
基于伪标签纠正的半监督深度子空间聚类
2023-10-12 04:08鲍兆强王立宏
烟台大学学报(自然科学与工程版) 2023年4期
鲍兆强,王立宏
(烟台大学计算机与控制工程学院,山东 烟台 264005)
深度学习多年来引起众多研究者的重视,因其在很多领域达到了近似人的识别和判断能力,如语音识别[1]、图像分类[2]及自动驾驶[3]等。深度学习被认为是非常有价值的学习方法,其多层网络结构能够通过投影变换逐渐提纯输入数据中的内在特征,最终输出希望的结果。目前深度学习的研究主要集中在分类问题等有监督的学习方面,通常以训练样本的网络实际输出和期望输出之间的差别来判断网络的训练情况,同时以正则化方法来约束模型的复杂程度,避免出现过拟合现象。在聚类等无监督学习方面,深度学习的研究相对较少。最近有研究将深度学习和无监督学习结合起来,在聚类方面得出很好的结果[4-8]。这些研究的主要思想是用深度学习来得到输入数据的高层表示,然后利用现有的算法完成聚类。这些工作的主要区别在于采用了不同的神经网络结构和目标函数。
高维数据的簇结构通常存在于低维的子空间中,子空间聚类是发现高维数据真实结构的有效手段。在子空间聚类中,一个基本假设是子空间的自表达性质,即一个子空间内的点可以由该子空间内的其他点线性表示[9]。子空间聚类的基本思想是获取合适的自表达系数矩阵,以该矩阵构造的相似矩阵进行聚类。如果将深度学习和子空间自表达联合起来求解,就会凭借深度学习得出的高层表示和子空间聚类的自表达性质,有效发现线性子空间或非线性子空间,从而得出比目前浅子空间聚类更好的结果[4-7]。深度学习在高维数据的子空间聚类方面已有一些研究,如自编码(AE,AutoEncoder)结构的神经网络[4],在编码结束时加入自表达层,编码数据输入自表达层,自表达层的输出输入解码层。AE要求网络输出应尽量还原输入数据(即解码功能),二者的误差项是优化的目标项之一。针对该自表达层的数据进行稀疏、低秩等正则化约束就可以达到较好的聚类结果[4,10-11]。PENG等在实验中发现,输出不一定必须还原输入数据,这样就可以只用一个多层前向网络来不断提纯输入数据,在输出层上完成各种正则约束的子空间聚类[12]。
本文拟从子空间聚类和深度学习相结合出发,采用对比学习和伪标签纠正机制,在训练网络时充分利用用户给定或自动获取的少量先验信息,提高聚类的性能,最后在4个测试数据集上验证所提方法的有效性。
1 深度子空间聚类
