
基于全局图和多粒度意图单元的会话推荐
2023-10-17 05:50李婉桦孙英娟刘艺璇刘乾
计算机工程 2023年10期
李婉桦,孙英娟,刘艺璇,刘乾
(长春师范大学 计算机科学与技术学院,长春 130032)
0 概述
推荐系统[1-2]在许多在线平台中扮演着重要角色,通过向用户推荐有用内容,从而有效解决信息超载问题。传统推荐算法常常依赖于用户配置文件的可用性和长期历史交互。协同过滤[3-4]等经典算法基于不同兴趣爱好对用户进行划分并推荐兴趣相似的商品给用户,基于内容的推荐算法[5-6]根据相关的项目信息完成推荐。但在现实中更多的交互信息来自未登录用户的浏览或短期历史行为,这就造成传统算法推荐效果较差。为了解决这一类问题,便出现了会话推荐[7-9],根据给定的匿名行为序列,按照时间顺序预测用户下一个可能感兴趣的项目。
在会话推荐模型研究之初,许多学者为了有效地对会话进行建模,采用马尔可夫链[10-11]作为核心算法。WU等[12]提出一种马尔可夫链嵌入模型,该模型将用户和物品映射到欧几里得空间,用户和物品之间的距离代表两者之间的转移概率,最后根据嵌入结果对候选项进行排序。RENDLE等[13]提出一种混合模型(FPMC),将矩阵分解方法与马尔可夫链方法相结合,同时学习用户的一般兴趣和下一个兴趣,取得了较好的效果,但由于马尔可夫链模型的假设是基于前一个动作来预测用户的下一个动作,这种强独立性假设容易受噪声数据的影响,因此限制了其在基于会话推荐中的使用。
针对上述问题,学者们提出了很多基于深度神经网络的会话推荐模型并取得了良好性能。HIDASI等[14]提出基于循环神经网络(RNN)的会话推荐模型(GRU4Rec),利用门控循环单元(GRU)层将会话数据严格按照时间顺序建模成单向序列。LI等[15]提出NARM 模型,该模型基于RNN 且将注意力机制引入GRU 编码器,捕获短期会话信息。LIU等[16]提出STAMP 模型,该模型基于多层感知机(MLP)和注意力机制提取用户潜在兴趣。以上模型都是简单地根据时间序列进行会话建模来提取用户信息,但事实上项目转换非常复杂,用户的行为可能不严格按照时间顺序发展,也就是说即使会话中项目顺序调换,也不影响用户对项目的偏好,而对会话中项目严格按照时间顺序建模可能导致过度拟合。
为了更好地表达项目之间的关系,学者们引入图神经网络(Graph Neural Network,GNN)模拟会话数据的项目复杂关系,提高会话推荐性能。WU等[17]提出基于图神经网络的会话推荐模型(SR-GNN),将会话建模成图以捕捉项目之间的关系。QIU等[18]提出FGNN 模型,利用多头注意力机制挖掘邻居信息。WANG等[19]提出GCE-GNN 模型,从会话和全局的角度学习项目之间的转换关系。XIA等[20]提出DHCN 模型,基于超图挖掘项目的高阶信息。然而,以上模型只是孤立地考虑会话中的每一项,在当前会话中没有从更高层次的角度捕捉会话语义。GUO等[21]提出MIHSG 模型,通过构造多粒度意图单元异构会话图从高层次的角度捕捉完整会话意图,因此得到了不错的模型效果。
虽然MIHSG 模型的效果较好,但是其多粒度意图单元异构会话图只是捕捉了当前会话内的项目信息,忽略了不同会话之间的项目信息。本文建立基于全局图和多粒度意图单元的会话推荐模型(GGMIU),在多粒度意图单元异构会话图[21]的基础上,添加跨会话图[19]以获取不同会话之间的项目信息。
1 问题描述
会话推荐旨在根据用户当前的连续会话数据,预测用户下一步将单击哪个项目,并不需要访问长期偏好配置文件。在本文会话推荐任务中,设I={v1,v2,…,v|I|}表示所有会话中用户产生交互项目的集合,vi表示交互过的项目,|I|表示所有项目的总数量。一个匿名会话由s={vt1,vt2,…,vtM}表示,其中,tn表示项目在位置n处被点击的编号,且会话s的长度为M。本文的目标是对当前会话下一步可能点击的项目进行预测,即预测vtM+1。将会话进行写入,模型会依据输入数据经过一系列处理得到候选项目概率值y^,将项目概率值通过排序筛选出概率值最高的前几个推荐项目,建立候选项目推荐序列。GGMIU 模型框架如图1 所示。
