
神经元计算机操作系统的资源分配方法
2023-09-22 06:21王凤娟金欧文邢庆辉邓水光
计算机研究与发展 2023年9期
王凤娟 吕 攀 金欧文 邢庆辉 邓水光
1(之江实验室 杭州 311121)
2(浙江大学计算机科学与技术学院 杭州 310058)
(wangfj@zhejianglab.com)
神经形态计算是一种模拟大脑结构和功能的计算模式,有望成为人工智能领域下一代主流的计算范式[1-2].脉冲神经网络(spiking neural network,SNN)是神经形态计算领域中最具有代表性的一种计算模型[3].SNN 通过模拟大脑神经元行为和神经元突触的连接方式,以其超低功耗和事件驱动的特性,赢得越来越广泛的关注[4].
SNN 应用是指运行于神经形态计算硬件并通过SNN 的推理或在线训练来实现功能的应用,SNN 应用是一类基于脉冲的机器学习方法.与人工神经网络(artificial neural network,ANN)类似,SNN 可以通过监督方法或无监督方法进行训练,以执行特定任务,在训练过程中,通过调整连接神经元之间的突触权重来实现预期的运行效果.
神经形态计算硬件是专为运行SNN 应用而设计的专用计算机系统.为了充分发挥SNN 的低功耗优势,国内外许多研究机构和企业正在研发一系列神经形态计算硬件,其中包括SpiNNaker[5],Brain-ScaleS[6],TrueNorth[7],Loihi[8],Tianjic[9-10],DYNAP-SE[11],Neurogrid[12]和Darwin[13]等.这些硬件都遵循共同的设计原则来运行SNN 应用,具体来说,它们都使用大量专门设计的神经形态计算核心来存储突触权重与并行模拟神经元动力学.
大规模神经形态计算硬件系统最常见的设计是采用2D 网格结构的片上网络,其主要特点是具有高可扩展性且具有并行计算的能力.基于这种架构,研发人员也开发了一系列配套的软件工具将SNN 应用部署到神经形态硬件系统.将SNN 应用部署到神经形态计算硬件系统主要分为3 个步骤:
1)SNN 应用建模和训练.2)编译.编译器首先根据神经形态计算硬件限制将SNN 应用中的神经元划分为多个神经元簇;然后根据映射规则,将神经元簇节点映射到手动指定或者自动查询的空闲的神经形态计算硬件核心上;最后根据映射的硬件和路由信息生成可以在硬件上运行的二进制指令.相关研究如 PACMAN[14],PyCARL[15],SpiNeMap[16],DFSynthesizer[17],以及文献[18]引入Hilbert curve 和Force Directed(FD)方法优化神经元簇的划分和映射过程,旨在降低SNN 应用在神经形态计算硬件上的脉冲通信能耗、延迟和拥塞.除此之外,在映射时将脉冲输入输出神经元簇映射到SNN 应用的外围核心,以减少脉冲输入输出的通信代价.3)运行时加载.将第2 步骤生成的二进制指令加载到对应的神经形态硬件核心上运行.相关研究如德国海德堡大学为BrainScaleS[6]硬件系统构建的运行时环境BrainScaleS OS[19]、英国曼彻斯特大学为SpiNNaker[5]硬件开发的软件工具链SpiNNTools[20],以及Intel 为Loihi[8]提供的开发工具链Loihi toolchain[21].
神经形态计算硬件具有支持多个SNN 应用在不同核心上并行运行的能力.随着硬件规模的增长,软件系统可管理和调度的神经形态计算硬件核心资源数量也在不断增加,远远超出了传统多核系统的数量,且SNN 应用具有到达时间和执行时长不可预测的特性,如何高效地为多个SNN 应用动态分配资源是一个重要的研究课题.目前,SNN 应用的资源分配在编译阶段手动或自动地将其绑定到神经形态硬件上,这种方法在小规模资源情况下可能不会受到明显的限制;然而,在面对大规模神经形态硬件系统时,如何动态地管理硬件资源并为大量SNN 应用分配资源则面临着巨大的挑战.
为了应对上面提到的挑战,我们提出了一种新颖的资源分配框架,首先提出与编译解耦的SNN 应用资源分配流程,编译阶段映射到逻辑核心,神经元计算机操作系统负责统一管理神经形态计算硬件资源,在加载SNN 应用时为SNN 应用分配神经形态计算硬件核心资源以及相关的输入输出路由信息.其次,引入最大空矩形(maximum empty rectangle,MER)算法处理神经形态计算硬件资源的管理和动态分配问题,并且基于SNN 应用的脉冲输入输出特性,本文提出一种基于MER 的脉冲输入输出通信代价最小化的核心资源分配(MER-based minimize spiking input and output costs resource allocation,MER-MSIOCRA)方法.文献[22]率先提出了MER 策略,并基于MER 策略提出了保持所有最大空矩形和保持非重叠空矩形2 种算法,这些算法证明只要存在一个合适的空闲区域,总是可以找到MER,并实验证明了这些算法在任务接受率上的优势.文献[23]基于MER 策略提出如何在二维空间中快速有效查找MER 并管理MER 列表,根据MER 列表为任务分配最合适的资源位置,并在任务动态添加或删除时,实时维护和调整MER列表.由于神经元计算机操作系统对神经形态计算硬件资源的管理和调度是基于二维网格(2D-Mesh)的核心资源,并且SNN 应用所需的核心资源可以表达为矩形区域内核心集,因此,我们把为SNN 应用分配资源理解为在神经形态计算资源中找到一块空闲的矩形区域核心集是非常合理的.然而,SNN 应用与传统应用的主要区别在于,SNN 应用的运行依赖于脉冲输入和脉冲输出来完成计算,因此,为SNN 应用分配资源需要考虑到脉冲的输入输出路由.而输入输出路由的选择会直接影响SNN 应用的运行延迟以及整个系统的性能,这是由于脉冲在神经形态计算硬件核心间的传输需要时间,如果SNN 应用被放置在距离输入输出通道较远的位置,那么脉冲的传输就需要更多的时间,这将导致计算延迟增加.因此,在为SNN 应用选择放置位置时,除了需要考虑空闲资源的位置和大小外,还需要考虑脉冲输入输出路由的影响.