在缺乏数据点标签的情况下,自监督 (self-supervision)和伪监督(pseudo-supervision)是两种提高聚类性能的可行方法。自监督学习是无监督的一种方式,通常需要预设一个任务,其目标函数不需要监督信息即可计算,自监督学习可获取后续分类等任务需要的高层语义信息。ZHANG等提出了自监督的卷积子空间聚类网络S2ConvSCN[13],在没有标签数据的情况下直接用谱聚类结果作为标签来监督子空间聚类和深度网络的学习。孙浩等提出一种基于自监督对比学习的深度神经网络来提升对抗鲁棒性,最大化训练样本与其无监督对抗样本间的多隐层表征相似性,增强了模型的内在鲁棒性[14]。伪监督学习可以是无监督的[15],也可以是半监督的[16]。文献[16]同时采用少量标签点数据和大量无标签数据训练网络,把无标签点的标签预测结果当作真实的标签使用,在各类之间找到低密度的分隔边界,从而提高泛化性能。LV等提出伪监督的深度子空间聚类PSSC[15],其中没有标签点数据,属于无监督学习。PSSC网络由局部保持模块、自表达模块和伪监督模块组成。模型需要多次迭代训练,在每次迭代中,模型使用上一次迭代的预测来重新标记样本,为此在编码器的后面引入了一个分类模块,该模块利用学习到的潜在表示和相似图来构建伪标签,用来监督特征学习。
在面对实际数据集时,用户或多或少会了解一些数据信息,或者通过少量标记数据获得一些有类标签的数据点。这些先验信息如果能加入到子空间的聚类中,会引导聚类过程得出更精确的聚类结果。李超杰研究了半监督深度聚类算法,包括基于标签自适应策略算法和基于成对预测的半监督深度聚类算法。算法利用标签信息指导簇心优化调整,或者基于已知的成对约束信息对数据集中无标记样本对的关系进行预测,在此基础上完成聚类任务[17]。
2 基于伪标签纠正的半监督深度子空间聚类
2.1 算法描述
2.1.1 算法思想 深度子空间聚类通常采用自编码器AE来完成输入数据的非线性变换和特征抽取,本文也是如此。对AE的训练要求可以是对输入数据的重建误差进行约束[6],也可以是对数据的局部保持误差进行约束[15]。深度子空间聚类通常在AE网络的编码层后面设置自表达层,然后设置解码层,编码结束后通过自表达矩阵来表示数据点之间的相似性。本文提出的算法结构如图1所示。
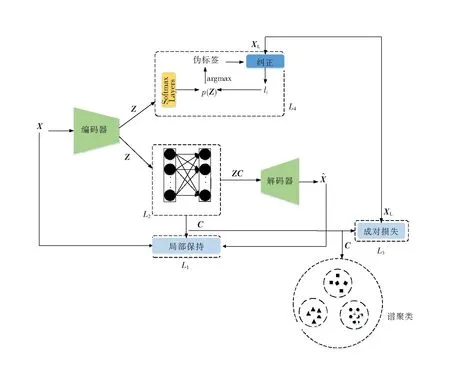
图1 基于伪标签纠正的半监督深度子空间聚类算法(SCPC)
