
跨尺度跨维度的自适应Transformer网络应用于结直肠息肉分割
2023-09-27 07:22:12梁礼明何安军李仁杰吴健
光学精密工程 2023年18期
梁礼明, 何安军, 李仁杰, 吴健
(江西理工大学 电气工程及其自动化学院,江西 赣州 341000)
1 引 言
结直肠癌是世界上最常见的高发癌症之一,具有极高的死亡率[1]。研究报告数据显示,早期结直肠腺瘤息肉可以通过简单手术予以切除,生存率高达95%。也就是说,早发现和准确诊断结直肠腺瘤息肉是有效降低死亡率的关键。但由于不同时期的结直肠息肉大小不一,形状尺度变化大、边界模糊且存在正常组织与病变区域相似度高等复杂特性[2],使得结直肠癌息肉分割面临众多挑战。
为了解决结直肠息肉难以准确分割的挑战,许多学者提出传统分割方法和基于深度学习的方法[3],传统方法主要依赖于人为选取特征,以区域生长,阈值图像和统计形状为主[4-6]。受到结直肠息肉图像病变区域复杂特性的影响,传统方法存在较大的局限性。随着深度学习的普及,卷积神经网络(Convolutional Neural Network,CNN)以强大的特征提取能力在图像处理领域开辟了新范式[7]。基于CNN结构的U型网络在生物医学语义分割任务中被广泛运用。U-Net[8]采用对称的编码-解码器结构,并在编码-解码器之间引入跳跃连接,使网络可以很好地将深层语义信息和浅层细粒度信息进行融合。由于卷积操作仅进行局部运算,难以建立远距离特征依赖关系,所以U-Net网络结构在一定程度上仍有较大的改进空间。Jha等[9]采用空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)来扩大模型感受野,嵌入SE(Squeeze and Excitation)[10]注意力机制促进通道特征信息之间的依赖关系,有效改善了息肉的分割精度,但在边缘细节上处理并不是很好。Fan等[11]使用并行部分解码器进行特征聚合,采用反向注意力模块构建区域和边界线索之间的显性关系,优化了分割结果边缘,但对小目标分割还存在漏检现象。Lou等[12]提出CaraNet,设计上下文轴向注意力模块和通道级特征金字塔模块来提高模型对小目标的分割性能,但整体流程较为复杂。
Transformer[13]结构通过捕获长距离依赖显性关系,建模全局上下文信息,在医学图像分析领域获得了出色的表现。Dai等[14]结合CNN和Transformer的优点,首次将Transformer结构应用于多模块医学图像分类任务,获得了较好的分类效果。Chen等[15]提出TransUNet,设计双边融合模块来处理不同分支的语义信息,改善了多器官和心脏图像分割任务的精度,但该结构带来了大量的浮点运算和参数,影响模型的实际应用。Wang等[16]采用金字塔视觉Transformer提取输入图像的语义信息,提出渐进式解码器来强调局部特征和强化目标信息,提升了息肉分割精度,但在未知数据集上的泛化性能较差。Wu等[17]结合Swin Transformer结构分成多阶段产生多个不同尺度特征,构建多尺度通道注意力机制和空间反向注意力机制,以提升网络学习和提取结直肠息肉各种形态特征的能力,进一步优化结直肠息肉分割结果,但该结构需要预训练权重才能发挥其效果,导致网络结构不能灵活调节。