本文提出的资源分配方法不仅提高了资源分配的灵活性,而且可以有效降低系统的脉冲输入输出功耗、延迟,以及降低资源碎片率.本文贡献有2方面:
1)提出了一种神经元计算机操作系统的资源分配框架,即与编译解耦的资源分配过程.具体来讲,在编译阶段,将SNN 应用映射到逻辑核心,无需关心神经形态计算硬件的实时运行状态;在运行时阶段,再为SNN 应用分配神经形态计算硬件核心资源及相关的输入输出路由信息.
2)创新地引入了最大空矩形算法来处理神经形态计算硬件资源的管理和动态分配问题.并且基于MER算法,结合SNN 的脉冲输入输出特性,我们提出了最小化脉冲输入输出通信代价的资源分配算法MERMSIOCRA.实验结果表明,对比现有算法,我们所提出的算法明显降低了脉冲输入输出的能耗和延迟.
1 相关工作
针对SNN 应用的资源分配问题,研发人员开发了一系列工具将SNN 应用映射到神经形态计算硬件核心上,相关研究如下.
BrainScaleS OS[19]以二维网格形式将神经形态计算硬件核心抽象化,并提供用于绑定指定硬件及其核心坐标的接口,然后将其转换为硬件指令.然而,此方法在编译SNN 应用时便固定了硬件资源,缺乏灵活性,未提及如何动态管理和分配核心.
SpiNNaker[5]构建的软件工具链也经过多次迭代以解决SNN 应用如何放置到硬件系统的问题.其中,PACMAN48[24]要求用户通过ybug2 工具手动加载编译后的SNN 应用和路由表到SpiNNaker 机器上,且只支持单板;文献[25]将SpiNNaker 系统中的映射问题抽象成电路布局设计,SpiNNTools[20]使用有向图描述映射情况,有向图的顶点表示PCB 板,有向图的边表示PCB 板之间的通信关系,通过一系列流程自动查询并绑定到可用的硬件机器,但仍是在编译映射前绑定到硬件机器,缺乏流程灵活性.
文献[21]中的方法是为Loihi[8]构建的包含编译和运行时2 个阶段的软件工具链,编译分为预处理、资源分配和代码生成3 个阶段,资源分配阶段通过将SNN 的网络实体贪婪地分配给可用的核心资源来执行资源分配,然后经过代码生成阶段将SNN 应用转换为二进制字节流,通过调用Loihi 运行时库完成运行.
IBM 建立的基于TrueNorth 芯片的软硬件生态系统[26]提出了设计和运行时2 个工作流,针对资源分配,在设计阶段的Placer 中采用了以最小化芯片间脉冲通信量、最小化芯片内脉冲通信距离和最大化输入输出为目标的启发式算法来完成神经元簇的物理映射.
上面所提到的软件都是在编译阶段完成SNN 应用的资源分配,在运行时阶段加载的神经形态计算硬件核心是在编译阶段手动或自动绑定的硬件核心,没有做到编译映射与运行时加载到神经形态计算硬件核心解耦.在面对多SNN 应用同时运行时,对神经形态计算硬件核心资源的统一管理和动态分配却往往被忽视.
Darwin-S[27]是相对更完整、更简洁的软件参考体系结构,它包括一个类脑操作系统(Brain-inspired OS)和一个集成开发环境(integrated development environment,IDE).Brain-inspired OS 提供了硬件抽象层和资源管理层,其中资源管理层实现神经形态计算硬件资源的管理和统一调度,在资源管理层为SNN 应用动态分配神经形态计算硬件核心资源及部分路由信息,如脉冲输入输出路由;IDE 中包括SNN构建语言和编译器,编译器根据硬件约束将神经元划分并映射到逻辑核心,文献[18]基于平台提出了一种先进的神经元划分和映射的算法.
2 问题建模
2.1 神经形态计算硬件模型
目前,几乎所有新型的大规模神经形态芯片[5-13]的设计都是基于二维网格片上网络(2D mesh network on chip,2D Mesh NoC)的计算架构.图1 展示了一个典型的神经形态计算硬件架构的抽象模型.这个架构由多个通过路由节点相互连接的同质同构神经形态核心组成,每个神经形态核心都能并行地模拟神经元行为并存储突触权重.每个神经形态核心与一个路由节点绑定,并通过双向链路将其与4 个方向上的邻居节点连接起来,从而形成了一个具有2D 网格拓扑结构的互联网络.通过互连线级联多个芯片,可以构建更大规模的二维网格.每个神经形态核心与其绑定的路由节点都有一个坐标 (x,y),神经形态核心之间通过路由节点传输脉冲包,脉冲包在片上网络采用XY算法进行路由,即通过目标神经形态核心与源核心在X和Y方向上的差值来完成传输.

