
基于集成学习的忽略成员的方法检测策略
2023-10-12 01:10边奕心王露颖
计算机工程与设计 2023年9期
边奕心,王露颖,赵 松,朱 晓
(哈尔滨师范大学 计算机科学与信息工程学院,黑龙江 哈尔滨 150025)
0 引 言
由于移动通信技术的迅猛发展,移动应用程序已经成为软件行业的发展主体。而代码异味不仅存在于传统桌面应用程序中,也存在于Android应用程序中。由于Android应用程序与传统桌面应用程序在内存、CPU、网络、电池以及程序编写等方面的诸多差异,使得Android应用程序中不仅存在传统面向对象的代码异味,还存在Android特有代码异味(Android-specific code smells)。Android特有代码异味的存在对Android应用程序产生了诸多负面影响,比如能耗、安全性、稳定性、内存和启用时间等,极大降低了用户体验。随着机器学习技术的发展,近年来很多学者尝试使用不同的机器学习方法来检测面向对象的代码异味,并取得了很好的效果[1-7]。然而,目前还没有使用机器学习算法来检测Android特有代码异味的相关研究。
为了检验机器学习模型是否可用于检测Android特有代码异味,本文提出了基于集成学习的检测策略。该策略将代码度量与程序文本信息相结合作为特征集,避免模型受限于度量信息,无法学习到度量之外的程序特征,提高了单一模型的学习能力和泛化能力。此外,为了快速、准确获得机器学习所需的大量标签数据,提出了一种基于Android项目构建正负样本的工具。能够自动生成机器学习模型需要的大量标签数据。
1 相关工作
1.1 忽略成员的方法
忽略成员的方法(member ignoring method,MIM)是指某个类中的方法,该方法即非空方法,也非静态方法,但该方法没有访问所在类的任何属性[8]。MIM的存在对Android应用程序有诸多负面影响,比如,增加程序的能耗,降低程序的可维护性等[8]。
迄今为止,研究人员提出了一些MIM的检测方法。Rasool等[8]根据代码异味的不同特征与定义选择不同的度量,以预设阈值的方式为各个异味制定不同的检测规则,来检测异味MIM,并实现了工具DAAP。Nucci等[9]通过度量和简单的文本比较来检测包括MIM在内的15种Android特有代码异味,并实现了工具aDoctor。随后Iannone等[10]对aDoctor进行了扩展,使其能重构包含MIM在内的5种与能耗相关的异味。
