
基于比较学习的漏洞检测方法
2023-09-22 06:21陈小全夏翔宇周绍翔
计算机研究与发展 2023年9期
陈小全 刘 剑 夏翔宇 周绍翔
1(北京城市学院信息学部 北京 100191)
2(中国科学院网络测评技术重点实验室(中国科学院信息工程研究所) 北京 100093)
3(中国科学院大学网络空间安全学院 北京 100049)
(chenxiaoquan@126.com)
当前软件中存在的漏洞是引发软件安全事件的主要原因.因此在软件开发过程中通过静态和动态的检测技术[1-3]来发现软件中存在的漏洞是很重要的工作.软件漏洞静态检测是通过扫描程序的源代码或者相应的二进制代码[4],找到符合软件漏洞特征代码片段的过程.其实施流程是,首先根据各种漏洞的特征,建立对应的漏洞特征库,如溢出漏洞特征库、格式化字符串特征库以及各种CWE 漏洞类型的特征库.接下来依据建立的特征库对程序进行静态分析,检测程序中是否存在匹配某种漏洞特征的漏洞.检测的大致流程包括建立源代码模型、构建漏洞特征库、判定漏洞,以及结果分析等关键步骤.检测的技术有数据流分析[5-8](data-flowanalysis)和符号执行[9-13](symbolic execution)等.动态漏洞检测技术指的是通过实际运行被检测的程序,记录程序的执行轨迹,分析程序执行流程中的数据和函数间的调用关系等信息,以此检测程序中是否存在某种类型的漏洞.典型的动态漏洞检测技术有模糊测试[14-17](fuzzing test)和动态污点分析[18-21](dynamic taint analysis,DTA).此外,当前随着深度学习技术在恶意代码检测、垃圾邮件过滤等方面的不断应用,学术界和工业界也在不断地尝试将深度学习技术应用于软件漏洞的挖掘和分析当中[22-25].与软件静态和动态检测技术相比较,应用深度学习技术进行软件漏洞挖掘可以实现软件漏洞的自动化挖掘和分析,大幅度地提高漏洞挖掘的效率和精度.基于该目的,本文提出并实现一种基于比较学习的深度学习方法,其核心思想是为深度学习训练集中的每个样本寻找类型相同的样本和类型不相同的样本.在模型训练的过程中,让模型学习类型相同样本大量的、细微的特征,也学习类型不相同样本之间非常明显的不同特征.通过这种方式,使得深度学习模型的漏洞识别精度大幅度提高,同时也可以检测多达150 种的CWE 类型的漏洞.
本文的贡献有3 方面:1)分析和整理了漏洞检测技术中经常使用的SARD 数据集.SARD 数据集包含了大量的漏洞程序和非漏洞程序,非常适合作为漏洞学习的样本集.但该漏洞数据集里的程序存在一些问题,如存在的非法字符阻碍深度学习模型的学习过程.通过整理,形成了一个源代码语言的语料库,可以用于训练自己的源代码词向量模型;一个漏洞数据集,可以用于训练漏洞检测学习模型.经过实验验证,使用该数据集训练出来的模型,其漏洞检测准确率可以达到92.0%.2)分析并讨论了基于深度学习的漏洞检测模型训练中数据集的样本程序是否符号化对模型的漏洞识别准确率的影响.经过实验验证与分析,发现数据集中程序样本符号化与否对深度学习模型的检测能力并没有太大的影响.3)提出并实现一种新的深度学习方法—比较学习法.该学习方法的灵感来源于人类的学习方式,人们经常通过比较来学习一个新的知识.通过使用这种学习方法,深度学习模型在提取一个程序样本的特征时,它不是单纯从一个样本中学习程序的特征,而是同时学习该样本的同类型样本和非同类型样本的特征.通过这种方式,模型不但学到了同类型样本普遍共有的特征,也学习到了非同类型样本不一样的特征.这样,模型提取特征的范围和视野将更加开阔,有力地阻止过拟合和欠拟合现象的发生.
1 相关工作
基于深度学习的源代码漏洞检测的思想来源于自然语言处理技术.在自然语言处理技术中,可以把自然语言当作一种时序字符串序列,然后训练一个神经网络模型捕捉时序序列中的特征,将其应用于语言识别和机器翻译等具体的应用.与此类似,程序语言也是一种时序语言,在执行的时候也是按照一定时间顺序先后执行.但程序语言与其他的语言(例如英语)相比,是一种标记语言,或者说是一种“硬语言”,其语法定义可以唯一地解释代码含义,计算机也能根据确定的规则分析和执行代码.而英语等自然语言的含义和形式会灵活变化,比如含义相同的文章可以有不同的表述,或者文章存在歧义等.从上面的分析不难看出,使用深度学习技术学习程序语言中的特征要比学习自然语言中的特征更加简单,因为程序语言中的单词含义唯一确定,不存在二义性.目前,很多的科研工作者已经使用深度学习技术提取源代码程序中缺陷部分的特征,训练相应的神经网络模型来进行软件的漏洞检测.如Russell 等人[22]针对C/C++开源软件代码,提出了基于深度学习的函数级缺陷检测方法.在文献[22]的方法中,直接以函数体为基本单位来识别函数中是否存在对应的缺陷,但存在的问题是该种方法并不适用于包含跨函数数据依赖关系的代码缺陷检测.Li 等人[23]基于深度学习方法实现了程序切片级别的缺陷检测方法.在文献[23]的方法中仅采用单一的词向量作为代码的特征向量表示,并且基于双向LSTM 神经网络实现了源代码缺陷的二分类检测,但并未在多个特征融合、多种漏洞类型分类等方面做进一步的研究.Zhou 等人[24]实现了基于图神经网络的源代码漏洞检测系统Devign.该系统同样是二分类的源代码漏洞检测系统,即给定源代码来判断其中是否存在漏洞,但是却无法识别具体的漏洞类型.Duan 等人[25]实现了基于注意力机制的源代码缺陷检测方法 VulSniper,实现了多类源代码缺陷检测,但涉及到的源代码漏洞类型较少,只涉及了CWE119 和CWE399 这2 种缺陷类型.Chakraborty等人[26]和段旭等人[27]基于代码属性图和深度学习技术实现了漏洞检测方法,但他们的不足在于仍然基于以函数或程序为单位进行漏洞检测,并且他们的方法仍然是二分类方法,并不能检测多种漏洞类型.Zou 等人[28]以及文献[29]在文献[23]的基础上,基于程序中的控制依赖关系,提出称之为“代码注意力(code attention)”的新机制.