
基于LSTM-Z的云平台主机负载预测方法
2023-10-12 01:09谢同磊梁晨君
计算机工程与设计 2023年9期
谢同磊,邓 莉,曹 振,梁晨君,李 超
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.湖北大学 信息建设与管理处,湖北 武汉 430062)
0 引 言
云数据中心按需为用户提供服务,服务器主机规模庞大,资源利用率低、耗电量高。研究表明微软Azure[1]有60%的虚拟机平均CPU利用率低于20%,有40%的虚拟机第95个百分数的最大CPU利用率低于50%;谷歌云平台主机CPU利用率低且呈现出随机的波动[2];低资源利用率主要是由云平台缺乏有效的资源管理造成的。主机负载预测可以促进有效的调度和资源优化配置,关闭不必要的空闲机器,帮助云平台进行有效的资源管理,降低数据中心成本。
在最近的研究工作中,一些深度学习的方法被应用到了主机负载预测。为了提前多步预测主机负载,Song等[3]使用长短期记忆网络LSTM模型进行主机负载预测,并取得比以往统计学方法更好的效果,但是随着隐藏层的增加会出现模型过拟合等问题。文献[4]基于深度循环神经网络编码器-解码器设计了一种主机负载在线预测模型,然而随着模型复杂度的提升,仍然会出现过拟合现象。Nguyen等[5]使用遗传算法和群智能算法代替神经网络中的反向传播过程,由于神经网络模型的大量参数计算,会增大遗传算法的计算复杂性。
云平台资源利用率主要包括内存资源利用率和CPU资源利用率等,主机CPU资源利用率是反映云平台能耗情况的重要指标。本文首先对云平台CPU资源使用情况的特点进行分析,设计并实现了基于Zoneout的长短期记忆网络主机负载预测方法(long short term memory with Zoneout,LSTM-Z)。该预测方法改变LSTM细胞状态的保留机制,使得LSTM门控结构中的隐藏层神经元随机地保持上一个时刻状态的值,进一步提高预测模型的泛化能力。神经元的更新策略会因为主机负载的突变性和随机波动性产生较大的性能扰动,而LSTM-Z基于随机保留和更新的策略表现出更加稳定的性能,泛化性更好,能较好地适应主机负载的波动性特点。在云平台主机的生命周期中,主机负载的不同历史数据对预测值的影响大小各异。为了更好地学习到历史窗口的数据依赖关系,本文基于遗传算法来优化主机负载历史窗口的权重向量,进一步提高模型的预测性能。遗传算法能够更好地收敛且能跳出局部最优,通过迭代进化探索历史窗口的权重向量能够较好学习历史信息,使本文所提的方法能更准确地预测主机负载。
1 相关工作
资源利用率低是云平台面临的主要挑战之一,而主机资源负载预测有助于实施有效的主动资源调度,同时能够满足服务水平协议(service level agreements,SLA)。目前大多数主机负载预测的工作都与机器学习有关,特别是深度学习。主要的相关工作体现在以下几个方面。
