
基于改进樽海鞘群算法的特征选择方法
2023-10-12 01:28:10申晋祥鲍美英张景安周建慧
计算机工程与设计 2023年9期
申晋祥,鲍美英,张景安,周建慧
(1.山西大同大学 计算机与网络工程学院,山西 大同 037009;2.山西大同大学 网络信息中心,山西 大同 037009)
0 引 言
数据分类是许多应用中的热点问题,现在一般采用机器学习进行分类,但分类的性能会受到冗余特征和噪声的影响,特征选择在提高机器学习技术的准确性和响应时间方面起着重要作用。特征选择的目标是去除不相关、冗余和噪声的数据,从而降低特征维度,提高分类精度。
特征选择主要有两种方法,过滤式方法和包装式方法。传统的特征选择方法在处理高维数据时时间成本高且不一定能得到真正的最优解。目前,通过把启发式算法引入特征选择,提高特征选择的性能,用于特征选择的启发式算法有粒子群算法、遗传算法、鲸鱼优化算法[1]、正余弦算法[2]、樽海鞘群算法[3]、蝴蝶优化算法[4]、蚁狮优化算法[5]、头脑风暴优化算法[6]、布谷鸟优化算法[7]和果蝇优化算法[8]等。
樽海鞘群算法[3](salp swarm algorithm,SSA)是Mirjalili等受深海中樽海鞘觅食和运动的启发而开发的一种新的群智能算法,该算法参数少,易实现,在解决低维优化问题时表现出良好的性能,目前已经广泛应用到多个领域,如机械设计、频率调控、图像阈值分割和特征选择等。在特征选择领域的研究主要有:文献[9]采用基于主成分分析和快速独立成分分析的混合数据变换方法对原始数据进行变换,使用二进制SSA算法进行特征选择,算法去除了不相关特征,提高了分类精度。文献[10]混合SSA和PSO算法用于特征选择,混合算法进行特征选择时性能和精度都有所增强。文献[11]在SSA中引入对立学习和局部搜索算法,增加了种群的多样性,提高了局部开发,在特征选择中效果良好。文献[12]在SSA中增加动态时变策略和局部最优解,提出一种多目标SSA算法,有效平衡勘探和开发,算法收敛速度快且不易陷入局部最优。文献[13]提出动态SSA算法,位置更新公式中引入Singer混沌映射,增强解的多样性;采用新的局部搜索算法,改善局部开发。
为提高SSA的收敛速度和精度,本文提出一种融合多种策略的改进算法CESSA。首先,采用无限折叠混沌映射(iterative chaotic map with infinite collapses,ICMIC)生成初始种群,使个体均匀分布在搜索空间,增强种群多样性;其次,在领导者位置更新中引入非线性收敛算子,控制搜索范围,加快收敛速度;最后,在追随者位置更新处根据樽海鞘个体的适应度值优劣分别采用线性算子和随机数进行更新。利用改进后的算法全局搜索能力增强,寻优精度增高的特点,将CESSA与K近邻(k-nearest neighbor,KNN)分类器结合形成特征选择算法CESSAFS。通过实验对算法进行验证,为数据分类提供新方法。
