
基于深度学习的危险驾驶行为检测模型研究
2021-12-29 01:10:00岳宸宇周沛松李明亮
新一代信息技术 2021年22期
岳宸宇,周沛松,2,李明亮,2
(1. 河北地质大学信息工程学院,河北 石家庄 050031;2. 智能传感物联网技术河北省工程研究中心,河北 石家庄 050031)
0 引言
长期以来,网络及交通等基础设施逐渐完善,我国运输能力也有了飞跃的成长。然而高效便捷的交通在给人们带来生活上便利的同时,也带来了由于各种原因引起的交通事故频发的严重安全问题。据统计,全球每年因交通事故死亡的人数达到130万人,约2 000万至5 000万人受到非致命性伤害[1]。利用计算机视觉来检测驾驶员分心状态可以减少人工检查费时费力废财的弊端。通过这种方式,能够作为一种智能化的安全辅助驾驶功能,能够及时提醒驾驶员注意开车安全,让视频监控变得不再依赖人工干预,而更加智能化,有着重要的实际意义。
1 基于PaddleX的危险驾驶行为检测方法
基于 PaddleX的危险驾驶行为检测方法总体设计即为该模型训练及测试总流程,总体设计流程图如图 1所示。主要针对 Kaggle 驾驶员状态检测数据集进行下载解压,读取数据,并安装相关配置环境,模型训练及导出、评估模型性能,为方便部署将PaddleX模型转换为PaddleHub模型,最后对模型进行测试。

图1 总体设计流程图Fig.1 Overall design flow chart
其中训练模型所采用的主要是 MobileNet轻量型网络,本章主要介绍 MobileNet的提出及迭代变化,包括最新提出的MobileNetV3模型及本设计所涉及到的原理。数据中提到相对重量级网络而言,轻量级网络因其有参数少、计算量小、推理时间短的特点,从而更适用于存储空间和功耗受限的场景。
基于 PaddleX的危险驾驶行为检测模型主要采用的是谷歌于 2019年在 arxiv公开的论文“Searching for MobileNetV3”中提出的第三代MobileNet,百度在其全流程开发工具包PaddleX中嵌入MobileNetV3网络,将其应用于目标检测等领域。MobileNetV3的网络结构如图 2所示,文中提到的 Large模型和 Small模型的整体结构一致,区别即是基本单元bneck的个数以及内部参数上,主要是通道数目不同。
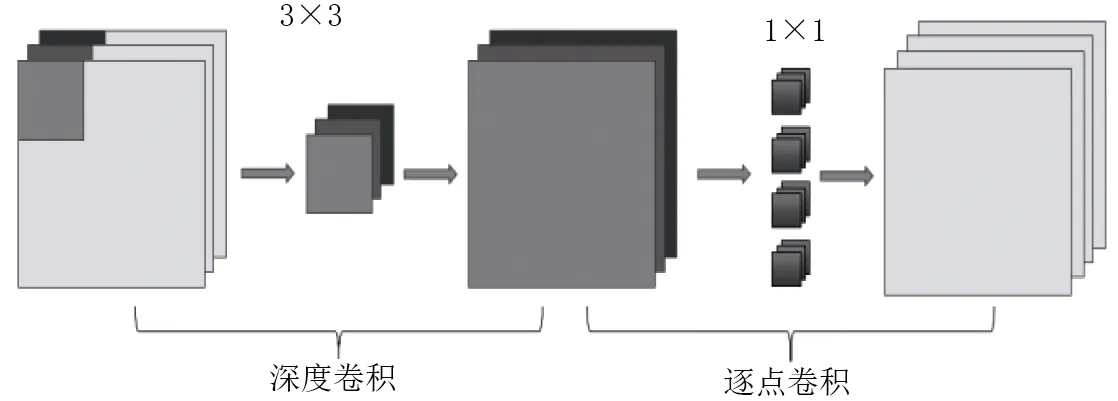
图2 通道分离卷积Fig.2 channel separation convolution
MobileNet是基于 TensorFlow框架下开发的一系列基于移动设备优化的计算机视觉模型,其设计目的是在考虑移动设备或嵌入式应用程序的受限资源的情况下有效地最大化精度。它们是小型、低功耗、参数化的模型,以满足设备的资源负担。可以为分类、检测和分割任务创建模型。宽度倍增和分辨率倍增是MobileNetV1的参数,可以调整以权衡资源精度的权衡。宽度倍增可以使网络变薄,而分辨率倍增可以改变输入图像的尺寸。这些变化可以减少每一层的内部结构参数。MobileNetV1引入了深度可分离卷积,有效替代了传统卷积层。标准卷积的特点是卷积核的通道数等于输入特征图的通道数。MobileNetV1通过从特征生成机制中分离空间滤波,可分离卷积有效地分解了传统卷积,从而减少模型所需要的参数和计算量。深度可分离卷积定义了两个独立的层:其一是用于空间滤波的轻量级depthwise(深度卷积)以及用于生成特征的 Point W ise Convolution(逐点卷积)。本质上深度卷积即是卷积核的通道数为 1;逐点卷积即是 1×1的卷积核,通道数等于输入特征图的通道数。
相比于 MobileNetV2网络,MobileNetV3网络优化了网络输出部分。移除之前的瓶颈层连接,进一步降低网络参数。可以有效降低11%的推理耗时,而性能几乎没有损失。
SE通道注意力机制,这里利用1×1卷积实现的 FC操作,本质上和 FC是一样的。这里利用hsigmoid模拟 sigmoid操作。利用 h-swish和 hsigmoid近似操作模拟swish和ReLU,公式为:
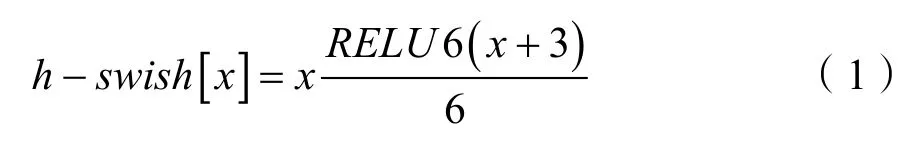
bneck模块是该网络核心模块,也是网络的基本模块。主要实现了“通道可分离卷积+SE通道注意力机制+残差连接”。
2 实验结果分析
(1)实验环境
硬件环境:CPU:4 Cores;RAM:32GB;GPU:Tesla V100;显存:32GB;磁盘:100GB;
编译环境:Jupyter Notebook;
