与完善,电子化、信息化媒体社交已更加深入人们的日常生活,且各大社交平台也在不断产生海量的数据[1]。信息的高速通达有利有弊,尤其对于某些突发事件,快速的网络传播极易引发网络舆情。若不对其进行正确的预警及引导,可能会造成一系列不可控的局面[2-3]。因此在大数据环境背景下,通过对网络舆情数据加以采集、分析、检测与预警,以实现对突发事件舆情的有效管控,同时引导并控制突发事件的态势走向,对应急决策均具有关键性的作用[4]。
目前国内对于舆情分析已有一定的研究,基于大数据环境的有灰色系统理论(Grey System Theory)、支持向量机(Support Vector Machine,SVM)等算法可用于数据分析,同时还考虑了分布式系统来提高数据的处理效率[5-7]。但对于海量且动态变化的舆情数据,现有大部分方法均存在数据分析时间较长或分析结果不理想等问题。因此,该文基于分布式存储及并行计算技术设计了一种适用于海量网络舆情数据的分析方法。该方法结合了Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)与Spark并行化计算,以实现对舆情数据的可靠分析。
1 系统设计
海量数据分析系统包括数据采集层、数据存储层、数据分析层和数据显示层,其整体架构如图1所示。

图1 数据分析系统的整体架构
其中,数据采集层用于接收系统的各类日志数据,并将收集的数据存储在Hadoop 分布式文件系统,即数据存储层中[8]。在数据分析层,可通过Spark SQL查询数据,且Spark 能够利用其弹性分布式数据集(Resilient Distributed Datasets,RDD)与数据库可用性组(Database Availability Group,DAG)机制将日志数据分发到集群,并实现并行计算和基于随机森林算法(Random Forest,RF)的数据分析,再将分析结果进行显示,同时还可以支持查询。
2 分布式存储系统架构
Hadoop 作为分布式计算平台主要功能是对大数据的存储及分析[9]。而HDFS 是Hadoop 的关键技术,其具备较高的可扩展性、容错性、可靠性以及高吞吐率等优势[10]。典型的HDFS 集群包括一个主节点和若干个数据节点,具体的模块阐述如下:
1)NameNode:作为集群中的主节点,其位于Master 服务器中,主要负责管控文件命名空间、调控和调节Client 端的访问文件,且维护系统内部的相关文件信息。同时在系统内还配备了一个备份节点,即Secondary NameNode,可用于存储NameNode 的元数据,并与之通信。
2)DataNode:作为集群内的数据节点,其位于Slave 服务器中,文件数据经划分后存储在各个DataNode 中。
此外,当进行数据读写时,Client端需先从Name Node中获取存储的元数据信息,才能与其建立通信,并进行相应的读写操作。由于数据读写过程中,传统的数据缓存方法不适用于分布式存储系统,为此设计了一种基于热点检测的缓存方法。该方法充分利用了分布式系统的访问模式,从而提升了缓存池中数据的命中率,并加快了缓存进度。
基于热点检测的缓存方法是将冷热数据进行区分,缓存架构如图2 所示。其中,采用固态存储硬盘构成热数据缓存池,并利用普通磁盘存储冷数据。

图2 基于热点检测的缓存架构
当Client 端需要读写的数据在缓存池中命中时,则直接展开读写操作,且无需访问普通存储磁盘;若没有命中,则需要把请求转至存储池以完成Client 端的读写。此外,Filter 模块可用于发掘热数据。若某一数据被反复访问,则由Promotion 模块将其转移至缓存池;若该数据没有被反复访问,则不转至缓存池,即处于候选状态。当缓存池的使用率大于某一限定值时,Agent 模块会把无效数据转移至存储池,或是将冷数据予以剔除,进而释放缓存空间。
3 基于并行计算的数据分析
传统的Spark 并行化计算中,其数据处理方法大多基于统计分析而展开。但对于海量数据而言,其分析效果并不理想。因此利用随机森林算法对区块内的数据进行分类,并通过Spark 架构实现数据的快速分析。
3.1 基于Spark的并行化计算框架
Spark 是一个基于内存计算的并行框架,其可有效地支撑交互式查询等计算方式[11-13]。Spark 采用了Master/Slave 的计算架构,其中Master 和Slave 分别存储Master 节点与Worker 节点的内容。Master 是集群的控制核心,负责系统的稳定运转;而Worker 则是集群的计算节点,负责接收Master 的指令并上传自身计算状况,然后再触发Executor 或者Driver。Executor 与Driver 分别负责执行、派发任务,且Driver通过创建Spark Context 对象来访问Spark。而Client作为用户的客户端,负责提交应用。
3.2 随机森林算法
随机森林算法的主要思想是将多个决策树分类器模型相结合[14-16],即将Bagging 与随机子空间合并进行决策,并通过投票决策得到最终结果。
随机森林算法主要包括决策树生长与投票过程,而生长过程又分成随机选取训练集、构建随机森林及分割节点。在节点分割过程中,选择系数φ最小的特征作为分割特征,计算过程如下:
首先,计算样本系数:
式中,Pi为样本集S中类别i的概率,类别总数为m。
然后,计算分割节点的系数:
式中,Ω为分割节点集,|S|为样本集中的样本数,|S1|、|S2|分别为子集S1和S2的样本数。
随机森林算法中训练集与特征集的选择方式,使得其具有较好的鲁棒性及容错性。因此,将其应用于海量数据的分析与分类中是可行的。
3.3 基于随机森林算法的数据分析方法
将随机森林算法融入基于Spark 的并行化计算,以实现海量数据的高质量分析,其流程如图3 所示。