图1显示算法包括4个模块,第一个是局部保持模块,用于约束重建误差L1,同时保持数据点之间的相似性,这个模块和PSSC表达不同,但是目的是相同的;第二个是自表达层的约束,通常对自表达矩阵C进行自表达误差约束L2,这个模块是和PSSC相同的。第三个是本文新增的对比学习模块,该模块利用现有的少量标签数据来控制自表达矩阵C,希望该矩阵能出现块对角的性质,即同一个类中的数据点之间的相似度尽可能高,而不同类的数据点之间的相似度尽可能低,其中的损失约束为L3。最后一个模块是基于伪标签纠正的交叉熵模块,利用给出的少量标签数据来匹配伪标签并纠正伪标签中可能出现的错误,并通过最小化网络分类层softmax给出的概率分布和纠正后的伪标签之间的交叉熵L4,来约束网络的迭代和权重更新,从而得到更准确的网络表达。最后对数据点之间的相似度矩阵W=(|C|+|CT|)/2进行谱聚类得出数据集的聚类结果。
2.1.2 算法步骤 图1所示算法整理如下:

算法 基于伪标签纠正的半监督深度子空间聚类算法 (SCPC) 输入:数据集X 已知样本标签XL 超参数γ1,γ2,γ3和γ4 需要聚类的簇数:K输出:聚类结果G 1. 随机初始化自编码器参数; 2. 预训练自编码器网络; 3. 随机初始化自表达层参数; 4.While 没有达到最大训练次数 5. 利用伪标签纠正策略训练整个网络; 6. 利用Adam优化器优化更新网络参数; 7. End while 8.计算相似度矩阵W=(|C|+|C|T)/2; 9.对相似度矩阵W进行谱聚类,得到聚类结果G。
2.2 模块描述
下面详细介绍每个模块的计算过程,本文用到的符号见表1。

表1 本文所用符号
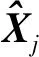
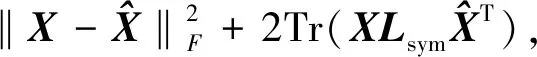
(1)

2.2.2 自表达模块 子空间聚类方法都是利用数据的自表达性质,将每一个数据点由处在同一子空间中的其他数据点的线性组合进行表示,所以在编码器和解码器之间加了一个全连接层,就是所谓的自表达层,如图1所示。其权重表示系数矩阵为C,自表达损失函数为
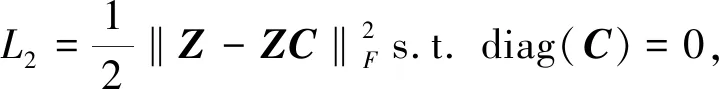
(2)
其中,系数矩阵C表示数据的子空间结构,C中结构块的数量表示簇的数量,因此系数矩阵C对聚类效果至关重要。Cij=0表示样本Xi和Xj不处于同一子空间,为了消除C=I的平凡解,添加了对角线约束diag(C)=0。