基于深度学习模型优化的方法在主机负载预测中的运用。Nguyen等[6]采用基于编码器和解码器的LSTM模型进行主机负载预测,并取得了比以往更好的效果。为了提高LSTM的记忆能力和非线性建模能力,Gupta等[7]提出了一种基于稀疏BLSTM的云数据中心资源使用预测方法。该方法是一种端到端模型,能双向地提取时序特征,不需要额外的特征提取步骤,资源预测的准确性比以往的方法有所提升。文献[8]基于概率预测(probabilistic forecast)和改进的多层长短期记忆网络(LSTM)云资源预测模型(PF-LSTM)进行研究,引入主机网络流量作为预测CPU利用率的额外协变量,使得模型的预测性能优于大部分传统策略方法。为了缓解循环神经网络梯度消失等问题,同时增强神经网络模型学习长期依赖关系的能力,Li等[9]提出了改进的循环神经网络模型(independently recurrent neural network,INDRNN)。此方法通过堆叠多个层来构建比一般RNN更深的深度网络,IDNRNN能够处理非常长的序列,可用于构建非常深的网络,并且可以进行稳定的训练。Billa等[10]探索了将Dropout技术应用到LSTM神经网络的前馈连接中,提高了模型的泛化性能。Zoneout比以前的研究更有优势,其最显著的贡献是不仅激活一个单元,而且保存它,使单元在语义上有意义,Zoneout旨在提高LSTM对隐藏状态扰动的鲁棒性,并使用随机机制强制隐藏层神经单元保持其先前状态的值,使梯度信息和状态信息更容易通过时间传播[11]。
结合遗传算法(genetic algorithm,GA)的神经网络模型研究。Nguyen等[5],使用遗传算法代替功能链接神经网络(functional link neural network,FLNN)的反向传播过程,提出了GA-FLNN对云平台作业实际使用主机资源进行预测,GA能够避免陷入局部最优并克服反向传播算法中收敛速度慢等问题,但此方法训练的神经元的结点较少,无法学习数据中心复杂的数据分布特性。此外,还有研究基于遗传算法优化BP神经网络(back propagation,BP)的连接权重和阈值来预测老人的负性情绪[12]。使用遗传算法取代神经网络中大量神经元参数的计算过程会非常耗时,因为在迭代进化计算的过程中,种群大小以及迭代次数会严重影响训练模型的时间,这影响了主机负载预测的实时性。
由于云平台环境的复杂性和用户作业提交的多变性,主机负载数据存在突变性和非线性等特点,这些方法难以有效捕获主机负载中短期突变的信息和学习历史数据的依赖关系。本文基于Zoneout的LSTM预测模型改变原来记忆细胞状态的更新,提高LSTM对隐藏状态中扰动的鲁棒性,使得梯度信息和状态信息更容易通过时间传播。主机某一时间点的负载情况与其附近的负载具有较大的相关性,离时间点越近,其差距就越小。遗传算法能够较好地收敛且能跳出局部最优,通过迭代进化探索历史窗口的权重向量能够较好地表示历史信息的依赖关系,使得提出的预测方法具有更好的性能。
2 云平台数据分析
目前有已发布的真实云平台资源使用跟踪数据,如谷歌trace[4]以及阿里云trace[13]等。本文以谷歌2011 trace和阿里云2018 trace为例进行分析。谷歌trace中记录了谷歌云平台超过1.2万台主机运行29天里的所有任务日志,其中有超过2500万个任务的资源使用数据,每个作业至少包含一个任务。谷歌trace并没有直接记录主机负载的日志文件,因此需要把一台主机中在同一个时间戳内所有任务的资源使用情况提取为当前时间戳内主机的负载信息。在阿里云trace中,记录了大约4000台主机运行8天的日志信息,其中直接包含了主机的负载数据表。
