
生成对抗网络与文本图像生成方法综述
2023-10-10 10:38:10赖丽娜周龙龙饶季勇徐天阳宋晓宁
计算机工程与应用 2023年19期
赖丽娜,米 瑜,周龙龙,饶季勇,徐天阳,宋晓宁
江南大学 人工智能与计算机学院,江苏 无锡 214122
近些年,随着深度学习理论技术的蓬勃发展,计算机视觉和图像自动化处理技术的研究已获得显著的创新和应用的突破。2014 年,Goodfellow 等[1]首次提出生成对抗网络(generative adversarial network,GAN)作为一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。2017年后,基于生成对抗网络的深度机器学习方法,已经被广泛地使用在文本描述到图像生成的技术中,并形成目标属性描述的高度区分和可泛化特点。通过使用文本描述生成一个直观的可视化图像,可以引用与当前对象、属性信息、空间位置和关联关系等密集语义信息,为支持复杂多样的场景实现奠定良好基础,例如文本建模、智能人机交互、视觉障碍者协助、智能问答、机器翻译等方面。
文本生成图像方法主要采用自然语言与图像集特征的映射方式,根据自然语言描述生成对应并具有足够视觉细节的图像,且在语义上与文本的描述保持一致,利用语言属性智能化实现视觉图像的通用性表达。为使生成的图像具有高度真实感,已有工作对GAN 做了广泛研究。GAN 包括了生成网络、判别网络和对抗网络,其中最主要的就是生成器和判别器。生成器负责根据随机噪声生成内容,而判别器负责给出生成图像和真实图像的匹配概率,并不断地交替训练,以满足真实度的要求。文本图像生成可以在计算机视觉领域解决多种问题。本文总结强调了基于GAN的文本图像生成领域的发展现状及发展历程,通过对文本编码器、文本直接合成图像、文本引导图像合成等多维度多模型的对比和分析,全面总结和分析了模型的特点,客观地提出了该领域目前研究的不足以及未来可能的发展方向。
本综述主要关注于回顾最近的相关工作,旨在分析使用生成对抗网络解决文本图像生成问题。为了提供清晰的路径,将GAN 组织归纳为四个主要类别。首先对GAN 和文本图像生成做了基础介绍;总结归纳了四种基础的GAN,强调它们各自特点;然后,总结了基于基础GAN的文本图像生成,讨论了模型和体系结构;回顾了基础GAN 以及基于基础GAN 的文本到图像合成性能指标和比较;最后,总结并概述了文本到图像生成领域的发展思路。
1 介绍
1.1 GAN介绍
GAN[1]主要由生成器和判别器构成。算法流程可总结为固定一方训练另一方。第一步:固定生成器G,训练判别器D。第二步:固定判别器D,训练生成器G。在图像生成研究方面,近年来流行的深度生成模型可以归结为三类:自回归模型(ARM)[2]、生成对抗网络(GAN)[3-12]和变分自动编码器(VAE)[13-14]。GAN的典型应用:
(1)生成数据[15]。GAN能够从大量的无标注数据中无监督地学习到一个具备生成各种形态(图像、语音、语言等)数据能力的函数(生成器)。
(2)图像超分辨率[16]。SRGAN[16]基于相似性感知方法提出了一种新的损失函数,有效解决了图像重建后丢失高频细节的问题,并使生成的高分辨率图像视觉效果更好。
(3)图像翻译和风格迁移[12,17]:由于GAN 的自主学习和生成随机样本的优势,以及降低了对训练样本的要求,使得GAN在图像风格迁移领域取得了一定成就。
(4)跨模态图像生成[18-19]。文本生成图像是GAN在跨模态图像生成上最主流也是最成熟的应用,GAN 本身超强的分布学习能力使得GAN可以建立文本到图像的条件分布,生成语义一致的图像。
1.2 基于GAN的文本图像生成
为实现文本图像生成,需要对文本信息进行语义、特征提取。在提取过程中用到了自然语言处理的方法。自然语言处理将文本进行编码,提取文本中的重要属性。但传统方法直接利用线性编码的方式,对文本信号进行映射。但是随着数据维度的增加,计算量将呈指数级增长。
近些年,自然语言高速发展,已有多种技术及模型(如图1)[20-24]。从Word2vec[25]到GPT-2[26],这些模型都是只考虑自然语言这种单一模态内部潜在的规律,虽然在语言的数据降维、特征保持、语义提取、因果推断等方面取得了一定成功,但并没有建立自然语言与其他模态之间的信息交互。例如:文本生成图片时,使用Bert[27-28]提取的自然语言的特征不能与使用CNN[29]提取的图像特征相匹配,从而生成的图片不能体现语义一致性,甚至出现错误的情况[30]。
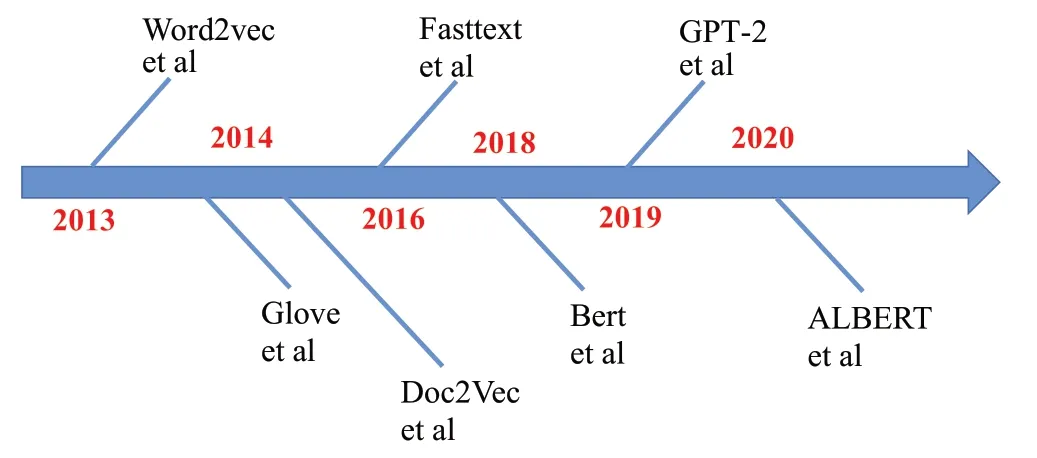
图1 文本图像生成领域代表性模型Fig.1 Representative models in text image synthesis field
在早期,文本图像生成主要通过监督学习和搜索相结合的方式进行,通过使用关键字(或关键短语)和图像之间的相关性识别信息。然后这些单元将搜索以文本为条件的相关性最高的图像,最终根据文本和图像优化图片布局。这种方法通常涉及多个领域的相关知识,包括自然语言处理、计算机视觉、计算机图形学等。传统的文本图像生成主要是缺乏生成新图像的能力,只能改变给定图像的特征。
为了解决生成图像定制化的问题,GAN 可以通过文本描述来指定要生成的图像类型。在文本生成图像中,GAN的判别器首先判断生成图像的合理性,当生成的图像合理之后,再训练图像与文本是否匹配。为了使判别模型能够拥有判断文本与图像是否匹配的能力,在训练时除了使用<假图,描述>和<真图,匹配描述>的样本外[31],添加了第三种样本即<真图,不匹配描述>。这种训练范式的目标函数如下所示:
其中,x表示真图,x̂表示假图,s表示匹配描述,ŝ表示不匹配描述。
2 基于功能的基础GAN的分类
本章提出了一种分类法,将基础GAN 模型分成四大类:语义增强GAN、可增长式GAN、多样性增强GAN和清晰度增强GAN(如图2)。其中语义增强GAN可保证文本到图像的一致性,可增长式GAN使训练稳定,多样性增强GAN使得生成图像丰富,清晰度增强GAN使得生成的图像质量高。