2 GGMIU 模型
GGMIU 模型是在MIHSG 模型的基础上进行改进。MIHSG 模型表示不同的粒度长度有不同的用户意图,可从高层次的角度捕捉完整会话意图,通过图2(a)进行说明。在图2(a)中,给出会话“面粉-黄油-鸡蛋”:当粒度长度为1时,该用户可能想买早餐类,则可以尝试推荐牛奶;当粒度长度为2 时就关注“黄油-鸡蛋”,该用户可能是想煎鸡蛋,则可以尝试推荐平底锅;当粒度长度为3时,该用户可能是想制作蛋糕,则可以尝试推荐烤箱。通过该示例表明,在MIHSG 模型中,单个项目就是最小的粒度,不同的粒度长度有不同的用户意图,因此可以从高层次捕捉不同的语义。
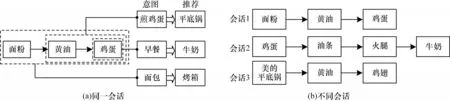
图2 同一会话和不同会话之间的项目信息Fig.2 Project informations between the same session and different sessions
虽然MIHSG 模型效果较好,但是其多粒度意图单元异构会话图只是捕捉当前会话内的项目信息,忽略了不同会话之间的项目信息。根据文献[19]推测,当前会话的项目出现在其他会话时,项目的邻居信息所展示的行为也能反映当前会话的用户意图,通过图2(b)进行说明。在图2(b)中,设当前会话是会话1,会话1 的“鸡蛋”也出现在会话2中,其项目对是“鸡蛋-油条”,所表现的意图可能是早餐类,可以尝试给会话1 的用户推荐“油条”。又比如,会话1 的“黄油”出现在会话3,其项目对是“美的平底锅-黄油-鸡翅”,所表现的意图可能是用“平底锅”煎“鸡翅”,可以尝试给会话1 的用户推荐“美的平底锅”。通过该示例表明:利用项目在其他会话中的邻居信息也能反映相似的用户意图,从而更好地推断当前会话的用户偏好。
2.1 跨会话图模块
为了捕获跨会话级别的项目转换信息,将其用于学习所有会话中的项目依赖关系,根据WANG等[22]提出的方法进行跨会话图的构建。对于当前会话的项目,它的近邻集合Nϒ(v)是在步长ϒ阶范围内交互过的项目,其中N表示集合。当前会话Sa的节点vi,a的近邻集合可以表示如下:
其中:va,i是会话sa的节点i;i′是会话sa中项目va,i在会话sb的顺序位置;ϒ是一个控制项目与项目之间转换建模的超参数,若ϒ超出范围,则它捕获的跨会话项目转换信息会带有噪声。
跨会话图是基于所有会话中的一个ϒ阶相邻项目集构建的图,如图3 所示。设Gc=(Vc,Ec)为跨会话图,其中,c表示跨会话图,Vc∈I表示所有会话被点击的项目集合,Ec={ec,i,j}表示边的集合,ec,i,j表示节点vi和节点vj之间的边,每条边(vi,vj,ec,i,j)对应于所有会话中的两个成对项目,vi∈I,vj∈Nϒ(vi)。此外,对于每个节点vi,会为其相邻边产生权重,以区分邻居的重要性,即每条边的权重是由相应边在所有会话中的频率确定。考虑到效率问题,跨会话图Gc的每个节点vi只保留最高权重的边数,边数自定义。需要注意的是,跨会话图Gc是一个无向加权图,因为ϒ阶邻居集是无向的。在测试阶段,没有动态更新跨会话图Gc的拓扑结构。

图3 跨会话图的构造Fig.3 Construction of cross-session graph
2.2 跨会话表示
受到LI等[23]和WANG等[19]方法的启发,根据在跨会话图上的传播特性,编码来自其他会话的项目转换信息,从而辅助推荐。本文基于图卷积网络的体系结构构建,运用图注意力网络理论得到连接项目的权重。每一层都由信息传播和信息聚合构成,先介绍单层,再推广到多层。
1)信息传播。一个项目可能涉及多个会话,从中可以获得有用的项目转换信息,从而有效地辅助当前预测。