Fig.1 Neuromorphic computing hardware resources model图1 神经形态计算硬件资源模型
神经形态计算硬件资源的大小通过二元组(N,M) 表示,这意味着有N×M个可用的神经形态核心(图1 实心圆圈所示).我们将神经形态计算硬件资源定义为一个集合:
其中,每个神经形态核心ci=(x,y)用一个二元组表示在二维网格中的坐标,x表示该神经形态核心在网格X方向上的位置,y表示该神经形态核心在网格Y方向上的位置.二维网格左上角的神经形态核心索引为 (0,0),右下角的神经形态核心索引为 (N-1,M-1).
软件与片上网络输入输出脉冲通过芯片边缘的4 个直接内存访问(direct memory access,DMA)通道进行通信,我们将脉冲输入输出方向定义为:dir∈{WEST,EAST,NORTH,SOUTH},分别代表西、东、北、南4 个方向的DMA 通道.我们将DMA 抽象为与片上网络同行同列的虚拟输入输出核心(如图1 的虚线圆圈所示),用于在软件与片上网络核心之间传递输入输出脉冲.虚拟输入输出核心定义为4 个边缘核心的坐标集合:
根据式(1)和式(2),我们将硬件资源表示为所有神经形态核心与虚拟输入输出核心的集合:
2.2 SNN 应用映射簇网络
编译阶段主要完成SNN 的划分和映射,SNN 应用编译离线完成,编译阶段映射的核心称为逻辑核心,如图2 所示SNN 应用1 和SNN 应用2 的编译过程,其中右侧空心圆圈形成的是一块 4×5的逻辑核心网格配置,逻辑核心具有与神经形态核心同样的行为和限制.值得注意的是,映射的逻辑核心无需与神经形态核心的实时状态进行绑定,即所有离线编译的SNN 应用可以使用同一块逻辑核心配置,实现了与神经形态计算硬件解耦的目的.

Fig.2 SNN APP compile图2 SNN 应用编译
根据神经形态核心的限制,将SNN 划分为神经元簇,并根据一定的映射规则[18]将神经元簇映射到逻辑核心,映射的产物是映射簇网络(mapped cluster network,MCN).在映射阶段,遵循着将与脉冲输入输出节点直接相连的神经元簇节点映射到网络的边缘逻辑核心.由于神经形态计算硬件存在对称性,在不影响实验结果的前提下,为简化表达,本文指定了默认脉冲输入输出方向为 WEST.我们将MCN定义为一个五元组:
其中,Vclu={c0,c1,…} 代表神经元簇节点集合,Vio={io0,io1,…}代表虚拟输入输出节点集合,表示软件与片上网络输入输出脉冲的虚拟节点集合.E={e0,e1,…} 代表边集;每个ei∈E用一个三元组ei=(si,ti,wi)表示,代表源节点si到目的节点ti的具有脉冲通信连接且通信流量权重为ei,并且此通信流量与该连接的脉冲传输的总数成正比;Eclu表示神经元簇之间的连接;Eio表示虚拟输入输出节点与神经元簇之间的连接,其中E=表示ci到逻辑核心的映射函数,即Plog(ci)=(xi,yi).
图2 给出了一个SNN 应用映射簇网络的示例.其中SNN 应用1 是一个包含12 个神经元(n0∼n11)的全连接SNN.首先,基于神经形态核心的限制(图2显示每个核心能存储的最大神经元数量为3)将神经元n0∼n11划分为4 个神经元簇节点c0∼c3,即Vclu={c0,c1,c2,c3};其中与脉冲输入直接相连的神经元n0∼n1被划分在神经元簇节点c0,定义与c0相连的虚拟输入节点为io0且连接权重w0=2,因此e0=(io0,c0,2),同理e1=(io1,c1,2),与脉冲输出直接相连的神经元n9∼n11被划分在神经元簇节点c3,定义与c3相连的虚拟输出节点为io2且连接权重w2=3,即e7=(c3,io2,3);则Vio={io0,io1,io2},Eio={e0,e1,e7}={(io0,c0,2),(io1,c1,2),(c3,io2,3)},Eclu={e2,e3,e4,e5,e6}.在映射阶段,根据映射规则,神经元簇节点c0∼c3分别映射的逻辑核心为:Plog(c0)=(0,0),Plog(c1)=(1,0),Plog(c2)=(1,1),Plog(c3)=(2,0).针对SNN 应用2,逻辑核心映射为:Plog(c0)=(0,0),Plog(c1)=(0,1),Plog(c2)=(1,1),Plog(c3)=(1,0).
2.3 问题定义
对于神经形态计算硬件资源HWsys和n个待分配神经形态计算硬件资源的SNN 应用MCN,TS={MCN0,MCN1,…,MCNn-1},资源分配问题可以被建模为MCNi中每个逻辑核心分配合适的神经形态核心以及指定脉冲输入输出方向.具体来说,就是将一组逻辑神经形态核心集合分配到物理神经形态核心集合,并指定虚拟输入输出节点与虚拟输入输出核心的映射.
输入:神经形态计算硬件资源HWsys和所有SNN应用的MCN集合TS;
输出:对每个MCN,一个映射函数P.P表示为MCN的逻辑核心(分配的)物理神经(形态核)心的映射函数,其中,
我们使用4 个指标来量化本文算法的性能.
