
设施蔬菜病害识别中的CNN池化选择
2021-12-29 01:10刘之瑜张淑芬张振斌董燕灵罗长银
新一代信息技术 2021年22期
刘之瑜,张淑芬,张振斌,董燕灵,罗长银
(1. 华北理工大学 理学院, 河北 唐山 063210;2. 华北理工大学 河北省数据科学与应用重点实验室,河北 唐山 063210;3. 华北理工大学 唐山市数据科学重点实验室,河北 唐山 063210)
0 引言
设施蔬菜可以随时随地监控设施内环境参数并及时调节,可以为设施内的蔬菜提供合适的生长环境提高蔬菜的产量和质量,因此设施蔬菜的建设规模发展迅速。相较于设施内蔬菜生长需要的空气温度和湿度、土壤的温度和湿度、光照强度、CO2浓度、土壤酸碱度等环境条件,蔬菜病虫害是影响设施蔬菜产量的最主要因素。很长时间内务农人员在管理设施蔬菜的时候只能靠肉眼去观察蔬菜的生长情况,是否有病虫害以及病虫害的危害程度,往往很难及时发现并采取措施,蔬菜病虫害总会造成蔬菜产量的减少和质量的降低,不止给务农人员造成了经济损失,也对人们的菜篮子造成了影响。
为了最大限度地减少生产损失和保持蔬菜作物的可持续性,必须采取适当的疾病管理和控制措施,突出对蔬菜作物的持续监测,并结合病虫害的快速准确诊断[1]。图像采集设备采集的蔬菜图像,由于其中细微的类间差异和较大的背景变化,大规模图像数据集的视觉分类具有挑战性。深度卷积神经网络(CNNs)是迄今为止解决这一问题最成功的模型,不断有各种卷积神经网络结构被提出来提高分类性能,如ResNet[2]、SENet[3]、InceptionNet[4]、VGGNet[5]。从网络结构的角度看,卷积神经网络主要包括卷积层、池化层和全连接层三个基本操作,卷积层通过卷积核从图像中提取有效特征[6-8],此外卷积层后常跟一个激活函数,如线性整流单元(ReLU)[9],以完成对网络的非线性变换;池化层是卷积神经网络中常用的另一个关键操作,经过池化操作可以有效降低特征图的维数,降低计算量同时增强对输入图像变化的鲁棒性,一定程度上可以减少过拟合,卷积神经网络常用的池化类型有最大池化[10]和平均池化[11],也有一些网络抛弃了池化操作,如ResNet[2],使用跨步卷积将池化层以1× 1卷积核代替,这样操作是有效的但不能确定所选节点是不是最有效的点;而全连接层起到了分类器的作用,将卷积层提取到的特征映射到样本标记空间,完成分类。
与卷积操作相比,池化操作较难手动选择,往往根据性能或经验来确定,需要在实验和错误中付出时间和精力来确定池化参数,如何根据不同类型的数据选择池化类型也是一个问题。本文对最大池化和平均池化的选择进行了研究,根据图像梯度的变异系数对池化的类型进行选择,将原数据集划分为最大池化部分和平均池化部分,再进行训练,实验验证了可行性。
