
基于深度学习的图像分割技术研究综述
2023-09-25 06:59唐璐赵英
电脑知识与技术 2023年23期
唐璐 赵英
关键词: 图像分割; 计算机视觉; 深度学习; 数据集; 评价指标
0 引言
图像分割[1]是计算机视觉中的一个重要任务,其目的是将一幅图像分割成不同的对象。在许多应用中,如图像识别[2]、目标跟踪和机器人导航等,图像分割都是一个必要的前置任务。图像分割一直是计算机视觉研究热点之一,许多传统的方法已经被提出并被广泛使用。近年来,深度学习[3]方法的发展为图像分割带来了新的突破,尤其是卷积神经网络(Convolu?tional Neural Networks,CNN) [4]的出现,使得图像分割的性能有了大幅提升。
1 传统的图像分割方法
1.1 基于阈值的方法
基于阈值的方法通常将图像中的像素值与一个固定的阈值进行比较。该方法的主要思想是根据像素值的大小将图像中的不同区域分割出来。它的主要步骤:1) 确定阈值:通过试验或根据应用场景确定一个合适的阈值,将图像中的像素值分为两类,例如背景和前景。2) 阈值分割:将图像中的每個像素值与所确定的阈值进行比较,根据比较结果将其分为两个类别。3) 后处理:进行形态学操作和噪声滤波等后处理操作,消除分割图像中的噪声和小的不连续区域。其方法简单易懂、计算量小,但由于阈值选择的固定性,对于图像中像素值变化大、光照不均匀等情况下效果较差,如果选择的阈值不合适,可能会导致图像分割结果不准确。因此,为了得到更好的分割效果,需要根据图像特点选择合适的阈值确定方法,并对阈值进行优化。
1.2 基于边缘的方法
基于区域的图像分割方法是将图像分割问题转化为区域的分割问题,将图像分成若干个不相交的区域,并将每个区域标记为属于不同类别的像素。这种方法的主要思想是将具有相似颜色、纹理、形状等特征的像素聚合成一个区域,并将区域划分为前景和背景。它的主要步骤:1) 超像素分割:将图像分割成一些超像素,每个超像素由若干个像素组成,具有相似的颜色、纹理、形状等特征。2) 特征提取:对每个超像素提取特征,如颜色直方图、纹理特征、边缘特征等。3) 区域合并:通过合并相邻的超像素来生成区域。合并的标准可以是相似度、距离或者其他特征。4) 分类:将每个区域分类为前景或背景。该方法的优点是,它可以考虑每个区域的上下文信息,从而更好地处理复杂的图像。然而,由于需要对每个区域进行分类,因此速度较慢,并且需要高质量的特征提取器和分类器。
1.4 基于聚类的方法
基于聚类的方法将像素点分为不同的聚类,每个聚类代表一种颜色或灰度值。常见的聚类算法包括K-means 和Mean-shift 算法等,K-Means 算法是一种典型的基于划分的聚类算法,也是一种无监督学习算法,对给定的样本集,用欧氏距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。Mean-shift算法是一种通用的寻找数据局部众数的搜索算法。对于给定的一定数量样本,随便选择一个点作为中心点,计算该点在一定范围之内所有点到中心点的距离向量的平均值,作为偏移均值,然后将中心点移动到偏移均值位置,通过这种不断重复的移动,可以使中心点逐步逼近到最佳位置,即选择的初始中心点会从沿一定变化方向移动到高密度中心点。基于聚类的方法计算速度快,但是需要事先确定聚类数量和聚类中心。
综上,这些方法通常不需要大量的计算资源和训练样本,但是由于特征提取和分类的过程是分离的,其分割结果可能不够精确。
2 深度学习方法
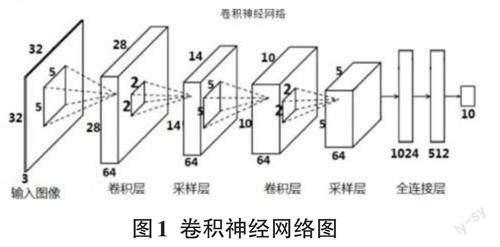
CNN是基于深度学习的图像分割方法中最常见的一种。它利用卷积操作在不同的层次提取图像特征,然后利用全连接层将特征映射到相应的分割结果。它是由输入层、卷积层、采样层(池化层)和全连接层交叉堆叠而成的前馈神经网络,使用反向传播算法进行训练,如图1。CNN有三个特性:局部连接、权重共享和汇聚。这些特性使得它具有一定程度上的平移、缩放和旋转不变性。它主要使用在图像和视频分析的各种任务上,比如图像分类、物体识别、图像分割等,其准确率也远远超出了其他的神经网络模型。它能够提取更加丰富的特征信息,具有较高的精度和鲁棒性,参数量较少,但是需要较大的计算资源和训练样本。
基于卷积神经网络的图像分割方法,相较于传统的基于阈值、边缘、区域和聚类的方法,具有更高的准确度和更强的泛化能力。其基本流程如下:1) 数据预处理:对图像进行预处理,包括图像尺寸归一化、数据增强等。2) 搭建CNN:选择适合的CNN模型,并对其进行修改以适应图像分割任务。3) 训练网络:将准备好的数据集送入网络进行训练,通过优化目标函数使网络输出的分割结果逐渐接近于真实分割结果。4) 预测分割结果:用训练好的网络对新的图像进行分割预测。基于CNN的方法具有较高的分割准确度和鲁棒性,但同时也需要大量的训练数据和计算资源。因此,在实际应用中需要考虑训练时间和硬件资源等问题。总体来说,基于CNN的图像分割方法在像素级别的目标分割任务中具有优秀的性能和广泛的应用前景。
