
多层次特征和粒子群优化的场景分类
2023-10-12 01:10张立亭罗亦泳杨静雯
计算机工程与设计 2023年9期
张立亭,喻 欣,罗亦泳,杨静雯
(东华理工大学 测绘工程学院,江西 南昌 330013)
0 引 言
遥感图像进行场景分类时,如何精准地提取图像特征以及高效的进行分类,是实现场景分类的重要前提。遥感图像的特征提取,其方法大致分为:图像低层、中层和高层特征。图像的低层特征包括结构、光谱、纹理特征,它们计算不复杂且容易实现,运用广泛。中层特征则是利用某种算法对低层特征进行编码,获得图像的中层特征。视觉词袋模型(BoVW)[1]是该特征中最具代表性的方法。高层特征一般是指卷积神经网络(CNN)模型提取的图像特征,其提供的是一种端到端的学习模型。除了将CNN模型迁移至遥感图像数据集中微调后进行分类,也可将CNN提取的某一全连接层进一步编码。目前大多数研究中,使用支持向量机(SVM)对图像特征进行场景分类,多使用网格搜索算法优化分类器,其耗时长且验证冗余。综合考虑到各层特征中各类算法的性能和效率,以及不同图像特征之间的特点,本文进行多层次特征提取,在分类时则引入结构相对简单、寻优能力较好的粒子群算法(PSO),来优化支持向量机的参数,以提升分类效果。本文利用SIFT提取低层特征,再通过聚集局部描述符编码(VLAD)对SIFT提取的局部特征描述子进行编码得到中层特征,同时使用预训练的VGG-16通过迁移学习的方法来提取图像的高层特征,再将上述提取到的各层特征利用支持向量机(SVM)进行分类,同时采用PSO进行参数寻优,提高遥感图像场景分类的精度。
1 多层次特征
1.1 图像低层特征
在本文中,利用SIFT[2]从每张图像中提取低层特征点。首先利用尺度可变高斯函数和图像卷积生成高斯差分尺度空间;然后在尺度空间中检测极值点,即每一个检测点与同尺度相邻的8个点和上下相邻尺度对应的9个点,共26个点比较。若该检测点在所有点中为最大或最小值,则该点为特征点;随后通过拟合函数来精确确定特征点的位置和尺度;接着通过图像梯度方向为每个关键点分配位置、尺度和方向3个指定方向参数;最后以数学方式来定义关键过程,以实现对关键点的描述。