在这种机制中,使用函数调用序列作为关键特征信息构建了多分类的神经网络模型μVulDeePecker,该模型可以检测多达40 种的CWE 漏洞类型.Wu 等人[30]使用了CNN与LSTM 的混合模型来进行程序漏洞特征的提取,其实验结果表明采用混合模型可以提取更多的漏洞特征信息,从而使得模型的检测效果更好.Nguyen 等人[31]把内核方法与双向循环神经网络(bidirectional recurrent neural network,BRNN)结合起来,提出了深度代价敏感内核机(deep cost sensitive kernel machine,DCKM)模型,可以处理机器指令集序列,实验结果显示该模型可以有效解决深度学习数据集中存在的数据不平衡问题.Li 等人[32]提出了一种基于混合神经网络的源代码漏洞自动检测框架.该框架利用低级虚拟机中间表示(LLVM IR)和向后程序切片将输入转换为具有显式结构信息的中间表示,再采用混合神经网络模型对源代码关键序列结构信息进行表征,然后自动化地漏洞检测.其优点在于该表征方式可以兼顾词法分析并进行细粒度地漏洞挖掘,准确地识别出漏洞的具体位置.Cao 等人[33]针对缓冲区溢出漏洞和资源管理型漏洞,分别使用CNN 与LSTM提取程序所含漏洞的全局信息和局部的特征信息,实现一种结合了傅里叶变换的深度卷积 LSTM 神经网络模型,并应用在程序的漏洞检测上面.Mao 等人[34]提出了基于注意力的双向长短期记忆网络(attentionbased bidirectional long short-term memory network,ABLSTM)模型,用于漏洞特征提取,取得了较好的漏洞检测效果,此外该文献也把深度学习的可解释性用在漏洞的探测方面,使得深度学习技术不仅可以用在软件方面,而且也使得内在的工作机制为大众所理解.此外,基于深度学习模型的漏洞检测技术中还有基于抽象语法树表征的漏洞挖掘模型[35-36]、基于图表征的漏洞挖掘模型[37-41]、基于文本表征的漏洞挖掘模型[42-44]以及把抽象语法树、文本表征、图表征结合起来的漏洞检测模型[45-46].
2 总体框架与实现过程
如图1 所示,本文提出的基于比较学习的漏洞检测技术分为多个步骤,下面分别介绍每一个步骤以及实现细节.

Fig.1 Overall framework for comparative learning图1 比较学习整体框架图
2.1 数据集准备
本文采用的源程序数据集来自于NIST 软件保障参考数据集(software assurance reference dataset,SARD)项目[47].该数据集能够为研究者提供一些已知的软件安全漏洞,可用于源码漏洞检测模型的训练.SARD中的源代码主要包括三大类别:1)“Fix”类型,表示源代码中的漏洞已被修复,不再包含漏洞;2)“Flaw”类型,表示其中的源代码含有漏洞;3)“Mixed”类型,表示相关源码中不仅包含漏洞,同时也含有相应的补丁程序.到目前为止,SARD 共有测试案例251 336条,其中包括C 代码96 494 个,C++代码34 133 个,Java 代码46 438 个,PHP 代码42 253 个,C#程序32 018个.选取其中的C 程序创建了实验的数据集,如表1所示.

Table 1 Data Set Composition表1 数据集构成
从表1 中可以看出,数据集中C 程序总数为96 494个,其中“Fix”类型的程序有568 个,它们没有漏洞;“Flaw”类型的程序有6 171 个,含有漏洞类型115 种;“Mixed”类型的程序有89 755 个,含有漏洞类型124 种.把Flaw 类型和Mixed 类型重复的漏洞类型去掉后,漏洞类型总数为180 个.同时,有27 种漏洞类型对应的程序数量超过了1 000 个,如表1 最后一列所示.
在创建这个数据集时,首先对数据集中所有的C 代码进行了检查,以此发现其中的一些错误.经过详细的检查,发现数据集中有20 个C 代码存在字符编码的错误,如表1 第4 列和图1 中1)所示.这些错误当中大部分是双引号的问题,其余是在语句行的末尾多了一些隐藏的字符,如“SUB”等.这些字符编码的错误会使得在使用JSON 格式保存数据集时,产生意想不到的问题.因此对这些文件进行了处理,结果如图1 中2)所示.
2.2 程序符号化
在基于深度学习的漏洞检测方法中,为了提高模型的泛化能力,普遍都会对数据集中的代码符号化,去除代码中个性的特征,辅之以用统一的符号来代替这些特征,降低模型提取程序特征的难度,提高模型的泛化能力.基于此,本文基于文献[26]的方式也对数据集中的C 代码符号化.方式是把程序所有的语句放在一行中,当成一个完整的语句,然后符号化.此外,在符号化的过程中,由于程序语言本身的关键字、标准函数库、API 函数库以及常用的头文件是程序特有的特征,所以符号化时保存了下来.代码1 显示了1 个示例程序源代码,代码2 表示把程序放在单独的一行中,代码3 表示符号化后的代码.表2显示了收集的程序本身的特征信息.数据集中代码符号化完整的流程如图1 中步骤①~③的1)~4)所示.然而在评价模型的实验过程中发现,在基于本文提出的比较学习的漏洞检测方法中,是否对数据集中的代码进行符号化,并不影响模型的漏洞识别能力,这从一个侧面反映出本文提出的深度学习漏洞检测方法具有比较强的学习能力,详细的实验内容和结果请参阅本文的第3 节.尽管如此,仍然在这里向大家展示深度学习中代码符号化的具体过程,以此了解深度学习在程序漏洞检测方面的普遍应用流程.