针对结直肠息肉分割当前面临的技术挑战,本文提出一种跨尺度跨维度的自适应Transformer分割模型。该模型首先在金字塔视觉Transformer(Pyramid Vison transformer v2,PVTv2)基础上融合CNN结构,不仅能有效提取全局上下文信息,还增强了网络对局部特征的解析能力。然后设计多尺度密集并行解码模块来补充浅层网络细粒度信息和深层网络语义信息之间的语义空白。最后引入多尺度预测模块以调整不同阶段预测结果,逐步细化息肉区域的边缘结构信息。
2 方 法
2.1 研究基础
卷积神经网络(CNN)通过与图像周围像素进行点运算提高模型的局部感知能力,具有平移不变性和归纳偏差,但受到卷积核大小、网络层数以及计算资源的限制,导致捕捉全局上下文特征信息的能力不足。而Transformer结构中的多头注意力机制能有效建立短距离和远距离的特征间距,使网络能够从全局角度解析语义信息。结直肠息肉病灶区域与正常肠黏膜对比度低、边界模糊,有效处理全局语义信息和局部细节信息能对分割精度提升带来很大的帮助。最近,基于Transformer结构方法在多种视觉任务上取得了与基于CNN结构相当的性能,PVTv2[18]表现得相当出色,其核心Transformer编码模块如图1所示。图1中zi-1表示第i个Transformer编码模块经过卷积前馈层和残差连接后的输出特征图;z′i表示经线性空间自注意力层和残差连接后的输出特征图。
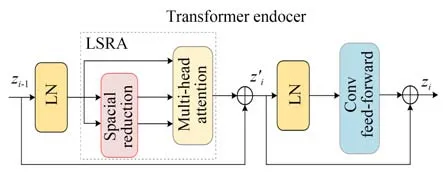
图1 核心Transformer编码模块Fig.1 Core Transformer encoding block
每个Transformer编码模块均由层归一化(Layer Normalization,LN)、线性空间自注意力层(Linear Spatial-reduction Attention Layer,LSRA)、卷积前馈层(Conv Feed-Forward,CFF)和残差连接组成,卷积前馈层由全连接层、高斯误差线性单元(Gaussion Error Linear Unit,GELU)和3×3的深度可分离卷积组成。其中,LSRA通过重塑图像结构,缩短远距离特征间距,从而增强网络捕获全局语义信息的能力。
LSRA接受三个相同维度的特征向量,分别是查询矩阵Q,键矩阵V和值矩阵K。相比于传统的多头注意力层,LSRA采用平均池化操作降低矩阵K和V的空间尺寸,在很大程度减少了计算开销。具体的计算过程如下:
其中:Concat(⋅)表示连接操作;WQj∈RCi×dhead,为线性投影参数;Ni表示第i阶段注意力层的头数,即每个头部的尺度(dhead)为表示第i阶段输出通道数;LSR(⋅)是降低输入序列(K或V)空间维度操作,其计算式为LSR(x)=Norm(Reshape(x,P)WS),其中,x∈R(HiWi)×Ci表示输入序列;P为线性池化大小,设置为7;Reshape(x,P)是将输入序列x重塑大小为P2×Ci,WS∈RCi×Ci是一种线性投影;Norm(⋅)值归一化层。
自注意力层使用位置编码方式来确定图像上下文信息,其输出结果是输出图像尺寸保持不变。当训练图像尺寸与测试图像尺寸不一致时,需要对图像进行插值操作来保持统一尺寸,而插值操作容易造成局部细节信息的丢失,导致分割结果精度下降。受到文献[19]的启发,为了改善零填充对位置编码泄露的影响,在LSRA后引入卷积前馈层。卷积前馈层计算式为:
其中:MLP(⋅)表示多层感知器;GELU(⋅)表示激活函数;DWConv3×3(⋅)表示3×3的深度可分离卷积;xin表示自注意力层的输出。
2.2 总体结构
为了减少空间归纳偏差和增强网络对上下文特征信息的有效表示,针对结直肠息肉的特点,本文提出一种跨尺度跨维度的自适应Transformer网络(Cross-Scale and Cross-Dimensional Adaptive Transformer Network,SDAFormer)应用于结直肠息肉分割,如图2所示。其网络结构主要包括编码器、混合注意力机制、多尺度密集并行解码(Multi-scale Dense Parallel Decoding,MDPD)模块和多尺度预测(Multi-Scale Prediction,MSP)模块。其中,编码器采用在ImageNet数据集上预训练的PVTv2网络模型,逐层提取结直肠息肉图像的空间信息和语义信息,输出多尺度特征图;混合注意力机制通过强调特征图的病灶部分,有效建立不同阶段,不同特征图之间的通道信息联系,以抑制背景噪声影响并为目标区域分配合适的学习权重;多尺度密集并行解码模块用于深层网络信息和浅层网络信息的互补,融合空间信息和语义信息;多尺度预测模块以可学习的方式来获取一组权重系数,对权重系数进行自适应加权加法来纠正预测错误分类结果。

图2 跨尺度跨维度的自适应Transformer网络Fig.2 Cross-scale and cross-dimensional adaptive transformer network
2.3 混合注意力机制
由于结直肠息肉图像中病灶区域的局部特征具有相关性,简单地融合浅层细粒度信息和深层语义信息,容易引入背景噪声等其他无关信息。为了自动调整不同特征之间的依赖关系,对重要特征施加合适的学习权重,在网络跳跃连接处引入空间注意力桥(Spatial Attention Bridge,SAB)模块和通道注意力桥(Channel Attention Bridge,CAB)模块[20]。相比于CBAM[21],SAB更加轻量级,能够在计算资源有限的情况下提供较好的注意力增益。CAB相对于SAB更加重量级,但在特征图的通道数较多时能够提供更好的注意力增益。
2.3.1 空间注意力桥模块
使用空间注意力桥模块来充分利用编码器不同阶段、不同尺度的特征信息,聚焦特征图中病灶部分,抑制背景噪声。算法伪代码(算法1)表示为:

Algorithm 1: Spatial attention bridge block Inputs: The input maps of the four channel attention bridge block Ci,i=1,2,3,4 Outputs: Si,i=1,2,3,4 1: χi mean=AvgPool(Ci) /*avg-pooling*/2: χi max=MaxPool(Ci)/*max-pooling*/3: χi s=Concat(hi mean,hi max)/*Concatenate the feature map odd*/4: α=Conv7×7(hc)/*7×7 convolution operation*/5: ε=σ(β)/*After sigmoid, the feature map becomeC×H×1*/6: Si=ε*Ci+Ci/*The feature map of sigmoid with the original feature and then add */End