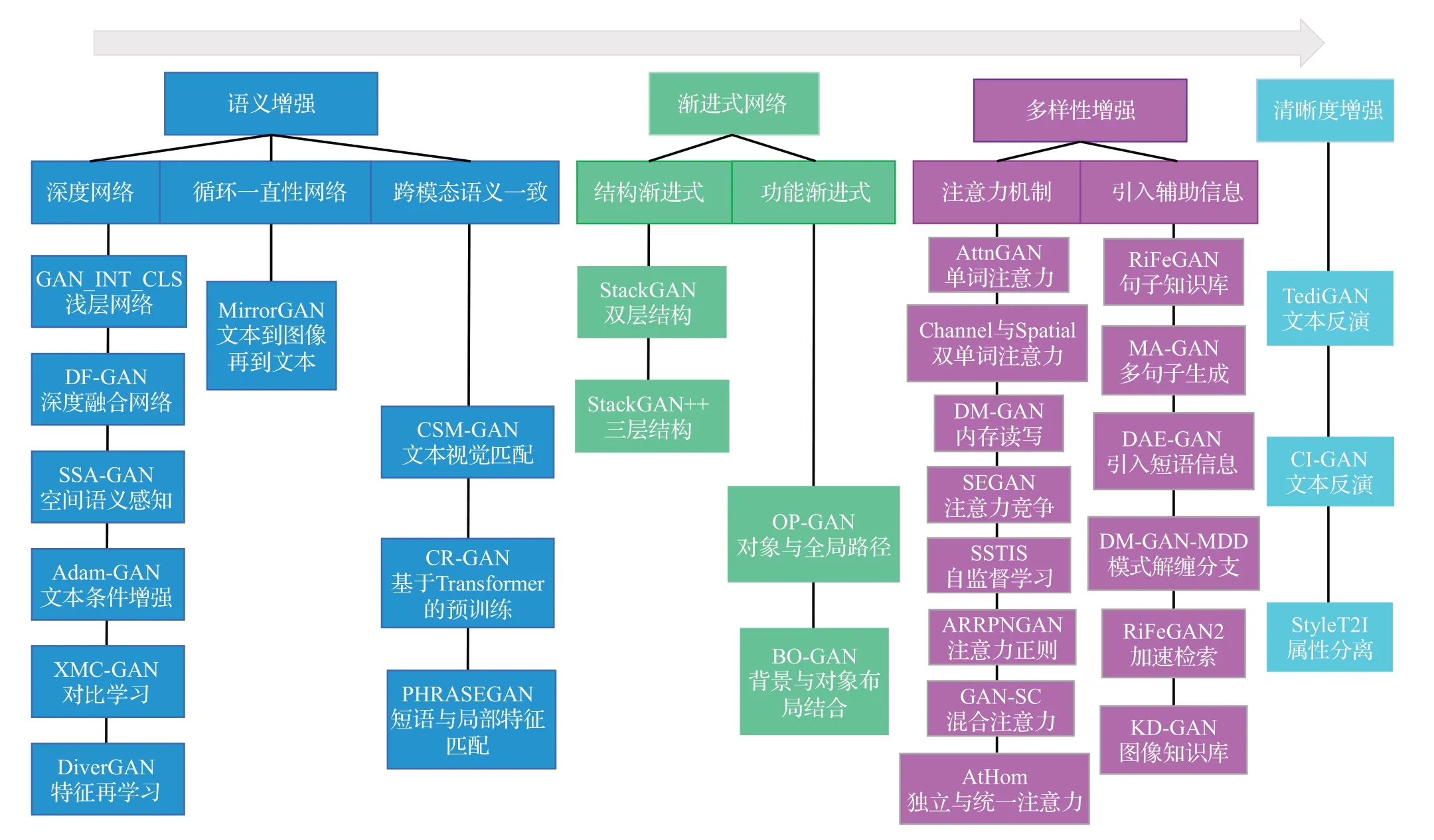
图2 各类方法间的联系与区别Fig.2 Connection and difference between various methods
2.1 语义增强GAN
语义增强GAN[32]代表了用于文本到图像合成的GAN框架的比较早期的作品,这一部分的GAN 主要专注于确保生成的图像在语义上与输入文本相关。然而,语义相关性是一个相对主观的衡量标准,每种图像本身都有丰富的语义与解释。因此,许多GAN 从不同的角度被提出用以增强文本到图像的生成。在这一节中,将具体回顾一种经典的方法——DCGAN[6]和SAGAN[12],它通常作为文本图像生成的主干(backbone)参与到各种复杂的GAN中进行训练[33]。
2.1.1 深度卷积生成对抗网络(DCGAN)
在原始的GAN[1]模型中,生成器和判别器都是浅层模型。为了生成分辨率更高的图像,需要更深的模型。2016年,Ⅰndico公司的Radford等[6]提出了DCGAN(deep convolutional GAN)模型,它代表了使用GAN进行文本图像生成的许多先驱工作(如图3)。该模型是GAN 的一个变体,在网络架构上改进了原始GAN,即在生成器和判别器中均使用深度卷积神经网络(convolutional neural network,CNN)[29]替换原始GAN的全连接神经网络(fully connected netural network,FCN),并用递归神经网络(recursive neural network,RNN)提取文本特征。具体来讲,DCGAN[6]的生成器和判别器用卷积层替换池化层。生成器先使用反卷积进行上采样,然后将生成的图像输送到判别器中,判别器再通过带有步长(stride)的卷积提取特征,提升文本到生成图像的语义正确性。其次,为避免初始化网络参数不佳的问题,并使训练过程更稳定,DCGAN[6]在生成器和判别器上都使用批归一化层(batch normalization)帮助梯度[34]在深层网络中的反传[35],适当增加初始化差,也缓解了“模式崩溃”问题,使得最终图像的多样性增强。然而,直接将批归一化层应用到所有层也会产生样本震荡和模型不稳定等问题,因此DCGAN[6]在生成器的输出层和判别器的输入层中取消了批归一化层,以此增加模型训练的稳定性。
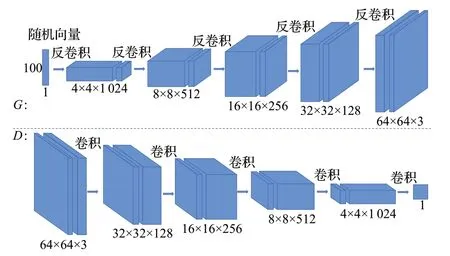
图3 DCGAN的网络结构Fig.3 Network structure of DCGAN
2.1.2 循环生成对抗网络(CycleGAN)
与DCGAN[6]不同,CycleGAN(cycle-consistent GAN)[12]可以实现无配对数据的训练(即在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现源到目标域的迁移)。CycleGAN[12]本质上是两个镜像对称的GAN构成的环形网络,这两个GAN共享两个生成器,并各自携带一个判别器(如图4)。在生成器处理图像的过程中,CycleGAN[12]使用了自适应层实例归一化方式(AdaLⅠN),提高了每一个像素的感知域,实现了输入像素的跳跃式传输,保护了信息传递的完整性。而判别器仅用于判断输入图像是否是某一特定域的图像,它首先用四层卷积与激活函数对图像进行特征提取和处理,最后再经过输出通道数为1 的卷积得到一个patch 的输出实现判别。它的训练过程如下:首先从域X中取出一组图像,再从域Y中取出另一组图像,以此训练生成器G:X→Y,得到生成图像G(x)后,再经过生成器F:Y→X得到F(G(x));同理有Y域到X域的转换关系G(F(y))。CycleGAN[12]通过循环一致性损失来保证生成器的输出和真实图像之间保持了内容上的相似性,以此实现高语义相关。

图4 CycleGAN的网络结构Fig.4 Network structure of CycleGAN
Base-GAN模型的机制与特点,如表1所示。

表1 Base-GAN模型的机制与特点Table 1 Mechanism and characteristics of Base-GAN models
2.2 可增长式GAN
早期的GAN 能够生成低分辨率的图像,而要生成高分辨率、高质量的图像困难重重,可增长式GAN可以解决此类问题,从低分辨率图片开始同时训练生成器和判别器,逐层增加分辨率,不断添加细节信息,最后平滑地生成高分辨率、高质量的图像。这不仅能加快训练的速度,而且极大程度地稳定了训练,生成高质量的图像。
渐进式增长生成对抗网络(progressive growing gan,PGGAN):如果直接生成大分辨率的图片,建立从初始训练的潜在空间到1 024×1 024像素的映射网络非常困难,这是因为在生成的过程中,判别器会很轻易识别出映射网络生成的“假图像”,导致映射网络缺乏收敛性。因此,PGGAN[3]通过一种渐进增长(progressive growing)的方式来训练GAN,“渐进增长”指的是先训练4×4 的网络,然后训练8×8,每个阶段增大两倍,最终达到1 024×1 024的高分辨率图像。虽然“渐进增长”能够加快训练速度,层与层之间的信息更加精细,生成图像的质量提高。但添加额外层会造成对损失函数的影响,使GAN 需要花费额外的时间重新达到收敛状态,影响模型训练的效率。为解决此问题,PGGAN[3]通过平滑过渡技术,将更大一级的网络融合进低一级的网络,使得高一级的比例渐渐变大,低一级的比例渐渐减小,从而平滑地增强新增层(如图5)。这样的逐层训练既加快了训练速度,又提高了训练稳定性,使得生成的图像质量变高。

图5 PGGAN的网络结构Fig.5 Network structure of PGGAN
2.3 多样性增强GAN
