
一种局部遮挡人脸识别的对抗样本生成方法
2023-09-22 06:21张万里杨奎武胡学先
计算机研究与发展 2023年9期
张万里 陈 越 杨奎武 张 田 胡学先
(战略支援部队信息工程大学 郑州 450001)
(wanli_zhang@aliyun.com)
深度卷积神经网络(deep convolutional neural network,DCNN)在人脸识别(face recognition,FR)取得了巨大的成功.在无约束的环境中,人脸识别在速度和准确度等几个指标上达到饱和状态.由于其优越的性能,人脸识别在身份认证、权限管理、安防监控等安全敏感性任务中得到了广泛的应用,这进一步增加了对人脸识别模型的安全性需求,特别是新冠疫情期间,口罩佩戴下的遮挡人脸识别就给人脸识别技术带来了前所未有的挑战.为推动开放场景中人脸识别技术的提升,中国图象图形学学会和视频国家工程实验室主办了CSIG FAT-AI 2021 开放场景口罩人脸识别挑战赛;2021 年6 月,计算机视觉国际会议(ICCV)组织了遮挡人脸识别挑战赛[1];2022年,苹果iOS 15.4 系统声称可以在戴口罩的情况下使用Face ID[2].可见,遮挡人脸识别(occluded face recognition,OFR)近几年已成为人脸识别领域的热门研究方向.然而,截至目前,国内外还没有OFR 开源模型,也没有相应的对抗样本生成方法,这不但限制OFR 的安全性研究,也使得OFR 的应用面临安全风险.开展针对OFR 的对抗样本生成技术研究,发现其脆弱性,不仅对推动OFR 模型的应用落地、提高模型的鲁棒性具有重要意义[3],还能在指导OFR 数据保护、保障个人信息安全方面具有很强的实用性[4].
1 相关工作
1.1 遮挡人脸识别技术
不管是在传统的人脸识别还是在遮挡人脸识别中,特征提取都是最关键的一环.深度学习强大的数据表征能力使传统的人脸识别方法逐渐被基于卷积神经网络(convolutional neural network,CNN)的深度学习方法接替.香港中文大学开发的DeepID[5]人脸识别模型,采用CNN 作为特征提取器,将人脸图像剪裁为多个局部块,每个局部块分别训练,最后将多个局部块的特征级联得到最后的人脸特征.随后,Google 开发的FaceNet[6]将度量学习思想引入CNN的训练中,提出了Triplet loss,通过构建一个包含了2个同类样本以及一个不同类样本的三元组、学习将同一人的人脸图像特征拉近、不同人的特征拉远,从而增强了特征的区分性.
虽然Triplet loss 借助度量学习的思想可以增强特征的区分性,但是当人脸样本数增加,潜在的三元组数量很大,而构建三元组就需要复杂的采样过程.此外采样会带来随机的干扰,对算法的鲁棒性有一定的影响.针对这些问题,Wen 等人[7]提出Center loss,通过引入一个使特征向其类心靠拢的损失项,不必构建三元组就能学习到内聚性特征,取得了优良的识别效果.
最近几年来,基于角度度量的人脸特征提取算法相继被提出,包括Sphereface[8],CosFace[9],ArcFace[10].这些方法对传统的softmax 损失进行改进,使得同一个人的人脸图像特征之间的夹角变小,不同人特征之间的夹角变大,从而增强夹角余弦度量下人脸特征的区分能力.当人脸因为遮挡造成特征缺失时,通常会导致算法精度大幅度降低.因此,拥有强大数据表征能力的深度学习方法在遮挡人脸识别的准确率上也强于传统方法.目前,业界对于遮挡人脸的识别主要采用2 种方法实现[11].
1)局部特征增强.其核心思想是通过提升人脸可见区域权重,定位非遮挡区域的面部关键点,精准分析面部特征属性并进行比对,从而提升遮挡人脸识别准确率.例如,在CSIG FAT-AI 2021 开放场景口罩人脸识别挑战赛中,百度团队和同为数码科技的团队都采用了局部特征增强的方法.前者针对戴口罩人脸识别问题,引入一种简单的口罩增强方法,能够在训练过程中对图片加入预设的口罩模板.后者为了适合口罩人脸识别的目标场景,在非口罩人脸训练集图片上将70%图片随机剪裁来模拟口罩.此外,这些团队还采取了高斯模糊、随机旋转等其他数据增强方式.
2)先对遮挡人脸进行修复,再对修复后的人脸图像进行识别.Li 等人[12]提出一种基于深度生成模型的人脸修复算法,模型训练时结合重构损失、对抗性损失和语义解析损失来保证修复后人脸的局部和全局一致性.但该方法采用了盲修复的方式,即对整个人脸图像进行重构,并没有考虑遮挡的位置信息.Mathai 等人[13]研究了修复人脸对识别的影响,并对太阳镜、麦克风、手和帽子4 种遮挡类型分别进行修复识别,最后得出结论:修复的人脸图像在人脸识别的算法中比不修复的人脸图像识别准确率要高,并且随着遮挡物面积的增大差距更加明显.同时,先修复后识别的遮挡人脸识别研究在公安办案、社会治理等领域也有着重大的意义.