综上所述,目前的检测方法主要采用传统的程序静态分析技术,依赖于不同的代码度量以及相应的阈值检测Android特有代码异味。然而,基于规则的检测方法,为找到合适每个度量的阈值,往往需要做大量的校准工作。此外,同一规则可能与多种代码异味相关,这将导致不同检测方法的检测结果存在较大的差异。
1.2 使用机器学习方法检测代码异味
随着机器学习技术的迅速发展,以及以Github开源代码库为支撑的“Big Code”的出现[1],很多学者尝试使用机器学习方法检测代码异味。目前已有一些研究使用机器学习方法检测面向对象代码异味。王帆等[2]在C4.5算法中加入对称不确定性,利用其计算条件属性间的相关度,更新信息增益率的计算,提高代码异味检测精确度。艾成豪等[3]提出基于Stacking集成学习模型的代码异味检测方法,提高了单一模型的泛化能力。以上研究在训练模型时,使用的特征集都是传统的代码度量。
近年来,随着深度学习模型在各个领域的卓越表现,软件工程领域的学者们开始尝试使用深度学习方法解决代码异味检测问题。Liu等[4]提出一种基于卷积神经网络的检测方法,用于检测依恋情结异味。在此基础上,Liu等[5]提出了一种基于卷积神经网络和长短时记忆网络的代码异味检测方法,检测4种代码异味。以上研究在训练模型时,不仅使用了传统的代码度量,还结合了代码文本信息(标识符信息)。Sharma等[1]分别使用卷积神经网络、循环神经网络和自编码器对4种代码异味进行检测。Sharma认为使用代码度量作为模型的输入,机器学习算法受限于度量信息,无法获得度量以外的源代码特征,影响模型的学习效果。此外,即便使用相同的度量,因为阈值的不同,导致不同检测方法的检测结果存在较大的差异。因此,Sharma没有使用任何传统的度量信息,而是使用程序文本信息作为模型的输入,不同于Liu等[5]使用的文本信息(仅标识符),Sharma将源代码转换为整数,然后以数字向量形式表示程序的文本信息,这种文本信息涵盖了程序的全部信息。
综上所述,已有使用机器学习或者深度学习检测代码异味的方法都只关注面向对象代码异味。目前还没有使用机器学习方法检测Android特有代码异味的相关研究。因此,为了检验机器学习模型是否可以用于检测Android特有代码异味,针对异味MIM本文提出基于集成学习的检测策略。
2 基于集成学习的MIM检测策略
2.1 方法概述
本文提出一种基于集成学习的MIM检测方法。该方法首先以开源的Android应用程序作为实验所需的代码语料库,从中提取度量和文本信息。通过特征融合将两种特征融合在一起,并与之相对应的分类标签一起构成MIM数据集。再对数据进行归一化,最后将得到的特征集送入的Stacking集成模型中进行分类。图1总结了本文异味检测技术的主要流程。
