
中文新闻文本多文档摘要生成
2023-10-12 01:28:56李宝安佘鑫鹏常振宁吕学强游新冬
计算机工程与设计 2023年9期
李宝安,佘鑫鹏,常振宁,吕学强,游新冬
(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引 言
随着深度学习在文本摘要领域的不断发展[1-5],基于深度学习的文本摘要技术[6],成为实现新闻自动化生产的方法之一。文本摘要技术始于抽取式摘要,近年逐渐发展为应用深度学习技术的生成式摘要,而在生成式摘要的领域内,又逐渐由单文档摘要发展为多文档摘要。生成式摘要较抽取式摘要更简洁连贯、概括性更强,多文档摘要较单文档摘要可处理更多文献、摘要信息更丰富。多文档生成式摘要技术既可用于生成文摘,亦可用于聚合式写作,是新闻自动化生产的核心技术。
本文针对新闻自动化生产的问题,基于Transformer[7]和指针生成网络[8],提出了一种面向中文新闻文本的多文档生成式摘要模型:Transformer-PGN,该模型利用融合段落注意力机制的Transformer模型对中文文本进行特征表达和深层次的综合特征抽取,捕获跨文档关系,再通过指针生成网络生成聚合式新闻。实验结果表明,该模型在中文多文档摘要评测数据集WeiboSum上取得了良好的效果,Rouge-1、Rouge-2和Rouge-L分别提升了2.1%、2.4%和2.3%。
1 相关工作
在生成式摘要中,根据产生摘要的文档数量可分为单文档摘要、多文档摘要。
单文档生成式摘要指从一个文档中生成一个摘要,摘要的句子由机器生成,生成方式接近于人的思考方式,摘要需简洁凝练、具有一定的连贯性。近些年,生成式摘要的主流模型都是基于Seq2Seq框架[9]。Google提出基于指针生成网络的单文档生成式摘要模型[8]。该模型一方面通过Seq2Seq框架保持抽象生成摘要的能力,另一方面通过指针网络从原文中取词,提高了摘要的准确度并解决了OOV问题。并使用覆盖率机制来处理重复问题,提高生成摘要的准确性。陈天池等[10]在传统Seq2Seq框架的基础上,解码端融合了Attention机制,解决了Seq2Seq在解码的时候无法获得输入序列足够信息的问题。李大舟等[11]提出了基于编解码器结构的中文文本摘要模型,编码器端将原始文本输入到编码器并结合双向门控循环单元生成固定长度的语义向量,使用注意力机制分配每个输入词的权重来减少输入序列信息的细节损失,解码器端使用LSTM网络,融合先验知识和集束搜索方法将语义向量解码生成目标文本摘要。从应用的角度看,单文档生成式摘要难以满足从多篇文档中生成摘要的场景,因为它无法从多个文档中生成一个涵盖不同中心点的、全面的摘要。