1)脉冲输入输出总能耗峰值
给定一个MCN和一个资源分配结果P(MCN),MCN消耗的脉冲输入输出能耗(energy cost,EC) 计算为:
其中,disi=‖P(si)-P(ti)‖ 表示2 个神经形态核心之间的曼哈顿距离,ENroute表示路由器路由一个脉冲的能耗,ENwire表示路由器之间的链路传递一个脉冲的能耗.
给定TS和每个MCNi的资源分配结果P(MCNi),基于式(5)计算神经形态计算硬件系统脉冲输入输出消耗的总能耗峰值:
2)脉冲输入输出平均延迟
给定一个MCN和一个资源分配结果P(MCN),MCN的脉冲输入输出平均延迟(average latency,AL)计算为:
其中,Lroute表示路由器路由一个脉冲的延迟,Lwire表示路由器之间的链路传递一个脉冲的延迟.
给定TS和每个MCNi的资源分配结果P(MCNi),基于式(7)计算神经形态计算硬件系统脉冲输入输出的平均传输延迟峰值:
3)脉冲输入输出最大延迟
给定一个MCN和一个资源分配结果P(MCN),MCN的脉冲输入输出最大延迟(maxmize latency,ML)计算为:
给定TS和每个MCNi的资源分配结果P(MCNi),基于式(9)计算神经形态计算硬件系统上脉冲输入输出的最大延迟为:
4)碎片率
给定TS和所有分配成功的MCNi集合TSsuccess,资源碎片率(fragmentation rate,FR)计算为:
其中,MCNi.w,MCNi.h分别表示MCNi的逻辑核心组成的矩形区域的宽和高,N×M表示神经形态计算硬件核心总数量.
3 神经元计算机操作系统的资源分配方法
3.1 神经元计算机操作系统的资源分配流程
文献[27]提出的Darwin-S 包括了IDE 和一个类脑操作系统Brain-inspired OS.IDE 包括编译器,负责编译SNN 应用并生成运行于神经形态计算硬件系统的二进制指令;Brain-inspired OS 作为运行时除了将SNN 应用加载到神经形态计算硬件外,负责抽象和管理神经形态计算硬件核心资源,统一为SNN 应用分配神经形态计算硬件资源,并行调度多个SNN 应用等.
本节提出的神经元计算机操作系统的资源分配流程是在Brain-inspired OS 的基础上实现的,旨在提升神经形态资源管理的效率以及资源分配的灵活性.
所提出的资源分配流程为:
1)编译器离线完成SNN 应用的编译,输出SNN应用在神经形态计算硬件上运行的二进制指令以及对应的MCN,其中编译阶段输出的二进制指令不用关注软件到片上网络SNN 的输入输出路由,或者在编译阶段统一默认一个输入输出路由.当SNN 应用需要运行时再发送到神经元计算机操作系统.
2)神经元计算机操作系统接收到SNN 应用时,根据操作系统管理的神经形态计算硬件核心资源的实时占用情况,给SNN 应用分配合适的空闲核心资源以及脉冲输入输出路由,根据实际分配的软件到片上网络的脉冲输入输出路由,修改SNN 应用中二进制指令和MCN中的输入输出路由信息并加载到神经形态计算硬件上运行.
图3 展示了其他现有研究的资源分配过程(图3(a))与我们提出的神经元计算机操作系统资源分配过程(图3(b))的对比.我们提出的资源分配流程带来的好处为:
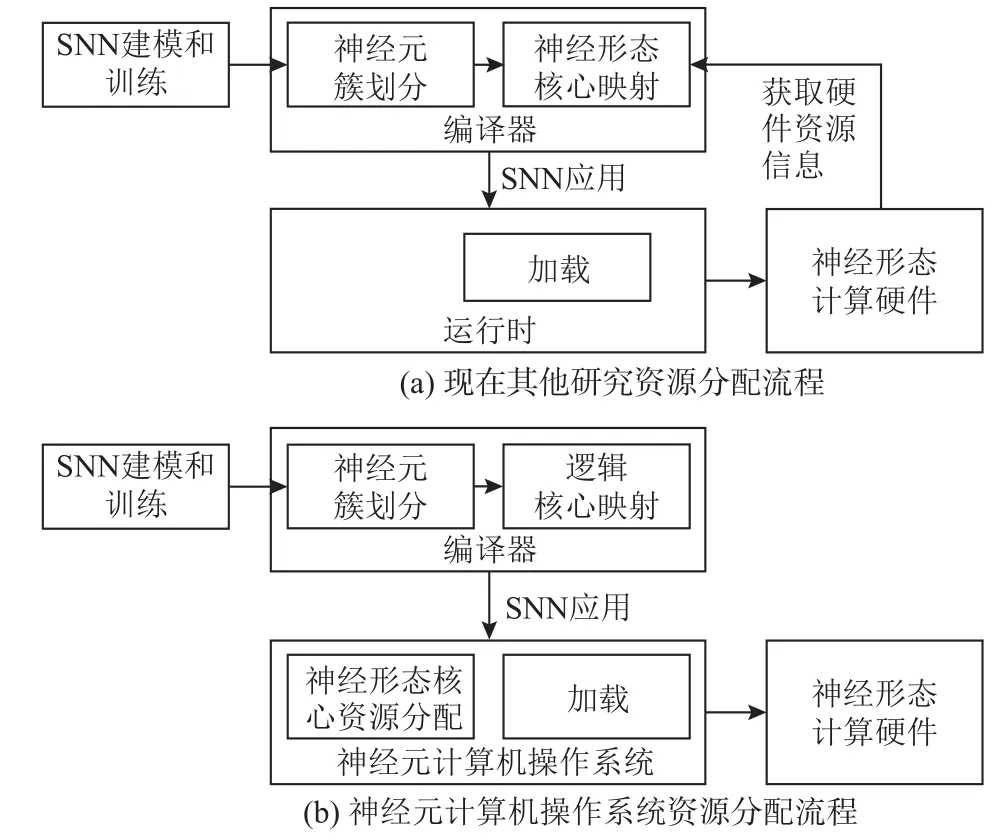
Fig.3 Comparison of resource allocation processes图3 资源分配流程对比
1)实现了编译与神经形态计算硬件的实时状态解耦.编译器假定一块资源永远是可用的,无需考虑软件与片上网络脉冲输入输出的路由以及真实的神经形态计算硬件的运行状态,如神经形态核心的占用情况、资源碎片化等.编译器可以将更多的精力集中在SNN 应用的优化上,这种策略能大幅度提升编译效率.
