
基于图像-文本语义一致性的文本生成图像方法
2023-09-22 06:22薛志杭许喆铭郎丛妍冯松鹤李浥东
计算机研究与发展 2023年9期
薛志杭 许喆铭 郎丛妍 冯松鹤 王 涛 李浥东
(北京交通大学计算机与信息技术学院 北京 100044)
(xzhbjtu@163.com)
近年来,基于图像及文本的跨媒体融合研究受到了广泛关注,如视觉问答[1]、图像字幕生成[2]、文本生成图像[3]等.文本生成图像(text-to-image,TTI)作为跨媒体领域的一个前沿任务,旨在通过一段自然语言文本生成与文本语义内容对应的高分辨率图像.目前,该任务已被广泛用于图像编辑、视频游戏、跨平台多媒体检索和计算机辅助设计等领域,成为当前计算机视觉和跨媒体分析领域的热门研究课题之一.其研究价值主要来源于2 个方面:1)获取图像的代价是昂贵的,而通过生成图像可以减少获取特定图像的代价;2)图像生成可以创造一些新颖的图像,而有些图像在现实生活中是无法获得的,如梵高风格的绘画作品.
在文本生成图像任务中,文本空间与图像空间之间存在较大的语义鸿沟,如何缩小这一差异已成为文本生成图像任务面临的主要挑战.针对这一问题,近年来随着生成对抗网络(generative adversarial network,GAN)[4]的出现及其在各类视觉任务上的优越表现,基于GAN 的文本生成图像方法[5-7]不断涌现并取得了一定进展.Xu 等人[5]提出了一种基于跨模态的注意力模型,该模型在文本编码器内,利用跨模态的注意力机制,对文本信息与图像信息进行交叉注意力编码和语义对齐.LeicaGAN 模型[6]、CPGAN模型[7]等通过在文本编码器中加入额外的视觉信息,将提取到的文本特征与视觉特征进行特征融合,从而缩小语义鸿沟.尽管这些方法试图减少文本与图像之间的跨模态差异,但是它们仍然存在不足.首先,在文本特征提取过程中,这些方法大多关注于文本编码器的优化,忽略了初始文本语义特征的局限性,使得模型在对齐图像与文本特征时,过分依赖于初始文本编码器的性能,忽视了具有语义一致性的生成图像对文本信息的增强作用,因而导致文本信息表征能力下降.其次,这些方法没有考虑生成目标区域间的交互,影响了生成图像质量.常见的深度卷积神经网络模型往往对小尺寸目标的识别定位能力不足[8],且训练样本集合中通常仅包含图像级标注信息[9-10],缺少目标区域级的细粒度监督信息,不利于这些深度模型对目标区域之间的关系进一步挖掘,使得前景、背景分界模糊.
针对上述2 点不足,我们创新性地提出了一种基于图像-文本语义一致性的文本生成图像方法(text-toimage generation method based on image-text semantic consistency)ITSC-GAN,其利用不同分辨率的生成图像信息对初始文本信息进行增强,并利用区域注意力机制关注图像子区域之间的内在关系,从而使文本与生成图像具有更高的一致性,并且使得生成图像中的显著区域得到增强.具体地,ITSC-GAN 包含2 个主要模块,分别是图像区域注意力模块(image regional attention module,IRAM)和文本信息增强模块(text information enhancement module,TEM).IRAM 从图像空间角度出发,首先提取图像区域特征,之后利用自注意力机制挖掘图像子区域之间的关系,强化图像区域之间的关联,使得生成图像中的目标更完整,前景与目标区域的边界更加清晰.TEM 从文本空间角度出发,利用交叉注意力模块和生成图像信息对初始文本信息进一步增强,从而提高生成图像与文本的一致性.在IRAM 和TEM 两个模块的联合作用下,ITSC-GAN 模型能够有效挖掘图像局部区域与文本语义标签的潜在对应关系,从而进一步提高图像子区域与文本语义的一致性.
