
基于高斯密度图的自然场景中文文字检测
2023-09-19 13:34:30王昌波仝明磊
电子设计工程 2023年18期
王昌波,仝明磊
(上海电力大学电子与信息工程学院,上海 200000)
随着人工智能学科的快速发展,文字检测技术得到了广泛的应用,如智能导航[1]、证件识别[2]、铭牌识别[3]和单据识别[4]等。目前深度学习方向的文字检测方法分为基于目标检测和基于图像分割的方法[5]。目标检测的方法通过CNN(卷积神经网络)提取图片的高层次特征,再生成预选锚框,通过目标框回归的方法找到合适的锚框。该方式具有计算量小、速度快的优势,但识别准确率略有欠缺,代表方法有CTPN[6]、TextBoxes[7]等。图像分割的方法本质上是对图片的像素点进行二分类,代表网络有U-net[8]等,这类检测方法具有精度高的优点,并且可以将任意形状的文字直接生成检测框,但计算量有所提升,并且分类结果之间是孤立离散的,代表方法有SegLink[9]、PixelLink[10]、InceptText[11]等。
虽然许多研究者提出了一些效果良好的文字检测方法,但大多是应用在英文文本的方法。对比英文文本,中文文本种类更多,文字更密集[12]。为了适应中文的特点,该文设计了一种适合中文文字检测任务的网络结构和方法,使用高斯分布密度图作为文字区域的标注,设计了一种类U-net结构的语义分割网络,并且将特征融合部分的结构由原来的跳跃连接模块改成了基于transformer[13]的交叉通道融合注意力模块,以解决编解码阶段特征集不兼容的问题。除了模型的改进外,该文针对密集文本区域预测出的密度图中,文本区域重叠的问题提出了解决方法。
1 方法建模
1.1 网络模型整体结构
该文针对中文文字检测的应用场景,设计了一种新的适合中文检测任务的网络。该网络由特征编码、特征解码和特征融合部分构成。特征编码部分采用VGG16 作为backbone,每个ConvBlock 部分添加了BN 层(Batch Norm layer),用来加快网络训练的收敛速度,防止梯度爆炸或消失。编码网络累计下采样五次,取1/2、1/4、1/8、1/16 这四个尺度特征图作为特征融合模块的输入。特征解码部分使用双卷积模块和线性插值函数逐层恢复特征尺度,同时在对应的尺度上叠加特征融合部分输出的特征图。多层次特征融合部分借助交叉通道融合注意力模块将不同层次的特征进行合理融合,解决了特征集不兼容的问题。模型的整体结构如图1 所示。
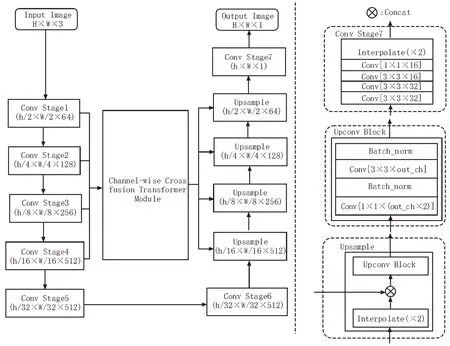
图1 模型结构
相比较于原始的U 型编解码网络,该网络结构着重考虑了不同层次特征融合的权重对输出结果的影响,能自适应地调整不同尺度下特征图所传递的语义信息。相比于同样的编解码结构,该网络能获得更好的收敛效果和收敛速度。
1.2 高斯分布密度图标签生成
高斯分布在自然和社会科学中经常被用来代表一个不明的随机变量。若随机变量X服从一个位置参数为μ、尺度参数为σ的高斯分布,记为:
其概率密度函数为:
通常距离文本框中心位置越近的像素点属于该文本的概率越高。文中将普通的四边形文字标注框转化成高斯分布的密度图标注。相较于传统二进制离散的数据标注,这种标注的内容是连续的数值,能够包含一定像素点间的关联信息[14],因此在密集文本检测中能显著提高检测的准确率。
实现中首先将实验数据集标注的四边形标注框映射到一张与输入图片同尺寸的空白背景图上,再通过仿射变换的方法将标准的二维正态分布图分别扭曲到该图上的每一个标注框内,生成计算网络损失的真值图(Ground Truths)文中由于输入图片的尺寸并不是原始尺寸,因此标注框还要跟网络训练时输入的图片保持同比例的缩放。
1.3 交叉通道融合注意力机制
U-net 与简单的编解码网络相比,其优势在于其跳跃连接模块能够融合网络在下采样过程中丢失的语义信息。但是在文献[15]中提到U-net 的4 个跳跃连接模块并不是对模型性能提升都有帮助,甚至有些部分还对网络的性能有负面影响。因此,该文采用交叉通道融合注意力模块(CCTM)取代传统的特征融合结构,交叉通道融合注意力模块如图2所示。