根据公布的云平台跟踪日志分析,云平台的主机资源利用率不高、负载不均衡,使得云平台维护成本高。图1描述了分别在谷歌trace和阿里云trace随机抽取的100台主机CPU利用率的CDF图。图1表明,云平台中主机CPU资源利用率大部分没有超过60%。其中,在阿里云trace中这些主机的CPU资源利用率集中在30%~50%之间,谷歌trace中这些主机的CPU资源利用率集中在10%~40%之间。云平台这种较低的资源利用率可能是由云平台中用户实际使用资源与云环境为用户预留资源之间的巨大差距造成的[14]。虽然,通过设置阈值机制可以比较容易为云环境资源定义扩展规则,但是与应用程序的多变需求相比,设置阈值机制无法准确地为用户提供资源[5]。
自相关性能够描述时序数据在时间上的依赖,自相关系数可以衡量这种依赖。对于主机负载序列滞后k阶的自相关系数计算如式(1)所示
(1)
式中:mi为第i个时间戳的主机负载值,u为负载的平均值。图2描述了阿里云trace中随机抽取的主机(ID:m_1307)CPU利用率的k阶自相关系数分布。从图2可以发现,主机CPU利用率数据具有局部相关性,一些观测值与附近的一些观测值相关,历史数据离当前值越近,对当前时刻的值影响越大。其中,滞后为1阶和2阶的自相关系数分别为0.9013和0.8403,主机负载数据存在明显的时间自相关性。这可以通过预测模型学习这种时间依赖关系,根据历史负载推测未来的主机负载情况。
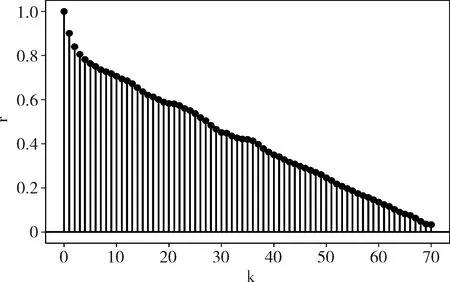
图2 阿里云trace主机CPU利用率自相关系数
图3描述了谷歌trace中随机抽取的主机(ID:4478967491)在某一时间段内CPU的实际使用情况,CPU资源利用率被归一化为0~1之间的数值。从图中可以看出CPU的利用率在一定范围内波动,呈现出非线性的特点,具有一定的突变性。在5月12日0时20分,CPU的利用率在局部范围内达到了最高0.4412;在5月12日16时,CPU的利用率在局部范围内突然降到了最低0.0752。云平台负载较大的波动性以及在短期内的突变性使得现有的预测模型难以准确预测。
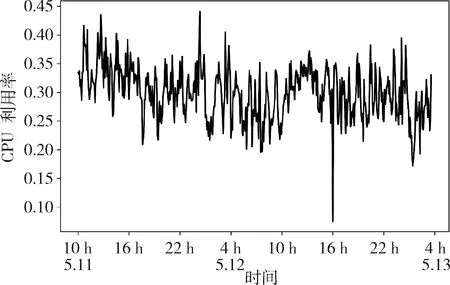
图3 谷歌trace中主机CPU使用情况
3 预测方法
历史数据是预测未来的重要参考信息,基于历史负载的变化情况预测主机未来的资源使用情况是提高其性能和工作效率的有效方法。本文将主机负载时间序列数据划分为固定窗口大小的历史序列数据,每个历史序列数据对应一个预测序列数据,通过训练模型来建立历史与未来的映射关系。假设随机抽取的一台主机历史序列数据为 (m1,m2,…,mn), 则预测模式为:(mi,…,mi+s-1)=f(mi-1,…,mi-k)。 其中,f为映射关系,s为预测步长,k为历史窗口大小。
3.1 主机负载预测方法
针对第2节云平台跟踪数据的资源使用特点,设计了如图4所示的云平台基于LSTM-Z的主机负载预测方法,用于主机CPU负载预测。主要由预处理器、训练器和预测器3个部分组成。通过预处理器对原始跟踪进行数据预处理,谷歌trace中任务资源使用数据被转化为对应时间戳的主机负载数据。原始跟踪数据较大且存在缺失值和异常值。因此,需要进行数据清洗和特征选择等一系列的工作。归一化消除量纲的影响,最后基于滑动窗口方法将数据进行转化,存储到数据库中供模型训练和预测。在训练器模块中,首先初始化滑动窗口权重参数,将时序数据输入到LSTM-Z进行训练,其结果用于计算初次的适应度。然后基于遗传算法进行选择、交叉、变异,计算适应度函数值。重复此过程至达到迭代终止条件时,保存最优的权重参数和模型,供预测器使用。在预测器中,使用训练好的模型和历史的数据对未来的主机负载进行预测。