Table 2 Features of C Language表2 C 语言的特征
代码1.示例源代码.
代码2.代码中所有的语句放在一行中.
代码3.符号化后的代码.
2.3 源代码语料库创建与词向量模型训练
在符号化完数据集中的代码后,就可以创建语料库,训练一个新的词向量模型,如图1 步骤④中的5)和6)所示.之所以要创建新的语料库并且训练一个新的词向量模型的原因是:当前并没有一个专门针对C 语言的词向量模型.现有的word2vec[48-50]模型大多数是处理自然语言的词向量模型,并不适合用在某种编程语言上,例如C 语言.而C 语言有其自己的语法、语义和时序特征,这是与自然语言以及其他编程语言最大的不同点.通过创建专门针对C 语言的词向量模型,可以让深度学习模型更好地理解C语言的本质特征和内在丰富的语义,学习到区别度更大的漏洞特征.创建语料库和词向量模型的具体方式为:首先对数据集中经过符号化的96 494 个C程序进行单词统计,得到词汇量为97 425 010、单词总数为24 610 的语料库.然后使用word2vec 中的CBOW 方法训练一个词向量模型.如图1 步骤⑤中的6)所示.CBOW 是word2vec 中用于将文本表示成向量的一种方法.在CBOW 方法中,通过周围词预测中心词,从而利用中心词的预测结果,并基于梯度下降法(gradient descent)不断地去调整周围词的向量,从而获得整个语料库中所有单词的词向量.此外,也可以使用word2vec 中的Skip-gram 方法来训练词向量模型.在实验中,2 种方法训练的词向量模型效果相差不多,这里不赘述.
2.4 代码向量化
当词向量模型训练完成后,就可以使用该模型来向量化数据集里的C 程序代码.如图1 步骤⑤所示.具体的实现方式为:1)读取数据集中每一行内容(一个完整的C 代码);2)使用分词工具NLTK[51-52]将一整行代码分为若干个单词;3)对每一个单词使用前面训练好的词向量模型实施向量化,生成维度固定的词向量;4)将每一个单词对应的向量进行相加,取平均值,得到整个程序对应的向量,如式(1)所示.其中,XC表示一个C 代码对应的向量表示,XW表示代码中一个词汇的向量表示,n表示代码中词汇的数量.5)重复图1 步骤①~④,得到数据集中所有代码各自对应的词向量.结果如图1 步骤⑥中的7)所示.基于图1 的步骤①~⑥,得到整个数据集中所有程序的向量化表示.
其中W 表示C 代码中的一个词汇.
2.5 样本集创建
把数据集中所有的程序向量化后,就可以创建训练集样本和测试集样本.正如在2.1 节描述的,数据集由96 494 个C 程序构成,有“Fix”“Flaw”“Mixed”这3 种类型的代码.其中“Fix”类型中的代码是已经修复好的代码,没有漏洞;“Flaw”类型的代码存在漏洞;“Mixed”类型的代码不但存在漏洞,还有对应的修复好的代码.基于这样的特点,创建样本:1)“Fix”类型的代码由于没有漏洞,直接就加入到样本集里;2)“Flaw”类型的代码由于性质单一,没有对应的修复程序,并且每一个漏洞程序都有确定的CWE 类型说明,所以也直接加入到样本集里,其CWE 类型说明可以作为样本的漏洞类型标签;3)“Mixed”类型的代码不但存在漏洞代码,而且存在对应的修复程序.基于这样的特点,首先把漏洞代码提取出来加入到样本集中(对应的CWE 类型说明作为样本标签);其次把每一个漏洞程序对应的修复程序提取出来加入到样本集里.这里需要注意的是,“Mixed”类型代码中的漏洞代码对应的修复程序数量不止1 个,有时候1个漏洞代码有多个对应的修复代码,其数量不固定,最少的有1 个,最多的有12 个.采用这3 种方式处理后,获得了数量为280 894 的样本集,其中含有漏洞的代码95 926 个,漏洞类型总数为180;不包含漏洞的代码184 968 个.但在实际的模型训练过程中,有的漏洞类型对应的样本数量非常少,不利于深度学习模型的学习,如CWE133 漏洞类型对应的样本数量为1 个,CWE020 对应的样本数量为2 个.因此把这些样本数量非常少的漏洞类型以及对应的样本从样本集里删除.经过修正后的样本集的样本总数为280 793,其中含有漏洞的代码为95 821 个,漏洞类型总数为150(详细的漏洞类型以及对应的样本数量请参阅附录A 中的表A1);不包含漏洞的代码为184 972 个.到此为止训练模型需要的数据集就创建完成.接下来就可以把数据集随机打乱,根据一定的比例划分成训练集、测试集和验证集.上面的过程如图1 步骤⑥和步骤⑦中的7)和8)所示.
2.6 比较学习方法
比较学习思想的灵感来源于人类的一种学习方式.当人类学习一个分类时,总是寻找和这个类别相似的类和不同的类.从相同类别中学习该类别共有的一些特征,从不同的类别中学习不同类别之间明显的区分特征.通过这种方式,人类可以非常快地掌握某种分类的重要和细微的特征.在本文中,比较学习思想采用3 种方式实现.
1)统计训练集中每一种漏洞类型的样本数量,也就是每个样本属于哪一种漏洞类型.如算法1 所示.
算法1.统计每一个漏洞类型的样本数量.
