
基于MCA-BERT的数学文本分类方法
2023-09-13 03:06杨先凤李自强
计算机工程与设计 2023年8期
杨先凤,龚 睿,李自强
(1.西南石油大学 计算机科学学院,四川 成都 610500;2.四川师范大学 影视与传媒学院,四川 成都 610066)
0 引 言
对现有资源进行分类标识,匹配学科知识图谱,彰显了构建学科知识图谱对教育的重要性[1]。非结构化文本数据是知识图谱构建的重要数据来源,文献[2]针对非结构化数据,围绕知识图谱中的信息抽取和信息融合任务开展了一系列的研究。对非结构化文本数据进行数据挖掘有利于后续任务的推进,文献[3]针对电子病历的非结构化数据对电子病历数据挖掘的4种典型任务命名实体识别、关系抽取、文本分类[4]和智能问诊进行了深入研究。文本分类是数据挖掘的重要子任务,将学科非结构化文本数据按知识类别分类不仅可以实现海量数据的自动聚类,还可以在一定程度上提高后续任务如关系抽取的精度,文献[5]通过文本分类识别出数据集中的积极样例进而提高了关系抽取的精度。
数学学科具有抽象性、简洁性和准确性的特点,具有很重要的研究价值,文献[6]基于SVM实现了数学题目的自动分类,可以帮助理解题意。本文以数学非结构化数据为研究对象,首先构建了数学数据集,然后提出了一种获得句子级的实体信息和词语级的实体信息并将二者与BERT生成的上下文信息结合的文本分类方法。最终实验结果表明该模型相比其它基准模型具有更好的文本分类效果。
1 相关工作
分类模型是实现文本分类任务的重要部分。传统的统计机器学习方法将文本转换成数字或One-hot向量表示,输入分类器如支持向量机分类器、朴素贝叶斯分类器,就可以得到分类结果。但是统计机器学习方法的缺点是需要特征工程工作的支持,非常耗时耗力,并且分类效果一般。深度学习的方法不存在统计机器学习的缺点,并且可以尽可能地挖掘文本中潜在的特征,进而提高分类效果。明建华等[7]提出将TextCNN模型应用在直播弹幕文本分类中,该模型可以更好地获取文本特征,从而获得比机器学习方法更好的分类效果,能够有效识别直播弹幕中的非法短文本。文本表示是文本分类任务的另一重要部分,仅用数字或One-hot向量表示文本会因为忽略词与词之间的关系、词与文本之间的关系而丢掉文本中的很多信息。Yao等[8]提到一种文本分类器FastText,该分类器将文本表示为词袋,并向其加入了N-gram特征处理词顺序丢失的问题,可以在训练时间比深度网络快许多数量级的情况下实现与深度网络相媲美的精度。Huang等[9]提出了一种新型文本分类模型,将层次注意力机制引入了文本分类,模型能够直观地解释各个句子和词对文档分类的重要性。