1.2 对抗样本生成算法
2013 年,Szegedy 等人[14]揭示了深度神经网络的脆弱性,并提出了对抗样本的概念,此后越来越多的对抗攻击方法被提出.Goodfellow 等人[15]基于CNN的高维线性假说提出了一种快速梯度符号法(fast gradient sign method,FGSM),通过沿损失函数梯度相反的方向创建扰动使模型误判.给定一个分类模型f(x):x∈X→y∈Y,对输入x,输出y作为分类预测.对抗攻击的目标是在x附近寻找一个样本x∗,导致模型输出错误.具体来说,有2 类对抗样本,非定向对抗样本和定向对抗样本,两者的区别在于定向对抗样本要诱导模型被错误识别为指定的目标.大多数情况下,对抗性扰动的Lp范 数要求 ‖x∗-x‖p≤ε,其中ε是人为设定的阈值,p可以为0,1,2,∞.FGSM 通过最小化损失函数J(x∗,y)来 寻找一个对抗样本x∗:
其中 ∇xJ(x,y)为损失函数的梯度,边界使用L∞范式.FGSM 速度较快,但每次攻击只涉及单次梯度更新,容易陷入局部最优值.
因此,一些研究在FGSM 的基础上作了各种改进,一类是引入迭代思想,基础迭代法(basic iterative method,BIM)在FGSM 的基础上加入了迭代过程,因此又称I-FGSM(iterative-FGSM)[16].该方法沿着梯度上升的方向进行多步小扰动,并且在每一小步后重新计算梯度方向,相比FGSM 能产生更接近最优解的对抗样本,但代价是增大了计算量.表述为
其中边界可以使用L2或者L∞范数,是经过t次FGSM 后的对抗样本,函数Clipx,ε(A)将输入向量A中的每个元素Ai,j裁剪到 [xi,j-1,xi,j+ε]之 间,α表示每次迭代图像像素更新的幅值.结果表明,迭代方法比单步方法具有更强的白盒攻击能力,但这种针对性的迭代计算降低了扰动的迁移性.
另一类是引入动量,通过在迭代过程中沿损失函数的梯度方向累积速度矢量,增大梯度下降的速度.动量迭代法(momentum iterative-FGSM,MI-FGSM)[17]将动量集成到I-FGSM 中,可以在迭代过程中稳定更新方向.
此外,Carlini 和Wagner[18]提出的C&W 攻击算法将扰动最小化和损失函数最大化这2 个优化问题结合为1 个目标函数,C&W 同时支持l0,l2,l∞攻击,这3种攻击方式算法基本相同,本文实验中采用使用最为广泛的l2定向攻击.假设攻击目标为t,被攻击模型的Logits 输出为Z,那么目标函数定义为
对抗样本的另一个特性是它们可以在不同的神经网络之间迁移,针对一个模型准备的攻击可以成功地混淆具有不同架构和训练数据集的另一个模型,这称为对抗样本的迁移性[14].按照目标模型是否已知,可以分为白盒攻击和黑盒攻击,白盒攻击假设完全了解目标模型,即其参数、体系结构、训练方法,甚至还包括其训练数据.在不知道目标模型的情况下生成对抗样本称为黑盒攻击[19].当研究者想对一个平台的黑盒模型进行攻击时,一种可行的方法是先训练一个与目标模型具有相似决策边界的替代模型,之后对模型进行白盒攻击得到对抗样本,再利用迁移性实现对目标模型的攻击.
由于基于局部特征增强的OFR 模型未开源,因此针对这类模型的攻击是典型的黑盒攻击.然而,传统的对抗样本生成方法存在着一定的局限性,如局部特征增强使得模型的权重发生改变,这使得传统的MI-FGSM 的攻击效果会有所削弱.同时,对于基于人脸修复的OFR,修复操作会更改输入的人脸图像,从而破坏了传统方法精心生成的对抗样本,导致无法达到对抗攻击的既定目标.考虑到OFR 模型的复杂情况,需要一种能根据其实现技术自适应调整攻击策略的对抗样本生成方法.
2 目标人脸修复识别模型(Arc-UFI)
鉴于目前缺乏OFR 开源模型,为验证攻击效果,本文以口罩遮挡人脸识别为现实需求,借鉴经典图像补全和人脸修复算法,建立了一种人脸修复OFR 模型——Arc-UFI(occlusion face recognition model based on Arcface with U-Net face inpainting),并将其作为目标模型以测试本文所提出攻击方法的有效性.
2.1 口罩遮挡人脸数据集构建
本文以CelebA[20]人脸数据集为基础进行口罩遮挡数据增强,生成了口罩遮挡人脸数据集,命名为Mask-CelebA.
数据集具体构建过程为:对于每张人脸图像,通过人脸特征点检测匹配口罩的关键区域,随后自适应调节口罩大小、倾斜角度以及亮度,以便将各式各样的口罩模板自然地贴合在人脸图像上,部分样式如图1 所示.口罩贴合流程如图2 所示.
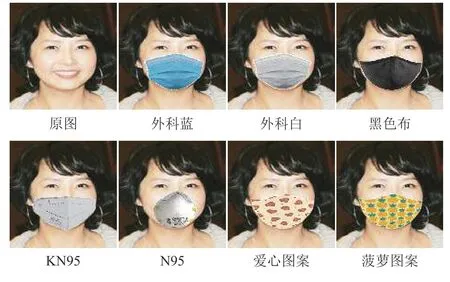
Fig.1 Mask style example图1 口罩样式示例

Fig.2 Mask fitting flow chart图2 口罩贴合流程图
2.2 Arc-UFI 网络结构和损失函数设计
1)Arc-UFI 网络结构设计
Arc-UFI 的网络结构如图3 所示.Arc-UFI 主要分为2 个模块:遮挡人脸修复模块和人脸识别模块.人脸修复模块包含遮挡区域的检测与丢弃、遮挡区域还原2 个部分,用于实现对输入人脸图像Iin遮挡区域的高效定位与修复,修复后的人脸Iinp输入LResNet100EIR[21]作为骨干网络的识别模型完成识别.

