
基于双判别器对抗模型的半监督跨语言词向量表示方法
2023-09-22 06:21张玉红植文武李培培胡学钢
计算机研究与发展 2023年9期
张玉红 植文武 李培培 胡学钢
(大数据知识工程教育部重点实验室(合肥工业大学) 合肥 230009)
(合肥工业大学计算机与信息学院 合肥 230601)
(zhangyh@hfut.edu.cn)
词向量是将单词表示为多维、连续的实数向量数学嵌入,由于其能较好地表示语义、语法和结构等特征信息,在自然语言处理(natural language processing,NLP)任务中得到了广泛应用[1].然而词向量的训练需要丰富的语料库,这使得小语种如阿拉伯语、葡萄牙语等的词向量训练受到限制.为此,研究者提出了跨语言词向量表示方法[2-4],即利用资源丰富的大语种词向量表示来辅助资源相对匮乏的小语种词向量表示,该问题的研究已广泛应用于跨语言词性标注[5]、跨语言信息检索[6]、跨语言实体连接和分类[7]等领域.
近年来,跨语言词向量表示的研究取得了很大的进步,已有方法主要分为2 类:一类是联合训练方式[8],即在不同语言中使用单词对齐的平行语料库同时训练跨语言词向量;另一类是映射方式[2-3,9],即在预训练的不同语言词向量空间之间学习一个线性映射矩阵.由于平行语料库的构造需要昂贵的代价,因此目前研究主要集中在后者.
文献[3]发现,不同语言的词向量空间具有相似的几何结构,即同构性假设.基于这一发现,通过最小化种子字典对的距离来学习线性映射关系,从而对齐词对.后续的研究[2,9]主要从减小字典规模等角度对文献[3]改进.随着生成对抗模型的广泛应用,研究者们提出了基于对抗的无监督跨语言词向量表示方法[10-12].文献[10]将生成对抗模型引入跨语言词向量表示,构建了不需要平行语料库的无监督跨语言词向量学习方法.随后的工作致力于提升无监督方法的稳定性和准确性.文献[11]通过在判别器中加入噪音提高对抗的稳定性.文献[12]引入对抗训练的后处理步骤,迭代更新学习到的映射矩阵.
尽管基于对抗训练的无监督方法在近距离语言对上取得了一定的成功,但在远距离语言对上效果却不尽人意.比如,在英语到西班牙语和英语到德语的近语言对上,其平均结果在80%左右,但在英语到土耳其语、普什图语等远语言对上的平均结果不足30%,有些语言对上甚至小于3%.显然该类方法在远距离语言对上效果难以令人满意[13].造成这一结果的原因可能有2 个:1)远距离语言对上同构性假设的不成立导致这种线性映射关系难以成立[14].一般情况下,不同语系的语言由于在单词语义、句法结构等方面存在较大差异被认为是远语言对,其词向量空间之间的同构性也较弱.2)无监督方法从全局角度最小化源语言空间与目标语言空间的距离来求解映射关系,仅能实现词向量空间的全局对齐,是一种粗粒度的对齐,而这种粗粒度对齐条件下可能存在多种细粒度的映射关系,从而难以保证细粒度词的对齐精度.如图1 所示,中文和英文2 个空间在全局对齐的条件下,可能产生“cat”与“猫”对齐,也可能产生“cat”与“车”对齐.

Fig.1 The possible mapping in unsupervised methods图1 无监督方法产生的多种可能映射
综上可见,跨语言词向量表示方法的效果大多依赖于同构假设和监督信号,无监督方法应用于非同构语言对时难以实现高质量对齐.因此,如何在远语言对上学习较好的映射关系是当前跨语言词向量表示中的挑战性问题.
现实应用中尽管监督信息是昂贵的,但获取少量监督信息在多数场景下仍是可行的.此外,在映射关系的迭代学习过程中产生的预对齐词对对学习映射关系也具有一定的监督作用.鉴于此,提出基于双判别器对抗的半监督跨语言词向量映射学习方法.首先,为了缓解远语言对上非同构性对映射关系学习的影响,使用自动编码器分别将源语言词向量空间与目标语言词向量空间映射到隐空间,使其在隐空间上具有相对较好的同构性.其次,在已有对抗模型生成的全局初始映射基础上增加一个细粒度判别器,并引入负样本字典和预对齐字典等信息进行半监督学习,通过计算初始生成字典与负样本字典、预对齐字典之间的距离进一步判断初始生成字典的正确性,消减词对映射的多种可能,提高初始字典对齐精度.本文的创新点有3 个方面:
1)设计了一个双向映射共享的细粒度判别器以构成包含双判别器的对抗模型,对原判别器生成的映射关系进行优化,以提升方法的性能.
2)提出引入负样本字典,并将其和预对齐字典一起进行半监督对抗学习,通过计算两者与初始生成字典的距离来判别初始生成字典的有效性,从而在全局对齐基础上提高细粒度的单词对齐精度.
3)多个数据集上的实验结果表明本文方法能通过半监督方式进一步优化全局对齐,提高词语对齐的精度.