本文主要的贡献有3 个方面:
1)提出了方法ITSC-GAN,其通过挖掘图像区域关系并增强文本信息,减少图像空间与文本空间的语义鸿沟,提升了这2 种模态间的语义一致性.
2)为实现ITSC-GAN 模型,本文创新性地提出2个模块TEM 和IRAM.其中,TEM 通过交叉注意力机制将文本特征与图像特征进行语义对齐,增强了生成图像与文本描述的语义一致性.IRAM 通过自注意力机制学习图像子区域之间的相互关系,增强前景、背景的区分度,使目标区域划分更加精确,并且使生成图像中的目标更完整.
3)在CUB 数据集上进行了对比实验及消融实验.与已有方法相比,本文方法ITSC-GAN 取得了更优的性能,且所生成的图像更加逼真.大量的实验结果验证了本文方法的优越性.
1 相关工作
1.1 图像生成方法
2016 年,GAN-INT-CLS 模型[3]将GAN 应用于文本生成图像任务中,引起了基于GAN 的文本生成图像方法的研究热潮.目前已有大量的文本生成图像方法,其中包括经典的多级对抗生成网络结构[11-12]、镜像方法[13]、动态记忆力方法[14]、注意力方法[5]等.StackGAN 模型[11]和StackGAN++模型[12]提出了多级GAN 结构,有效降低生成高分辨率图像的难度,但其忽略了生成图像与文本的语义一致性,导致生成图像质量较差.Qiao 等人[13]通过CycleGAN 模型[15]与AugCycleGAN 模型[16]的启发,提出了 MirrorGAN 模型[13],将镜像方法引入文本生成图像中.DM-GAN 模型[14]为了解决最终生成图像质量受最低分辨率生成图像的影响,将动态记忆方法引入到文本生成图像任务中.AttnGAN 模型[5]将注意力机制引入到文本生成图像任务中.该方法在文本编码器中,将文字信息和图像信息进行交叉注意力编码以及语义对齐,并在生成图像的过程中,采用交叉注意力方法,利用文本特征与图像特征的注意力权重信息,将文本特征动态地转化成图像特征,从而改善生成图像的质量.后续许多方法,如MirrorGAN模型[13]、DM-GAN 模型[14]、SegAttnGAN 模型[17]等均利用文本编码器来进行语义对齐.然而,这类模型都存在一个缺陷,即过于依赖预训练中的文本编码器性能.虽然在某种程度上,文字编码器能够弥补文本和图像之间的语义鸿沟,但是仍有可能出现语义不对齐的情况,进而使得后续过程中,文本特征向图像特征的动态转换也存在一定的局限性.
1.2 自注意力与交叉注意力
近年来,将Transformer 模型[18-23]应用到跨模态任务中成为研究热门.这些工作利用自注意力方法与跨模态的交叉注意力方法,实现模型的性能提升.VisualBERT[19],VL-BERT[20],ViLBERT[21]旨在构建输入的文本信息与输入图像中的子区域的内在关系,并进行语义对齐,这些模型在视觉问答、视觉推理的任务中都有良好的表现.Unicoder-VL[22]通过构建一个预训练的通用编码器,学习视觉和语言的联合表示方法,在视觉和语言的跨模态任务中都有显著效果.Wang 等人[23]提出的跨模态自适应消息传递可以自适应地控制消息跨模态传递的信息流,在图像检索任务中有不错的表现.
自注意力与交叉注意力在文本生成图像任务中也有很好的应用,如XMC-GAN 模型[24]使用跨模态交叉注意力模块作为文本编码器,将文本特征与图像特征进行翻译和对齐.Naveen 等人[25]在AttnGAN模型[5]的基础上,利用BERT[26],GPT2[27]等不同的模型作为文本编码器,来解决从文本描述中提取语义信息的困难.然而这些模型在使用自注意力与交叉注意力方法时,虽然考虑了文本描述中单词的相互关系以及文本描述与图像之间的跨模态关系,但是忽略了图像子区域之间的相互关系,不利于捕获图像和文本信息的映射关系.