王根生等[10]提出用训练生成的Word2vec词向量和TF-IDF算法构建文本的向量表示,用卷积神经网络负责特征的提取,最后取得了不错的分类效果,说明实体词信息对文本分类任务的重要性。为了更好地学习文本中字与字之间的上下文关系,段丹丹等[11]提出了将BERT运用在中文短文本分类中,使用Transformers 编码器作为特征抽取器可以获得更丰富的上下文信息。特定领域的文本分类可以挖掘到该文本中的潜在价值,杜琳等[12]提出将BERT应用在病历文本分类中,能够有效地利用宝贵的中医病例文本资源。
2 模型结构
BERT预训练模型可以有效提取文本的上下文信息。用数学文本中所有领域实体词对应的Word2vec词向量的平均池化来表示句向量可以从句子级方面提取文本的实体词信息。对数学文本中的所有领域实体词采用注意力机制可以获得文本中不同实体词的权重信息,可以从词语级方面进一步加强实体词信息的作用。MCA-BERT模型结构如图1所示。
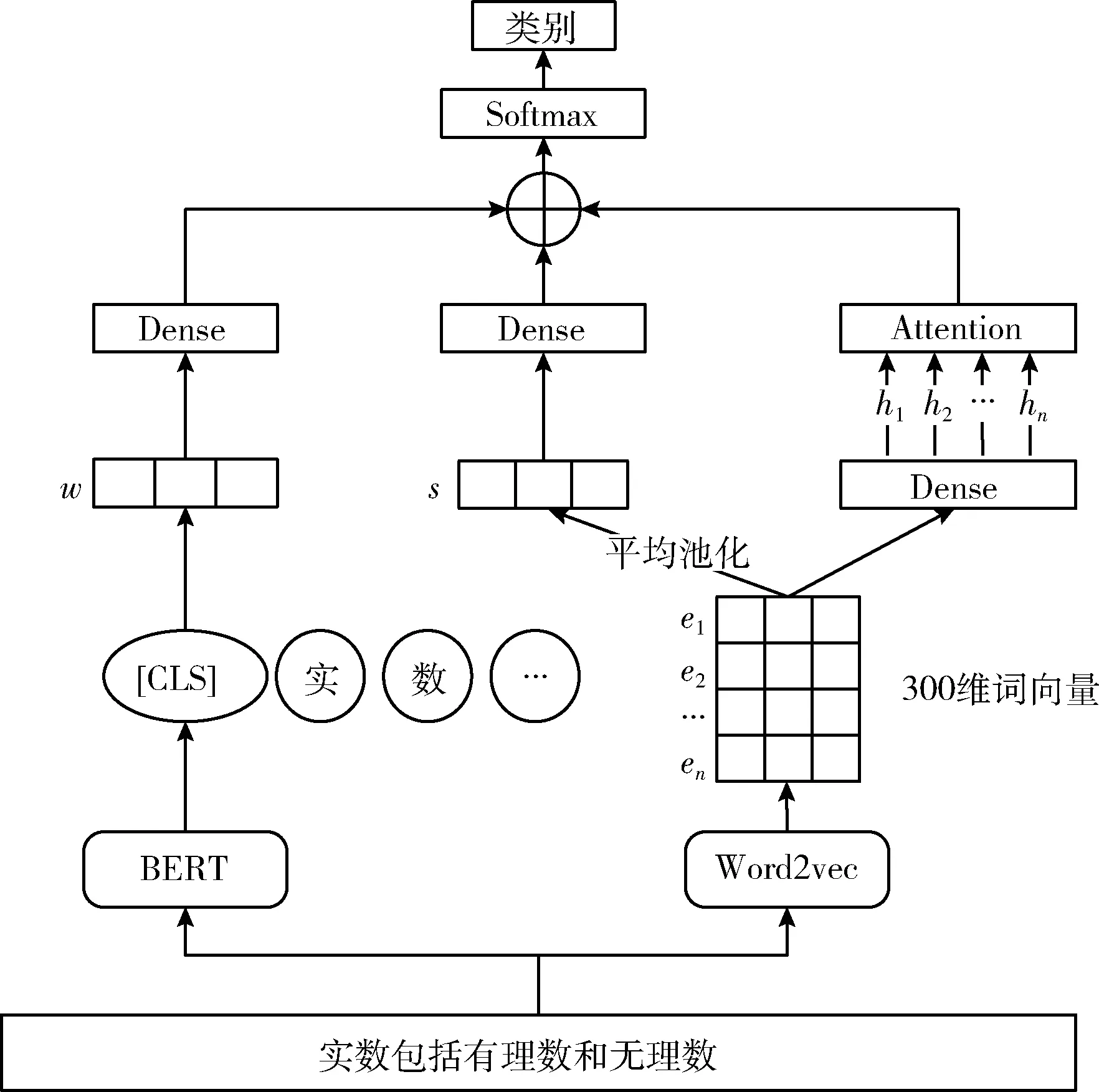
图1 MCA-BERT模型结构
该模型网络包含以下4个部分:
(1)BERT Context Information Channel(BERT_CIC)BERT上下文信息通道;
(2)Average Pool Channel(APC)平均池化通道;
(3)Attention Weight Channel(AWC)注意力权重通道;
(4)Softmax输出层。
2.1 BERT上下文信息通道
BERT的模型结构如图2所示。
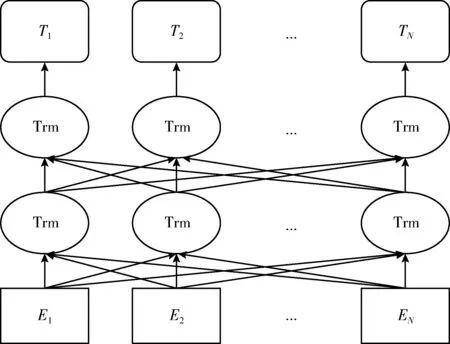
图2 BERT模型结构
模型的输入E是文本中每一个字对应的输入向量,输入向量生成的方式如图3所示。
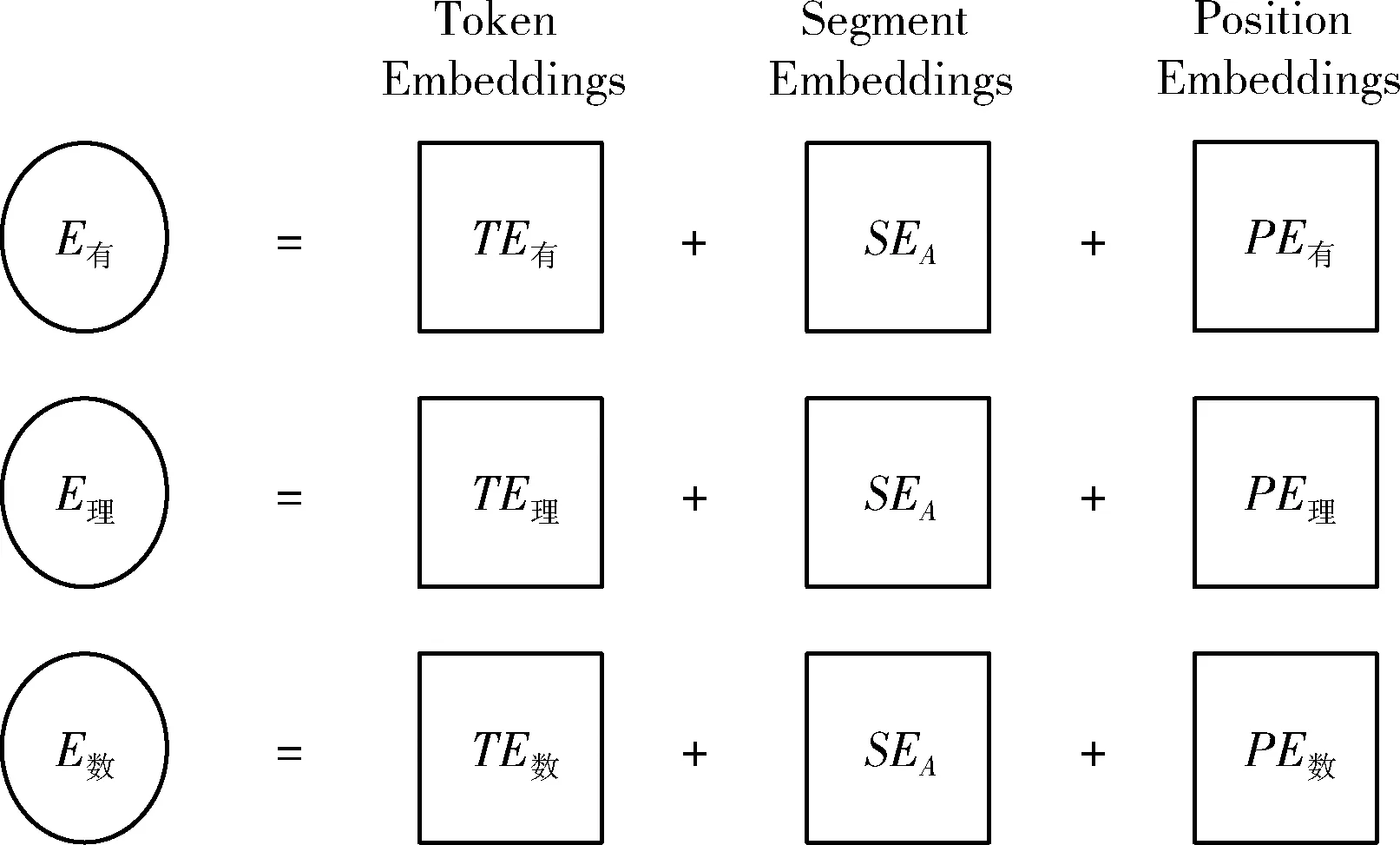
图3 输入向量的组成
每一个字的输入向量等于字向量TE和文本向量SE以及位置向量PE的和。Trm是指Transformers,由若干个编码器和解码器堆叠形成,BERT只用到了Transformers的编码器部分,编码器包含一个多头自注意力机制和一个全连接层。多头自注意力机制允许模型在不同的表示子空间里学习到相关的信息,全连接层输出的是每一个输入对应的隐藏层向量,该向量可用于下游任务。BERT与Word2vec最大的不同在于BERT的输出向量是动态的,不同两句话中同一个词生成的输出向量会因为上下文信息的不同而不同,可以很好地解决一词多义的问题。
