
高效多注意力融合的U-Net结直肠息肉图像分割算法
2023-09-13 03:57:28许增宝苏树智胡天良
湖北民族大学学报(自然科学版) 2023年3期
许增宝,苏树智,胡天良
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
结直肠癌是世界上最常见的癌症之一[1],就死亡率而言,被认为是主要致命癌症。结直肠癌的主要原因是长在结肠或直肠内壁的息肉发生癌变[2]。早期的结直肠镜检查可以有效地避免癌细胞向远处的器官扩散[3],从而降低治疗费用、减少病人痛苦、降低死亡率。结直肠镜检查是预防和发现结直肠癌的最佳方法,医生也可以通过该检查,在结直肠息肉发展成结直肠癌之前将其切除。然而由于在检查中息肉图像具有颜色、大小以及形状多样性的特点,导致对息肉图像的准确发现和切割一直存在困难。
近年来,深度学习被应用在各个领域[4],诸多基于U-Net的分割算法在医学领域中占据着重要的地位[5],很多学者将基于U-Net的图像分割算法做出改进,辅助医生发现和切割息肉。为了缩小编码子网络和解码子网络中特征映射之间的语义差距,Zhou等[6]提出U-Net++算法,将编码子网络和解码子网络通过一系列嵌套且密集的跳跃路径连接起来。为了使区域和边界具有约束,Fang等[7]提出新的选择性特征聚合网络,该网络包含1个共享编码器和2个相互约束的解码器,分别用于预测息肉区域和边界。为了提高分割效率,Jha等[8]提出了ResU-Net++算法,引用挤压块、激励块以及注意力机制来提高其分割的效率。为了获取更多的语义信息,Ibtehaz等[9]提出了MultiResU-Net算法,通过将2个U-Net互相堆叠来获取更多的语义信息。
以上方法在结直肠息肉图像分割中虽然能取得一定的效果,但对于图像的连续性均有一定破坏。除此之外,结直肠内部环境复杂,内窥镜图像存在光照不均、视野模糊、噪声干扰、形态多样等缺陷,使得模型难以对数据进行有效泛化。针对以上问题,提出用于结直肠息肉图像分割的基于U-Net的高效多注意力融合(efficient multi-attention fusion based on U-Net,EMAU-Net)算法。EMAU-Net算法基于U-Net图像分割算法进行改进,利用快速行进方法(fast marching method,FMM)抑制结直肠镜检查中产生的高光噪声。为了增强息肉特征,在编码器部分应用轻量级网络SegFormer[10]来提取全局特征。对于解码器部分,基于空间和通道挤压与激励块(spatial and channel squeeze &excitation block,scSE)[11]提出深度可分离注意力机制(depthwise separable scSE,DscSE),其中,深度可分离卷积通过将标准卷积操作分解成逐通道卷积和逐点卷积来减少参数量,而scSE模块则提取特征图的通道和空间重要性程度并进行相加处理。
1 U-Net算法
U-Net是用于图像分割任务的网络结构,采用了编码器-解码器结构。U-Net的网络结构被广泛用于医学图像分割[12]、道路图像分割[13]等任务,并且在这些任务中取得了优异的性能表现。U-Net网络结构如图1所示。

图1 U-Net网络结构Fig.1 U-Net network structure