2 ITSC-GAN 模型
2.1 模型整体结构
图1 展示了ITSC-GAN 模型的整体结构.给定一个文本描述T=(Tl|l=0,1,…,L-1),ITSC-GAN 模型的目的是输出生成图像X={xi|i=0,1,2},其中L代表文本描述的单词数量,i对应不同分辨率的生成阶段.模型由文本编码器、图像编码器和3 级GAN 构成.其中,3 级GAN 包含生成模块 Fi(·)与本文提出的图像区域注意力模块和文本信息增强模块.文本描述T经由文本编码器,提取全局句子特征向量s和单词特征矩阵W.之后将特征向量s与随机噪声z拼接后,输入到3 级GAN 中,经由生成模块得到图像特征hi,再经由图像区域注意力模块得到图像区域特征fi,该模块建立图像子区域之间的联系.然后将区域特征fi与初始单词特征矩阵W传入文本信息增强模块,该模块将文本特征与图像特征进行语义对齐,并实现特征融合,得到图像特征.之后通过生成模块 Fi+1(·)得到图像特征hi+1.然后将得到图像特征H={hi|i=0,1,2},分别传入对应的生成器Gi(i=0,1,2)中,得到生成图像xi(i=0,1,2).最后将生成图像与全局句子特征向量s分别传入到判别器Di中,判别生成图像的真假以及生成图像和文本描述是否语义一致.

Fig.1 The architecture of ITSC-GAN图1 ITSC-GAN 的框架图
2.2 文本编码器与图像编码器
1)文本编码器.如图1 所示,给定文本T,文本编码器将输出全局句子特征向量s和单词特征矩阵W.本文采用长短时记忆网络(long short term memory,LSTM)作为文本编码器.此过程形式化地表现为
其中W=(wl|l=0,1,…,L-1)∈RD×L,wl是第l个单词的特征向量,对应第l个隐藏层输出,而s∈RD是最后一个隐藏层的输出,式 FLSTM(·) 为长短时记忆网络,D为wl和s的向量维度.
本文还采用了条件增强模块[11],由于数据集中存在文本图像对稀少的问题,通过该模块对文本句子特征进行重采样,增加随机性,增强模型的鲁棒性,增强公式为
其中sca∈RD′,D′是经过条件增强后的向量维度.
2)图像编码器.图像编码器旨在从图像中提取特征.本文的图像编码器采用Inception-v3 模型[28],该编码器在ImageNet[29]数据集上进行预训练.
其中Iimg为输入图像,fc∈RD×N为图像提取到的图像特征,由模型的中间层得到.fv∈RD为图像全局特征,由模型最后一层得到.
2.3 多级生成网络
如图1 所示,将在得到全局句子特征向量sca和单词特征矩阵W后,送入GAN.GAN 中含有3 个生成器G0,G1,G2,分别生成64×64×3,128×128×3,256×256×3 分辨率的图像.3 个生成器的输入分别为隐向量h0,h1,h2.将GAN 公式化后为:
其中z表示服从标准高斯分布的随机噪声,式为第i阶段的图像区域注意力模块,式为第i阶段的文本信息增强模块,式 Fi(·) 是第i阶段的生成模块,xi表示生成图像.
2.3.1 图像区域注意力模块(IRAM)
IRAM 旨在构建生成图像子区域间的联系,使得生成目标更具完整性,前景、背景边界更加清晰.如图2(a)所示,本文设计的IRAM 主要由卷积神经网络(CNN)和自注意力模块(self-attention module,SAM)所构成.SAM 结构如图2(b)所示,由Transformer[18]中的多头注意力和前馈网络构成.图像特征hi经过CNN 得到区域特征fi,之后通过3 个线性层分别映射到相应的特征空间得到Qs,Ks,Vs,并利用Qs,Ks,Vs完成对区域特征fi的自注意力,得到区域特征.这一过程的具体公式有:
其中WQ,WK和WV均为权重矩阵,λs为自定义参数,FCNN(·)为卷积神经网络.
