
基于深度学习的医患舆情多维演化仿真分析
2023-10-10 10:38蒋知义
计算机工程与应用 2023年19期
谭 旭,吴 璞,蒋知义,邹 凯,吕 欣
1.湘潭大学 公共管理学院,湖南 湘潭 411105
2.深圳信息职业技术学院 素质赋能中心,广东 深圳 518172
3.国防科技大学 系统工程学院,长沙 410076
2021年3月11日,十三届全国人大四次会议表决通过了关于国民经济和社会发展第十四个五年规划和2035 年远景目标纲要[1],提出全面推进健康中国建设,统筹发展和安全,建设更高水平的平安中国;加快数字化发展,建设数字中国。据《中国医师执业状况白皮书(2017年)》数据显示,当前平安中国建设在医疗服务方面还不够系统和完善,不同程度的医疗纠纷、医患冲突等事件频频发生[2]。同时数字中国建设促进了互联网应用的井喷式增长,但也掀起了网络舆论的热潮。根据中国互联网络信息中心(CNNⅠC)发布的第47次《中国互联网络发展状况统计报告》,截至2020年12月,我国网民规模达9.89亿,使用手机上网的比例达99.7%[3]。紧张的医患关系和快速传播的网络载体助推医患舆情的发酵和蔓延,影响整个社会的稳定和谐,亟待政府部门妥善解决。
当前许多学者对于医患关系的法律制度构建[4-5]、管理模式探索[6-7]、传媒传播机理探究[8-10]、评价决策分析[11]等方面的研究较为广泛。围绕以医患关系为主体的社交媒体网络舆情分析的研究较为缺乏。随着大数据、人工智能技术的爆发式发展,网络舆情已成为衡量主流民众表达情绪的晴雨表,能有效表征医患关系的演化趋势及内涵特点,因此对社交媒体平台的文本进行情感分析能够直观地反映出网民的真实情感倾向。目前文本情感分析主要基于传统机器学习[12-14]和深度学习方法[15-17]。由于传统机器学习在情感分类任务中不能有效利用上下文文本语义信息,因此影响其分类的准确性。较之传统的机器学习,BERT(bidirectional encoder representation from transformers)预训练模型(pre-trained model)摆脱了复杂特征工程的束缚,通过注意力机制[18]使模型充分学习上下文语义信息,从而实现更精准的情感分类结果,并通过微调在自然语言处理的下游任务中取得较好结果,是目前应用最广泛且效果显著的深度学习预训练模型[19]。
虽然BERT在情感分类任务上表现突出,但在主题维度的挖掘和时间序列数据的预测方面稍显不足。为了多维度且更细粒度地探析情感演化,通过主题挖掘(topic mining)能够从海量文本信息中识别出关键词与核心主题[20],其中LDA模型[21]能取得良好的主题挖掘效果且具有灵活的可扩展性[22-24],适合与其他模型相结合。ARⅠMA模型是在ARMA模型[25]的基础上进行差分处理建构的,其具有结构简单、方便操作、预测速度快等特点,相对于其他时间序列预测方法更适合实际应用[26]。
综上,为了深度理解我国医患关系的演化趋势和公众的关注焦点,为政府部门健全医患舆情风险预警与应对机制提供科学合理的实证分析结论。本文拟通过模型构建部分进行LDA-BERT 医患舆情多维演化分析建模和ARⅠMA 时间序列预测建模。再通过实验与分析,验证模型的分类和预测效果,并从粗粒度和细粒度两个层面对全国医患舆情分布和年度医患舆情演化进行深入剖析,得到医患舆情地区、时间、主题、未来趋势的多维度刻画,最后给出实证分析结论。本研究契合政府部门对医患舆情的现实管控需求,对构建和谐医患关系、保持社会和谐稳定具有重要的现实意义。
1 模型的构建
为了深入剖析医患舆情演化,本文分别从地区、时间、主题三个维度解析医患舆情演化过程,并对医患舆情的正负向情感及总的情感演化进行预测。如图1为本文所构建的医患舆情多维演化分析及预测模型框架。