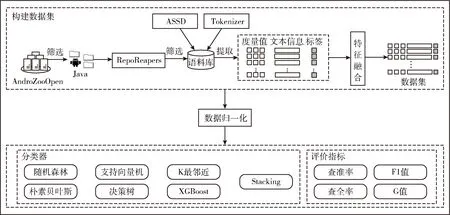
图1 融合文本信息和集成学习的MIM检测方法
2.2 构建数据集
本节详细介绍生成标签数据集的过程及使用的工具。
2.2.1 实验对象获取
在开源代码库AndroZooOpen[11]中下载Android应用程序,作为备选的代码语料库。AndroZooOpen是一个公开的Android应用程序集合,包括Gitbub、F-Droid和Google Play在内的多个数据来源。AndroZooOpen目前包含76 466个由不同语言开发的Android应用程序。本文选择主要由Java语言开发的Android应用程序,因为Java 是目前移动应用软件开发的主流语言之一,而且目前Android特有代码异味的检测工具只能检测由Java语言开发的应用程序。
首先,从AndroZooOpen下载110个开源Android应用程序。然后,使用工具RepoReapers[12]去除低质量的Android应用程序。RepoReapers可以从8个方面对AndroZooOpen中的程序质量进行评分(分别是体系结构、社区、持续集成、文件、提交历史、许可证、问题和单元测试)。如果待选应用程序在7个方面的评分均大于零,则选取该程序。经过筛选,最终确定70个Android应用程序作为代码语料库,这70个应用程序共有747 264行代码,9574个类和87 320个方法。
2.2.2 样本生成
在图像处理领域,研究者可以免费获得大量的有标签的图像数据集,用以构建模型的训练集。而在代码异味检测研究中,目前还没有类似的资源可供研究者使用[1]。为了解决这个问题,Liu等[4,5]和Sharma等[1]利用已有代码异味检测工具的输出结果,构建模型的训练集。本文借鉴这种方法,使用工具ASSD检测异味MIM并自动生成正、负样本集。本文使用的工具ASSD是在检测工具DAAP[8]源代码的基础上对其功能进行扩展,以自动生成正负样本。ASSD没有改变DAAP的异味检测规则,为区别于原DAAP工具,本文将改进后的工具称为ASSD,其流程如图2所示。
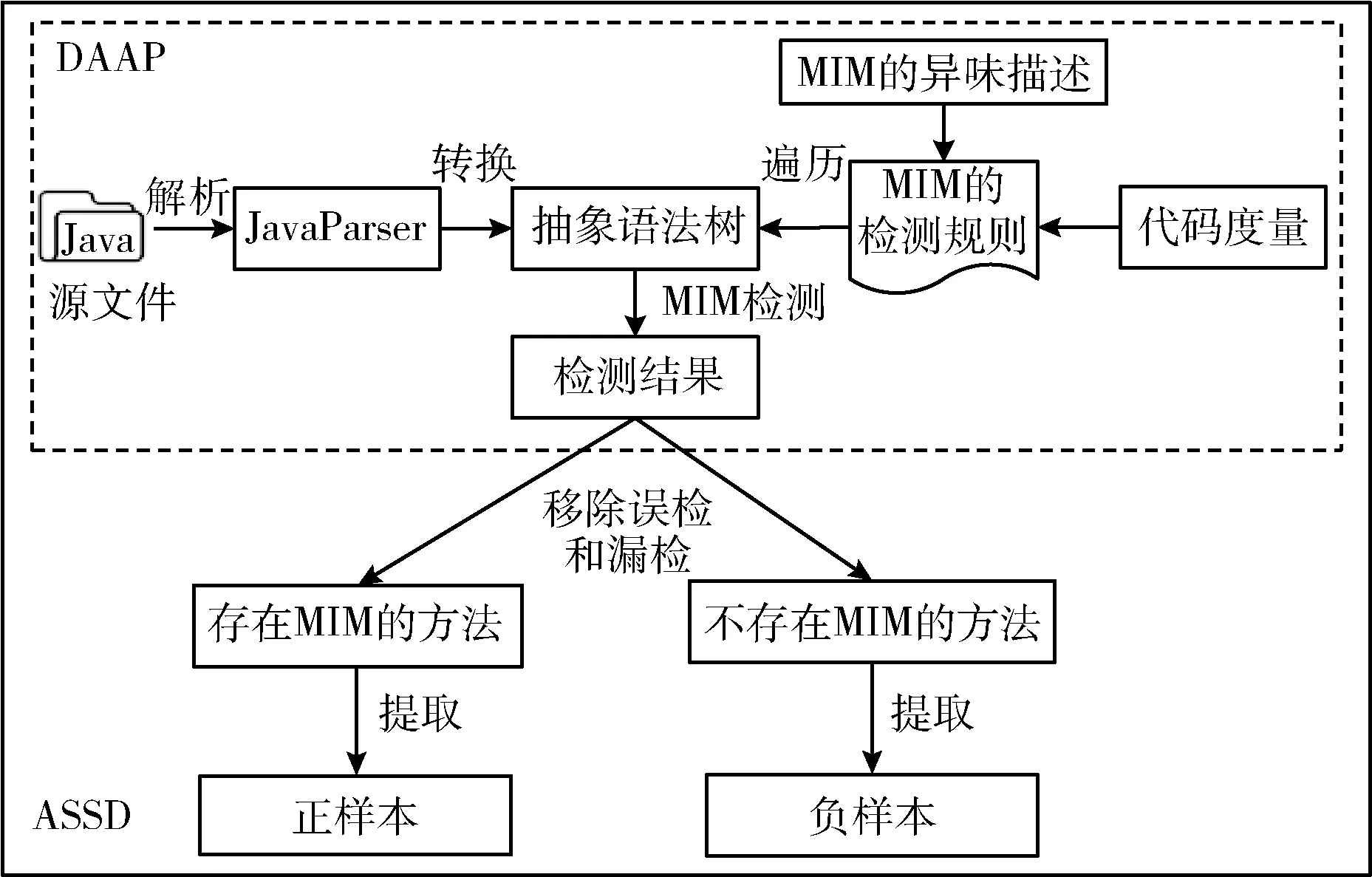
图2 ASSD自动生成正负样本集的流程