BERT模型有两个自监督任务Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM是指随机mask每一个训练句子中15%的词,用其上下文来做预测,在这15%中,80%是被替换成[mask],10%是随机取一个词来代替被mask的词,10%维持原状。NSP是指从语料中选择一些句子对A和B,其中50%的数据中B是A的下一条句子,剩余50%的数据中B是语料库中随机选择的,通过训练可以学习句子间的相关性。
BERT上下文信息通道中文本经过BERT编码输出的句向量w是在文本前添加的[CLS]对应的隐藏层向量。因为[CLS]本身没有语义,得到的向量是经过多头自注意力机制后所有词的加权平均,相比其它的向量,可以更好地表征句子语义。
2.2 平均池化通道
2.2.1 One-hot
词向量可以对文本进行编码,One-hot是最简单的编码方式。One-hot词向量的分量只有一个是1,其维度是整个词汇表的大小,虽然这样可以唯一表示所有的词汇,但是词汇量一旦过多,会导致维度灾难问题的出现。除此之外,词与词在空间上都是垂直的关系,相关性为0,存在语义鸿沟的问题。One-hot工作原理如图4所示。

图4 One-hot编码
2.2.2 Word2vec
Word2vec通过将One-hot词向量转化为低维度的连续值,可以解决One-hot词向量维度灾难和语义鸿沟的问题。词向量与词向量之间的相似度计算用的是余弦相似度[13],其值越接近1,向量之间的相似度越高,余弦相似度公式如式(1)所示
Similarity(A,B)=∑ni=1Ai×Bi∑ni=1(Ai)2×∑ni=1(Bi)2
(1)
Word2vec模型是一个简单化的神经网络,只包含输入层、隐藏层和输出层。该网络最终的目的是获得通过训练得到的权重矩阵,该权重矩阵可以唯一表示输入的One-hot向量,从而实现将高维的One-hot编码降维至Word2vec形式的表示。Word2vec模型根据输入输出的不同可以分为两种,一种是CBOW,它的输入是目标词对应的上下文词向量,而输出就是这个目标词的词向量。另一种是Skip-Gram模型,它的输入输出和CBOW相反。
本文用维基中文数据训练的Word2vec词向量模型查询与“有理数”余弦相似度最高的5个词,结果见表1,由表可知关联性越高的词汇余弦相似度越高。
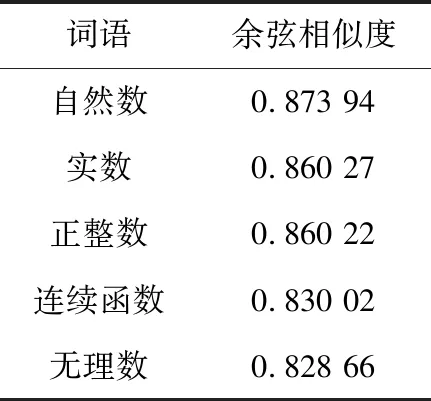
表1 与“有理数”最相似的5个词语
2.2.3 平均池化