1 基本樽海鞘群算法
樽海鞘群以链状进行活动,前端的樽海鞘称为领导者,其余的是追随者,基于樽海鞘群算法的数学模型如式(1)~式(3)[3]:
SSA领导者位置更新如式(1)
(1)

c1=2e-(4l/lmax)2
(2)
式中:l和lmax分别表示当前迭代次数和最大迭代次数。
SSA追随者位置更新如式(3)
(3)
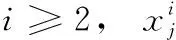
基本SSA采用随机初始化种群,种群多样性较差;领导者位置更新随机性大,收敛速度慢;追随者进行局部开发,对新解一律接受,不考虑解的优劣,可能会导致陷入局部最优。上述原因,使基本SSA算法收敛精度不高,收敛速度慢且易陷入局部最优解。
2 改进的樽海鞘群算法
对于基本SSA的缺点,本文分别从种群初始化及领导者和追随者的位置更新对SSA进行改进。
2.1 种群初始化
基本SSA随机初始化种群,如式(4)
X=rand(N,D).*(ub-lb)+lb
(4)
式中:rand(N,D) 生成一个N×D的随机矩阵,每个元素值都在(0,1)范围内,N是种群个数,D是解的维度。ub和lb分别表示搜索空间的上、下边界,“.*”表示矩阵的点乘,X是搜索空间的N×D矩阵。
混沌理论是数学方法,它可以提高元启发式算法的性能,文献[14,15]中指出,用混沌映射代替模型中的随机数可以提高算法的全局收敛能力,防止陷入局部最优。现有的混沌映射有多种,有些已经引入优化算法,如Logistic映射、Chebyshev映射等,ICMIC[16]映射在混沌区域内的均匀分布特性优于Logistic映射和Chebyshev映射,对比Logistic、Chebyshev和ICMIC映射的分布(如图1所示),取初值相同,迭代次数相同,迭代150次,发现ICMIC映射分布更均匀。种群的初始位置对算法的收敛速度和寻优精度有很大影响,本文采用ICMIC映射初始化种群,比随机方式生成的种群多样性更好,分布更均匀,避免算法早熟或陷入局部极值。
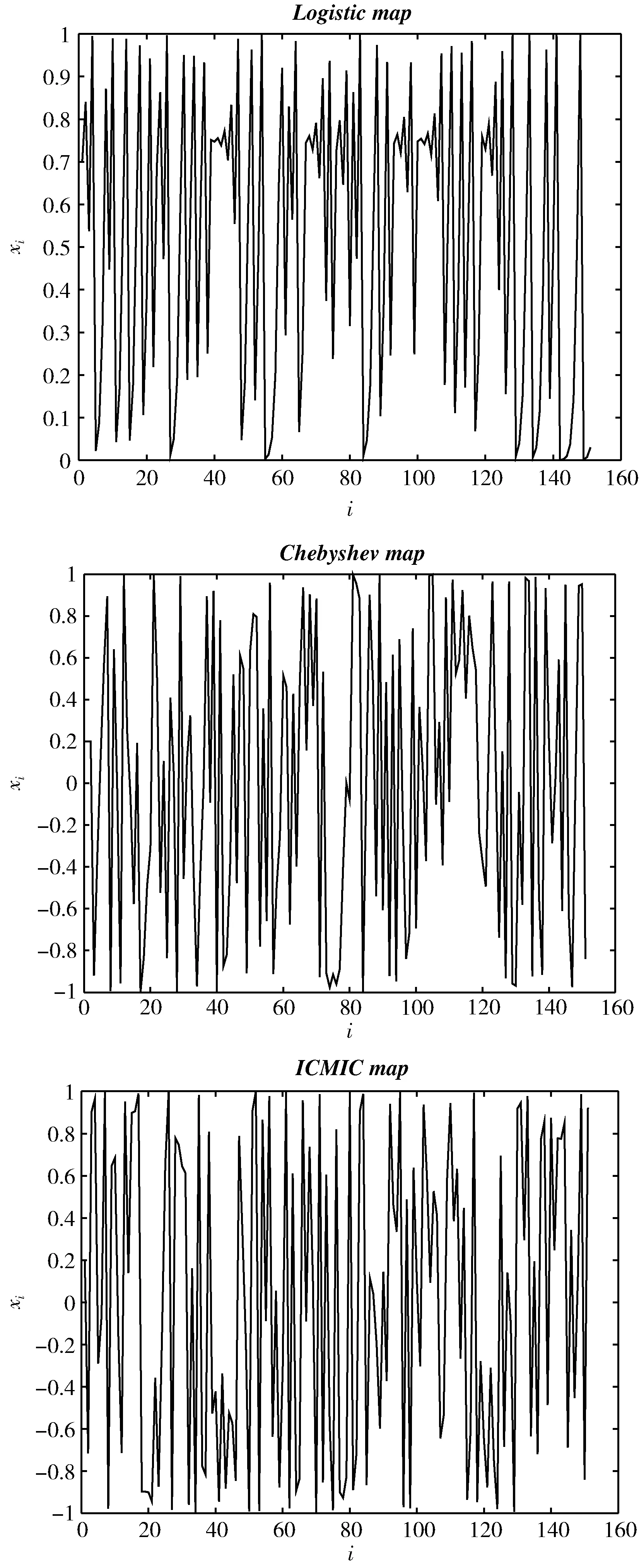
图1 对比Logistic、Chebyshev和ICMIC映射分布
ICMIC映射产生初始种群如下,首先通过ICMIC映射在[0,1]区间产生混沌序列,如式(5)