1 相关工作
基于映射的跨语言词向量表示方法将不同语言的词向量空间映射到一个共同空间,使得共同空间中不同语言具有相同语义的词尽可能接近.根据种子字典的数量与作用,已有方法大致分为3 类:监督方法、无监督方法和半监督方法.
1.1 监督方法
监督方法主要是借助部分对齐的词对来学习映射关系.
文献[3]发现不同语言的词向量空间具有相似几何结构,通过最小化5 000 个种子字典的欧式距离学习1 个线性映射矩阵,将源语言词向量空间映射到目标语言词向量空间.随后的工作对其进一步完善和改进.文献[15]使用典型关联分析(canonical correlation analysis,CCA),将源与目标映射到第三方共享空间,实现双向映射关系学习.在映射学习任务中经常出现1 个词同时被认为是多个词的映射,这种现象被称作为Hubness 问题,该问题是影响映射学习性能的主要因素之一.文献[16]通过优化正确映射对与错误映射对之间的最大边界解决Hubness 问题,提高映射学习性能.为解决不一致问题,文献[17]从归一化词向量、对线性映射施加正交约束、最大化词与词向量间的相似度3 个角度避免映射矩阵学习陷入局部最优.文献[18]引入CSLS(cross-domain similarity local scaling)距离作为字典间的优化函数学习映射关系,提高了跨语言词向量表示性能.
相对来说,监督方法取得了较为满意的效果,但其效果很大程度依赖于种子字典是否充分.
1.2 无监督方法
无监督方法中映射关系的学习不需要平行语料库,具体可分为基于启发性规则和基于生成对抗模型2 个子类.
1)基于启发式规则.文献[19]使用主成分分析对齐2 种语言单词分布的二阶矩,再利用计算机视觉中的迭代最近点(iterative closest point,ICP)方法迭代细化对齐.文献[20]通过探索词向量空间之间的结构相似性学习初始矩阵,然后使用具有鲁棒性的自学习步骤改进映射矩阵.文献[21]将词向量对齐看作是最优传输(optimal transport,OT)问题,使用GW(Gromov-Wasserstein)距离衡量词对间的相似度.
2)基于生成对抗模型.文献[10]提出使用对抗训练来构造双语字典,采用线性映射矩阵作为生成器,二元分类器作为判别器,该方法在双语词典构建任务上取得了突破性的成果,但存在难以收敛问题.文献[11]将高斯噪音注入判别器以提高对抗训练的稳定性.文献[12]在对抗训练基础上引入后处理步骤,迭代更新对抗训练学习到的映射矩阵,同时使用CSLS 寻找最邻近词以缓解Hubness 问题.文献[22]引入自动编码器构建隐空间后再进行对抗训练,缓解了跨语言向量空间非同构假设带来的影响.
目前无监督方法的性能与监督方法具有明显差距,尤其是在远语言对上.
1.3 半监督方法
半监督方法借助少量的字典或者其他弱监督信息学习映射关系.
文献[2]借助自学习框架,仅使用 25 个词对学习线性映射,获得与监督方法相当的性能.文献[23]使用少量对齐的种子字典和未对齐的嵌入空间进行半监督学习,并利用过滤技术缓解Hubness 问题.此外,文献[24]在没有种子词典情况下,将2 种语言中出现的少量相同字符串作为弱监督信号学习线性映射.文献[9]利用相同拼写的字符串作为弱监督信号学习映射关系.
尽管半监督方法利用监督信息提高了跨语言词向量表示学习的精度,但这种提升大多表现在近距离语言对上,在远距离语言上的表现仍难以令人满意.
2 基于双判别器的跨语言词向量表示方法
给定预训练的源语言词向量空间X={x1,x2,…,xn}和目标语言词向量空间Y={y1,y2,…,yn},n为向量空间中的单词数,本文的任务是学习一个双向映射关系,将2 个向量空间映射到1 个公共空间,使得2个互为翻译的词在该空间上彼此距离最近,从而实现跨语言词向量表示.
2.1 方法框架
为提高远语言对上词向量对齐效果,提出半监督的双判别器对抗词向量表示方法.图2 展示了本文方法框架,分为2 个模块:1)基于自编码器构建隐空间X′和Y′,以缓解远语言对上同构性假设不成立的影响;2)在学习到的隐空间上,利用负样本字典Dng和预对齐种子字典Dal进行半监督对抗训练,学习双向映射关系以对齐2 个隐空间中的词对.其中负样本字典Dng是在映射关系训练过程中产生的,将在2.3 节详细介绍.