虽然可增长式GAN能够保证GAN的稳定训练,使生成图像与真实图像存在较小偏差的图像,也会导致生成图像特征单一的问题。而要使输出图像多样化,使图像低维度表征被最大化表达,且不能降低训练的稳定性,则需要兼顾样本的保真性和多样性[37]。这就是多样性增强GAN 的目的。这样生成的图像不仅与语义相关,而且具有不同的类型和视觉外观。
2.3.1 双判别器生成对抗网络(D2GAN)
D2GAN(dual discriminator GAN)[5]既可以高效地避免模式崩溃问题又可以扩展到庞大的数据集(如图6)。通过结合KL和反KL散度生成一个统一的目标函数,从而利用了两种散度的互补性,有效地在多模式下分散预估密度。D2GAN[5]有两个判别器:D1和D2,两个判别器在与一个生成器一起进行极大极小的博弈同时,一个判别器会给符合分布的数据样本给予高奖励,而另外一个判别器更偏向于生成器生成的数据。生成器将同时欺骗两个判别器。当训练的两个判别器最优时,优化D2GAN[5]的生成器可以让原始数据和生成器产生的数据之间的KL 散度和反向KL 散度最小化,最小化目标函数的损失,从而有效地避免“模式崩溃”的问题[38]。实验结果表明,D2GAN[5]可以在保持生成样本质量的同时提高样本的多样性。更重要的是,这种方法可以扩展到更大规模的数据集(ⅠmageNet)[39],并保持生成图像的多样性和高质量。

图6 D2GAN的网络结构Fig.6 Network structure of D2GAN
由于单判别器判别性能不佳,有可能会导致误判。2022年,申瑞彩等[40]提出使用选择性集成学习思想的生成对抗网络模型将判别器集成,这些判别器各自具有不同的网络结构,并在集成判别网络中引入具有动态调整基判别网络投票权重的多数投票策略,对集成判别网络的判别结果进行投票,有效地促进了模型的收敛、解决了生成样本多样性差等问题。
2.3.2 基于自注意力的生成对抗网络(SAGAN)
传统的卷积方法(如PGGAN[3])仅仅根据低分辨率特征图中的空间局部点生成高分辨率细节,然而卷积算子有一个局域接受域,距离较远的关系只能经过几个卷积层进行联系,不利于学习长期依赖关系。且大多GAN多注重纹理细节而非整体的几何结构,因而SAGAN(self-attention GAN)[11]为生成器和判别器均引入了自注意力机制,用于捕获全局依赖性,有效地捕获了相隔很远区域之间的关系,辅助CNN[29]建模图像中的长期依赖(如图7)。生成器可以绘制细节丰富的图像,判别器也可以更准确地对全局图像结构实施复杂的几何约束。GAN 的训练通常存在“模式崩溃”问题,也就是判别器训练的效果很好,而生成器的生成效果远远落后传统的GANs 通过判别器的正则化减缓判别器的训练速度,从而实现GAN 的整体减速。SAGAN[11]通过对判别器和生成器采用不同的学习速率,减少判别器的更新次数,以此同步生成器和判别器的学习,稳定训练。分别在生成器和判别器上采用SN、TTUR,以及不同层次的特征图(feature map)进行性能评价,在当时已有的GANs中效果最佳。
2.4 清晰度增强GAN
为增强生成图像的清晰度,必须提高图像的分辨率。因此通过急剧损失函数提升图像边缘的清晰度,或利用残差注意力网络辅助并行结构网络进行文本生成高质量的图像,并不断降低图像的损失程度,最后达到提高图像清晰度的效果。
基于样式的生成对抗网络(StyleGAN)。StyleGAN[36]由两个网络结构组成:映射网络和综合网络。映射网络通过控制生成一个中间向量来减少特征之间的相关性,相较于仅使用输入向量控制特征的方法,能够极大程度地缓解“特征纠缠”的问题[36]。综合网络通过自适应实例归一化(AdaⅠN)来精确地控制样式信息,以此保留图片的关键信息,实现风格控制的目的。
StyleGAN[36]在PGGAN[3]的基础上,加入噪声映射网络[4],通过类似于AdaⅠN的方式来添加噪声,然而使用这种方式加入噪声会导致训练不稳定,造成语义不协调、生成的图像有时包含伪影、斑点以及局部区域扭曲等问题。为解决此类问题,提出权重解调(weight demodulation)添加噪声,即将i、j、k三个维度进行归一化处理,使得改变部分细节并不会改变主体,以此保证了位移不变性[41]。同时训练出的模型能够对抗噪声网络,当发生“特征纠缠”时,映射网络会拟合出真实数据分布的形状,使得生成的图像与真实图像的偏离不会过大,很好地解决了PGGAN[3]训练中产生的“特征纠缠”问题。由实验结果可知,StyleGAN[36]在细节部分微调时不会改变主体,使得训练的稳定性更高。
3 基于功能的文本图像生成模型分类
上一章提及的各种类别的GAN将在本章进行文本图像生成方面的具体应用。收集了近几年来典型的几种文本图像生成的T2Ⅰ模型[42],并将有关的GAN列表整理,包含适用场景以及相关的性能指标。为了评估文本图像合成方法的实用价值,对不同方法的复杂度进行了分析对比。如图8所示,从GAN-ⅠNT-CLS、TAC-GAN到最近的CⅠ-GAN、StyleT2Ⅰ的模型架构图来看,图像生成模型的复杂度在不断提高,计算资源的需求也在变大。与此同时,最终生成图像的效果也越佳,语义一致性、多样性以及视觉真实性也在不断提高。
3.1 基于语义增强的文本图像生成
3.1.1 基于DCGAN的T2I模型
GAN-ⅠNT-CLS[43]是文本生成图像最早的工作(如图9),它结合了具有图像-文本匹配的判别器GAN-CLS和具有文本流形插值的GAN-ⅠNT来寻找文本与图像之间的语义匹配。GAN-ⅠNT-CLS[43]采用DCGAN[6]作为主干网络(backbone),生成图像的分辨率为64×64。

图9 GAN-ⅠNT-CLS的网络结构Fig.9 Network structure of GAN-ⅠNT-CLS