2)只有当SNN 需要加载到神经形态计算硬件运行时才需要给SNN 分配硬件资源,而不需要提前为待编译的SNN 应用预留资源.
3)实现了神经元计算机操作系统统一管理神经形态计算硬件资源以及最大化利用硬件资源.例如,如图4(a)所示,在神经形态计算硬件不足或者资源碎片化严重时,我们通过应用迁移有效地利用碎片化资源.如果硬件资源因为碎片化无法满足SNN 应用C的资源需求,神经元操作系统的任务调度模块会将已部署的SNN 应用B迁移到其他碎片化位置,释放并整合更多的资源以满足SNN 应用C的需求.应用迁移的过程只需在神经元计算机操作系统完成即可,不需要重新编译SNN 应用.
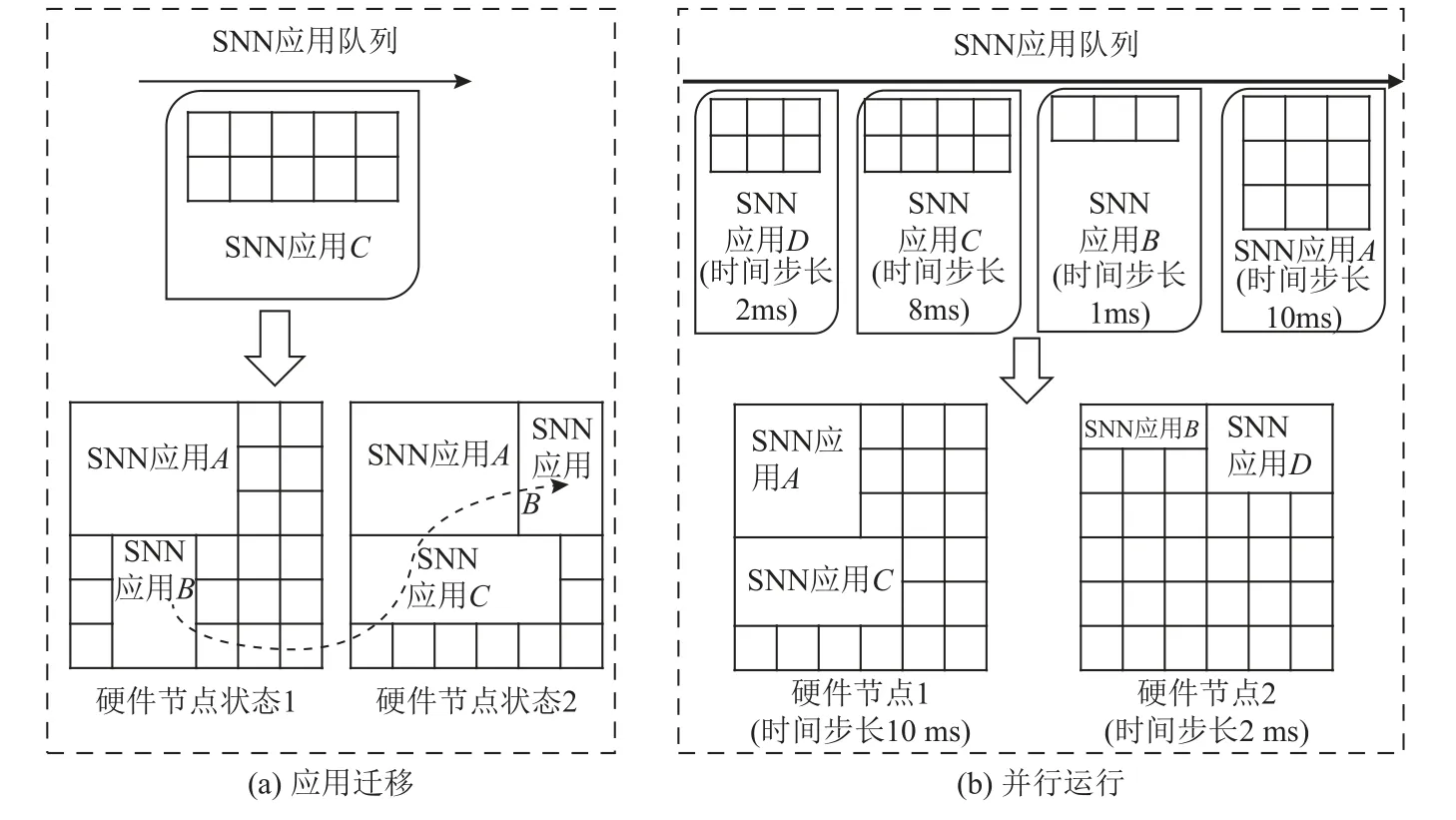
Fig.4 Parallel scheduling scenario图4 并行调度场景
4)实现了神经元计算机操作系统可以并行运行多个SNN 应用的可能性.SNN 应用是通过每个时间步完成脉冲计算,而不同的SNN 应用所需的时间步可能不一样.在调度多个SNN 应用时,我们的操作系统可以将具有相同时间步的SNN 应用分配或迁移到共享一个时间步的硬件节点上运行,实现真正的并行运行多个SNN 应用.如图4(b)所示,对于SNN 应用A~D,其时间步长度分别为10 ms,1 ms,8 ms,2 ms,将相近时间步的SNN 应用A和C分配到硬件节点1上,并将硬件节点1 计算的时间步长度设置为10 ms,那么在调度硬件节点1 上应用时,可以并行运行SNN 应用A和C;同理,将SNN 应用B和D分配到硬件节点2,硬件节点2 计算的时间步长度设置为2 ms,即可以做到并行运行硬件节点2 上的所有应用.3)和4)流程主要是由神经元计算机操作系统的调度器和资源分配模块协同完成的,其中调度器的详细内容超出了本文的讨论范围,因此不再进行详细说明.