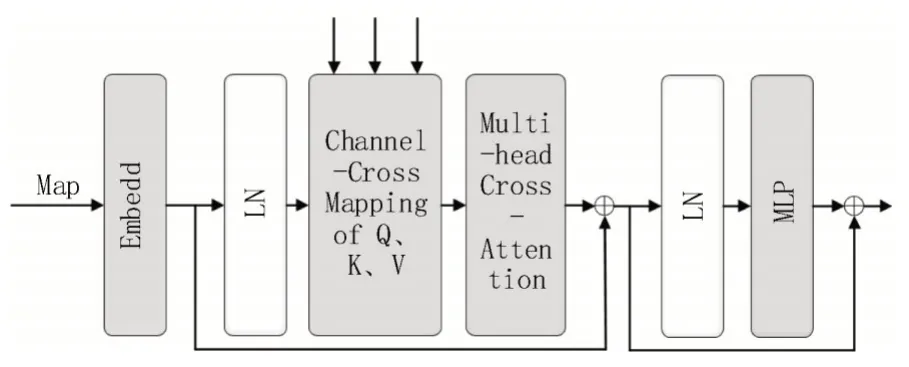
图2 交叉通道融合注意力模块
编码网络提取出的特征图经过一个Embed 模块变成一个单维的张量,该张量被输入到线性归一化模块LN 中,LN 的输出与其他三个层次特征图的输出一同经过交叉通道映射模块后,被送入多头注意力机制模块MSA。MSA 模块的输出首先叠加经过Embed 模块的特征张量,再输出到下一部分的LN 模块和MLP 模块。从Embed 模块到MLP 模块的流程是一个CCTM 的Block,然后可以根据需要调整Block的数量。在CCTM 的输出结果之后,需要经过一个Reconstruct 操作将单维张量再转换回特征图,该图与解码网络中的同尺度特征相叠加,至此完成交叉通道融合注意力的工作。
1.4 网络工作过程
该文在网络加载数据时还需要根据原始标注信息生成由高斯分布标注构成的GT 图。该图是一个取值范围在[0,1]区间连续的并且尺寸与网络输入图片相同的单通道图片。由于该文网络中添加了BN层,因此,网络的输入图片需要缩放到网络指定的输入尺寸,再作归一化处理。然后将归一化图片输入到网络,网络输出文字密度图。在网络训练过程中,该文用网络输出的密度图和预处理得到的GT 计算网络的MSE(Mean Square Error,均方差损失),反向传播、调整网络权重。在测试过程中,将该密度图输入到后处理流程中生成预测框。网络工作流程如图3所示。
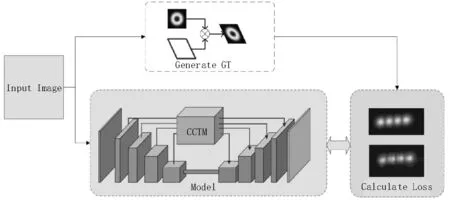
图3 网络工作流程
1.5 预测框的生成
文中网络输出的是文字密度图,无法直接用于评估和展示,因此在后处理部分需要将密度图转换为文字预测框。
首先,将网络输出的密度图进行二值化,得到一张像数值仅有0 和1 的单通道图片。然后,对该图片进行连通域处理,得到文字分布的连通域信息。之后,筛选掉面积过小的部分,为保留下来的连通域生成最小的外接矩形。一般来说,该矩形可以作为文字预测框输出,但经过该文实验验证,在中文文本密集且文本面积较小的区域,容易出现不同文本区域,预测出来的连通域存在重叠的情况,严重影响了检测的准确率,因此文中提出了采用对矩形框内的图片向矩形的长边进行垂直投影的方法,以划分出矩形内重叠的文本区域。具体实现如下:
如果生成的矩形符合长宽比在0.56 到1.8 之间,则直接输出该矩形作为预测框;否则,就认定该矩形框为异常检测框。对于异常检测框,首先对二值化图上的该矩形部分进行透视变换,使其长边映射到x轴上,如图4 所示。然后将透射图上的像素点在x轴上进行投影,获得投影曲线用f(x)表示,如图5 中粗实线。对投影曲线进行求导获得投影导数曲线,用f′(x)表示,如图5 中细实线。

图5 投影曲线、导数曲线和分割点
设h为透视图片的高度,垂直分割超参数为α,表示重叠区域高度和图片高度比值的阈值,水平分割超参数为β,h×β被用于控制相邻重叠区域的最小分割间隔,x0为当前分割的位置,x-1是前一个分割点的位置,则满足式(3)-(6)要求即可逐个获取分割点。图5 中的垂直虚线为计算出来的分割点。
按照待分割点占长边的比例将原矩形框沿长边分解为多个矩形框,新产生的矩形框作为预测框。经实验证明,该方法能大幅提高检测的准确率。有无异常检测框再分割方法的输出结果如图6 所示。

图6 无再分割和有再分割对比
2 实验
2.1 实验环境
实验采用的系统为Ubuntu 20.04,GPU 型号为GTX Titan X,显存为12 GB,核心频率为1 075 MHz,Python 版本为3.6,Pytorch 版本为1.7.0。
2.2 数据集
实验在CTW(Chinese Text in the Wild)数据集[16]上完成。该数据集包含100 万个汉字,共由3 850 个字符构成,这些汉字由人工在30 000 多张街景图像中进行注释。同时,这些图片里还包含了多种类型自然场景下的文本,如平面文本、凹凸文本、弱光环境下的文本和部分遮挡的文本等。
