
基于依存句法的可解释图像描述生成
2023-09-22 06:21刘茂福毕健旗周冰颖胡慧君
计算机研究与发展 2023年9期
刘茂福 毕健旗 周冰颖 胡慧君
(武汉科技大学计算机科学与技术学院 武汉 430065)
(liumaofu@wust.edu.cn)
图像描述生成,旨在给定一幅图像,生成描述该幅图像的自然语言文本.近年来,随着社会媒体和电子商务的发展,图像描述生成已广泛应用于商品描述生成等任务,引起广泛关注[1-2].为适应需求,设计高效且具备可解释性的图像描述生成模型存在一定难度,原因包括:1)模型不易理解视觉目标实体与其对应文本之间复杂的关系;2)根据提取的视觉和语法特征,很难可控地、可解释地生成图像描述.
编码器-解码器框架在图像描述生成任务中应用广泛[3-4].编码器中,Faster R-CNN 被用于提取图像中的区域特征[5],区域特征包括图像区域中的实体、实体间关系和场景语义[6]的特征表示.在此基础上,曾有工作将图像中的实体根据位置等关系构成场景图[7],并应用图神经网络获取实体词结点的特征表示[8-9],旨在高效利用图像中包含的各类信息.在Faster RCNN 提取出的图像区域特征基础上,Transformer 被广泛应用于提炼图像实体及其关系的细粒度表征[10-11];但仅使用Transformer 提取的图像实体及其关系特征易忽视与图像实体词间潜在的语法关系,进而忽略语言模型的可解释性.解码器中,当前主流模型普遍采用长短期记忆网络(long short-term memory,LSTM)或软注意力机制LSTM[12],通过选择性聚焦于重点图像区域来生成图像描述中的单词;但基于软注意力机制的模型仅根据图像部分区域特征和某一时刻的文本词特征之间的关系来生成图像描述文本,并未将深层语法信息带入生成模型,无法很好地体现语言模型的可解释性.为了在模型中增加语法信息,曾有工作从模板库中提取词性序列[13-14]或句法树[15]作为额外的语法信息,以提高生成描述的准确性与多样性.但利用词性序列或句法树仅考虑当前文本词的语法限制,而缺乏当前文本词与其他文本词的长距离交互限制.此外,上述工作[10-15]在可解释性上关注较少.依存句法反映了任意2 个长距离单词之间依存关系的依存句法,可作为模型的补充语法信息用于提高模型的可解释性.但由于每条图像描述都对应唯一独特的依存句法三元组序列,而构建一个依存句法模板库较为困难.
为解决现有语言模型可解释性不足和语法信息利用不全的问题,考虑设计同时生成依存句法三元组序列和图像描述的模型.如图1 所示,依存句法三元组序列(dependency syntax triplet sequence,DSTS)可以限制每个时间戳上的单词选择.例如,三元组“ 〈aux,2,3〉”不仅限制图像描述中第3 个词“is”的词性为辅助动词,还限制了图像描述中位置2 和位置3对应单词之间的修饰关系,而模型Bottom-Up[16]模型和X-LAN[17]模型由于缺少“car”与“road”之间的长距离依赖而不能生成辅助动词“is”.

Fig.1 Examples of generated image captions by Bottom-Up,X-LAN and IDSTM models图1 Bottom-Up,X-LAN 和IDSTM 模型生成的图像描述示例
本文提出基于依存句法三元组的可解释图像描述生成模型(interpretable image caption generation based on dependency syntax triplets modeling,IDSTM),该模型主要由图像编码和文本解码2 部分组成,联合生成依存句法三元组序列和图像描述.图像编码部分,依存句法编码器提取图像区域实体词之间潜在的依存关系;图像描述编码器增强视觉实体词的特征表示.文本解码部分,依存感知长短期记忆网络(dependency-aware LSTM,DLSTM)以依存句法编码器输出作为输入,输出潜在的图像描述文本对应的依存句法;聚焦图像信息的视觉感知长短期记忆网络(vison-aware LSTM,VLSTM)和词感知长短期记忆网络(word-aware LSTM,WLSTM)交互地将DSTS 和视觉特征解码为图像描述文本.为评估生成DSTS 的质量,本文还提出新的评价指标B1-DS(BLEU-1-DS),B4-DS(BLEU-4-DS),M-DS(METEOR-DS).
本文的主要贡献包括3 个方面:
1)设计了基于依存句法三元组序列建模的可解释图像描述生成模型,将多任务学习的目标设定为联合生成依存句法三元组序列和图像描述文本.
2)将Transformer 作为图像内容编码器融进图像视觉实体词间的依存关系挖掘,并建立图像视觉实体词和依存句法三元组之间的映射关系.
3)提出新的应用于测评DSTS 生成质量的评估指标,即B1-DS,B4-DS,M-DS,以证明提出的模型在生成DSTS 方面的能力.