2)基于1)返回的结果,为训练集里的每一个样本寻找漏洞类型相同的样本和漏洞类型不同的样本.如算法2 所示.首先,从训练集Train中选取1 个样本,称之为目标样本;其次,在aDict中删除该目标样本,因为目标样本本身不能作为自己比较学习的样本;再次,在aDict中获取与目标样本类型相同的样本的数量,如果该数值大于Num那么就可以在aDict中随机选取Num个样本作为目标样本的同类型样本,否则按aDict中实际的样本数量为目标样本选取同类型的样本;最后,采用上面相同的步骤为目标样本选取类型不相同的样本.算法的输出SameSam和DiffSam分别表示选取的同类型样本集合和不同类型样本集合.
算法2.选择相同样本和不相同样本.
3)根据2)中返回的同类型样本集合和不同类型样本集合,构建目标样本的同类型学习矩阵和不同类型学习矩阵.如算法3 所示.
算法3.创建目标样本的同类型学习矩阵和不同类型学习矩阵.
在算法3 中,根据目标样本的同类型样本集合SameSam,创建同类型学习矩阵tmatr,然后把矩阵中每一个同类型样本对应的向量进行相加并取平均值,得到最终的同类型学习矩阵SameMatrix.不同类型样本集合DiffSam也采取这种方式,得到不同类型样本集合的学习矩阵DiffMatrix.重复图1 步骤①~③就可以为训练集中每一个样本建立同类型的学习向量和不同类型的学习向量,从而创建比较学习的样本基础.这一过程如图1 步骤⑧中的9)所示.在9)中,第3 行表示目标样本,第1 行和第2 行表示同类型的样本,第4 行和第5 行表示不同类型的样本.当为训练集建立起比较学习矩阵后,就可以将训练集以及比较学习矩阵输入到深度学习网络中,进行深度学习模型的训练.
上面介绍了比较学习的核心思想和实现算法,其中必须要考虑的问题是当为数据集中的训练样本寻找类型相同和类型不相同的学习样本时,所找的学习样本的数量是主要的性能开销.从直觉上看,所找的学习样本数量越多,则深度学习模型训练过程中将会花费更多的时间和消耗更大的内存.而在本文进行的实验评价过程中也证明了这一点.在实验中发现,基于比较学习的深度学习模型在训练过程中的性能开销与学习样本的数量成正比关系,即:学习样本越多,性能开销越大.然而在大量的实验过程中也发现,基于比较学习的深度学习模型漏洞检测的准确率不会受到学习样本数量变化剧烈的影响,也就是学习样本的数量与深度学习模型识别漏洞的能力没有较大的关系.基于这个发现,在使用本文所提出的比较学习方法训练深度学习模型时,可以选取适当的数量值作为学习样本的数量,从而降低深度学习模型的性能开销,但不会对模型识别漏洞的能力造成太大的影响,详细的实验过程和结果请参阅3.4.2 节任务2.
2.7 深度学习模型
本文采用的深度学习模型是一个简单的全连接神经网络.因为在研究中发现,即使是简单的神经网络,基于本文的词向量模型和比较学习也能获得较高准确率的漏洞识别效果.本文使用的神经网络示例图如图1 步骤⑨中10)所示,详细的结构如图2 所示.
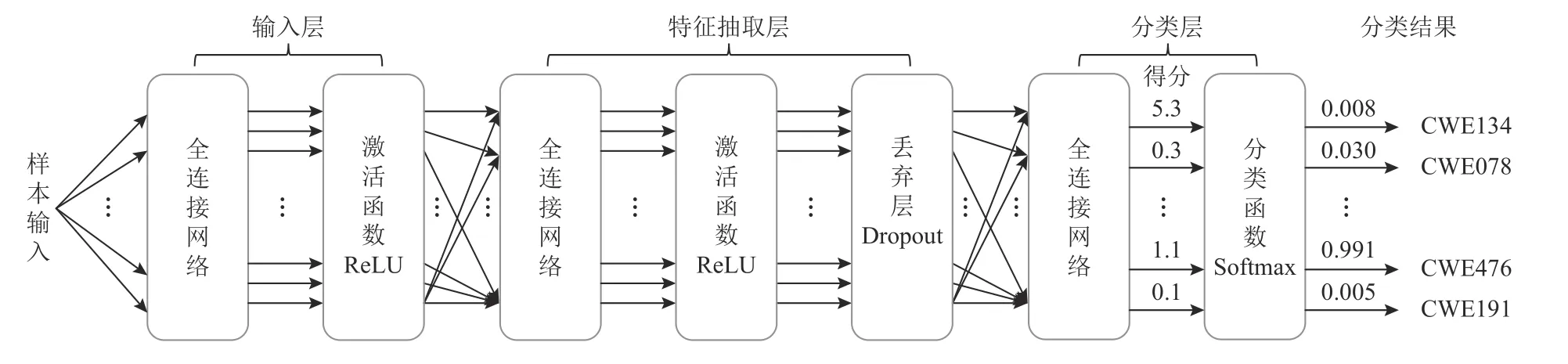
Fig.2 Deep learning network architecture图2 深度学习网络结构
该深度学习模型包含1 个输入层模块、1 个特征抽取层模块和1 个分类层模块.其中,输入层模块由1 个全连接网络和ReLU 激活函数构成.特征抽取层模块由数量不固定的全连接网络构成,在全连接网络之间采用ReLU 激活函数,以及1 个丢弃层Dropout.分类层模块由1 个全连接网络构成,输出每一个样本的得分,然后使用Softmax 函数对得分进行计算后输出150 个漏洞类别预测的概率值,其中概率值最大的即为最终的分类结果.
模型中使用的损失函数是交叉熵损失函数(cross entropy loss),如式(2)中,Closs表示损失值.除此之外,模型中也使用余弦相似度(cosine similarity)公式来计算相同类型向量之间相似性的损失计算,以及不同类型向量之间相似性的损失计算,如式(3)和式(4).其中,式(2)中的M表示漏洞类别的数量.yic表示符号函数(0 或者1),如果样本i的真实类别等于c,则yic=1,否则yic=0.pic表 示样本i属于类别c的概率预测值.式(3)中的Sloss表示目标样本与同类型样本的相似性计算的损失值,式(4)中的Dloss表示目标样本与不同类型样本相似性计算的损失值,Ti,Si,Di分别代表目标样本、同类型样本和不同类型样本向量的各分量.最后,把这3 个损失值进行相加得到最终的模型损失值Loss,如式(5)所示.
