
汉传佛典汉英平行语料库建设研究
2023-10-19 12:35:18马杰森
文化创新比较研究 2023年22期
马杰森
(绍兴文理学院 外国语学院,浙江绍兴 312000)
汉传佛典是中华传统文化的有机组成部分,其数量众多,内涵深厚。在与世界文化交流的历史进程中,佛典的对外译介极具挑战性。2023年习近平总书记在中国共产党与世界政党高层对话会上提出“要共同倡导加强国际人文交流合作,探讨构建全球文明对话合作网络,丰富交流内容,拓展合作渠道,促进各国人民相知相亲,共同推动人类文明发展进步”[1]。因此,积极推进中华文明与世界其他文明的交流沟通,是时代对中国学者提出的必然要求。正如潘文国先生所言,“汉籍英译不是外国人的专利,中国学者和翻译工作者应该理直气壮地勇于承担这一工作”[2]。近年来,随着机器翻译的快速发展,神经网络机器翻译(以下简称“NMT”)的准确性和高效性早已超越了普通人类译者,特别是ChatGPT这个基于神经网络架构训练而成的生成型预训练变换模型,超越了一般人的知识翻译能力,使得翻译产业开始步入大生产时代。基于“平行语料库在语言对比、翻译研究、翻译教学、自动翻译、双语词典编纂和自然语言处理等领域具有重大的理论意义和应用价值”[3],创建大型汉传佛典汉英平行语料库,以促进汉传佛典外译事业,就显得尤为必要。
1 汉传佛典汉英平行语料库建设的现状
据马伟德(Marcus Bingenheimer)统计,截至2023年3月共有639份汉传佛典被译成西方语言,总计1 421个译本。但我国学者的参与度较低,译介数量很少,这与我国作为汉传佛典的主要传承与发展者的身份严重不符。汉传佛典的英译虽有纸质或电子类汉英佛学双语词典,比如,苏慧廉(W.E.Soothill)与何乐益(Lewis Hodous)合编的《中国佛典术语双语词典》、陈观胜与李培茱编著的《中英佛典双语词典》、派伊(Michael Pye)和李雪涛等合编的《多语对照中国佛典术语辞典》,以及穆勒(C.Muller)主持编辑的在线电子词典等可资参考,但此类双语词典仅限于对佛典术语提供解释和对应的英译,很少像平行语料库那样提供真实的例句或上下文语境,因此在汉传佛典外译实践中很难满足实际需要。
到目前为止,我国尚无可资利用的汉传佛典汉英平行语料库。国外虽有佛典平行语料库,但数量很少,且并非用于翻译目的。东京大学SAT大正藏文本数据委员会创建的佛典平行语料库(BDK-SAT parallel corpus)提供中文检索,可查找对应的英译和上下文,但只限于日本佛经传道协会版权所有的译本,作为翻译参考价值有限。另外,挪威奥斯陆大学人文学系创办的佛典文献宝库(Thesaurus Literaturae Buddhicae),该文库是梵、中、藏、英,多语平行语料库,提供搜索功能。不过该库提供的英译本多译自梵文本或藏文本,用于汉英翻译参考价值不大。由此可见,现有汉传佛典平行语料库资源与汉传佛典在世界文化中的地位不对称,很难满足学界在汉传佛典外译和研究方面的需要。
2 汉传佛典汉英平行语料库创建的实践路径
汉传佛典汉英平行语料库是以语料库语言学理论为指导,考虑机助翻译、机器翻译的需求及中古汉传佛典语言的特点而创建的。建设的总目标是收录汉传佛典较重要的100部典籍及名家英译本,使其库容量达到1 000万汉英字数的规模,以充分发挥汉传佛典汉英平行语料库在计算机辅助翻译、双语词典编纂、NMT模型预训练、典籍翻译研究和教学、中华文化外译方面的利用价值。建设的过程涵盖语料的采集、清洗、对齐、记忆库和术语库的提取、语料库的导出和文本分词、词性标注等方面,基本路径如图1所示。
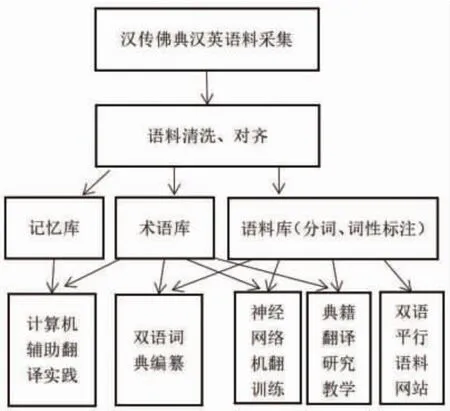
图1 汉传佛典汉英平行语料库建设的基本路径
2.1 汉传佛典汉英语料的采集