1 相关工作
1.1 图像描述生成
目前大多数图像描述生成模型倾向于应用编码器-解码器框架将输入图像转换为文本.最初,软注意力机制[12]被用来捕获生成的文本词在图像中对应的显著视觉区域.自适应注意力机制[18]控制模型的图像注意力机制仅在视觉显著区域存在的时刻发挥作用,而在生成连接词的时刻关注文本本身的信息.He等人[19]引入了视觉-语义双重注意力机制,从视觉和语义2 个角度分别捕捉图像及其描述文本的有益信息.Ben 等人[20]使用带有语义约束的自批判性学习方法[21]优化了图像描述生成模型在训练阶段和测试阶段之间的差异.Anderson 等人[16]和Shi 等人[8]的图像编码阶段采用了Faster R-CNN 方法,通过检测图像中实体的边界和实体间的关系来表示图像区域实体特征.基于属性骨架分解[15]的模型使用Attr-LSTM和Skel-LSTM 生成由句法树引导的图像描述文本.Deshpande 等人[13]将词性标注序列作为模型的输入,以提高生成图像描述的速度和多样性.Hou 等人[14]使用词性标注序列模板来改进视频文本的语法表示.Yang 等人[22]将语言模型与视觉结构对齐,使用词性模板约束生成模型,而为图像描述生成模型选择合适的语法模板仍具有挑战性.
Transformer 模型由于其强大的特征提取能力被广泛使用.Luo 等人[10]使用双层协同Transformer 来提高图像描述生成模型的性能,并使用Transformer对齐了区域特征和网格特征.Ji 等人[11]利用Transformer中的层内和层间的全局表示,通过LSTM 梳理Transformer 编码器层中的所有输出向量来探索图像实体词间潜在的语义信息.因此,本文选择Transformer 作为编码器,旨在提取更高级的依存句法特征.
在图像描述生成领域,多任务学习(multi-task learning,MTL)也常用于增强文本词的表示.Shi 等人[8]提出的模型在生成图像描述的同时预测了单词的词性,词性预测任务作为辅助任务提高了模型生成图像描述的准确率.Wang 等人[23]使用双向长短期记忆网络(bi-directional LSTM,BiLSTM)和多任务学习来完成图像-句子检索.多任务学习考虑了任务之间的共同性,可通过共享模型中的重要模块降低模型参数大小.受多任务学习的启发,考虑增加依存句法三元组序列生成任务作为辅助任务,使图像描述生成任务更具可解释性.
1.2 可解释性
可解释性是指模型为用户解释决策结果的能力[24].深度学习模型中的可解释性研究大多集中在2个方向:1)可视化决策过程,如权重可视化或画出一个决策树等;2)多任务联合训练,通过辅助任务的学习降低主要任务学习的难度.Lu 等人[25]提出了可解释Hash 编码方法,嵌入了不同类别的判别信息,使每次决策都具有固定意义.Tang 等人[26]采用从解码器获得的规则来解释编码器中事件分类器的结果,使分类更具可解释性.计算机视觉领域中常用的可视化技术在自然语言处理中也被广泛应用,Gonen 等人[27]便基于视觉可视化方法提出了一种可解释的错误单词检测方法,使错误单词判定过程更具可解释性.
1.3 依存句法
依存句法是一种以谓语动词为结构中心的句法分析方法.Falenska 等人[28]采用基于BiLSTM 的模型验证了依存句法中包含的结构信息对文本分析的积极作用.Wang 等人[29]根据依存句法构建了句法树,并验证了自注意力机制[30]中的位置标记嵌入向量结合依存关系顺序后可以提高Transformer 对文本编码的性能.Bugliarello 等人[31]的研究表明,依存句法通过自注意力机制增强了模型在机器翻译的表现,而在图像描述生成领域,没有关于依存句法的开创性应用.因此,本文尝试采用依存句法来提高图像描述生成模型的可解释性.
2 可解释图像描述生成模型
本文提出的可解释图像描述生成模型IDSTM 如图2 所示,该模型由图像编码和文本解码2 个部分组成.IDSTM 模型在生成图像描述文本之前,会先理解潜在的依存句法,再根据句法信息组织用以描述图像的单词,符合人类的学习思维.