Fig.3 Arc-UFI network structure图3 Arc-UFI 网络结构
Arc-UFI 的人脸修复模块使用了编解码结构,网络架构采用U-Net[22],用于提取图像的深度特征.为了提升网络性能和方便模型训练,Arc-UFI 对U-Net网络进行了修改,将残差块引入U-Net 网络当中,通过在编码器和解码器中增加“跳跃连接”(图4 中的虚线箭头),弥补信息损失、提升网络性能.
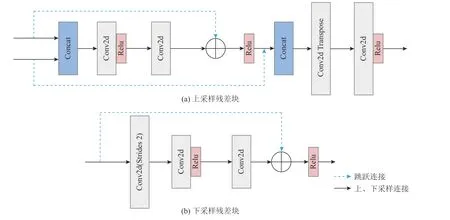
Fig.4 Upsampling and downsampling residual blocks used in Arc-UFI图4 Arc-UFI 中使用的上、下采样残差块
2)Arc-UFI 损失函数设计
Arc-UFI 使用Adam 优化器[23]训练人脸修复模型.在图像补全领域,均方差损失(mean squared error,MSE)[24]是一种常用的计算输出图像和真实图像距离的损失函数,表示为 LMSE.对于一个m×n尺寸的图像,损失函数 LMSE为
其中,Iinp(i,j)为修复后的图像坐标(i,j)处的像素值,Igt(i,j)为原图Igt中此位置的像素值.然而,基于MSE的传统损失函数不足以表达人眼视觉系统对图片的直观感受[25].例如对比的2 张图片仅仅是亮度不同,但是计算出的 LMSE差别却很大,而一幅很模糊的图与另一幅很清晰的图,它们之间的 LMSE可能反而会很小.因此,为了保证生成的修复图像在自然属性上与真实人脸更接近,损失函数还引入了结构相似性(structural similarity)函数SSIM[25],主要用于测量缺失图像的真实值和网络的输出值之间的相似程度,记为
其中l(Igt,Iinp),c(Igt,Iinp),s(Igt,Iinp)分别为亮度、对比度和结构比较.最终的损失函数为
其中a为均方差损失的权重.在Mask-CelebA 数据集上训练Arc-UFI 人脸修复模型,该数据集包含超过200 000 个样本,包含的人脸图像具有较高的质量.将数据集分为测试集(1 000 张图像)、训练集(100 000张图像),其中20%的训练集图像作为验证集.Arc-UFI 的人脸修复结果如图5 所示,图5(a)为口罩遮挡人脸,图5(b)为真实人脸,图5(c)为修复的人脸.修复后的人脸能够有效提高识别准确率,具体参考4.1 节.

Fig.5 Example of Arc-UFI face inpainting图5 Arc-UFI 人脸修复示例
3 自适应对抗样本生成方法(AOA)
为了能够对遮挡人脸识别模型进行攻击,本文提出了一种自适应对抗样本生成方法——AOA(adversarial examples against occluded faces recognition based on adaptive method),该方法主要由针对局部增强的对抗样本生成模块AOA1 和针对人脸修复的对抗样本生成模块AOA2 这2 部分构成,对抗样本生成框架如图6 所示.

Fig.6 Adversarial examples generation framework of AOA图6 AOA 对抗样本生成框架
在实际应用场景中,需要判断目标OFR 模型的类别才能有针对性地生成对抗样本,因此在目标模型类别判断时,首先假定目标模型属于局部特征增强模型,然后按照AOA1 方法生成对抗扰动r0,目标模型的输出为f(x+r0),可以根据 δ(f(x+r0)-yt)的 值判断是否攻击成功.当值大于等于阈值 τ时,选择AOA1 进行攻击,反之选择AOA2,记为
其中N表示进行攻击的次数,τ的值取决于OFR 这2种实现方法的使用情况分布,目前局部特征增强OFR 应用更为广泛,而随着人脸修复OFR 模型的进一步研究,可以相应地调整阈值.为了便于理解,本文中 τ=0.5.克罗内克函数 δ为:
由于局部特征增强的OFR 模型增大了遮挡外可见区域的识别权重,因此AOA1 在MI-FGSM 对抗样本生成方法的基础上进行了改进:1)对干扰区域做了针对性的限制,提升了对抗样本的生成效率,增强了对抗扰动的可视性;2)添加了全变分损失(total variation loss,TV loss)使得对抗样本更平滑、更自然.
同时,针对人脸修复的OFR 模型,AOA2 通过破坏其遮挡区域的分割过程,使得目标模型分割出错,同时对抗扰动也使得目标模型的识别准确率下降.此外,考虑到物理攻击的可实现性,AOA2 也对干扰区域进行了限制.