3 实验与评估
3.1 实验环境
实验所用的计算机使用的CPU 为2 颗E4216,32 核64 线程,主频为2.1 GHz,显卡为一块NVIDIA Quadrp,显存为4 GB,硬盘容量为3.6 TB,内存大小是16 GB.软件环境采用Linux 20.04,开发语言为Python 3.8.深度学习框架采用Pytorch1.10.1+Cuda11.3.
3.2 实验数据集
本文采用2.5 节所构建的数据集,样本总数为280 793,其中含有漏洞的代码为95 821 个,漏洞类型总数为150;不包含漏洞的代码为184 972 个.样本集中所有样本的标签根据SARD 数据集的注释进行标注.
3.3 评估指标
在深度学习领域,混淆矩阵是通用的衡量模型性能的指标,该矩阵描述了数据集中样本的实际类别和预测类别之间的混合,即真阳性(true positive,TP)、假阴性(false negative,FN)、假阳性(false positive,FP)和真阴性(true negative,TN).其中,TP表示漏洞代码被分类正确的情况,FN表示漏洞代码被分类不正确的情况,FP表示非漏洞代码被分类为漏洞代码的情况,TN表示非漏洞代码被分类为非漏洞代码的情况.本文使用3 种评估指标:召回率(Recall)、精确率(Precision)和准确率记为(Accuracy),如式(6)~(8)所示.基于评估指标分别绘制模型的精确召回曲线(precision recall curve,PR)、接受者操作特征曲线(receiver operating characteristic curve,ROC).同时,在实验的过程中也观察了模型损失函数值的变化情况.
3.4 实验过程
3.4.1 数据集的平衡性问题
如2.5 节所述,数据集中样本总数为280 793.其中漏洞代码数量为95 821,非漏洞代码数量为184 972,包含的漏洞类型为150 种,漏洞种类以及各种漏洞对应的样本数量请查阅附录A 中的表A1.为了直观地显示出各种漏洞类型所占的比率,画出它们的饼状图,如图3 所示(注:由于数据集中漏洞类型较多,图3中并没有把所有漏洞类型的标注显示出来).
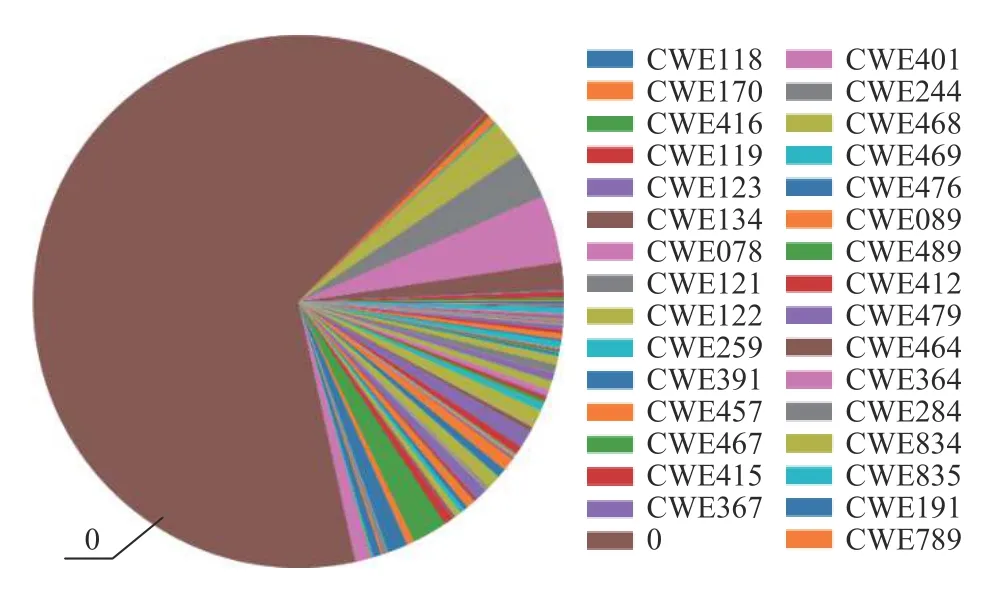
Fig.3 Vulnerability type distribution of datasets图3 数据集漏洞类型分布
从图3 中可以看出,这样的数据集存在2 个问题:问题1 是数据集中非漏洞代码的数量非常大,如图3中棕色区域所示;问题2 是漏洞代码分布情况非常不平衡.这2 个问题都会使得模型产生严重的过拟合或欠拟合,降低模型的识别能力.针对这2 个问题采用2 种方式进行解决:1)对数据集中的非漏洞代码进行随机欠采样处理,降低非漏洞代码的比例,处理之后的数据集分布情况如图4 所示.经过这样的处理后,数据集中非漏洞代码的数量降为16 359,各种漏洞代码数量仍为95821.如图4 中灰色区域所示,数据集中样本总数为112180.经过处理之后的数据集中非漏洞的样本数量大幅度地降低,使得数据集整体处于基本平衡的状态.2)把数据集中的样本数量依据6:2:2 的比例分为训练集、测试集和验证集.训练集用来训练模型,测试集用来测试模型的评价指标,验证集用来验证模型的漏洞识别效果.正如问题2 数据集中各种漏洞类型的样本数量存在不平衡的问题,对这个问题的解决采用对训练集中漏洞数量较少的漏洞类型进行过度采样的方法,具体使用边界线-SMOTE(borderline-SMOTE)技术.之所以不对测试集和验证集过度采样,是因为测试集和验证集是用来检验模型的效果,其数据分布情况必须保持原始状况,这样才能保证测试的真实性和有效性.