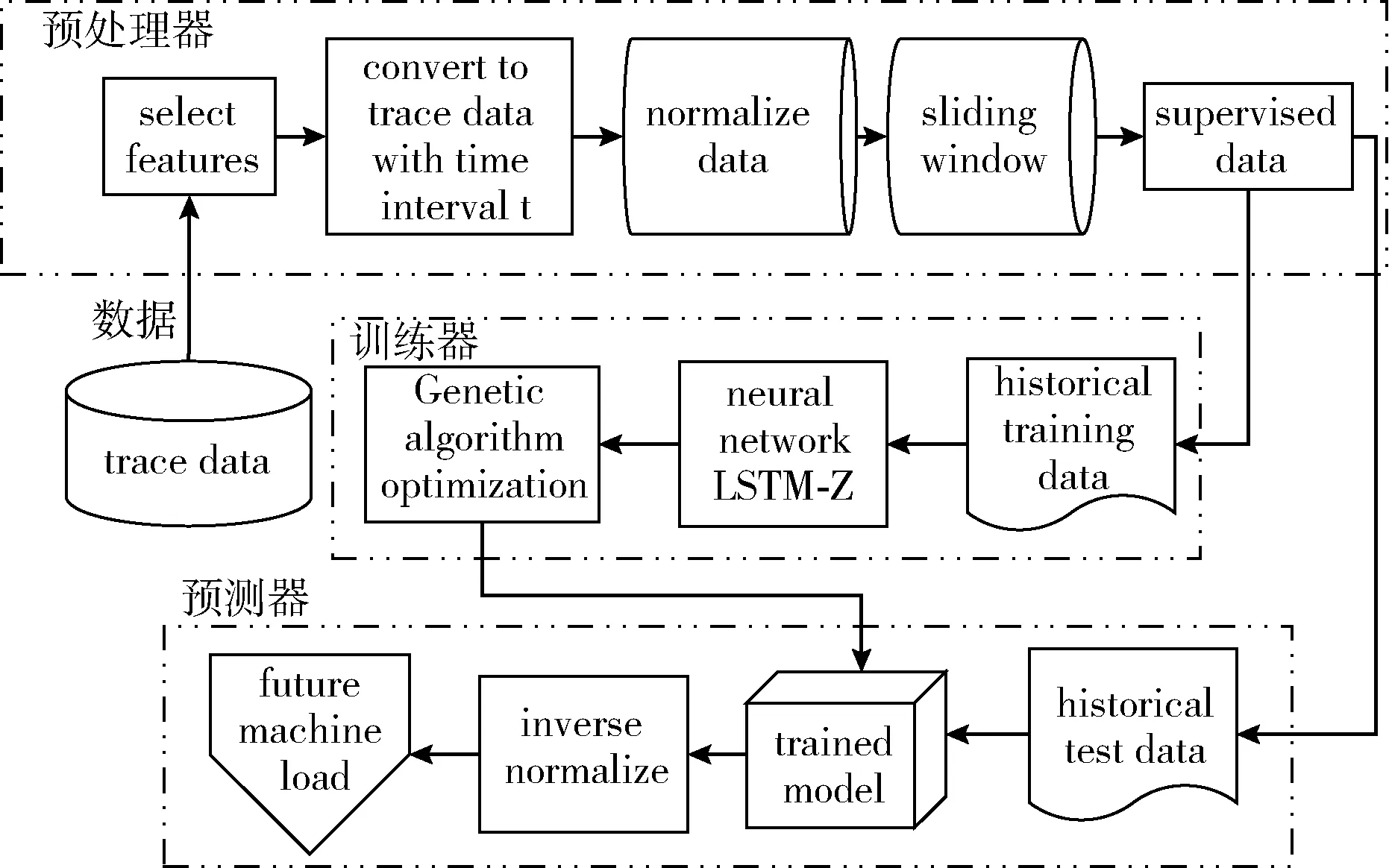
图4 云平台主机负载预测方法LSTM-Z
3.2 基于Zoneout的长短期记忆网络模型LSTM-Z
主机负载数据存在突变性和非线性等特点,这使得传统的预测模型无法达到较好的预测效果。虽然LSTM本身具有良好的非线性建模能力,但应用于主机负载预测建模时,仍然存在模型泛化能力低等问题。机器学习模型过拟合是长期存在的问题,过拟合的本质是模型适应噪声,而不是捕捉数据中存在变化的关键因素,导致模型的泛化能力弱[15]。正则化可以提高神经网络模型的泛化能力。
目前Dropout正则化技术被广泛应用于深度学习模型的训练中,由于时序信息在一定程度的丢失,Dropout的抛弃机制并不能有效提高主机负载的预测性能。一些学者对循环神经网络正则化[11]技术有过研究并取得了不错的效果,文献[16]将Zoneout运用于跨尺度循环神经网络中,从而实现对各个模块的随机更新。Zoneout本质上仍是一种正则化的技术,不像Dropout那样删除隐藏单元,Zoneout旨在提高LSTM对隐藏状态扰动的鲁棒性,并使用随机机制强制一些隐藏层神经单元保持其先前状态的值,使得梯度信息和状态信息更容易通过时间传播。为了提高LSTM模型主机负载预测的泛化能力,本文将Zoneout更新机制集成到LSTM的门控结构中,改变LSTM细胞状态的保留机制,从而实现一种主机负载预测方法。
长短期记忆网络LSTM是一种特殊的循环神经网络,可以缓解逐渐消失的梯度问题,并且能够学习长期依赖关系。LSTM通过门结构来控制信息的传递,分别是遗忘门、输入门、输出门。LSTM-Z通过将某些单元的激活随机替换为它们在上一个时间步的激活,控制LSTM细胞形态和状态特征的下一次输出,其具体每一步的信息传递过程如图5所示,图5中的粗线部分是Zoneout技术引入的新操作,表示相应的状态被对应的掩码所屏蔽。其中ft、it、ot、ct、ht分别表示遗忘门、输入门、输出门、记忆单元、隐藏层的输出值,Wf、Wi、Wg、Wo分别表示遗忘门、输入门、细胞状态、输出门的权重矩阵,bf、bi、bg、bo分别表示相应的偏置,dt表示对应的掩码信息,具体计算步骤如下:
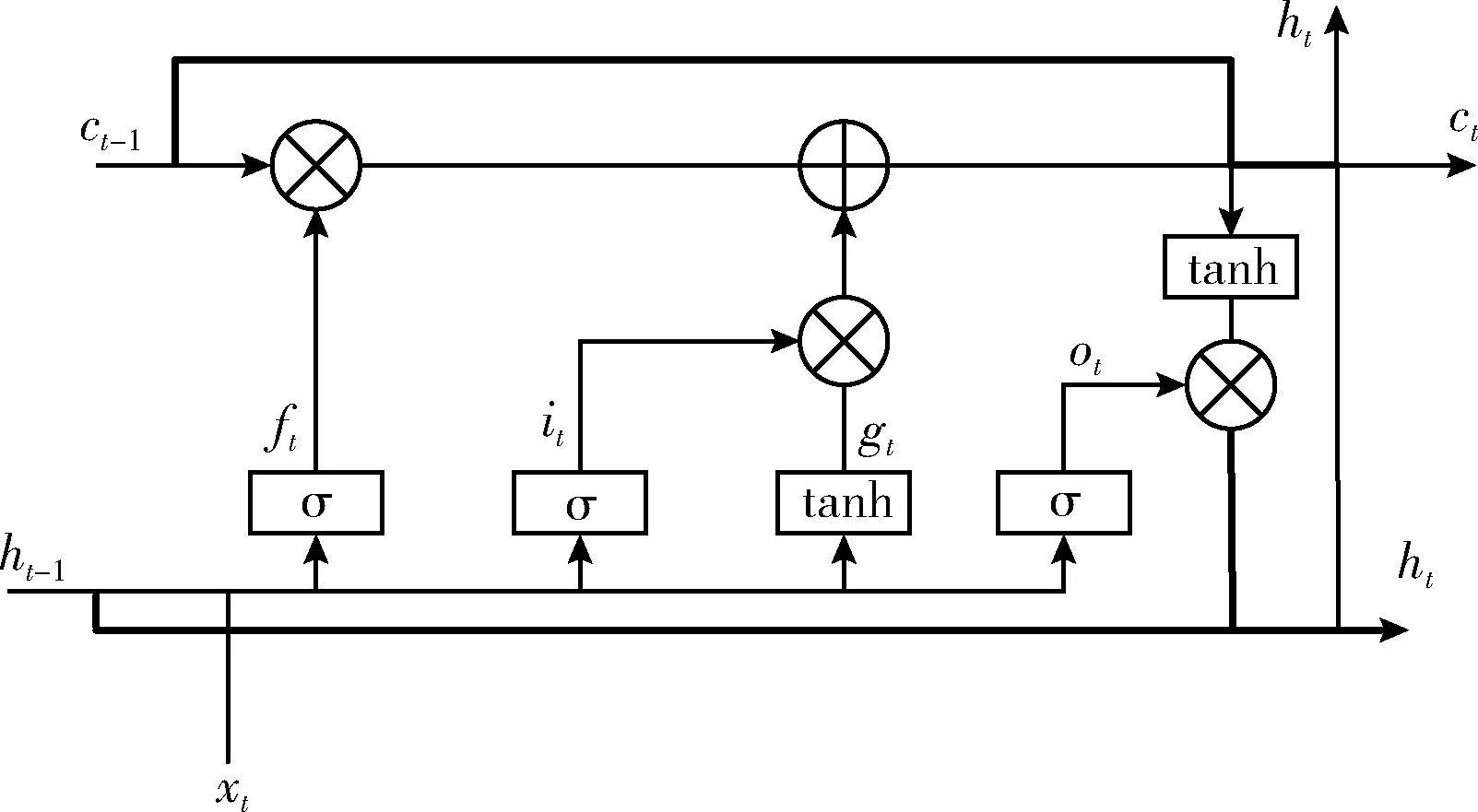
图5 LSTM-Z模型结构
(1)细胞状态通过遗忘门的sigmoid计算单元对重要信息进行保留,选择性丢掉不重要的信息。遗忘门通过查看ht-1和xt的数据信息计算得到一个0到1之间的向量值,向量中的值表示对上一个细胞状态中对应信息的保留程度。具体计算过程如式(2)所示
ft=σ(Wf[ht-1,xt]+bf)
(2)
(2)通过遗忘掉不重要的信息以后,细胞状态通过输入门进行信息更新。将ht-1和xt送进输入门来操作信息的更新,然后利用tanh单元计算ht-1和xt新的候选细胞信息gt,这个过程的计算如式(3)和式(4)所示
it=σ(Wi[ht-1,xt]+bi)
(3)
gt=tanh(Wg[ht-1,xt]+bg)
(4)