DAAP是目前检测异味种类最多、检测准确度最好的Android特有代码异味检测工具。DAAP可以检测包括MIM在内的25种Android特有代码异味,无论在检测的异味种类还是检测精度方面,都优于知名的检测工具aDoctor[8],并且DAAP是完全开源的工具,使用者不仅可以免费获得,而且可以在其基础上进行功能扩展,以满足不同的需求。因此,本文首选DAAP检测MIM异味。但是,由于DAAP的检测结果只能定位到类级别,而MIM属于方法级别的异味。因此,本文在DAAP的基础上,对其功能进行扩展,开发了ASSD。ASSD首先利用JavaParser将待分析的Java源代码解析生成抽象语法树,然后根据检测规则遍历语法树,输出异味。图2中虚线部分所示为DAAP工具,虚线外的功能是本文扩展的功能。ASSD不仅可以将检测出的MIM异味定位到所在的方法,而且还可以将每个存在MIM的方法和不存在MIM的方法提取到单独的文件夹中,生成正负样本集,即存放有异味方法的文件夹为正样本集,存放无异味方法的文件夹为负样本集。因此,ASSD从异味检测到样本生成完全自动完成。
由于检测规则自身的局限性,检测工具在检测异味的过程中会产生一定数量的误检。因此,为了保证输入模型数据的准确性,本文采用人工复检方法,对ASSD输出的代码异味进行检查,去除误检。
2.2.3 提取特征
分类器的特征集由两部分构成:代码度量和代码文本信息。
(1)提取代码度量特征
代码度量表示程序的结构信息,是代码异味检测研究中常用的判断依据[13]。本文选择代码度量作为模型的部分输入特征。度量指标选择检测工具DAAP检测MIM异味时使用的度量指标,分别为NSM(被检测方法是非静态方法)、AM(被检测方法所访问的内部成员的个数)和FACC(被检测方法所访问的内部属性的个数)。本文使用ASSD提取其中的度量值,其数据集格式如图3所示。

图3 度量数据格式
(2)提取文本信息特征
Sharma等[1]认为,只使用代码度量作为特征集,模型受限于度量信息,无法学习到度量之外的程序特征。因此,Sharma使用工具Tokenizer将源代码转换为整数,用数字向量表示程序文本信息,并将这些数字向量作为模型的特征集。Tokenizer可以将源代码转换为整数,不同的代码信息匹配不同的整数,图4为一小段Java方法和相应的由Tokernizer产生的整数。

图4 Tokenizer标记MIM示例
本文参考Sharma等的方法,将ASSD输出的标签样本集中的源代码转换成数字向量,用这些数字向量表示代码文本信息,作为模型输入的部分特征集,其数据集如图5所示。

图5 文本信息数据格式
此外,在对Tokernizer提取的代码文本特征统计和分析中发现,80%的方法中不会超过61个元素。为了避免因特征过多而导致的维度爆炸,在本文中将模型输入的单个样本中的代码文本特征个数固定在61个,即只针对被检测方法中的61个元素进行预处理,将方法中元素少于61个以全零向量来做补零扩展。
2.2.4 特征融合