(5)
式中:α∈(0,1) 是控制参数,xn的初始值是0.152,α越大产生的混沌序列越好,选取α=0.9。

(6)
2.2 领导者位置更新方式改进
优化算法一般有一个平衡全局和局部搜索的参数,在SSA算法中是c1, 算法迭代前期进行全局勘探,寻找有希望的解空间,迭代后期在最优解附近进行开发,提高解的精确度。基本SSA中,领导者位置更新采用概率方法,领导者从迭代开始直接向食物源移动,移动的步长和方向都是随机的,搜索范围不确定,可能出现早熟收敛,也可能跳出全局最优,为改善这种情况,提高精确搜索,引入非线性算子(如式(7)所示),使迭代后期可以在小范围内进行精确搜索
ω(l)=3-20(l/lmax)
(7)
式中:l和lmax是当前迭代次数和最大迭代次数,利用ω(l) 控制搜索范围,迭代前期,领导者搜索范围较大,随着迭代增加,搜索范围减小,迭代后期,收敛在最优解附近进行小范围精确搜索,提高寻优精度。如式(8)
(8)
ω(l) 反映樽海鞘领导者受全局最优解影响程度的变化,ω(l)控制算法在搜索空间中更好地进行全局勘探和局部开发。增加ICMIC映射和非线性算子的算法称为CSSA。
2.3 追随者位置更新改进

(9)
g(l)=0.5*(lmax-l)/lmax
(10)
c4=exprnd(0.6)
(11)
2.4 CESSA伪代码
增加ICMIC映射并使用2.2节、2.3节中的领导者和追随者位置修改的算法命名为CESSA,算法步骤如下:
步骤1 设置算法初始参数。种群规模N, 搜索空间维度D, 最大迭代次数lmax, 搜索空间上界ub和下界lb等,使用ICMIC产生初始种群Xi(i=1,2,…,N)。
步骤2 计算每个樽海鞘的适应度值,找出最优的适应度值,作为食物源F。
步骤3 根据式(8)计算领导者樽海鞘的位置更新。
步骤4 根据式(9)计算追随者樽海鞘的位置。
步骤5 种群的每个樽海鞘位置均已经更新,执行步骤6,否则跳转到步骤3。
步骤6 根据搜索空间的上下界ub、lb修正越界的樽海鞘的位置。
步骤7 若迭代终止条件不满足,则跳转到步骤2。
步骤8 输出最优解食物源F。
3 基于CESSA的特征选择算法
CESSA算法与K近邻分类器结合形成一种特征选择分类模型CESSAFS。在模型中,采用CESSA算法在搜索空间选择特征子集,K近邻分类器对选择的特征子集进行评估。
3.1 初始化
特征选择问题是二元优化问题,CESSAFS首先通过ICMIC生成P个个体,每个个体代表给定优化问题的解,维度是分类数据集的特征总数。然后,采用式(12)把每个解转换为二进制BX