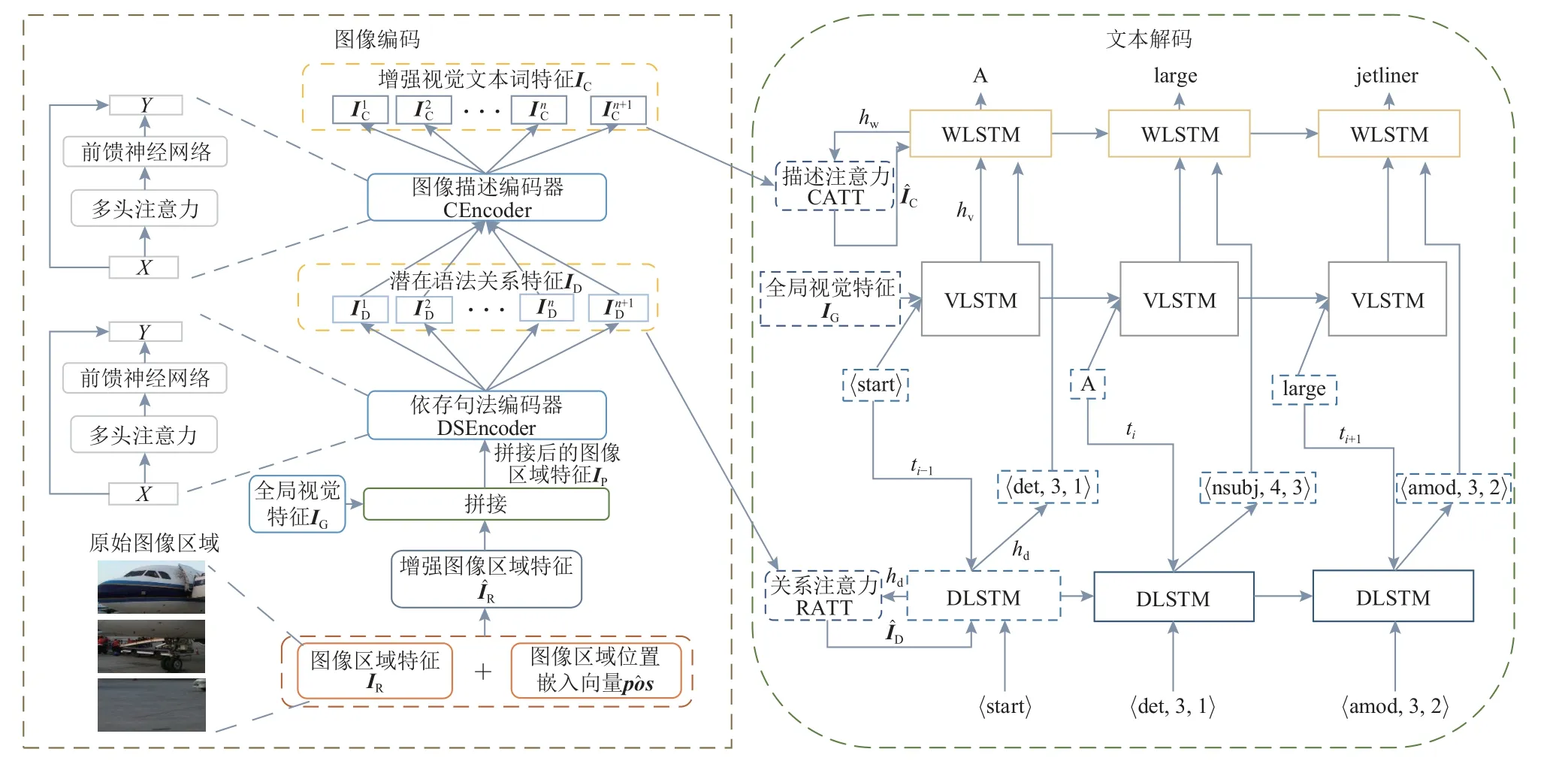
Fig.2 IDSTM model framework图2 IDSTM 模型框架
图像编码部分,依存句法编码器DSEncoder 以图像区域特征IR、图像区域位置嵌入向量和全局视觉特征IG作为输入,通过与图像描述编码器CEncoder 交互来确定文本解码部分DLSTM,VLSTM,WLSTM 所需的视觉与依存关系信息.文本解码部分,通过多任务联合学习方式完成依存句法三元组序列和图像描述文本2 个生成任务.图2 中,WLSTM 为词感知LSTM,VLSTM 为视觉感知LSTM,DLSTM 是依存感知LSTM,生成依存句法三元组序列DSTS,ti表示第i个时间步,描述注意力CATT 和关系注意力RATT 为软注意力机制.
2.1 图像编码阶段
其中∈Rn×E表示增强后的图像区域特征.基于区域特征,按区域个数维度求和平均后得到全局视觉特征表示IG,
IDSTM 模型采用了2 个基于Transformer 的编码器提取图像区域特征,即图2 中依存句法编码器和图像描述编码器.依存句法编码器从优化后的图像区域特征提取图像内实体词间的句法特征,用于依存句法三元组序列生成.图像描述编码器增强图像中包含实体词的特征表示,用于图像描述生成.将全局视觉特征IG和图像区域特征拼接得到图像区域特征IP,
其中concate(·)指连接操作.将IP∈R(n+1)×E输入至依存句法编码器进一步处理,
其中Ol代表编码器第l层的输出,依存句法编码器的初始输入为IP,即X0=IP,FFN(·)代表双层前馈神经网络.多头注意力Multihead(·)的计算公式为:
2.2 文本解码
1)依存句法三元组序列生成.参考描述表示为S={word1,word2,…,wordn},IDSTM 模型的输入为由参考描述得到的依存句法三元组序列R={relation1,relation2,…,relationL}.利用视觉关系信息,首先采用了图2 中的关系注意力机制RATT,使模型学习依存句法特征ID的有价值部分,用来指导时间步ti的三元组生成.注意力机制的计算过程为
为预测时间步ti的三元组,将与前一时间步ti-1三元组嵌入向量ri-1进行整合,作为DLSTM 输入的ri-1,由依存句法三元组经过线性层得到,如依存句法三元组“ 〈aux,4,3〉”的下标为3,则线性层下标为3 的位置对应的参数即为三元组的嵌入向量,公式为:
其中wordi和relationi分别代表 S 和 R 中的第i个词和依存句法三元组,L是依存句法三元组的长度,u指批次(其最大值为B),word0是初始化字符“ 〈start〉”.