首先将来自编码器四个阶段的输出特征图分别进行全局平均池化和全局最大池化,平均池化对结直肠息肉病灶区域进行去噪,最大池化用于凸显图像待分割的目标区域;然后拼接同一阶段池化后的特征图,将拼接后的特征图输送到权值共享的扩展卷积运算中(扩展卷积运算由一个卷积核大小为7,扩张率为3,填充量为9的卷积组成),使用Sigmoid函数生成空间注意力图,最后将生成的空间注意图以逐元素的方式与原始输入特征图相乘,并引入残差结构。图3为空间注意力桥模块示意图。
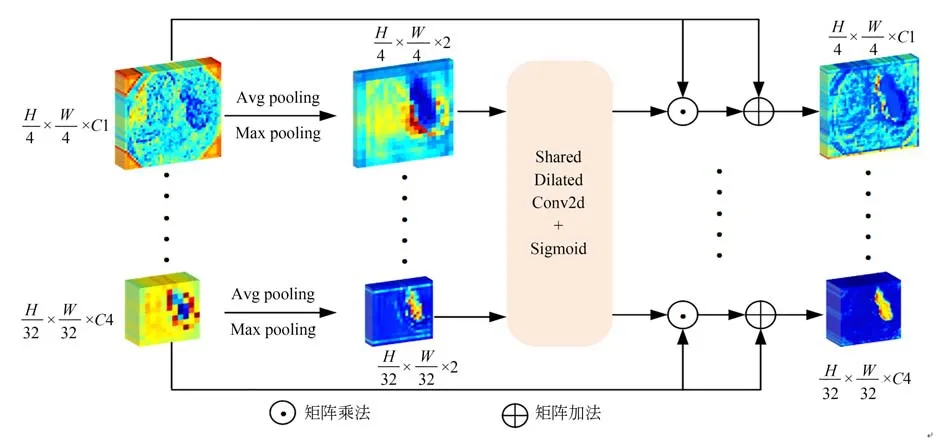
图3 空间注意力桥模块Fig.3 Spatial attention bridge block
空间注意力桥模块的具体表示为:
其中:Avg表示全局平均池化;Max表示全局最大池化;Conv7d表示7×7卷积;Ei表示第i阶段输出特征图;Concate表示拼接操作;
2.3.2 通道注意力桥模块
多阶段,多尺度信息的获取对于不同大小目标的分割起着至关重要的作用。在空间注意力桥模块后面引入通道注意力桥模块有利于建立不同阶段特征图之间的长期依赖关系,从而增强重要信息的微观表达能力。算法伪代码(算法2)表示为:
通道注意力桥模块将多阶段,多尺度信息的融合细分为局部信息融合(一维卷积操作)和全局信息融合(每个阶段都有不同的全连接层),来提供更丰富信息的通道注意力图。首先将来自SAB四个阶段特征图分别进行全局平均池化,然后拼接四个阶段池化结果得到1×1×C权重值。接着使用由一个3×3卷积核和全连接层组成多层感知器网络来促进局部信息和全局信息的交互,使用Sigmoid函数生成通道注意力图,最后将生成的通道注意图以逐元素的方式与原始输入特征图相乘,并引入残差结构。图4为通道注意力桥模块示意图。

Algorithm 2: Channel attention bridge block Inputs: The input maps of the four stagesEi,i=1,2,3,4 Outputs: Ci,i=1,2,3,4 1: hi mean=AvgPool(Ci) /*avg-pooling*/2: hc=Concat(h1 mean,h2 mean,h3 mean,h4 mean)/*Concatenate the feature map of avg-pooling*/3: β=Conv3×3(hc)/*3×3 convolution operation*/4: γ=σ(β)/*After sigmoid, the feature map becomeC×H×1*/5: Ci=γ*Ei+Ei/*The feature map of sigmoid with the original feature and then add */End

图4 通道注意力桥模块Fig.4 Channel attention bridge block