2.2.3 对比学习模块 对比学习是近些年来提出的潜在空间学习方法[19-20],通过数据增广获取同一个样本的不同版本,这些版本的潜在空间表达应该是相似的。对比学习以此为约束信息,获取鲁棒的数据表达。卢绍帅等提出了一种用于小样本情感分类任务的弱监督对比学习方法,旨在学习海量带噪声的用户标记数据中的情感语义,同时引入对比学习策略来捕获少量有标注数据的对比模式[21]。根据对比学习的思想,在半监督的背景下,相同标签的样本之间应该是相似的,而不同类标签的样本之间应该有较大差异。本文假定已经获取了少量样本的标签信息,为了充分利用这些先验知识,将这些标签转换为成对约束信息,即must-link和cannot-link,如图2所示。实线连接的点Xi和Xj表示must-link,即样本Xi和Xj具有相同的类标签,聚类结果应处于同一簇内;虚线连接的点表示cannot-link,两个样本点具有不同的类标签,聚类结果一定处于不同簇内。实心点是已标签点,没有连线的点对之间关系未知。

图2 标记样本内的成对信息
利用得到的标签点信息,可得到成对约束矩阵ML和CL,大小均为n×n。如果样本点Xi和Xj具有相同类标签,则Xi和Xj为must-link,即ML(i,j)=1。如果Xi和Xj具有不同的类标签,则Xi和Xj为cannot-link,即CL(i,j)=1。具体公式如下:

(3)
为了使系数矩阵C拥有更好的块对角结构,利用成对约束矩阵给C施加约束,具体损失函数L3为

(4)
其中,γ2和γ3是损失项的系数,⊙为Hadamard积运算符。E=max(0,m-C)为惩罚矩阵,当样本Xi和Xj为must-link时,为了将Xi和Xj聚类到同一个簇,Cij的值应该大一些,如果Cij的值较小,就对当前的Cij进行惩罚,m为惩罚度。同理样本Xi和Xj为cannot-link时,Cij的值应该小一些才能避免将Xi和Xj聚类到同一个簇,因此对Cij的值进行惩罚。成对约束的损失函数L3最小化可以使得C有更好的块对角结构,从而得到更好的聚类效果。
2.2.4 伪标签的纠正模块 分类层softmax的引入,是为了能够获取有益的伪标签来监督网络的训练,从而提高聚类的效果。但是分类层产生的伪标签是不精确的,因此不能够稳定地提高特征表示的质量。为了解决上述问题,本文提出了伪标签纠正算法。利用少许已标记的数据点对分类层产生的不精确伪标签进行纠正,从而进一步稳定提高特征表示的质量。
由于预测出来的伪标签标记规则不同,需要利用Kunhn-Munkres算法[22]把预测标签映射为真实标签。具体来说,将预测出来的每一类标签与每一种真实标签一一对比,形成一个代价矩阵,然后利用Kunhn-Munkres算法计算出代价最低的映射关系,根据映射关系把预测标签映射为真实标签,再利用已知的标签对映射后的伪标签进行纠正。