2)图像描述生成.给定包含n块被选图像区域特征和融合全局视觉特征的依存关系特征IC=,IDSTM 模型采用双层LSTM来生成图像描述.生成图像描述的最小化交叉熵损失函数为
双层LSTM 具体是指其底层和顶层.底层LSTM如图2 的视觉感知VLSTM,由fVLSTM表示,向量与全局视觉特征表示IG作为输入,
其中hv∈R1×H代表了VLSTM 的隐藏层状态.
顶层LSTM 如图2 的词感知WLSTM,由fWLSTM表示,它将VLSTM 隐向量、RATT 注意力模块输出的依存关系特征和由DLSTM 生成的三元组嵌入向量ri作为输入,通过式(14)限制词表可选择的范围:
现代市场营销模式把消费者的利益和需求放在首要位置,这是市场营销的一场巨大变革。很多企业在企划市场营销之前,都要对消费者的消费需求和消费欲望与市场行情进行客观、详细的深入了解。其次,企业要针对自身的产品对行业内部的市场饱和程度进行调研,准确针对自身的产品进行市场定位,结合企业自身的情况和未来发展的方向,对潜在的消费者、市场、客户进行精准的定位。在完成这一系列的前期转化工作之后,企业集中所有的人力、物力、财力制定出准确的市场营销计划和方案,很好地落实到实践中去,实现社会、消费者和企业三方共赢的良好发展趋势。
采用软限制和硬限制2 种机制将依存句法三元组嵌入向量ri整合至WLSTM,如图3 所示.软限制首先生成整个依存句法三元组序列的嵌入向量,再根据注意力机制使WLSTM 在嵌入向量中寻得关注部分;硬限制将依存句法三元组嵌入向量,根据位置信息直接指导文本单词的生成,这是因为每个在第i个位置的三元组描述的是第i个词与其他某位置的词之间的依存关系.

Fig.3 The image caption generation based on soft limitation图3 基于软限制的图像描述生成
IDSTM 模型采用了多任务学习的方式来优化目标,整体损失函数为
其中 γ为平衡系数.当 γ=1.5 时,图像描述生成任务对模型损失值的影响程度大于依存句法三元组序列生成任务,符合模型最终目标.
3 实 验
3.1 数据集与评价指标
IDSTM 模型在MSCOCO 数据集[32]上进行了广泛实验.数据集划分与Karpathy 等人[1]操作相同,即训练集、验证集和测试集图像规模分别为113 000 幅、5 000 幅和5 000 幅,每幅图像标注有5 个描述文本.为评估模型在图像描述生成方面的性能,采用了7个标准评估指标,B1(BLEU-1)至B4(BLEU-4)[33],METEOR[34],ROUGE-L[35]和CIDEr[36].
生成DSTS 的质量间接反映所提出的IDSTM 模型的可解释性.然而,与一般评测DSTS 任务不同,图像描述生成任务的输入不包含标签文本,因此,需要设计新的评价指标来评估IDSTM 模型生成DSTS 的质量.本文提出新的评价指标B1-DS,B4-DS,M-DS,其采用了与B1,B4,METEOR 相同的计算公式,B1-DS 根据候选DSTS 和参考DSTS 的unigram 重复度来计算得分,M-DS 同时考虑了候选DSTS 和参考DSTS 之间的重叠块的顺序.
为直观地评估生成DSTS 的可行性,在MSCOCO训练集[1]上,对其依存句法三元组类别、三元组序列、单词数量进行了统计,分别为4 442,566 500,11 275,其中依存句法三元组序列与图像描述的数量相同.实验中,对于三元组和单词维度而言,由于三元组类别数量少,三元组的选择比模板或单词选择更加简单.
3.2 实验设置
本文采用Faster R-CNN 来检测所有可能的区域,并控制每个图像包含的区域数量为36 个.每个区域的图像特征都是一个2 048 维的向量.在训练过程中,批大小设置为64.依存句法编码器和图像描述编码器中,多头注意力的层数为4,每层包含8 个头、1 个线性层和1 个残差连接.选择Adam 作为模型训练阶段的优化器,编码阶段和解码阶段的初始学习率分别为0.001,0.0005.解码阶段,DLSTM,VLSTM,WLSTM隐向量维度均为1 024,每个单词或三元组也被表示为1 024 维向量.软注意力机制中的注意力维度为1 024.测试阶段采用束搜索策略生成DSTS 和图像描述文本,且束大小设置为5.在图像描述生成过程中,采用教师强制(teacher-forcing)机制来提高训练阶段的收敛速度.与常用图像描述生成模型不同,IDSTM 模型中的WLSTM 将三元组嵌入向量作为输入,避免DLSTM可能导致的梯度误差积累.使用Stanford CoreNLP工具包[37]来解析图像描述,得到对应的由形如“〈relation,pos1,pos2〉”的三元组构成的DSTS,“relation”表示索引pos1 和索引pos2 之间的依存关系.
为验证IDSTM 模型中Transformer 结构特征的提取能力,分别对图2 依存句法编码器和图像描述编码器注意力头数进行参数优化,如图4 所示.