尽管已有检测方法均使用代码度量作为特征集[16],但是,代码度量只能提供程序的结构信息,为了提高机器学习模型的学习效果,本文在代码度量的基础上,融入了代码文本信息。融合过程如下:将两组数据读入到numpy数组中,利用MIM在Android应用程序中的位置信息作为匹配键对代码度量和文本信息进行合并。此外,为避免重复样本数据对实验结果的影响,还需对相同的样本数据进行去重操作。删除重复数据后,得到一个含有2552条正样本和3265条负样本的数据集。其中,每条样本由3个代码度量、61个文本信息和1个异味标签组成,共65个元素,样本格式如图6所示。
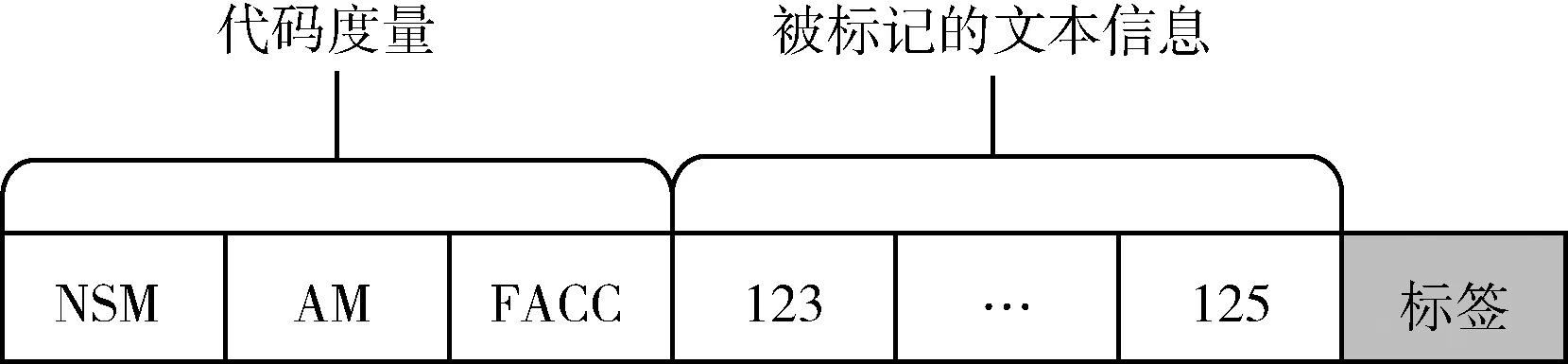
图6 样本格式
2.3 数据归一化
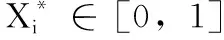
(1)
2.4 Stacking 集成学习模型的构建
不同的机器学习模型对代码异味检测的效果是不同的,为了使不同的模型之间能够取长补短,增强模型的泛化能力,从而避免单一模型预测性能不佳、鲁棒性较差的特点。本文构建了一种两层结构的Stacking集成学习模型,如图7所示。
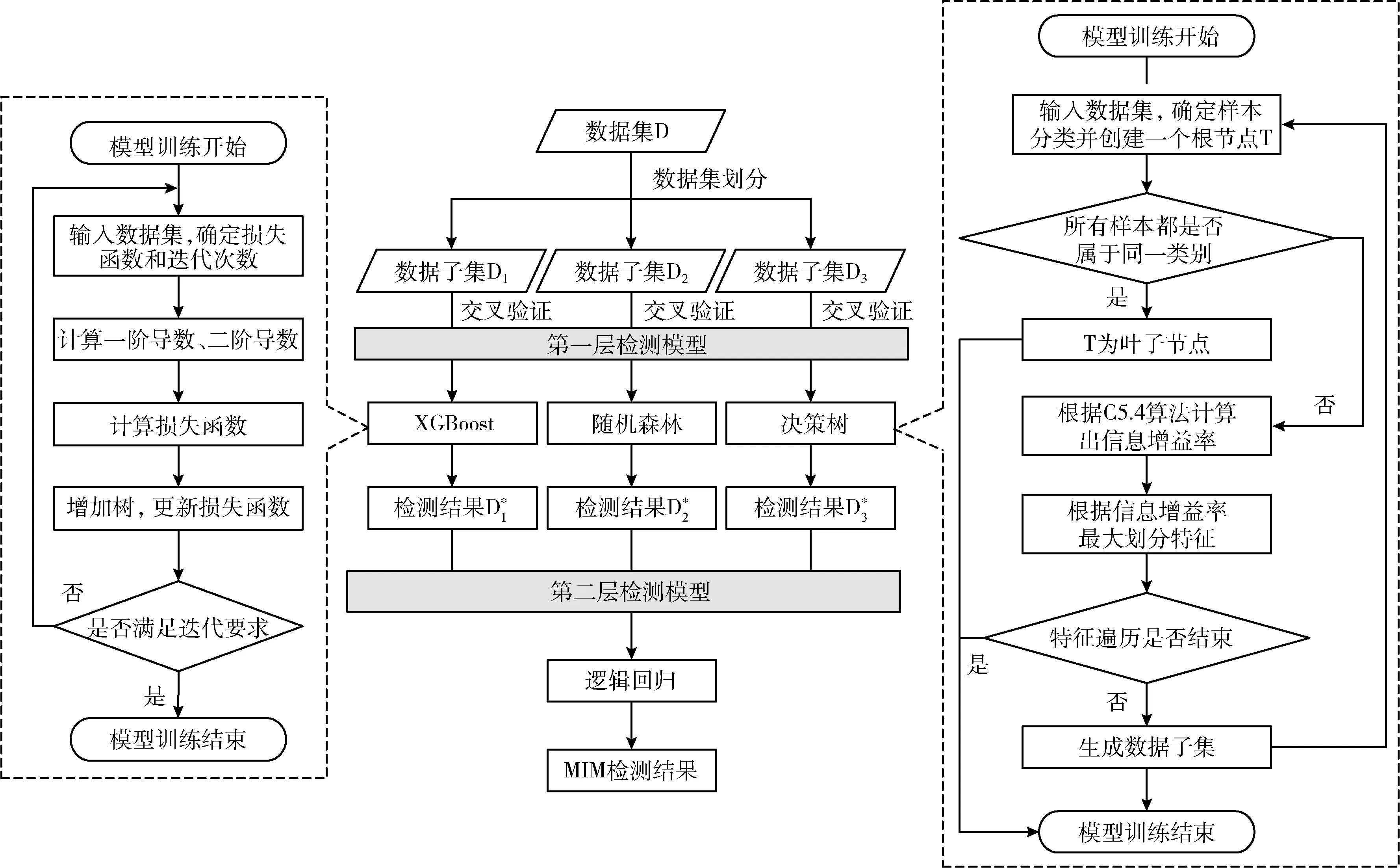
图7 Stacking 集成学习模型流程
Stacking模型的第一层选择XGBoost、随机森林和决策树作为基分类器。它们之间存在异构性,且各自对MIM的检测效果也较为优异。以这3种机器模型作为基分类器,可以使Stacking模型通过不同的学习策略,学习到更多的特征,实现模型间的互补性,有助于提升模型整体的检测效果。由于模型第二层的输入是由基分类器的预测结果所组成的数据集,不再是原数据集。所以,在模型训练时,可能会发生过拟合的情况。这是由于第一层基分类器在提取数据特征时,使用较复杂的非线性变换所导致的[15]。因此,在选取第二层元分类器时,本文与艾成豪等[3]和Tang等[15]一样选择逻辑回归作为元分类器。该分类器结构简单且可以使用正则化进一步防止过拟合的情况发生,常被用于处理二分类问题。它的实现过程如算法1所示:
算法1:Stacking 集成学习模型
输入:归一化后的数据集
输出:MIM检测结果
(1)将原始数据集D随机划分成3份,分别表示为D1、D2和D3;
(2)通过交叉验证的方法,确定各个模型的最优参数;

(5)将D*作为第2层检测模型的输入,对元模型进行训练,得到最终的检测结果。
3 实验设计与结果分析