文本中实体词的词向量的平均池化可以减少特征和参数,并且可以作为句向量表示文本,其公式如式(2)所示
s=∑ni=1ein
(2)
其中,ei表示文本中的第i个数学实体词对应的词向量,n表示实体词的个数,s表示最终输出的句向量。不同句子中的实体信息差别越大,最终得到的句向量之间的余弦相似度越小,所以句向量可作为句子级的实体信息,帮助判断文本的类别。例如文本是“无理数和有理数统称为实数。”,e0表示“无理数”的词向量,e1表示“有理数”的词向量,e2表示“实数”的词向量,则文本的句向量s=(e0+e1+e2)/3。
2.3 注意力权重通道
句子级的实体信息对每一个实体词的关注程度都是一样的,只能简单地帮助判断句子的类别。在文本分类任务中,不同实体词的贡献是不同的,注意力机制可以对输入的每一个实体词向量分配不同的权重,使得模型能够多关注一些重要实体信息,注意力计算公式如下式表示
ei=uTitanh(wihi+bi)
(3)
αi=softmax(ei)
(4)
o=∑ni=1αihi
(5)
其中,hi是经过Dense层非线性变换过后的实体词向量,uTi是输入hi对应的权重向量,wi是输入hi对应的权重矩阵,bi是偏置向量,αi是hi的注意力权重,o是最终的加权和输出。最终得到的输出o会突出部分权重较高的词的实体信息,所以可作为词语级的实体信息,帮助判断文本的类别。
2.4 Softmax输出层
输出部分的公式如下式表示
yj=softmax(zj)
(6)
zj=WTjx+bj
(7)
x=xBERT_CIC⊕xAPC⊕xAWC
(8)
softmax(zj)=exp(zj)∑nj=1exp(zj)
(9)
其中,yj是指第j类的概率,WTj是权重矩阵,bj是偏置矩阵,x是输入向量,由xBERT_CIC、xAPC、xAWC拼接而成。xBERT_CIC是BERT上下文信息通道的输出,xAPC是平均池化通道的输出,xAWC是注意力权重通道的输出。
3 实验以及结果分析
3.1 实验数据集
本文构建的数据集来源包括:手动搜索的教案文本、爬取人教版课本内容获得的文本、爬取中文维基百科对数学实体词描述的部分获得的文本、调用科大讯飞语音转写接口转写初中数学课堂视频得到的文本。获得数据之后,接着对上述文本进行清洗、筛选、标注,最终得到一共6142条数据。数据内容是对数学概念的描述,如:“正数的绝对值是他的本身、负数的绝对值是他的相反数、0的绝对值是0。两个负数比较大小,绝对值大的反而小。”,“解析式形如y=k/x的函数叫作反比例函数,其中k也叫作反比例系数,反比例函数的定义域是不等于零的一切实数。”。初中数学实体词是指可在初中数学中能够找到相关定义的词,如“三角形”、“无理数”、“反比例函数”等。本文在划分数据类别的时候,以人教版的初中数学目录为参照,将整个知识体系分为代数和几何两个大类,然后将代数继续细分为如下3类:
(1)数与式:实数及其运算、代数式及其运算以及根式的相关内容,主要包括有理数、实数、整式、分式、单项式、多项式等知识点。
(2)方程、不等式、函数:方程、不等式、函数这3个概念是区别而又紧密联系的,概念大量交叉,所以该类包含上述3部分的所有内容,主要有方程与方程组、列方程解应用题、不等式与不等式组、平面直角坐标系、变量与函数、正比例函数、一次函数、反比例函数、二次函数等知识点。
(3)统计与概率:统计与概率的所有内容,主要包括总体、个体、众数、平均数、中位数、方差、标准差、直方图等知识点。
根据初中数学知识的重要程度,本文将几何这个大类的文本继续细分为如下4类:
(1)三角形:三角形的所有内容,主要包括三角形的概念与性质、相似三角形、全等三角形、三角函数等知识点。
(2)四边形:四边形(矩形、平行四边形、梯形、菱形)的所有内容,主要包括四边形边、角的概念与性质、四边形的面积计算、四边形的判定等知识点。
(3)圆:圆的所有内容,主要包括圆的概念与性质、圆和圆的位置关系、弧的概念和性质、直线和圆的关系、弦的概念和性质等知识点。
(4)几何知识类:没有包含在上面几何3大类知识点的内容,如视图的概念和判断、线的概念与性质、角的概念与性质、多边形(不包括三角形和四边形)的概念与性质等知识点。
部分数据内容及其类别见表2。

表2 数据分类示例
3.2 参数设置
为了解决现有Word2vec词向量模型存在部分数学实体词的词向量缺失和数学实体词的词向量训练不充分的问题,本文从初中数学中筛选出了782个数学实体词添加到自定义用户词典,然后用本文的6142条数据训练Word2vec词向量,训练的主要参数见表3。其中sg用于设置训练算法,默认为0,对应CBOW算法,sg设置为1则采用Skip-Gram算法。Skip-Gram能够更好地处理出现频率较低的词,比如很少出现在文本中的实体词“混循环小数”、“大数定理”等。size是指输出词的向量维数,默认为100,设定为300。window表示当前词与预测词在一个句子中的最大距离是多少,设定为默认值5,一旦当前词和预测词的距离超过5就可以认为两词的相关性不大。Skip-Gram神经网络在训练的时候会有非常大的权重参数,负采样negative samping每次让一个训练样本仅仅更新一小部分的权重参数,可以降低梯度下降过程的计算量。对于小规模数据集,一般选择5到20个negative words,本文设定的negative值为10。workers表示控制训练的并行数,设定为4,可以减少训练时间。iter表示随机梯度下降法中迭代的次数,设定为10。