(3)通过前两步的计算,在此步更新细胞信息ct-1为ct。在LSTM门控结构中,根据遗忘门的信息ft和输入门更新后的候选信息gt得到新的细胞信息ct。原始LSTM的细胞状态ct计算如式(5)。为提高模型的泛化能力,本文使用Zoneout来计算下一个细胞状态。Zoneout在训练中注入噪声,这样可以使隐藏状态和存储单元随机保持先前的值。细胞状态的计算为式(6)
ct=ft⊗ct-1+it⊗gt
(5)
(6)
(4)更新完细胞状态后,在输出门根据输入的ht-1和xt使用sigmoid单元来判断输出哪些状态特征,然后经过tanh层得到一个输出值向量。原始LSTM在计算隐藏层状态ht时,如式(8)所示。本文基于随机机制强制LSTM中隐藏层神经单元保持其先前状态的值,具体计算隐藏层状态如式(9)所示
ot=σ(Wo[ht-1,xt]+bo)
(7)
ht=ot⊗tanh(ct)
(8)
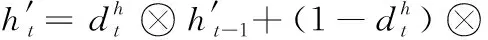
(9)
3.3 基于进化算法优化的主机负载预测
LSTM-Z模型提高了预测性能,在预测主机负载时表现出了较好的效果。主机负载数据的预测值受邻近历史值的影响,不同历史值其影响大小不同。不同历史值以及预测长度的变化对模型都产生了一定的影响,于是本文基于遗传算法对未来主机负载的LSTM-Z预测做进一步优化。
遗传算法是一种典型的进化算法。其本质是一种高效、并行、全局搜索的方法,引入种群、父代、子代、染色体等基本概念,能够在搜索的过程中自动获取有关搜索空间的知识,并通过不断的进化,探索一种最优的解[12]。遗传算法能够较好地处理时序数据的历史窗口权重信息,这样能更好地发挥模型对于云平台具有多变性和波动性数据的预测。
遗传算法的基本步骤包括编码、初始化种群、选择、交叉、变异从而不断产生新的子代进行求解。编码是将主机负载历史信息权重的表现型结构数据转换为遗传空间的基因型结构数据。交叉和变异都是在个体间的基因段上进行的。此外,适应度函数和终止条件也是算法中两个比较重要的概念。适应度函数关系到最优解的确定,而终止条件一般为最大迭代次数或达到解的条件。由于GA选择个体是根据适应度函数来评估。平均绝对百分比误差能够描述预测性能的差异,因此基于式(10),根据式(11)计算适应度的评估值。其中oi和yi分别是预测值与真实值,n为预测样本数,F为适应度函数
(10)
(11)
主要操作算子的计算过程如下:
(1)初始化:遗传算法需要解决的是预测优化问题,由于不同历史值对预测值的影响不同,需要调整历史值的权重输入。在初始化时,先随机初始化满足式(12)的多个个体,并在此基础上进行遗传迭代。假设每代种群有n个个体。每个权重表示占整个历史信息输入的比例,历史值的输入调整主要包括权重的组合和改变。因此,本文初始化种群,将窗口的参数扁平化为一个一维向量,并进行组编码。图6描述了任意一个个体染色体的编码结构,染色体由多组基因片段组成。一个个体有唯一的一条染色体 (w1,w2,…,wk), 表示一种最优解的可能,其基因序列w表示一个权值所对应的基因片段,g表示相应的基因编码。其中每个个体基因序列的表现型满足

图6 个体染色体的编码方式
(12)
(2)选择:根据适应度对个体进行评价,采用轮盘赌算法选择出优良的个体,每个个体被选择的概率与其适应度成正比。这是模拟生物自然选择的过程,如式(13)所示,其中qi为每个个体被选择的概率,适应度大则表示个体较优,更容易遗传给后代
(13)