3.1 对抗干扰区域限制模块
1)AOA1 中的遮挡人脸关键区域框定
局部特征增强方法主要是通过提升人脸可见区域权重来实现OFR,所以AOA1 主要将干扰集中在口罩之外的人脸关键区域,如眼睛、鼻子等.通过在人脸图像上生成注意力图,也可以发现彩色人脸区域(如图7(a)所示)在传统人脸识别任务中的作用更为突出,而对于基于局部特征增强的OFR 任务,眼睛部分的作用更为突出(如图7(b)所示).因此,可将对抗扰动限制在OFR 中更为重要的眼睛三角区域.

Fig.7 Face recognition facial attention visualization diagram图7 人脸识别面部注意力可视化图
首先使用工具dlib[26]自动标定人脸的68 个特征点,对于口罩遮挡人脸,可能会出现dlib 无法检测到人脸的情况,此时自动结合未佩戴口罩时的眉毛、眼睛部位的特征点,预测出遮挡人脸的特征点,如图8(b)所示.然后,按照特征点序号31 至35、26 至17 的顺序依次连接这15 个点,从而形成了如图8(c)所示的限制区域.

Fig.8 Adversarial perturbation region restriction图8 对抗扰动区域限制
2)AOA2 中的口罩区域框定
针对基于人脸修复的OFR 模型,本文除了在整个图像添加扰动外,也尝试将扰动限制在口罩区域.为了实现口罩区域框定,本文通过使用Labelme 工具[27]标注生成了一个基于Mask-CelebA 数据集的口罩分割数据集并对U-Net 模型进行了训练,实现了较好的分割效果,如图9 所示.
3.2 对抗样本生成模块
1)针对局部特征增强OFR 的对抗样本生成(AOA1)
本文首先针对常用的模型结构IR50,IR101,IR152[28]进行集成,上述模型都在Mask-CelebA 数据集上进行FR 训练.
生成定向攻击样本时,AOA1 首先通过集成模型计算每张干净人脸与其他人脸的相似度,然后选择相似度最大的人脸作为目标人脸,生成随机噪声作为扰动的初始值,并通过点乘干扰区域掩码将扰动自适应地叠加在对识别影响更关键的区域,接着根据损失函数逐步迭代计算当前图片与攻击目标的人脸相似度(person-similarity,PS),直到PS 大于阈值或达到预设的迭代次数后停止迭代,从而获得最终的对抗样本.生成非定向对抗样本时,则在当前图片与干净人脸相似度小于阈值或达到预设的次数后停止迭代.
为了降低噪声对对抗样本可视性的影响,AOA1在优化问题中添加TV loss 正则项来保持图像的光滑性[29],记为 Ltv,当相邻像素的值彼此接近时,Ltv较低,否则较高.最后,生成的扰动会经过高斯核函数卷积叠加在原图上,高斯滤波将图像频域处理和时域处理相联系,作为低通滤波器使用时,可以将低频能量(比如噪声)滤去,起到图像平滑作用.对抗样本尽管引入了额外的平滑性约束,但攻击在较低失真的情况下仍具有相同的成功概率[30].
针对局部特征增强OFR 的对抗样本生成AOA1的整体流程如算法1 所示.
算法1.针对局部增强OFR 的定向对抗样本生成.
2)针对人脸修复OFR 的对抗样本生成(AOA2)
针对人脸修复的OFR 模型,AOA2 主要攻击其遮挡区域图像分割过程,从而使修复算法无法正确分割裁剪遮挡区域.AOA2 可以设定对抗攻击后分割的预测形状,从而对图像分割步骤构成巨大的安全威胁.
遮挡人脸语义分割模型定义为函数fseg,输入图像x大小为C×H×W,其中C,H,W分别表示通道数、输入的高度和宽度,C=1 表示灰度图像,C=3 表示彩色图像.fseg(x)表示对给定输入图像x的预测.预测的大小为M×H×W,其中M是类的总数,在遮挡人脸口罩分割的情况下M=2.离散化后神经网络的预测定义为,每个像素包含预测类别(即0~M-1),大小为H×W.
生成对抗样本时,使用欧几里得距离(L2)和最大距离(L∞)[17]来测量原始图像和生成图像之间的差异.其中L2用来计算对抗样本与原始图像之间的变化距离,L∞用来测量所有像素中单个像素的最大变化.
为了量化对抗样本生成的准确性,AOA2 计算了目标掩码Ytarget与生成对抗样本的预测分割掩码Yseg之间的交集(intersection over union,IoU)和像素准确度(pixel accuracy,PA).在选择背景标签为0、目标分割实体标签为1 的设置中,IoU和PA定义为:
其中S{Aij=Bij}表示一个与A,B同大小的矩阵,当A和B对应位置的像素标签相同时,Sij=1,否则Sij=0,且i∈{1,2,…,H},j∈{1,2,…,W}.
对抗样本生成过程中,通过最小化 ‖x-(x+r)‖2,从而使得 argmax(fseg(x+r))=Ytarget,(x+r)∈[0,1]C×H×W.这个方程迭代地找一个较小的扰动r以改变模型使得预测结果为Ytarget,将其称为目标对抗掩码,同时保持原始图像x与其对抗样本x+r之间的L2距离最小.在此设置中,以迭代方式计算扰动rn,乘以常数 α.然后添加到图像xn中:xn+1=xn+αrn.下面详细说明如何计算扰动rn.
定向性的分割攻击必须:1)增加目标对抗掩码中选定前景像素的预测可能性;2)减少未在同一掩码中指定的所有其他像素的预测可能性.为实现这一特征,rn设定为扰动之和,如式(10)所示:
其中 ⊙表示哈达玛积(Hadamard product).另外,f(x)c表示神经网络进行预测的通道,在口罩分割的情况下,c=0 表示背景通道,c=1 表示前景通道.