环境配置:Python版本:python 3.7;pip版本:21.1;OpenCV2;
框架版本:PaddlePaddle 2.0.2。
(2)解压数据集
数据集解压根据环境需要修改路径,在之后的训练过程中路径必须统一,否则执行程序将会报错。
!unzip/home/aistudio/data/data35503//imgs.zip-d /home/aistudio/work/imgs
!cp/home/aistudio/data/data35503/lbls.csv/home/aistudio/work/
(3)安装PaddleX
import os
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
(4)定义数据加载器
由于分类使用ImageNet格式的数据集,用于识别任务的数据加载器的类定义使用pdx.datasets.ImageNet,其主要目的在于读取数据。
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
model.train(num_epochs=20,train_dataset=trai n_dataset,train_batch_size=32,log_interval_steps=2 0,eval_dataset=eval_dataset,lr_decay_epochs=[1],sa ve_interval_epochs=1,learning_rate=0.01,save_dir='output/mobilenetv3')
(5)实验结果
模型在Jupyter Notebook运行结果如图3所示,测试程序中分别读取十张图片对应各个标签的图片。模型测试结果在最下方分别输出,格式为:(类别ID,类别,识别成绩/准确度),测试结果显示:10张不同状态图像测试运行时间为:492 ms。
图3 激活函数损失对比Fig.3 activation function loss comparison

图4 实验运行结果Fig.4 experimental results
3 结论
本设计针对驾驶员常见危险驾驶习惯如驾驶汽车过程中看手机、打电话、进食以及同车内乘客聊天等现象,设计基于深度学习技术的危险驾驶行为检测模型。采用PaddlePaddle框架,利用Kaggle驾驶员状态检测数据集训练并测试基于PaddleX+OpenCV的深度学习网络模型;将PaddleX深度学习网络模型转化为 PaddleHub轻量型深度学习网络模型便于部署和应用;能够实现对驾驶员normal driving(正常驾驶);texting -right(右手发短信/玩手机);talking on the phone -right(右手打电话);texting - left(左手发短信/玩手机);talking on the phone - left(左手打电话);operating the radio(调试车载多媒体);drinking(进食);reaching behind(向后排拿东西);hair and makeup(整理妆容);talking to passenger(同乘客谈话)等10种驾驶行为的检测,其中有9种危险驾驶行为,并且识别准确率可达到98%以上。经测试,模型可同时进行10种状态检测,检测运行时间为492 ms,由此可推断,该模型可进行实时检测驾驶员危险驾驶状态。
根据模型表现,下一步可以将模型部署到手机端或类似于树莓派等嵌入式终端进行本地检测,同时还可以将模型进行“边缘端+云端”部署,这样可以实现更加稳定的实时检测,并且可以根据模型不断迭代实现模型检测的高效性和高鲁棒性。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:13:42
汽车实用技术(2022年4期)2022-03-07 06:07:20
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
小小艺术家(2018年1期)2018-06-05 16:55:48
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
公民与法治(2016年4期)2016-05-17 04:09:26
新少年(2015年6期)2015-06-16 10:28:21
电视技术(2014年19期)2014-03-11 15:38:20
海外英语(2013年11期)2014-02-11 03:21:02