1 卷积神经网络中的池化
在卷积神经网络被广泛应用之前,传统的图像识别算法采用人工设计特征提取算子的方法来提取图像特征,比较著名的有 SIFT[12]和 HOG[13]特征提取算子,大多数特征提取算子都采用池化操作来减少特征向量的大小。池化的数据扫描方式类似于卷积核,一个4×4的矩阵经过2×2大小步长为2的滑动窗口池化操作后尺寸变为2×2的矩阵,最大池化对输入的特征图矩阵采用取最大值的操作,滑动窗口扫过的区域取四个元素中的最大值,最大池化窗口覆盖区域取值过程如图 1所示。平均池化对输入的特征图矩阵采取求均值的操作,滑动窗口扫过的区域取四个元素的平均值,平均池化窗口覆盖区域取值过程如图2所示。
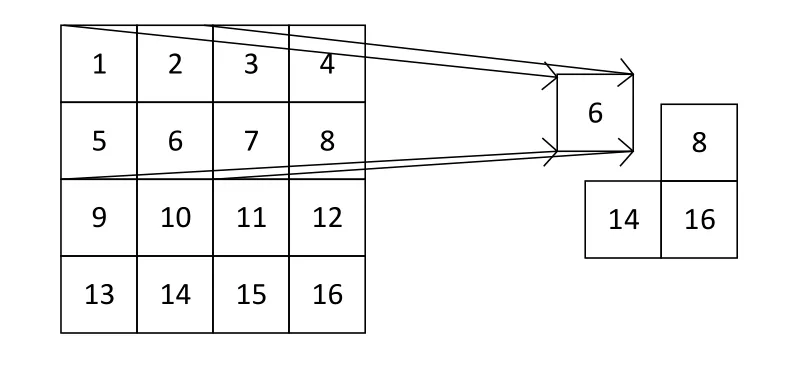
图1 最大池化窗口取值效果Fig.1 value taking effect of maximum pooling window
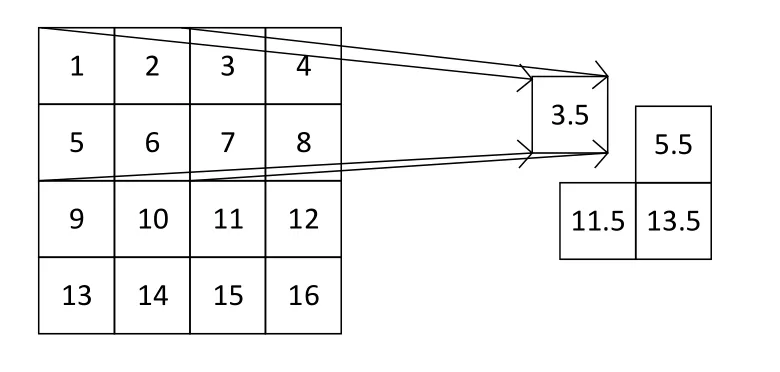
图2 平均池化窗口取值效果Fig.2 average pooling window value effect
除了最常用的最大与平均池化,许多新的池化方法也被提出,Dingjun Yu等[14]提出了一种称为混合池的特征池化方法来对卷积神经网络进行正则化,用最大和平均池化的随机选择过程代替了确定性池化操作,并有效降低了过拟合,经测试该方法优于单独使用最大或平均池化。Caglar Gulcehre等[15]提出了Lp范数[16]池化,通过训练参数P将Lp范数变的可训练,参数P由取值1的平均池化到取值∞的最大池化,实验证明有助于提高模型准确率。ChenYu Lee等[17]通过树形结构合并最大和平均池化,结合之后得到的新的池化层是可训练的,并易于实现,通过实验证明树形合并操作提高了模型的准确率,并适用于不同的模型。Lin Min等[18]提出了一种全局平均池(Gap),全局平均池将输出特征平均化,然后将特征传给分类器,与传统的全连接层相比,可以减少过拟合,在CIFAR-10和CIFAR-100数据集上验证了模型可行性。Faraz Saeedan等[19]提出了一种保留特征细节的自适应池化,可放大空间变化保留结构细节,细节保留池化可随网络训练,实验证明在不同网络模型上占有优势。Kobayashi Takumi[20]提出了根据输入特征自适应调整池化功能的池化方法,无需手动调整,将池化的合并方式以参数化的形式导出,通过输入特征图中的全局统计信息来估计参数,以实现池化的灵活组合,实验证明在多种模型中有效。