实验环境如下:操作系统是windows 10处理器是Intel Core CPU i7-5500,内存是4 GB,实验工具为PyCharm和IntelliJ IDEA中完成,编程语言为Python和Java。在实验过程中,采用十折交叉验证对模型进行验证。此外,实验相关数据已上传至https://github.com/18745332164/MIMDetection。本文主要围绕以下3个问题进行实验研究:
RQ1:融合代码文本信息是否能提高模型的检测性能?若仅以单一特征作为模型的输入,其检测性能会有何变化?
RQ2:Stacking集成学习模型对MIM的检测性能是否有提高?
RQ3:本文提出的检测方法是否优于现有的检测方法?
3.1 模型评价指标
本文使用常用的查准率、查全率和F1值对模型进行评估,它们的计算方法如式(2)~式(4)所示
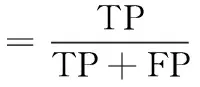
(2)
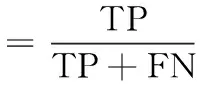
(3)

(4)
其中,式(2)和式(3)中的TP(true positive)为被检测为正的正样本数;FP(false positive)为被检测为正的负样本数;FN(false negative)为被检测为负的正样本数。
此外,由于实验数据集呈现不平衡状态,本文引入G值对模型进行更全面的评估,该指标能够更直观评价类不平衡的表现,其计算方法如式(5)所示

(5)
3.2 实验设计
实验一:为了回答RQ1,分别以2.2节构建的融合两类特征的数据集、仅代码度量和仅文本信息的数据集作为6个机器学习模型(XGBoost、随机森林、决策树、支持向量机、朴素贝叶斯和K最邻近)的输入,使用十折交叉验证对模型进行验证。最后,使用查准率、查全率、F1值和G值对不同特征输入下的6种检测模型的检测效果进行比较。
实验二:为了回答RQ2,将融合代码度量和文本信息的特征集作为模型输入的数据集,采用十折交叉验证的方法分别对3个机器学习模型以及由它们所集成的Stacking模型进行验证。最后比较4种检测方法的查准率、查全率、F1值和G值。
实验三:为了回答RQ3,首先,从Palomba等[9]提出的一个开源Android应用程序数据集(共60个Android应用程序)中选取了10个开源Android应用程序作为待测试程序。其中,这10个应用程序与模型训练阶段的70个应用程序没有重叠。表1列出了所用的10个开源Android项目的详细信息。然后,将新的测试集输入已训练好的Stacking分类器进行MIM异味检测。此外,为了进行对比,本文使用检测工具DAAP和aDoctor分别对这10个应用程序进行MIM异味检测。为准确评价两检测工具的检测结果,本文以Palomba等[16]提出的MIM异味目录作为参考,最后使用查准率、查全率、F1值和G值对3种检测方法的检测效果进行比较。