在本文中,在进行SIFT特征提取时,使用大小为16×16,步长为8像素的滑动窗口,最终每幅图像得到一个128维的图像局部特征。
1.2 图像中层特征
图像场景分类时,有很多方法可以进行图像中层特征的提取。在本文中,图像中层特征是利用VALD算法对SIFT提取的图像局部描述子进行编码。VLAD是一种简化的Fisher Vector,它利用K-means聚类方法代替GMM(高斯混合模型)聚类,充分利用局部特征,计算高效且方便。其具体的步骤[3]如下:
(1)本文局部图像块的特征为128维向量X={x1,x2,…,xN}∈R128×N,N为图像块数。利用K-means聚类生成M类,聚类中心为B={b1,b2,…,bM}。
(2)将每个局部描述子赋给离它最近的聚类中心,然后所有局部描述子与聚类中心的差值做累加,即
(1)
式中:NN(xt) 表示离xt最近的聚类中心。
(3)对差值和vi做L2归一化,拼接成一个K=M×128的一维向量
v=[v1,v2,…,vM]=[v1,v2,…,vK]
(2)
K-means聚类的缺点之一是对码本大小(即M)敏感。在本文中,根据文献[4]选择码本大小进行特征编码。
1.3 图像高层特征
卷积神经网络作为深度学习中最常用的一种网络模型,其提取的图像高层特征,既可用于直接分类,也可以提取出来再继续处理。目前,被广泛使用的CNN模型包括VGGNet系列、GoogLe Net系列、ResNet系列和Alex Net等。由于VGG-16模型具有层数较少,性能较高等优点,本文利用预训练的VGG-16对遥感图像进行高层特征的提取。