Weitao Wan等[21]提出了一种用于语义感知特征池的基于熵的特征加权方法,该方法可轻松集成到各种CNN体系结构中进行训练,核心思想是使用信息熵来量化网络对其类预测的不确定性,并以此估计特征向量在特征图中空间位置处的重要性,将网络的注意力集中在语义上重要的图像区域上,从而改善了大规模分类和弱监督语义分割任务。在许多网络模型中,由于网络层参数结构的原因,需要将输入图像强制缩放成固定大小的尺寸,He Kaiming等[22]提出了空间金字塔池化(SPP),是一种自适应的池化操作,该方法对输入尺寸没有要求,采用不同的池化窗口进行池化,将得到的结果合并产生固定大小的输出,解决了网络要求输入固定大小的图像的问题。
2 变异系数指导的池化选择
池化操作除了有消除冗余信息降低特征图维数的作用,还有对特征图中的特征信息进行选择性保留的作用。最大和平均池化都对特征图进行了下采样,但最大池化在一定程度上对特征做出了选择,将分类识别度更高的特征提取出来,更多的保留了图像的纹理信息,也起到了非线性作用,因纹理特征的重要性最大池化的可选择性更大;平均池化更善于对图像的整体特征信息进行下采样,更有利于信息的完整传递,其贡献度主要集中在减少特征图维度上。池化操作在卷积神经网络的设计中必不可少。
池化操作特征提取的误差主要来自滑动窗口大小受限造成的估计值方差增大和卷积层参数误差造成估计均值的偏移,平均池化能减小滑动窗口大小受限造成的估计值方差增大带来的误差,更多的保留图像的背景信息,最大池化能减小卷积层参数误差造成估计均值的偏移带来的误差,更多的保留纹理信息[23]。
本文在进行最大池化和平均池化的选择时,采用了变异系数作为指导选择参数,变异系数又称标准离差率,是衡量数据值离散程度的一个统计量,适用于数据值测量尺度相差太大的情况。
变异系数cv为标准差与平均值之比,公式如下:

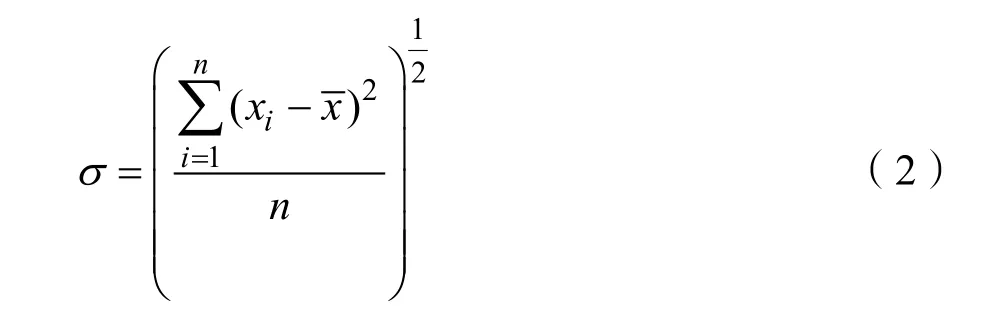
数学中的梯度以向量表示,函数 f( x, y)在点(x, y)处的梯度记作 ∇ f ( x, y)。梯度的计算公式如下。
梯度向量:

梯度的值:
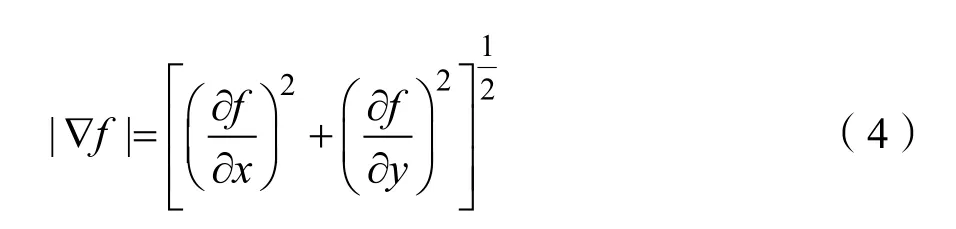
梯度的方向角:

图像的梯度值代表了图像像素值的变化量,梯度值的大小代表了像素值的差异性,而图像的特征边缘往往梯度值变化明显,蔬菜叶片病虫害图像的健康区域和病害区域差异明显,如西红柿早疫病,会使叶片枯黄,与健康叶片的绿色差异明显。通过统计梯度值的分布情况可以在一定程度上分析图像特征的离散程度,计算图像梯度值的标准差、均值和变异系数,分析标准差和均值的对比,若比值大于1则表明图像的方差标准差的比重更大,需要采用平均池化来降低误差,若比值小于1则表明图像均值的比重更大,需要采用最大池化来降低误差。
算法描述如下:
输入:待处理的图像数据集
输出:根据变异系数划分完成的数据集
Step.1读取数据集中的一张图像,进行如下处理:
(1)将图像矩阵中的像素值以二维数组的方式读取
(2)调用函数计算图像梯度值并保存为二维数组
(4)调用函数计算图像梯度值的标准差σ
(6)if(cv≤1)
将图片划分到最大池化数据集
else
将图片划分到平均池化数据集
Step.2读取待处理数据集中的下一张图像,返回步骤(1),直至全部图像处理完毕。
Step.3得到根据变异系数划分完成的数据集
Step.4将划分好的数据集放到卷积神经网络中进行训练
3 实验
在本节介绍实验所用数据集,网络模型的搭建,实验环境的参数和实验结果及分析。
3.1 实验环境
本文实验设备为笔记本电脑,电脑操作系统为64位windows 10系统;CPU处理器为十代i7八核高性能处理器2.30 GHz;运行内存为16 GB海力士DDR4 3200 MH z;显卡为 GeForce R TX 2060显卡内存为6 GB,支持GPU加速;编译语言为Python 3.8.5;深度学习框架为Pytorch 1.6.0。
3.2 数据集构建
本文采用 PlantVillage大型植物病害图像数据集,选取其中六种植物十种病害作为实验数据集,分别为健康蓝莓叶片、健康樱桃叶片、樱桃白粉病、橘子绿病、桃核菌斑病、健康桃叶片、马铃薯早疫病、健康马铃薯叶片、马铃薯晚疫病、健康大豆叶片,共18 814张图片,分为训练集13 170张图片和测试集 5 644张图片,分别占比 70%和30%,六种植物病害图像样本示例如图3所示。

图3 六种植物病害图像样本示例Fig.3 image samples of six plant diseases
通过变异系数算法根据图像池化选择划分原数据集为两个数据集,划分后的数据集包括最大和平均池化两部分,数据集划分前后分支结构分别如图4所示,划分后如图5所示。
图4 划分前数据集结构Fig.4 dataset structure before partition
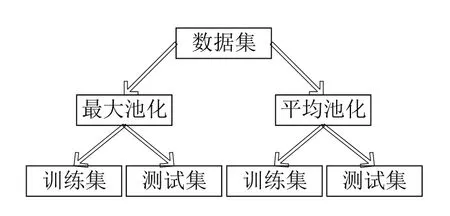
图5 划分后数据集结构Fig.5 pataset structure after partition
3.3 卷积神经网络模型搭建