当使用静态掩码方法生成对抗样本时,梯度来源于每次迭代时目标对抗掩码中对应的目标像素.然而,在对抗优化期间,某些像素的预测可能已达到目标,此时不需要进一步的优化,为了仅优化来自于预测与目标对抗掩码不一致的像素,AOA2 引入了一种利用自适应掩码定位的方法,rn如式(11)所示:
以这种方式更新rn可确保梯度仅来自每次迭代时标签与目标对抗掩码不同的像素.动态计算掩码时,需要优化的像素数量逐渐减少.如图10 所示,①~②的迭代占了总迭代次数的59.1%,而此时改变的像素仅占总改变像素的16.4%.因此,扰动乘数 α如果设置为固定值,可能导致在 α值较低时优化停止,或者在 α值较高时产生较大的扰动.于是,AOA2 采用了动态扰动乘数策略,即使用 αn=β·IoU(Ytarget,Yn)+σ,其中 β和 σ是用于计算最终扰动乘数的参数,Yn是第n次迭代的预测值.该方法允许扰动乘数值随着要优化的像素数量减少而动态增加.针对人脸修复OFR的对抗样本生成,结合了动态计算掩码和动态扰动乘数后,AOA2 整体流程如算法2 所示.
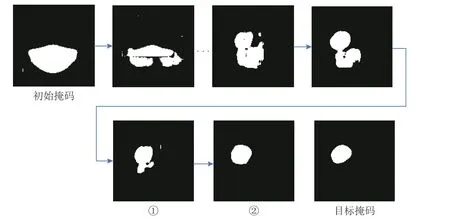
Fig.10 Attack process of image segmentation图10 图像分割攻击过程
算法2.针对人脸修复OFR 的对抗样本生成.
4 实验结果及分析
4.1 实验设计
被攻击的目标模型除了上述的Arc-UFI、虹软(ArcSoft)和百度(Baidu)OFR 模型外,本文还选取了3 种目前最先进的一般FR 模型,包括SphereFace,CosFace,ArcFace.对于一般FR 模型,在测试中,首先使用这些模型提取人脸图像的特征,然后使用最近邻分类器进行人脸识别.本文在Mask-CelebA 数据集上进行了实验.实验选择1 000 张不同身份的1 000张图像形成图库集,ArcSoft 在本地建立人脸库,Baidu 的FR 则将实验图片上传到云人脸库中.随后,在本地对这1 000 张人脸图像执行非定向攻击和定向攻击.实验参数设置如表1 所示,衰减因子的选择参考文献[17].

Table 1 Experimental Parameter Settings表1 实验参数设置
4.2 实验结果及分析
1)Arc-UFI 修复人脸相似度比较结果
对于无遮挡人脸x,其对应的口罩遮挡人脸为xmask,修复后得到的图像记为UFI(xmask).使用不同FR模型计算UFI(xmask)与x的相似度,记为PS1;未进行人脸修复的口罩遮挡人脸图像xmask与x之间的相似度,记为PS2.除了ArcSoft,Baidu 这2 个针对遮挡人脸做了局部特征增强的OFR 模型外,本文还在FaceNet,SphereFace,CosFace,ArcFace,dlib-r27 官方使用29 层ResNet[31]生成的一般FR 模型上进行了测试.实验结果如图11 所示.

Fig.11 PS value of different FR models about mask occluded face图11 不同FR 模型关于口罩遮挡人脸的PS 值
图11 中,由于dlib-r27 的正向人脸检测器无法检测出口罩遮挡情况下的人脸,进而无法计算出与真实人脸的相似度,故将其记为0.而对于FaceNet,SphereFace,CosFace,ArcFace,使用MTCNN 网络进行人脸检测,均可正常检测出口罩遮挡人脸.由图11 可见,UFI 修复后的人脸有助于人脸识别,且Arc-UFI的识别效果远超一般FR 模型,证明了将Arc-UFI 作为受害者模型开展安全研究的合理性.
2)针对局部特征增强的对抗测试结果
针对局部特征增强的对抗攻击实验,本文在ArcSoft 和Baidu 的FR 和一般FR 上进行测试.成功的非定向攻击旨在使模型误判,而成功的定向攻击旨在使模型将攻击样本误判为某特定目标,依照此概念分别测试了对应的攻击成功率(attack success rate,ASR).为了进一步测试AOA 在局部特征增强OFR 攻击任务上的性能,实验还测试了I-FGSM,MIFGSM,AOA 在攻击成功时的平均迭代次数.图12、图13分别展示了针对局部特征增强OFR 的非定向攻击和定向攻击测试结果.从图12 和图13 中可以看出,AOA 在对局部特征增强OFR 的定向和非定向攻击任务中,在Baidu、ArcSoft 模型上的攻击成功率远高于其他攻击方法,在对ArcFace 等一般FR 模型攻击中,AOA 的攻击成功率也与MI-FGSM 攻击效果相当,远高于其他3 种攻击方法.