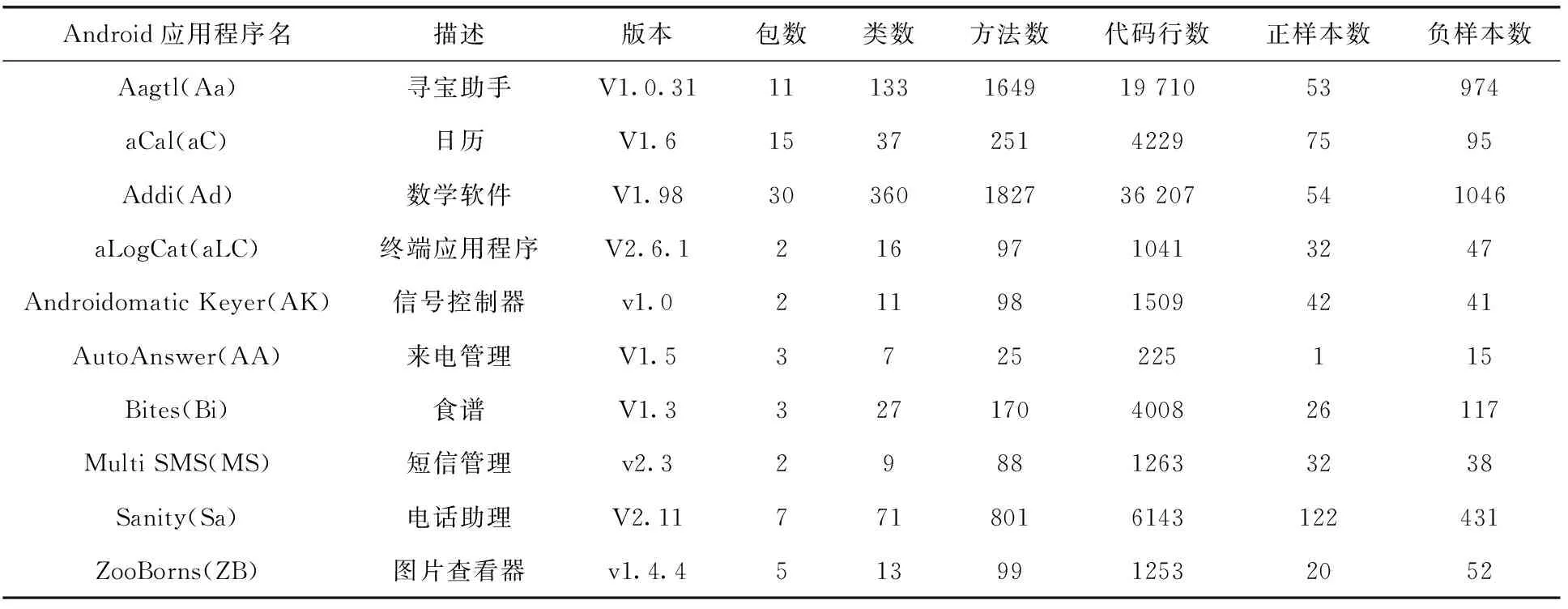
表1 10个Android应用程序及相关信息
3.3 实验结果分析
RQ1:表2为不同机器学习模型在不同特征下对异味MIM的检测结果。根据表2的结果可以看出:
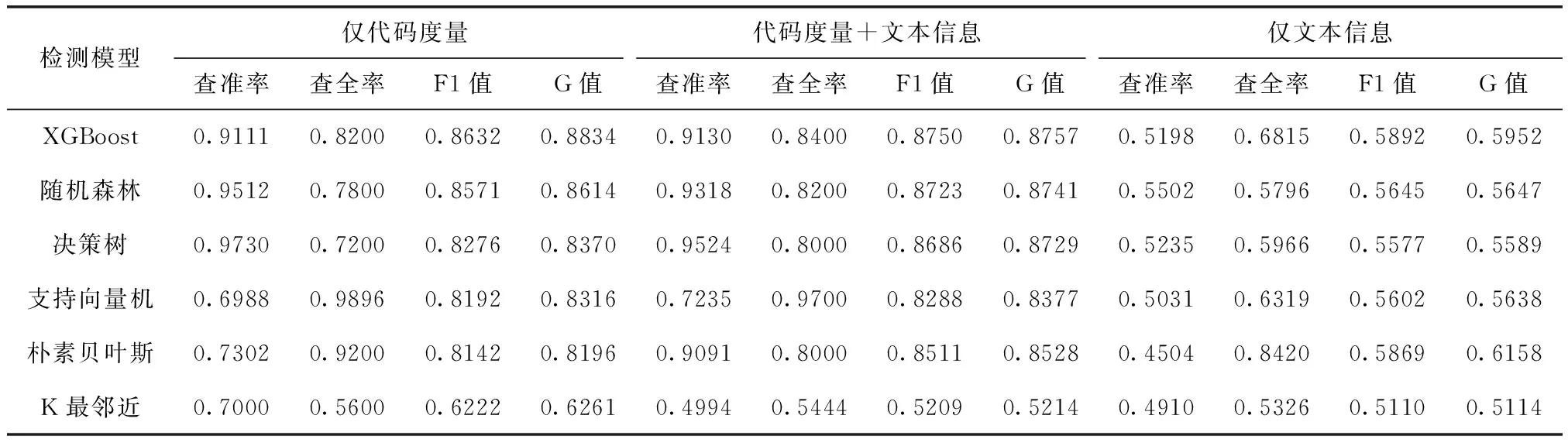
表2 不同模型在不同特征下的MIM检测结果
(1)融合文本信息后,6种分类器对MIM的检测性能综合排名为:XGBoost>随机森林>决策树>朴素贝叶斯>支持向量机>K最邻近。
(2)当以代码度量和文本信息共同作为特征输入时,除K最邻近对MIM的检测结果较仅以代码度量为特征输入的检测结果降低了以外。其余5种机器学习模型对异味MIM的检测结果,均优于仅以代码度量为特征输入和仅以文本信息作为特征输入的模型检测结果。其中,在融合文本信息后,决策树的检测性能提高的最为明显,其F1值提高了4.1%=(86.86%-82.76%)、 G值提高了3.59%=(87.29%-83.70%)。
(3)当仅以单一特征作为机器学习模型的输入时,以代码度量作为特征输入的分类器,其检测效果均优于以代码文本信息作为特征输入的分类器。以代码度量作为输入数据集时,6种分类器对MIM的检测性能综合排名为:XGBoost>随机森林>决策树>支持向量机>朴素贝叶斯>K最邻近。
XGBoost、随机森林和决策树无论是以代码度量作为特征集,还是以代码度量和文本信息作为特征集,其检测效果均优于其它分类器。故为避免由单一模型泛化导致模型检测性能不佳的问题,本文选择XGBoost、随机森林和决策树作为后续Stacking集成学习模型的基分类器。
RQ2:表3列出了文本信息融合后单一模型和Stacking 集成学习模型的性能比较。根据表3的结果可以看出:相对于单一机器学习模型,Stacking集成学习模型的检测效果更好,在F1值和G值上都有一定提升。
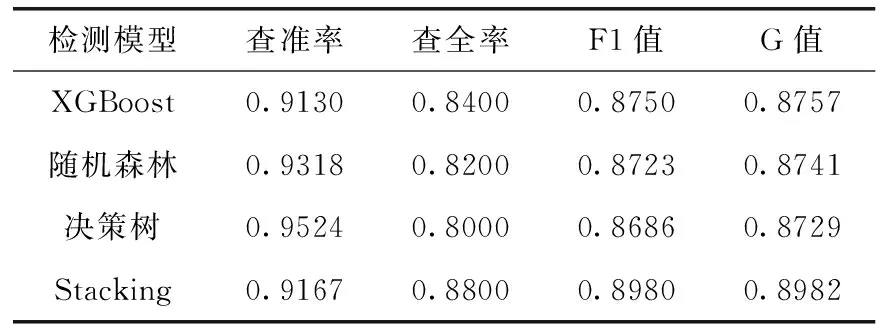
表3 文本信息融合后单一模型和Stacking集成学习模型的比较结果
从理论层面来分析Stacking集成模型优于单一模型的原因,是因为Stacking集成学习模型能发挥各模型的自身优势,从不同的角度来学习数据,屏除预测结果较差的环节。从模型优化的角度来分析,单一模型在训练优化的过程中,通常会陷入局部最小点的风险,有的局部最小点通常会导致模型的泛化性能不佳,而通过集成多个基学习模型可以减少此风险发生的概率,提高检测性能。