网络模型的搭建和训练测试均在 Pytorch 1.6.0框架下实现,Pytorch由Facebook公司基于Torch库开发的基于Python的库,支持动态神经网络,设置网络结构简单直观灵活,支持GPU加速的张量计算,框架简洁快速高效有利于研究人员快速搭建出模型。本文采用Python语言来构建和训练网络,分别搭建AlexNet和VGG16网络,AlexNet网络结构和每层参数数量如图 6所示,卷积层和全连接层参数依次为34 944、614 656、885 120、1 327 488、884 992和 37 752 832、16 781 312、4 090 700,总参数为62 378 344。参数统计如表1所示。

表1 AlexNet每层参数统计Tab.1 parameter statistics of each layer of AlexNet

图6 AlexNet分层结构Fig.6 AlexNet hierarchy
VGG16网络层级构和特征图大小如图 7所示,池化层无训练参数,卷积层和全连接层参数依次为 1 792、36 928、73 856、147 584、295 168、590 080、590 080、1 180 160、2 359 808、2 359 808、2 359 808、2 359 808、2 359 808、102 764 544、16 781 312、86 037,总计134 346 581。参数统计如表2所示。

表2 VGG16每层参数统计Tab.2 parameter statistics of each layer of VGG16
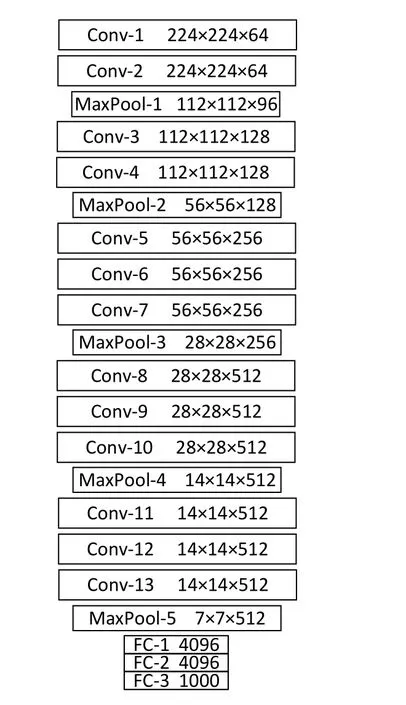
图7 VGG16模型参数结构Fig.7 parameter structure of VGG16 model
3.4 实验和结果分析
首先 AlexNet模型使用未划分数据集训练,分别采用最大和平均池化分两次进行了训练,训练过程中的loss值统计绘图如图8所示,准确率统计绘图如图9所示。图8中lossAA曲线(虚线)为 AlexNet以平均池化训练未划分数据集的 loss值,lossAM曲线为AlexNet以最大池化训练未划分数据集的loss值,通过对比可以发现用最大池化来训练loss值的时候loss值更低,网络更稳定。图9中accAA曲线(虚线)为AlexNet以平均池化训练未划分数据集的准确率,accAM 曲线为AlexNet以最大池化训练未划分数据集的准确率,二者基本持平,采用最大池化训练准确率更高。