多文档生成式摘要的目的是在一组主题相关的文档中生成一个简短而信息丰富的摘要。多文档生成式摘要比单文档生成式摘要更复杂、更难处理。这是因为在多文档生成式摘要任务中,文档之间有更多不同和冲突的信息。文档通常较长,文档之间的关系更加复杂。对于模型来说,保留复杂输入序列中最关键的内容,同时生成相关的、非冗余的、非事实错误和语法可读的摘要是很有挑战性的。Google提出基于Transformer的T-DMCA[12](transformer decoder with memory-compressed attention)多文档生成式摘要模型,该模型包含一个抽取式模型和一个生成式模型,首先通过抽取式模型生成有序的段落列表,再通过生成式模型生成文本。该模型还提出memory-compressed注意力机制,该机制通过卷积神经网络压缩多头自注意力提高计算效率。但该模型未能捕获跨文档之间的关系。耶鲁大学构建了新闻领域第一个大规模多文档摘要数据集Multi-News[13],并提出Hi-MAP(hierarchical MMR-attention pointer-generator model)多文档生成式摘要模型。该模型通过集成的MMR(maximal marginal relevance)模块计算句子的相关性和冗余性,从而计算候选句子的排名,然后通过指针生成网络生成摘要。百度提出基于图的多文档生成式摘要模型GraphSum[14]。该模型包含Transformer编码器、图编码器和图解码器。得益于图形建模,该模型可以从长文档中提取重要信息,并能够更有效地生成连贯的摘要。在大规模多文档摘要数据集WikiSum和MultiNews上的实验结果表明,GraphSum相对于已有的生成式摘要方法具有较大的优越性,在自动评价和人工评价两种方式下的结果均有显著提升。
虽然现有的工作为多文档生成式摘要奠定了坚实的基础,但与单文档生成式摘要和其它自然语言处理主题相比,它仍然是一个较少见的研究课题。目前,许多现有的基于深度学习的多文档生成式摘要模型未考虑文档之间的关系,从而忽略了多文档中可能包含的相同、互补或矛盾的信息。捕获跨文档关系,有助于模型提取关键信息,提高摘要的相关性并降低冗余度。本文提出的Transformer-PGN模型利用融合段落注意力机制的Transformer结构对中文文本进行特征表达和深层次的综合特征抽取,并捕获跨文档关系;然后,通过结合coverage机制的PGN网络生成更有效的摘要。
2 Transformer-PGN模型
本文使用WeiboSum数据集,模型的输入为一组主题相关的多文档,输出为该组多文档对应的摘要。摘要来源于微博用户参考消息、环球时报等发布的微博,多文档来源于Google搜索引擎返回的前5个结果(检索词为摘要的前20个字符),每个文档按换行符被切分为多个段落。由于输入模型的段落较多且单个段落可能冗长,本文采用Rouge-2和Single-pass聚类算法选择K个句子串联作为模型输入。对于所有的输入段落 {P1,…,PL}, 采用Rouge-2计算每个段落与参考摘要的召回率,所有段落按召回率大小降序得到 {R1,…,RL}; 然后,对前L′个段落进行Single-pass聚类,得到K个段落组成的簇 {SP1,…,SPK}, 对于每个簇Si, 取簇内一个段落,组成段落 {S1,…,SK}; 最后,将K个段落串联为模型输入。