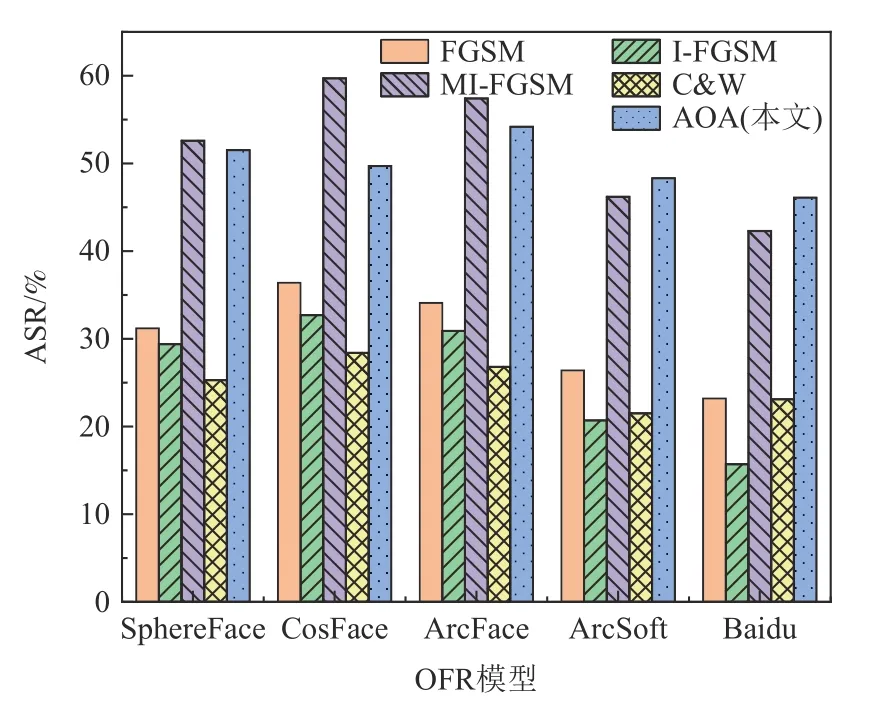
Fig.12 Non-target attack results of local feature enhanced OFR图12 局部特征增强OFR 的非定向攻击结果

Fig.13 Target attack results of local feature enhanced OFR图13 局部特征增强OFR 的定向攻击结果
此外,AOA 减少了对抗样本生成的迭代次数,由表2 和表3 可知,AOA 在攻击效果更好或相当的情况下,平均迭代次数比MI-FGSM 降低了约33%,对比其他攻击方法更是大幅度降低,对抗样本的生成效率大幅度提升.
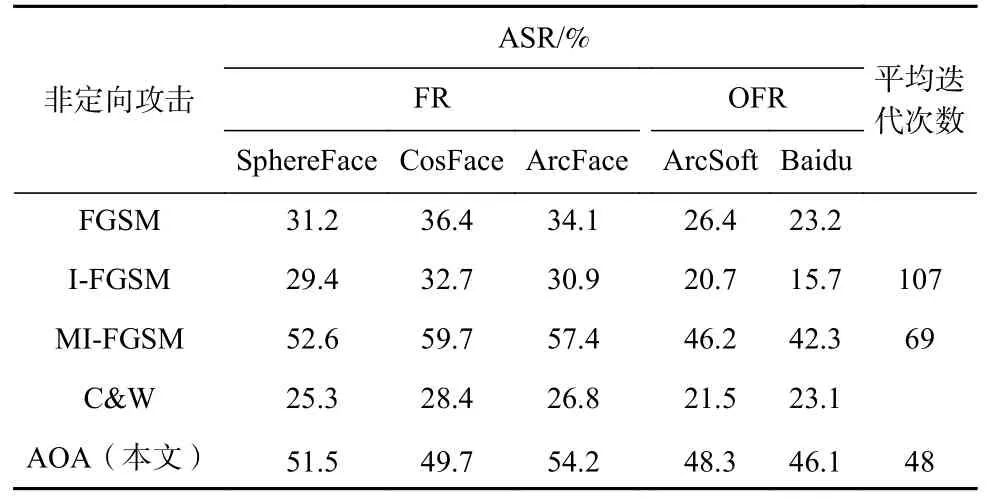
Table 2 Test Results of Non-target Attack on Local Feature Enhanced OFR表2 局部特征增强OFR 的非定向攻击测试结果
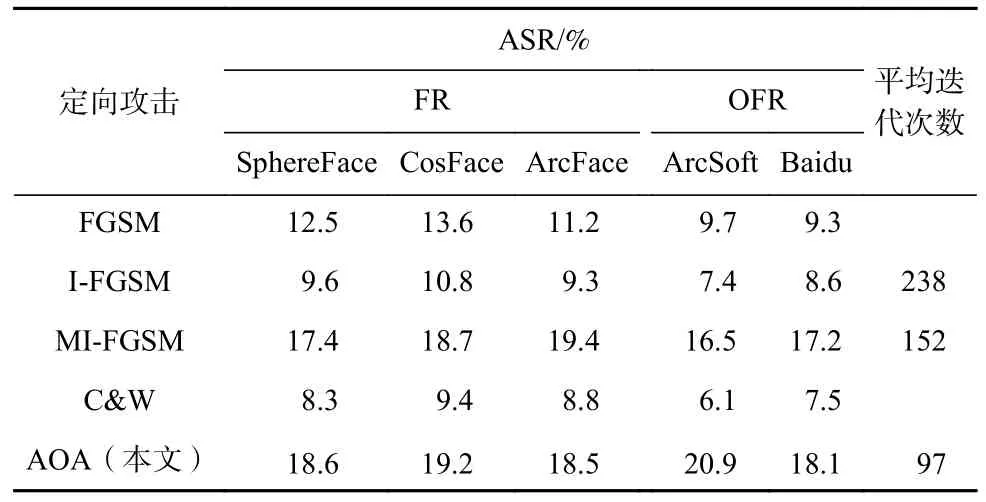
Table 3 Test Results of Target Attack on Local Feature Enhanced OFR表3 局部特征增强OFR 的定向攻击测试结果
由于替代模型生成对抗样本时,不同模型具有相似的分类边界,AOA 对生成的干扰噪声进行高斯滤波,而高斯函数具有旋转对称性,意味着高斯滤波在后续边缘检测中不会偏向任何一方,使得生成每个像素的噪声与周围像素具有相关性,降低了不同模型生成的干扰噪声之间的差异,因而有效提升对抗样本攻击成功率.同时,由于AOA 针对性地限制了对抗干扰区域,使得干扰高效地添加在对识别效果影响较大的区域,因此对抗样本生成效率大幅度提升,但这也导致了在一般FR 模型中,AOA 的攻击效果受到限制,攻击成功率提升并不明显.此外,为了探究不同攻击方法的迭代次数对ASR 的影响,实验测试了定向攻击不同迭代次数时的攻击目标人脸识别率,实验结果如图14 所示.