Simonyan K等提出VGG-16网络模型:13个卷积层:内核大小为3×3,步长为1×1;5个池化层:内核大小为2×2,步长为1×1;3个全连接层;1个Softmax层。该网络首层卷积通道数为64,随着层数的增加翻倍,最多为512个通道,后不再变化。在卷积层之后是3个全连接层,两个全连接层通道为4096维和一个用于Softmax通道为1000维。文献[5]指出,全连接层所提取特征的分类效果始终优于卷积层提取的特征。前两个全连接层,它们进行分类的结果大致相同,但在大多数情况下,第一个全连接层的特征表现稍好。至于最后一个全连接层,因为它实际上是一个Softmax层,只是通过特定任务计算每个已定义类别的分数,该图层不像以前的图层那样包含太多一般要素信息。因此,本文选择使用VGG-16模型的第一个全连接层提取特征作为全局特征。
2 粒子群算法优化SVM参数
支持向量机是被广泛应用的机器学习方法,其核心思想是寻找一个最优的分类超平面,将待分类的两类样本正确分开,使两类样本点到超平面的间隔尽可能大。它在处理小样本、高维数和非线性等问题上表现良好,并且在解决分类问题上有很大的优势,被广泛应用于分类领域。
核函数选择不同使SVM形成不同的分类器,其常用的核函数类型包括线性核、多项式核、径向基(RBF)核和Sigmoid核函数4类。本文的SVM选择RBF核函数,而核函数的参数选取对分类结果影响很大,影响核函数的参数为惩罚因子和核函数参数。因此,需要选择合适的参数以提升分类效果。针对参数的选择问题,尚未有统一的方法。传统的方法包括交叉验证法、网格搜索法等,但存在耗时长以及冗余的验证流程等问题,使用更多的是群智能算法,如遗传算法、粒子群算法(PSO)和量子粒子群算法等优化SVM参数。考虑到粒子群算法结构简单且寻优能力较好,本文利用PSO算法优化SVM参数,其具体步骤[6]如下:
(1)参数初始化,包括种群规模,粒子的初始位置和速度;
(2)通过K折交叉验证确定每个初始化粒子的适应度值,即交叉验证所得到的分类准确率。
(3)根据式(3)、式(4),来更新粒子的位置和速度
vi=wvi+c1r1(pbesti-xi)+c2r2(gbesti-xi)
(3)
xi=xi+vi
(4)