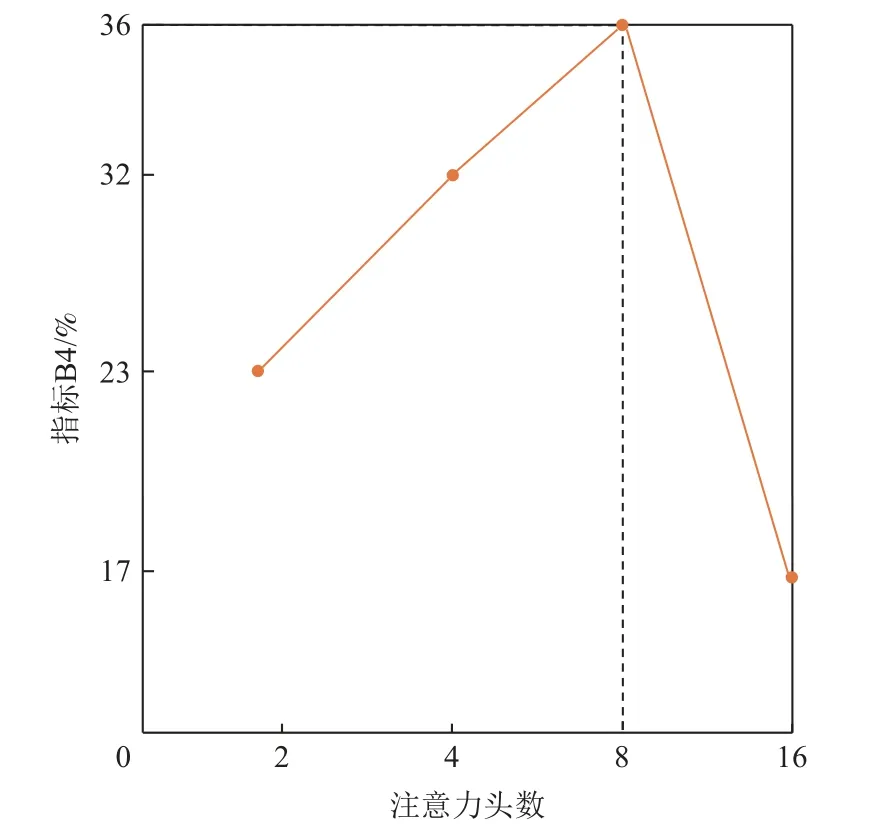
Fig.4 The variance of B4 with the attention heads图4 指标 B4 随注意力头数的变化
图4 中可以看出,注意力头数对指标B4 的影响呈波峰状,在注意力头数为8 时,模型取得最高B4 值;在注意力头数从8 上升至16 时,模型的效果急剧下降,该现象表明大量注意力头会使图像在自注意力中的特征维度降低,进而影响特征表达,导致原本完整的特征被切分.此外,无论是依存句法特征还是依存关系特征均存在内部长距离依存关系,因此不适合被切分过细.
3.3 对比实验分析
为验证本文提出的IDSTM 模型的有效性,采用的对比模型为:
1)SCST[21]在重新训练基线模型的过程中,奖惩正确与错误采样以提高模型选择的准确性.
2)LSTM-A[38]采用CNN 网络来提取属性信息,增强模型对图像中实体间关系的理解.
3)Bottom-Up[16]提出利用自底向上和自顶向下的注意力机制来捕获视觉特征,并将其用于语言模型来生成图像描述文本.
4)ICSAD[15]将生成的语法树作为图像描述文本的语法框架,优化粗糙文本提高模型的图像描述生成能力.
5)POS+Joint[13]利用词性标注序列来提高模型的生成速度和文本多样性.
6)X-LAN[17]采用X-Linear 注意力来捕获多模态间二级交互关系,进而提取多模态间的高级特征表示,提高图像描述的生成能力.
7)DLCT[10]沿用了Transformer 结构,将图像网格特征与图像区域特征对齐,提高模型对图像的感知能力.
8)GET[11]在Transformer 结构基础上沿用了LSTM,将Transformer 内部每层的输出都作为LSTM 的输入,并组合了所有图像特征,用来指导图像描述生成.
9)IDSTMwA 基于软注意力机制选择依存句法特征,指导图像描述生成.
10)IDSTM 基于生成的依存句法三元组序列位置信息,指导WLSTM 生成图像描述文本.