汉传佛典浩如烟海,经典甚多,如果将凡有英译本的汉传佛典全部收入语料库进行汉英句对齐,规模之大,小型科研团队很难完成。无论样本有多大,除非它充分涵盖特定话语传播的体裁和语境的范围,否则样本仍然是部分的和不完整的[4]。因此汉传佛典汉英平行语料库在建设过程中对典籍的采集需有所规划,所选典籍要能涵盖经、律、论三藏和不同历史时代,以确保所选典籍样本的代表性和平衡性。在建设初期,宜选择对中国佛教影响最大及最能体现中国佛教基本精神的13部佛经,即以《心经》《金刚经》《坛经》《维摩诘经》《法华经》等为主,有计划有步骤地收录不同历史时代的经、律、论三藏典籍及其英译本,最终达到1 000万字数的适当规模。
确定好佛典后,还得解决以下3个问题。第一,如何选取汉译本的问题。有些典籍在历史上汉译本众多,如何进行选择呢?鉴于建设的是汉英平行语料库而非单语语料库,因此汉译本选择主要取决于英译本所依底本。比如,《法华经》现存有竺法护、鸠摩罗什等3个译本,然众多英译本多以鸠摩罗什本为底本,故对《法华经》的采集便只选鸠摩罗什本。有时,应该遵循英译者的做法,以某汉译本为主导,添加源自参考本中的修订或补缺信息,并加以备注。第二,如何选择英译本的问题。有些佛典英译本并非译自汉语本,而是梵文本或藏文本,比如,《楞伽经》有柯利睿(Thomas Cleary)译自梵语本的英译本,《维摩诘经》有瑟曼(Robert Thurman)译自藏文本的英译本,这些译本虽出自名家之笔,但考虑到梵文本或藏文本的内容和汉语本有较大出入,故需舍弃。还有某些重要经典,如《金刚经》,其英译历史有100多年,英译本非常丰富,因此要注意均匀选取各个时期的译本,以方便后续开展历时研究。对于同一时期不同典籍的译本也要尽可能多收集,以方便后续的共时研究。第三,如何利用现有相关资源的问题。在确定汉、英译本后,为减少扫描、文字识别等工作,尽量采用现有网络电子佛典资源。不过对于采集的语料,需要注意版权问题。
2.2 汉传佛典汉英语料的清洗与对齐
语料清洗一般是指清除所采集语料中的噪音,此类噪音主要为错字乱码、多余的标点、多余的空格、段落标记等。在处理时一般先将各类格式的语料转成统一编码UTF-8格式,然后用文本整理器快速批量处理各种噪音。对于英译本中用拉丁字母转写的梵语词汇往往存在带变音符号的扩展拉丁字母,这种字母是嵌入在PDF等原始文档中,当被复制到其他格式文档时,由于缺少转换所需的编码信息,会出现大量乱码。因此,对于此类扩展拉丁字母建议通过替换的方式全部改为无变音符号的拉丁字母,以减少后期应用的问题。另外,还需去除文本中的各类注释、附录词汇表、参考文献等信息,只保留典籍名称、译者姓名、出版时间、出版社、翻译底本等元信息和正文内容。清洗完成后还需要校对,可利用WPS或WORD拼写检查工具先进行粗略校对,之后再对齐和精校。
语料句对齐目前技术上一般采用基于句长、词汇、混合式等方式进行机器自动对齐,在此基础上再进行人工手动拆分和调整。对齐工具可选择“嵌入式对齐工具、独立式对齐工具、在线对齐工具或开源对齐工具”[5]。汉传佛典语料不同于其他普通文本,在构词、语法和句式上受到梵文佛经的影响,语言形态有别于传统汉语,是中国古代汉语中的一个特殊类型[6]。加之佛典文本在古代并无句读标识,近现代学者在解读、注释或翻译汉传佛典时,受个人的知识结构、语言知识和背景知识的影响,对于某些经文往往存在句读划分差异。另外,同一部汉传佛典存在不同译本或不同版本,内容上相差较大。有些译者在翻译汉传佛典时,会以其中某个版本为底本,再辅之以其他版本的内容,而其他译者可能只依其中某个版本来翻译。一般说来,对于同一作品的多个译本,往往是采用“一对多”的对齐方式,以便于翻译研究和翻译教学。但针对汉传佛典的上述特殊情况,采用“一对多”的方式必然增加对齐难度和对齐时间,且难以达到句对齐的理想效果。所以对于汉传佛典汉英语料的对齐,原则上采用“一对一”的方式比较切合实际。汉传佛典语言简洁,重意合、轻形合,一句汉语包含的语义信息量可能很大,而英语重形合、轻意合,一句汉语有时往往被分割成多个英语句来表达。因此,以汉语句为标准对齐,有时会造成一句汉语对应多句英语,而过长的语句不利于后续NMT模型的预训练——语句越复杂,模型就需要更多的时间和资源来处理,所以在NMT模型预训练前一般要剔除句子长度差距过大的语句,以减少干扰。因此以英语句为标准进行句对齐,适当切分汉语句子,这样能保证英汉句长更合理。