(3)交叉:交叉是遗传算法的重要操作,是从两个父代产生后代从而把更多有益的信息遗传给后代的过程。交叉算子是基于交叉率进行的,对于两个父代,随机交换两个父代的一个基因片段。由于交换基因片段后可能不再满足式(12),因此需要对个体基因进行调整。对于小于1的个体随机选取一个基因段的表现型加上其差值,对于大于1的个体随机选取一个或多个基因段的表现型减去其差值或上限值,直到满足式(12)。这样能够在进行基因组合和调整的过程中保留父代较多的优良基因片段。在式(14)中,C表示交叉调整操作,交叉率为c,c∈[0,1], 当随机概率小于c时,个体才进行交叉操作。x为第d代的pi和pj交叉后的个体
x(d)=C(pi(d),pj(d))
(14)
(4)变异:变异是遗传算法的辅助性操作,可以丰富子代以增加新的信息、扩大搜索空间避免陷入局部最优。在满足式(12)的前提下,在丰富子代的同时使父代的基因片段产生较少的改变,变异操作随机选择一个交叉后个体的两个基因片段,并交换两个基因片段的位置。在式(15)中,M表示变异操作函数,变异率为m,m∈[0,1]。 算法过程每次产生一个概率数,如果随机概率数小于变异率,个体则进行变异,否则不进行。p是变异后的个体,用于计算下一代的适应度
p(d+1)=M(x(d))
(15)
4 实验与结果分析
为了评估本文的方法,使用第2节中分析的谷歌trace和阿里云trace进行实验。对于谷歌trace,按照第3节中数据预处理器的方法预处理数据,提取一个月前20天的数据作为训练集,第21天到26天的数据做验证集,第27天到最后的数据做测试集。对于阿里云trace,提取第1天到第6天的数据作为训练集,第7天的数据作为验证集,第8天的数据作为测试集。本文先使用LSTM-Z预测方法对主机负载预测做了相关实验,将LSTM-Z与LSTM[3]、INDRNN[9]以及文献中的BC-LSTM[17]进行对比实验。使用4.1节所述3个指标客观评估本文的方法,得出实验结果并进行对比,最后基于遗传算法做了进一步的优化实验。实验部分本文采用了Keras2.1.5,Tensorflow1.15.0深度学习框架,使用Python3.7进行编程,IDE集成开发环境为PyCharm。硬件环境为6核CPU(Core i5-10400F @ 2.90 GHz),内存容量为16 G(威刚DDR4 2666 MHz)和Nvidia GeForce GTX 1050Ti(4 GB)。
4.1 评价指标
为了客观评价实验结果,本文使用回归任务评估指标均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)评估实验方法的性能。RMSE的主要目标是衡量预测值与真实值之间的偏差,受异常值影响大,经常作为机器学习预测结果的评价标准,其计算过程如式(16)所示,其中,oi表示预测值,yi表示真实值,n为预测值数量。MAE具有较好的鲁棒性,其计算原理如式(17)所示。MAPE跟MAE很相似,不同之处在于误差还要与真实值做比较,能较为准确展现出预测值与真实值的相对误差,其计算过程如式(10)所示
(16)
(17)
4.2 单步主机负载预测