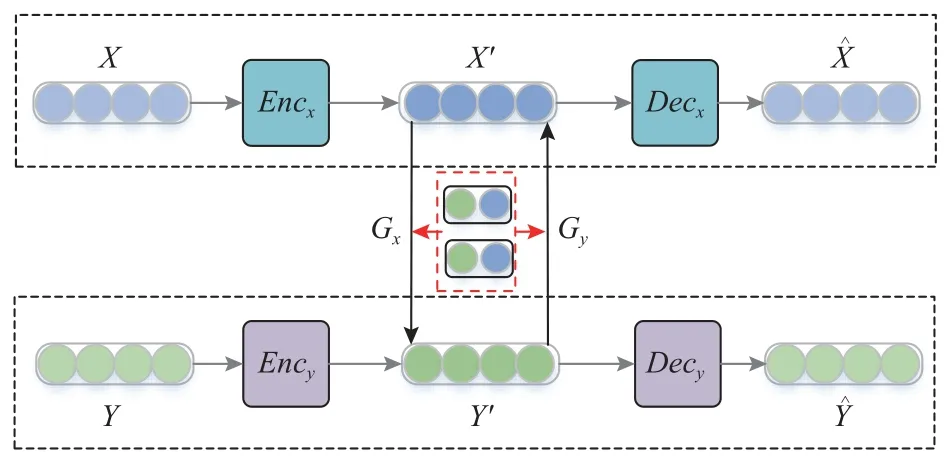
Fig.2 The framework of our method图2 本文方法框架
隐空间构建的具体方法为:首先,使用2 个编码器Encx与Ency分别将源语言与目标语言词向量空间X和Y映射到2 个独立的隐空间X′和Y′;其次,利用解码器Decx,Decy对隐空间解码得到与,通过最小化2 个空间的重构误差,即ˆ=X,=Y,以保证编码后的隐空间能代表原空间的信息.
下面重点介绍基于2 个隐空间X′和Y′,半监督学习双向线性映射Gx和Gy的过程,如图3 所示.图3 中生成器Gx和判别器Dx构成初始对抗模型,从全局角度学习X′到Y′的初始映射.在此基础上,引入细粒度判别器D和字典信息(包括负样本字典Dng和预对齐字典Dal)半监督地对初始映射关系进行细粒度优化,从而得到较为准确的X′到Y′的词语对齐映射.同样地,生成器Gy、判别器Dy以及细粒度判别器D用于学习Y′到X′的映射.为保证双向映射后的词对能相互对齐,提高对齐精度,双向映射学习过程共享细粒度判别器D.
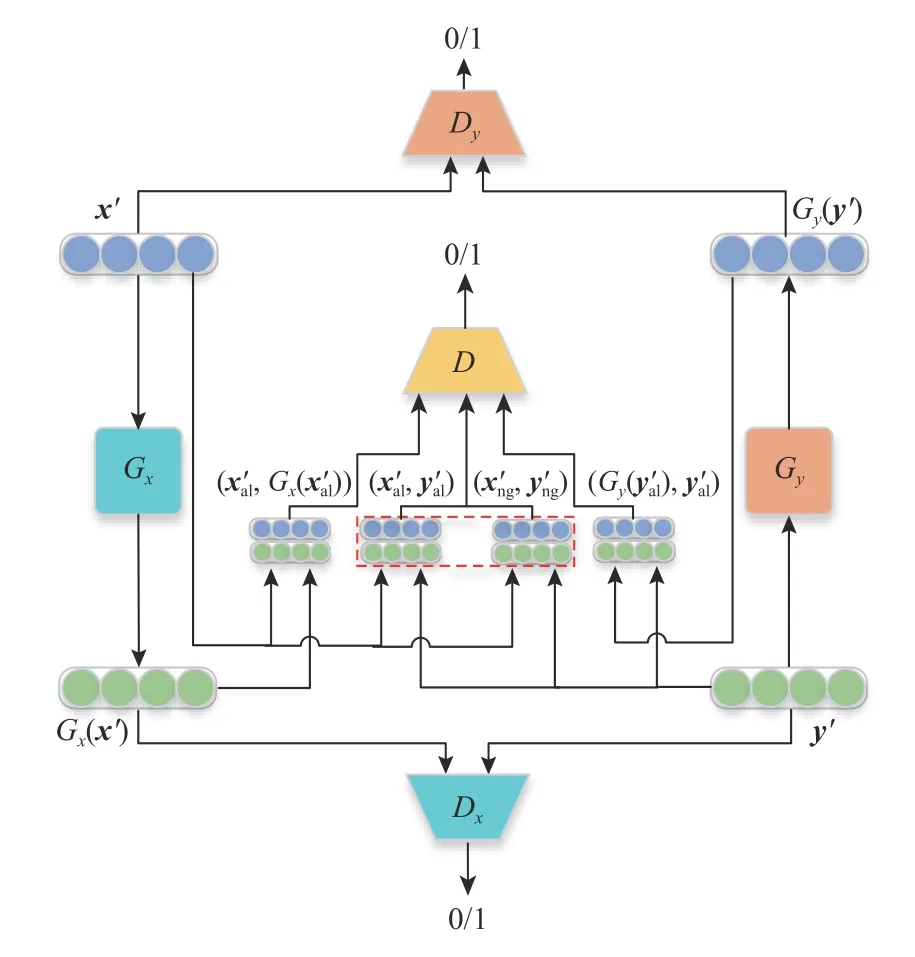
Fig.3 The bidirectional mapping learning based on double discriminators图3 基于双判别器的双向映射学习
双向映射关系学习过程中,需要考虑双向的损失函数,可具体表示为
由于双向映射学习过程类似,下面以源语言到目标语言的映射学习Lx为例进行说明.X到Y的映射学习过程分为初始映射关系学习和共享细粒度优化2 个步骤.