通道注意力桥模块可表示为:
其中:GAP表示全局平均池化;Concate表示拼接操作;FCi表示第i阶段全连接层;Conv1d表示3×3标准卷积。
2.4 多尺度密集并行解码模块
网络解码阶段得到不同尺度特征图,这些特征图蕴含的语义信息和空间细节信息像素相关性是不同的,通过直接上采样操作来恢复图像特征的空间细节,容易造成局部细节信息丢失[22]。因此,本文设计一种新的多尺度密集并行解码模块来对各阶段输出图像进行解码重建,其结构如图5所示。
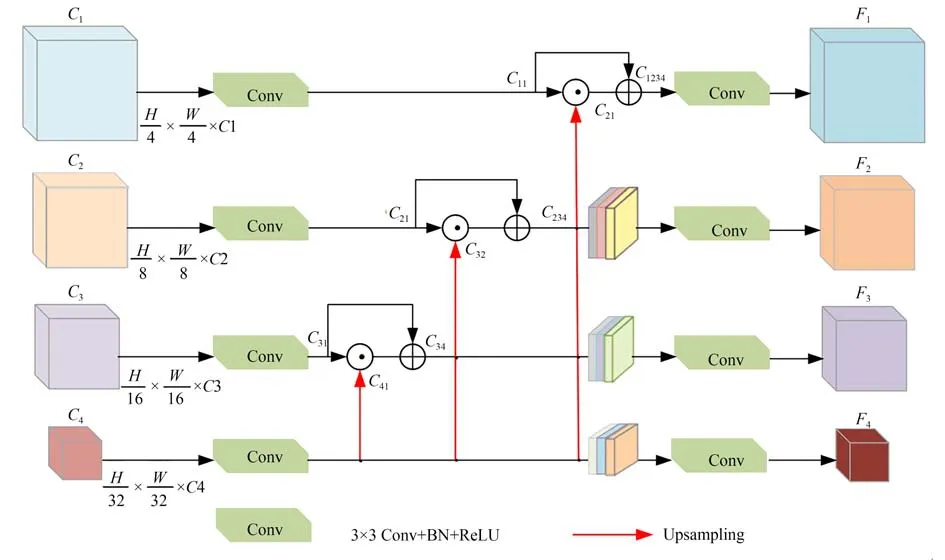
图5 多尺度密集并行解码模块Fig.5 Multi-scale dense parallel decoding block
多尺度密集并行解码模块由标准3×3卷积,批量归一化(BN)层,ReLU激活函数和上采样层组成。模块首先将高级特征图C4进行双线性插值上采样操作,使其分辨率与特征图C3相匹配,然后通过两个标准3×3卷积、批量归一化和Re-LU激活函数来传递语义结果,得到传递结果C41和C31,再将得到的结果C41与原特征图C31进行矩阵乘法并引入残差结构,最后利用卷积单元来平滑连接特征,得到第三阶段融合特征图。重复上述过程,直至融合所有阶段的输出,最终得到四个阶段的预测输出结果。
2.5 多尺度预测模块
在结直肠息肉病理图像中,病变区域通常具有不同的形状和大小,且与正常组织高度一致。由于肠黏膜特征的相似性,精细的息肉外观特征及容易被忽视。为了促进网络对边缘细节的识别能力,Fan等[11]和Lou等[12]提出反向注意力模块和轴向注意力模块减少目标边缘像素点的误分类。文献[23]提出一种多尺度预测模块,以可学习的方式获取一组权重系数整合不同阶段的预测结果,其结构如图6所示。
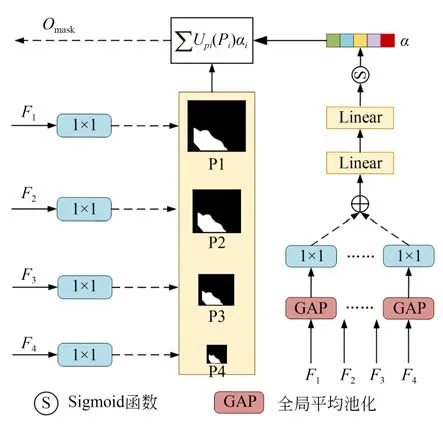
图6 多尺度预测模块Fig.6 Multi-scale prediction block
具体来说,在多尺度密集并行解码模块获得输出特征图Fi后,采用四个并行的1×1卷积和上采样(Upsampling)操作获取不同阶段对应的输出二进制掩码Pi。同时,将输出特征图Fi全局平均池化进行空间信息压缩,然后使用4个并行的1×1的卷积来匹配池化后特征的维度,将匹配后的特征图先进行信道加法融合,再通过两个连续的全连接层进一步编码,利用Sigmoid函数得到权重系数,最后采用自适应加权加法得到预测输出掩膜。
3 实验与分析
3.1 数据集和实验设置
为了验证本文模型的有效性,实验采用4个公开的结直肠息肉数据集,即CVC-ClinicDB[24]、Kvasir-SEG[25],CVC-ColonDB[26]和ETIS[27]。其中CVC-ClinicDB数据库包含612张分辨率大小为384×288的结肠镜图像;Kvasir-SEG数据集包含了1 000张结肠镜图像和分割掩膜;CVCColonDB数据集包含了380张分辨率为574×500的结肠镜图像;ETIS数据集包含了196张分辨率为1 226×996的结肠镜图像。实验训练由未经过任何数据增强随机抽取550张CVC-ClinicDB数据图像和900张Kvasir-SEG数据图像组成,测试集由剩下的62张CVC-ClinicDB数据图像、100张Kvasir-SEG数据图像、196张ETIS数据图像和380张CVC-ColonDB数据图像组成。为了方便模型训练和测试,将训练集图像统一分辨率352×352。