云平台主机负载的准确预测对于提高资源利用率,降低数据中心成本和确保作业调度至关重要。主机负载预测首先要做的工作是短期预测,能较为准确地预测主机未来一步5分钟的CPU平均负载具有非常重要的意义,因为主机CPU的平均负载水平是衡量云平台主机集群能耗的一个非常重要的指标。在主机负载预测实验中,通过控制变量观察模型的收敛程度、误差值和运行时间,分别确定出重要的超参数epochs=50,batch_size=130,hidden_size=128,LSTM-Z的方法中单独设置了zone_out_c=0.8,zone_out_h=0.01,使用Adam做为优化器。实验初步探索了滑动窗口的长度,一方面要考虑主机负载数据的时间相关性,另一方面也要考虑运行性能。由于负载数据具有的波动性和周期性,滑动窗口的大小对不同数据集预测结果也有影响。结合多次实验综合考虑后,对这部分实验的滑动窗口大小设置为30。
从图7可以看出,LSTM-Z在训练集和验证集上的收敛效果明显优于其它对比方法且表现出更加稳定的性能,这主要是因为LSTM-Z在进行正则化机制时并没有完全删除隐藏单元,随机地使一些隐藏层神经单元保持其先前状态的值,提高LSTM对隐藏状态中扰动的鲁棒性,更好地适应主机负载这种具有较大波动性特点的预测。由表1可知,在多个对比实验中LSTM-Z模型取得了最好的预测效果;与LSTM模型相比,在谷歌trace中MAE、MAPE和RMSE分别降低了8.31%、17.47%和4.51%,在阿里云trace中MAE、MAPE和RMSE分别降低了8.01%、5.24%和8.73%。
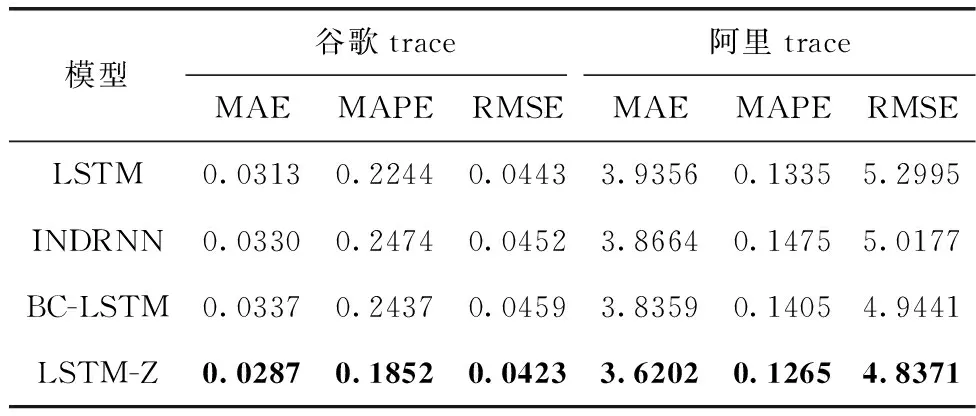
表1 测试集上实验指标的比较
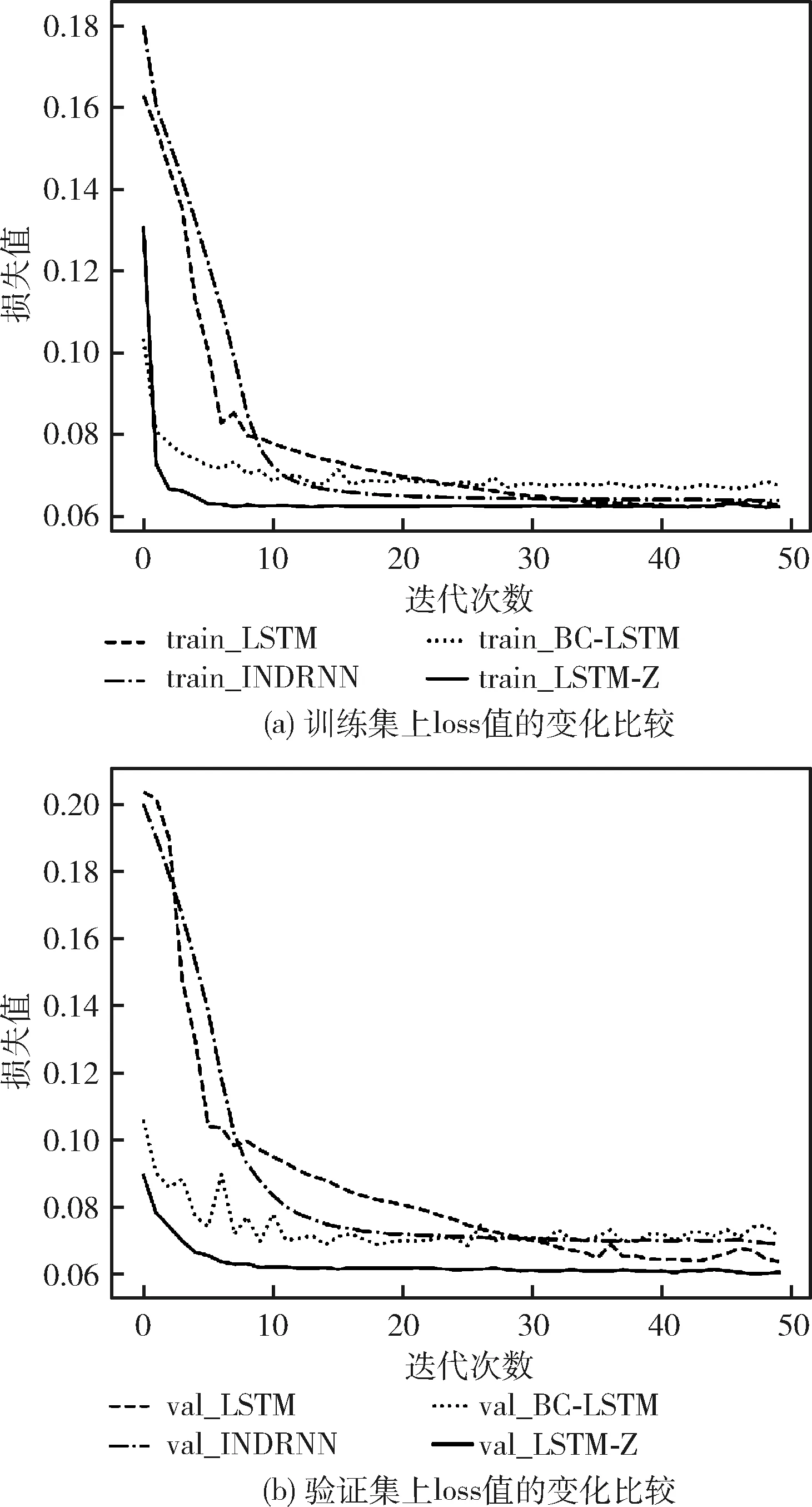
图7 谷歌trace实验中loss值的变化情况
在云平台短期主机负载预测中,预测算法所需时间也是评估模型性能的一个重要指标,在线训练和预测要求能对未来的主机负载变化做出及时的响应,算法所消耗的时间会影响云平台资源的调度。结合表1和表2可以看出,基于LSTM和INDRNN的预测模型虽然耗时比较短,但是预测精度相对来说并不高。基于BC-LSTM的主机负载预测方法对之前的工作进行了进一步的改善,但在不同负载数据中表现出性能的不稳定性,同时也增加了时间的消耗。改进门控的LSTM-Z模型显得更加轻量级并且预测误差更小,预测时间较短,具有更好的适用性。
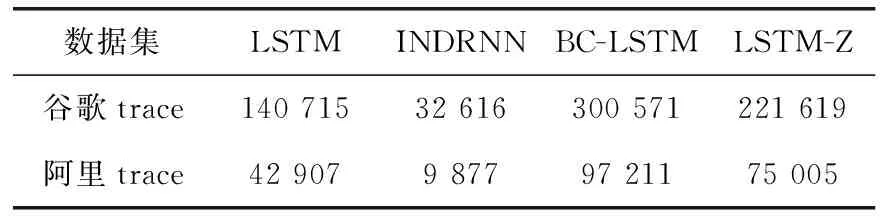
表2 算法执行时间对比/ms
4.3 多步主机负载预测
为了验证本文方法在多步预测的有效性,分别进行了时间步长为3和6的实验,即预测未来15分钟和30分钟的主机负载变化情况。从图8两个数据集的实验结果可以看出,随着预测时间步的增长,实验中预测模型的预测误差都在逐渐增大,但是LSTM-Z的预测性能均优于前三者对比的模型。这是因为预测未来更长的时间,云平台的不确定性因素更大,使得主机负载变化模式更加难以被学习。
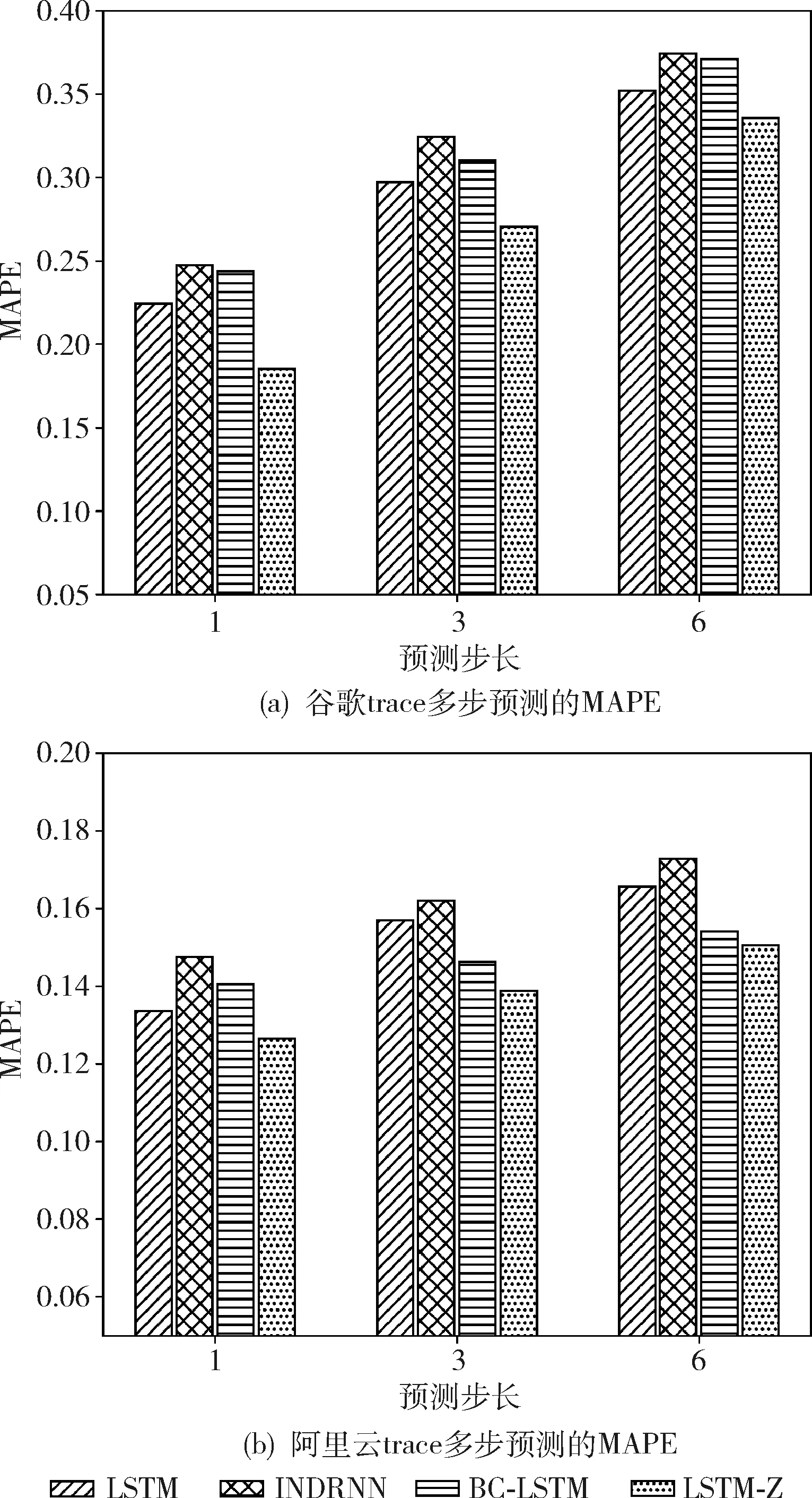
图8 云平台多步预测的MAPE对比
LSTM-Z使用随机机制强制一些隐藏单元保持其先前状态的值,提高了对隐藏状态扰动的鲁棒性和增强了模型的泛化能力。在谷歌trace的多步预测实验中,与LSTM、INDRNN和BC-LSTM相比,预测未来3步时,MAPE分别降低了8.95%、16.56%、12.83%,预测未来6步时,MAPE分别降低了4.72%、10.42%、9.64%。在阿里云trace的多步预测实验中,与LSTM、INDRNN和BC-LSTM相比,预测未来3步时,MAPE分别降低了11.66%、14.38%、5.13%,预测未来6步时,MAPE分别降低了9.06%、12.80%、2.33%。