图1 医患舆情多维演化分析及预测模型框架Fig.1 Framework of doctor-patient public opinion multi-dimensional analysis and prediction
1.1 LDA-BERT医患舆情多维演化分析建模
为提升BERT 模型的情感分类精度以获得高质量的舆情演化分析效果,增加BERT模型主题维度的语义信息,不仅从粗粒度层面直观分析医患舆情全国地区分布情况,而且从结合了主题的细粒度层面对年度医患舆情的演化进行剖析,实现了对医患舆情地区、时间、主题下的多维度分析。本文将LDA 模型主题抽取技术与BERT 模型予以融合,以期达到在不同主题下精确表征情感演化过程,包括LDA模型主题提取和BERT模型情感倾向识别两个阶段,具体流程如图2所示。
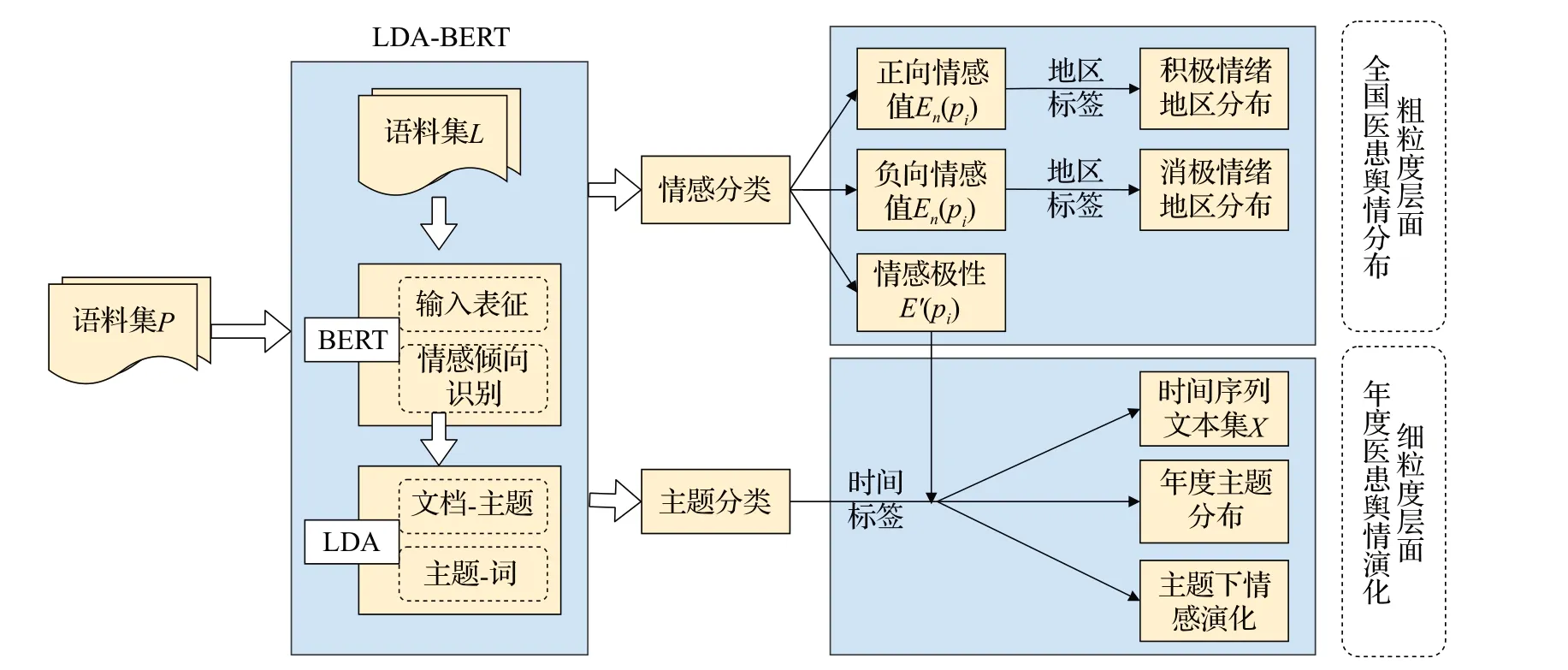
图2 LDA-BERT医患舆情多维演化分析建模流程Fig.2 LDA-BERT modeling process for doctor-patient public opinion multi-dimensional analysis
针对文档的主题提取,给定文档集P={p1,p2,…,pN},其中,pi(i=1,2,…,N)为若干词条组成的文本,假设主题集为T={T1,T2,…,TL} ,词语集为W={w1,w2,…,wM}。通过将文档集中每篇文档的主题以概率分布的形式给出,分别得到“文档-主题”概率分布θp和“主题-词”概率分布φt。其中,θp和φt分别满足以α和β的超参数的Dirichlet分布,如式(1)和式(2)所示:
其中,Γ(⋅)为Gamma函数,θp,l表示主题Tl在文档p中的概率分布,φl,m表示词语wm在主题Tl中的概率分布。
利用Gibbs 采样,可得到“文档-主题”概率θp,l和“主题-词”概率φl,m,如式(3)和式(4)所表达:
其中,表示词语w被分配给主题Tl的频数,表示文档p分配给Tl的词语数。
而后为了实现情感的识别,本文拟采用如图3所示的BERT[16]模型,主要包含输入层、双向Transformer 编码层和输出层。BERT模型输入时会在词向量表示的文本的句首前添加字符[CLS],句尾后添加字符[SEP],并用[MASK]进行句中内容的随机遮盖。在初始词向量的基础上,通过Token、Segment 和Position Embeddings 叠加嵌入来增强表达,充分刻画每一个Token与句子的特征。基于双向Transformer 架构的编码层,能够充分学习文本语义与上下文之间的语义关系。再引入注意力机制,对文本特征进行提取,将获取到的特征信息进行如式(5)所示的加权处理:

图3 BERT情感分类模型Fig.3 BERT model for sentiment classification
其中,Q、K、V为输入向量矩阵,dk是输入向量K的维度大小。通过softmax 函数进行归一化处理,得到当前单词在每个句子中每个单位位置的表示程度,并对V进行加权。特征信息的权重越大,表明其在情感分类任务中越重要。BERT模型在输出时的文本语义融合了整个文本上下文的语义信息。本文在BERT 原有模型的基础上,在下游任务中构建了情感分类器,用于执行情感分类任务(如表1 所示)。每个文档记为:{pi,score:{Ep(pi),En(pi)},label:E′(pi)},其中pi为第i个文档,score为情感倾向值,label为该文档的情感倾向标签。

表1 情感分类器的标签设置Table 1 Label setting for sentiment classifier
由此,改进后的LDA-BERT多维演化算法模型步骤如下:
步骤1数据预处理与语料集词典构建。输入医患舆情文本语料集P,对语料集P进行分词、去停用词等预处理,构建语料词典。
步骤2LDA主题数确定及主题抽取。通过计算不同主题个数并结合可视化来进行文本主题分类,确定LDA主题最佳个数K。通过主题抽取得到每一个文档pi对应的主题Tl的“文档-主题”概率分布θp,l、每一个主题Tl对应的词语wm的“主题-词”概率分布φl,m,确定文本语料集中文档所属的主题及各主题下的词语分布。
步骤3进行BERT 的输入表征和情感分类器构建。输入标注语料集L,通过BERT模型将输入语料进行文本的向量化表示,句首添加字符[CLS]、句尾添加字符[SEP]、字符[MASK]在句中以一定概率随机出现;然后执行MLM(masked language model)、NSP(next sentence prediction)任务;预训练模型的损失主要在MLM、NSP中,因此两个任务联合学习的损失函数如式(6)所示:
其中,θ是BERT中Encoder部分的参数,θ1、θ2分别是两个任务中的Encoder 参数;基于标注数据集对BERTbase预训练模型下游任务中加入新的处理类,用于执行SC(sentiment classification)任务。
步骤4BERT 情感分类深度预训练和微调。设置预训练和微调阶段参数:学习率、epoch训练次数、batch大小、最大序列长度、初始化参数等。为避免训练过程出现过拟合现象,采用Adam算法计算最佳学习率。输出epoch训练结果并迁移至微调模型中,输入语料集P,经过下游SC 任务计算出各语料集中每个文档pi的情感倾向信息{pi,score:{Ep(pi),En(pi)},label:E′(pi)}。
步骤5将步骤4 中的每个文档pi的情感倾向信息中添加地区标签得到{pi,score:{Ep(pi),En(pi)},label:E′(pi),location}从粗粒度层面对全国医患舆情分布进行分析;将步骤2中生成的“文档-主题”分步添加到每个文档pi的情感倾向信息并融入各文档对应的时间标签得到{pi,score:{Ep(pi),En(pi)},label:E′(pi),theme,time},并从细粒度层面对年度医患舆情演化进行剖析。
1.2 ARIMA医患舆情时间序列预测建模
根据1.1节步骤5中的每个文档pi的情感倾向信息,分别构建时间序列总文本集XSUM={time,Num(pi)},正向情感时间序列,负向情感时间序列,时间是按年份/季度来计量的。假设X={X1,X2,…,Xt},为得到平稳时间序列进行差分处理,那么Xt的d阶差分Yt=(1-B)dXt,其中B为滞后算子。Yt服从ARMA(p,q)模型,则Xt是符合ARIMA(p,d,q)模型过程的。自回归过程如式(7)所示:
其中,Yt为时间序列文本集Xt的差分值;μ1,μ2,…,μp为该方程的自回归系数;ut为服从均值为0、方差为σ2的正态分布且在不同时刻的值互不相关的白噪声过程;滑动平均过程如式(8)所示:
其中,δ1,δ2,…,δq为该方程的滑动平均系数;γt为白噪声序列。
由此可得到ARMA模型数学表达式(9):
ARⅠMA时间序列建模分析步骤如下:
步骤1拆分训练集和测试集。对构建的医患舆情时间序列X(包括时间序列总文本集XSUM、正向情感时间序列Xp、负向情感时间序列Xn)均拆分为以2016年至2020年的数据为训练集,2021年1月至6月的数据为测试集。
步骤2时间序列平稳性检验。对非平稳医患舆情时间序列X,经过d次差分得到平稳时间序列Yt。
步骤3ARⅠMA模型的识别与定阶。根据自相关函数(ACF)与偏自相关函数(PACF),初步识别模型中p与q的可能取值。再基于AⅠC 准则、BⅠC 准则和HQⅠC准则进行模型定阶,计算出各自对应的值,选取三者值达到最小的那一组作为理想阶数ARMA(p,q)。
步骤4白噪声与相关性检验。对差分后的平稳序列进行纯随机性检验,判断序列是否为白噪声序列。并对ARMA(p,q)模型所产生的残差做德宾-沃森(D-W)检验,判断残差的自相关性。
步骤5模型参数估计。采用最小二乘法估计模型的参数μ和δ,对t+1 时刻进行预测,公式如式(10)所示:
步骤6检验模型性能。用测试集对模型预测结果进行检验,计算总发文量、正负向情感的平均绝对百分比误差(MAPE)[27]和对称平均绝对百分比误差(SMAPE),由此分别计算三者的平均误差率。
2 仿真实验分析
2.1 数据来源
为深度探析近年来医患关系现实情况及医患舆情演化趋势,本文以新浪微博社交平台为数据源,构建基于Python 的网络爬虫框架。在遵循网络爬虫规则的前提下,通过高级搜索在“医患关系”“暴力伤医”话题下爬取了2016 年1 月1 日至2021 年6 月10 日的发帖和评论内容,共计99 841条。经过数据预处理后最终得到数据81 203条,即医患舆情文本语料集P为81 203条。对医患舆情文本语料集进行词云图可视化,如图4 所示,发现医患舆情主要聚焦于暴力伤医、医患关系、医者仁心、伤医事件等方面。预训练语料集L来自新浪微博公开正负情感标注数据集约12万条(正负向情感标注各6万条),按9∶1∶1 的比例将预训练语料集L拆分为训练集95 991条,测试集12 000条,验证集12 000条。

图4 医患舆情主题词词云Fig.4 Theme word clouds of doctor-patient public opinion
2.2 全国医患舆情分布
为剖析医患关系的本质,本文从宏观维度以近6年的医患文本数据为切入口,呈现我国医患关系在全国范围内地区分布差异性及其正负向情感偏向程度,利用LDA-BERT 医患舆情多维演化分析模型进行粗粒度层面的分析。根据1.1 节算法中的步骤3 在BERT-base 模型的基础上构建BERT 情感分类器,输入语料集L,执行步骤4 预训练过程,设置初始学习率为2E-5,最大序列长度为128,epoch训练次数为30次。通过训练迭代了8 999步得到模型的AUC值为0.979 2,loss值为0.06。为对比本文算法的情感分类效果,采用文本情感分类经典模型TextCNN作为分类基线模型。基于2.1节语料集L进行训练,训练结果如表2所示。通过实验对比能够清晰地看出,LDA-BERT情感分类模型效果突出。