表3 Word2vec训练参数
MCA-BERT部分网络参数见表4。其中Dropout设置为0.7的含义是保留该神经网络层百分之七十的结点,丢弃其余的结点,可以在一定程度上减小网络的大小,防止模型过拟合。损失函数选择的是categorical_crossentropy,它适用于多分类并且Softmax作为输出层的激活函数的文本分类问题。

表4 网络参数
3.3 评价指标
P=TPFP+TP
(10)
R=TPFN+TP
(11)
F1=2P·RP+R
(12)
其中,TP表示模型中预测正确的正样本,FN表示模型中预测正确的负样本,FP表示模型中预测错误的负样本。F1可以很好地兼顾精确率和召回率,因为本文是一个多分类问题,所以使用宏平均作为评价指标,宏平均是所有类的F1值的算术平均,其计算公式如下式表示
Pmacro=1n∑ni=1Pi
(13)
Rmacro=1n∑ni=1Ri
(14)
F1macro=2Pmacro·RmacroPmacro+Rmacro
(15)
其中,Pi是第i类的精确率,Ri是第i类的召回率,n是类别数目,Pmacro是宏平均的精确率,Rmacro是宏平均的召回率,F1macro是宏平均的F1值。
3.4 实验结果与分析
3.4.1 实验一
为了验证MCA-BERT模型的有效性,本文将该模型与以下模型进行对比:
TextCNN:首先对文本进行编码,然后采用3种尺寸(2、3、4),一共3*2个卷积核对文本进行特征提取,相比单个卷积核可以得到更丰富的特征表达,最后将获取的特征拼接并输入Softmax层完成文本分类。
FastText:首先对文本进行编码,然后利用N-gram挖掘文本特征,最后输入层次Softmax完成分类。
Word2vec平均池化单通道:以文本中实体词的词向量的平均池化作为输入,后接256维Dense层和Softmax层完成文本分类。
BERT单通道:以BERT生成的768维句向量作为输入,后接256维Dense层和Softmax层完成文本分类。
BERT拼接Word2vec平均池化单通道:将BERT生成的768维句向量与Word2vec平均池化得到的300维向量拼接作为输入,后接256维Dense层和Softmax层完成文本分类。
BERT_CIC+APC双通道:将BERT_CIC的输出与APC的输出拼接再输入Softmax完成文本分类。
