
基于多模型加权组合的文本相似度计算模型
2023-10-17 05:49刘栋杨辉姬少培曹扬
计算机工程 2023年10期
刘栋,杨辉,姬少培,曹扬
(1.中国电子科技集团公司第三十研究所,成都 610041;2.中电科大数据研究院有限公司,贵阳 550022;3.提升政府治理能力大数据应用技术国家工程实验室,贵阳 550022)
0 概述
计算2 篇短文的语义相似度在各种语言处理任务(如剽窃检测、问题回答、机器翻译等)中起着重要作用。语言表达的多样性给语义文本相似度(Semantic Text Similarity,STS)任务带来一定挑战,如2 个带有不同词汇的句子可能有相似的含义[1]。
文献[2]设计了一个依赖树结构的LSTM 来进行文本建模,该模型在STS 任务中取得的性能优于线性链LSTM。文献[3]提出了一种用于文本建模的分层CNN-LSTM 架构,该架构使用CNN 作为编码器将句子编码为连续表示,并使用LSTM 作为解码器。为了增强传统的捕获上下文信息的单词嵌入表示,文献[4]提出了一种基于卷积滤波器的N-gram 词嵌入方法,该方法在多语言情绪分析中取得了稳健的性能。文献[5]为了降低中文文本相似度计算的复杂度,同时提高文本聚类的准确度,提出了一种基于DF_LDA 的文本相似度计算算法。实验结果表明,该算法能够有效减少文本特征向量维数,节省文本相似度计算时间,提高文本聚类速度。文献[6]提出关于语义、语句的短文本相似度分析方案,结合知识、语料库表达术语等分析多义问题,随后通过选区分析树掌握短文本句法结构信息。文献[7]针对大多数NLP 神经网络模型都是以细粒度的方式提取文本,不利于从全局角度把握文本含义的问题,将传统统计方法与深度学习模型相结合,提出了一种基于多模型非线性融合的新模型。该模型使用基于词性的Jaccard 系数、术语频率反向文档频率(TF-IDF)和Word2Vec-CNN 算法分别测量句子的相似度,根据各模型的计算精度得到归一化权重系数,并对计算结果进行比较,然后将加权向量输入全连接神经网络中,给出最终的分类结果。文献[8]提出结合语义和中心词管理机制的相似度计算方案。首先使用Bi-GRU 模型提取上下文信息,在获得中心词集后通过注意力机制和字符拼接获得2 个句子的语义增强表示,最后使用一维卷积神经网络将单词嵌入信息与上下文信息相融合。文 献[9]使用语篇表征结构(Discourse Representation Structure,DRS)用于衡量相似度,虽然该方法可以捕获句子的结构和语义信息,但是无法适用于句子深层语义解释。文献[10]系统地分析了不同层次的句法信息和语义信息对文本情感识别准确性的影响,使用树核函数作为一种直观有效的方法,根据输入数据的结构化表示生成不同的特征空间。实验结果表明,该方法能保持语义特征和句法特征的高度融合。
已有研究大多关注单一的文本特征或语义特征。本文在考虑次序、主题、语义等内容的基础上,结合文本的结构化信息等,分别提出基于多词嵌入与多层次比较以及基于Tree-GRU 的文本相似度计算模型。结合上述2 种模型构建一种基于多模型加权组合的文本相似度计算模型。