本实验在操作系统Windows11进行;建模基于深度学习架构Pytorch 3.9(Facebook Inc.,美国)和计算统一设备架构CUDA 12.1(Nvidia Inc.,美国)。计算机具体配置:显卡(Nvidia Ge-Fore GTX 4070 Ti GPU,Nvidia Inc.,美国)、中央处理器(Intel Core TM i5-13600KF CPU,Inter Inc.,美国)。模型使用以加权二进制交叉熵损失函数和加权交并比损失函数为基础的联合损失,采用自适应矩估计优化器(Adam),实验迭代次数50,批量大小设置为6,初始学习率5×10-5,动量设置为0.9,并使用多尺度训练策略{0.75,1,1.25}。
3.2 评估指标
本文采用Dice相似性系数、平均交并比(Mean Intersection Over Union,MIoU)、召回率(Sensitivity,SE)、精确率(Precision,PC)、F2得分和平均绝对误差(Mean Absolute Error,MAE)来对结肠息肉的分割结果进行评估。其具体计算式分别为:
其中:X为预测输出图像,Y专家标注的金标签图像,TP为预测结果中正确分类的前景像素数目,FN为预测结果中被错误分类为前景像素数目,FP为预测结果中被错误分类为背景像素数目,N为图像中的像素点数。
3.3 对比试验
为了验证本文方法在结直肠息肉数据集分割方面的优势,分别与经典医学图像分割网络UNet,EU-Net[28],PraNet和CaraNet以及最近提出基于Transformer结构的医学图像分割网络PolypPVT[21],SSFormer和MSRAFormer进行比较,实验结果如表1~表2所示。表中最优指标加粗表示。

表2 CVC-ColonDB和ETIS数据集上不同网络分割结果Tab.2 Segmentation results of different networks on CVC-ColonDB and ETIS datasets
表1给出本文模型和其他7种模型在Kvasir和CVC-ClinicDB数据集上的评估结果,表2给出本文模型和其他7种模型在CVC-ColonDB和ETIS上的评估结果,在Dice指标和MIoU指标均为最高。Dice指标是用于衡量分割结果中预测像素数量与总数量的比例,值越高表示分割结果与真实标签越接近,分割质量越高。F2得分是综合考虑召回率和精确度,相比于F1分数,F2分数更加重视召回率,值越高表示能更准确地将目标对象从背景中分割出来。表2显示,在Kvasir和CVC-ClinicDB数据集中,本文方法的Dice和F2得分分别为0.932,0.942和0.931,0.954,相比基于CNN的基础网络CaraNet,分割结果分别提高了1.4%,1.7%和0.6%,0.6%。与基于Transformer结构的PolypPVT相比,Dice指标分别提高了1.5%和0.5%。表2显示,本文方法在CVC-ColonDB和ETIS数据集上的Dice和MIoU指标分别为0.811,0.805和0.731,0.729。实验结果表明,本文方法分割效果更好,泛化性能更加,病变区域误分类更少。