(12)
3.2 适应度函数
特征选择的目标是要求分类的准确率高(即分类错误率低),选择的特征子集尽量小,构造的适应度函数如式(13),通过适应度函数评估每个解的质量
(13)
式中:α和β是权重因子,用于确定偏重分类准确率还是选择的特征数,|n| 是选择的特征数,|D| 是数据集的总特征数。
3.3 特征选择实现流程
CESSAFS的特征选择流程如图2所示。

图2 CESSAFS算法的流程
4 实验与结果分析
4.1 CESSA性能分析
为了验证本文改进算法在优化问题中的收敛速度和解的精度等性能,选取8个基准测试函数对改进算法进行仿真实验,F1~F4是单峰函数,单峰函数在定义域内只有一个最小值,测试算法的收敛速度和精度,F5~F8是多峰函数,多峰函数含有多个局部最优解,测试算法跳出局部最优值,进行全局勘探的能力。其中F1函数维度30,F8函数维度是4,其余函数维度均为10,8个函数自变量的范围和最小值均采用默认值。
4.1.1 优化性能分析
实验使用的操作系统是Windows10,CPU 2.6 GHz,内存16 G,Matlab R2016a编写程序代码,迭代次数500,种群数30。比较基本算法SSA,改进后的算法CSSA、ESSA和CESSA的运行情况,各算法分别独立运行30次,获取实验结果的平均值和标准差进行评价,实验结果见表1。

表1 基准测试函数优化结果
由表1中的平均值反映算法的收敛精度,CSSA、ESSA和CESSA都比标准的SSA寻优精度高,说明加入不同策略可以增强算法的性能。对于4个单峰函数,CESSA在求解精度上最高达到1e-135。对于4个多峰函数,F5和F7达到了理论的极值点0,表明引入指数随机数算子进行扰动,对算法跳出局部最优具有较大作用,F6的收敛精度大大改进,F8的收敛精度与SSA的相当,但仍优于SSA的收敛精度。CSSA、ESSA和CESSA的标准差都比SSA的小,说明改进的算法寻优具有稳定性。可见,CESSA算法在求解单峰、多峰的高维基准函数时具有明显的优势。
4.1.2 收敛性分析
为了更清楚观察算法的收敛性能,绘制算法SSA、CSSA、ESSA、CESSA在求解30维函数时的收敛曲线,如图3所示。
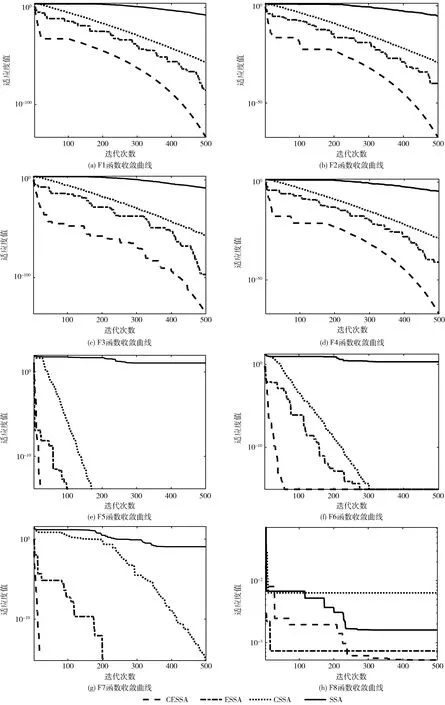
图3 函数收敛曲线