BERT_CIC+AWC双通道:将BERT_CIC的输出与AWC的输出拼接再接入Softmax完成文本分类。
实验结果见表5。
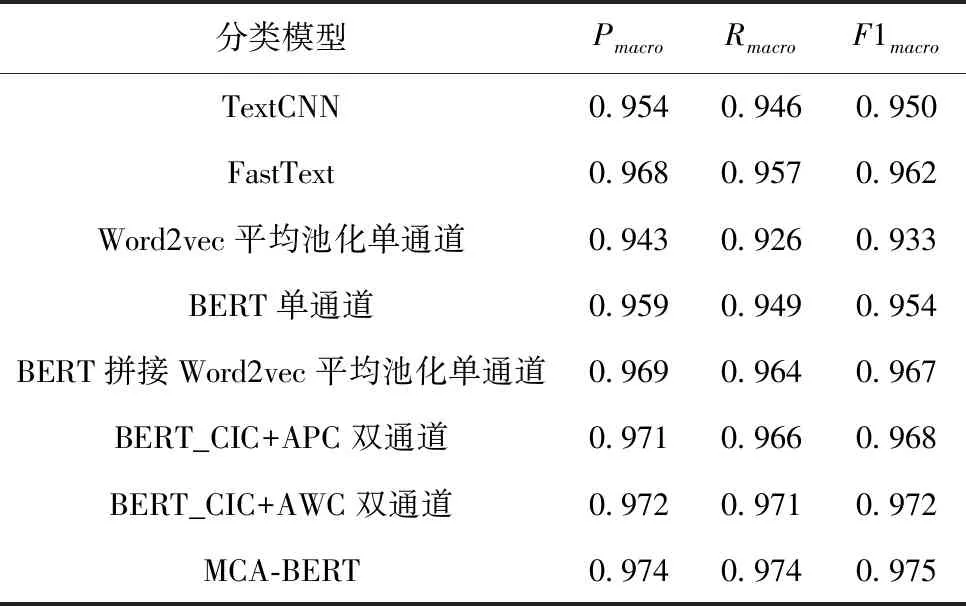
表5 模型结果(实验一)
3.4.2 实验二
为了探究不同预训练模型对该实验的影响,本文将BERT预训练模型与BERT-wwm[14]、BERT-wwm-ext、RoBERTa-wwm-ext[15]、ALBERT-base[16]预训练模型进行了对比,每个模型输出的向量维度都是768,各模型的特点如下:
BERT-wwm:BERT-wwm是在BERT基础上,将Mask任务由替换字词修改为替换一个完整的词,训练完成后字的embedding具有词的语义信息。
BERT-wwm-ext:相比BERT-wwm的改进是预训练模型做了增加,次数达到5.4 B;训练步数增大,训练的第一阶段1 M步,训练第二阶段400 K,在一些中文任务上效果有提升。
RoBERTa-wwm-ext:该预训练模型在BERT的基础上做了以下调整:引入了动态mask,相比于静态,动态mask是每次输入到序列的mask都不一样;改变了预训练的方法,移除了BERT的NSP任务,相比于BERT,采用了连续的full-sentences和doc-sentences作为输入(长度最多为512);训练时间更长,batch size更大,训练数据更多。
ALBERT-base:采用了两种减少模型参数的方法,模型比BERT占用的内存空间小很多,同时极大提升了训练速度,并在一些任务中获得比BERT更好的模型效果。
实验结果见表6。

表6 模型结果(实验二)
然后本文对BERT_CIC+APC双通道、BERT_CIC+AWC双通道、MCA-BERT、MCA-RoBERTa-wwm-ext的验证集损失进行了对比,如图5所示。
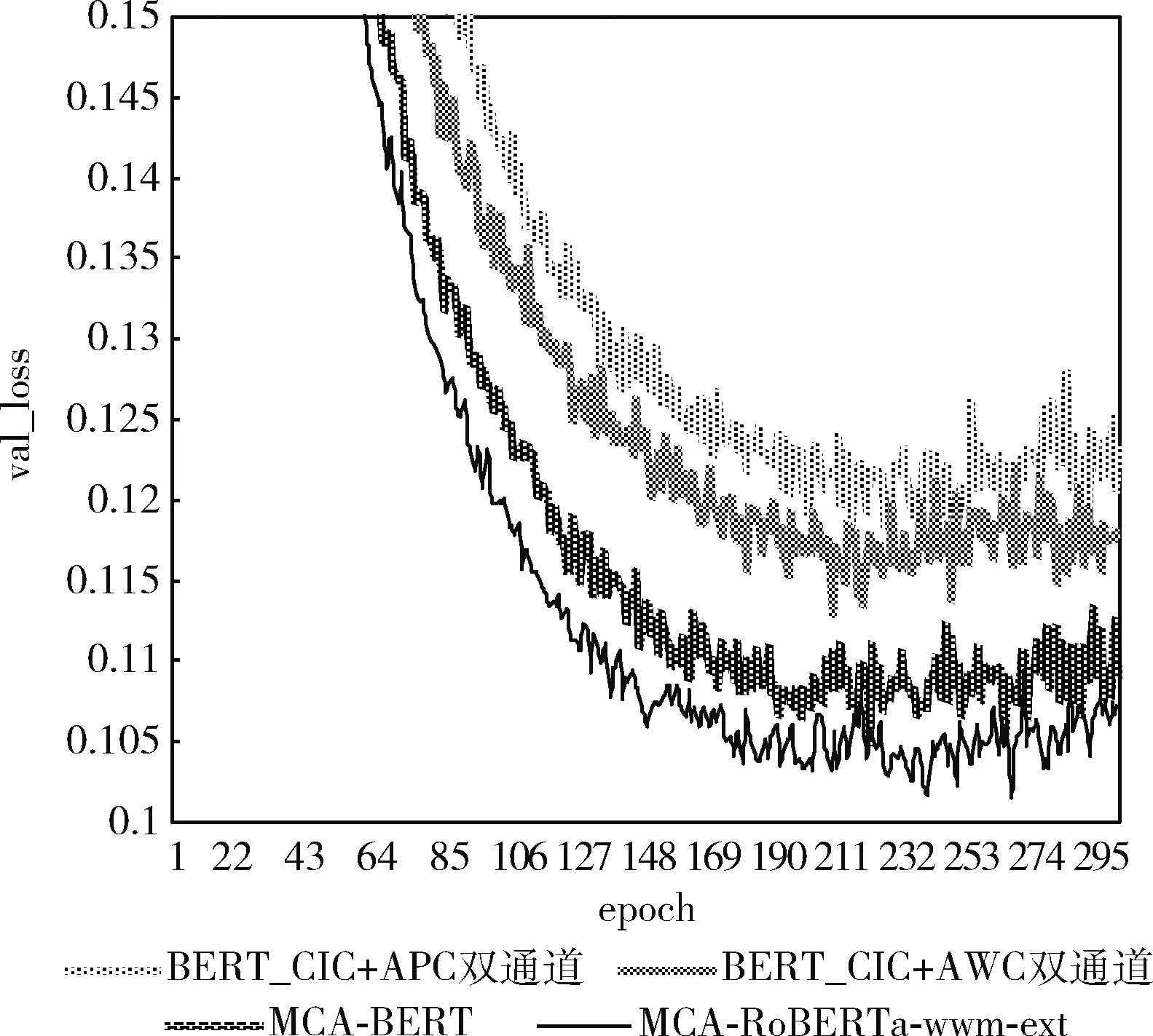
图5 验证集损失
3.4.3 实验三

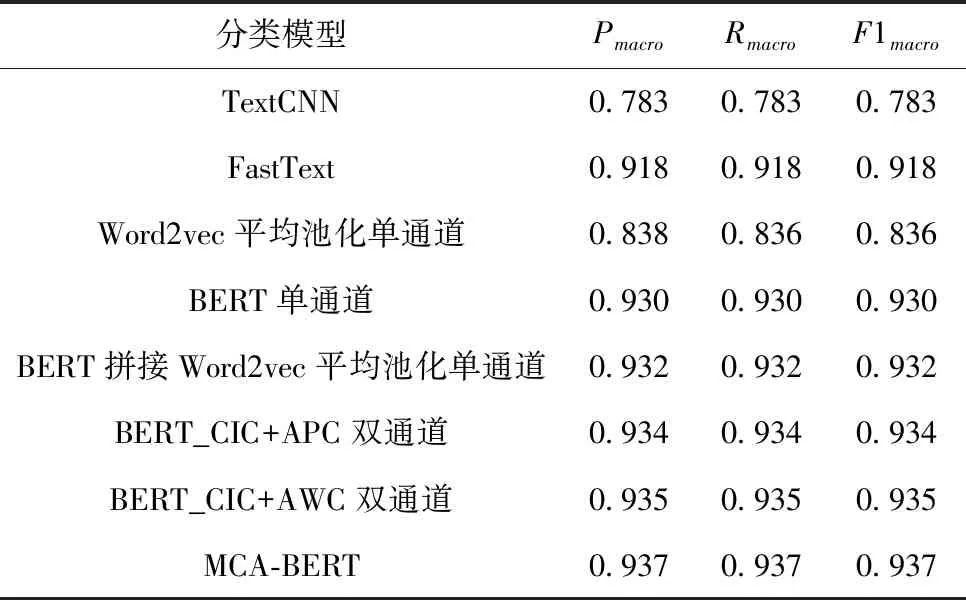
表7 模型结果(实验三)
3.4.4 实验分析
由实验一可知,传统的TextCNN仅通过卷积挖掘文本的特征效果很差,原因是最大池化丢失了结构信息,很难发现文本中的转折关系等复杂模式,并且TextCNN只知道关键词是否在文本中出现,以及相似度强度分布,不知道关键词出现的频率以及这些关键词出现的先后顺序。