Fig.4 Vulnerability type distribution after data set processing图4 数据集处理后的漏洞类型分布
经过边界线-SMOTE 技术处理后的训练数据集中,样本总数为239 691,各种漏洞类型平均样本数量为1 597,整体分布情况如图5 所示.从图5 中可以看出训练数据集中各漏洞类型的数据量基本保持平衡,非漏洞的数据量占比稍大,如图5 中绿色部分所示.这和漏洞分布的实际情况保持一致.在真实的漏洞分布中,存在漏洞的程序的数量毕竟较少,而不存在漏洞的程序较多.到此为止,实验中需要的数据集处理完成.从整体上看该数据集符合深度学习训练对数据集平衡性的要求,而且从图6 中可以看出,在训练的过程中,模型训练损失值和测试损失值下降趋势相同,并且差值比较小,说明模型使用这样的数据集进行训练,泛化能力较强,可以有效地防止深度学习过程中出现的欠拟合和过拟合现象的发生.此外,在3.4.2 节评价实验中较高的验证准确率也说明该数据是比较合适的,可以应用于模型训练与检测的过程.
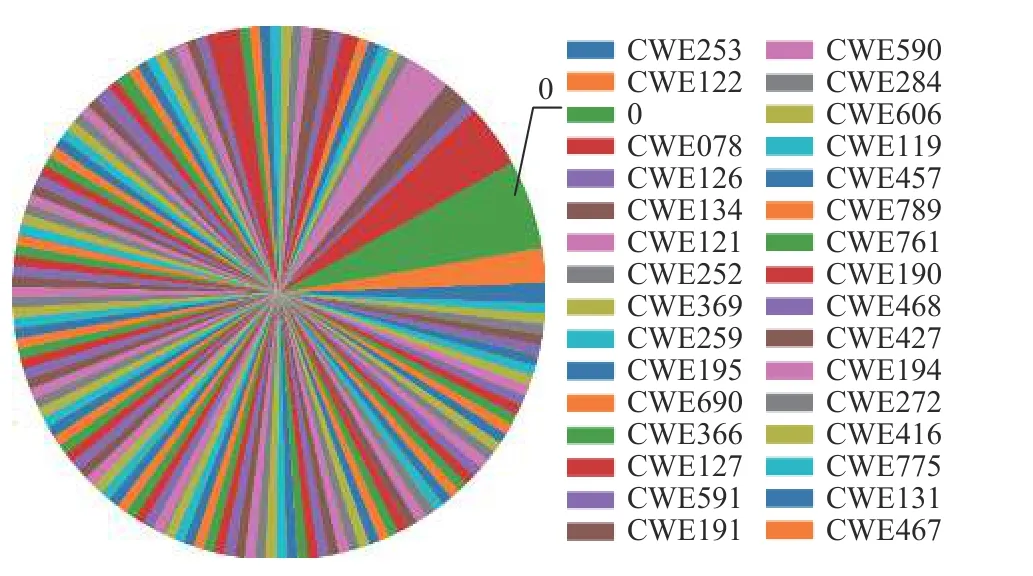
Fig.5 Vulnerability type distribution after over-sampling图5 过度采样后的漏洞类型分布
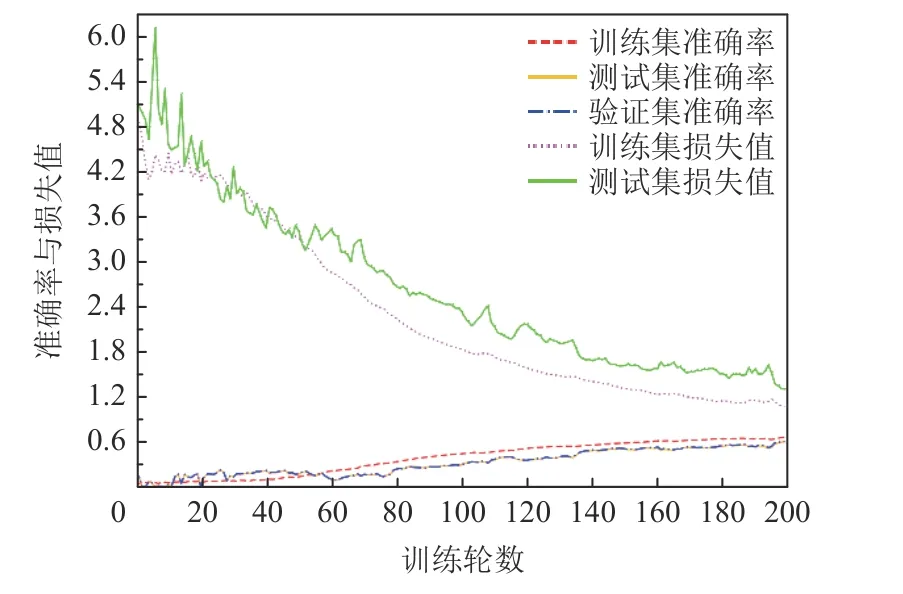
Fig.6 Changes of accuracy rate and loss value when comparative learning is not used during training图6 训练中未使用比较学习时准确率和损失值的变化
3.4.2 实验评价
为了评价本文所提出的基于比较学习的方法的有效性,设置了3 个实验任务.任务1 验证比较学习的漏洞识别的准确率和训练过程中的损失值变化情况;任务2 对比较学习的性能开销进行分析;任务3对基于比较学习的模型学习能力进行检测.在实验过程中模型的各参数进行如下的设置:epoch=200,batchsize=2 048,pnum=10,nnum=10,dropout=0.2,learningrate=0.2,其中参数pnum表示训练集中每个样本对应的同类型样本的数量,参数nnum表示训练集中每个样本对应的不同类型样本的数量,它们都可以取不同的数值,这里设置为10.
任务1.比较学习在漏洞识别准确率和损失值方面的表现.