句子对齐具体操作可在汉英语料文本清洗阶段,通过正则表达式快速给每个段落末尾添加段落标记,然后将汉英语料导入雪人CAT对齐项目,勾选“使用段落信息”,这样可以实现段落层面的自动对齐,然后再按照段落以英语句作为标准,根据英语句子意思切分汉语句子,点击回车或删除键对汉英句子进行拆分或合并,实现句级层面对齐。汉语句依英语句意切分后,对于汉语句原来的标点符号仍旧保留,不做修改,这也是研究英汉语言差异的基础信息。
2.3 记忆库、术语库提取及应用
在计算机辅助翻译(CAT)领域,普遍采用翻译记忆库(TMX)来辅助译员进行翻译实践。当译员翻译一篇文档时,计算机会自动检索之前翻译过的句子,如果有相同或相似的句子,翻译记忆库就会给出已翻译的对应句子,译员可以直接使用,也可以根据需要进行修改,从而提高翻译速度和准确度。在利用雪人CAT软件完成汉传佛典语料对齐后,可直接在雪人CAT软件中,鼠标右键点击对齐文件名,在弹出的菜单中选择“导出记忆库”,保存文件类型选择“TMX文件”,输入保存文件名,点击“保存”按钮即可完成记忆库的导出。翻译记忆库主要存储源语言和目标语言的翻译句对,并不需要对生成的语料进行词性标注或进行中文分词。译员使用翻译记忆库可以记录专业术语、翻译技巧和翻译规范等信息,保持翻译的一致性和高效性,也便于术语的规范和管理。
术语库是重要的语言资产,在人工翻译、计算机辅助翻译和机器翻译引擎训练、翻译教学等方面都有重要作用[7]。在每部汉传佛典完成对齐后,都需要对该典籍的术语进行提取,之后再将各部典籍的术语进行汇总,为后续的各种应用做好准备。但在提取术语前,需先明确佛典术语的定义。术语是“各门学科的专门用语,在专业范围内表示单一的专门概念”[8]。佛典术语是专门用语,是在佛典范围内表示单一的专门概念。从广义说,它是包括特定之物名称的集合,即人们从颜色、形状、功用等角度对特定与佛典相关的具体之物加以辨别认知的结果,也包括标记此领域新概念称谓的特定语言符号。名物术语词是不同语言长期接触、相互融合而产生的语言现象。因此,参照相关辞典可对汉传佛典术语进行比较明确的筛选。
平行语料库提取术语的原理是“利用平行语料库中术语使用的统计信息构建自动词库”[9],即分别从中文、英文语料中提取术语,然后进行共现分析,根据分析统计结果自动得到汉英对照术语。利用雪人CAT软件提取术语正是基于此原理,具体操作如下:在雪人CAT软件中完成汉英语料对齐后,打开菜单中的“词语管理”,选择“短语管理”,弹出的“最低词频”对话框中输入适当的频次,然后该软件会自动计算生成汉英短语对照表,我们可手动选择符合上述定义的短语作为术语,然后点击“导出”,保存为纯文本格式术语表。保存完毕后可继续对该术语表进行编辑。提取的术语库后续可以结合Python中文分词组件CRF(Conditional Random Fields)分词工具,对中古汉语佛典进行分词,以提高分词准确度。此外,术语库可用于NMT模型预训练及典籍翻译研究与教学,还可将术语库与语料库相结合以便开展佛典双语词典的编纂。
2.4 语料库分词、词性标注和应用