各模型的实验结果如表1 所示,有3 个发现:
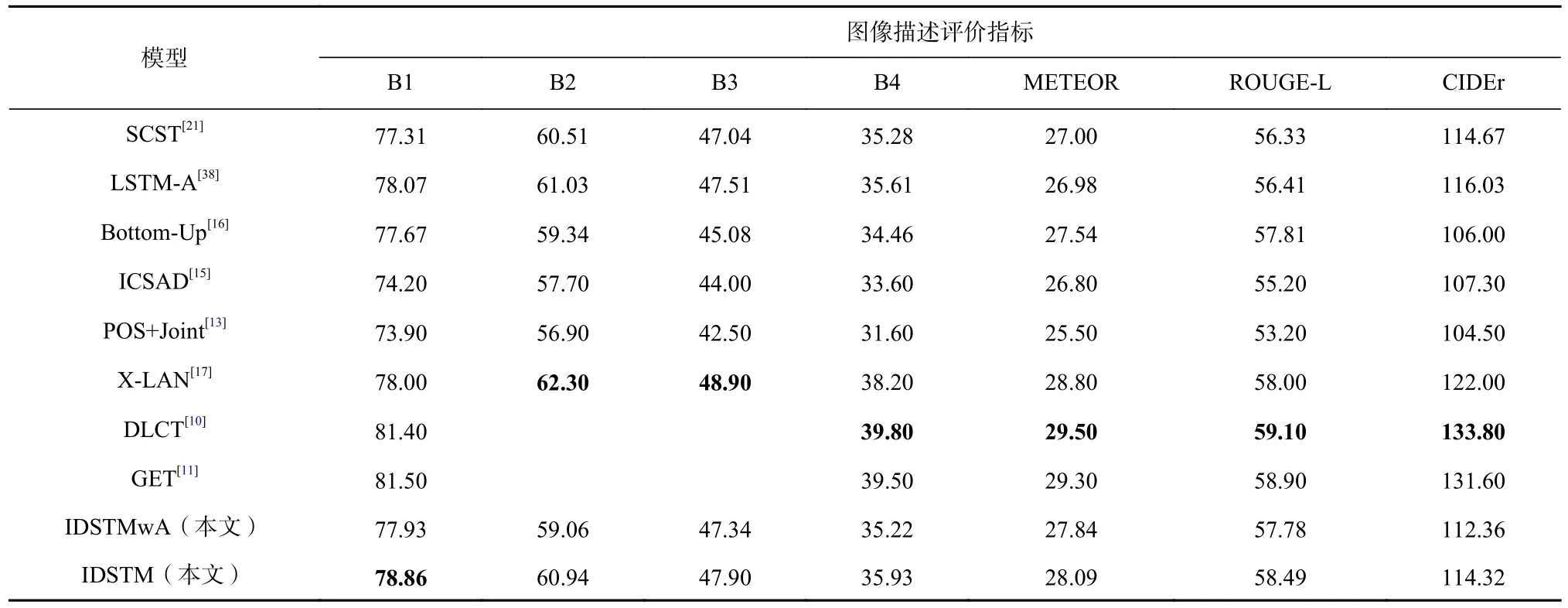
Table 1 Experimental Results of IDSTM and Comparative Models on MSCOCO Dataset表1 在MSCOCO 数据集上IDSTM 模型和对比模型的实验结果 %
1)对于3 个评价指标B4,METEOR,ROUGE-L,IDSTM 模型比模型SCST,LSTM-A,Bottom-Up 的效果好,表明本文提出的IDSTM 模型可以生成更丰富的图像描述文本,且模型生成的依存句法特征提供了足量句法信息,即IDSTM 模型能比其他基线模型发现更多的语法限制.然而,IDSTM 模型在CIDEr 分数上略低于LSTM-A 等模型.原因可能在于IDSTM模型生成的图像描述文本中存在不同于参考描述的同义词,导致整体文本重复度变低.对于模型ICSAD和POS+Joint,IDSTM 模型在所有评价指标上都表现更突出,相比于词性标注序列和句法树,依存句法提供了更丰富的句法信息.
2)X-LAN,DLCT,GET 模型的表现十分突出,在CIDEr 指标上体现最为明显.主要原因是上述3 个模型均采用了强化学习的方法来奖励模型,在模型得到的CIDEr 分数更高时奖励则更大.与上述模型不同,IDSTM 模型更关注于模型的可解释性.与IDSTM 模型结构更相似的X-LAN 模型在指标B1 上的值低于IDSTM 模型,体现出依存句法三元组对选词的语法限制.
3)IDSTM 模型在所有指标上都优于IDSTMwA模型,在B4 和CIDEr 指标上,IDSTM 分别比IDSTMwA高0.71%和1.96%,这表明IDSTM 模型可以学习到质量更高的依存句法三元组嵌入向量特征表示.
图5 为Bottom-Up 与IDSTM 模型在训练阶段的收敛速度对比图,横轴表示训练的迭代次数,纵轴表示损失值或B4 值,训练最大迭代次数为40.从图5可以发现,在损失值和B4 值指标上,IDSTM 模型都取得了更好的效果.IDSTM 模型的损失值曲线相较于Bottom-Up 模型显得更加平滑,在第29 轮训练时取得最优模型,而Bottom-Up 则需要34 轮训练.相较于模型Bottom-Up,IDSTM 模型在依存句法三元组序列生成和图像描述生成2 个任务上共享图像编码区特征提取器的参数,因此在损失函数上的限制更多,也反映出依存句法可以提高模型对文本单词和依存句法三元组的特征学习表示能力.
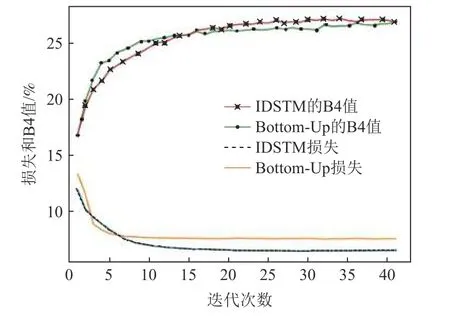
Fig.5 Convergence of IDSTM and Bottom-Up in the training phase图5 IDSTM 与 Bottom-Up 在训练阶段的收敛情况
3.4 消融实验分析
消融实验通过替换至少1 个IDSTM 模型中的模块来实现,表2 列出了用于消融实验的变体模型名称以及模型的描述,移除图像特征提取模块的对应模型会直接采用图像区域特征代替,实验结果如表3所示.