1 基于多词嵌入与多层次比较的文本相似度计算模型
本节提出一种基于多词嵌入与多层次比较的文本相似度计算(MMTSC)模型,模型结构如图1 所示。MMTSC 模型的组成结构包括3 个部分:

图1 MMTSC 模型架构Fig.1 The architecture of MMTSC model
1)多词嵌入。输入句子转换为多个单词向量,其中单个单词包括多个嵌入向量。
2)句子序列建模。通过最大池化操作[11]和GRU 神经网络[12]提取单词向量的最佳词特征,并进行句子表示。
3)多层次比较。针对2 个句子,从字词比较、句子比较、词句比较3 个方面进行分析,通过加权计算得到最终的相似度计算结果。
1.1 多词嵌入
在给定单词w后,可结合K个预先训练的单词嵌入得到 单词向量ew,concat:
其中:⊕是连接算子;ew,i是第i个嵌入向量。
将单词向量ew,concat输入H 卷积滤波器即可得到关于单词w的多层次嵌入表示ew,mutil,具体计算过程如下:
其中:σ为Logistic Sigmoid函数;fi表示第i个滤波器;bfi表示偏置向量。fi的转置向量与ew,concat、bfi维度一致。
1.2 句子序列建模
给定输入句子序列s=[w1,w2,…,wn],根据式(1)~式(3)得到序列的多词嵌入表示smutil=[ew1,mutil,ew2,mutil,…,ewn,mutil]。本节通过最大池化操作和Bi-GRU 神经网络提取每个单词向量中的最佳词特征序列smutil,用于句子序列建模。具体过程如下:
1)最大池化操作。为了构造一个最大池句子嵌入es,max,从句子序列嵌入表示smutil中提取最大可能的特征表示:
其中:ewk,mutil[i]是ewk,mutil的第i个元素。
2)GRU 神经网络。由于基于最大池化操作提取的嵌入特征忽略了词序的性质,因此本节基于GRU 神经网络提取句子嵌入es,GRU来补充句子嵌入es,max。句子嵌入smutil中的每个元素ewi,mutil被作为单个GRU 单元中前一时刻的ht-1。GRU 神经网络的训练公式如下:
其中:⊙是元素乘积操作;Wz、Wr、Ws是权重矩阵;xt是输入数据分别是隐藏状态、输出状态bz均为常数;σsig和φtanh分别为Sigmoid 函数和tanh 激活函数,分别用来激活控制门和隐藏状态。
hn是基于GRU 神经网络得到的句子嵌入es,GRU,通过将2 个句子嵌入es,max和es,GRU连接起来,得到句子嵌入es:
1.3 多层次比较
1.3.1 词与词比较
给定2 个输入单词w1和w2,2 个单词的嵌入序列表示分别为ew1,mutil[i]和ew2,mutil[i],2 个单词的相似度向量Sdc的计算公式如下:
其中:g()函数用于将矩阵调整为向量;ωdc、bdc分别为权重矩阵、偏差参数。
1.3.2 句子与句子比较
给定2 个输入句子s1和s2,编码处理后获取2 个句子嵌入es1和es2,利用如下指标计算2 个句子的相似度向量:
1)余弦相似性εcos,计算公式如下:
2)乘法矢量εmul和绝对值εabs,计算公式如下:
3)神经差异εnd,计算公式如下:
其中:ωnd、bnd分别为权重和偏差参数矩阵。
句子与句子的相似度向量Ssent的计算公式如下:
其中:ωsent、bsent分别为权重和偏差参数矩阵。
1.3.3 词与句比较
给定句子s1的嵌入表示序列es1和句子s2的多词嵌入表示序列es2,multi,基于式(15)得到句子s2中第i个单词与句子s1的相似度矩阵Ss1,ws=[Ss1,ws[1],Ss1,ws[2],…,Ss1,ws[n]]。
其中:es2,multi[i]为单词s2第i个单词的多词嵌入表示;ωws和bws分别为权重矩阵和偏差矩阵。
基于相似度矩阵得到相似度向量的计算过程如下:
其中:Ss2,ws为利用式(15)、式(16)计算得到的句子s1中单词与句子s2的相似度矩阵;ωws′和bws′分别为权重和偏差矩阵。
1.3.4 相似度计算
针对任意2 个句子对的文本相似度分数,可以通过式(18)~式(20)计算得到:
其中:ωl,1、ωl,2和bl,1、bl,2为模型相关参数为文本对的相似度计算结果。
2 基于Tree-GRU 的文本相似度计算模型
LSTM 可以在序列模型任务中很好地应对任意长度的序列。文献[13]提出了LSTM 模型对应的变种模型,其具有较强的表示能力,能获取更多的长期信息,在预测和分析不同的序列目标时取得了良好效果。文献[14]针对性地提出以GRU 为主题的Tree-GRU 模型——Child-Sum Tree-GRU。在Tree-GRU 内存在多个GRU 单元,能从中掌握Child 的个人信息,以此合理使用网络拓扑结构并保持结构的丰富性。基于此,本节提出以Tree-GRU 模型为基础的文本语义相似度计算模型。该模型首先将文本以浅层语法树结构的形式进行呈现,然后通过Tree-GRU 模型进行文本相似度分析。
2.1 基于短语的浅层语法树结构化特征
浅层句法树(Shallow Tree,ST)属于简单化的结构信息,但是通过ST 能观察复杂结构的变化[15]。Severyn[16]在创建问答句子时,关系模型选择浅层句法树进行特征呈现,取得了较为理想的实验结果。基于ST 结构的句子表示如图2 所示,ST 基本形式是深度为3 的树,最底层(叶子节点)用于表示单词原型,中间部分属于单词的词性,最上层能综合多个词汇内容。通过处理文中的单词信息,可以促进文本单词匹配概率的提升。浅层句法树可以通过简单化的结构将树核函数作用在浅层句法树中,从而获得多样化的词性信息,如词性N-gram 特征。

图2 基于ST 结构的句子表示Fig.2 Sentence representation based on ST structure
由于浅层句法树中可供选择的句法信息并不多,因此本节进行更深层次的句法信息分析。首先将相同短语成分的单词节点、词性节点统筹在相同节点中,随后组织串联多个节点,以此建立短语浅层句法树PST。这些相同节点能直接将文本中的词汇组合成不同的句法成分,并不需要关注句法内部结构。如图3 所示,文本“A man is riding a horse”中的单词节点可以划分为VP(is)、NP(A man)、PP(riding)和NP(a horse)。