2.2 初始映射关系学习
初始对抗模型包含1 个生成器和1 个判别器.生成器Gx用于生成X′到Y′的初始映射,基于该映射生成的词对尽可能地混淆判别器Dx;而Dx则用于识别输入是X′的生成空间Gx(x′) 还是Y′空间.通过Gx和Dx不断地对抗训练形成初始映射关系Gx和基于该关系生成的初始对齐字典
在这一过程中,判别器Dx的损失函数可定义为
其中Ex和Ey分 别表示对源语言空间X′和目标语言空间Y′的采样,通过最小化LDx使判别器Dx能最大程度地鉴别出Gx(x′)和y′.
而生成器Gx的损失函数表示为
2.3 共享细粒度优化
2.2 节所述的初始对抗模型仅基于全局距离度量生成一个初始的映射关系,由于缺乏必要的监督信号引导,导致其生成的词对映射存在多种可能,难以保证正确性.为此,在原有对抗模型基础上引入负样本字典和预对齐字典 (Xal,Yal)作为监督信号,利用双向映射共享的细粒度判别器D识别是真实翻译对还是通过生成器生成的初始映射对,从而识别初始映射对中的正确翻译对,提升对齐精度.
在细粒度判别器判别过程中,需要考虑2 个主要问题.
在预对齐字典 (Xal,Yal)基础上进一步引入负样本
对抗训练的成功依赖于如何有效区分真实样本和伪样本,而预对齐字典和负样本分别提供了正、负样本的监督信号,有利于提高判别器D的判别能力.本文设计了随机负采样和基于邻近相似度2 种负样本字典生成方法.
①随机负采样方法.初始映射生成后,一般采用最近邻方法寻找初始翻译对,从而使初始翻译对的2 个词具有一定的相关性.本文面向所有的初始翻译对,采用随机采样策略获取负样本,具体可表示为
②基于相似度的负采样方法.随机负采样策略在全局范围内随机选择负样本,其选择的负样本与正样本具有较强差异性但相关性不足.为此提出基于相似度的负样本采样方法.首先,从所有初始翻译对中选择最接近Gx(x′) 的前k个目标词;其次,排除第1 个目标词以及监督种子对,以避免其与真实对齐的样本重复;然后,从前2~k个中进行采样.与随机负采样方法相比,这种策略具有2 方面优势:一方面,将负样本范围确定在基于近似度的前k个样本中,确保选择的负样本与真实对齐样本具有一定的语义相关性;另一方面,排除了第1 个目标词和监督种子,从前2~k个中采样.这种方案即使在第1 个目标词为正样本不满足时,从前2~k个中排除监督种子字典后再采样,能大概率排除真实对齐被采样为负样本的情况,确保两者的语义差异性.因此,本方案所选的负样本与真实对齐样本既有语义相关性又有语义差异性,达到负样本的参照作用.这里k=5,相似度计算采用余弦函数,记为
2)如何进行判别
共享细粒度判别器D的任务是利用监督的负样本和对齐字典,通过判别初始映射生成的词对与字典间的距离,从初始映射对中进一步筛选出更靠近监督词对的翻译对.因此,共享细粒度判别器D的损失函数可被定义为
此外,需要说明的是,为了对齐种子字典的空间分布,式(6)中判别器D不是从整个词向量空间中采样,而是从种子字典中采样.
在上述方法的基础上,为保证映射关系的准确性,引入循环一致性约束,即源空间被映射到目标空间后可以准确地再映射回源空间,源语言的循环一致性损失函数表示为
综上,从源到目标的半监督对抗训练损失函数可表示为
类似地,从目标到源的半监督对抗训练损失函数表示为
3 实验结果及分析
3.1 数据集与对比实验
采用Muse[12]与Vecmap[20]这2 个数据集来验证方法的有效性.数据集和源代码见https://github.com/joyce99/ZhiWenwu/tree/master/MUSE-master.
Muse 数据集包含30 种语言,词向量维度为300,是使用FastText 方法基于维基语料库训练所得,包含110 个语言对的种子字典.种子字典分为训练集与测试集,分别包含5 000 个和1 500 个翻译对.本文从中选择了9 个语言对,分别是英语(En)、西班牙语(Es)、意大利语(It)、法语(Fr)、阿根廷语(Ar)、土耳其语(Tr)、南非荷兰语(Af)、普什图语(Fa)、奥罗语(Et).根据GH(Gromov-Hausdorff)距离[23](记为dGH)计算语言对之间的空间分布相似度,dGH<0.3 表示2个空间为近语言对,dGH≥0.3 表示2 个空间为远语言对.
Vecmap 数据集包含英语(En)、西班牙语(Es)、意大利语(It)、芬兰语(Fi)、德语(De)等单语词向量.由于该数据集是基于网络爬取的语料库,其训练所得词向量质量不高,导致其同构性较弱.现有方法在该数据集上的效果普遍不理想.该数据集仅提供英语到西班牙语、意大利语、芬兰语、德语的单向字典.为完成双向映射学习,额外补充了反向字典.具体做法是将英语到其他语种的字典反转和去重,以确保测试集为1 500 个翻译对.