针对神经元计算机操作系统管理以及为SNN 应用分配神经形态计算硬件资源的方法,本文引入MER 算法管理空闲资源[23].MER 顶点包括左上角(left top,LT)、右上角(right top,RT)、左下角(left bottom,LB)、右下角(right bottom,RB),为SNN 应用分配资源时,将SNN 应用MCN的逻辑核心形成的矩形放置在顶点的位置,对于所有满足资源分配条件的候选位置,找到一个最合适的位置分配给SNN 应用.
图5 展示了当前神经形态计算硬件资源空闲资源的MER 列表 {MER0,MER1,MER2,MER3,MER4},其中黑色实心圆圈表示已被占用核心.图5 中蓝色和绿色标识的在MER0中为图2 所示的2 个SNN 应用分配的神经形态核心;为SNN 应用2 分配的神经形态核心集合为 {c0:(0,4),c1:(1,4),c2:(1,5),c3:(0,5)},其中c0:(0,4)表示为SNN 应用2 节点c0分配的神经形态核心是 (0,4);为SNN 应用1 分配神经形态核心的2 种方案,方案1 和方案2 分配的神经形态核心集合分别为 {c0:(0,1),c1:(0,2),c2:(1,2),c3:(0,3)} 和 {c0:(N-2,1),c1:(N-2,2),c2:(N-2,2),c3:(N-2,3)};为SNN 应用1 和SNN 应用2 分配的虚拟输入输出方向都为 WEST;为SNN 应用1 分配的方案1 明显优于方案2,相较于方案1,方案2 将整体资源切割成了更多的碎片资源,且方案2 为SNN 应用1 分配的神经形态核心离 WEST方向的虚拟输入输出核心距离较远,导致脉冲输入输出通信距离变长,从而增加了脉冲输入输出的能耗和延迟,关于这个问题,我们将在3.2 节更系统和数学化地提出我们的解决方案.

Fig.5 Resource allocation strategy of neuron computer operating system图5 神经元计算机操作系统资源分配方案
3.2 最小化脉冲输入输出通信代价的资源分配算法
随着神经形态芯片的发展,神经元规模的扩大导致了通信瓶颈的出现,这包括软件的通信瓶颈和片上网络的通信瓶颈.因此,在SNN 应用逻辑核心间的通信距离相对固定的情况下,如何最小化脉冲输入输出距离成为了神经元计算机操作系统为SNN 应用分配神经形态硬件资源时需要量化的重要指标.在处理传统资源的放置策略时,基于MER 的任务放置方法是将邻接值作为其分配准则.邻接值的定义是,尽可能将新到达的任务放置在MER 的边缘或靠近其他任务的位置,这样的布局可以极大程度地减少不同任务间的碎片化,从而有效降低整体资源的碎片率.文献[28]在考虑任务的生命周期的同时,提出了一种创新的基于MER 的三维邻接值启发式算法,与其他算法相比,这一算法展示出了更优秀的任务接受率.而SNN 与传统任务最大的区别是,SNN运行是通过脉冲输入输出完成计算的,脉冲输入输出需要通过软件与片上网络之间的DMA 通道传递;基于邻接值的资源分配策略在初期容易将应用分配到相邻的资源区域,这意味着应用会集中在同一边的输入输出通道,在脉冲通信量大的情况下,必然会产生通信延迟.为了解决这个问题,本节提出一种基于MER的最小化脉冲输入输出通信代价的资源分配方案,旨在降低脉冲输入输出的功耗和延迟,同时提高资源利用率.下面将详细介绍神经元计算机操作系统如何基于MER 算法为一个SNN 应用MCN分配最优的神经形态计算硬件资源的过程.
3)对于每一个满足放置的MERj,Clog各逻辑核心相对位置固定,结合MERj的4 个顶点和脉冲输入输出方向,有8 种放置情况:PDIR={WLT,WLB,NLT,NRT,ERT,ERB,SLB,SRB},WLT和WLB表示 WEST方向脉冲输入输出的左上角和左下角,NLT和NRT表示 NORTH方向的左上角和右上角,ERT和ERB表示 EAST方向的右上角和右下角,SLB和SRB表示 SOUTH方向的左下角和右下角.