本文的摘要模型如图1所示。模型的基本结构由编码器和解码器组成,编码器将输入文本表示成若干带有语义向量的输入序列,解码器则从输入序列中提取重要内容,生成文本摘要输出。模型的编码器采用融合段落注意力机制的Transformer及双向LSTM结构,模型的解码器采用Vanilla Transformer、单向LSTM及指针网络,同时采用coverage机制避免生成重复内容。
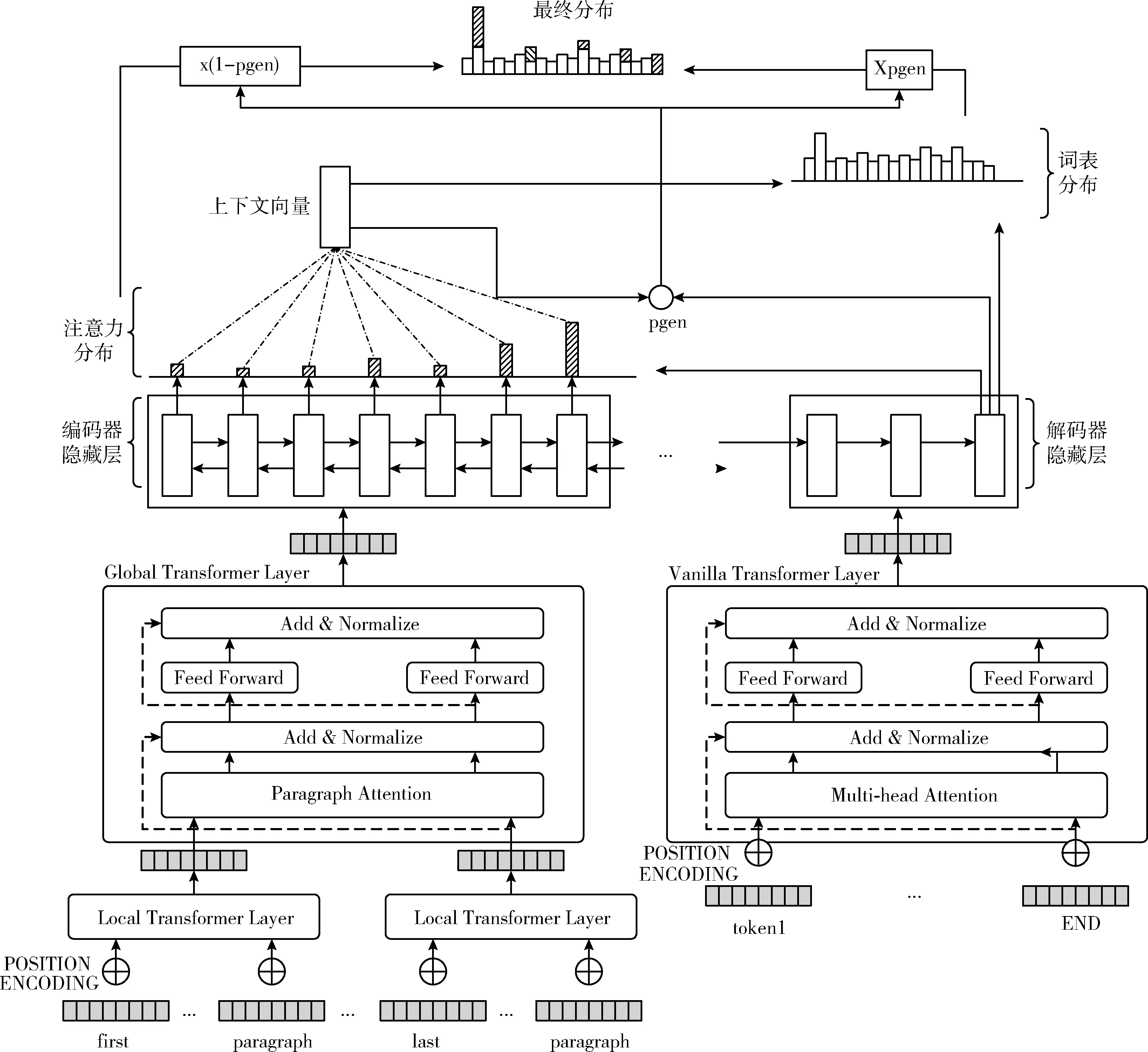
图1 总体结构
2.1 编码器

2.1.1 嵌入层
嵌入层由词嵌入层、词位置嵌入层和段落位置嵌入层组成。嵌入层结构如图2所示。其中,位置嵌入层采用Sinusoidal位置编码,Sinusoidal位置编码通过使用不同频率的正弦、余弦函数生成,公式如下
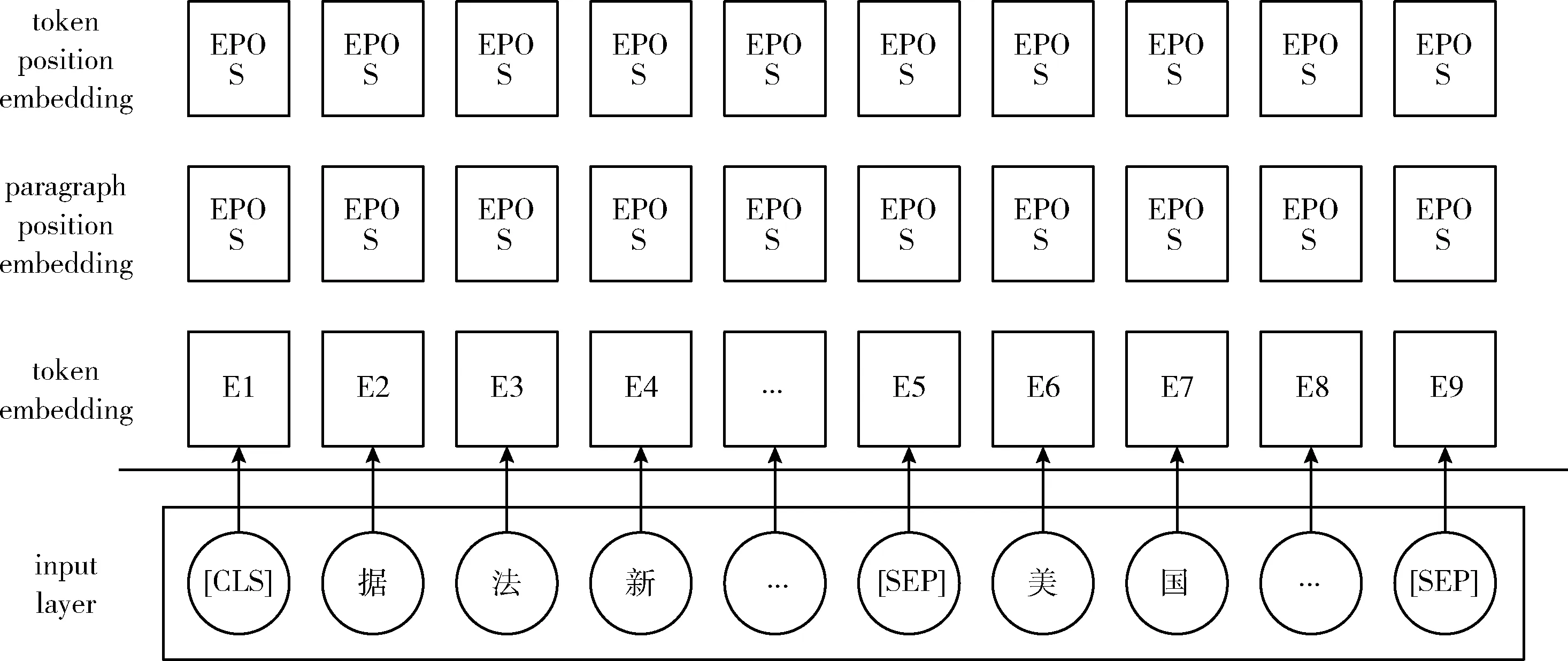
图2 嵌入层结构
epos[2i]=sin(pos/100002i/dmodel)
(1)
(2)
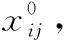
peij=[ei;ej]
(3)
(4)
2.1.2 Local Transformer层
Local Tranformer层对每个段落内的词进行编码,其结构同vanilla transformer[3]层,由以下两个子层组成
h=LayerNorm(xl-1+MHAtt(xl-1))
(5)
xl=LayerNorm(h+FFN(h))
(6)
其中,LayerNorm为归一化层;FFN为以ReLU为隐藏激活函数的两层前馈神经网络;MHAtt为Vaswani等介绍的多头注意力机制,其结构[7]如图3所示,公式如下
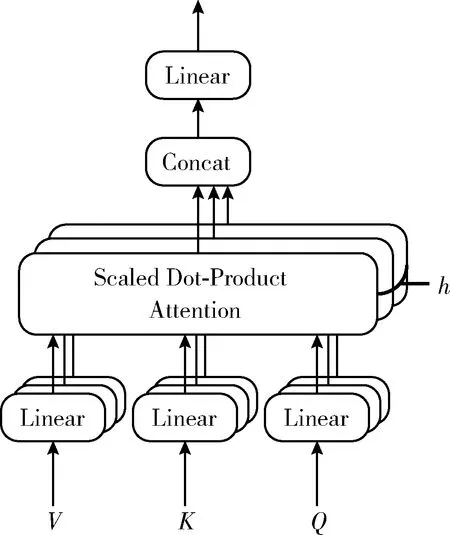
图3 multi-head attention结构
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(7)
(8)


图4 Scaled Dot-Product Attention结构
(9)
其中,dk指key的维度,softmax函数公式如下
(10)
2.1.3 Global Transformer层
Global Transformer层用于多个段落间交换信息。首先对每个段落采用段落注意力机制,使每个段落可以通过自注意力机制获取其它段落的信息,从而生成一个可以捕获所有上下文信息的上下文向量。然后,上下文向量经线性变换,叠加至每个词向量,并输入至前馈神经网络,全局性地更新每个词的向量表示。
段落注意力机制与自注意力机制同理,每个段落通过计算注意力分布获取其它段落的文本信息。