对比实验包括无监督方法、监督方法和半监督方法.无监督方法包括:1)文献[12]基于生成对抗网络对齐2 个空间以获得初始词典,并引入后处理步骤,迭代更新对抗学习的映射矩阵;2)文献[20]利用词向量的结构空间相似性获得初始映射矩阵,并利用自学习算法迭代更新初始映射矩阵;3)文献[22]利用自动编码器将词向量空间映射到隐空间以缓解同构假设的约束,然后利用对抗训练来对齐隐空间.监督方法包括:1)文献[12]通过最小化翻译词对间的距离学习正交映射,并使用CSLS 距离寻找最近邻;2)文献[25]将映射到共享空间的步骤简化为训练单个正交转换.半监督方法则使用对齐的双语词典和未对齐的嵌入进行半监督映射矩阵学习,并用过滤技术缓解Hubness 问题[23].
3.2 实验设置
针对预训练的词向量空间,在Muse 和Vecmap数据集中选择词频最高的前20 万个词向量作为训练样本来学习跨语言词向量表示.在学习隐空间过程中,自编码器设置类似于文献[22],设置隐空间维度为400.在半监督对抗训练中,判别器Dx,Dy,D都使用包含204 个隐藏层的多层感知器,其激活函数为Leaky-ReLU 函数.其中判别器Dx和Dy使用词频前75 000 个词向量作为输入,判别器D从种子字典中进行采样,种子字典的初始数量为5 000 对,会随着迭代训练不断扩大数量.参照文献[12]的做法,每更新5 次判别器后更新1 次生成器.在对抗训练过程中,采用随机梯度下降方法,其中批大小为32,学习率为0.01,衰减率为0.98.采用CSLS 检索方法搜索最近邻种子字典,参数k=10.
实验采用P@1 作为评估指标来验证方法的精度,其计算方法为:
其中ti为方法学习到的映射空间中距离源空间单词si最近的单词.如果 (si,ti)为正确翻译对,则 (si,ti)=1,否则 (si,ti)=0.
3.3 实验结果与分析
3.3.1 近语言对的结果
表1 展示了各方法在Muse 数据集上近语言对的实验结果,由表1 可知:
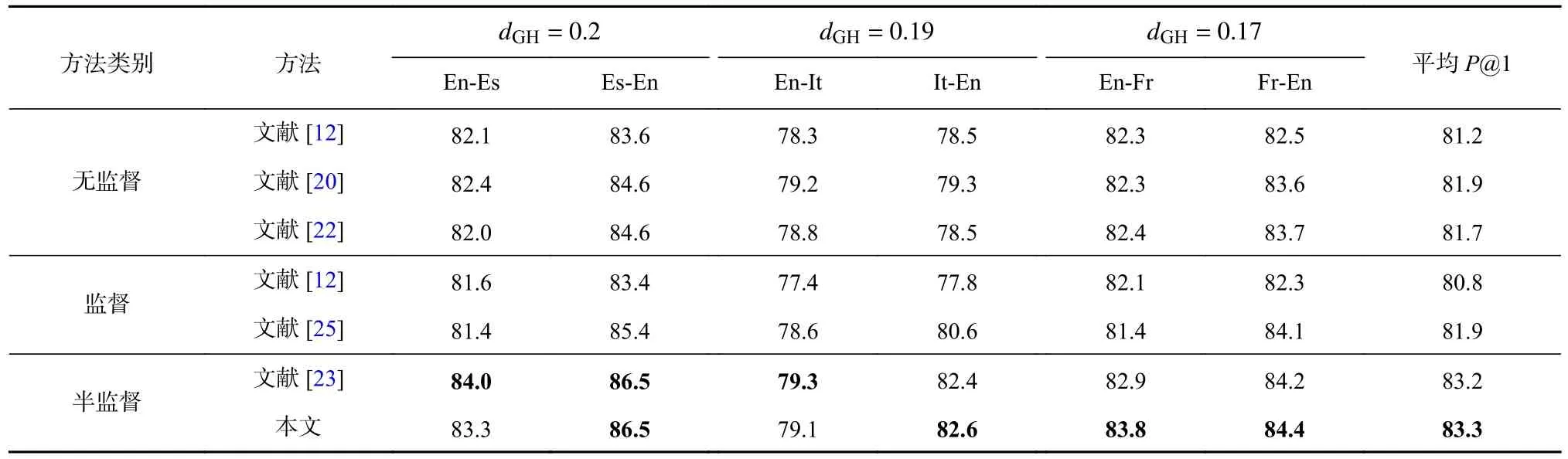
Table 1 P@1 Comparison of All Methods on Similar Language Pairs in Muse Dataset表1 各方法在Muse 数据集上近语言对的P@1 对比 %
1)各个方法在近语言对上的结果总体差异较小.
2)文献[23]方法与本文方法是2 个半监督方法,与其他方法相比,其性能平均提高了1%.半监督方法在学习过程中不断生成预对齐翻译词对,这些翻译对作为监督信号来辅助下一次迭代学习过程.当算法收敛时,所得的监督信号数量总体大于监督方法中给定的翻译词对数量,尤其是近语言对.因此,半监督方法比预先仅给定部分监督信号的监督方法更有效.