表3给出了本文网络和其他7种网络的模型参数性能,以Transformer结构为基础的Polyp-PVT,SSFormer-L,MSRAformer和本文方法在分割性能指标上均高于基于CNN结构的U-Net,EUNet和PraNet。在一定程度上Transformer结构会提升网络的参数量和计算复杂度,相比于其他7种网络本文方法在参数量上获得最优,计算复杂度和单轮训练时长均获得了次优结果,分别为24.99 M,10.01 G 和 127 s。相比于基于Transformer结构MSRAformer,本文方法参数量和计算复杂度分别降低了63.26%和52.98%。相比于基于CNN结构的EUNet,本文方法参数量和计算复杂度分别降低了20.31%和18.31%。综合分析,本文方法在兼顾参数量、计算量和推理时间的情况下,获得较好的分割结果,实现了网络分割性能的提升。

表3 不同网络性能对比(CVC-ClinicDB)Tab.3 Performance comparison of different networks(CVC-ClinicDB)
图7和图8分别显示了本文方法和上述7种方法在CVC-ClinicDB,Kvasir,ETIS和CVCColonDB数据集上的分割结果,从上往下依次为原始输入图像、金标签、U-Net,EU-Net,PraNet,CaraNet,Polyp-PVT,SSFormer,MSRAFormer和本文方法。从图7~图8可以看出,在病灶区域占比较小的病理图像中,EU-Net不能很好地区分背景和前景,出现大量的误检现象。Polpy-PVT使用相似性聚合模块有效分割病灶区域占比小的病理图像,但分割大面积病灶区域时分割结果出现内部不连贯现象。SSFormer和CaraNet减少了分割结果内部不连贯情况,但分割结果边缘不平滑、出现伪影。U-Net和PraNet建模全局信息能力不足,存在大量漏检错检的现象,易将背景错分成前景。由于结直肠息肉病灶区域与正常组织对比度低,如图7第4列和图8第9列所示,U-Net,PraNet和MSRAFormer把病灶区域较深的区域当作正常组织,把正常组织较浅的区域错认为病灶部分,误检现象十分严重。同时,由于结直肠息肉的复杂特性,病灶区域常常被淹没在肠黏膜中,病灶区域变化大常常成为分割的难点,如图7第7列和图8第2列所示,EUNet,Polyp-PVT和CaraNet不能高效定位病灶区域,导致正常组织与病灶边缘分割粗糙,出现伪影。相比之下,本文方法通过Transformer编码器对全局上下文信息进行高效建模,以有效应对结直肠息肉病灶区域尺度变化大的特点,利用混合注意力机制高显病灶区域,减少背景干扰因素的影响,采用多尺度预测模块细化边缘信息,减少分割结果边缘不光滑、伪影现象。综合对比分割结果,本文方法不管是在视觉效果上还是在分割精度上均更胜一筹。
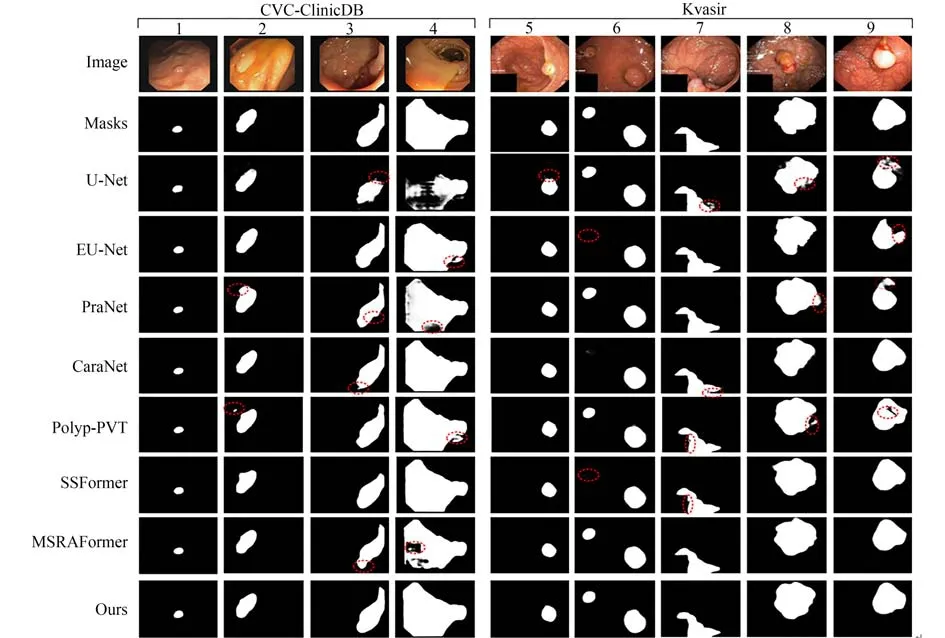
图7 Kvasir和CVC-ClinicDB数据集上不同网络分割结果Fig.7 Segmentation results of different networks on Kvasir and CVC-ClinicDB datasets