例如:已知8个样本点的真实标签为B1=(1,1,3,3,2,2,1,1),整个数据集共16个点,假定前8个是已标记的样本点。数据集的预测标签为B2=(2,3,1,1,2,3,2,2,1,1,1,2,3,2,2,3),真实标签的种类为LB1={1,2,3},预测标签的种类LB2={1,2,3}。
利用Kunhn-Munkres求出预测标签与真实标签的映射关系f={1→3,2→1,3→2},即需要把预测标签中的1,2,3分别与真实标签3,1,2匹配,此时预测伪标签B2映射为B2r=(1,2,3,3,1,2,1,1)。很明显,映射后的标签存在两个错误(图3中用下划线标识),利用已知的真实标签B1对B2r中的错误进行纠正,纠正后整个数据集的预测结果为B2t。

图3 伪标签的匹配和纠正
在实现的过程中,在特征提取模块(编码器)的后面添加了一个带有softmax层的全连接层作为一个分类模块,它利用编码器学习到的特征表示Z转换成p(Z),其中p(Zi)∈K表示对Zi预测的分类结果概率分布,K表示簇数。p(Zi)t表示第i个样本属于t簇的概率,表示为

(5)
将伪标签描述为
li=argmax[p(Zi)]k,
(6)
其中[·]k表示预测向量的第k个元素,它对应的预测伪标签的概率为
pi=max[p(Zi)]k。
(7)
在实际中通过设置阈值,筛选出可信度较高的伪标签来帮助网络的训练,为概率pi设置了一个较大的阈值t0,来选择可信度较高的伪标签进行监督:

(8)
对应的损失函数为
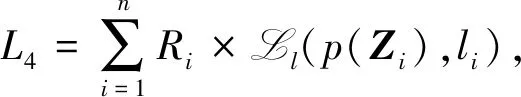
(9)
其中,损失函数Ll是交叉熵函数,li是纠正后的伪标签。
联合四个模块,得到本文总损失函数:
s.t. diag(C)=0,
(10)
其中,γ1,γ2,γ3和γ4为损失项的系数,在网络微调阶段,采用网格搜索这四个系数,找出最优系数组合。
3 实验及结果分析
3.1 数据集及评价指标
为了测试算法的聚类效果,对4个基准数据集进行了实验,分别是ORL和Umist两个人脸数据集、COIL20和COIL40两个物体数据集,数据集的详细情况见表2。
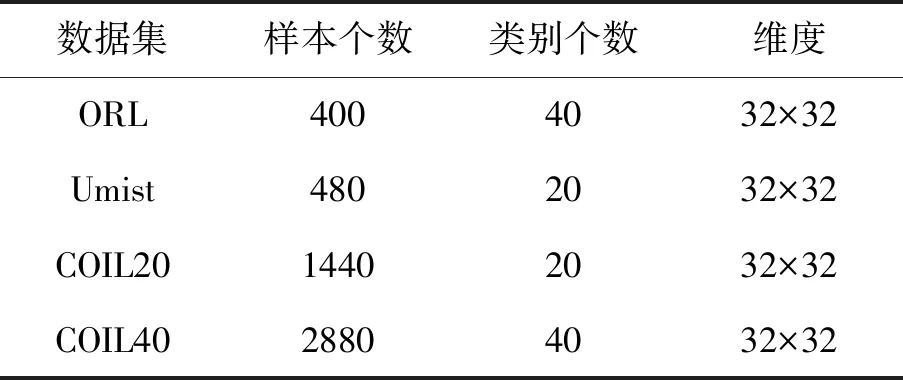
表2 实验数据集详细信息
(1)ORL数据集:该数据集由40个人的面部图像组成,每个人在不同的光照条件下有10个面部图像,在拍摄图像时伴有光线和面部表情和姿势的变化。