Fig.14 Effect of the number of iterations on the target face recognition rates during target attack图14 定向攻击时迭代次数对目标人脸识别率的影响
图15 展示了干净样本及使用AOA 生成的定向对抗样本在Baidu 识别后的Top-3 结果,可见AOA 生成的对抗样本更自然.

Fig.15 Example of target attack on local feature enhanced OFR图15 局部特征增强OFR 的定向攻击示例
3)针对人脸修复的对抗攻击结果
首先测试了AOA 对人脸修复模型遮挡图像分割的攻击效果,在此过程中本文比较了该过程采用动态扰动乘数对攻击过程的影响.实验结果如图16所示,可见当采用动态扰动乘数策略时,由于乘数随着要优化的像素数量的减少而动态增加,从而攻击不会因为要优化的像素过小而停止,提高了攻击的可持续性.
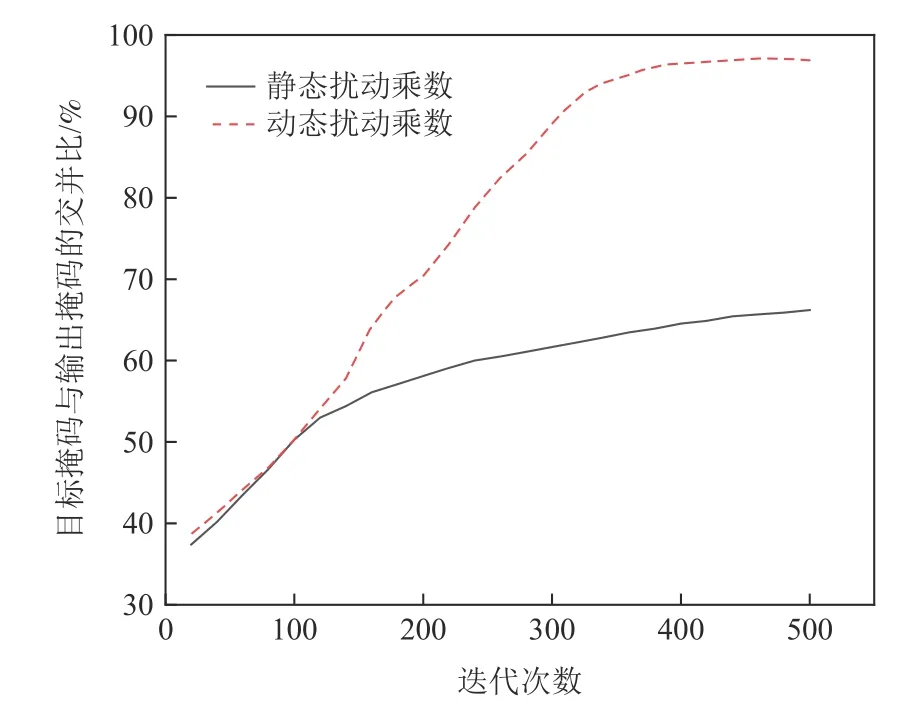
Fig.16 Comparison diagram of dynamic perturbation multiplier and static perturbation multiplier图16 动态扰动乘数与静态扰动乘数对比图
图17 展示了遮挡人脸语义分割的对抗样本攻击效果.图17(a)为待分割的纯净样本遮挡人脸图像,图17(d)为分割模型未受到攻击时的分割结果,可以看出此时正确分割了口罩遮挡区域.在以图17(g)为目标掩码的情况下,使用AOA 生成的对抗样本如图17(b)所示,输出结果图17(h)转移了分割区域,成功欺骗了遮挡人脸分割模型.与此同时,产生的对抗扰动也是很难察觉的.将产生的对抗扰动增强8 倍后的结果如图17(e)所示.将对抗扰动限制在口罩区域,限制区域的对抗样本及其对抗扰动可见图17(c)和图17(f).