由图1可知,U-Net的编码器部分采用了一系列卷积层和最大池化层,通过不断的下采样操作,将输入图像的尺寸降低,从而提取图像的低级特征。解码器部分则采用了一系列的反卷积层和上采样层,将编码器输出的低分辨率特征图还原为原始图像大小的特征图,并且逐步恢复图像的高层语义信息。在编码器和解码器之间,U-Net还采用了跳跃连接的技术,使得网络可以将编码器中不同层次的特征与解码器中对应层次的特征相结合,进而实现更加精细的分割效果。这种跳跃连接的设计可以帮助U-Net更好地处理图像中的边界细节,从而提高分割的准确性。
2 EMAU-Net算法
针对结直肠内窥镜检查中的息肉边界难区分以及小目标难定位等问题,分别对U-Net编码器和解码器做出改进,同时在数据预处理部分也做出改进,得到EMAU-Net算法,架构如图2所示。由图2可知,将处理过的数据输入EMAU-Net网络中,该算法能充分利用深度学习网络的强大能力,有效地进行息肉分割任务。
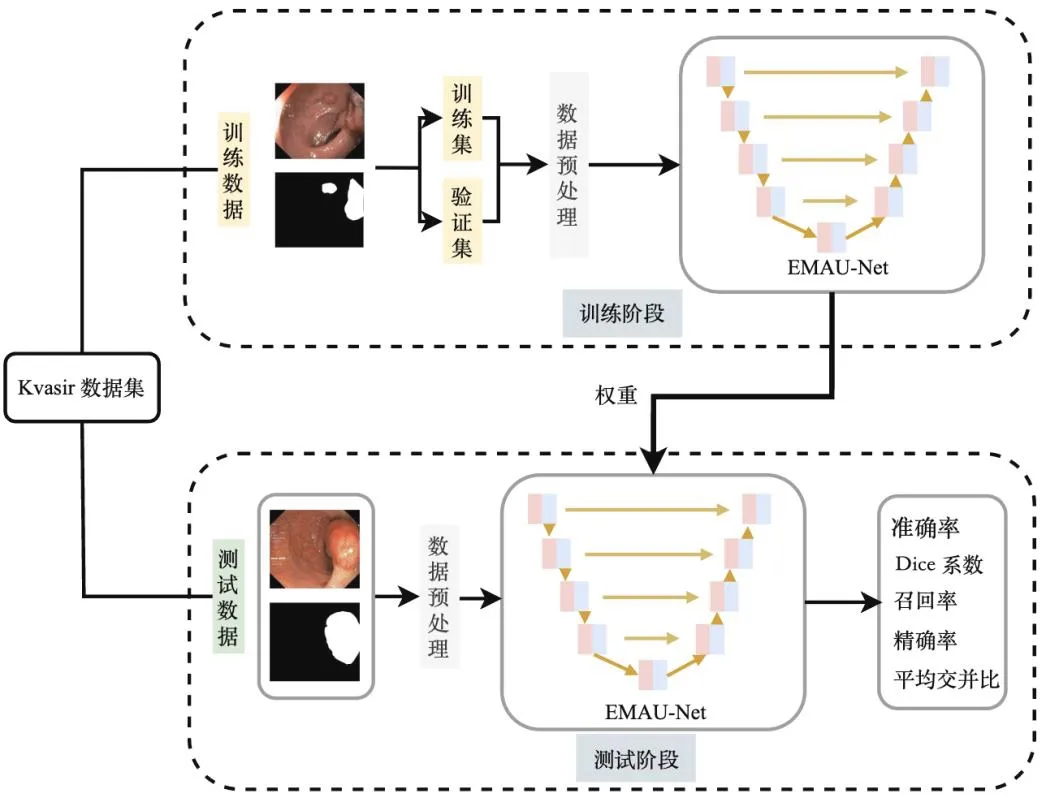
图2 EMAU-Net架构Fig.2 EMAU-Net architecture
2.1 自注意力编码器
采用SegFormer中的Transformer模块来替换U-Net中原始的特征提取模块。该模块能有效提升内窥镜检查中息肉图像特征的提取能力,相比于传统U-Net,它主要包含高效多头自注意力层和混合前馈层,能提取图像中的丰富细节和语义特征。在每个尺度上都通过高效多头自注意力层进行自注意力计算,对输入特征进行增强,能提取大尺度的粗粒度特征和小尺度的细粒度特征,这有助于提高模型对目标物体边缘和细节的识别能力。
SegFormer是基于Transformer的目标分割网络,其设计高效、准确且简单。与视觉Transformer(vision transformer,ViT)[14]模型不同,SegFormer使用了分层特征表示的方法,其中每个Transformer层的输出特征尺寸逐层递减,从而有效地捕获不同尺度的特征信息。这种方法在不需要使用大量计算资源的同时,还可以提高模型的准确性和鲁棒性。同时,SegFormer还采取了舍弃ViT中的位置编码操作的策略,这一策略能够避免测试图像与训练图像尺寸不同而导致模型性能下降的问题。相比之下,SegFormer使用的分层特征表示方法更具有通用性和适应性,能够更好地处理多种不同大小和形状的图像,其网络结构如图3所示。

图3 Segformer 网络结构Fig.3 Segformer network structure
由图3可知,对于给定的图像,先将其划分为多个较小块,然后将其输入到Transformer模块中,以获得原始图像分辨率的多级特征。然后再将这些多级特征传递给解码器。对于这些较小块,在ViT中是将1个N×N×3的块统一为1个1×1×C的向量。这可以很容易地将1个2×2×C特征路径统一到1个1×1×Ci+1向量中,以获得分层特征映射,然后将合并后的多级特征输入到高效多头注意力中。在原始的多头注意力过程中,每个Q、K、V都有相同维数的N×C,其中N=H×W为序列的长度,自注意力机制SA如式(1)所示:
(1)
其中,SS为归一化指数函数;Q为当前位置的输入信息;K为与Q进行相似度计算的键信息;V为与K对应的输入信息;dh为Q和K的维度;T表示转置。该过程计算的时间复杂度为O(N2),对于大分辨率的图像来说计算是极其复杂的。这里使用减少比率的方法来减少以下序列的长度,如式(2)(3)所示:
(2)
(3)
其中,SR为矩阵维数转换函数;SL为线性函数。在ViT中使用位置编码来引入位置信息,但其分辨率是固定的。然而,当测试分辨率与训练分辨率不同时,位置编码需要插值,这将使精度受到影响。因此,在该Transformer模块中引入了混合前馈网络(mix feed-forward network,Mix-FFN),其考虑了0填充对泄漏位置信息的影响,如式(4)所示:
Xo=SMLP(SGELU(Conv3×3(SMLP(Xi))))+Xi。
(4)
其中,SMLP为多层感知机(multi-layer perceptron,MLP)函数;SGELU为高斯误差线性单元函数;X0为输出结果;Xi为输入的特征值。
利用SegFormer来代替U-Net原始特征提取模块,可以更好地学习全局上下文信息,从而更准确地预测像素级别的语义分割。
2.2 轻量级解码器
针对息肉分割问题,在解码器部分嵌入改进后的scSE注意力模块,以加强有意义特征和抑制无用特征,同时避免过多参数的使用。改进后的scSE模块能够更快、更细致地处理语义信息,并使分割边缘更加平滑。
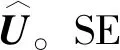
cSE模块的核心思想是将特征图的全局空间特征压缩为各通道的描述符,根据各个通道之间的依赖不同对特征图进行调整,提高网络对于重要通道特征的表征能力。将输入特征图U=[u1,u2,…,uc]视为通道ui∈RH×W的组合。空间挤压由全局平均池化层执行,生成向量z∈R1×1×C及其第k个元素,如式(5)所示:
(5)
其中,i、j分别为输入特征图中第k个通道特征图上每个参数所处的高、宽空间位置(i∈H,j∈W),即每个参数的坐标。该操作将全局空间信息嵌入到向量z中。该向量如式(6)所示:
(6)

(7)
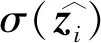
sSE模块通过压缩特征图的通道特征来提高网络对重要空间特征的学习能力。假设U=[u1,1,u1,2,…,ui,j,…,uH,W],其中ui,j∈R1×1×C表示位置在特征图(i,j)处的所有通道特征信息,通过通道数为C、权重为Wsq的1个1×1的卷积块对输入特征图进行通道压缩,输出通道数为1、尺寸为H×W的特征图如式(8)所示:
q=Wsq*U,
(8)
其中,*代表卷积操作。将得到的特征图q经Sigmoid函数σ(·)归一化,得到特征图中每个空间位置(i,j)的空间信息重要性程度σ(qi,j),以增强对重要空间位置特征的提取能力。
scSE模块对输入特征图U进行通道和空间上重要性程度的提取。该模块融合了cSE和sSE模块的优点,并将两者进行相加组合。处理后,scSE模块得到具有高重要性的特征子图,进一步强化激励,促进网络学习更有意义的特征信息。
针对息肉分割研究,为解决在使用scSE模块时可能导致的模型参数量大幅增加的问题,提出了使用深度可分离卷积[15]替代scSE模块中传统卷积的方法,这可以在满足精度需求的前提下大大减少模型的参数量,有助于提高算法在资源受限场景中的性能表现。
2.3 图像高光处理