(2)Umist数据集:这个数据集由20个人的480张人脸图像组成,每个人的图像数量为24张,每张图像都有姿势的变化,数据集的每个图像像素都调整为32×32。
(3)COIL20和COIL40:COIL20数据集包含20种不同形状物体的1440张灰度图像,而COIL40由40种不同形状物品的2880张32×32像素的灰度图像组成。
本实验采用三个标准指标来评估算法性能,包括准确率ACC(Accuracy)[23]、归一化互信息NMI(Normalized Mutual Information)[24]和纯度 PUR(Purity)[25]。三个指标的值越高,代表聚类效果越好。三个指标的表达式分别为
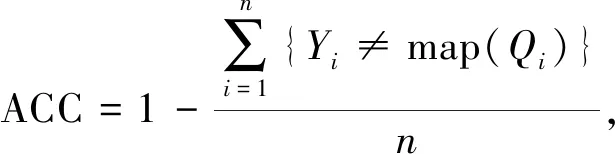
(11)
其中,Yi表示第i个样本的标签,map(Qi)代表第i个样本聚类结果Qi映射的真实标签。
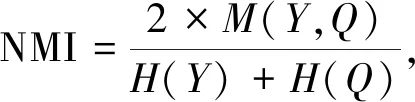
(12)
其中,Y为样本点的真实标签,Q为聚类标签,M计算的是Y和Q之间的互信息,H用来分别计算真实标签和聚类标签的熵。
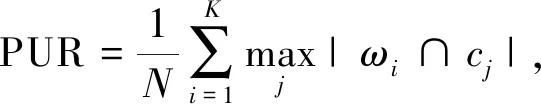
(13)
其中,N是样本数量,ωi表示聚类结果中第i个簇中的所有样本,cj表示真实类别中第j个类别中的真实样本。
3.2 实验方案与结果
将本文方法与一些常见的子空间聚类算法进行对比,包括低秩表示(LRR)[26]、低秩子空间聚类(LRSC)[27]、稀疏子空间聚类(SSC)[28]、具有l1范数的DSC(DSC-L1),具有l2范数的DSC(DSC-L2)[4],深度嵌入聚类(DEC)[29]以及伪监督深度子空间聚类(PSSC)[15]。为了测试伪标签纠正机制和L3模块的影响,通过去掉伪标签纠正和L3模块进行消融实验。
首先,在没有自表达网络层和softmax分类层的情况下预训练自动编码器卷积网络,网络架构信息如表3所示。然后添加自表达网络层和softmax分类层对整个网络进行微调,在训练过程中利用已知标签对生成的伪标签进行纠正来监督网络的训练。预训练阶段设置学习率为1.0×10-3,在微调阶段设为1.0×10-4。为提高预测伪标签的可信度,把阈值t0设置为0.8。使用基于自适应动量的梯度下降法Adam[30]来最小化损失函数。在得到C之后计算相似度矩阵W,完成谱聚类。
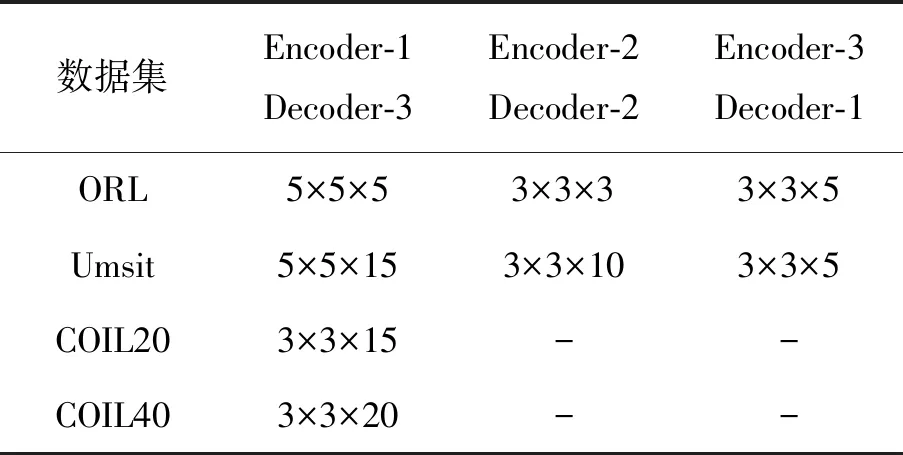