其中,xi=(x1,x2,…,xn) 为粒子的当前位置;vi=(v1,v2,…,vn) 为粒子速度;pbest为粒子i的个体最优解;gbest为粒子群的全局最优解;c1和c2为学习因子,是常数;r1和r2是0~1的随机数;w为惯性因子。
(4)将每个粒子的当前适应度值与粒子个体极值进行比较,若优于个体极值则替换;再将当前个体极值与全局极值比较,若优于全局极值则替换。
(5)若当前未满足终止条件,则循环执行步骤(3),直至达到终止条件为止。
(6)将优化得到的参数值C和g输出,利用SVM进行分类预测。
3 实验与结果分析
3.1 数据集
目前,已经有很多公开的数据集可用于遥感图像场景分类的性能评估。本文采用RSC11数据集和WHU-RS19数据集进行实验。
RSC11数据集[7]是从谷歌地球中提取的,该数据集覆盖了包括华盛顿、洛杉矶、旧金山、纽约、圣地亚哥、芝加哥和休斯顿在内的多个美国城市的高分辨率遥感图像。使用了红、绿、蓝3个光谱波段,包括密林(denseforest)、草原(grassland)、港口(harbor)、高层建筑(highbuil-dings)、低层建筑(lowbuildings)、立交桥(overpass)、铁路(railway)、住宅区(residentialarea)、道路(roads)、疏林(sparseforest)、储罐(stroagetanks)11个复杂场景类。一些场景类别在视觉上非常相似,这增加了识别场景图像的难度。数据集共包含1232张图像,每类约100张。每张图像的大小为512×512像素,空间分辨率为0.2 m。图1为RSC11数据集中各类图像的示例。

图1 RSC11数据集中各类图像示例
WHU-RS19于2010年发布[8]。经过几次扩展,最终版本由19个类别组成,共1005张图像[9]。