2022年,Tao等[44]提出了深度融合GAN(DF-GAN),在DCGAN[6]的基础之上引入了残差模块[45]。不同于GAN-ⅠNT-CLS[43]的是:(1)DF-GAN[44]在每一个批归一化层(batch norm)中都使用文本作为条件来对原特征图的值进行缩放、平移,堆叠的仿射变换操作使得文本语义可以充分融合到每一个生成阶段,这增强了文本语义的指导(如图10)。(2)DF-GAN[44]的判别器引入了一个零中心梯度惩罚正则项,通过添加这种正则项约束判别器的收敛。(3)DF-GAN[44]可以生成256×256分辨率的图像,并且DF-GAN[44]模型在CUB[46]和COCO[47]两个数据集上都达到了SOTA(state-of-the-art)的结果。
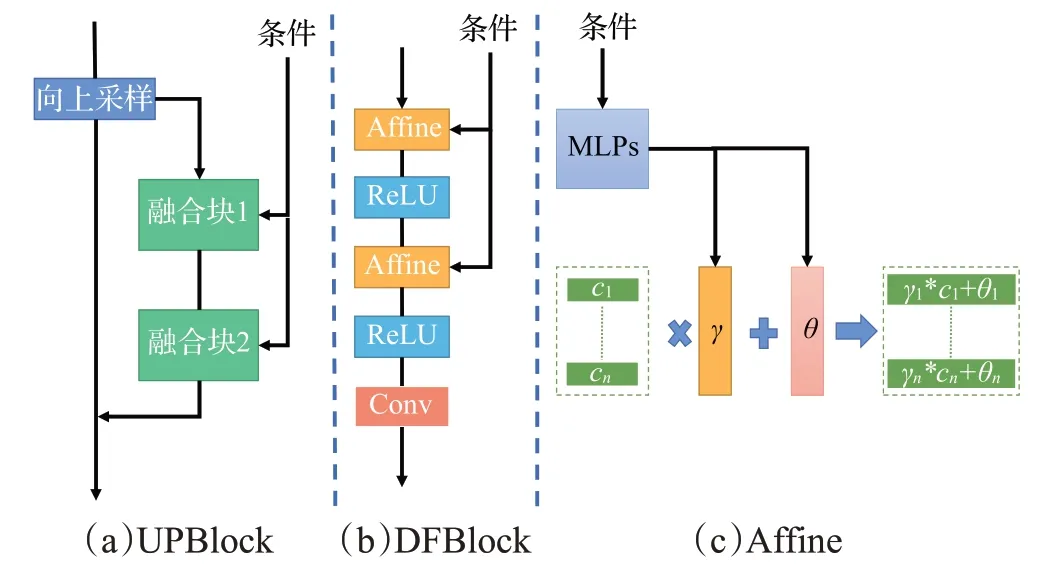
图10 DF-GAN的网络结构Fig.10 Network structure of DF-GAN
Zhang 等[48]提出的DiverGAN 认为将噪声向量经过简单的学习后直接reshape到二维的语义空间进行后续的卷积操作会损害图像的多样性,所以它将经过一次学习后的4×4 的特征图拉平,通过全连接层进行再学习,这样提高了图像多样性。
Liao等[49]基于DF-GAN[44]提出了语义空间感知GAN(SSA-GAN),SSA-GAN通过无监督的方式为每一个生成阶段制作一个语义掩码(如图11),这个语义掩码中的对象区域被高亮,非对象区域被抑制[49]。DF-GAN[44]中的经过批归一化层(batch norm)的输出特征都被乘上相同分辨率大小的语义掩码,这个操作将文本语义的控制精确到了对象级别,因此生成器可以生成语义准确的对象。

图11 SSA-GAN的网络结构Fig.11 Network structure of SSA-GAN
Wu等[50]在Adam-GAN中提出了一种补充属性信息的有效文本表示方法。首先,构造了一个属性内存来联合句子共同控制文本到图像的生成。其次,探索了两种内存更新机制,样本感知机制和样本联合机制,以动态优化广义属性内存。此外,还设计了一种属性-句子-联合条件生成器学习方案,使特征嵌入排列在多个表示之间,从而促进了跨模态网络的训练。
Zhang 等[18]提出的XMC-GAN 通过学习使用模态间(图像-文本)和模态内(图像-图像)的对比损失,帮助判别器学习更稳健和更具辨别力的特征,因此XMCGAN[18]即使在单阶段训练中也不易出现模式崩溃。在MS-COCO上,与其他三个最新模型相比,XMC-GAN[18]的FⅠD从24.70到9.33,图像质量提高了77.3%,图像-文本对齐提高了74.1%。因而XMC-GAN[18]生成放入图像保真度高,能够描绘出更清晰的物体和更连贯的场景。
Huang 等[51]设计了一个动态语义进化(DSE)模块,首先聚合历史图像特征来总结生成反馈,然后动态选择在每个阶段需要重新组合的单词,并通过动态增强或抑制不同粒度子空间的语义来重新组合它们。他们还提出了一种新的单一对抗性多阶段架构(SAMA)[51],通过消除复杂的多个对抗性训练需求,扩展了之前的结构,从而允许更多的文本-图像交互阶段,最终促进了DSE模块[51]。
上述模型均以DCGAN[6]为网络骨架,通过加深网络中的卷积和上采样层数来提高生成图像的分辨率。过深的DCGAN[6]骨架容易造成模式崩溃的问题,使得模型的训练很不稳定。另外,无论是GAN-ⅠNT-CLS[43]还是DF-GAN[44]、SSA-GAN[49]、Adam-GAN[50]等都只利用了句子信息,没有使用更细粒度的单词信息,这天然地造成生成图像的细节部分不够完美。所以这些模型只适用于生成场景单一、内容简单的图像。若能将单词信息和短语信息引入上述模型,并有效地控制图像的细节部分,将极大地提高这些模型的生成能力。
3.1.2 基于CycleGAN的T2I模型
2019 年,Qiao 等[52]基于CycleGAN[12]提出Mirror-GAN 以解决语义不相关的问题(如图12),使用一种全新的全局到局部的注意力模块,无缝嵌入到生成器,使得不同域的语义一致性得到保留。为平衡文本生成图像和图像生成文本这两个过程,基于交叉熵使用了文本语义重构损失。

图12 MirrorGAN的网络结构Fig.12 Network structure of MirrorGAN
图像生成文本属于深度学习领域中另一个难题,目前图像生成文本的研究并不成熟,特别是针对细粒度图像问题,现有的Ⅰ2T模型并不能较好地刻画图像中的细节,这造成了MirrorGAN[52]更适合生成对象明确,细节要求不高的图像。随着Ⅰ2T 的发展,MirrorGAN[52]会越来越有潜力。
T2Ⅰ-GAN模型的机制与特点,如表2所示。
3.1.3 基于跨模态语义增强的T2I模型
2021年,Tan等[19]在CSM-GAN中提出了两个模块:文本编码器模块和文本-视觉语义匹配模块。在文本编码器模块中,CSM-GAN[19]引入了文本卷积神经网络来捕获和突出文本描述中的局部视觉特征。文本-视觉语义匹配模块的目的是在全局语义嵌入空间中,使合成图像与其对应文本描述的距离比不匹配的文本描述的距离更近,这提高了语义的一致性。
2022 年,Fang 等[68]提出了一种多层次图像相似度(multi-level images similarity,MLⅠS)损失,以改进真实图像与物体特征之间的相似度度量。此外还用YOLOv3提取了真假图像中的对象,在鉴别器上引入了一个基于对象相似性的正则损失项,进一步增加了生成图像的多样性,缓解了模式崩溃。
AttnGAN[54]使用LSTM 与Ⅰnceptionv3 训练的跨模态对齐模型被大多数研究者使用[69],而CR-GAN使用更先进的CLⅠP-ViT与ResNet101训练对齐模型,这使得到的文本与图像特征更加准确,一致性更高,这对绝大多数生成模型都适用。另外,CR-GAN的鉴别器使用单词特征的均值作为条件,实验证明这对提高文本与图像的语义一致性是有效的。
Fang 等[70]在AttnGAN[54]的基础上使用了更先进的Transformer作为文本特征编码器,并与图卷积网络搭配使用,旨在建立文本短语与图像局部特征之间的联系。并将与图像局部特征对齐后的文本短语引入生成器中,进一步提高文本与图像之间的联系。Fang 等[70]还提出了一种短语-对象鉴别器,来提高所生成的场景图像的质量和短语-对象的一致性。