Fig.17 Adversarial examples for semantic segmentation of occluded faces图17 针对遮挡人脸语义分割的对抗样本
AOA 可以使修复算法无法正确分割裁剪遮挡区域,同时也使得口罩上的干扰被保留下来.针对人脸修复的OFR 模型,本文在Arc-UFI 上进行了对抗测试.如图18 所示,AOA 能有效降低人脸识别的置信度,而FGSM,I-FGSM,MI-FGSM 针对Arc-UFI 生成的对抗样本并不能实现很好的攻击效果,这是因为限制在口罩区域的扰动会在人脸修复过程中被分割过滤掉,而AOA 生成的扰动绕过了人脸修复过程中的分割过程.AOA 在以高成功率实现攻击的同时,对原始图像的修改非常微小,以至于对原始图像的修改在很大程度上是肉眼看不见的.
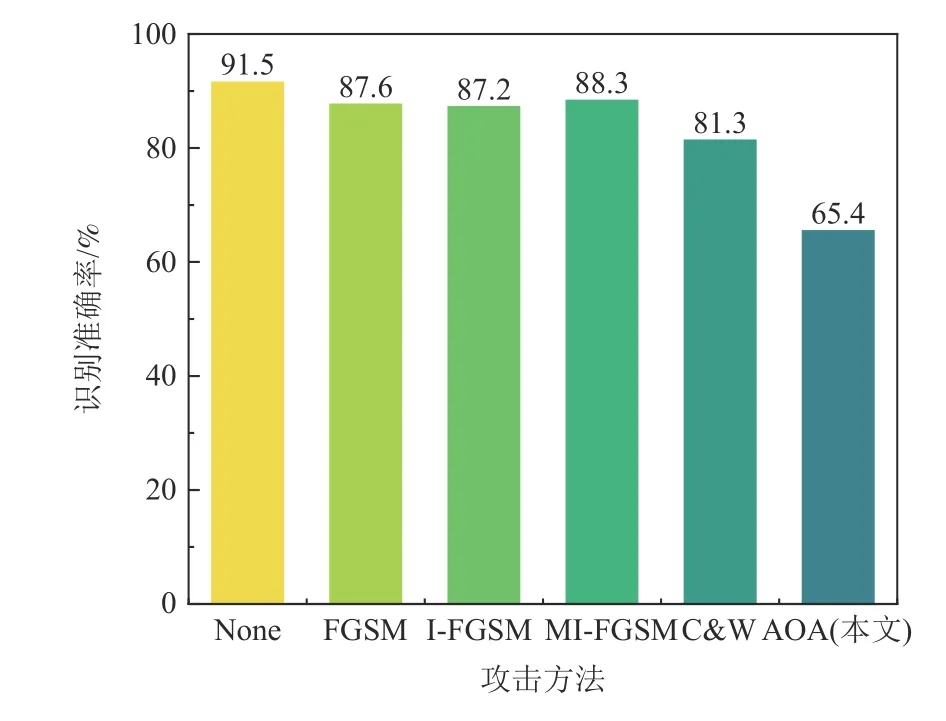
Fig.18 Recognition accuracy after adversarial attack on Arc-UFI图18 对Arc-UFI 的对抗攻击后的识别准确率
4.3 AOA 模型特点及优势
1)自适应攻击能应对多种OFR 模型,从整体上来看,可以根据目标模型调整攻击策略,对比单一的攻击方法,提高了对抗样本生成效率,降低了计算成本.
2)针对局部特征增强的OFR,通过结合动量和集成模型训练方法提高了对抗样本的泛化性.
3)通过注意力机制提取在OFR 中作用更突出的人脸特征区域,进而针对性调整干扰区域,以在优化过程中寻找更好的对抗性扰动,从而提高攻击成功率.
4)针对人脸修复的OFR 对抗样本生成方法中,为了拟合每次迭代时标签与目标对抗掩码不同的像素,使用了动态计算掩码和动态扰动乘数方法,优化过程的像素数量开始很高,随着预测与目标对抗掩码一致而逐渐减少,既减少了冗余计算开销,又通过动态增大扰动乘数保证了攻击的可持续性.
5 总结与展望
本文提出了针对OFR 的自适应对抗样本生成方法AOA,该方法是一种2 阶段自适应对抗样本生成方法,能够实现局部特征增强及人脸修复的遮挡人脸识别模型的攻击,有着泛化性好、攻击力强的优势.
鉴于当前人脸修复识别模型还停留在理论研究层面,本文设计实现了一个通用的面向人脸遮挡的Arc-UFI,并将其作为攻击的目标模型.针对虹软(ArcSoft)、百度(Baidu)FR 的实验结果表明,AOA 可有效实现对局部特征增强OFR 模型的攻击,并能够大幅度提高对抗样本生成的效率.针对Arc-UFI 的实验结果表明,AOA 能有效攻击模型对遮挡区域的分割过程,进而使目标模型的识别准确率下降.
另外,本文所提的Arc-UFI 和面向局部遮挡人脸识别的对抗样本生成方法,还可以作为一种通用的人脸识别模型安全测试方法,通过攻击找出模型漏洞,从而增强模型鲁棒性,为局部遮挡人脸识别的工程实现和落地应用提供基准开发和测试环境.
作者贡献声明:张万里负责模型和方法的实现,以及论文初稿撰写;陈越和杨奎武提出论文思路并指导论文撰写;张田负责相关文献资料的收集、分析和图表整理;胡学先指导论文修改与校对.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年31期)2020-06-01
数学物理学报(2019年4期)2019-10-10
动漫星空(2018年9期)2018-10-26
贵州师范学院学报(2016年3期)2016-12-01
电源技术(2015年11期)2015-08-22
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