设xv∈Rd(d表示项目嵌入的维度)为项目的向量表示,利用会话感知注意力将邻居集中的每个项目进行线性计算,得到项目的邻居表示xNc.v,如式(1)所示:其中:ξ(vi,vj)代表不同邻居的重要性权重,即一个项目越接近当前会话的偏好,这个项目就越重要。ξ(vi,vj)计算如下:
其中:σ为LeakyReLU 激活函数;⊙表示元素乘积;[;]表示拼接操作;λi,j∈Rm表示跨会话图的边(vi,vj)的权 值;W1∈R(d+1)×d和P1∈R(d+1×1)是可训练的参 数矩阵;s为当前会话的特征,通过计算当前会话项目表示的平均值得到。s计算如下:
采用Softmax 激活函数将项目vi的所有邻居进行系数规范化,如式(4)所示:
2)信息聚合。将项目表示xv和项目的邻居表示xNc,v进行聚合得到当前跨会话图的项目vi表示,如式(5)所示:
其中:ψ为ReLU 激活函数;W2∈Rd×2d为变换权重。通过聚合器层,项目的表示依赖于它自己及其近邻项目。采用聚合器从一个层扩展到多个层来探索高阶连接信息,这样可以将更多与当前会话相关的信息纳入当前表示。第u层的一个项目表示计算如式(6)所示:
其中:Γ为聚合函数;xu-1,v表示由前面的u-1 层信息传播生成的v项目表示,设x0,v为xv的初始传播迭代。由此可知,一个项目的u层表示由它的初始表示和它的邻居循环到u层组成。这样可以将更有效的消息合并到当前会话的表示中。
在跨会话表示中,使用丢弃率来避免过度拟合,如式(7)所示:
其中:D为丢弃率函数。
2.3 连续意图单元
当前基于会话的推荐方法分别考虑每个项目,但这容易忽略本地会话片段的更高层次的意图。为了能更加深层次地挖掘用户在当前会话中的意图,利用项目的连续意图单元进行提取。连续意图单元表示一组连续相邻的项目,设vk,j=(vj,vj+1,…,vj+k-1)为一个连续的意图单元,它是一个连续片段,在原会话中从第j个位置开始到j+k-1 位置结束,长度为k,同时将会话的单个项目定义为单粒度,2 个或2 个以上的项目定义为多粒度。为了能更好了解连续意图单元的结构,通过图4 进行说明。在图4中,2 级连续意图单元v2,1是从原会话{v1,v3,v2,v4,v3,v2}第1 个位置开始且长度为2 的连续片段,v2,2是从原会话第2 个位置开始且长度为2 的连续片段(v3,v2),其他以此类推。连续意图单元的长度k用粒度级别来表示,即k级连续意图单元的粒度级别为k。需要注意的是同级的意图单元是不重复的。

图4 连续意图单元、k 级意图会话图和多粒度意图单元异构会话图的构造Fig.4 Construction of continuous intention unit,k-level intention session graph and multi-granularity intention unit heterogeneous session graph
对于会话s,vk,j的k级连续意图单元的意图用xk,j表示,如式(8)所示:
其中:R 是Readout 函数。
为了提取高阶意图单元的完整意图,考虑使用基于序列和基于集合的Readout 函数分别得到xk,q,j和xk,p,j。一方面xk,q,j能得到节点顺 序相关的潜在 信息,另一方面xk,p,j能得到节点顺序无关的潜在信息。为此,vk,j的k级连续意图单元的意图计算如式(9)所示:
其中,xk,q,j∈R1×d可通过门控递归单元得到;xk,p,j∈R1×d可通过平均值和最大值得到。
2.4 意图会话图和多粒度意图单元异构会话图