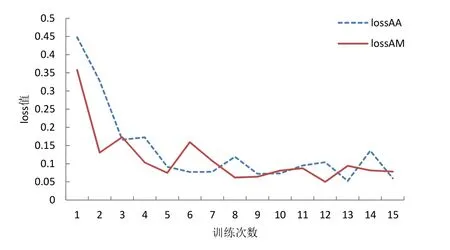
图8 AlexNet训练未划分数据集loss值对比Fig.8 comparison of loss values in AlexNet training undivided dataset
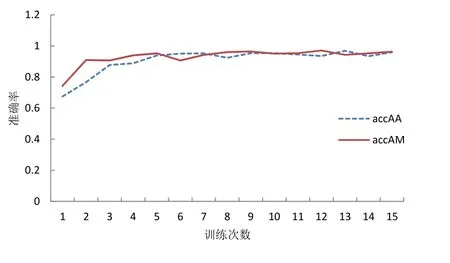
图9 AlexNet训练未划分数据集准确率对比Fig.9 comparison of accuracy of AlexNet training undivided datasets
然后用 AlexNet网络训练划分好的数据集,先用使用最大池化的网络训练最大池化部分数据集,切换为平均池化网络再行训练平均池化部分,训练过程中loss值统计绘图如图10所示,准确率统计绘图如图11所示。从图10中可以看出loss值很低,在 0.1以下,说明网络比较稳定,从图11 中可以看出准确率很高而且很稳定,在 95%以上。AlexNet实验过程中的准确率统计如表 3所示,其中平均准确率为后10次平均准确率,可以看出 AlexNet先划分数据集再进行训练的平均准确率最高,各自最高准确率基本持平,相差不超过 0.42%,说明通过变异系数对数据集的池化选择在AlexNet中有效。
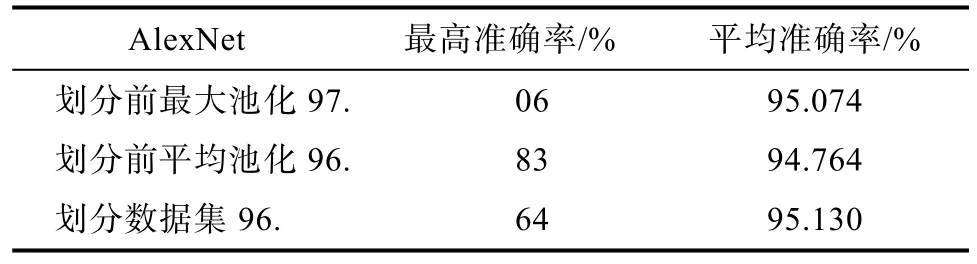
表3 AlexNet准确率统计Tab.3 AlexNet accuracy statistics
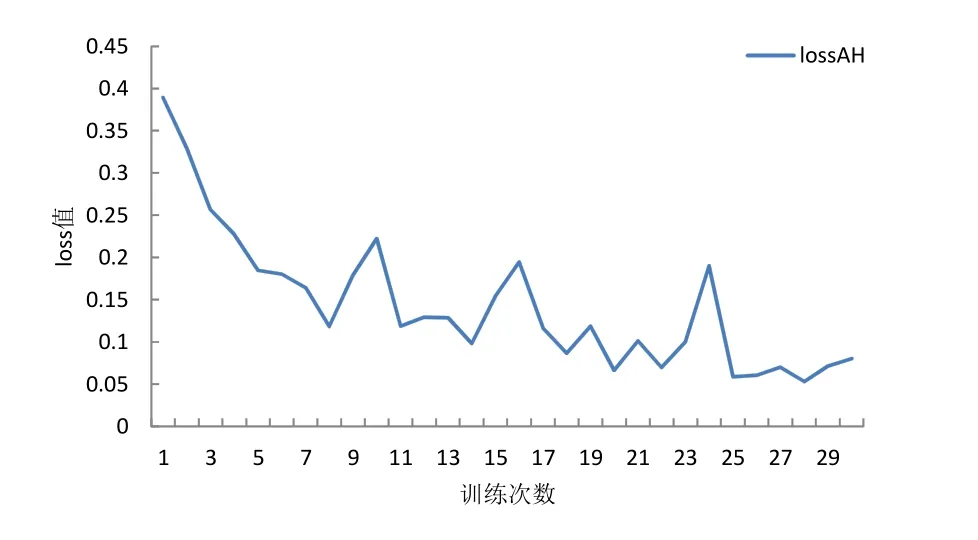
图10 AlexNet训练划分好的数据集loss值Fig.10 loss value of dataset divided by AlexNet training
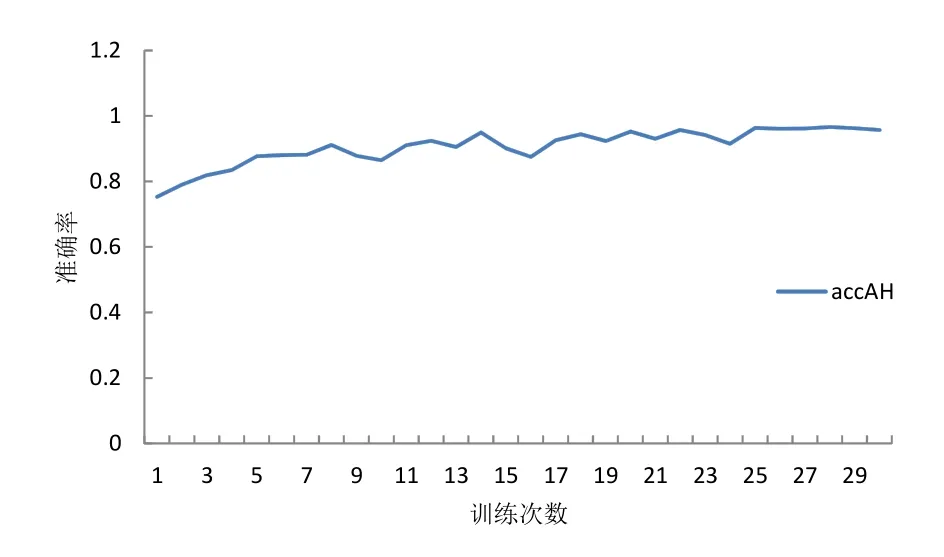
图11 AlexNet训练划分好的数据集准确率Fig.11 accuracy rate of dataset divided by AlexNet training
使用VGG16模型使用未划分数据集训练,先用使用最大池化的网络训练最大池化部分数据集,切换为平均池化网络再行训练平均池化部分,训练结束后loss值的统计绘图如图12所示,准确率的统计绘图对比如图13所示。图12中lossVA曲线(虚线)为 VGG16以平均池化训练未划分数据集的loss值,lossVM曲线为VGG16以最大池化训练未划分数据集的loss值,通过对比可以发现用最大池化来训练 loss值的时候 loss值更低,网络更稳定。图13中accVA(虚线)曲线为VGG16以平均池化训练未划分数据集的准确率,accVM曲线为VGG16以最大池化训练未划分数据集的准确率,二者基本持平,采用平均池化训练准确率更高。