2.3.2 文本信息增强模块(TEM)
TEM 旨在利用生成图像增强文本特征的表征能力,进而增强生成图像与文本描述的语义一致性.如图2(a)所示,本文设计的TEM 主要由交叉注意力模块(cross-attention module,CAM)与交叉注意力层(crossattention layer,CAL)构成.其中CAM 的结构如图2(c)所示,其包含2 个连续的多头注意力,且子层是并行解码多个对象.TEM 的输入为单词特征矩阵W.与SAM 一致,在CAM 的第1 个多头注意力中,通过线性层得到,,,并实现对W的自注意力.在第2个多头注意力中,将该层得到的与SAM 中得到的Ks,Vs进行注意力权重计算,得到注意力权重矩阵M,并实现文本特征与图像特征的交叉注意力,得到单词特征矩阵=(|l=0,1,…,L-1)∈RD×L.上述过程用公式表示为:
之后,得到的权重矩阵M和特征矩阵作为输入传入CAL 中,其结构如图2(d)所示.CAL 中的计算公式为:
其中 αj,i的含义是第i个单词与第j个图像子区域的相似度.最终可得到=(c0,c1,…,cN-1)∈RD×N,实现由文本特征到图像特征的动态表示.
2.4 损失函数
ITSC-GAN 模型的损失函数由生成器和判别器的损失函数构成.生成器的损失函数LG定义为
其中Gi表示第i个生成器.式(16)中等号右侧的第1项为生成损失函数LGi,第2 项为条件增强损失函数Lca[11],第3 项为DAMSM 损失函数[5].其中 λ1和 λ2是条件增强损失和DAMSM 损失的相应权重.生成损失函数LGi展开为
其中Di代表第i个判别器,等号右侧括号内的第1 项为非条件损失函数,其功能是使生成图像效果更逼真,第2 项为条件损失函数,其功能是使生成图像和文本描述语义一致.条件增强损失函数Lca展开为
其中DKL(·) 为计算KL 散度公式,µ(·) 与 Σ(·)分别是求均值与方差公式.Lca的功能是增强训练数据,避免模型过拟合.对于DAMSM 损失函数[5],其功能是通过预训练的文本编码器和图像编码器,衡量图片与文本的匹配程度,使文本与对应的图像具有语义一致性.
判别器的损失函数LDtotal为
其中LDi为非条件损失函数,用于判别输入图像的真假;LCDi为条件损失函数,用于判别输入的图像和文本描述是否语义一致.LDi与LCDi展开式为:
3 实 验
3.1 实验设置
在实验中,我们将AttnGAN 模型[5]作为基础模型.文本编码器采用Bi-LSTM 构建文本特征,单词特征维度为256,语句长度为18.图像编码器采用Inceptionv3 网络,全局图像特征维度为2 048,局部图像特征维度为768.设置式(16)中参数λ1=1,λ2=5,SAM 和CAM模块的子层数m=1,多头注意力数n=8.本文使用Adam优化器迭代训练整个网络,批处理(batch size)大小为33,初始学习率(initial learning rate)为0.000 2,网络迭代训练次数为600.
3.2 数据集与评价指标
为了验证本文所提方法的有效性,本文在单目标数据集CUB[9]以及更复杂的多目标数据集COCO[10]上进行训练和测试.CUB 数据集包含200 种鸟类图像共11 788 张.其中,训练集含有8 855 张图像,测试集含有2 933 张图像,每一张图像对应10 句文本描述.由于CUB 数据集中80%的鸟类的目标部分仅占整体图像的50%左右[9],背景干扰较大,因此本文首先对图像进行了裁剪等预处理操作,以确保目标部分占图像的75%,突出前景目标.COCO 数据集包含多个目标和复杂背景的图像.其中,训练集含有82 783 张图像,测试集含有40 470 张图像,每一张图像对应5 句本文描述.
本文采用了初始分数[30](inception score,IS)、Fréchet 初始距离[31](Fréchet inception distance,FID)和R-precision[5]作为评价指标,定性地评价ITSC-GAN模型的生成效果.其中IS的计算公式为
其中x为生成样本,y为图像编码器模型所预测的标签.p(y|x)和p(y)分别是标签y的后验概率和边缘概率,Ex(·)是求期望运算,exp(·)为指数运算.IS分数越高,证明生成图像的质量越高且更具有多样性.