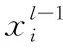
(11)
αij=softmax(eij)
(12)
(13)

(14)
(15)
其中,Wo1和Wo2是模型参数。
2.2 解码器
模型的解码器采用Transformer层和指针生成网络,同时采用coverage机制避免生成重复内容。解码器使用的指针生成网络包含指针网络、单向LSTM和注意力机制。Transformer层采用Vanilla Transformer结构,Transformer层的输出编码状态hi作为单向LSTM网络的输入向量,在时间步t得到解码状态序列st。 该时间步输入序列中第i个词的注意力分布为at, 公式如下
(16)
(17)
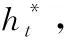
(18)

(19)

(20)
其中,wh、ws、wx、bptr、σ、xt定义请参见文献[8]。生成单词w的概率分布计算公式如下
(21)
覆盖率机制可以解决重复性问题,将先前时间步的注意力权重加到一起得到覆盖向量ct, 用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。覆盖向量ct计算公式如下
(22)
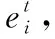
(23)
其中,Wc为模型参数。
3 实验与分析
3.1 实验数据
本文的实验数据采用WeiboSum中文多文档摘要评测数据集,包含训练集新闻主题8000个,验证集新闻主题1000个,测试集新闻主题1000个,其中,每个主题包含一篇新闻摘要和至少两篇新闻文档。
3.2 评价指标
目前,多文档摘要任务的评价指标主要有Rouge和基于信息理论的评价标准。Rouge是一个评估指标的集合,是许多自然语言处理,如机器翻译、单文档摘要和多文档摘要任务等最基本的度量方法之一。通过将自动生成的摘要与一组相对应的人工编写的参考文献逐词进行比较,获得预测/基准事实的相似性评分。其评价原理是计算生成的摘要与参考摘要重叠的n-gram的召回率来衡量生成摘要质量,值越大,生成的摘要质量越高。常用指标有Rouge-1,Rouge-2,其计算公式如下

(24)
其中,分子中的Countmatch(gramn) 表示生成摘要中与参考摘要中相同n元数目,分母中的Count(gramn) 为参考摘要中总的n元数目。
为了更好评价摘要,本文还采用了Rouge-L评价指标,Rouge-L指标表达的是匹配两个文本单元之间的最长公共序列,其计算公式如下
(25)
其中,LCS(X,Y) 是X和Y的最长公共子序列的长度,m表示参考摘要长度。
3.3 实验环境及参数设置
本文实验环境及参数设置见表1。

表1 实验环境及参数设置
3.4 实验结果与分析