3)本文方法超越了大多数基准方法,在4 种语言对上略胜于文献[23]的半监督方法,说明了本文方法具有一定的优越性.
3.3.2 远语言对的结果
表2 和表3 分别展示了各方法在Muse 数据集的远语言对和Vecmap 数据集上各语言对的表现.
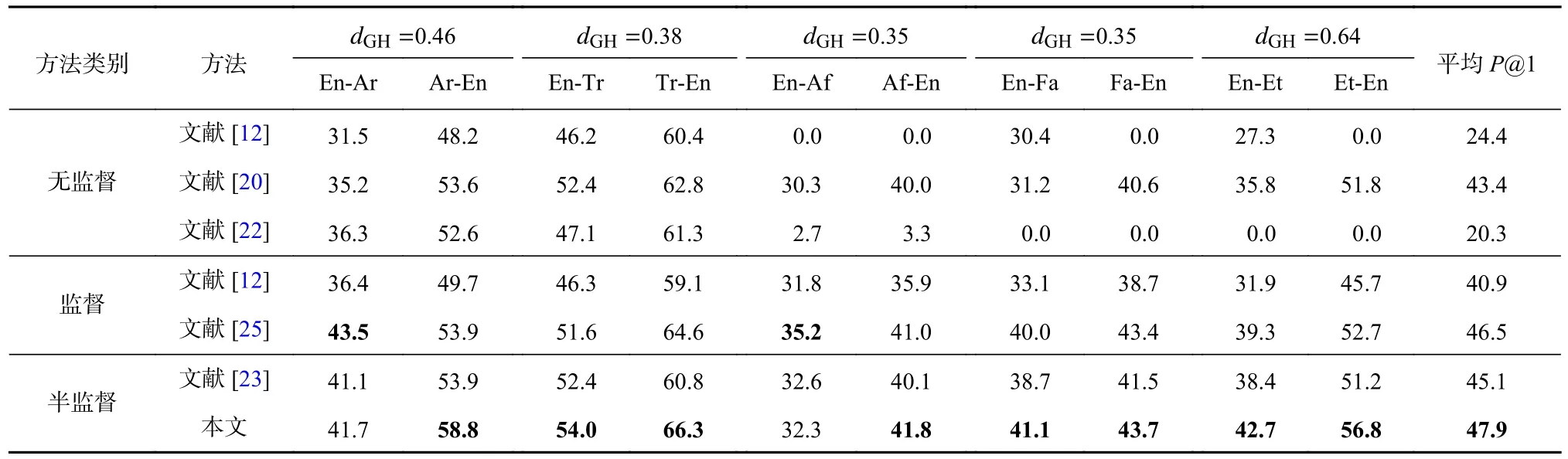
Table 2 P@1 Comparison of All Methods on Dissimilar Language Pairs in Muse Dataset表2 各方法在Muse 数据集上远语言对的P@1 对比 %

Table 3 P@1 Comparison of All Methods on All Language Pairs in Vecmap Dataset表3 各方法在Vecmap 数据集上各语言对的P@1 对比 %
1)与近语言对相比,半监督方法和监督方法在远语言对上的性能差异较大,一定程度上表明了种子字典等监督信号对于远语言对的映射学习具有重要作用.
2)半监督方法和监督方法性能好于无监督方法,而半监督方法和监督方法性能相差不大,表明了半监督方法仅利用少量种子字典就达到了监督方法的性能.
3)与监督方法相比,本文方法在2 个数据集上都具有一定的优势,表明了在训练过程中,利用前一次迭代预训练的种子字典和负样本字典辅助下一轮种子字典的生成是有效的.
4)本文方法优于无监督方法.由表2 可见,3 个无监督方法[12,20,22]在多个语言对上无法收敛.而本文方法P@1 在所有语言对上的结果有明显提升.与文献[20]方法相比,本文方法的P@1 分别提升了5.3%和2.2%.与文献[22]的方法相比,其P@1 也提升了27.6%和20.2%.实验性能的提升表明引入细粒度判别器进行半监督学习能进一步提高2 个空间的对齐精度.
5)本文方法好于其他半监督方法.与文献[23]的半监督方法相比,本文方法的P@1 平均提高了2.9%.这主要得益于自动编码器与多判别器的引入.通过自动编码器构建隐空间,一定程度上缓解同构假设的约束,而引入细粒度判别器能进一步提高对齐精度.
3.3.3 不同种子字典数量的影响
为进一步评估本文方法的有效性,在Muse 数据集的2 个近语言对(En-Es,En-Fr)和2 个远语言对(En-Tr,En-Et)上讨论了各个方法性能随种子字典个数(500,1 000,2 500,5 000)的变化趋势,结果如图4 所示.