FID主要用于计算2 个多维变量分布之间的距离,本文通过预训练的图像编码器模型,提取生成图像和真实图像的特征,并计算FID分数:
其中 µx,µx′分别是真实图像与生成图像的均值,Σx,Σx′则分别是真实图像和生成图像的协方差矩阵,tr(·)为矩阵求迹运算.FID越低,表示生成图像和真实图像的特征距离越近,所产生的生成图像质量越接近真实图像的质量,即生成图像的质量更高.
由于IS和FID评分并不能衡量生成图像是否良好地依赖于文本描述,所以本文采用了R-precision作为评价指标,其用于衡量生成图像与文本的一致性.R-precision是在检索上常用的指标,本文利用生成图像检索相对应的文本描述.具体地,首先计算1 个全局图像特征和100 个候选句子向量之间的余弦距离D.设候选句子向量中包含了R个匹配文本与100-R个随机选择的不匹配文本.在每次检索中,对于相似度前R个文本描述中,若有r个文本描述与生成图像相匹配,则R-precision=r/R.在实验中,我们将设置R=1.另外,我们将生成图像分成10 份进行检索,最后取结果的平均值和标准差.
3.3 实验结果
3.3.1 定量分析
表1 列出了ITSC-GAN 模型与当前主流方法在CUB 数据集的性能对比结果.由表1 结果可以看到,ITSC-GAN 模型的表现最优.在IS评分的表现上,与AttnGAN 模型[5]相比,ITSC-GAN 模型有明显的提升,IS评分从4.31 增长到4.63,提升了约7.42%.与MirrorGAN模型[13]相比,ITSC-GAN 模型在IS评分上也提升了1.5%左右.这充分说明ITSC-GAN 模型在生成图像的质量与多样性上性能更好,所生成图像的清晰度更优.在FID评分的表现上,相比AttnGAN 模型[5]获得24.37 的FID分数,ITSC-GAN 模型的FID分数为17.36,降低了28.76%.与MirrorGAN 模型[13]在FID的表现相对比,ITSC-GAN 模型所获得的FID降低了5.34%.这说明ITSC-GAN 模型相比于其他模型,生成的图像更加逼真,在细粒度细节上表现更好.
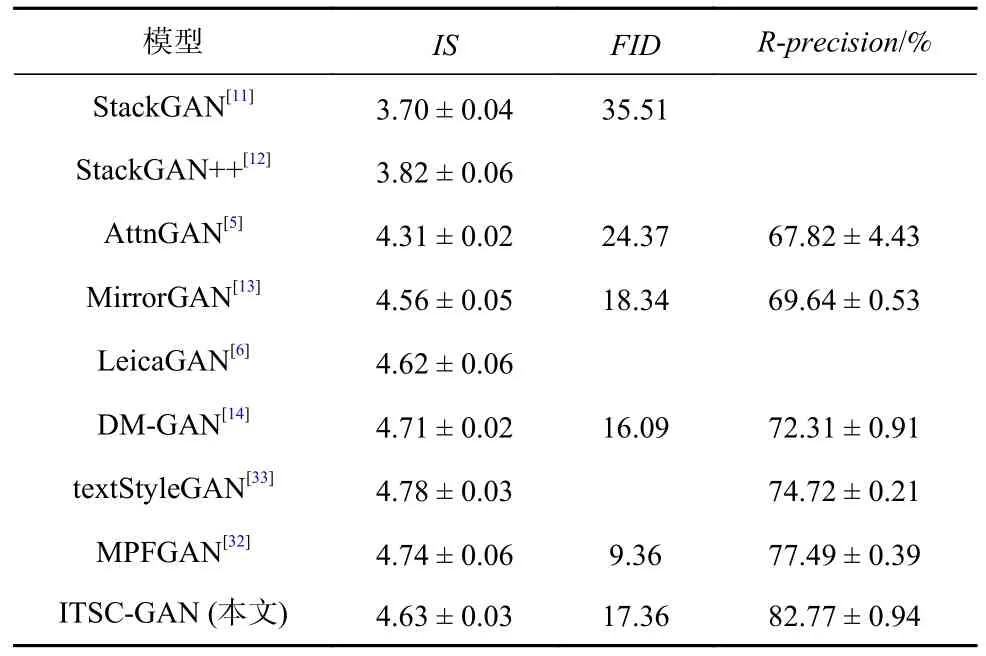
Table 1 Performance Comparison of ITSC-GAN and Mainstream Methods on CUB Dataset(mean ±std)表1 CUB 数据集上ITSC-GAN 与主流方法的性能对比(mean ± std)
在R-precision评分的表现上,与AttnGAN 模型[5]相比,ITSC-GAN 模型有显著提升,R-precision评分从67.82%增长至82.77%,提升了约14.95%.与DM-GAN模型[14]和MPFGAN 模型[32]相比,ITSC-GAN 模型在R-precision评分上分别提升了约10.46%和5.28%.Rprecision性能的显著提升充分说明ITSC-GAN 模型生成的图像与文本描述的匹配程度更加紧密,在保持文本图像语义一致性上表现更加优异.