针对内窥镜运动过程中产生的高光噪声,引入由外而内层层递进的FMM来解决该问题。FMM是基于曲线演化的图像修复算法。它将待修复的图像分为3个集合,并采用到达时间函数T(x,y)的形式模拟曲线演化过程,从边缘向内部推进,逐点完成图像的修复。具体而言,待修复区域记为Ω,该区域的边界记为∂Ω。FMM的核心思想是计算每个待修复像素点p的修复值I(p),并逐步将I(p)推进到已知像素点区域D,最终完成整幅图像的修复。FMM流程如图4所示。
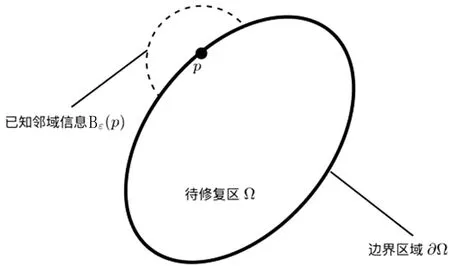
图4 FMM流程Fig.4 Flow of FMM
由图4可知,在计算I(p)的过程中,以p为中心定义1个邻域B,并考虑在该邻域内的每个已知像素q对p修复产生的影响。该影响如式(9)所示:
Iq(p)=I(q)+∇I(q)(p-q),
(9)
对于邻域Bε(p)的所有已知像素点q,找到1个权重函数w(p,q),加权平均每个像素q对于待修复像素p的影响,从而求出p的修复值。该修复值计算如式(10)所示:
(10)
利用FFM对息肉数据进行高光处理,前后对比如图5所示。由图5可知,高光处理后的图像呈现出更高的清晰度和对比度,消除了光线干扰导致的亮度变化和细节模糊。这种图像质量的提升使医生能够更准确地观察和分析结直肠组织的形态和特征。同时,处理后的图像也为计算机辅助诊断提供了更理想的输入。
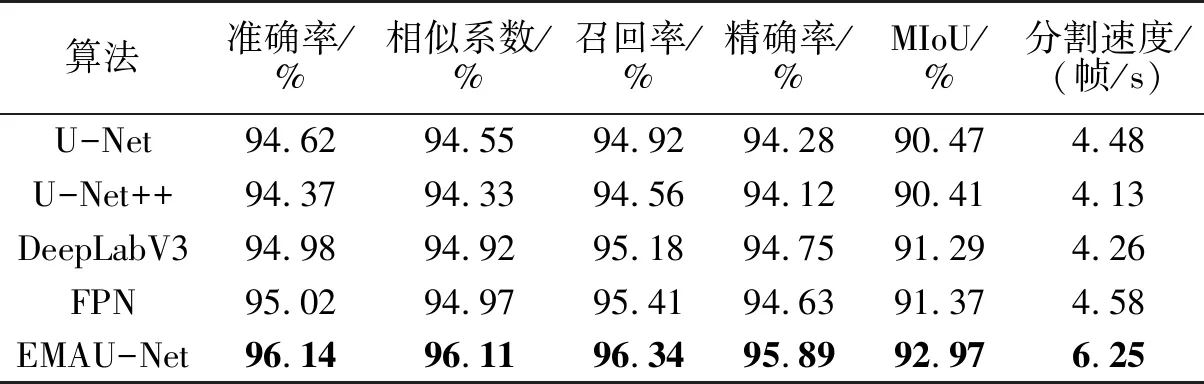
表1 对比实验结果Tab.1 Comparison of experimental results
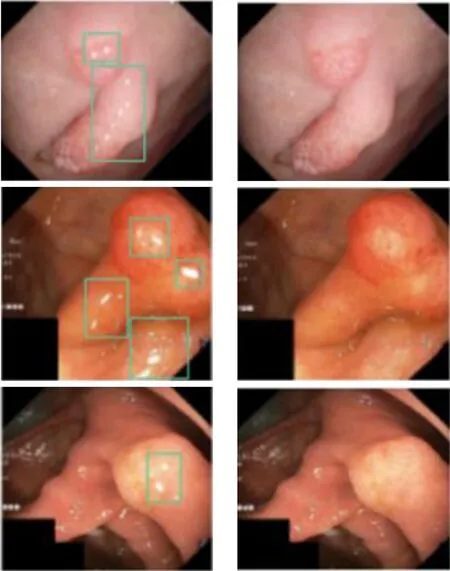
(a) 处理前 (b)处理后图5 高光处理效果Fig.5 Highlight effect
3 实验结果与分析
3.1 实验环境
Kvasir-SEG数据集是1个用于医学图像分割的公共数据集,旨在帮助开发和测试基于深度学习的医学图像分割算法。该数据集包括1000张内窥镜图像和相应的标签。EMAU-Net算法运行环境的硬件设备参数为:CPU为i5-10400F,内存为16GB,显卡为Nvidia RTX3060,操作系统为Ubuntu 20.04.5 LTS,软件编程环境为Python3.9,使用的深度学习框架为PyTorch 1.8。
为了评估分割算法的性能,使用了准确率、召回率、相似系数、精确率、平均交并比(mean intersection over union,MIoU)和分割速度作为指标。这些评价指标被广泛用于医学图像分割领域,可以帮助客观地评估算法的准确性和效果。
3.2 对比实验
研究中还比较了多种不同的分割算法,包括U-Net、U-Net++、DeepLabV3、特征金字塔(feature pyramid networks,FPN)算法,统一使用Kvasir-SEG数据集进行评估,对比实验结果如表1所示。
由表1可知,EMAU-Net算法的所有指标均表现最好,其中MIoU达到92.97%。其次,FPN和DeepLabV3的表现也很优秀,MIoU分别达到91.37%和91.29%,但是在边缘部分分割效果较差。而U-Net和U-Net++表现相对较差,MIoU均低于90.50%。除此之外,EMAU-Net算法在以上算法中的分割速度也是最优的。总的来说,EMAU-Net算法在Kvasir-SEG数据集上具有较好的性能,比其他常见的图像分割算法好。图像分割结果如图6所示。由图6可知,结直肠内部环境复杂,然而通过对比其他算法分割结果发现,EMAU-Net算法能够有效识别并分割出具有复杂纹理的区域,以保持目标物体的完整性和连续性,并减少了误差和伪影的出现。这种能力使得EMAU-Net算法能够更精确地捕捉到目标结构的边缘,并生成更准确的分割结果。