对于任务1,分为2 组实验:第1 组实验比较在本文整理的数据集上应用比较学习前后的漏洞识别的准确率和损失值变化情况;第2 组实验比较在文献[28]的数据集上应用比较学习前后的表现.经过大量的实验后,第1 组的实验结果如图6 和图7 所示.其中图6 显示了未应用比较学习时模型训练过程中训练集、测试集和验证集的准确率变化,以及训练集和测试集损失值的变化情况.图7 显示了应用比较学习后训练集、测试集和验证集的准确率变化,以及训练集和测试集损失值的变化情况.

Fig.7 Changes of accuracy rate and loss value after comparative learning is used during trinting图7 训练中使用比较学习后准确率和损失值的变化
从图6 中可以看出,未应用比较学习前,模型的训练集、测试集和验证集的准确率不高,训练集准确率为68.5%,测试集的准确率为62.9%,验证集的准确率为62.5%;而且训练集和测试集的损失值的下降趋势不平稳,波动起伏较大,很不稳定.从图7 中可以看出,在应用比较学习后,模型的训练集、测试集和验证集的准确率稳步提高,最后趋于平缓,训练集的准确率达到95%,测试集的准确率达到92.0%,验证集的准确率达到91.9%(注:由于测试集和验证集的准确率几乎相同,所以在图6 和图7 中显示得不明显).训练集和测试集的损失值在前20 轮训练中迅速下降,急速收敛,在之后的训练中趋于平缓,显示出模型逐步趋于稳定.
在第2 组实验中,选取文献[28]的数据集验证本文提出的比较学习方法的效果.文献[28]使用的数据集被称之为MVD(multiclass vulnerability dataset).在该漏洞数据集中,总共有181 641 个被称为代码片段(code gadgets)的样本程序.其中,138 522 个样本没有漏洞,43 119 个样本存在漏洞,其漏洞类型覆盖40 种CWE 类型的漏洞.在实验中,仍然按照6:2:2 的比例划分训练集、测试集和验证集.图8 和图9 分别展示了在MVD 数据集上使用比较学习前后的模型训练集、测试集和验证集的准确率变化,以及训练集和测试集损失值的变化情况.

Fig.8 Changes of accuracy value and loss value for MVD when comparative learning is not used during training图8 训练中未使用比较学习时MVD 准确率和损失值的变化
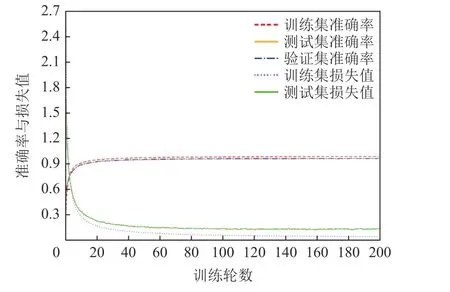
Fig.9 Changes of accuracy value and loss value for MVD after comparative learning is used during training图9 训练中使用比较学习后MVD 准确率和损失值的变化
从图8 中可以看出,未应用比较学习前,文献[28]的训练集、测试集和验证集的准确率不高,训练集准确率为78.1%,测试集的准确率为73.1%,验证集的准确率为73.09%;而且训练集和测试集的损失值的下降趋势不平稳,波动起伏较大,很不稳定.
从图9 中可以看出,在应用比较学习后,文献[28]中的模型训练集、测试集和验证集的准确率在比较短的时间内急速提高,在将近20 轮时达到95%以上,最后趋于平缓,训练集的准确率稳定在97.9%,测试集的准确率稳定在95.9%,验证集的准确率稳定在96.2%(注:由于测试集和验证集的准确率几乎相同,图9 中显示得不明显).训练集和测试集的损失值在前20 轮之内迅速下降,急速收敛,在之后的训练过程中趋于平缓,显示出模型逐步稳定下来.
任务2.比较学习在性能开销方面的实验分析.
在比较学习中,由于需要为训练集中每个样本选取数量不同的同类型样本和不同类型的样本进行训练学习,所以比较学习的性能开销主要花费在为每个样本选取学习的样本方面.实验数据集中总共包含150 种不同类型的漏洞样本,所以为每个样本选取不同数量的、不同类型的漏洞样本时,其数量上限为150.对于为每个样本选取漏洞类型相同的样本,其数量与不同类型漏洞样本的数量类似.因此在实验中,以数量5 为步长,递进地为每个样本选取数量不同的同类型样本和不同类型样本,然后测量训练时内存的使用量和花费的时间.经过30 次实验后,绘制出了如图10 所示的比较学习性能开销图.当选择不同数量的比较学习样本时,训练集、测试集和验证集的准确率变化情况,如图11 所示.

Fig.10 Changes of model performance varying with the number of comparative learning samples图10 模型性能随比较学习样本数量的变化
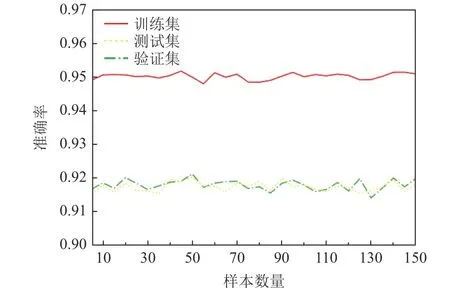
Fig.11 Changes of model accuracy varying with the number of comparative learning samples图11 模型准确率随比较学习样本数量的变化
从图10 中可以看出,总体上模型的性能开销与选取的比较学习的样本数量成正比关系,随着比较学习样本数量的增加,模型的性能开销也逐渐增大.当为训练集中的每个样本选取150 个比较学习的样本时,性能开销达到最大值,此时内存使用量达到614.9 MB,消耗的时间达到1 243 s.但同时在实验中也观察到,尽管模型的性能开销随着比较学习样本数量的增加而增加,但模型的准确率并没有随着样本数量的增加而剧烈地变化,总体上维持在固定的区间之内.训练集准确率的范围为0.948~0.952,测试集的准确率范围为 0.914~0.921,验证集的准确率范围为0.915~0.920,如图11 所示.因此针对这种情况,可以为训练集中的样本选取数量适当的比较学习样本来降低模型的性能开销,而模型的准确率却不会发生大的变化.而且,实验也从模型的PR 曲线和ROC 曲线衡量了当比较学习样本的数量发生变化时模型的PR 值和ROC 值的变化情况.经过大量实验表明,模型的PR 值和ROC 值总体保持稳定,如图12 和图13 所示.图12 显示模型测试过程中每种漏洞类型的PR 曲线.从图12 中可以看出,多数漏洞类型的PR值较高,在召回率与精确率之间取得了不错的平衡.最终所有漏洞类型的平均PR 值为0.85,如图12 中橘黄色区域所示.图13 显示了模型测试过程中每种漏洞类型的ROC 曲线以及AUC(area under curve).从图13 可以看出,多数类型的 ROC曲线趋向于图的左上方,并且所有类型的 AUC平均值为0.96,如图13 中橘黄色区域所示,说明模型的总体效果与性能比较好.