表3 数据集的网络设置
表4记录了本文算法SCPC和对比算法在4个测试数据集上的聚类结果,其中SCPC在4个数据集上的标签点个数为50个。关于标签点比例的讨论见3.3节。如表4所示,SCPC在4种常见的数据集上表现出了良好的聚类效果。与非深度学习模型LRR,LRSC和SSC相比,SCPC在4个数据集上的ACC、NMI和PUR均增加了约10%及以上,这也证明了基于卷积神经网络结构的自编码器能够提取更加良好的特征表示。

表4 不同算法在四个数据集上的聚类结果
相较于DSC-L2,算法SCPC在COIL20数据集上的ACC、NMI和PUR分别增加了3.89%、3.8%和3.6%。与PSSC相比,SCPC在Umist、COIL20和COIL40三个数据集上的聚类表现都更好,这也验证了本文提出的伪标签纠正机制和成对约束信息能够提高子空间聚类的性能。
3.3 消融实验
为了进一步验证伪标签纠正机制和成对约束对子空间聚类效果的影响,通过分别去除对比学习模块和伪标签纠正机制,然后在4个数据集上进行测试,结果如表4中的SCPC1和SCPC2。其中,SCPC1是只去掉对比学习模块时的聚类结果;而SCPC2是只去掉伪标签纠正模块时的聚类结果。通过表4中的消融实验结果可以观察到,仅保留伪标签纠正机制或对比学习模块得到的聚类结果要比SCPC的结果差一些。从实验结果看,伪标签纠正模块对提高聚类性能的作用更明显一些,同时也证实了伪标签纠正机制和对比学习模块的联合作用对提高子空间聚类性能的有效性。
另外,实验记录了不同个数的标签点对聚类结果的影响,假定最多只拥有50个标签点。表5记录了SCPC算法在各数据集的半监督聚类结果。从表5可以看出,在各个数据集上随着标记数据点个数的增加,各项聚类指标均有不同程度的增加,只有一种情况有轻微的下降。因为标签点的随机性,对聚类的影响程度是不确定的,但标签点的介入总体上能提升聚类性能。
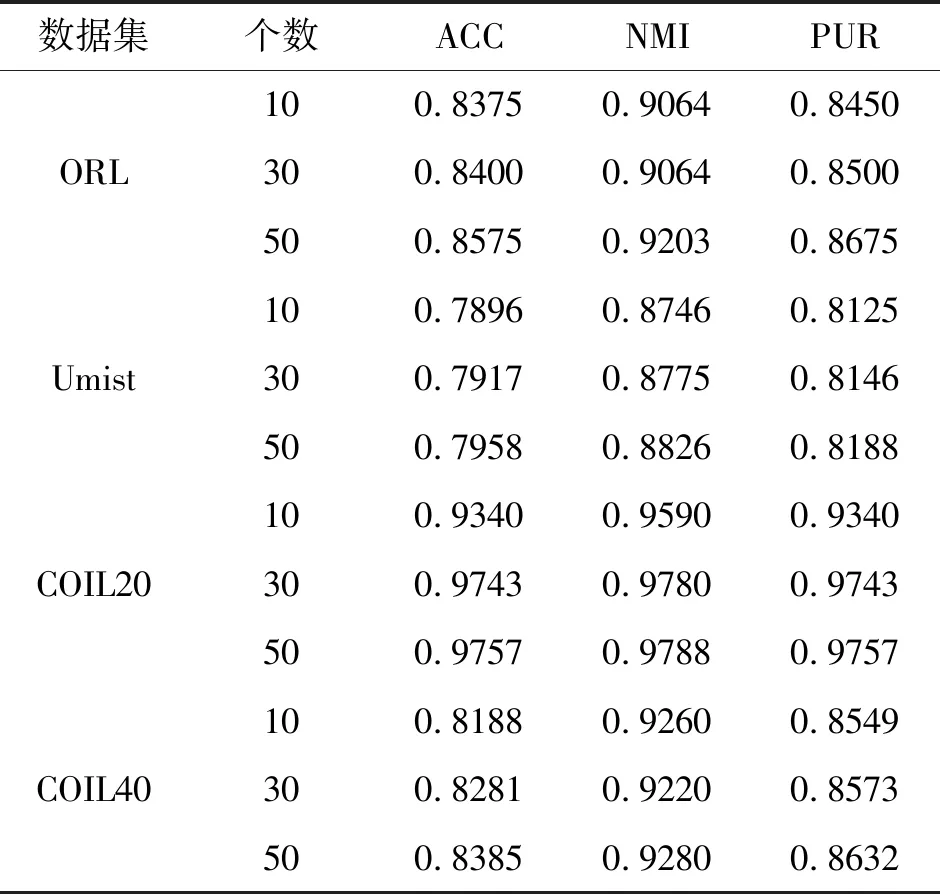
表5 半监督聚类结果
3.4 最优参数搜索
SCPC的损失函数L有γ1、γ2、γ3和γ4四个参数,通过网格搜索法寻找每个数据集上的最优参数。由于三个指标度量聚类性能的角度不同,同时满足三个指标最优的参数很可能是不存在的,因此本文选择聚类准确率ACC这个直观的指标作为最优参数搜索的依据。实验中固定两个参数的值来研究另外两个参数对SCPC的影响。如图4、5所示,SCPC算法对参数γ2、γ3、γ4不敏感,即γ2、γ3、γ4的变化对聚类性能影响不大。当γ1、γ2、γ3、γ4都取104时,在ORL数据集上ACC取得最大值;当γ1=10,γ2=10-4,γ3=10-1、γ4=10-4时,ACC在COIL40数据集上取得最大值。按照相同的方法搜索,得出数据集COIL20和Umist的最优参数,见表6。