为了验证coverage机制对于基于指针生成网络的多文档生成式摘要的有效性,设置实验2和实验3;为了验证在多文档生成式摘要任务中指针生成网络较Transformer模型的优越性,设置实验1和实验3;为了验证在指针生成网络中采用Transformer结构进行特征提取的有效性,设置实验3和实验4;为了验证融合段落注意力机制的Transformer-PGN模型的有效性,设置实验4和实验5。具体实验内容如下:
实验1:采用Transformer模型在WeiboSum数据集上进行多文档生成式摘要任务,实验名称记为Transformer。
实验2:采用融合注意力机制的指针网络在WeiboSum数据集上进行多文档摘要任务,实验名称记为PGN(wo coverage)。
实验3:采用See等[8]提出的融合coverage机制的指针生成网络在WeiboSum数据集上进行多文档摘要任务,实验名称记为PGN。
实验4:采用本文提出的基于Transformer(未融合段落注意力机制)和指针生成网络的多文档生成式摘要模型WeiboSum数据集上进行多文档摘要任务,实验名称记为Transformer-PGN(wo paragragh attention)。
实验5:采用本文提出的基于Transformer(融合段落注意力机制)和指针生成网络的多文档生成式摘要模型WeiboSum数据集上进行多文档摘要任务,实验名称记为Transformer-PGN。
5组实验的结果如图5和表2所示。

表2 各模型实验结果
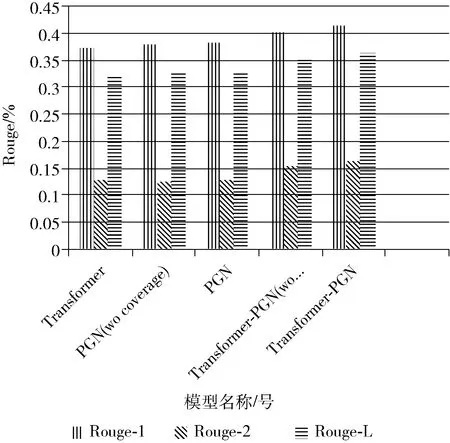
图5 各模型实验结果
为了验证coverage机制对于基于指针生成网络的多文档生成式摘要的有效性,进行实验2(PGN wo coverage)和实验3(PGN)的对比实验,实验3(PGN)在实验2(PGN wo coverage)的基础上增加了coverage机制。增加coverage机制的指针生成网络模型在Rouge-1、Rouge-2和Rouge-L上较未采用coverage机制的指针生成网络模型都有略微提升,说明coverage机制可以提高基于指针生成网络的多文档生成式摘要的效果。
为了验证在多文档生成式摘要任务中指针生成网络较Transformer模型的优越性,设置实验1(Transformer)和实验3(PGN)的对比实验。实验结果表明,指针生成网络在Rouge-1上较Transformer模型提升了0.9%,在Rouge-L上较Transformer模型提升了0.6%,在Rouge-2上于Transformer模型效果相同,说明在WeiboSum数据集上的多文档生成式摘要任务中,指针生成网络优于Transformer模型。
为了验证在指针生成网络中融合Transformer结构进行特征提取的有效性,设置实验3(PGN)和实验4(Transformer wo paragraph attention)的对比实验。实验结果表明,融合Transformer结构的指针生成网络较仅使用指针生成网络在Rouge-1、Rouge-2和Rouge-L上均提升2%以上,说明在LSTM网络的基础上,融合Transformer结构可以进行更深层次的特征提取。