图12 VGG16训练未划分数据集loss值对比Fig.12 comparison of loss values of VGG16 training undivided dataset
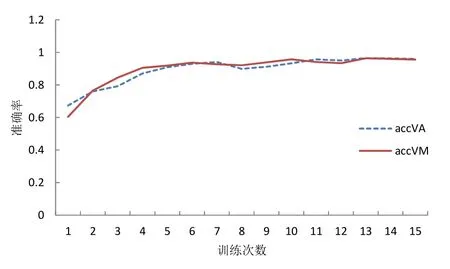
图13 VGG16训练未划分数据集准确率对比Fig.13 accuracy comparison of VGG16 training datasets
然后用VGG16网络训练划分好的数据集,先训练最大池化部分数据集再行训练平均池化部分,其训练loss值统计绘图如图14所示,准确率统计绘图如图15所示。从图14中可以看出loss值很低并趋于平稳,在 0.1以下,说明网络比较稳定,从图 15 中可以看出准确率很高而且很稳定,在95%以上。VGG16实验过程中的准确率统计如表4所示,其中平均准确率为后10次平均准确率,可以看出 VGG16先划分数据集再进行训练的平均准确率最高,各自最高准确率基本持平,相差不超过 0.14%,说明通过变异系数对数据集的池化选择在VGG16中有效。

表4 VGG16准确率统计Tab.4 accuracy statistics of VGG16
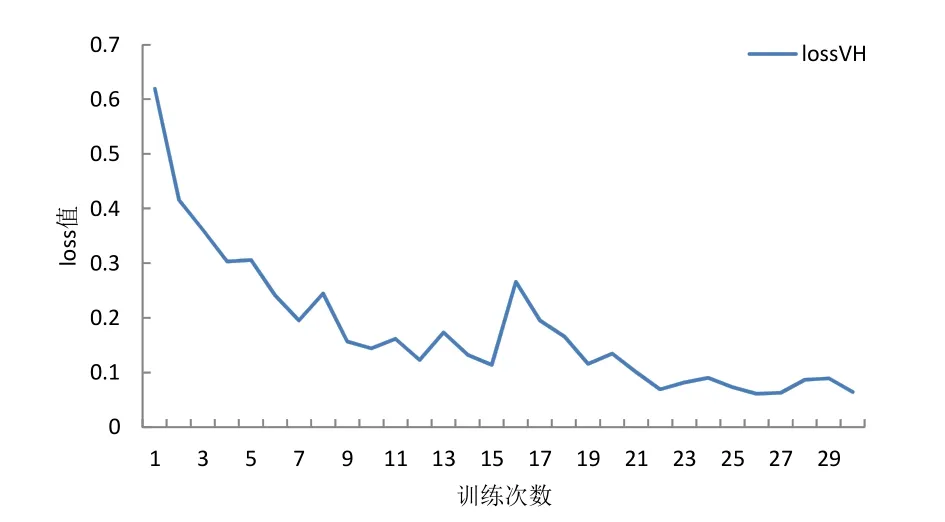
图14 VGG16 训练划分好的数据集loss值Fig.14 loss value of VGG16 training divided dataset
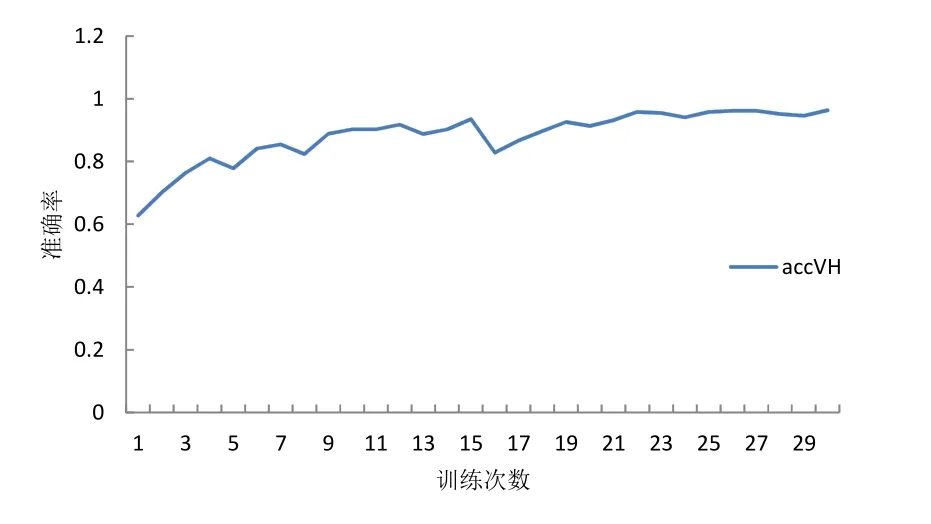
图15 VGG16训练划分好的数据集准确率Fig.15 accuracy of VGG16 training dataset
4 结论
卷积神经网络在设施蔬菜病害识别中应用广泛,本章对卷积神经网络在进行病害图像识别分类的训练过程中,最大和平均池化的选择进行了研究,通过计算图像变异系数大小决定该图像适合最大还是平均池化,变异系数大于1适合使用平均池化否则使用最大池化,将图像划分为最大池化训练部分和平均池化训练部分,再由卷积神经网络训练分类。经实验验证在 AlexNet和VGG16网络中均有提升,准确率稳定在 95%以上,该方法有效。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
中国交通信息化(2018年5期)2018-08-21