3.3.2 定性分析
图3 为ITSC-GAN 与其他模型在CUB 测试集上生成图片的对比结果.如图3 所示,StackGAN 模型[11]与StackGAN++模型[12]所生成的图像虽在生成图像的纹理上表现较好,但是仅生成了目标的大致轮廓,细节部分较模糊,生成效果不佳.AttnGAN 模型[5]、MirrorGAN 模型[13]与DM-GAN 模型[14]生成的图像中,虽然轮廓清晰,提升了纹理细节,但背景与目标边界不够清晰,且存在“多头鸟”与“多脚鸟”等目标不完整的问题(如图3 的AttnGAN 行的第3 列、MirrorGAN行的第7 列与DM-GAN 行的第9 列所示).同时,这些方法的生成图像与文本描述在细节上没有保持良好的语义一致性,即生成的目标与文本描述不一致(如图3 的AttnGAN 行的第7 列、MirrorGAN 行的第12 列与DM-GAN 行的第13 列所示).而相比之下,ITSC-GAN 模型生成的图像轮廓更加清晰,在细节纹理上表现更好,生成目标更加完整,前景与背景的边界更加明确.在细节上,生成图像与文本描述具有良好的语义一致性.上述与主流方法的生成图像对比示例体现了本文所提方法的优越性.

Fig.3 Results comparison of ITSC-GAN and the baseline models on CUB test set图3 ITSC-GAN 与基线模型在CUB 测试集上的结果比较
3.4 验证实验
3.4.1 消融实验
为了验证本文方法中各个模块的有效性,本文在AttnGAN 模型[5]的基础上,依次增加IRAM 与TEM,并在CUB 数据集上构建消融实验,其结果如表2 所示.与AttnGAN 基础模型相比,加入IRAM 的模型在IS评分中获得了3%左右的提升,这说明挖掘图像子区域之间的关系有助于生成图像质量的提高.另外,相比于基础模型,加入TEM 的模型在R-precision评分上获得了13.28%左右的提升,证明了TEM 有利于文本与生成图像的语义对齐.ITSC-GAN 方法在基础模型的基础上同时引入IRAM 和TEM,在IS分数与Rprecision评分上均取得了最佳表现.这说明IRAM 通过在视觉空间对图像特征添加区域注意力机制,增强了图像特征的表征能力.该图像特征作为TEM 的输入,进一步增强文本特征,提升了文本与图像的语义一致性.

Table 2 Ablation Experiments on CUB Dataset(mean ±std)表2 CUB 数据集上的消融实验(mean ± std)
为了更进一步分析模块的作用,本文对不同模块的生成图像进行了可视化对比,如图4 所示.相比于基础模型,加入IRAM 的模型所生成的图像在前景、背景分界部分更为明晰.而加入TEM 的模型所生成的图像,虽然在轮廓边缘上较为模糊,但与文本信息保持了更好的语义一致性.上述定性和定量的分析结果均证明了本文所提出的IRAM 模块与TEM 模块的有效性.