3.2 基于渐进式网络的文本图像生成
3.2.1 结构渐进式网络
基于PGGAN[3]渐进增长的思想,StackGAN[53]被提出。早期的GAN-ⅠNT-CLS[43]只能生成64×64的图像,想要直接基于DCGAN[6]生成256×256的图像是困难的,需要很深的网络结构,这必然存在因参数量过大而训练不稳定的问题,最终生成的图像也难以被认为是真实的。StackGAN[53]采用PGGAN[3]的递进生成模式,将文本生成图像的分辨率从64×64提高到了256×256(如图13)。具体来讲,StackGAN[53]将文本生成图像分成了两个阶段,第一阶段生成64×64 的低分辨率图像,这个阶段的实现和GAN-ⅠNT-CLS[43]相似,之后复用第一阶段的中间特征图来重复上采样生成过程,最终得到256×256的图像。StackGAN[53]采用和GAN-ⅠNT-CLS[43]相同的策略,在生成器中通过级联文本特征来引导语义图像的生成,文本与图像通过卷积进行特征融合,实现相互关联的效果[71]。由于文本数据维度较高,且数据量小,存在潜在特征空间不连续的问题,因此StackGAN[53]提出了一种条件增强的策略,不是直接将文本特征作为条件变量输入,而是产生一个额外的服从高斯分布的隐变量输出生成器。在训练过程中StackGAN[53]通过KL 散度来优化这两个线性层,最终,StackGAN[53]在CUB[46]和Oxford-102[72]两个数据集上的效果证明了条件增强的有效性。后续的很多研究工作也沿用了StackGAN[53]的条件增强策略。
StackGAN[53]虽然可以生成256×256分辨率的图像,但是网络结构简单,模型层数较少,最终生成的图像很模糊。另外,第一阶段的输出作为第二阶段的输入,这使得第二阶段非常依赖第一阶段的效果。
3.2.2 功能渐进式网络
Zhang 等[73]在AttnGAN 的基础上修改了第一和第二阶段的生成任务,将生成完整的低分辨率图像改为生成低分辨率的前景图像,这使得在生成过程的前期,模型更加关注前景对象,而对背景不做考虑,有利于生成栩栩如生的前景对象。
2022 年,Chen 等[67]提出的BO-GAN 是一种两阶段的文本生成图像方法,其中第一阶段重新设计文本到布局的过程,将背景布局与现有的对象布局相结合,第二阶段将对象知识从现有的类到图像模型转移到布局到图像的过程,以提高对象的保真度。具体地说,引入了一种基于转换器的架构作为布局生成器来学习从文本到对象和背景布局的映射,并提出了一种由文本参与的布局感知特征归一化(TL-Norm)来自适应地将对象知识转移到图像生成中。
Hinz等[74]提出的OP-GAN专门关注单个对象,同时生成符合整体图像描述的背景。该方法依赖于一个类似于的对象路径,它迭代地关注在给定当前图像描述时需要生成的所有对象。并行地,一个全局路径生成背景特征,这些背景特征随后与对象特征合并。
为了提高复杂场景的合成质量,Wu 等[75]提出了一种一步对象引导的联合Transformer解码器来同时解码图像标记和解码布局标记,可以实现改变以对象为中心的布局来控制场景。他们还引入了一个基于仿射组合的细节增强模块,以丰富更细粒度的语言相关视觉细节。
将文本生成图像,转变成文本生成布局图和布局图生成完整图像两个递进的子问题,这缓解了生成图像中对象丢失和对象模糊的问题,但同时也造成了模型复杂度的提高,训练和使用困难。
3.3 基于多样性增强的文本图像生成
D2GAN[5]在无监督的单模态任务中证明了多判别器将协同辅助生成器生成高质量多样性的图像。这也符合将复杂问题拆分的分治思想。在文本生成图像的任务中,将图像真实性与图像语义一致性拆分是当下最主流的做法[76]。具体来讲,使用无条件判别器和有条件判别器共同指导生成器生成图像,无条件判别器只关注生成图像的真实性,有条件判别器只关注图像文本的语义一致性。SAGAN[11]利用自注意力机制解决了长距离依赖问题,从而提高了生成图像的多样性。注意力机制可以有效地强化必要信息,是提高图像多样性的重要手段。此外,通过引入额外的信息补充细节,优化训练也越来越受欢迎。
3.3.1 引入注意力机制提高图像的多样性
2018 年,Xu 等[54]提出的AttnGAN 使用了三个判别器[54],分别对不同分辨率的图像进行判别(如图14)。分辨率越低,图像的细节信息越少,判别器将重点关注生成对象的结构信息,低分辨率图像只要拥有一个相似性结构,就大概率被视为真实的图像;反之,分辨率越高,图像的细节信息越多,高分辨率的判别器将更加关注细节信息,细节内容丰富的图像有较高概率被视为真实图像。AttnGAN[54]中,每一个判别器都被拆分成三部分:特征提取网络,无条件判别网络和有条件判别网络。特征提取网络用于提取图像特征,无条件判别网络根据所提取的图像特征判断输入图像的真实性,有条件判别网络根据提取的图像特征与所给的文本特征判断文本与图像的一致性。多尺度、多任务的判别器在提高生成图像多样性上的优势使得它成为文本生成图像任务中判别器模型的首选。
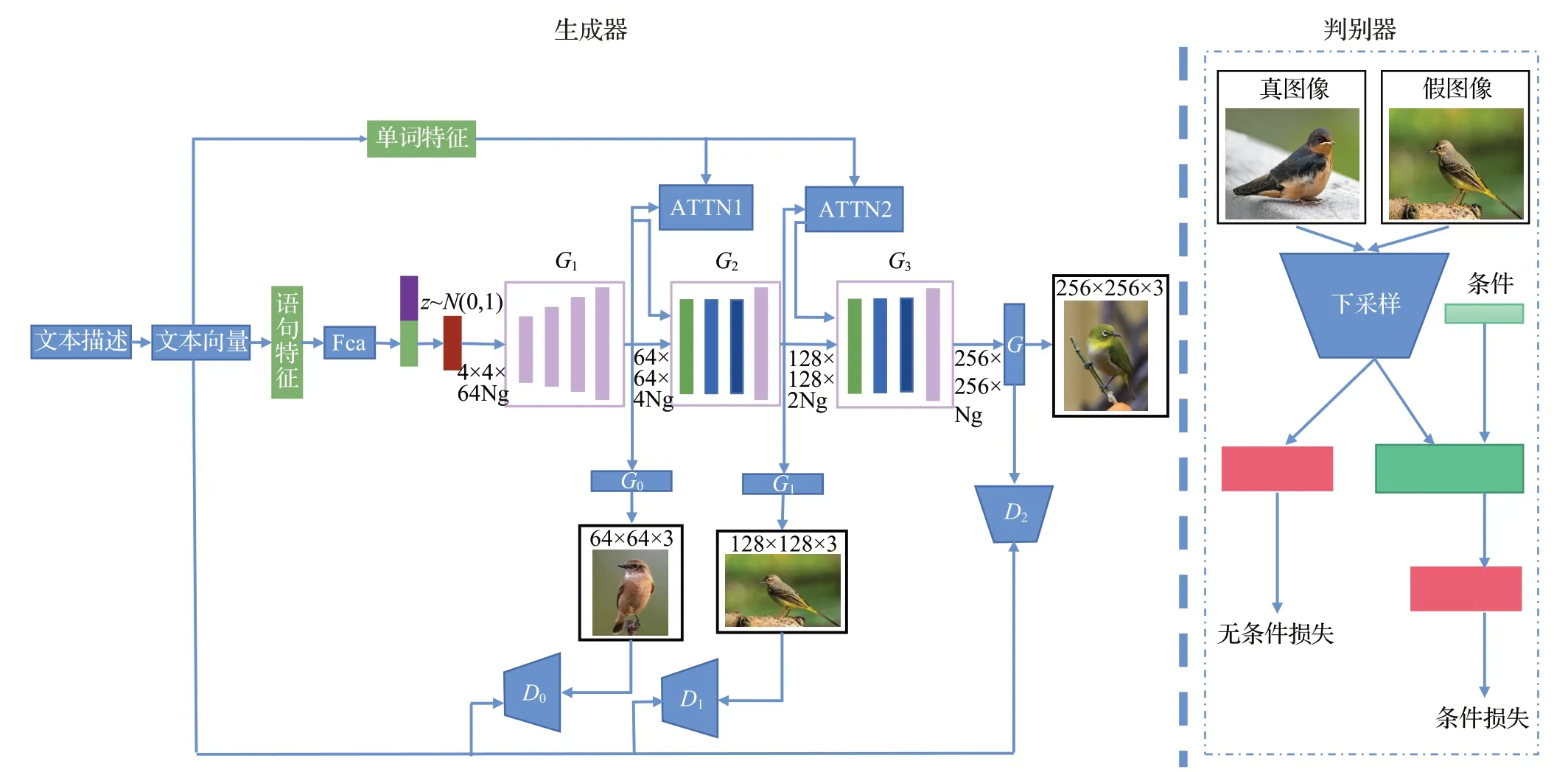
图14 AttnGAN的网络结构Fig.14 Network structure of AttnGAN
AttnGAN[54]在生成器中设计了一个单词注意力模块,该模块可以将单词信息引入生成过程,并通过迭代学习建立了一个单词到图像局部信息的映射,实现通过单词控制生成图像的局部特征。单词注意力模块首先通过计算单词特征与特征图的局部特征之间的关系矩阵,然后使用关系矩阵与单词特征为每一个像素级别的局部特征构造一个跨模态的特征表示,最终通过堆叠的卷积操作来融合两个模态的特征,并建立单词与图像局部特征的联系。