3 数据集
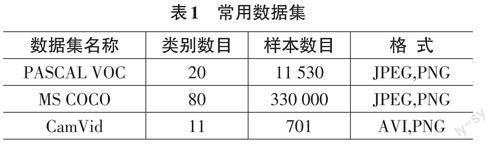
数据集的质量和数量对图像分割方法的性能和效果有很大影响。因此,选择合适的数据集非常重要。在选择数据集时,需要根据具体应用场景和算法需求进行选择,同时需要注意数据集的标注质量和数量,以及数据集的广泛使用程度等因素。此外,对于一些复杂的场景,还需要进行数据增强以增加训练数据的数量,表1对PASCAL VOC、MS COCO和CamVid 常用数据集一些基本信息进行了汇总。
PASCAL VOC:包括20个对象类别,例如人、车、动物等。数据集包括11 530个图像,每个图像都有一个语义分割标注,该数据集的标注非常准确,是评估图像分割算法的重要基准。MS COCO:包括80个对象类别,例如人、车、飞机等。数据集包括330 000个图像,每个图像都有一个实例分割标注和语义分割标注,该数据集的标注非常精细,是评估图像分割算法的重要基准。CamVid:包括11个对象类别,例如路标、行人等。数据集包括701个视频帧,每个帧都有一个像素级别的标注,该数据集是评估视频分割算法的重要基准之一。
4 评价指标
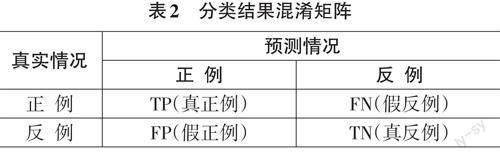
TP(True Positive) :真正例,模型预测为正例,实际是正例;FP(False Positive) :假正例,模型预测为正例,实际是反例;FN(False Negative) :假反例,模型预测为反例,实际是正例;TN(True Negative) :真反例,模型预测为反例,实际是反例;n表示类别数,如表2所示。
4.1 Mean Intersection over Union(MIoU)
MIoU是一種常用的图像分割评价指标[5],用于衡量模型在像素级别上预测结果与真实标注的重叠程度。IoU是一种常用的评价指标,可以衡量分割结果与真实标注之间的重叠程度。MIoU 即为所有类别IoU的平均值。适用于多类别分割,对不平衡数据集的鲁棒较好,但计算量较大,公式如下:
4.2 Pixel Accuracy(PA)
PA是分割准确率的一种度量方式,它表示预测的像素分类结果与真实标签的像素分类结果,相匹配的像素数占总像素数的比例。简单易懂,易于计算,但不适用于不平衡数据集,公式如下:
4.3 Precision
Precision表示模型预测为正例的所有样本中,预测正确(真实标签为正)样本的占比,公式如下:
4.4 Recall
Recall表示所有真实标签为正的样本,有多大百分比被预测出来,公式如下:
4.5 F1 Score(F1)
F1综合了Precision和Recall两个指标,是一个比较全面的评价指标。适用于不平衡数据集,不适用于样本比例不同的情况,公式如下:
5 结论
图像分割在许多领域中都有广泛的应用,如医学影像[6]、自然图像和遥感图像等。在医学影像领域中,图像分割能够帮助医生进行病变检测和诊断,如肿瘤分割和心脏分割等。在自然图像领域中,图像分割能够帮助计算机识别不同的物体,并进行目标跟踪和图像检索等。在遥感图像领域中,图像分割能够帮助计算机对地面物体进行分类和监测,如土地利用和城市规划等。然而,图像分割仍然存在一些挑战和难点。首先,图像分割需要大量的标注数据和计算资源,这在训练和应用中都是一个难点。其次,图像分割需要解决一些具体的问题,如处理图像中的噪声、模糊和边缘不清等问题。此外,不同的图像分割方法适用于不同的场景,如何选择合适的方法进行分割也是一个难点。综上所述,基于CNN的图像分割方法在图像分割领域取得了显著的进展,具有更好的性能和更高的准确度,但也存在一些缺点。未来,需要继续探索更加高效和准确的图像分割算法,以满足实际应用中的需求。
猜你喜欢
无线互联科技(2016年13期)2017-01-10
现代电子技术(2016年22期)2016-12-26
科技视界(2016年26期)2016-12-17
中国科技纵横(2016年17期)2016-11-30
商(2016年33期)2016-11-24
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
中国市场(2016年38期)2016-11-15
电脑知识与技术(2016年24期)2016-11-14
电脑知识与技术(2016年24期)2016-11-14
中国市场(2016年33期)2016-10-18