空间分辨率高达0.5 m,光谱波段为红、绿、蓝,图像像素为600×600,包括机场(airport)、海滩(beach)、桥梁(bridge)、商业区(commercial)、沙漠(desert)、农田(farmland)、足球场(footballField)、森林(forest)、工业区(industrial)、草地(meadow)、山区(mountain)、公园(park)、停车场(parking)、池塘(pond)、港口(port)、火车站(railwayStation)、住宅区(residential)、河流(river)、高架桥(viaduct)19个场景类别。由于该数据集中的图像提取自世界不同地区,相应的场景图像在规模、方向、分辨率和光照方面都有很大的差异。图2为WHU-RS19数据集中各类图像的示例。

图2 WHU-RS19数据集中各类图像示例
3.2 评价指标
本文采用2个指标来评价遥感图像数据集的场景分类性能:总体分类精度和混淆矩阵。
总体分类精度为
(5)
式中:N为数据集的样本总数;Z为分类正确的样本数。
混淆矩阵是一个更直接的评价指标,允许直接可视化每个类的分类性能。矩阵的每一列代表一个预测类中的实例,每一行代表一个实际分类中的实例,因此矩阵的每一项xij代表的是实际上属于第i种类型的图像,预测为第j种类型的图像占i类别样本的比例。
3.3 实验架构
本文实验的总体流程如图3所示。
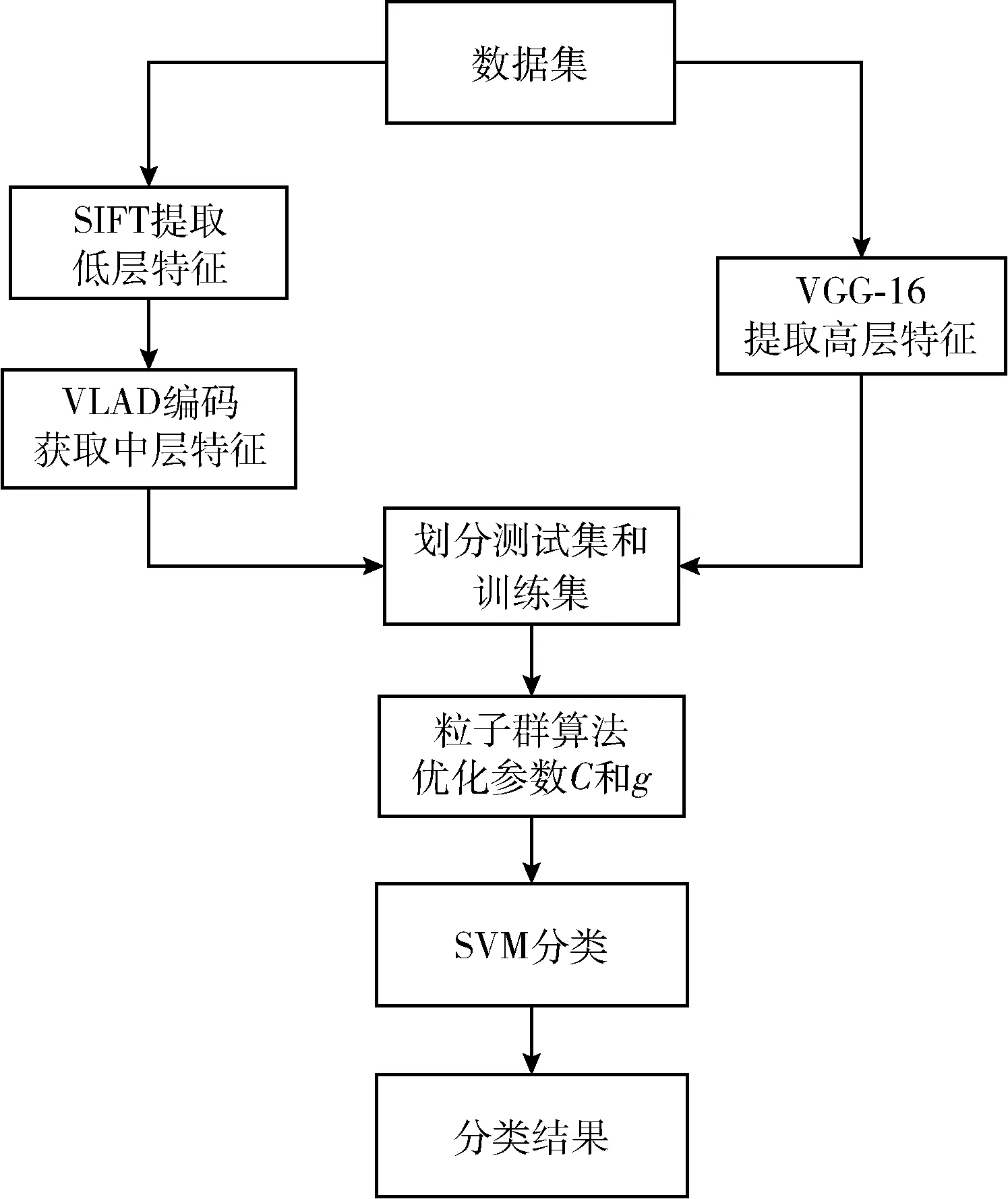
图3 实验总体流程
本文实验内容分为两部分:在实验一中,利用SIFT、VLAD(SIFT)、VGG-16分别提取各层特征作为SVM的输入数据,按训练集占总数据集的比例0.1,0.2,…,0.9, 随机划分训练集和测试集,依次进行分类实验,取10次实验的平均值作为最终的分类准确率。分类时,惩罚因子C设为1,核函数参数g设为1。在实验二中,选取每个数据集中分类准确度最高的方法,采用粒子群优化算法,算法中涉及到交叉验证的过程,K设为5,输出优化参数C和g,获得优化后的分类精度。本文中使用的是由台湾林智仁老师等开发完成的LIBSVM工具箱。
3.4 结果分析
3.4.1 各层特征分类结果分析