2.3 评估指标
该文采用文字检测任务广泛采用的准确率P(Precision)、召回率R(Recall)以及F1 值三项具体数值对模型进行评估。在该指标中使用的4 个参数分别是TP(真阳性)、TN(真阴性)、FP(假阳性)和FN(假阴性)。
Precision 为预测结果中正确预测的比例:
Recall 为真实正例中被预测出的比例:
F1 值是综合考虑Precision 和Recall 的指标:
2.4 数据预处理
由于CTW 数据集中测试集和验证集的标注文件不完整,该文实验将数据集按8∶1∶1 的比例划分为训练集、验证集和测试集,其中,训练集图片数量大约有14 000 张,验证集和测试集图片数量大约有1 700 张。考虑到网络训练采用原始的2 048×2 048分辨率的图片,对硬件要求高且实验周期长,该文将使用的图片尺寸设定为1 024×1 024 分辨率,既保证了实验对硬件条件要求宽松,又能够缩短网路的训练时间。该文的数据预处理是与训练或测试过程同步进行的,根据网络参数要求调整输入图片的尺寸,同时也计算出与图片保持相同缩放比的新标注框,并且在网络训练阶段还需生成真值图。
2.5 模型训练
该文训练的模型采用了Adam 优化器[17-20],并且为了保证模型的收敛速度和收敛效果,采用了学习率动态调整的策略。该文训练的所有版本的模型训练次数均为8 个epoch,训练时的batch_size 参数设置为2,测试时为设置10。
2.6 消融实验
为了验证该文方法的效果,进行了消融实验。结果如表1 所示。方法1 使用VGG16 作为编码网络,特征融合部分采用U-net 的跳跃连接结构,在生成GT 时采用标准二维高斯分布图扭曲到原标注框的方法,解码网络采用了双卷积加上采样的方式。方法2 是在方法1 的基础上添加交叉通道注意力机制。方法3 是在网络与方法2 相同的基础上添加了后处理的异常检测框,再进行分割的方法。由表1可以明显看出,方法2 对比方法1 在三个方面均有一定幅度提升,显示了交叉通道注意力机制对该文实验是有效的。方法3 比方法2 在三个指标上有很大提升,这表示该文提出的异常检测框再分割的方法对实验结果有非常明显的优化效果。
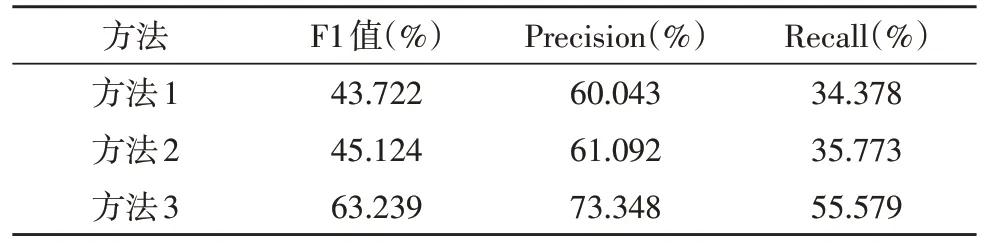
表1 不同方法消融对比
2.7 显性结果展示
为了使实验的结果更加直观,图7 展示了网络输出的密度图和标出预测框的原图。在复杂的自然场景中,该文方法对大目标或密集的小目标都有很好的检测效果,即使有文字目标存在部分遮挡的情况也能检测到,显示了该文方法具有很好的准确性和鲁棒性。

图7 部分结果展示
3 结论
该文提出了一种基于高斯密度图区域标注的中文文本检测方法,该方法针对密集中文文本精确度差和小文本难以定位的问题,将高斯分布图作为标注的方式应用在深度学习网络上,有效地提高了分割的准确率。并且在网络的特征融合部分采用了交叉通道注意力机制,提高了网络的收敛效果和性能。对于密集文字区域网络输出的密度图容易有区域重叠的问题,根据中文文本通常成行或列出现的特点,提出异常检测框再分割的方法,应用在后处理中能够极大地提高密集文本检测的准确率。
猜你喜欢
小天使·一年级语数英综合(2021年9期)2021-09-22 12:18:18
数字通信世界(2021年3期)2021-04-09 02:05:00
小雪花·小学生快乐作文(2020年6期)2020-10-13 09:48:27
湖北理工学院学报(2020年4期)2020-08-22 06:43:26
文苑(2020年12期)2020-04-13 00:55:10
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
计算机应用与软件(2017年4期)2017-04-24 10:39:07
河南科技(2014年23期)2014-02-27 14:19:15