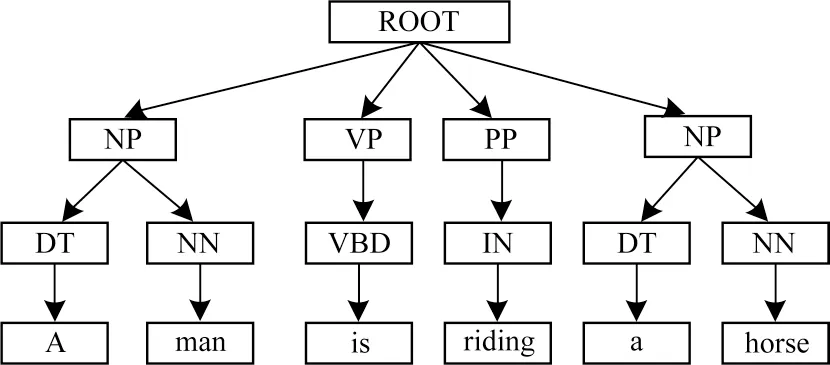
图3 基于PST 结构的句子表示Fig.3 Sentence representation based on PST structure
2.2 文本相似度计算模型
Tree-GRU 模型架构如图4 所示,其相似度计算过程为:首先直接将文本1、文本2 中的单词转换为语义实数向量;然后将文本转换为第2.1 节中的PST结构并进行特征提取,使用对应的Tree-GRU 模型进行计算,获得根节点的隐藏状态hL和hR;最后通过hL和hR进行文本相似度计算,获得相似度计算结果。
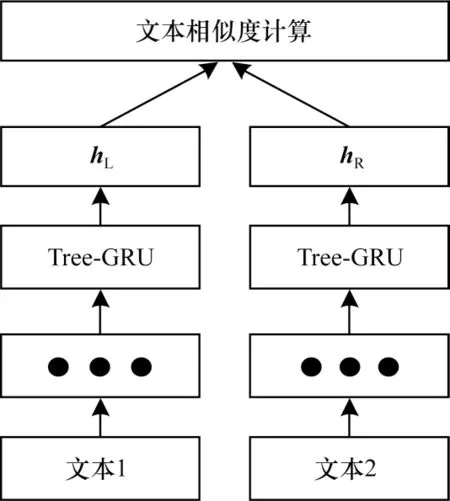
图4 Tree-GRU 模型架构Fig.4 The architecture of Tree-GRU model
在使用PST时,hL和hR分别表示左、右2 个文本转换后Tree-GRU 中根节点o的隐藏状态ho。ho的计算公式如下:
利用神经网络对hL和hR进行计算,可以得到2 个文本的相似度计算得分y∧,具体计算公式如下:
其中:rT=[1,2,3,4,5]。
3 基于多模型加权组合的文本相似度计算
为了更好地强化模型的特征,同时保证最终文本相似度计算的准确性,本节将MMTSC 模型与Tree-GRU 模型进行加权组合,构建一种基于多模型加权组合的文本相似度计算(WMMTSC)模型。WMMTSC 模型的计算结果如式(31)所示:
其中:MMMTSCsim是MMTSC 模型的计算结果;MTree-GRUsim是Tree-GRU 模型的计算结果。
WMMTSC 模型具体实现流程如图5 所示。

图5 WMMTSC 模型架构Fig.5 The architecture of WMMTSC model
4 实验验证
4.1 实验数据
采用STSB、SICK、MRPC 等3 个数据集进行文本相似度对比实验。3 个数据集的详细信息如表1所示。

表1 数据集信息Table 1 Datasets information
4.2 评价指标
选择精确率μprecision、召回率μrecall、F1 值作为模型性能评价指标。其中:μprecision主要面向预测结果,用于分析实际正样本在预测正样本中所占的比例;μrecall主要面向实际样本,用于分析被预测为正的样本在总样本中的占比;F1 值用于综合分析精确率和召回率,判断结果的整体状况,计算中用F1表示。3 个评价指标计算公式分别如下:
其中:NTP是正例预测为正例的个数;NFP是负例预测为正例的个数;NFN是正例预测为负例的个数。
4.3 实验结果分析
4.3.1 不同预训练单词嵌入方法的对比
针对不同的预训练单词嵌入方法进行对比,采用相似性得分z和预先训练单词嵌入时可使用的比例p作为评价指标,实验结果如表2 所示,最优结果加粗标注。从表2 可以看出,集合5 种预训练单词嵌入方法相比其他数量的单词嵌入方法效果更好,将5 种预训练单词嵌入方法结合起来进行处理,在p值提高的同时文本相似度计算结果也得到了提升。在数据集方面:SICK 数据集由于存在较少的多词表达式和惯用词,使得其p值较高;对于STSB 和MRPC数据集,由于MRPC 中数据无法转换为语法树,而STSB 中数据虽然可以转换为语法树,但是生成的语法树结构复杂,从而使得实验结果存在较大的偏差。