表6 参数设置
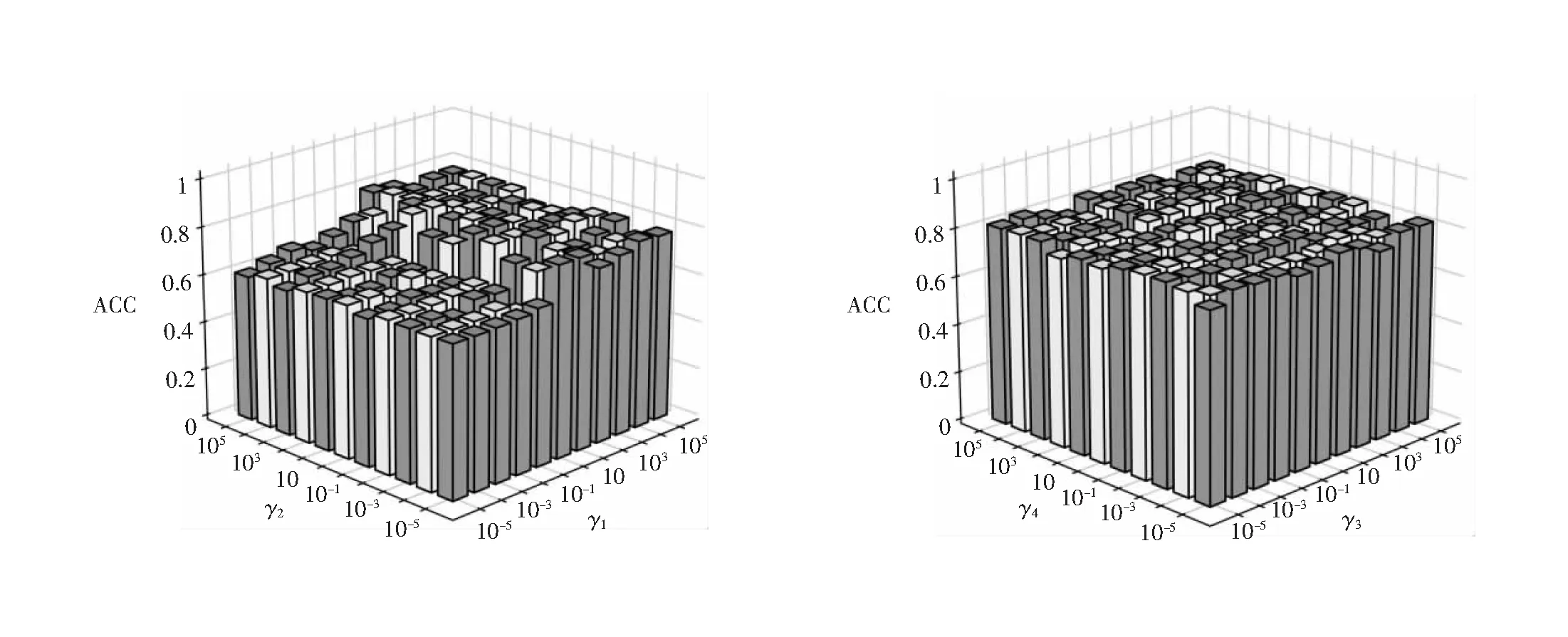
图5 参数对COIL40数据集ACC的影响
为了将满足must-link的点对(i,j)聚到同一个簇中,用惩罚矩阵E=max(0,m-C)对较小的Cij进行惩罚。图6是在γ1、γ2、γ3和γ4设置如表6所示下对m进行的测试。从图6可以看出,m对Umist数据集效果影响不大,故任取m为1,在COIL20和ORL数据集上m设置为5能取得较好的效果,而COIL40数据集在m=7时能取得较好的效果。每个数据集经过自编码器编码后都会得出其潜在的数据表示,这个潜在表示再用自表达矩阵进行重新表示,就得到了自表达系数矩阵C。从这个过程看,C和数据集本身、网络的自编码器,以及自表达过程都是密切相关的。COIL20数据集在不同的m值上ACC取值变化较大,反映出该数据集的自表达矩阵元素取值范围较广,适当的惩罚度m能有效促进聚类结果的改变,这也是深度子空间聚类算法能得出较好结果(如SCPC算法的ACC达到0.975 7)的原因。

图6 惩罚度m对ACC的影响
4 结 论
本文提出的算法SCPC是一种半监督的学习算法,该方法充分利用少量已知样本标签来获得更好的特征表示和相似度矩阵W。一方面基于对比学习的思想,利用这些已知样本标签来获得成对的约束信息,来约束系数矩阵C的块对角结构,从而获得更好的聚类性能;另一方面用这些真实标签来纠正网络分类层产生的伪标签,通过反复训练来监督整个网络的训练,纠正网络权重的值。实验表明,算法SCPC的性能优于或接近先进的子空间聚类算法。同时也证明了利用半监督信息和对比学习方法在提高子空间聚类性能上的可行性和有效性。以后的工作会继续研究用不同方式来嵌入先验信息来提升子空间聚类的性能。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
车迷(2018年11期)2018-08-30
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
海峡姐妹(2018年3期)2018-05-09
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