各层特征进行分类的结果见表1,在文中的两个数据集上,随着训练集占比越重,分类精度均有所提升,占比达到0.9时,分类效果最佳。利用VGG-16提取的高层特征分类效果最好,其次是利用VLAD编码得到中层特征的分类效果,而利用SIFT提取的低层特征分类效果最差。主要是因为卷积神经网络可以训练得到图像的高层特征,比获得较低层特征的方法相比,具有更好的分类性能,RSC11数据集的分类精度为92.91,WHU-RS19数据集的分类精度为95.89。
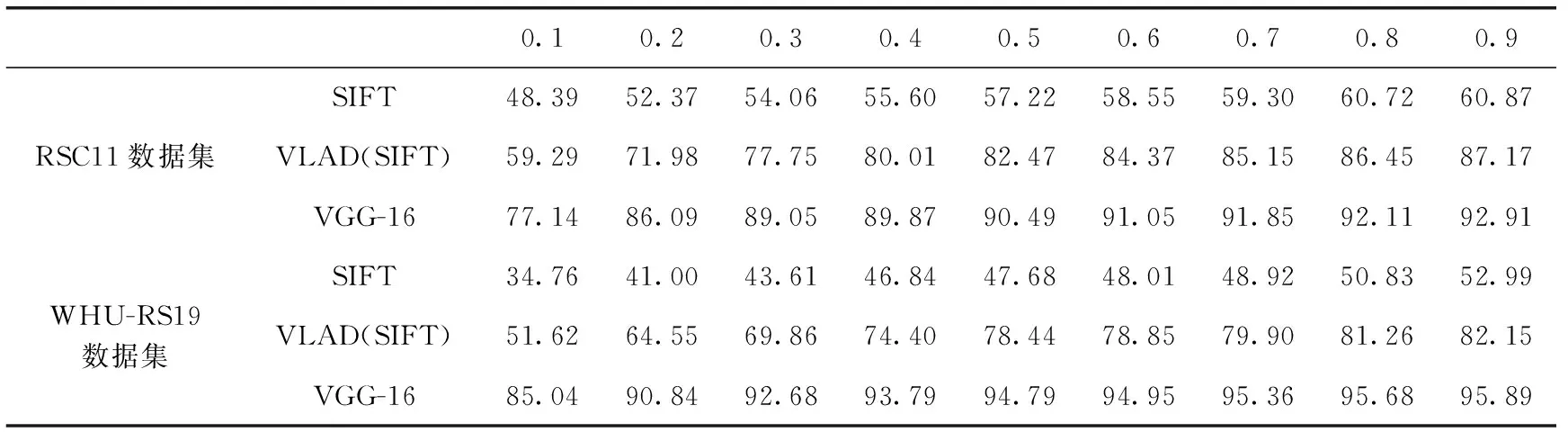
表1 各层特征分类精度
使用本文方法对RSC11和WHU-RS19数据集的分类识别率分别如图4和图5所示(图中每类内的柱状排列顺序依次为0.1~0.9)。各分类的识别率大致呈现低层特征<中层特征<高层特征,且随着训练集的占比增加而提升,也存在少数降低的情况,可能是由于训练集是根据占比随机选取组成所导致的。RSC11的各个类别中,立交桥(overpass)和铁路(railway)的分类效果较差,该类中存在较多的交通设施类,包含的场景类别较为复杂。而WHU-RS19中,森林(forest)和港口(port)的分类效果较差,其受光照、方向等方面的影响,同类的场景图像间差异大,容易错分入其他近似的类别中。综上所述,在不同的场景类别中,纹理差异性小的类别分类精度较高,如农田(farmland)、沙漠(desert)等,而对于包含多种地物的复杂场景分类精度较低,如立交桥(overpass)、建筑物等,特别是同种地物根据覆盖属性划分为不同类别,如高层建筑和低层建筑等。
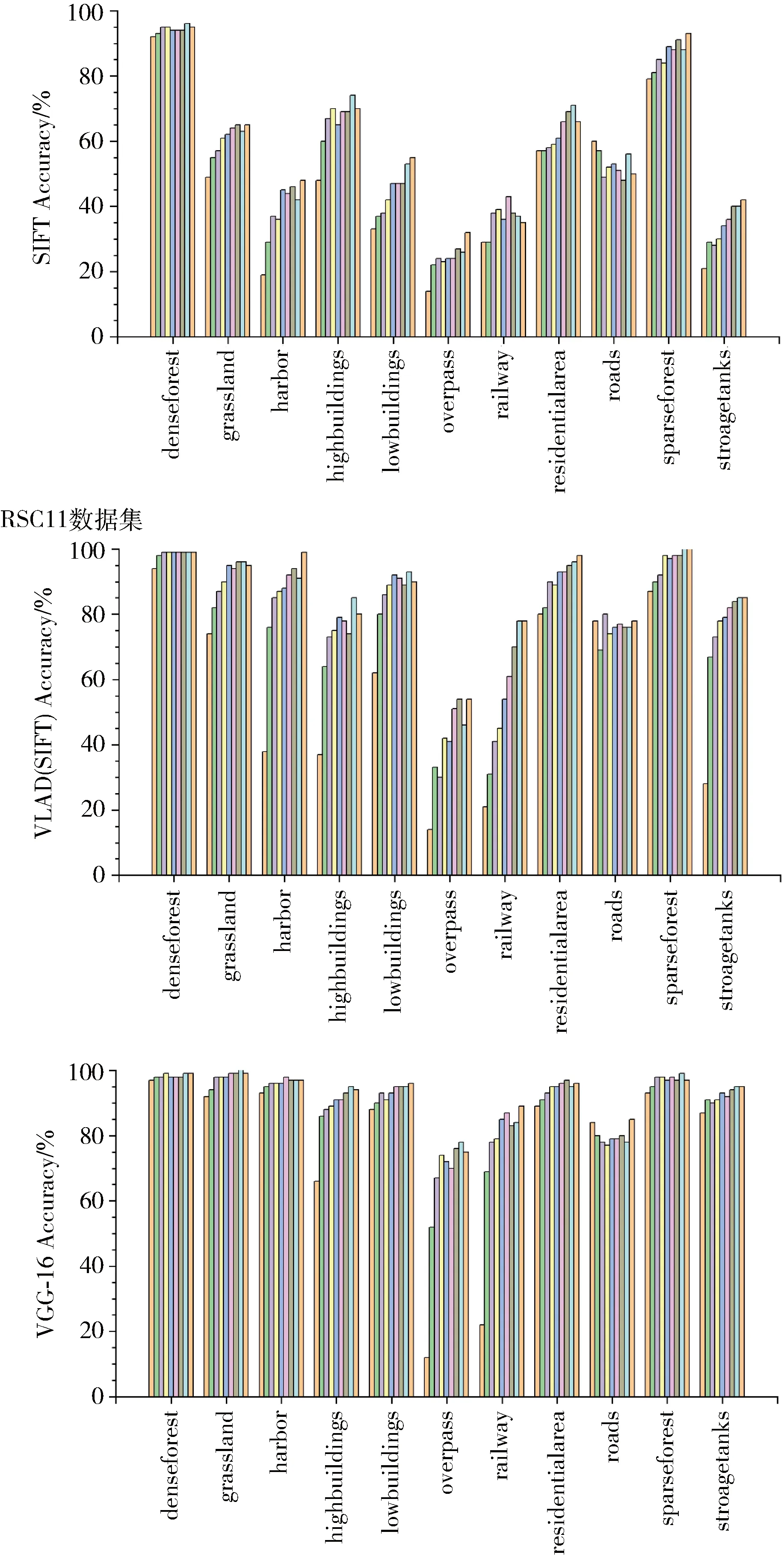
图4 RSC11数据集场景分类准确率
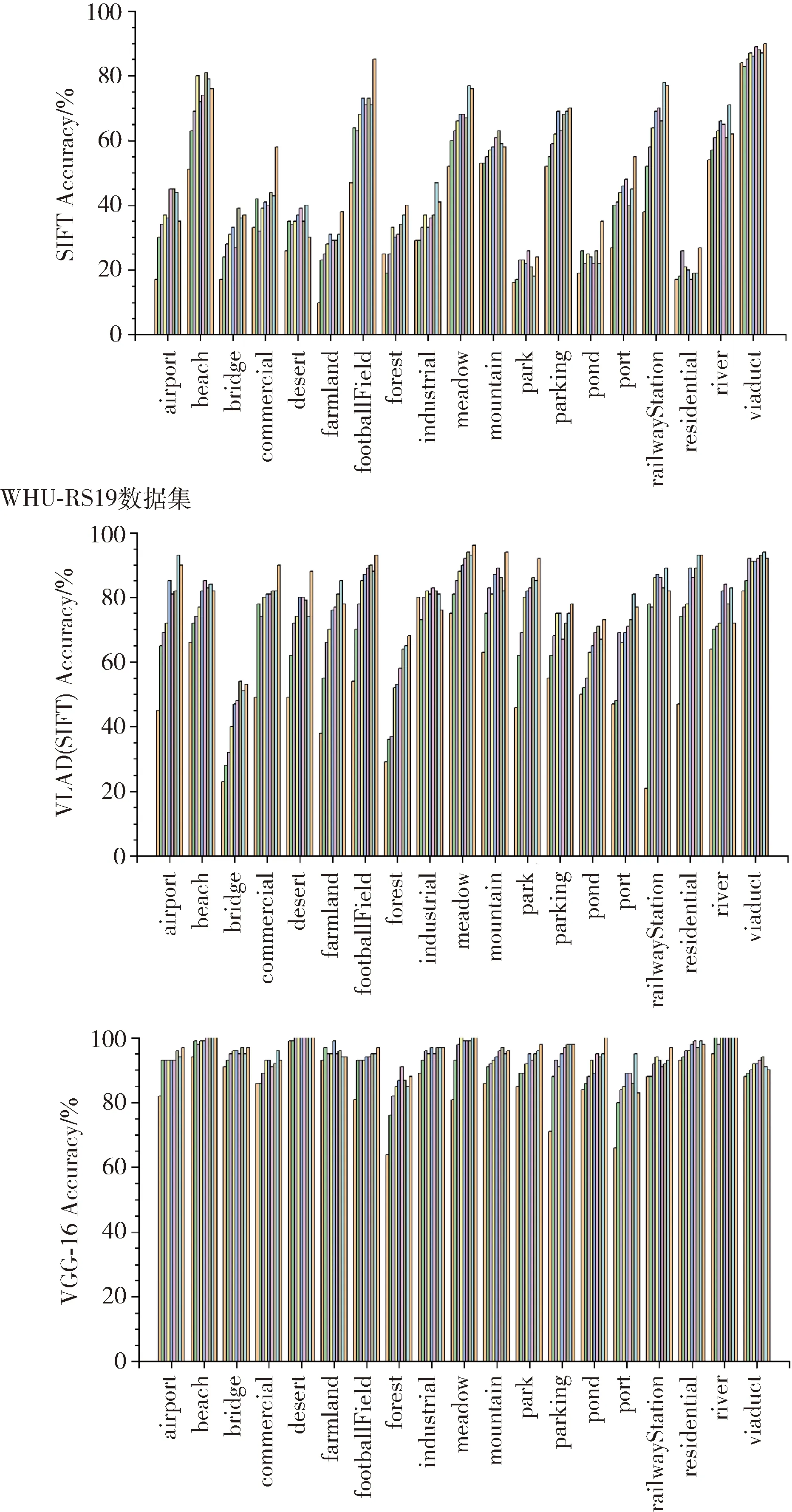
图5 WHU-RS19数据集场景分类准确率
3.4.2 PSO优化SVM的分类结果分析