表2 情感分类结果对比Table 2 Comparison results of sentiment classification
由此,将训练好的模型迁移到情感分类微调模型中,输入医患舆情文本语料集P。通过模型进行情感值计算和情感极性分类。找到语料集P中各文档对应的ⅠD 建构新的URL 来获取对应的地区标签,并将标签与各语料集中每个文档pi的正向情感值Ep(pi)和负向情感值En(pi)对应,可以得到时空维度下全国医患舆情分布情况,分别如图5、图6所示。

图5 正向情感全国地区分布图Fig.5 Regional distribution map of positive sentiment

图6 负向情感全国地区分布图Fig.6 Regional distribution map of negative sentiment
如图5 和图6 分别为全国34 个省份的医患舆情正负向情感地区分布情况,其中,图5 能够直观看出贵州省在医患舆情上表现最突出的积极情绪,其次是黑龙江省。图6 能够清晰看出最具消极情绪的微博用户多分布在甘肃省,其次为辽宁省和宁夏自治区。医患舆情在地区分布上具有明显的差异性,地区间的差异影响着公众对医患关系的认知,进而影响着医患关系的发展。因此,对于医患舆情管控方面,针对地区差异要有所侧重。对于地区间的医疗资源的不均衡,也应有所调整。
2.3 年度医患舆情演化
为更细腻地刻画近6 年来国内医患关系的变化细节,借助本文LDA-BERT混合模型的多维度智能分析和可视化呈现,从网络舆情的视角探寻总体情感极性的演化情况,如图7所示。根据1.1节算法的步骤1进行数据预处理,采用中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词表进行更为精确的停词处理。将生成的词典经过doc2bow 计算每个不同单词出现的次数,将单词转化成整数ⅠD,并将结果作为稀疏向量返回,生成语料。训练TFⅠDF模型[28]并生成TFⅠDF 矩阵,选择α=‘auto’,β=0.01 的先验参数,对LDA模型进行训练,经过迭代计算,K=4 时,困惑度最小,主题数最优。结合gensim调用api实现LDA的可视化交互分析。通过pyLDAvis 可视化得到图8 主题分布情况。验证主题数K=4 时主题抽取分布较为均匀合理。图8 中左侧部分表示医患舆情语料集的四个主题分布,圆的大小表示每个主题出现频率的大小,圆与圆之间的距离远近表示主题间的相似性,可以看到主题4与其余三个主题之间距离较近,关系较为密切。图8右侧部分表示λ=1 时四个主题中排名前三十的词语分布。其中λ越接近1,词语与主题的相关性越高。从图中可以发现,与主题最为密切相关的词语主要集中在四个层面:医患主体层面,如“医生”“医院”“患者”等;法律惩治层面,如“律师”“法律”“严惩”等;医疗纠纷层面,如“医疗”“医闹”“看病”等;新闻报道层面,如“新闻”“卫健委”“人民日报”等。抽取各主题下排前10的词语,得到医患舆情“主题-词”分布,见表3所示。

表3 医患舆情的“主题-词”分布结果Table 3 “Theme-word”distribution of doctor-patient public opinion

图7 不同年度下医患舆情总体情感极性演化趋势Fig.7 Sentiment evolution trend of doctor-patient public opinion in different years