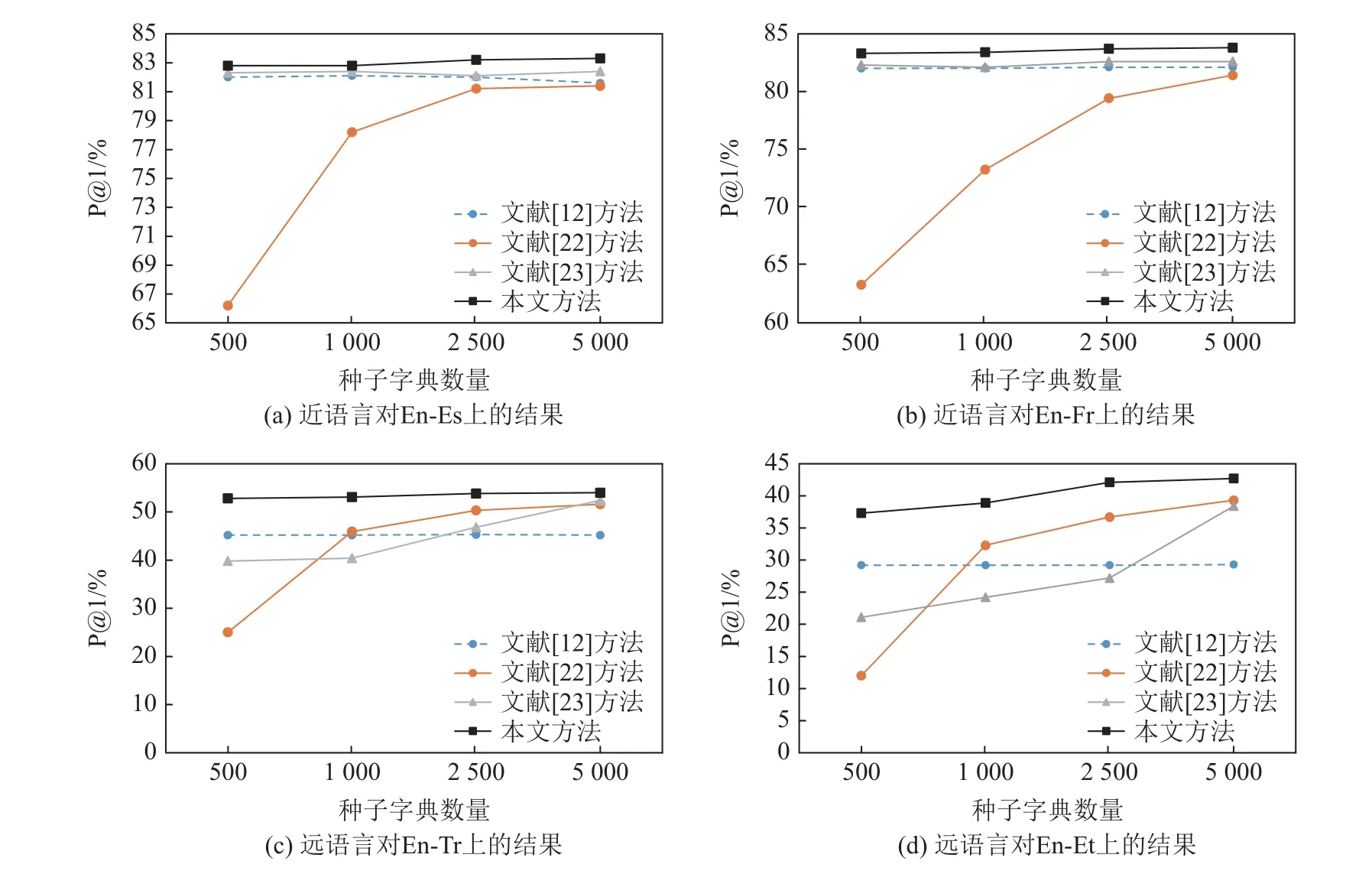
Fig.4 P@1 varying with the number of dictionary图4 P@1 随种子字典数量的变化
1)近语言对(En-Es,En-Fr)上,随着种子字典数量的增加,文献[12]方法、文献[23]方法与本文方法的性能相比变化不大.可见同构条件下,利用线性映射关系能较好地对齐2 个空间,不需要过多的监督信号引导.而对于远语言对(EN-Tr,EN-Et)来说,文献[22-23]的性能随种子字典数目的增加而增加,而本文方法随种子字典数目的增加相对稳定,说明种子字典在非同构条件下对于词向量对齐具有重要作用.
2)在远语言对(En-Tr,En-Et)上,与其他方法相比,本文方法性能较优,且随种子字典数量的增加,其表现相对稳定.由此可见,本文方法的良好性能不过度依赖种子字典是否充分,即使在种子字典较少情况下也能达到较好效果.
3)值得注意的是,无论近语言对还是远语言对,文献[22]方法的性能随种子字典数量变化较大.在En-Es 上,字典数量为500 时其精度约为66%,当字典数量为2 500 时其精度达到了81%.原因可能是该方法没有使用生成的新种子字典更新映射矩阵.
3.3.4 消融实验
为进一步分析本文方法中不同部分的作用和有效性,设计了消融实验,分别分析了自动编码器、细粒度判别器D、种子字典和负样本字典对算法性能的影响.在Muse 数据集上选取En-Es(近语言对)、En-Tr 和 En-Et(远语言对)进行了实验.结果如表4 所示.