2019 年,Zhu 等[55]提出的DM-GAN 在AttnGAN[54]的基础上设计了一个写入门,根据前一阶段的图像特征重新定义单词内容,突出重要单词的作用。此外,DM-GAN[55]还设计了一个响应门自适应地融合两个模态的特征。Lee 等[57]提出的ControlGAN 在AttnGAN[54]的基础上添加了单词通道注意力,ControlGAN[57]发现像素级别的单词注意力更关注形容词,而通道注意力更加关注名词,ControlGAN[57]使用两个单词注意力的堆叠,最终提高了生成图像的质量。Tan 等[58]提出的SEGAN在AttnGAN[54]的基础上设计了一个注意力竞争模块,对重要单词进行激励,对不重要单词进行抑制,着重强调重要单词的指导作用。
2022 年,Tan 等[77]提出的SSTⅠS 在AttnGAN[54]的基础上纳入自监督学习,以增加基于文本描述的生成图像的内容的变化。具体而言,SSTⅠS[77]的鉴别器可以识别旋转的图像,SSTⅠS中的图像的变化反过来提高了鉴别器中的学习表示,从而提高了鉴别器的分类能力。Quan 等[78]在AttnGAN[54]的基础上提出了ARRPNGAN,它利用注意力正则化方法将生成器的注意力集中在与图像特征对应的文本向量的关键部分。基于注意力的生成器可以生成高清晰度的图像。另外,它引入局域提取网络(region proposal network,RPN)和编码器机制[78]来准确地区分特征对象和复杂的背景。基于该方法的鉴别器可以通过减少背景的干扰,更精确地区分生成的图像和真实图像。在当前的文本到图像模型中通常使用批处理归一化(BN)来加速和稳定训练过程[79]。然而,BN 忽略了个体之间的特征差异和模式之间的语义关系。为了解决这个问题,Huang 等[79]提出了一种新的模块自适应语义实例归一化(adaptive semantic instance normalization,ASⅠN)。ASⅠN考虑生成图像的个体性[79],将文本语义信息引入图像归一化过程中,在生成图像与给定文本之间建立一致且语义上密切的相关性。
2023 年,Ma 等[80]提出的GAN-SC 在文本到图像的生成模块中引入了混合注意力机制,并利用单词级别的鉴别器引导生成器捕获图像的细粒度信息,从而生成高质量的图像。在跨模态相似损失部分,文献[80]通过最小化一致性对抗和分类损失来减少文本与图像之间的语义差异。
2022年,Shi等[81]开发了两个注意力模块,分别从独立模态和统一模态中提取关系。第一个是独立模态注意模块(ⅠAM),它旨在找出生成图像中语义上重要的区域,并提取文本中的信息上下文。第二个模块是统一语义空间注意模块(UAM),用来求出提取的文本上下文与生成图像中的基本区域之间的关系。特别是,为了使文本和图像的语义特征在统一的语义空间中更接近,AtHom 利用一个额外的鉴别器来区分两种不同模式的同态训练模式[81]。
多鉴别器之间的协同关系一直没有严格的定义,如何搭配有条件和无条件损失间的比重也无法精准地把控。所以优化多鉴别器之间的协作关系,将是未来多鉴别器模型的一个重要研究方向。此外,跨模态注意力机制虽然可以有效地关注一些重要的细节信息,但会引入额外的资源消耗,随着分辨率的提高,注意力模块的资源消耗将会呈指数级增长。跨模态注意力机制也存在多模态信息之间粒度不匹配、不对齐等问题,如何更好地对齐多模态信息是制约多模态注意力的关键。
3.3.2 引入额外信息提高图像的多样性
2020 年,Cheng 等[60]提出的RiFeGAN 将数据集的所有文本当作一个文本知识库,在图像生成阶段,从知识库中选择最接近候选文本的辅助文本作为补充,然后使用自注意嵌入混合模块融合文本。直观地说,更多的文本可以为生成模型提供更多的信息,从而生成的图像可以包含更多的细节。2021年,Cheng等[82]提出的RiFeGAN2利用特定领域的约束模型来限制文本的搜索范围,然后使用基于注意力的标题匹配模型来基于约束先验知识细化兼容的候选文本。与RiFeGAN相比[60],RiFeGAN2可以在运行得更快的同时提供更好的结果[82],将检索的时间复杂度降低了两个数量级。Yang 等[65]提出的MA-GAN使用多个句子一起生成一张图像。该方法不仅通过探索描述同一图像的不同句子之间的语义相关性,提高了生成质量,而且保证了相关句子的生成相似性。Ruan 等[62]提出的DAE-GAN 引入额外的短语信息,从多个粒度对句子级、单词级和短语级的文本信息进行综合编码,然后在两阶段生成的初始阶段生成带有句子级嵌入的低分辨率图像。在优化阶段,将短语级特征作为中心视觉、单词级特征作为周边视觉,最后设计了相应的匹配损失函数来确保文本-图像语义的一致性。Peng等[64]提出的KD-GAN构建了一个图像知识库,在生成过程中通过文本检索相似的图像,并将相似的图像作为参考知识引入生成器的生成过程。引入参考知识不仅提高了生成图像的质量,而且提高了生成图像与输入文本的语义一致性。Feng 等[56]提出的DM-GAN-MD在鉴别器上引入一个模式解缠的分支,使鉴别器可以分离样式和内容。提取的内容部分的公共表示可以使鉴别器更有效地捕获文本-图像的相关性,而提取的样式部分的模式特定表示可以直接转移到其他图像上。
2022年,Li等[83]将真实图像的数据集作为图像知识库,在生成过程中通过文本或者单词在数据库中检索相似的图像,检索到的相似图像在生成模型的每个阶段被调制,并融合进生成图像中,这种处理可以极大地提高生成图像的质量和多样性。显而易见这种处理使得单纯的文本到图像生成变成了<文本,图像>到图像的生成,不提倡这种处理方式。
引入额外的信息是目前最有效的提高生成图像质量和多样性的方法。额外信息可以是细粒度的单词,短语,也可以是细粒度的图像切片,还可以是功能性的网络分支。引入额外的信息必定造成模型复杂化,训练困难化,对于硬件的要求非常高,很多工作只能停留在理论阶段,难以被广泛应用。但随着计算机硬件的发展,引入额外的信息来提高生成图像的质量也是不错的选择。
3.4 基于清晰度增强的文本图像生成