图3是各算法在8个基准函数运行的收敛曲线,从图上可以更加直观地看出各算法的收敛精度和收敛速度的差异,图中横坐标是迭代次数,纵坐标是适应度值。由图3(a)~图3(h)观察发现,迭代初期,CSSA、ESSA和CESSA都迅速下降,这是混沌映射初始化种群的效果,使种群具有多样性,出现快速收敛,随着迭代次数的增加持续下降,未出现停滞现象并且寻优精度较高。SSA算法收敛曲线下降较慢,随迭后期停止。F5和F7收敛速度快,并达到理论最优值0。由图3可以看出,CESSA算法在对8个基准函数优化时,收敛速度都是最优,尤其在函数F1、F3、F7上,收敛速度明显优于其它算法。结果验证本文对算法的改进是有效的,改进的算法寻优效果好,性能稳定,最优解精度更高。
4.2 CESSAFS性能分析
选取机器学习数据集UCI中的10个典型数据集测试算法CESSAFS的性能,数据集的信息见表2。
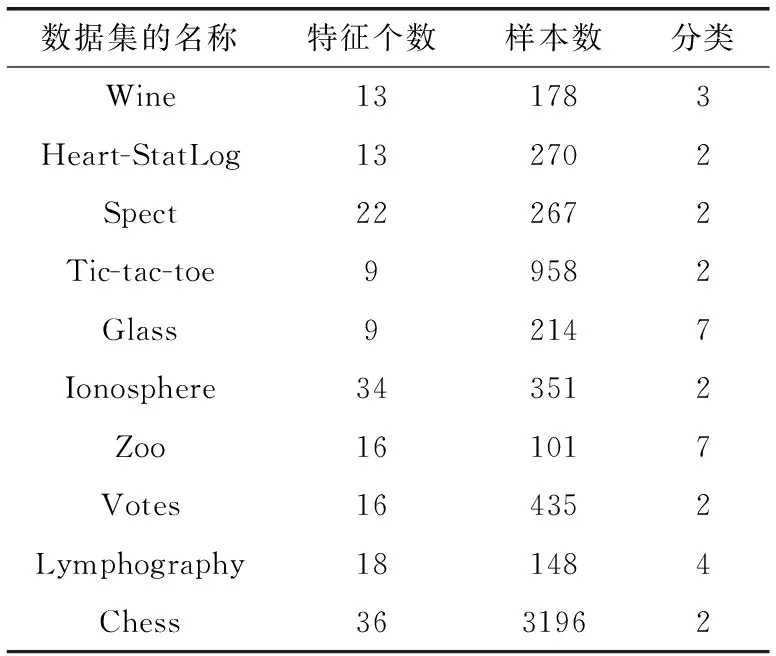
表2 UCI中的部分数据集
采用十折交叉验证,每个数据集被随机分成10份,每份大小相同,其中1份作为测试集,9份作为训练集,重复10次实验,结果取平均值。
4.2.1 实验设计
为了客观评价CESSAFS算法的性能,本文采用包装式特征选择算法PSO、BOA、SCA、ALO和WOA与本文的特征选择算法CESSAFS进行比较。算法的种群规模设置为20,迭代次数为100,KNN中的k取值5,维度是分类数据集的特征个数,与其它算法保持一致,CESSAFS的适应度函数的权重α=0.99,β=0.01。PSO的c1=2,c2=2,惯性设置0.9;SCA的参数A设置为2。
算法分别在每个数据集上独立运行10次,取结果的平均值,比较算法的平均适应度值、平均分类准确度、平均选择的特征数,实验环境设置同4.1。
4.2.2 实验结果分析
算法在10个UCI数据集上的实验结果见表3和表4。
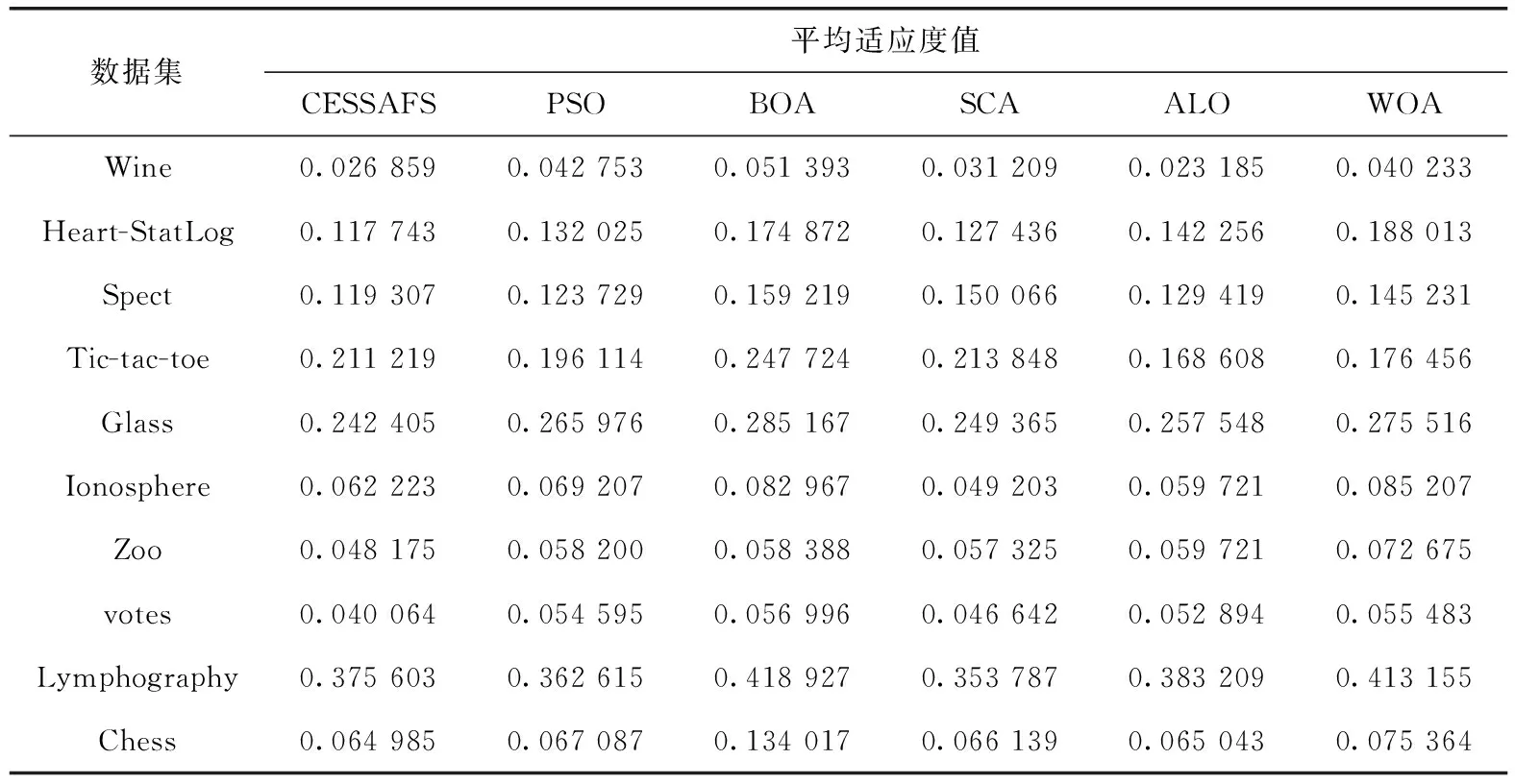
表3 不同算法在UCI数据集上的平均适应度值对比

表4 不同算法在UCI上平均分类准确率和所选特征数的对比
CESSAFS算法的适应度函数由分类错误率和所选特征率组成,函数的适应度值越低,说明算法效果越好。分类错误率越低,则数据分类的准确率越高;所选特征越少,则算法的降维效果越好。平均适应度值反映以上两个目标的综合情况,从表3可以看出,CESSAFS的平均适应度值整体最优,在10个数据集中的6个达到比较算法中最低值,然后是SCA和ALO,分别在2个数据集上达到平均适应度值的最小值。上面数据说明,CESSAFS的综合性能在搜索空间中表现是最佳的。