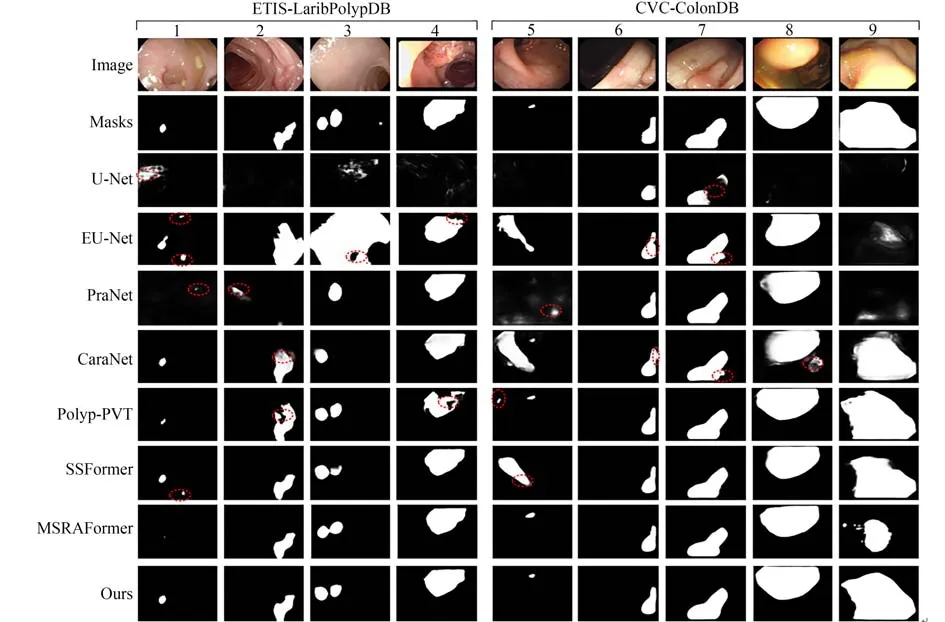
图8 CVC-ColonDB和ETIS数据集上不同网络分割结果Fig.8 Segmentation results of different networks on CVC-ColonDB and ETIS datasets
3.4 消融实验
为了探究本文方法各模块对整体模型分割性能的影响,在Kvasir和CVC-ColonDB数据集上进行消融研究。M1在分层Transformer编码器的基础上加入多尺度密集并行解码模块,M2是在M1的基础上添加空间注意力桥模块,M3是在M2的基础上添加通道注意力桥模块,M4是在M3的基础上添加多尺度预测模块,即本文所提方法。消融结果如表4所示,最优指标加粗表示。混合通道注意力机制能有效建立通道信息之间的联系,抑制背景噪声的影响,提升网络的相似性系数和平均交并比。多尺度预测模块对多尺度特征进一步挖掘边缘细节信息,纠正预测分类结果,提升网络像素精度和F2得分,消融实验进一步验证了各模块对整体模型的贡献。
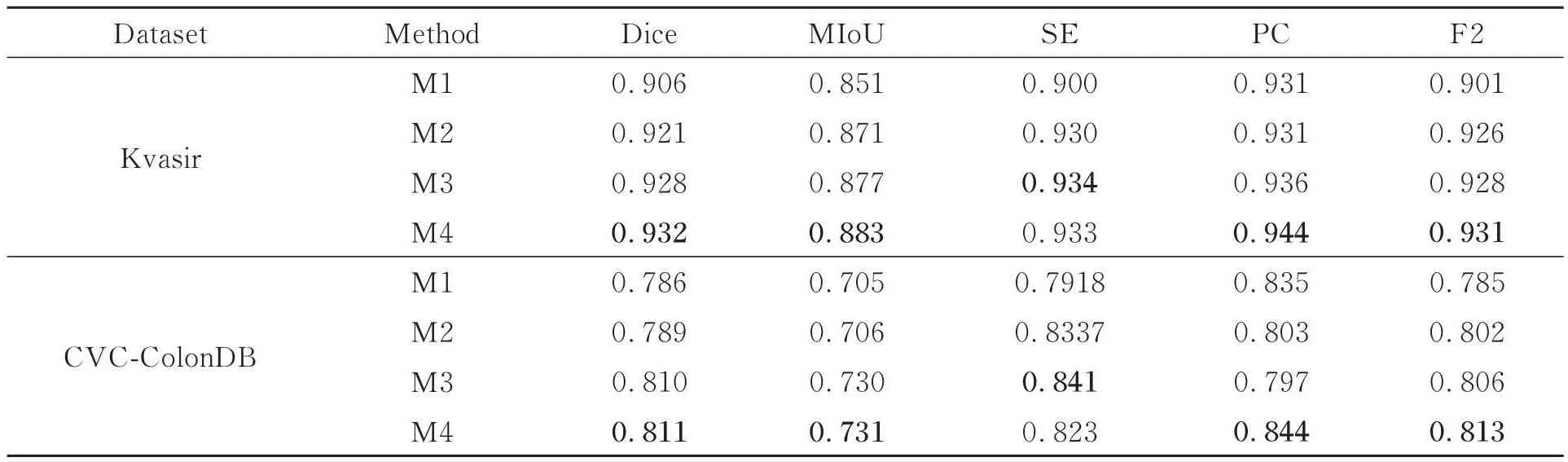
表4 各模块在Kvasir和CVC-ColonDB数据集上消融结果Tab.4 Ablation results of each module on the Kvasir and CVC-ColonDB datasets
4 结 论
本文提出跨尺度跨维度的自适应Transformer网络应用于结直肠息肉分割,有效地改善了结直肠息肉分割时边缘细节信息丢失和病灶区域误分割等问题。使用Transformer编码器提取结直肠息肉图像病灶特征,通过在网络跳跃连接处引入混合注意力机制,以减少通道维度冗余和增强模型的空间感知能力。同时设计一种新的多尺度密集并行解码模块,充分融合不同尺度的特征信息。最后利用多尺度预测模块激活病灶区域边界的特征响应,进一步优化分割结果。在CVC-ClinicDB和Kvasir-SEG数据集的Dice相似性系数分别为0.942和0.932,相比于基于Transformer结构的SSFormer分别提高了3.6%和1.4%,分割性能优于现有算法,对结直肠息肉的诊断具有一定的临床应用价值。为验证该方法的泛化性和普适性,在CVC-ColonDB和ETIS数据集上进行了验证,实验结果表明本方法在未知数据集上适应能力较强。
猜你喜欢
中国临床医学影像杂志(2021年10期)2021-11-22 07:46:44
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
家庭医学(下半月)(2020年3期)2020-05-30 12:42:10
中国生殖健康(2019年3期)2019-02-01 06:12:08
太空探索(2016年5期)2016-07-12 15:17:55
中国当代医药(2015年31期)2015-03-01 02:08:23
西南军医(2015年2期)2015-01-22 09:09:25
中华皮肤科杂志(2014年3期)2014-12-19 12:54:58
时代英语·高三(2014年5期)2014-08-26 17:01:17
中国中西医结合外科杂志(2013年3期)2013-03-11 20:05:02