StyleGAN[36]在通过一个映射网络将随机噪声进行解纠缠,解纠缠的编码被称作样式编码,这些样式编码被应用在不同的上采样模块中,并被证明可以控制不同的图像细节。传统的前向生成策略是用文本作为条件控制图像的生成,但大部分的生成模型只能产生256×256分辨率的图像,生成更高分辨率的清晰图像将会带来更大计算资源的消耗,这制约了文本图像生成的发展。所以为了避免上述问题,将文本投影到StyleGAN[36]的样式空间,进而利用StyleGAN[36]生成图像成为了文本生成图像的一种新方法。
文本指导的反演GAN:Xia等[61]提出的TediGAN将真实图像与匹配文本映射到预训练的StyleGAN[36]的样式空间,并拉近它们的距离来实现文本与图像的语义一致性(如图15),然后利用StyleGAN[36]生成语义一致且多样性高的图像。与基于RNN、CNN[29]的跨模态对齐模型相比,这种将文本与真实图像投影到一个预训练的样式空间的方法更简洁,且容易训练。显而易见,预训练的StyleGAN[36]的生成能力决定了反演模型的上限;另外,在小数据集上的预训练模型会造成反演模型泛化能力不足的问题。这些问题受限于数据集规模与机器算力的发展,随着大规模数据集的产生,泛化问题将会逐渐缓解。

图15 TediGAN的网络结构Fig.15 Network structure of TediGAN
2021年,Wang等[63]提出的CⅠ-GAN通过学习文本表示和StyleGAN[36]潜在代码之间的相似模型,进一步揭示了训练后的GAN模型的潜在空间的语义。通过文本来优化反向潜码,进而可以生成具有所需语义属性的图像。
虽然在文本到图像的合成方面已经取得了极大的进展,但以前的方法并没有推广到输入文本中看不见的或代表不足的属性组成。缺乏组合性,可能会对稳健性和公平性产生严重的影响。例如,无法合成代表性不足的人口统计学群体的人脸图像。StyleT2Ⅰ提出了一种CLⅠP引导的对比损失来更好地区分不同句子之间的不同组成[84]。为了进一步提高组合性,StyleT2Ⅰ设计了一种新的语义匹配损失和空间约束来识别属性的潜在方向[84],用于预期的空间区域操作,从而更好地分离属性的潜在表示。基于识别出的潜在属性方向,StyleT2Ⅰ提出了组合属性调整来调整潜在代码,从而更好地实现图像合成的组合性[84]。
反演模型通常需要使用StyleGAN[36]在原数据集上预训练,然后才能被利用。StyleGAN 的预训练效果决定了反演模型的上限[36],这制约了反演模型的发展。此外,将文本信息投影到StyleGAN的隐空间[36],必然存在跨模态对齐问题,如何做到细粒度的对齐,也是未来一个重要的研究方向。
4 数据集及相关指标
CUB[46]数据集包含200种鸟类[85],11 788张图片。由于该数据集中80%的鸟类物体图像大小比小于0.5[72],作为预处理,裁剪所有图像,以确保鸟类的边界框具有大于0.75的物体图像大小比。Oxford-102[72]数据集包含来自102个不同类别的8 189张花的图片。为了展示该方法的泛化能力,还使用了COCO[47]数据集进行评估(如表3)。与CUB[46]和Oxford-102[72]不同,COCO[47]是一个更具挑战性的数据集。COCO 数据集[47]包含多个物体和各种背景的图像。COCO[47]中的每个图像都有5个描述,而CUB[46]和Oxford-102 数据集[72]中的每个图像都由[86]提供10个描述。在文献[43]上进行实验设置后,直接使用COCO[47]提供的训练集和验证集,同时将CUB[46]和Oxford-102[72]分割为类别不相交的训练集和测试集。使用了多模态的CelebA-HQ[3]数据集,这是一个大规模的人脸图像数据集[87],拥有30 000张高分辨率的人脸图像,每张图像都有高质量的分割掩码、草图和描述性文本。并将TediGAN[61]与图像生成的最先进方法AttnGAN[54]、ControlGAN[57]、DM-GAN[55]和DF-GAN[44]进行比较(如表4)。

表3 文本图像生成模型的评价指标(COCO和CUB)Table 3 Evaluation index of text image generation models(COCO and CUB)

表4 文本图像生成模型的评价指标(CelebA-HQ)Table 4 Evaluation index of text image generation models(CelebA-HQ)
FⅠD 距离[88]用以衡量图像质量和多样性。通过将Ⅰnception-v3 作为特征提取器,计算真实图像和生成图像在特征空间的Frechet距离对图像质量进行评估。结果显示FⅠD的值比ⅠS的值更具有鲁棒性,能够用于复杂的数据集。FⅠD 计算合成图像的分布和真实图像之间的Frechet 距离。较低的FⅠD 意味着生成的图像分布与真实图像分布之间的距离更近。FⅠD可以表述为:
式中,r、g为真实图像和合成图像的表示向量:μr、μg;∑r和∑g分别表示真实图像分布和合成图像分布的均值和协方差。
R-precision[54]用以评估生成图像与对应文本描述之间的视觉-语义相似度,即准确率。通过对提取的图像和文本特征之间的检索结果进行排序,来衡量文本描述和生成的图像之间的视觉语义相似性。除生成图像的文本描述外,还从数据集中随机抽取其他文本。然后计算图像特征和每个文本描述的文本嵌入之间的余弦相似性,并按相似性递减的顺序对文本描述进行排序。如果生成图像的真实文本描述排在前R个内,则相关。R精度越大,图像与真实文本描述越相关。继Xu 等[54]之后,使用R-precision来评估生成的图像是否很好地适应了给定的文本描述。R-precision 是通过检索给定图像查询的相关文本来衡量的。计算全局图像向量和100个候选句子向量之间的余弦距离。候选的文本描述包括R个真实值和100-R个随机选择的错误匹配描述。对于每一次查询,如果排名前R个检索描述中的r个结果是相关的,那么R-precision是r/R。实验中,用R=1来计算R-precision。将生成的图像分成10个部分进行检索,然后取结果分数的均值和标准差。R-precision计算公式如下:
其中,TP是正例预测正确的个数,FP是负例预测错误的个数。
ⅠS 分数[89]用来衡量图像质量和多样性。首先借助外部图像分类器(一般使用在ⅠmageNet 上训练好的Ⅰnception-v3网络)对质量进行评估,接着利用不同类别的概率分布的信息熵对图像多样性进行评估,ⅠS分数越高,图像的质量越好,多样性越佳。ⅠS 计算条件类分布和边缘类分布之间的KL-散度。生成的模型为所有类别输出了高度多样性的图像,每个图像显然属于特定的类别。ⅠS可以表述为:
其中,x是合成图像,y是预训练inception-v3网络预测的类标签。
LPⅠPS 即学习感知图像块相似度,也称为“感知损失”,用以度量两张图像的差别,该度量标准学习从生成图像到真实图像的反向映射,强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPⅠPS 比传统方法(比如PSNR、SSⅠM)更符合人类的感知情况。LPⅠPS 的值越低表示两张图像越相似,反之差异越大。计算公式如下:
其中,d(x,x0)为x与x0之间的距离,给定不同的基础网络,计算深度嵌入,规格化通道维度中的激活函数,用向量w缩放每个通道,取L2 距离,然后对空间维度和所有层次求平均。
Acc即预测精准度,是预测正确的样本占所有样本的比例,其中预测正确的可能有正样本也可能有负样本。通过文本和相应生成的图像之间的相似性来评估准确性。计算公式如下所示:
其中,TP是正例预测正确的个数,FP是负例预测错误的个数,TN是负例预测正确的个数,FN是正例预测错误的个数。
Real 即真实性,通过用户研究来评估,通过用户的直观感觉判断哪张照片更符合文本描述。
5 文本生成图像模型的应用
文本生成图像的研究绝大多数停留在理论阶段,真正可以实地应用的模型并不多。主要的原因有以下三点:(1)小模型的泛化性能太差,对复杂场景图的生成很难达到人类的预期。(2)只有参数量达到近千亿的超大模型才可以生成质量很好的图像(达到人类的预期)。模型的训练会消耗巨大的财力,目前国内外只有极少数公司有能力去做。(3)大模型的推理过程耗时巨大,难以部署到终端。
虽然文本到图像生成的应用难度巨大,但依然有人探索如何在精简模型的同时,尽可能地提高模型的性能。2022年,Li等[90]首次将神经搜索(neural architecture search,NAS)方法与文本到图像合成相结合,实现了NAS、GAN和Transformer的首次结合,并改进了一种使用轻量级Transformer 处理特性映射的新方法,它使Transformer 能够作为NAS 的搜索空间,并在推理的中间过程中垂直集成特性。基于神经搜索的方法对进一步提高现有模型的性能有很大的帮助。
对文本生成图像的应用的研究并不仅仅局限在模型性能上,进一步探索已有模型的潜能也是一个重要的方向。2022 年,Zhang 等[91]对正太分布的噪声空间进行解缠,分离出不同的潜码簇,这些潜码簇分别对应图像中的对象的大小、方向等,这种模态解缠的处理工作对生成模型的应用及下游工作很有帮助,在不改变文本描述的情况下可以实现对部分细节的调整。
此外,Zhang 等[92]提出了一种跨语言生成模型。大部分文本生成图像只用一种语言描述训练生成模型,而CJE-TⅠG[92]则通过在输入端引入一个多语言对齐模块,将多语言投影到一个公共空间中,使用对齐的文本与单词特征共同发挥作用来引导生成模型生成图像。这种多语言对齐模块可以添加到绝大多数现有模型中,扩展了现有模型的泛化性能及实用价值。
文本生成图像的应用虽然还未成熟,但现有的基于AttnGAN[54]的多阶段模型和基于DF-GAN[44]的单阶段模型,以及基于StyleGAN[36]反演的模型已然达到了生成简单图像的目标,可以用于简单的图像制作,但这些模型均难以生成质量合格的复杂场景图像,且这些模型只能输入较短的文本描述,大致不超过25 个英文单词。因此,文本生成图像的应用还有很长的路要走,期待早日可以开花结果。
6 结论与未来展望
随着计算机视觉和自然语言处理的高速发展,本文详细地回顾了基于生成对抗网络的文本图像生成方法。这些生成的图像通常依赖于生成对抗网络(GAN)[93]、深度卷积译码器网络和多模态[94]学习方法。本文将基于功能的基础GAN 分为四大类:语义增强GAN、可增长式GAN、多样性增强GAN和清晰度增强GAN。语义增强GAN可保证文本到图像的一致性,可增长式GAN用以稳定训练,多样性增强GAN 用以丰富生成图像的种类,清晰度增强GAN 用以提升生成图像的质量。首先介绍了各个类别代表性方法的模型和关键贡献(DCGAN[6]、StackGAN[53]、AttnGAN[54]、TediGAN[61]等),并将各个方法进行对比分析;详细说明了最常用的评估方法(ⅠS、FⅠD、R-precision等)。
尽管目前的方法已经在生成图像的质量方面以及图像与语义一致性方面有大幅提高,但仍然有很多难点亟待研究。首先,未来的工作应该集中在迭代和交互操作以及再生上,在生成更符合输入文本含义的更高分辨率图像,找到更好的自动度量标准,标准化用户研究等方面仍有很大的改进空间。其次,利用文本生成视频有很重要的研究价值,是未来的研究方向之一,但需要探索更多的语音视频评估方法。再次,由于数据集和设备内存的不足的局限性,复杂的模型不适合用于轻量型和便携式的设备上。最后,目前大多数模型以单条描述语句为研究对象,而复杂文本中的描述对象在图像中的定位,以及图像与语句之间的交互仍是一项具有挑战性的任务。因此,如何融合文本视觉表示和更复杂的视觉识别模型以及文本与图像之间的交互也是未来的重点研究方向之一。希望本文内容有助于研究人员了解该领域的前沿技术,并为进一步研究提供参考。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
现代语文(2016年21期)2016-05-25 13:13:44
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