Fig.4 Comparison of generated images from different modules图4 不同模块的生成图像比较
3.4.2 模块子层数的影响
表3 展示了在CUB 数据集上SAM 和CAM 子层数m对模型性能的影响.根据表3 的实验结果可以发现,当子层数m=1 时,IS分数最高,模型性能最好;而当子层数m>1 时,IS评分与R-precision评分呈现断崖式下降.

Table 3 Comparison of IS and R-precision for Different Module Layers m(mean ± std)表3 不同模块层数 m 的IS 和R-precision 对比(mean ±std)
如图5 为不同m取值下的生成图像结果.可以看到,随着层数m的提升,前景与背景的区分度越来越差,如图5 最后一行第2 列的图像中,鸟的尾部与背景边界模糊.同时也逐渐出现文本描述与生成图像语义不一致的问题,如随着m的增大,生成图像中对于单词“red”的表现越来越差.图5 表明,过大的子层数m不利于生成高质量图像.

Fig.5 Impact of module sublayer m on the generated images图5 不同模块子层数m 对生成图像的影响
3.4.3 不同数据集的结果展示
为了更进一步验证ITSC-GAN 的有效性,本文在COCO 数据集也进行了相应的训练与测试.如表4的结果展示,ITSC-GAN 模型在IS和R-precision评分上都有所提升.与基础模型相比,ITSC-GAN 模型在IS评分上获得了5.45%左右的提升,这说明ITSCGAN 模型生成的多目标、复杂场景图像质量更好,清晰度更佳.另外,相比于基础模型,ITSC-GAN 模型在R-precision评分上获得了约6.50%的提升,证明了ITSC-GAN 模型所生成的图像与文本的语义一致性更强.

Table 4 Experimental Results on COCO Dataset(mean ±std)表4 COCO 数据集上的实验结果(mean ± std)
如图6 展示了基础模型与ITSC-GAN 模型的生成图像效果对比.基础模型生成的图像存在多目标边界模糊、生成目标不完整、与文本无法保持良好的语义一致性的问题(如图6“基础模型”第5 列所示).而ITSC-GAN 模型生成的图像多目标边界更加清晰,生成目标更加完整,在细节纹理上表现更好,与文本具有较好的语义一致性.

Fig.6 Presentation of results from COCO dataset图6 COCO 数据集的结果展示
4 结束语
本文提出了一种基于图像-文本语义一致性的文本生成图像方法ITSC-GAN.我们创新性地提出了图像区域注意力模块(IRAM)与文本信息增强模块(TEM).其中,前者构建图像区域之间的联系,后者实现视觉与语言跨模态的语义对齐,增强了生成图像的质量和文本与图像语义的一致性.在公开的文本生成图像数据集CUB 上,大量的对比及消融实验结果验证了ITSC-GAN 方法的有效性和优越性.然而所设计的TEM 仍有进步的空间,在后续的工作中会对其更进一步改进,例如:1)增强文本编码器,得到表征能力更强的文本特征;2)将增强后的文本信息与未增强的文本信息进行自适应地结合,从而进一步增强文本特征的表征能力.
作者贡献声明:薛志杭提出论文想法,负责文献调研、实验设计与分析以及论文的撰写与修改;许喆铭负责文献调研,参与论文想法的讨论,撰写并修改论文摘要、引言;郎丛妍负责整体指导,参与论文想法的讨论,梳理论文逻辑,撰写并修改论文摘要与前言;冯松鹤、王涛、李浥东对论文的结构和内容提供指导意见,确定了论文的研究思路.
猜你喜欢
公民与法治(2022年5期)2022-07-29
小雪花·成长指南(2022年1期)2022-04-09
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
成都信息工程大学学报(2018年3期)2018-08-29
传媒评论(2017年3期)2017-06-13
电子设计工程(2017年20期)2017-02-10
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
燕山大学学报(2015年4期)2015-12-25