(a) 原图 (b) 标签 (c) FPN (d) U-Net++ (e) DeepLabV3(f) EMAU-Net图6 图像分割结果Fig.6 Image segmentation results
3.3 消融实验
为了验证模型中各个单独组件的影响进行了消融实验。从U-Net原始网络结构开始,逐渐过渡到EMAU-Net算法模型,共设置了4组对比方法。表2为消融实验结果,第1组是U-Net原始网络结构,作为实验的基准模型,在此基础上,逐步引入新的组件并对其进行测试;第2组基于U-Net对数据进行高光处理,记为HT(highlight treatment);第3组在第2组的基础上,添加自注意力模块,记为HT-SA(self attention);第4组在第3组的基础上,添加轻量级解码器,即EMAU-Net。由表2可知,从准确率、相似系数、召回率、精确率、平均交并比、分割速度这6个指标来分析,算法每一部分的改进都取得了有效的性能提升;并且这些改进相互补充,使得效果叠加,减少了分割误差和伪影,提高了目标检测和定位的准确性,增强了分割结果的完整性和连续性,同时加快了分割速度。

表2 消融实验结果Tab.2 Results of ablation experiment
消融实验图像分割结果如图7所示。由图7可知,EMAU-Net算法处理结果明显优于原始U-Net算法,在息肉边缘区域可以捕获更细粒度的特征。通过对算法HT-SA的实验数据分析可以发现,应用SegFormer后的算法分割速度有极大地提升。相比较于HT-SA,EMAU-Net添加了改进后的scSE,分割速度也有较明显提升,在其余各项性能指标方面表现也均为最优。

(a) 原图 (b) 真实标签 (c) U-Net (d) EMAU-Net图7 消融实验图像分割结果Fig.7 Image segmentation results of ablation experiments
4 结论
提出了基于U-Net的高效多注意力融合息肉分割(EMAU-Net)算法,分别从编码器和解码器2个层面对U-Net进行改进。针对编码器部分,使用轻量级Transformer模块替换U-Net中原始的特征提取模块;针对解码器部分,嵌入改进后的scSE模块,提高精度的同时又降低了参数量;除此之外,还对数据部分进行了高光处理。实验结果表明,EMAU-Net算法保留了息肉区域的细节特征,对息肉边缘部位的分割敏感性也很高,可以有效地将息肉区域分割出来,便于医生作出正确的诊断,该研究成果有望为医生对结直肠癌的诊断和治疗提供有力帮助。
猜你喜欢
睿士(2023年8期)2023-08-23 13:07:06
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
玩具世界(2021年5期)2021-03-08 08:42:02
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
家庭影院技术(2017年12期)2017-02-06 02:32:05
电子器件(2015年5期)2015-12-29 08:42:24