Fig.12 PR curve of the model test图12 模型测试的PR 曲线

Fig.13 ROC curve the model test图13 模型测试的ROC 曲线
任务3.基于比较学习的模型学习能力的检测.
本文在实验的过程中,也对本文提出的基于比较学习的模型的学习能力进行了检测.其具体的方式是比较模型对测试集中各种类型样本的分类能力.图14 是原始测试集特征的t-SNE(t-distributed stochastic neighbor embedding)图,图15 是使用训练完的深度学习模型提取的测试集特征的t-SNE 图.

Fig.15 t-SNE diagram of test set features extracted by deep learning model图15 深度学习模型提取的测试集特征的t-SNE 图
从图15 中不难看出,本文基于比较学习训练的深度学习模型具有较强的分类能力,如图14 和图15中的紫色区域所示.在图14 中,紫色区域代表的漏洞类型比较分散.而在图15 中,紫色区域代表的漏洞类型比较好地聚集在一起,说明模型学习到了测试集中各漏洞类型的特征,并且测试集中各漏洞类型的特征经过本文训练的深度学习模型的处理,具有了较强的可区分性,这就使得模型识别漏洞的能力大幅度地提高.
4 样本符号化对模型准确率影响的讨论
众多基于深度学习的漏洞识别模型为了提高模型的泛化能力,都会对数据集中的样本进行符号化,去除个性化的程序特征,辅之统一的符号来代替这些特征,降低模型提取程序特征的难度,提高模型的泛化能力.但在实验过程中发现,在基于比较学习的深度学习漏洞检测任务中,数据集中的样本程序是否符号化对模型的准确率并没有太大的影响.实验分别以本文整理的数据集和文献[28]中的数据集为对象进行了验证.实验的过程为:首先对经过符号化处理的数据集进行学习训练,测量其准确率;然后再对未经过符号化处理的数据集进行学习训练,测量其准确率;最后对比这2 种模式下符号化与否对模型准确率的影响程度.实验结果如图16、图17 和图18、图19 所示.图16 中是本文中的数据集经过符号化处理后,训练学习时的准确率.其中,训练集的准确率为95.1%,测试集的准确率为91.6%,验证集的准确率为91.5%.图17 显示的是没有经过符号化处理的本文数据集训练时的准确率,其中,训练集的准确率为93.7%,测试集的准确率为92.0%,验证集的准确率为91.8%.

Fig.16 Accuracy of our data set after symbolization图16 符号化后的本文数据集的准确率

Fig.17 Accuracy of our data set after non-symbolization图17 无符号化后的本文数据集的准确率

Fig.18 Accuracy of MVD data set after symbolization图18 符号化后的MVD 数据集的准确率

Fig.19 Accuracy of MVD data set after non-symbolization图19 无符号化后的MVD 数据集的准确率
从图16 和图17 中可以看出,对数据集进行符号化处理和不进行符号化处理,模型的准确率变化幅度不是很大,其中训练集的变化幅度稍大点,差值达到了1.4,而测试集和验证集的变化幅度很小,几乎可以忽略不计.类似地,文献[28]中的MVD 数据集在基于比较学习的模式下也有相同的情况.通过以上的2 个实验不难看出,数据集中的样本是否符号化并不会影响基于比较学习的深度学习模型的训练方式,不会对训练的准确率产生较大的影响.其原因在于:基于比较学习的深度学习方式,通过大量同类型样本和不同类型样本的比较学习,模型确实学到了同类型程序和不同类型程序内在的特征,数据集中样本是否符号化并不会影响比较学习模式下模型的实际表现.
5 结论
本文提出了一种基于比较学习的漏洞检测方法.在比较学习法中,针对数据集中的每个样本为其构建同类型的样本集合和不同类型样本的集合.通过这种方式,使得深度学习模型在训练的过程中,可以提取同类型样本的共有特征,以及不同类型样本中可区分性较强的特征,使得深度学习模型识别漏洞的能力大幅度地提高.尽管本文提出的比较学习方法可以提高基于深度学习的漏洞识别模型的准确率,并且在本文整理的数据集以及相关文献中的数据集上有不错的表现,漏洞识别准确率比较高,但本文方法并没有在实践中进行应用,这是未来将要开展的工作,相信会在不久的将来,本文所提出的方法会有不错的实际应用效果.
作者贡献声明:陈小全、刘剑提出了算法思路和实验方案,以及论文撰写;夏翔宇、周绍翔负责数据收集整理与深度学习模型训练.
附录A.
猜你喜欢
今日农业(2022年13期)2022-09-15
数学教学通讯·小学版(2022年4期)2022-05-29
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
新校园·上旬刊(2017年10期)2017-12-08
纺织科技进展(2016年3期)2016-11-29
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