图3 随机森林算法并行化计算流程
首先将输入的数据抽象为RDD 并分发到Spark的Worker 节点上,且每个Worker 节点均利用随机森林算法进行数据分析归类,同时利用广播的方法在全部Worker 节点上共享随机森林算法分割节点的系数;然后经Spark 的Map Partitions 函数得到各个Worker 节点上的数据类别,并对其进行累加;最后更新各个决策树直至满足迭代终止条件,即可输出海量数据的类型及数量。
4 实验结果与分析
实验中所构建的HDFS 集群配备了9 台操作系统为Ubuntu 14.04 的服务器,且Hadoop 版本为2.6.0,Spark 版本为1.5.0。该文将基于Matlab 平台训练随机森林算法用于舆情数据分析,并从微博选取2021年国庆节前后一周的话题评论、关注数据。
4.1 并行计算速度分析
在所提方法中,使用Hadoop 分布式方法存储舆情数据,并基于Spark 并行方式分析数据。为验证其有效性,使用传统或分布式方式存储及查询舆情数据,即通过Hive 或Spark 从HDFS 查询一定数量的评论记录。查询不同数量的评论数据时,各方法的响应时间如图4 所示。
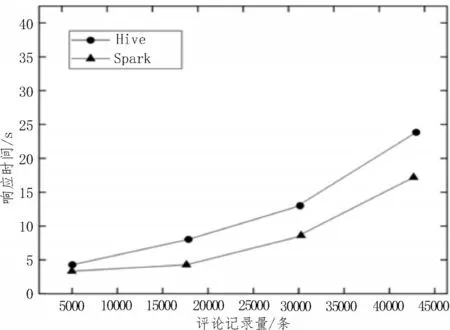
图4 不同方法的数据查询响应时间
由图4可知,随着查询评论记录数量的增加,两种方式的响应时间均有不同程度的上升。但Spark查询方法的响应时间较短,即速度较快。以查询30 000条评论记录为例,Spark查询方法的响应时间约为7.8 s,而Hive 查询方法的响应时间接近于12.5 s。此外随着查询数据量的增多,基于Spark 查询方法的响应速度也更快,故其在并行计算方面的优势更为显著。
4.2 分布式存储效率分析
基于热点检测的缓存机制能够较好地处理冷数据,并减少存储开销。其与传统缓存方法的数据读写速率如表1 所示。
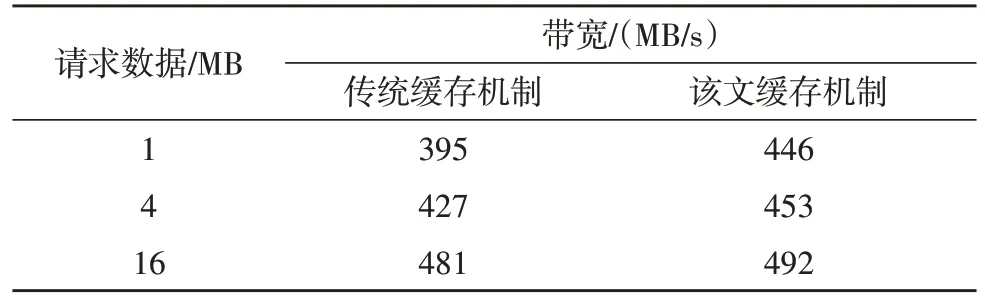
表1 不同缓存机制的数据读写速率
从表中可以看出,相比于传统缓存机制,基于热点检测的缓存机制具有更优的读写速率。随着请求数据大小的增加,传统缓存机制的读写速率出现了快速上升,这是由于传统缓存机制将大量冷数据放入缓存池,既占用了容量又影响了读写效果。以4 MB和16 MB 为例,传统方法增加了54 MB/s,而该文机制仅增加39 MB/s。原因是该文机制利用数据访问热度进行排序,能更好地利用缓存池容量。此外还可提高读写性能,从而实现了高效的分布式数据存储。
4.3 舆情分析准确率对比
舆情分析结果的准确性对数据使用者至关重要,并直接影响了相关措施的实施。为论证所提方法的分析性能,将其与文献[4]、文献[5]、文献[7]进行对比分析,不同方法的分析准确率如图5 所示。

图5 不同方法的数据分析准确率
从图5 可以看出,该文方法的分析准确率相比于其他方法最高,且当其趋于稳定时,准确率可达96%。由于该方法结合了Hadoop 分布式存储及Spark 并行计算,并采用随机森林算法进行数据的分析汇总,较大程度地保证了数据分析结果的可靠性。而文献[7]基于灰色系统理论进行数据分析,单一的分析模型难以保证海量数据分析准确率,因此其值低于80%。同样,文献[5]仅考虑R+Hadoop 框架实现舆情分析,缺乏有效的数据分析算法,故其准确率也并不理想。文献[4]则采用高性能的支持向量机模型进行数据分类,虽然提高了分析准确率,但由于缺乏并行计算的支持,相比于该文方法的分块处理,其结果仍有待进一步提升。
5 结束语
随着移动互联技术的不断发展,社交媒体成为了公众表达观点的关键平台,因此实时了解并掌握舆情动态也较为重要。为此,该文提出了一种基于分布式存储和并行计算的海量网络舆情数据分析方法。其将采集的舆情数据存储于HDFS 中,并基于Spark 框架对数据进行随机森林并行化分析,且支持系统查询分析结果。实验结果表明,基于Spark 查询方法的响应速度更快,且数据分析准确率超过了90%,并在保证数据分析可靠性的同时加快了响应速度。然而由于条件有限,该实验仅配备了9 台服务器。因此在接下来的研究中,将扩展节点、完善软硬件设施,以提高所提方法的普适性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中学数学杂志(初中版)(2016年5期)2016-11-01
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