图8 主题分布寻优结果Fig.8 Optimization results of theme distribution
根据表3,按照概率大小分布,主题1概率最高的关键词是“医生”,主题2概率最高的关键词分别为“医疗”“患者”,主题3、4概率最高分别为“医院”“医患”。将四个主题分别命名为“医生”“患者”“医院”“医患关系”。
为了时序地演化医患舆情发展态势,分析不同主题下的情感趋势分布如图9 所示。在四个主题的整体趋势上,舆情情感呈波动状态,在2019年第四季度和2020年第一季度正负情感都处于较高态势,在2020 年第二季度之后正向情感开始高于负向情感,与2019 年底爆发的新冠疫情有关,疫情期间对于医护人员支援武汉的各种正面报道,给公众重新树立起医护人员医者仁心、无私奉献的形象,对于缓解医患关系具有重要意义,因此在疫情之后医患舆情首次出现正向情感高于负向情感。各主题在2017年第四季度情感差异较为明显。其中,“医生”主题下正负情感相近,“患者”主题下正负情感差异最为明显,“医院”主题下和近年的趋势较为接近,“医患关系”主题下正向情感态度最低。这说明公众对于“患者”与“医患关系”持消极态度,主要是对于患者袭医伤医造成各种医闹事件的不满。
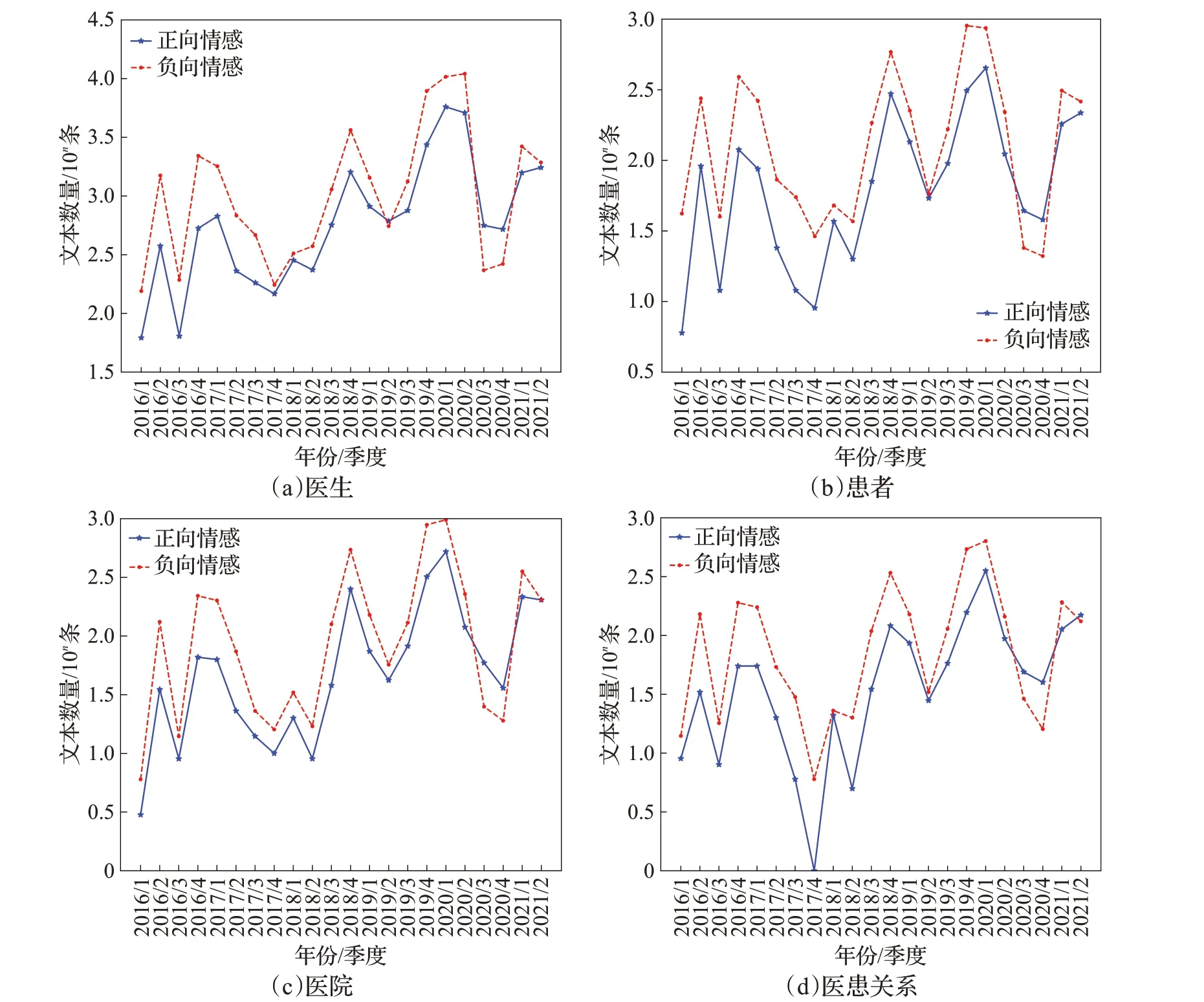
图9 不同主题下医患舆情情感演化趋势图Fig.9 Sentiment evolution trend diagram of doctor-patient public opinion under different themes
为探析各年度主题词分布,对2016—2021 各年度进行主题词抽取并进行词云图可视化分析得到图10。由图10中近6年来主题词词云展示,将各年度主题分别归纳为:法治监管、医闹伤医、病人救治、医疗纠纷、护医措施、理解医生。发现医患关系中的关注主体由对患者主体的关注转为对医生主体的关注。结合年度整体情感演化趋势(图7)不难发现,公众对于医患关系的关注与重视是呈现波动上升的,而对于医患关系的情感纠葛从开始的“医闹伤医”“医疗纠纷”到最近的“保护医生”“理解医生”是趋于缓和的发展态势。同时,各年度主题也反映了在医患关系中需要在法律层面和护医措施上作出改进。