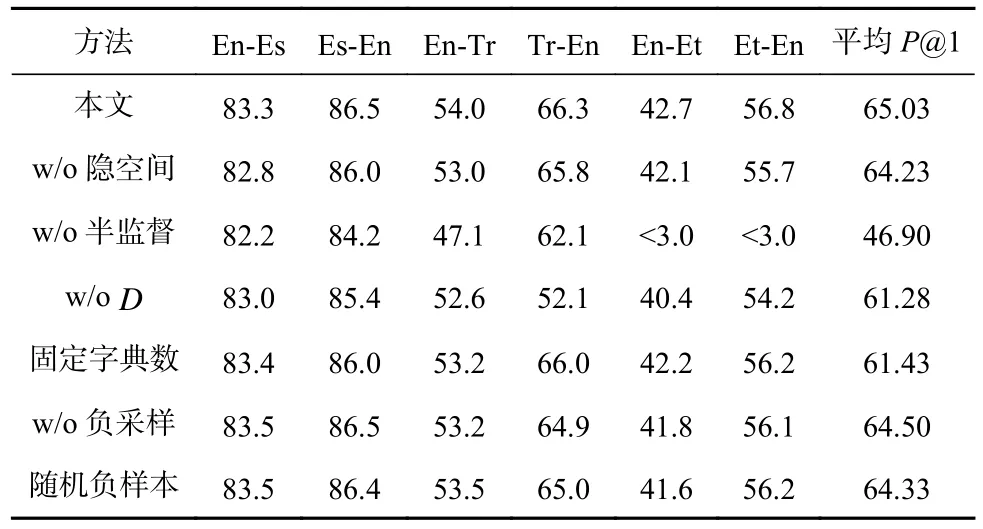
Table 4 Ablation Experiment in Muse Dataset表4 在Muse 数据集上的消融实验 %
1)“w/o 隐空间”即去除自编码机构建隐空间的过程.与本文的全模型相比,“w/o 隐空间”在2 个远语言对上精度都有所下降,表明隐空间能在一定程度缓解远语言对不满足同构假设的影响.
2)“w/o 半监督”不使用监督信号训练模型,即去掉种子字典和细粒度判别器.与全模型相比,“w/o半监督模块”在远语言对上的精度小于3%,不能实现收敛.这是由于没有种子字典的诱导,无监督对抗模型在远距离语言对上难以实现高质量的对齐.
3)“w/oD”保留种子字典但去掉细粒度判别器.与全模型相比,“w/oD”在2 个语言对上的精度都有下降.由此可见,本文方法中的细粒度判别器D能进行细粒度的对齐,从而生成更高质量的映射矩阵.
4)“固定字典数”即在训练迭代过程中,不将上一轮迭代的预对齐字典加入种子字典中.与全模型相比,“固定字典数”的实验结果稍有所下降,说明在训练过程中利用预对齐字典不断扩大种子字典数量具有一定的有效性.
5)与全模型相比,“w/o 负采样”的实验性能在3 个语言对上平均下降0.53%.这说明负采样在对抗训练学习中具有一定的监督作用,能提高判别器D的判别能力,从而提高生成器的学习能力.
6)随机负样本是在本文方法基础上将相似度负样本生成方法替换为随机负样本生成方法.与全模型相比,随机负样本的性能略微下降,平均精度下降了0.7%.这是由于全模型在前k个最近邻范围内进行负采样,使得负样本与真实对齐词较为接近.因此,基于最近邻生成负样本的策略使得细粒度判别器D的训练更好地反映了翻译词对与最近邻词之间的关系,从而促使生成器尽可能地生成靠近其正确翻译词而远离其k最邻近的词向量.
4 总结与展望
本文提出了基于双判别器对抗的半监督跨语言词向量映射学习方法,在已有对抗模型生成的初始映射基础上,增加了一个双向映射共享的细粒度判别器,并引入负样本字典和预对齐字典进行半监督学习,在全局空间距离最小化基础上进一步判断初始生成字典的正确性,从而提高初始字典的对齐精度.在2 个跨语言数据集上的实验效果表明,本文方法能够有效提升跨语言词向量表示性能.
未来,我们将会研究如何在远距离语言对上生成高质量的种子字典,进一步削弱种子字典的约束.同时,我们也将进一步探索如何在自动编码器中引入监督信号,从而更好地构建高语义隐空间.
作者贡献声明:张玉红提出论文想法、方法设计,负责实验指导、论文的写作与修改;植文武参与实验设计与探究、代码实现、实验数据整理与分析、论文的写作与修改;李培培负责部分实验数据分析、论文的修改;胡学钢指导实验设计和论文的修改.
猜你喜欢
家教世界(2023年28期)2023-11-14
家教世界(2023年25期)2023-10-09
红外技术(2022年11期)2022-11-25
新高考·高一数学(2022年3期)2022-04-28
高技术通讯(2021年1期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电脑与电信(2018年11期)2018-02-16
信息安全研究(2016年3期)2016-12-01
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