FastText利用N-gram方法提取文本中特征,对于目标词来说可以获得前N-1个词所能提供的全部信息,但是需要相当规模的训练文本来确定模型的参数,可以一定程度上地提高分类效果。Word2vec平均池化单通道的方法只考虑了文本的实体词信息,而没有考虑到文本的上下文信息,所以效果相对较差,但是最终的结果说明句子级的实体信息对文本分类任务来说是有帮助的。BERT单通道的方法可以很好地挖掘文本的上下文信息,但是忽略了文本中实体信息的作用。BERT拼接Word2vec平均池化单通道的方法与BERT_CIC+APC双通道的方法对比表明双通道相比单通道的方法能够更有效地融入句子级的实体词信息,从而获得更好的分类效果。BERT_CIC+AWC双通道的实验结果表明词语级的实体信息比句子级的实体信息更有效。MCA-BERT的方法同时融入句子级的实体词信息和词语级的实体词信息能够获得更好的文本分类效果,最终的实验F1值相比BERT单通道的方法提高了2.1个百分点。实验二对比各种预训练模型发现将BERT替换成RoBERTa-wwm-ext能够获得更好的文本分类效果,验证集的损失收敛得更快更低。实验三中MCA-BERT模型得到的F1值相比BERT单通道的方法提高了0.7个百分点,说明通用数据集的文本分类任务也可以通过增强实体信息而提高文本分类效果,但是提升的效果不如特定领域的文本分类。
4 结束语
为了提高数学文本分类的效果,本文构建了数据集并根据数据集的特点提出了一种MCA-BERT的方法,并与其它基准模型进行了对比,实验结果表明该方法能够有效提高文本分类的精度,该方法可以为特定领域的文本分类任务提供参考。然后本文将MCA-BERT中的BERT与其它主流预训练模型进行了对比,发现更换RoBERTa-wwm-ext模型能够进一步提高文本分类效果。最后,用MCA-BERT模型在通用文本分类数据集THUCNews数据集上进行了测试,结果表明该模型也能在一定程度上提高通用文本分类任务的效果。下一步工作,我们会在此基础上实现命名实体识别任务和关系抽取任务从而构建基于非结构化数据的数学知识图谱,并探索更有效的实体词信息获取方法,将其拓展到其它文本分类任务中。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
新高考·高一数学(2022年3期)2022-04-28
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
计算机技术与发展(2019年1期)2019-01-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