图10 2016—2021年度医患舆情主题词云分析结果Fig.10 Theme word cloud analysis results of doctor-patient public opinion from 2016 to 2021
2.4 医患舆情情感预测分析
为进一步探寻医患舆情情感演化态势,通过对医患舆情情感走势进行科学合理的前瞻和预判,帮助政府部门更好地管控社交媒体平台的网络舆情,从而为制定相应舆情防范策略提供合理的理论参考。根据1.1节算法中的步骤5,得到时间维度上的舆情情感分析结果,代入1.2节算法中的ARⅠMA模型进行预测,确定不同参数下预测效果,分别计算平均绝对百分比误差(MAPE)和对称平均绝对百分比误差(SMAPE),如表4所示。由此确定ARⅠMA模型的阶数为(1,1,0)时,误差最小。总发文量预测的MAPE值为9.46%、SMAPE值为14.15%,正向情感预测的MAPE值为11.15%、SMAPE值为14.82%,负向情感预测的MAPE 值为6.72%、SMAPE 值为11.2%。由此得到医患舆情预测模型的平均误差率不超过11.25%,三者的预测趋势如图11所示,可以发现预测结果与真实结果虽然存在一定范围的滞后性,但是整体的演化趋势是一致的,能够较好地预判医患舆情未来发展趋势。

表4 不同参数下医患舆情情感预测误差对比Table 4 Sentiment prediction error comparison of doctor-patient public opinion under different parameters

图11 医患舆情情感预测对比分析Fig.11 Comparison analysis of sentiment prediction for doctor-patient public opinion
根据图11 可以看出,总发文量与正负情感骤升的区间为新冠疫情暴发时期,其余区间数据总体上在一个范围内波动,但2021 年之后预测的趋势仍然处于缓慢上升态势。对比图11(b)与(c)发现,医患舆情负向情感从高于正向情感到逐渐趋于持平,差距逐渐减小,说明医患关系有缓和迹象,但医患关系依旧是一个亟待解决和关注的问题。
3 结语
本文围绕医患关系这个国内持续讨论的热门话题展开研究。从网络舆情的角度获取互联网复杂语境下大规模医患舆情文本数据,通过构建LDA-BERT-ARⅠMA混合深度学习模型来探寻医患舆情的多维度演化过程,并从粗粒度和细粒度两个维度深度剖析了医患舆情在不同地区、主题、时间层面的情感演化趋势并进行未来情感走势预测。本文能够较为完整地展现2016 年至2021 年医患舆情情感演化和公众对于医患关系话题下重点关注的主题。实证分析表明:(1)从地区分布来看,医患舆情地域分布上的情感差异明显,政府部门可根据地区特色进行针对性干预和监管。(2)从主题分布来看,医患舆情关注焦点在法治监管、医疗纠纷、护医措施等层面,相关部门在法制监管的力度和广度方面还需加强,对于护医措施方面应明确公安机关、医院、医生和患者不同主体的责任与义务。(3)从舆情的演化与预测来看,未来一段时间负向情感与正向情感差距适当减少,医患关系有缓和迹象,但仍需重视和监管负向情感舆情态势。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
海外华文教育(2016年1期)2017-01-20
信息安全研究(2016年4期)2016-12-01
当代教育理论与实践(2015年9期)2015-12-16
中国卫生(2014年12期)2014-11-12
中国卫生(2014年12期)2014-11-12
中国卫生(2014年10期)2014-11-12
中国卫生(2014年8期)2014-11-12