RQ3:表4列出了3种检测方法对表1中的10个Android应用程序检测结果的平均值。根据表4的结果可以看出:在相同测试程序的前提下,对异味MIM的检测效果,本文方法在查准率、查全率、F1值和G值上都优于DAAP和aDoctor。其中,本文所提方法较DAAP的查全率提高的最为明显,平均提高了43.12%=(97.98%-54.86%)。
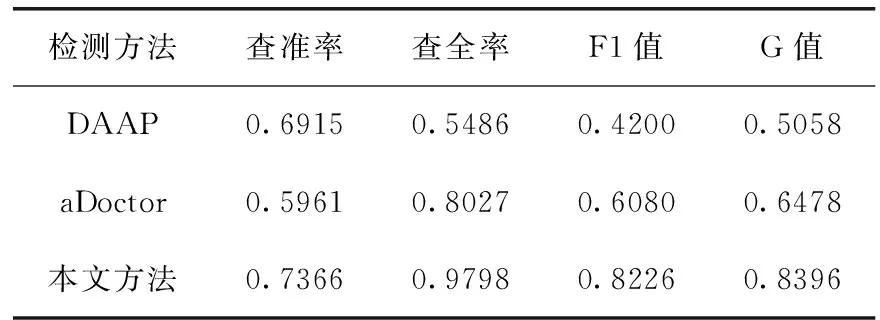
表4 不同方法间的平均比较结果
不同方法对10个Android应用程序中的异味MIM的具体检测结果如图8所示。
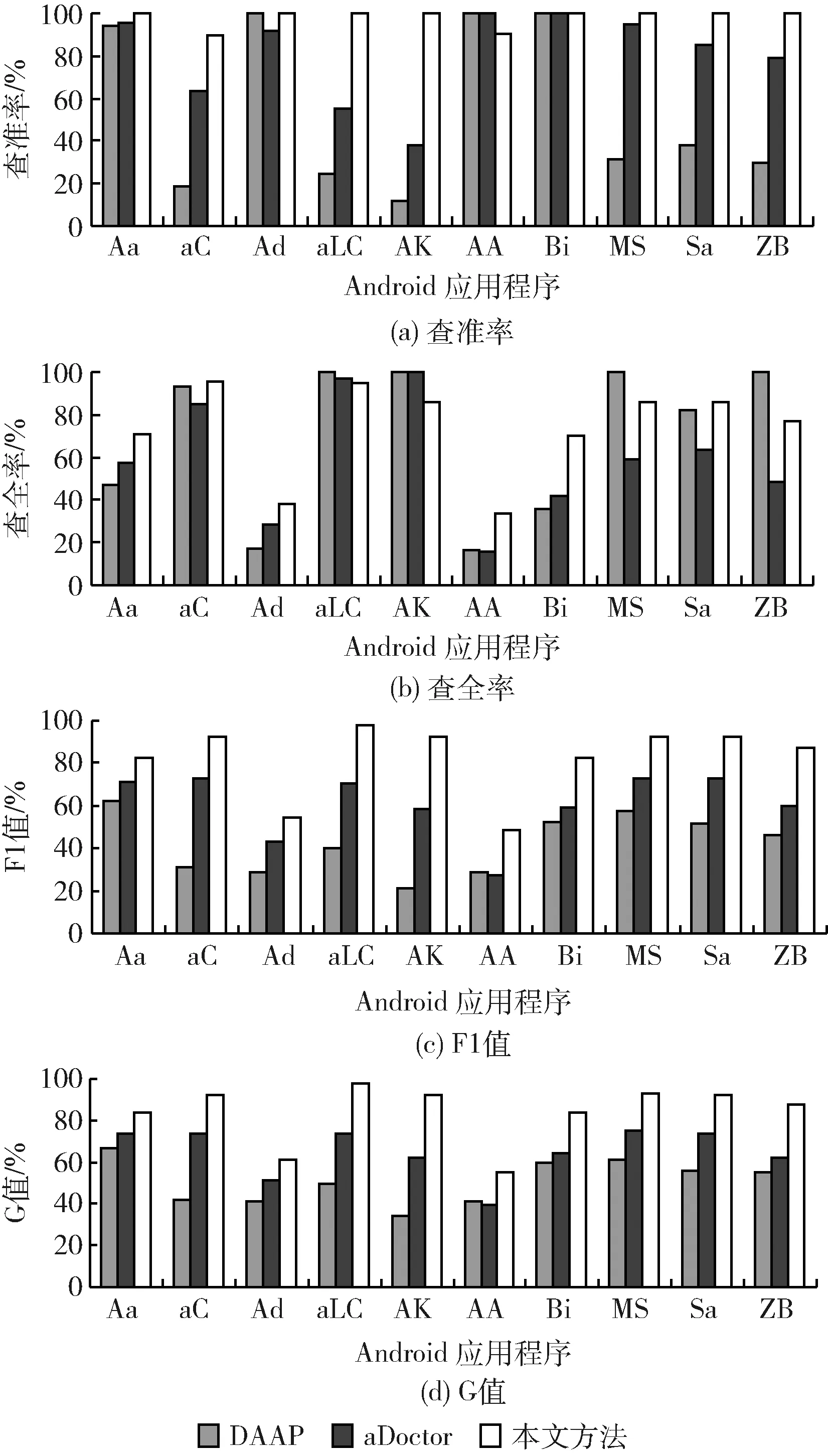
图8 不同方法在10个Android应用程序上的检测结果
从图8中可以看出本文所提出的检测方法明显优于DAAP和aDoctor。其中,对应用程序aLogCat中的异味MIM检测效果最好,F1值达到97.44%、G值达到97.47%。
以上实验结果表明,使用本文方法检测Android特有代码异味MIM取得了很好的结果,验证了本文所提检测模型的有效性。
4 结束语
本文提出一种基于集成学习的MIM检测策略。该策略首先将代码度量与文本信息相融合作为特征集,避免模型因受度量信息的限制,无法学习到度量之外的程序特征。然后,为了避免单一机器学习模型的局限,提高模型的泛化能力,本文构建了Stacking集成学习模型。然后,将特征集输入所构建的集成学习模型中进行异味检测。实验结果表明,融合文信息的方法和Stacking集成学习算法有更好的查准率、查全率、F值以及G值。此外,为了快速、准确生成机器学习模型所需的大量样本集,本文还实现了一种可以利用开源Android项目自动构建正负样本的工具ASSD。本文只介绍了1种Android特有代码异味的检测,后续也会对更多类型的异味进行检测。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学年刊A辑(中文版)(2019年3期)2019-10-08
电脑报(2019年12期)2019-09-10
石油石化绿色低碳(2019年6期)2019-01-14
中国计算机报(2018年30期)2018-11-12
宠物世界·猫迷(2017年7期)2018-01-25
猪业科学(2018年8期)2018-01-22
中国学术期刊文摘(2016年1期)2016-02-13
家庭生活指南(2009年7期)2010-04-07