设有向图Gk,s=(Vk,s,Ek,s)为k级意图会话图,其中,节点Vk,s表示k级连续意图单元,Ek,s是两个k级连续意图单元的边,s表示会话。将不同k级意图会话图统一,得到多粒度意图单元异构会话图。在多粒度意图单元异构会话图中,节点vk的边类型有粒度内边(▷)和粒度间边(◁),粒度内边在同级意图会话图中进行项目之间的连接,粒度间边将1 级和高级意图会话图进行连接。在3级意图会话图中能构造6条粒度间边,分别是(v3,1,◁,v1,4)、(v1,1,◁,v3,2)、(v3,2,◁,v1,2)、(v1,2,◁,v3,3)、(v3,3,◁,v1,3)和(v1,3,◁,v3,4)。针对(v3,1,◁,v1,4),v3,1是从原会话第1 个位置开始且长度为3 的连续片段(v1,v3,v2),v1,4是从原会话第4 个位置开始的项目v4且是连续片段(v1,v3,v2)的后一个项目,又因为粒度间边是将1 级和高级意图会话图进行连接,因此粒度间边将v3,1和v1,4连接。针 对(v1,1,◁,v3,2)和(v3,2,◁,v1,2),v3,2是从原会话第2 个位置开始且长度为3 的连续片段(v3,v2,v4),v1,1是原会话第1 个位置的项目v1且是原会话片段(v3,v2,v4)的前一个项目,v1,2是从原会话第2 个位置开始的项目v3且是原会话片段(v3,v2,v4)的后一个项目,同时因为粒度间边是将1 级和高级意图会话图进行连接,所以粒度间边将v3,2和v1,1、v1,2分别进行连接,其他以此类推。
2.5 连续意图单元会话学习
采用异构图注意力(Heterogeneous Graph ATtention,HGAT)网络得到每个连续意图单元的表示。对于有向边(α,e,β),其中,e是边,α和β分别表示为源和目标意图单元,同时可表示任何粒度级别。在一个k级的异构会话图中,将kα∈{1,2,…,K}和kβ∈{1,2,…,K}分别定义为意图单元α和β的粒度级别。ε定义为边缘类型,它包含粒度内边和粒度间边。在异构图注意力网络的每一层中,通过注意力机制聚合内邻居和外邻居的表示。内邻居集合Nε计算如式(10)所示:
其中:Λ为Softmax 函数;Wl,ε∈Rd×d和al,ε∈R2d×1是权重;B0,α=xα和B0,β=xβ分别是意图单元α和β的初始表示;Bl,α和Bl,β分别表示意图单元α和β在HGAT 上的第l层表示。
同时,利用多向注意力机制通过Readout 函数得到输出节点的表示,如式(11)所示:
其中:i表示注意力的头数索引;H为注意力机制的总头数。
因为异构会话图为有向图,每个节点都具有来自内邻居和外邻居的上下文。为从两个方向提取上下文信息,应用HGAT 来聚合内邻居和外邻居信息以生成节点表示。因此,对于该图的每个意图单元v,聚合v两个方向的嵌入,即和,其中,表示v左边方向的信息嵌入表示v右边方向的信息嵌入。节点v的最终表示Bl+1,v为两个方向的嵌入之和以及会话中所有节点嵌入的平均值之和其中,表示会话中所有节点的嵌入平均值之和。
利用局部表示Hk,l和全局表示Hk,g挖掘连续 意图单元每个级别的用户偏好。当给出会话si和相应的连续意图单元嵌入Bk,i∈Rd(i=1,2,…,nk,k=1,2,…,K)时,将最后一个意图单元Bk,nk作为局部表示Hk,l,软注意力机制得到全局表示Hk,g,其中,nk是k级意图单元数,K是意图级别数。
全局表示Hk,g通过聚合所有意图单元的嵌入来表示。设C={Bk,i|i=1,2,…,nk,k=1,2,…,K}为意图的上下文集合,Bc是上下文集合中的一个嵌入。Hk,g计算过程如下:
其中:Wk,0∈Rd;Wk,3∈Rd×d;Wk,4∈Rd×d;bk∈Rd为可学习的权重;σ(·)为Sigmoid 函数;χk,c为权重系数。
最后,将全局表示、局部和跨会话表示相拼接,得到连续意图单元的每个级别用户偏好,如式(14)所示:
其中:Wk,5为权重。
2.6 意图融合排序和预测
式(14)生成的不同粒度级别会话嵌入(H1,s,…,Hk,s,…,HK,s)通过意图融合排名(IFR)机制[21]融合所有粒度级别的意图预测推荐结果得到用户的意图。首先根据每一级的意图得到一个单独的推荐;然后将结果进行融合形成最终的推荐;最后对于每个k级别意图,可采用内积来计算候选项目意图和k级别会话嵌入之间的相似度。对于候选项集I={v1,v2,…,v|I|},计算项目vi的意图在会话嵌入Hk,s和x1,i之间的相似度,如式(15)所示:
其中:<,>是内积运算。
同时,受文献[24-25]的启发,可对会话重复点击行为和探索行为进一步分析以提高准确性,这首先需要将内部会话项目和外部会话项目分开,通过使用Softmax 函数进行归一化,计算过程如下:
其中:R={r1,…,ri,…,r|R|}为内部会话项目,O={o1,…,oi,…,o|O|}为外部会话项目,|R| +|O|=|I|;∈R和∈O分别是内部会话项目和外部会话项目的概率分布。然后使用一个鉴别器来重新加权项目得分,以平衡重复点击和探索点击之间的焦点。分数y就是这两部分的组合,计算过程如下:
其中:W6∈Rd×2、W7∈Rd×d为权重矩阵;πk,r、πk,o为权重系数。
式(16)~式(18)为重复探索规范化(RENorm)策略的具体过程。
遵循意图融合排序机制,通过一个加权和运算符聚合各个层次的意图所产生的概率分布得到最终的概率分布y^,计算过程如下:
其中:和yk为标准化权重;θk为每个概率分布的可学习因素。
最后使用交叉熵函数作为损失函数,计算如下:
3 实验与结果分析
3.1 数据预处理
采用Diginetica 和Tmall 数据集进行实验评估GGMIU 模型的性能。在Diginetica 数据集中,使用的数据是其用户的互动信息,可以从CIKM Cup2016比赛下载得到。在Tmall 数据集中,使用的数据是隐藏个人信息的用户在天猫电商上的购买信息,数据可从IJCA15 大赛下载得到。实验模仿RENDLE等[13]提出的预处理方式,筛选数据集中数据长度是1的会话,同时去除测试集中点击次数低于5 的项目。经过上述预处理后,Diginetica 数据集剩下43 097 个项目,Tmall 数据集剩下40 728 个项目。此外,为了能有更多的会话数据进行训练,将每个会话进行再次划分,具体为:对于每个会话s={ts,1,ts,2,…,ts,m},划分为点击项序 列以及对应的标签,即([ts,1],ts,2),([ts,1,ts,2],ts,3),…,([ts,1,ts,2,…,ts,m-1],ts,m),应用于这两个数据集的训练和测试。数据集统计信息如表1所示。

表1 数据集信息Table 1 Data set information
3.2 评价指标
实验选用推荐系统经常使用的两个评价指标:平均倒数排名(Mean Reciprocal Rank,MRR)和精确度(Precision,P)进行模型有效性测试。同时,选用概率值最高的前10 或者20 个推荐项目作为候选项目推荐序列。
MRR@20 表示正确推荐项目在前20 个推荐项目中位置倒数的平均值。若正确推荐项目未出现在推荐序列上,则MRR@20 值为0。值越高,表明算法预测性能越好,计算如下:
其中:N表示测试集样本总数;M表示正确推荐项目在推荐序列前20 个中所占的数量;τ(it)表示推荐列表中推荐项目i所在的位置。
P@20 常作为推荐系统预测精确度的衡量指标,表示正确推荐的项目在前20 个项目中的比例,计算如下:
其中:V表示返回前20 个推荐项目中正确推荐的项目数。
3.3 实验参数设定
在验证集上选取其他超参数,验证集是训练集的10%随机子集。所有参数均采用高斯分布初始化,均值为0、标准差为0.1。GGMIU 模型设定节点隐向量的维度d为100,迭代次数为20,训练批次大小为100。此外,模型使用Adam 算法优化器,初始学习率为0.001,每迭代3 次学习率衰减0.1,正则化系数为10-5。实验参考文献[19,21],设置评估指标连续迭代3 次小于最佳指标则停止迭代。
3.4 对比模型
对比模型具体如下:
1)Item-KNN,基于当前会话的项目和其他会话的项目之间的相似度来推荐项目。