Table 2 Ablation Experiment Models表2 消融实验模型

Table 3 Ablation Experiment Results表3 消融实验结果 %
从表3 可得到6 个发现:
1)w/o 1 m 模型在B1,B4,CIDEr 指标上得分较低,然而在B1-DS,B4-DS,M-DS 指标上却得分较高,w/o 2 m 的效果与其恰好相反.此现象表明使用基于Transformer 的单层图像特征提取器只能提高2 个生成任务中的1 个,缺少2 个任务间的交互.
2)相比表1 的Bottom-Up 模型,w/o ms 模型的CIDEr 提高3.92%.w/o ms 模型在生成图像描述文本时,生成了更多的连接词,如“is”和“are”,连接词的出现会增大共现概率,从而提高基于TF-IDF 的CIDEr指标.从模型结构上分析,w/o ms 模型与Bottom-Up模型只相差依存句法三元组序列生成模块,表明依存句法三元组序列生成任务的有效性.
3)choms 模型在B1-DS,B4-DS,M-DS 指标上比IDSTM 模型分别低3.64%,6.44%,2.57%,可知当依存句法编码器与图像描述编码器异构时,交换2 个特征提取器的顺序会降低模型性能.
4)w/o conn 在各个指标上的效果均较差,表明残差连接在IDSTM 模型中发挥了较重要的作用,使反向传播更加稳定.
5)cls 模型在各个指标上的结果表明,将依存句法三元组序列的生成任务视为序列标注任务增大了模型的复杂度,因此将其视为生成任务更为合理.
6)w/o 1 m,w/o 2 m,w/o ms,choms 模型的实验结果表明,依存句法编码器和图像描述编码器在IDSTM模型中起到了关键作用,为依存句法三元组序列和图像描述的生成提供了关键视觉和语法信息.
3.5 可解释性分析
在IDSTM 模型生成图像描述的过程中,其依存句法三元组与图像描述中词的向量权重可视化图如图6 所示.
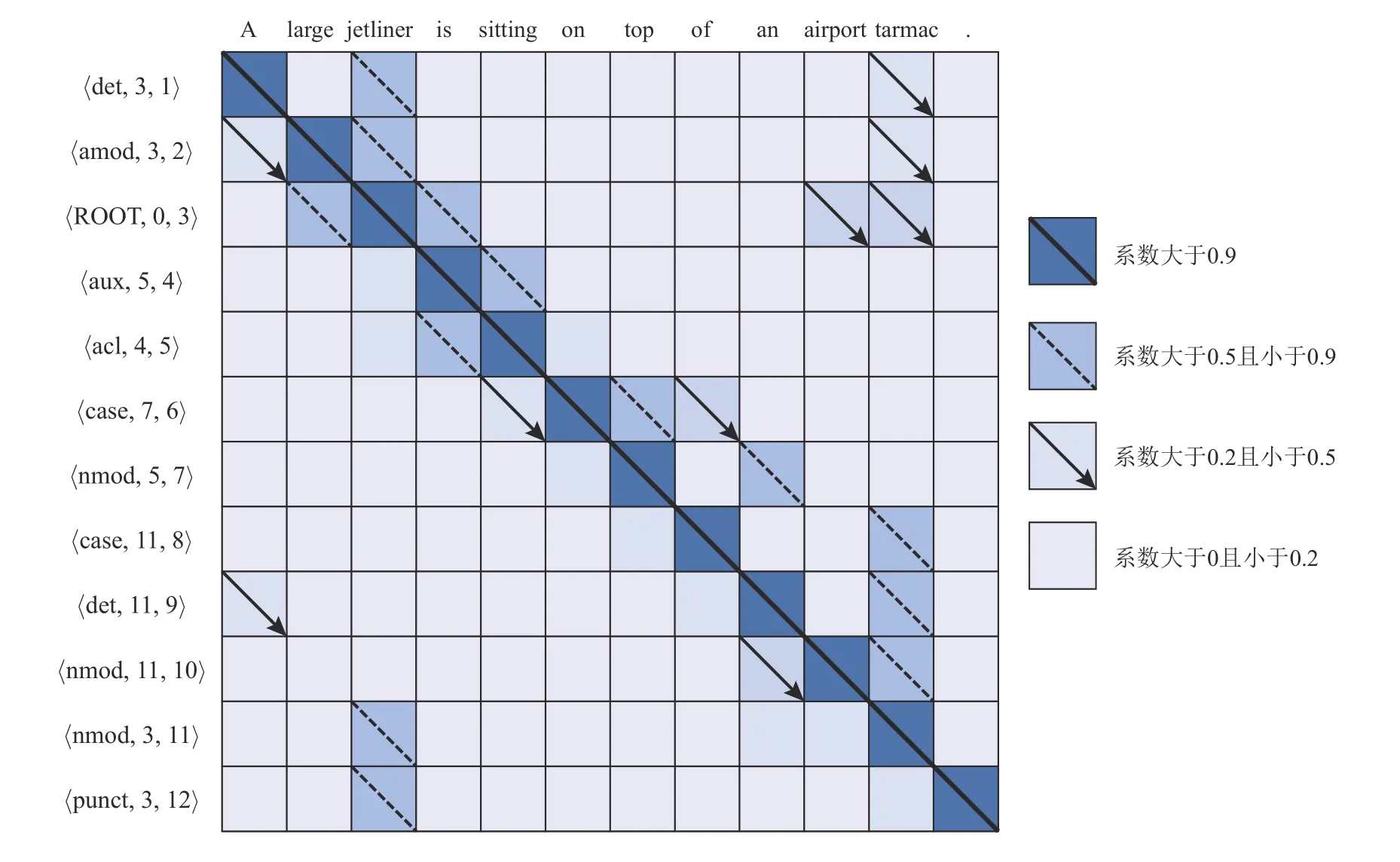
Fig.6 The visualization of dependency syntax triples and word attention weight in IDSTM model图6 IDSTM 模型中依存句法三元组与词的注意力权重可视化
由图6 可知,每个依存句法三元组都与对应位置文本词的相关性最高,与其他长距离位置的文本词的相关性较低.“ 〈nmod,5,11〉”三元组表示词“tarmac”和词“jetliner”存在“nmod(复合名词修饰词)”依存关系.“jetliner”作为依存句法中的词“ROOT”与词“large”也存在“amod(形容词性修饰词)”依存关系.此外,由三元组“ 〈case,7,6〉” 和“ 〈case,11,8〉”的嵌入向量存在的差异可知,依存句法三元组嵌入向量的计算不仅受到自身序列的限制,还受到单词出现位置的影响.