在各个方向放置需满足条件:
为了保证分配的输入输出核心靠近芯片边缘,且输入输出通道均衡在不同的片上网络路由通道,当模型放置在 NORTH,EAST,SOUTH方向时,将Clog分别向右旋转90°,180°,270°;旋转后逻辑核心组成的宽高变化为,以及所有逻辑核心为:
同时根据确定的神经形态核心坐标与输入输出方向确定虚拟输入输出节点坐标:
5)根据式(5)计算MCN在MERj的候选放置位置的脉冲输入输出通信代价,以及根据式(16)计算邻接值CV.
其中,n表示MCN放置到候选位置后MCN矩形区域接触到的已放置SNN 应用数量与接触到的神经形态计算硬件资源区域的边的数量之和.Lengthp表示第p个接触核心边缘的重叠长度.
6)根据步骤3~5 找到MCN在MERs的所有可能放置候选位置以及放置后的脉冲输入输出通信代价和邻接值,并优先选择脉冲输入输出通信代价最低的放置方案,在脉冲输入输出通信代价相同的情况下,选择邻接值最大的方案以降低碎片率.
完整地为SNN 应用集合TS分配神经形态计算硬件资源的算法如算法1 所示.
算法1.MER-MSIOCRA.
4 实 验
4.1 实验环境
我们使用软件仿真一个抽象的目标神经形态计算硬件平台来测量本文提出的方法.表1 中列出了目标硬件平台的参数.

Table 1 Parameters of Target Neuromorphic Computing Hardware表1 目标神经形态计算硬件参数
实验是在Ubuntu 20.04.1(GNU Linux 5.4.0-125-generic x86 64)服务器上进行的,该服务器具有16 个CPU 内核(Intel Xeon Processor(Skylake,IBRS)CPU@2.92 GHz),64 GB 内存.
所有仿真程序都是由C++实现,没有用到GPU计算能力或多核并行计算功能.
4.2 对比算法
神经形态计算硬件领域暂没有提出相关资源分配方法,为了将本文提出的MER-MSIOCRA 算法与其他算法的性能进行比较,对比了2 种传统二维资源分配算法:1)SBHF 算法[29].用于解决二维装箱问题,该算法将不同大小的矩形放入特定大小的箱子中.该算法将箱子的可用区域按照自下而上的架子组织,每次在架子上放置矩形时都可以调整开放架子的高度.然而,下方区域架子的高度不可变,被称为封闭式货架.2)MER-3D-Contact 算法[28].选择邻接值最高的放置方案,具有较高的任务接受率和较低的碎片率.
为了体现公平性,上述2 种对比算法在查找到候选位置后,脉冲输入输出方向选择到4 个方向中脉冲输入输出通信代价最低的方向.
4.3 评价指标
评价资源动态分配的所有指标为:
1)系统脉冲输入输出总能耗峰值(式(6));
2)系统脉冲输入输出平均延迟(式(8));
3)SNN 应用的脉冲输入输出最大延迟(式(10));
4)资源碎片率(式(11)).
4.4 实验结果分析
在第1 个实验中对比了能耗、平均延迟和最大延迟,我们设计了5 组SNN 应用集,每组应用集的数量如表2 所示,5 组SNN 应用集随机产生的规则一致,如表3 所示.为了保证3 种算法对比的基准一致,SNN 应用集1~应用集4 的每组SNN 应用集所需的总资源小于硬件资源,表示每组SNN 应用集都能被成功分配,而SNN 应用集5 所需的总资源约等于硬件资源.针对SNN 应用集5,SBHF 并没有得到完全分配,而MER-3D-Contact 和MER-MSIOCRA 算法中所有的SNN 应用均分配成功.

Table 2 Number of SNN APP Sets表2 SNN 应用集数量

Table 3 SNN APP Set Generation Rules表3 SNN 应用集生成规则
如图6 展示了3 种算法在神经形态硬件系统能耗峰值的实验结果.实验结果表明,基于4 组应用集(数量分别为40,60,80,100)的碎片率一致的情况下,MER-MSIOCRA 算法明显优于其他2 种算法,这是因为MER-MSIOCRA 算法总是优先给SNN 应用分配离输入输出通道较近的神经形态核心.MER-MSIOCRA算法比MER-3D-Contact 算法最高降低了71%,比SBHF 最高降低了81%;对于应用集(数量为200),由于SBHF 算法并没有完全分配所有的应用,因为统计的能耗值是部分应用的结果,而针对完全分配成功的MER-3D-Contact 和MER-MSIOCRA 的结果分析,MERMSIOCRA 明显优于MER-3D-Contact.

Fig.6 Results on energy consumption for spiking input and output图6 脉冲输入输出能耗结果
图7 展示了3 种算法在神经形态硬件系统的平均延迟结果.实验结果表明,在碎片率一致的情况下,MER-MSIOCRA 算法也表现出较好的性能;MERMSIOCRA 算法比MER-3D-Contact 算法降低了70%,比SBHF 算法最高降低了81%.