2)GRU4Rec[14],是一种通过门控循环单元捕捉用户序列的依赖关系的模型。
3)NARM[15],是一种基于RNN 的通过注意力机制捕捉当前会话用户意图的模型。
4)SR-GNN[17],在图神经网络层获得项目嵌入,对最后一个项目应用注意力机制,以计算基于会话推荐的会话级嵌入。
5)GCE-GNN[19],首先通过构建会话图和全局图,学习全局项目嵌入层和会话项目嵌入层,然后利用软注意力机制聚合两层的项目嵌入得到会话嵌入,最后添加位置信息以获得最终结果。
6)DHCN[20],利用基于超图的神经网络捕获项目之间的高阶信息,并将自监督学习作为增强超图建模的辅助方法。
7)MIHSG[21],通过构造多粒度意图单元异构会话图从高层次的角度捕捉完整的会话意图。
3.5 与MIHSG 模型的比较
GGMIU 模型是在多粒度意图单元异构会话图的基础上添加了跨会话图。为了证明GGMIU 模型的有效性,与没有加入跨会话图的MIHSG 模型在Tmall 和Diginetica 数据集上进行比较,如图5 和图6所示。由图5 和图6 可以看出,在Tmall 和Diginetica数据集上,GGMIU 和MIHSG 模型均在第4 次迭代后MRR@20 和P@20 指标未出现剧烈波动,模型趋于平稳,GGMIU 模型在MRR@20 和P@20 指标上的表现优于MIHSG 模型,且差距也趋于稳定。由此可以证明添加了跨会话图的模型能更深层次地挖掘不同会话之间的潜在信息,从而提高模型推荐效果。
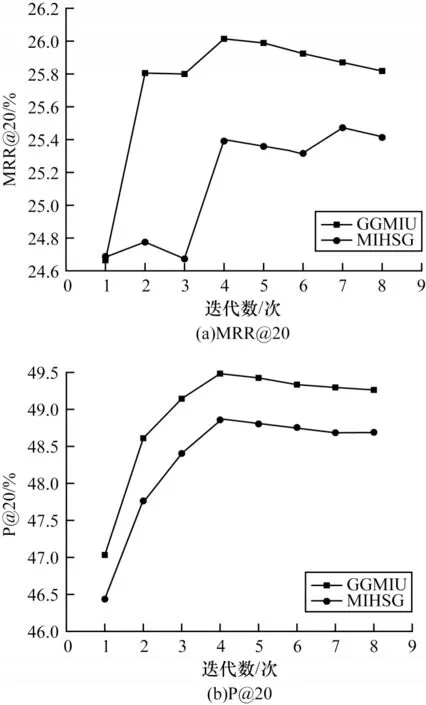
图5 Tmall 数据集上的实验结果Fig.5 Experimental results on the Tmall data set

图6 Diginetica 数据集上的实验结果Fig.6 Experimental results on the Diginetica data set
3.6 整体性能比较
GGMIU 模型和基线模型在两个真实数据集上的实验结果如表2 所示,其中,使用粗体突出每列的最佳结果,下划线表示次优结果。由表2 可以看出,GGMIU 模型表现最优,并得到以下结论:

表2 不同模型在两个数据集上的实验结果Table 2 Experimental results of different models on two data sets %
1)SR-GNN、GCE-GNN、DHCN、MIHSG、GGMIU等应用图神经网络的模型比Item-KNN、GRU4Rec、NARM 等没有应用图神经网络的模型预测效果更好,这是因为图神经网络模拟会话中项目转换关系建模成图能更好地捕获项目之间的依赖关系,证明了基于图神经网络的模型更适合会话推荐。
2)除了Diginetica 数据集上的P@20 指标外,MIHSG 模型优于SR-GNN、GCE-GNN 和DHCN 模型。这是因为SR-GNN、GCE-GNN 和DHCN 模型只是孤立地考虑会话中的每一项,没有从高层次的角度捕捉会话语义,MIHSG 模型通过多粒度连续用户意图单元从高层次角度捕捉会话完整的意图,从而提高了模型性能。
3)GGMIU 模型优于所有模型,相较于MIHSG 最优基线模型在Tmall 数据集上 的MRR@20 和P@20上增益分别高达2.12%和1.27%。这是因为GGMIU模型在多粒度意图单元异构会话图的基础上,添加了跨会话的全局图,以获取不同会话之间项目的信息。可见,GGMIU 模型不仅考虑了高层次角度的会话语义,而且还考虑了跨会话角度的项目信息,从而提高了模型精度。
3.7 参数调整实验