通过分析Bottom-Up,X-LAN,IDSTM 模型在MSCOCO 数据集上图像描述生成的实例,分析IDSTM模型的可解释性,如图7 所示.

Fig.7 The image captions generated by Bottom-Up,X-LAN and IDSTM models图7 Bottom-Up,X-LAN,IDSTM 模型生成的图像描述
每次图像描述选词决策时,IDSTM 模型都将依存句法三元组的嵌入向量考虑其中.IDSTM 模型首先从输入图像中提取实体词对应的依存句法特征.在图像中的实体间,依存句法关系可能存在于任意2 个图像区域中.图7 图像实线框对齐的实体单词“men(男人们)”和图像虚线框中对齐的文本单词“standing(站立)”存在一个依存句法关系“acl(动名词)”,文本单词“top(顶部)”和文本单词“snow(雪面)”可以形成一个依存句法关系“nmod(名词性形容词)”.单词与单词之间的依存句法关系可以为多种类型,如“top”可以指名词,表示顶部,也可以指形容词,表示某物是顶尖的.在得到实体间可能存在的依存关系后,IDSTM 模型将该特征与图像自身视觉特征输入DLSTM 中得到对应的依存句法三元组.依存句法三元组嵌入向量作为指导信息会被输入双层LSTM,用来限制图像描述生成模型在生成描述文本时的用词.因此,IDSTM 模型是在依存句法信息已知的前提下生成对应合适的图像描述,具备一定可解释性.
对比Bottom-Up 模型和X-LAN 模型,本文的IDSTM模型生成了可解释的句法信息.例如,在图7 中,Bottom-Up 模型和X-LAN 模型仅使用图像区域特征就得到了单词“people(人们)”,但“people(人们)”更适用在通用场景下的图像描述任务,然而IDSTM 模型采用了额外的可解释的句法信息,即依存句法三元组“ 〈ROOT,0,4〉”的嵌入向量,生成了更加准确的实体单词“men(男人们)”.语料库中文本词“men(男人们)”以“ROOT(词根)”身份出现41 083 次,而文本词“people(人们)”仅出现22 792 次.因此,相比于文本词“people(人们)”,文本词“men(男人们)”更可能成为 “ROOT”词.此外,文本词“people(人们)”在基于依存句法的统计下更偏向于跟随在“A group of(一群)”词组之后,所以IDSTM 模型在考虑依存句法三元组信息后,将“people(人们)”改为“men(男人们)”.
4 结论
本文提出了一种新的可解释图像描述生成模型,该模型采用多任务学习联合生成依存句法三元组序列和图像描述文本.多任务学习将依存句法三元组生成和图像描述生成相结合,根据先生成句法再生成图像描述的思路,使IDSTM 模型的可解释性得到增强,使生成的依存句法三元组嵌入向量特征有效限制图像描述生成过程中文本词的选择.提出新的评价指标B1-DS,B4-DS,M-DS 有效验证了IDSTM 模型生成DSTS 的有效性.大量实验表明提出的IDSTM 模型具备可解释性.
未来计划找出图像描述生成模型的可解释性和准确性之间的平衡.在损失函数的设计上引入基于多任务的强化学习来提高依存句法三元组序列生成和图像描述生成的准确性.
作者贡献声明:刘茂福提出研究思路和模型,负责论文写作;毕健旗负责实验和论文写作;周冰颖协助实验和完善论文;胡慧君参与问题讨论和审阅论文.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
中华诗词(2021年3期)2021-12-31
大连民族大学学报(2021年2期)2021-07-16
山西大学学报(自然科学版)(2021年1期)2021-04-21
法律方法(2021年4期)2021-03-16
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
文教资料(2018年30期)2018-01-15
传播力研究(2017年5期)2017-03-28