数据分类准确率分析。从表4可以看出,CESSAFS在10个数据集的6个数据集中达到最优的分类准确率,剩余的4个数据集中,SCA在两个数据集上达到最优,ALO在两个数据集上达到最优。在Tic-tac-toe数据集上,CESSAFS的准确率仅比排在第一的ALO低0.040,在Ionosphere数据集上,CESSAFS的准确率仅比排在第一的SCA低0.014,在lymphography数据集上仅比排第一的SCA低0.020,在Chess数据集中,比排第一的ALO低0.001。说明CESSAFS对数据分类的准确率整体是良好的。
选择特征个数分析。从表4中可以看出,CESSAFS在10个数据集中选择的特征数均值达到最小的有5个数据集,SCA在10个数据集中的4数据集中选择的特征数数最小,其次是BOA,在1个数据集中所选择的特征数最小。在Wine数据集上,虽然SCA选择的特征数最小,但CESSAFS的平均分类准确率比SCA高0.0057。综合分析,CESSAFS在数据降维方面表现良好,在大多数数据集中缩减数据特征的同时还能保持较高的分类准确率。
对比CESSAFS算法与其它算法的平均适应度值,平均分类准确率和平均选择的特征个数,可以看出CESSAFS的整体性能较优,说明本文引入的改进策略是有效的。
5 结束语
本文提出了一种改进的SSA算法CESSA,为了评估CESSA的性能,在8个基准函数上进行了测试,仿真结果表明CESSA算法能平衡全局和局部搜索,提高解的精度。CESSA与K近邻分类器结合构成分类算法CESSAFS,进行特征选择,把CESSAFS在UCI的10个数据集中进行测试,并对比包装式特征选择算法PSO、BOA、SCA、ALO和WOA,结果表明,CESSAFS在整体性能指标上优于其它特征选择算法,说明算法是有效的。未来可以将改进算法应用到不同优化问题,如任务调度、云计算和图像分割等,还可以探索算法的多目标优化问题。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
文萃报·周五版(2022年42期)2022-05-30 10:48:04
包装工程(2022年9期)2022-05-14 01:16:22
生态学报(2017年20期)2017-11-22 04:31:23
电子制作(2017年23期)2017-02-02 07:17:06
中国塑料(2016年11期)2016-04-16 05:26:02
西北工业大学学报(2015年4期)2016-01-19 03:31:47
大自然探索(2015年10期)2015-09-10 21:25:47
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