跨会话表示的丢弃率是影响模型性能的重要因素。在Tmall 和Diginetica 数据集上探究不同的丢弃率对模型性能的影响,如图7 所示。由图7 可以看出,在丢弃率为0.3时,GGMIU 模型在Tmall 数据集上能取到P@20 和MRR@20 的最大值,因此在Tmall数据集上取丢弃率为0.3 更合适。在丢弃率为0.3 和0.1时,GGMIU 模型在Diginetica 数据集上能取 到P@20和MRR@20 的最大值,但在丢弃率为0.1 时P@20 和MRR@20 的差值小于在丢弃率为0.3 的差值,因此在Diginetica 数据集上取丢弃率为0.1 更合适。

图7 在Tmall 和Diginetica 数据集上的不同丢弃率分析Fig.7 Analysis of different dropouts on the Tmall and Diginetica data sets
3.8 消融实验
项目的推荐概率结果由IFR 和RENorm 决定。为了研究IFR 和RENorm 的有效性,进行消融实验,如表3 所示,其中,使用粗体突出每列的最佳结果,GGMIU 模型结合IFR 和RENorm,模 型1 移除了RENorm,模型2 移除了IFR。由表3 可以看出,结合IFR 和RENorm 的GGMIU 模型结果远优于模型1 和模型2,在Tmall 数据集上的MRR@20 和P@20 增益分别高达11.20%和17.42%。这说明将探求会话重复点击行为和探索行为的RENorm 与融合所有粒度级别的意图预测推荐结果的IFR 相结合达到了较好的推荐效果,这也证明了每个模块都是有效的。

表3 消融实验结果Table 3 Results of ablation experiment %
3.9 隐向量维度对模型性能的影响
为了方便GGMIU 模型与其他模型进行比较,设置隐向量维度d为100,其实不同的隐向量维度会影响GGMIU 模型的推荐效果。在本节中,通过设置隐向量维度d为50、100、150、200、250 和300,分析隐向量维度d对模型性能的影响,如图8 所示。由图8 可以看出,随着隐向量维度d的增加,MRR@20 和P@20 指标也随之增加,当达到一定的维度时,指标开始下降。对于Tmall 数据集:在隐向量维度d提升到100后,MRR@20 指标开始趋于平稳;在隐向量维度d提升到250后,P@20 指标开始下降。对于Diginetica数据集:在隐向量维度d提升到150时,MRR@20 指标开始下降;

图8 隐向量维度d 对模型效果的影响Fig.8 Influence of hidden vector dimension d on model effect
在隐向量维度d提升到200时,P@20 指标开始下降。由此可知,即使同一个数据集,不同的评估指标对应的最优隐向量维度d是不同的。在一定范围内,增加隐向量维度d有助于模型预测效果的提升,但继续提高维度效果反而会越来越差,不仅容易导致过拟合,而且会加大计算代价。综合考虑性能和计算代价来看,在Tmall 和Diginetica 数据集上,GGMIU 模型的隐向量维度d设为200 更合适。
4 结束语
本文考虑了会话信息表示中当前会话的高层次会话语义和不同会话间的项目信息,建立基于全局图和多粒度意图单元的会话推荐模型。首先构造跨会话图,利用图神经网络得到跨会话表示;接着在连续意图单元上构造多粒度意图单元异构会话图,得到全局和局部表示;最后将三者表示进行融合,捕获会话中项目之间的复杂依赖关系。三者所融合的表示经过会话重复点击和探索行为分析后,聚合所有级别的单元预测结果得到最终的预测概率值。通过大量的实验结果验证了所提模型的有效性。后续将对多粒度意图单元异构图做进一步改进,探究意图单元的潜在信息以挖掘用户的意图,提高推荐性能。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
疯狂英语(双语世界)(2017年4期)2017-04-28
海外华文教育(2016年3期)2017-01-20
延河(下半月)(2014年3期)2014-02-28
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