表2 不同预训练单词嵌入方法的实验结果Table 2 Experimental results of different pre-trained word embedding methods
4.3.2 加权因子设置
加权因子的设置对于WMMTSC 模型的计算结果有着重要影响。针对不同的加权因子组合进行对比实验,所用的数据源自STSB 数据集部分内容,实验结果如表3 所示。从表3 可以看出:通过调整MMTSC 和Tree-GRU 2 种模型的权重,可以提高组合模型的文本相似度计算准确性;通过组合方式能确保计算结果的精准度,使文本特点更为多样化;当C1=0.6、C2=0.4 时模型性能最佳,因此,将WMMTSC模型权重参数C1和C2分别取值为0.6 和0.4。
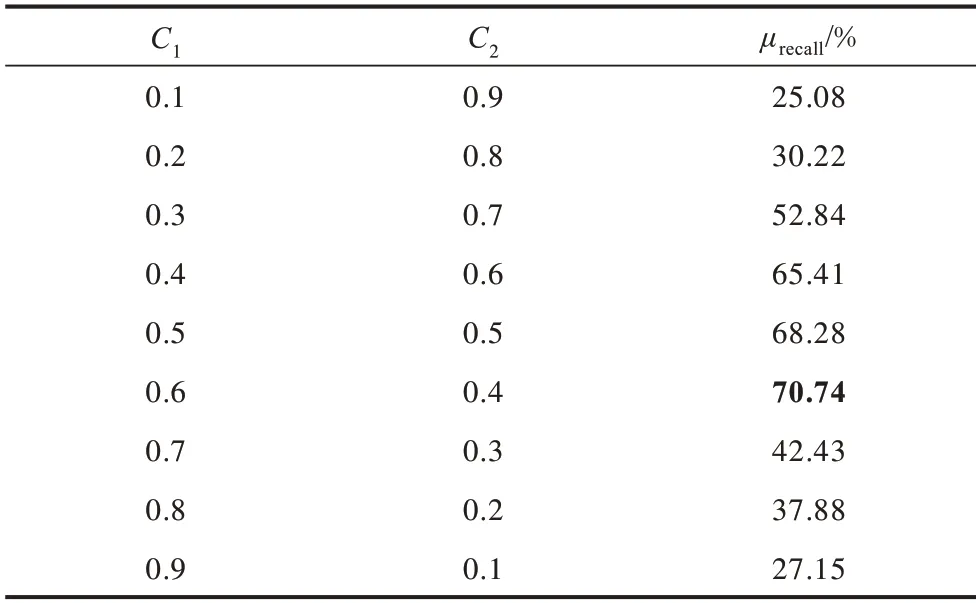
表3 不同C1和C2取值下的实验结果Table 3 Experimental results under different C1 and C2 values
4.3.3 文本相似度实例分析
利用WMMTSC 模型在SICK 数据集上进行文本相似度分析实验,结果如表4 所示。从表4 可以看出:句子对1 的主语有多个表达方式,但是意思一致,因此,相似度达到了6.7;句子对2 和句子对3分别是肯定句和否定句,相似度都保持在较低水平;在句子对4中,名词所在位置有所不同,但是意思相同,WMMTSC 模型能客观判断语义关系,因此,取得了较高的相似度计算结果。通过观察SICK 数据集中的相似度计算结果可知,模型计算结果与实际情况基本吻合,从而验证了WMMTSC模型的准确性。

表4 文本相似度分析结果Table 4 Results of the text similarthity analysis
4.3.4 组合模型对比
为客观判断组合模型WMMTSC 的有效性,选择μprecision、μrecall、F1作为 评价指标,将WMMTSC 模型与MMTSC 模型、Tree-GRU 模型进行对比,实验结果如表5 所示。从表5 可以看出,在3 个数据集上WMMTSC 模型在3 个评价指标上均取得了较高的数值(评价指标数值越高,对应的模型效果越好),这主要是因为WMMTSC 模型结合了MMTSC、Tree-GRU 这2 种模型的优点,能够更有效地实现句法、语义等多种信息的采集和处理。
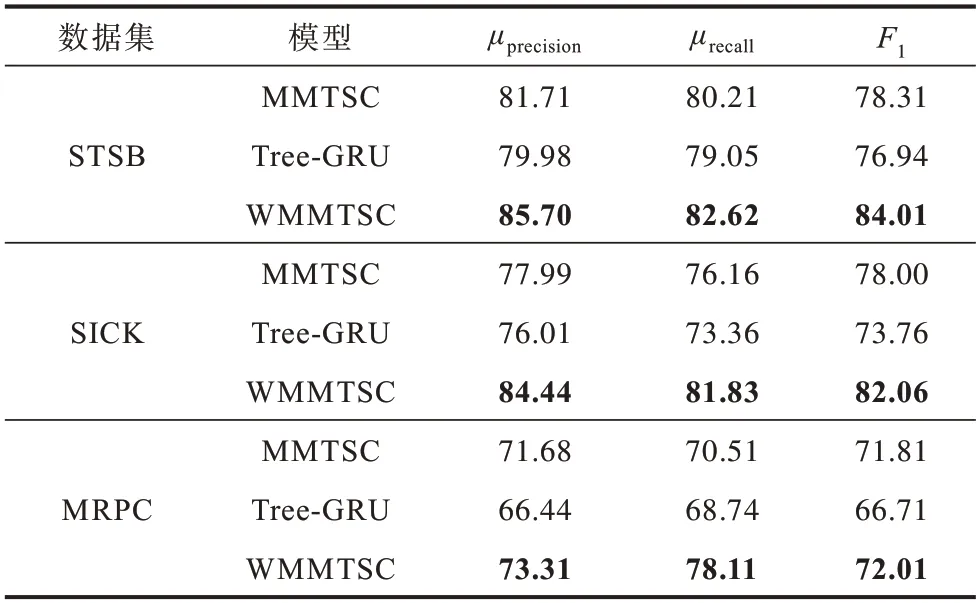
表5 组合模型实验结果对比Table 5 Comparison of experimental results of the combined models %
4.3.5 不同句长下的相似度计算结果