为了验证融合段落注意力机制的Transformer-PGN模型的有效性,设置实验4(Transformer wo paragraph attention)和实验5(Transformer-PGN)的对比实验。增加段落注意力机制的Transformer-PGN模型较未使用段落注意力的模型在Rouge-1上提升了1.2%,在Rouge-L上提升了1.3%,在Rouge-2上提升了0.9%,说明了段落注意力机制可以实现对中文文本特征的更深层次抽取和对跨文档关系的有效表达,使得模型对原文的理解更加充分,从而在多文档生成式摘要任务中能够有效提升模型性能。
综上所述,融合段落注意力机制的Transformer-PGN模型在Rouge-1、Rouge-2和Rouge-L上均高于其它4个模型。采用融合段落注意力机制的Transformer结构对中文文本进行编码,可以对原文的上下文理解更加充分,生成语义信息更丰富的上下文向量;指针网络可以更好的逐词生成摘要;覆盖率机制可以有效解决生成摘要词语重复问题。显然,本文提出的模型在所有实验方法中效果最优,能够结合上下文和段落关系对多文档充分建模,更适合于多文档生成式摘要任务,较Transformer模型在3个指标上均提升了3个百分点以上,充分验证了本文所提方法的可行性和有效性。
4 结束语
本文针对中文新闻多文档摘要文本特征抽取不充分、无法捕获跨文档关系和生成摘要内容重复问题,提出了一种面向中文新闻文本的多文档生成式摘要模型Transfor-mer-PGN,使用融合段落注意力机制的Transformer结构和指针生成网络,最后结合coverage机制避免重复问题。实验结果表明,Transformer-PGN模型在中文新闻多文档摘要任务中,Rouge评测分数均高于其它4个模型,生成的摘要结果更接近标准摘要,同时能有效减少生成重复内容的问题,具有更高的正确性。未来将尝试结合强化学习提升模型性能[15]。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
娃娃画报(2019年5期)2019-06-17 16:58:10
散文诗(2017年17期)2018-01-31 02:34:11
广东第二课堂·小学(2017年9期)2017-09-28 14:51:06
信息安全研究(2016年4期)2016-12-01 06:06:54
读写算(下)(2016年11期)2016-05-04 03:44:07
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电测与仪表(2015年5期)2015-04-09 11:30:42