4.4 基于进化算法优化的预测实验
在实验中,历史窗口的大小对预测结果产生了一定的影响,主机负载数据的预测值受邻近历史值的影响,不同历史值其影响大小不同。本文基于历史窗口使用遗传算法对模型做了进一步优化以达到较好的预测性能。在进一步改进的模型方法中,本文在单步预测的基础上做了进一步实验。在实验中,设置种群大小为48,交叉率为0.5,变异率为0.05。在阿里云trace的预测实验中MAPE为0.1221,在LSTM-Z实验模型(MAPE=0.1265)和LSTM实验模型(MAPE=0.1335)的基础上,MAPE降低了3.48%和8.54%;在谷歌trace的预测实验中MAPE为0.1798,在LSTM-Z实验模型(MAPE=0.1852)和LSTM实验模型(MAPE=0.2244)的基础上,MAPE降低了2.92%和19.88%。在实验结果的前200个时间戳中,真实值与预测值随着时间的变化如图9所示,其中横坐标表示观测的时间戳,纵坐标表示该时间戳下主机CPU的利用率。从图中可以看出,不管是CPU利用率序列的波峰还是波谷的预测情况,本文方法都能都能保持较优的预测性能,预测值曲线与真实值曲线都能较好的匹配。与本文方法相比,基于LSTM的预测在CPU负载序列波动性更大的点上存在较大的偏差,特别是对峰值的预测效果稍差。
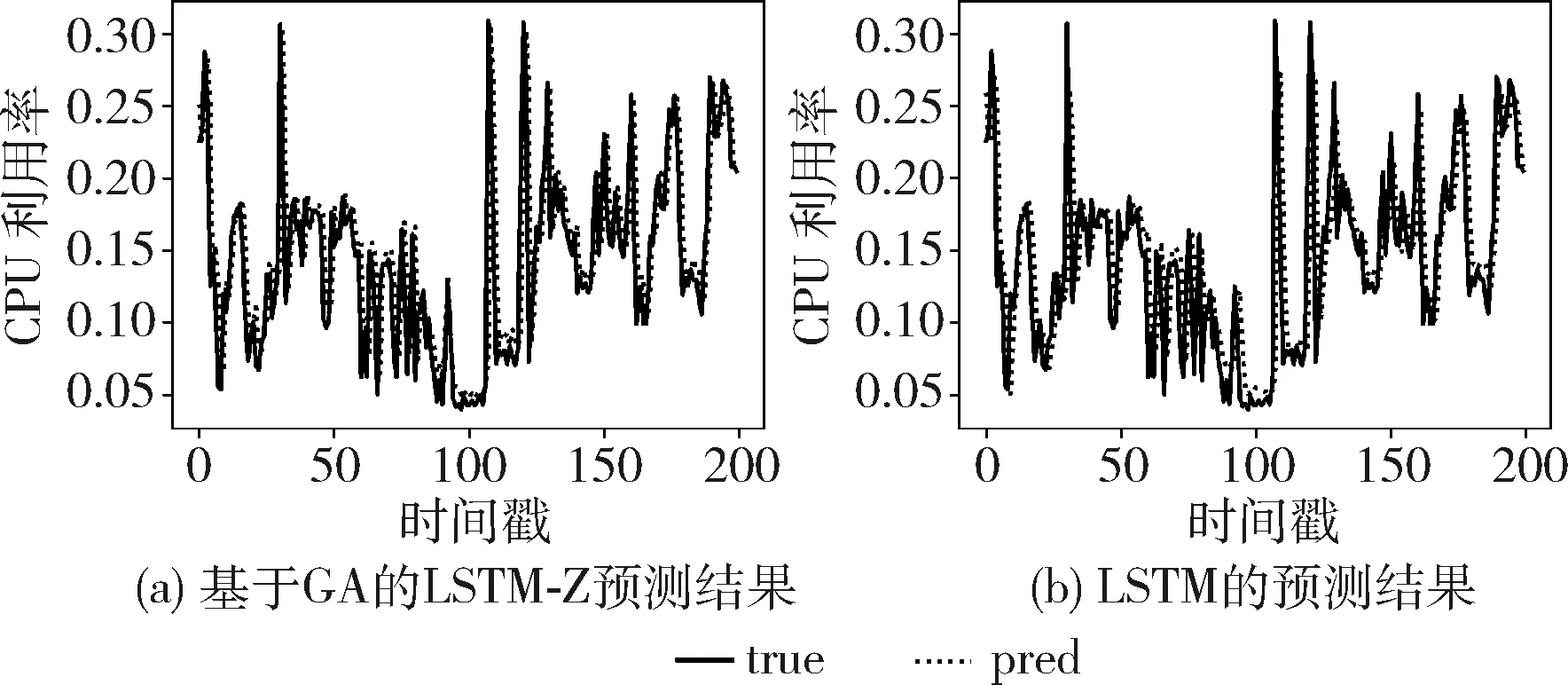
图9 谷歌trace实验中预测结果对比
综上所述,本文提出的方法比以往的方法在主机负载预测方面性能有所改善,能够更好地适应主机负载这种具有非线性和突变性的数据特点。这主要因为基于Zoneout技术改进的方法应用到了LSTM的门控结构,在一定程度上保留了通过神经元前向和后向的信息流,这有助于提高模型的泛化能力,增强捕获主机负载中短期突变信息的能力。将遗传算法和滑动窗口结合能够更好地表示历史窗口的数据依赖关系,然后作为预测模型的输入从而降低了预测误差,进一步优化了预测模型。
5 结束语
本文对云平台数据进行了分析,阐述了现在主流云平台需要进行主机负载的迫切需要,并分析了云平台主机负载CPU利用率的一些特性。为了使预测模型能够更好地适应主机负载数据突变性和短期波动性的特点,本文设计并实现了基于Zoneout技术的LSTM主机负载预测方法,增强预测模型捕获主机负载中短期突变的能力。为了更好地学习到历史窗口的数据依赖关系,本文基于遗传算法,通过迭代进化探索历史数据窗口的权重向量,从而进一步提高模型的预测性能。实验结果表明,本文提出的方法比起以往的方法在主机负载预测性能方面有所改善。
随着深度学习模型提取特征能力的不断增强,多源数据的挖掘与研究可作为下一步的研究工作。遗传算法的搜索空间还可以考虑应用在神经网络的超参数上,由于迭代次数和种群大小限制了遗传算法的时间性能,在考虑基于遗传算法改进预测模型时,应该要基于预测的实际情况进行。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中国煤炭(2020年2期)2020-01-21
中国化肥信息(2019年6期)2019-01-19
消费导刊(2017年24期)2018-01-31
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
统计与决策(2017年2期)2017-03-20