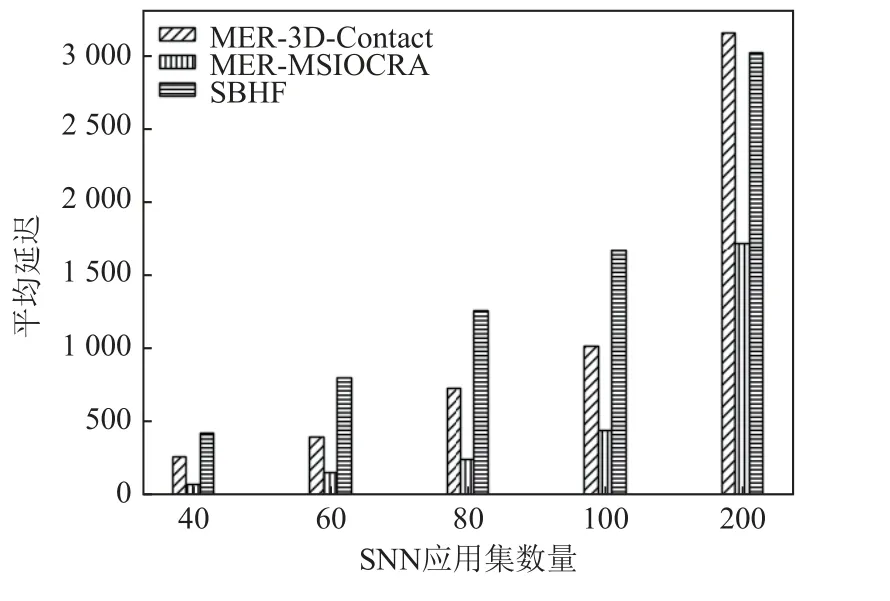
Fig.7 Results on average latency for spiking input and output图7 脉冲输入输出平均延迟结果
图8 展示了在给定神经形态硬件资源中分配的SNN 应用最大延迟结果.在碎片率一致的情况下,MER-MSIOCRA 算法比MER-3D-Contact 算法最高降低了79%,比SBHF 算法最高降低了84%.因为MERMSIOCRA 算法总是优先将SNN 应用分配到靠近输入输出通道的位置.
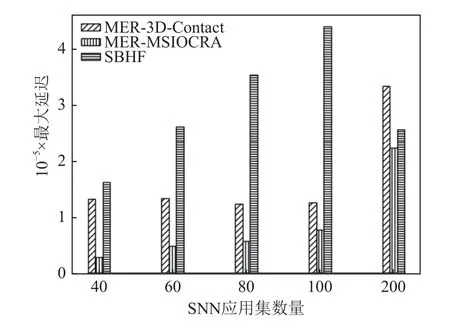
Fig.8 Results on maximum latency for spiking input and output图8 脉冲输入输出最大延迟结果
在第2 个实验中,我们通过碎片率验证MERMSIOCRA 算法的优势,我们设计了4 组SNN 应用集,每组应用集的数量如表4 所示,4 组SNN 应用集随机产生的规则一致如表3 所示.为了保证3 种算法对比的基准一致,APP Set1 所需的总资源是小于硬件资源的,APP Set2~ APP Set4 所需的总资源是高于硬件资源的,即可以保证SNN 应用集中有分配不成功的应用.

Table 4 Number of SNN APP Sets for Fragmentation Rate Test表4 用于碎片率测试的SNN 应用集数量
图9 展示了4 组数据集的碎片率结果,3 种算法在APP Set1(数量为100)中产生的碎片率一致,因为APP Set1(数量为100)中所有的应用都分配成功;APP Set2(数量为200)中所有应用在MER-3D-Contact和算法MER-MSIOCRA 都分配成功,表现优于SBHF;APP Set3(数量为300)和APP Set4(数量为400)在3种算法中都有部分应用没有分配成功,但MERMSIOCRA 明显优于其他2 种算法,相比MER-3DContact,MER-MSIOCRA 产生的碎片率最高降低了32%,相比SBHF,MER-MSIOCRA 最高降低了92%.

Fig.9 Results on fragmentation rate图9 碎片率结果
5 结论
本文提出了一种神经元计算机操作系统的资源分配流程,即与编译解耦的资源分配过程在软件层面大幅度提升了系统效率.基于所提出的资源分配流程,本文还提出了MER-MSIOCRA 算法,一种基于MER 的最小化脉冲输入输出方法.其主要思想是在不改变SNN 应用模型内核心之间的相对距离的情况下,通过旋转SNN 应用模型将输入输出核心放在靠近DMA 通道的方向.实验结果表明,MER-MSIOCRA算法在脉冲输入输出能耗、延迟的性能比现有算法有明显的提升,在应对大规模SNN 应用并发时,MERMSIOCRA 算法在碎片率上也表现出较好的性能.
作者贡献声明:王凤娟和吕攀为共同第一作者,提出了论文的总体框架和算法思路,完成了实验并撰写论文的主体部分;金欧文、邢庆辉参与了论文讨论和论文修改;邓水光提出指导意见并修改论文.
猜你喜欢
自然杂志(2021年6期)2021-12-23
英语文摘(2020年10期)2020-11-26
装备制造技术(2019年12期)2019-12-25
铁道通信信号(2019年3期)2019-04-25
测控技术(2018年7期)2018-12-09
现代装饰(2018年5期)2018-05-26
校园英语·中旬(2017年10期)2017-11-20
吉林省教育学院学报(2017年3期)2017-05-31
计算机应用(2016年10期)2017-05-12
电源技术(2015年5期)2015-08-22