图6为PSO-SVM算法在RSC11和WHU-RS19数据集上粒子的适应度收敛情况。表2为在本文两个数据集上PSO-SVM算法的表现,表中记录了优化后的参数C和g,训练集交叉验证的平均分类准确率(CV)以及测试集的分类精度。图7、图8为PSO-SVM算法下,测试集的混淆矩阵。
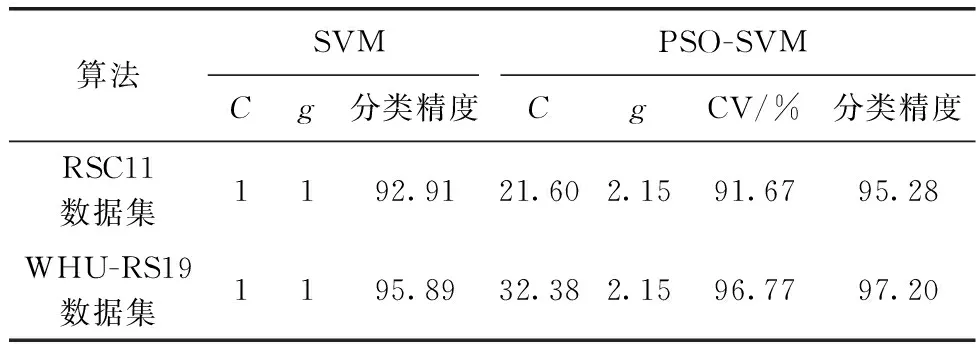
表2 数据集实验结果
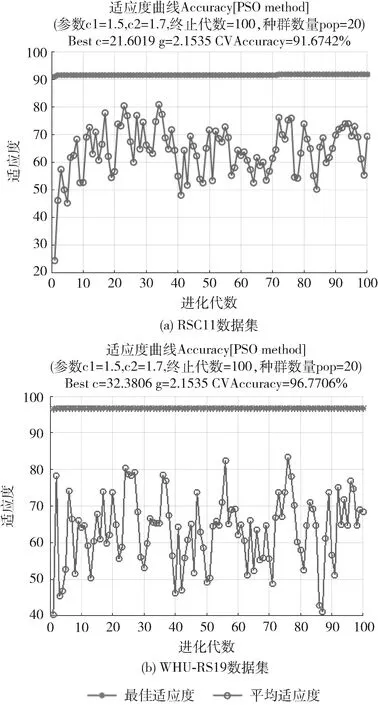
图6 PSO-SVM优化结果
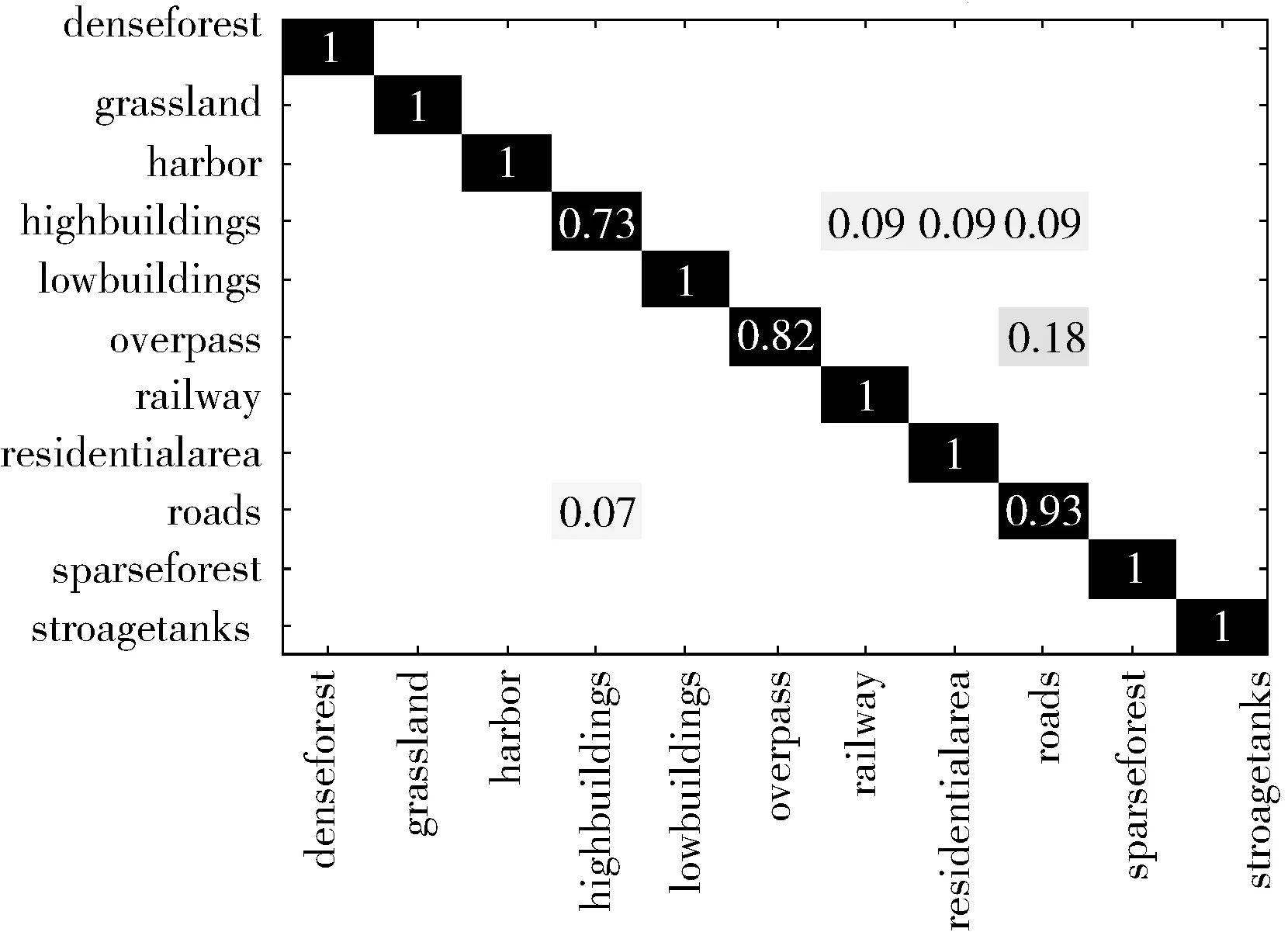
图7 RSC11数据集分类结果混淆矩阵
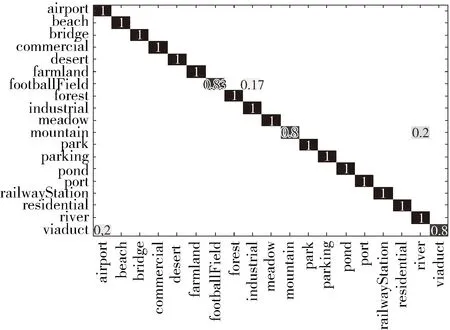
图8 WHU-RS19数据集分类结果混淆矩阵
从表2中可以看出,RSC11数据集只在测试集上的分类效果较好,测试集上的交叉验证分类准确率稍有下降,而WHU-RS19数据集上,PSO-SVM算法在训练集上的交叉验证分类准确率以及测试集上的分类结果均明显优于未进行参数寻优的分类结果。从数据集的分类识别率分析,前者的识别率大部分有所提高,有少部分稍微下降,高层建筑(highbuildings)的识别率最低,其次是立交桥(overpass)、道路(roads),且存在相互错分的情况。高层建筑所包含的地物类别复杂,与其它错分类中均有一定的相似之处,另外两类均属于交通设施类,类间差异小,提取的特征内容受影响较多,对分类效果造成一定影响。后者的识别率大部分都有提高至100%,而足球场(footballField)、山区(mountain)、高架桥(viaduct)的识别率均有所下降,分别错分入工业区(industrial)、河流(river)、机场(airport)中,由于足球场、山区、高架桥这几类图像在某些特征上与其错分的类别比较相似,不易区分。
综上所述,PSO-SVM算法在一定程度上可以提高数据集的分类效果,且在不同的数据集上效果不同。
3.4.3 WHU-RS19数据集不同分类方法分类性能对比