将STSB 数据集中的部分文本按句子长度进行分类,分别统计不同模型的相似度计算性能。当句长在20~90时,文本将保持稀疏化,由此计算得到的结果无法具备代表性。为此,将WMMTSC 模型、M-MaxLSTM-CNN模型[16]、Tree-LSTM模型[17]分别在长度为20~90 的STSB 文本数据上进行对比实验,结果如表6 所示。从表6 可以看出:当文本长度扩增时,3 种模型的计算结果均有所降低,特别是句长从20 增加到40 时尤为显著,但是WMMTSC 模型的实验结果仍优于其他模型;当句长大于40 小于50时,3 种模型的性能又会得到提升;当句长大于50时,M-MaxLSTM-CNN 模型与Tree-LSTM 模型的计算性能基本相同,Tree-LSTM 模型则在句子长度较长时相似度计算性能大幅降低。

表6 不同句长下3 种模型的实验结果Table 6 Experimental results of three models under different sentence lengths
4.3.6 与已有模型的对比
为验证WMMTSC 模型在3 个数据集上的有效性,将DT-TEAM[18]、ECNU[19]、BIT[20]、TF-KLD[21]、NNM[22]、MPCNN[23]、Tree-LSTM[16]、HCTI[24]、S-LSTM[25]、MGNC-CNN[26]、MVCNN[27]、S-MaxCNN[28]、M-MAXCNN[29]、M-MaxLSTM-CNN[17]作为对比模型,分 别在3 个数据集上进行实验,结果如表7 所示。从表7可以看出,WMMTSC 模型在3 个数据集上的文本相似度计算性能相较于其他模型具有明显优势,这主要是因为其他模型通常使用混合手工特征(单词对齐、句法特征、N-gram 重叠)和神经句子表示的集成方法,而WMMTSC 模型一方面使用多个预训练单词嵌入方法,保持更大的词汇嵌入比例,进而提升相似度计算效率,另一方面则通过结构化特征来表示句子级文本的句法、语义等信息,解决了句子级文本相似度计算方法中平面特征表征性弱的问题。

表7 不同模型在3 个数据集上的计算结果Table 7 Computing results of different models on three datasets %
5 结束语
本文提出一种基于多模型加权组合的文本相似度计算模型WMMTSC。该模型首先基于多个预训练单词嵌入和多层次比较来测量语义文本相似关系;然后基于浅层语法树方法和Tree-GRU 模型进行文本相似度计算,解决文本平面特征表征性弱的问题;最后通过对上述2 个相似度计算结果进行加权组合,以得到文本相似度的最终计算结果。实验结果表明,相对于DT-TEAM、ECNU 等模型,WMMTSC 模型的文本相似度计算性能有显著提高,能取得更好的计算分析结果。下一步将利用依存关系树进行文本的结构化处理,并结合多词嵌入方法来完成迁移学习任务。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃科技(2020年20期)2020-04-13
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
火炸药学报(2014年3期)2014-03-20
电力自动化设备(2013年11期)2013-09-18