在雪人CAT软件中完成汉英语料对齐后,鼠标右键点击对齐文件名,在弹出的菜单中选择“导出双语对照文件”,即可得到网页格式的生语料库,再将网页格式生语料库转存为纯文本格式语料库以备分词和词性标注。这对NMT模型的预训练很有价值,可以帮助模型更好地理解原始文本,准确地捕捉文本中的语义和句法信息,提高模型的性能和效果。英语词汇间由于有空格分割,因此不需要分词,而汉语词汇之间没有任何词界标识,所以“中文语言处理必须先分词”[10]。由于我国大部分汉译佛典完成于中古时期,即魏晋南北朝隋唐这个时期。中古汉译佛典语言既不同于上古汉语,又不同于现代汉语,而是“佛典混合汉语”,其词汇特点可归纳为大量使用口语词、俗语词、复音词和外来词。此时期是汉语从上古时期的单字词为主转为近古时期的双字词为主的过渡期,存在大量状态尚未固定的字组,使得中古时期词和短语的边界不明确,造成中古汉语分词困难,严重制约着机器分词准确率和一致性的提高。目前,南京师范大学文学院采用中古时期的佛经等各类语料,运用条件随机场(CRF)模型和词典相结合的方法,研发了中古汉语分词系统,可以服务于中古时期汉译佛典的分词[11]。“汉语词性标注往往需要更复杂的语言处理技术”[12],好在CRF分词工具集成有词性标注功能,结合佛典术语库,标注准确率令人满意。对于英语语料的词性标注一般采用斯坦福大学的POSTagger软件进行标注,对佛典中的梵语名、物术语词性标注不准确的可以通过文本编辑器的查找替换功能进行纠正。
完成语料库分词和词性标注后,可将语料导入平行语料库网站,从而丰富语料库网站建设。对于本地平行语料库在典籍翻译研究和教学的应用,可利用支持双语平行语料库检索分析的ParaConc或PowerGREP软件进行,也可将语料库导入兰卡斯特大学研发的语料库分析工具LancsBox中使用。由于后者既可为英语语料自动添加词性标注等信息,也可自动为汉语语料进行分词或添加词性标注,所以在导入语料库时要注意去掉自动标注功能,以免重复分词与标注。
利用双语平行语料库进行NMT模型预训练是个大工程。这项工作需要较高的技术要求和计算资源,对于个人或者小型学术团队来说具有较大的挑战性。这方面可与高水平科技公司开展合作,让外语学者发挥自身语言优势建设双语平行语料库,让科技公司利用其自身的硬件资源和软件优势进行NMT模型预训练,以开发出更好的机器自动翻译系统,助力典籍翻译和中华学术外译工作。
3 结束语
在中国文化“走出去”的背景下,创建一个汉英字数达到1 000万级别的大型汉传佛典汉英平行语料库具有多方面的意义和价值。首先,它可为汉传佛典的翻译与研究提供坚实的语料库实证数据,便于佛典翻译的误漏查询,也可为典籍汉英语言之间的转换机制提供丰富的研究线索。其次,建成后的汉传佛典平行语料库网站还能服务于典籍翻译教学和传统文化教学。该语料库可以为师生提供大量鲜活的中国传统典籍汉英平行语料,弥补教材中相关语料的不足。再次,汉传佛典汉英平行语料库的建设可为其他中华文化典籍,比如,儒、道、诸子典籍平行语料库的建设提供借鉴参考。此语料库完成后导出的翻译记忆库和术语库有助于计算机辅助翻译实践、编纂电子或纸质双语词典,有效服务于中华文化典籍外译实践。最后,建成的汉传佛典汉英平行语料库和术语库可以为NMT模型预训练提供精确的双语语料,可极大提升机器翻译佛典的质量,促进中华典籍英译模式的推陈出新,服务中华文化外译事业,助力中国文化“走出去”。
猜你喜欢
黄河之声(2022年6期)2022-11-22 11:18:10
现代园艺(2020年17期)2020-12-22 03:45:08
韶关学院学报(2020年1期)2020-02-24 22:08:04
黄河之声(2019年6期)2019-12-17 18:41:47
汉字汉语研究(2018年3期)2018-11-06 07:03:04
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
西域历史语言研究集刊(2015年0期)2015-08-21 08:37:56
西域历史语言研究集刊(2015年0期)2015-08-21 08:37:54
语言与翻译(2014年1期)2014-07-10 13:06:14