WHU-RS19数据集是最常用的遥感图像场景分类数据集之一,为了验证本文方法的优越性,将本文方法在该数据集上的表现结果与其它文献方法所得结果进行对比,见表3。

表3 WHU-RS19数据集不同分类方法对比
由表2可知,本文方法相比其它的方法,分类结果提升了1%~3.7%左右,从而说明了本文方法的有效性。利用提取的图像特征进行场景分类时,通过PSO优化SVM参数,可以使分类效果更佳。
4 结束语
本文提出了多层次特征提取结合PSO-SVM的图像场景分类算法。利用SIFT算法、VLAD算法以及VGG-16模型分别提取遥感图像的低、中、高层特征,将提取的特征作为SVM的输入数据,按训练集占总数据集的比例0.1,0.2,…,0.9, 随机划分进行实验,得出:在提取的3种特征中,高层特征分类效果最好,中层特征次之,低层特征最差。在参数优化的实验中,选择CNN获得的高层特征,占比则为0.9,利用PSO算法优化SVM的惩罚参数(C)和核函数参数(g),得到各数据集的分类准确率。通过本文两个数据集的分类结果,可以明显看出,该方法比实验一方法的分类结果好,且较以往的方法也有一定的提升。但是,本文所使用的方法也存在一定程度的不足,如提取的特征未实现融合,不同的数据集适用于不同的分类器等。下一步的的工作将针对特征加权融合,和分类器的适用性问题,以更好提升场景分类效果。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
测控技术(2018年10期)2018-11-25
报刊荟萃(上)(2018年3期)2018-04-24
浙江工业大学学报(2017年5期)2018-01-22
数学物理学报(2017年5期)2017-11-23
益寿宝典(2017年34期)2017-02-26
建筑工程技术与设计(2015年12期)2015-10-21
物理与工程(2014年4期)2014-02-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
