
基于YOLOv8 网络的棉蚜图像识别算法及软件系统设计
2023-09-10 07:12:42马盼杨子恒万虎何顺黄远徐胜勇
智能化农业装备学报(中英文) 2023年3期
马盼,杨子恒,万虎,何顺,黄远,徐胜勇*
(1. 华中农业大学工学院,湖北武汉,430070; 2. 华中农业大学深圳营养与健康研究院,深圳市,518000;3. 中国农业科学院深圳农业基因组研究所和岭南现代农业科学与技术广东省实验室深圳分中心,深圳市,518000; 4. 华中农业大学植物科学技术学院,湖北武汉,430070;5. 华中农业大学园艺林学学院,湖北武汉,430070)
0 引言
棉蚜使用刺吸式口器吸食棉花叶片或幼嫩组织中的汁液,引起棉株营养恶化,造成幼苗萎蔫、叶片萎缩畸形、枝叶枯萎或落叶枯死[1]。棉蚜还会影响叶片的呼吸作用和光合作用,导致棉花产量与品质下降[2]。因此,棉蚜的防治对于棉花生产具有重大意义。棉蚜防治的相关研究主要集中在两个方面,一方面是预测棉蚜种群变化及为害程度[3],另一方面是采用多种防治手段对棉蚜为害进行有效治理[4-6]。在棉蚜防治研究中,通常都会使用人工方式进行棉蚜种群数量的统计,有些研究还需要对棉蚜的死活进行判断。棉蚜的体形极小,一些棉蚜密度较高的试验区难以直接计数,工作量大且费时费力,急需智能化检测技术替代人工计数。
近年来,随着人工智能和计算机视觉技术的快速发展,有大量的研究将机器学习和深度学习用于害虫识别任务[7-8]。(1)传统图像处理和机器学习的害虫识别。卜俊怡等[9]采用不同的颜色空间模型分割诱虫板,用最大类间方差法确定害虫分割阈值,之后提取害虫区域的颜色、形状、纹理共计20 种特征并使用随机森林模型识别害虫并计数,对番茄常见的作物害虫识别准确率均达到了90%以上。ZHU 等[10]针对储粮昆虫,基于图像处理技术设计了一款安卓应用程序,可以实现对储粮昆虫的识别和计数。俞浩等[11]采用高光谱成像技术进行油菜角果蚜虫侵染的定位识别,使用PCA 模型对高光谱数据做降维处理,之后使用线性模型对降维后的数据分类,蚜虫识别率达到99%。HAYASHI 等[12]使用Google Cloud AutoML Vision 机器学习平台训练模型对同一宿主的3 种蚜虫进行识别,使用每个物种20、50、100、200 和400 张图像构建模型,通过图像反转增加和不增加训练数据量。当用每个物种400 张图像训练模型时,正确识别率>0.96。SHAJAHAN 等[13]针对大豆蚜虫提出了一种基于形状分析的图像处理方法,通过提取蚜虫的形状参数完成识别和计数。LIU 等[14]针对小麦蚜虫提出了一种基于有向梯度特征的直方图和支持向量机建立的蚜虫识别模型,此方法与其他5 种常用的蚜虫检测方法进行了比较,且使用不同的蚜虫密度、颜色或位置的植物上的图像,结果表明,此方法提供的平均识别率和错误率分别为86.81%和8.91%。(2)深度学习的害虫识别。王林惠等[15]设计了一套基于卷积神经网络的柑橘虫害识别系统,采用Faster R-CNN 模型识别柑橘虫害区域,实现了柑橘虫害的精确定位。CHEN 等[16]利用卷积神经网络对叶片上的蚜虫若虫进行分割和计数,试验结果表明该方法的计数准确率达到95.6%、R2达到0.99,该方法具有一定的通用性,可以应用于其他种类的害虫。董伟等[17]基于深度学习卷积神经网络对常见的5 种鳞翅目害虫进行识别和计数,达到了实际应用水平。YAN 等[18]使用高光谱相机结合机器学习方法实现了对棉花蚜虫虫害的早期检测,并将卷积神经网络与传统机器学习方法进行比较,结果表明卷积神经网络优于传统机器学习方法。CHEN 等[19]提出了一种从数字图像中识别和计数小麦螨的3 步深度学习方法,将大图像分割为小图像再进行标记和放大,然后构建了一个深度学习网络实现了小麦螨种群的精确识别,准确率达到94.6%。陈娟等[20]提出了一种基于改进残差网络的害虫图像识别方法,与3 种传统害虫识别方法相比,对38 种北方园林害虫的平均识别准确率平均提高9.6%。姚青等[21]提出了基于双线性注意力网络的农业灯诱害虫细粒度图像识别模型,试验结果表明该模型可以自动识别6 类相似的19 种农业灯诱害虫,提高了农业灯诱害虫自动识别的准确率。曾伟辉等[22]提出了一种基于SCResNeSt 的低分辨率水稻害虫图像识别方法,与现有方法对比,ESRGAN 数据增强方法可以恢复真实的作物害虫信息,识别精度达到91.20%,比原始ResNet50 网络提高3.2 个百分点,满足野外实际场景下的应用需求。
总体而言,对于害虫识别的研究被广泛开展,但对于棉蚜这种极小尺寸、极大密度且死、活和蜕皮混杂的场景,仍然需要进一步探索准确有效的识别方法。YOLO 网络因为其良好的目标检测性能,被用于昆虫的识别计数,如ZHONG 等[23]基于YOLO 算法和基于全局特征的支持向量机分类实现了对田间飞行昆虫的计数,可用于智能农业设备。但是,YOLO 模型的预训练模型主要针对COCO 数据集来训练的,因此对于高分辨率图像中的小目标检测效果较差[24]。因此,本文研究了一种基于YOLO 的棉蚜识别算法和软件,科研人员只需导入手机拍摄的棉蚜图片,即可准确地检测图片中的棉蚜死蚜虫和活蚜虫的数量,并将计数结果保存在Excel 表格中,方便科研人员使用。其中,将原始大图像裁剪为多幅子图像再进行训练集制作和目标检测,有效提升YOLO 模型检测小目标的效果。该技术可以将棉蚜防治相关科研人员从繁重的计数工作中解脱出来,也可以为无人农场等生产场景中的精准喷施作业提供关键作业信息。
1 材料和方法
2023 年2—3 月,在华中农业大学培育了棉蚜样本。栽种了24 株水培棉花苗,置于26 ℃恒温条件下24 h 光照培养并定期浇水,直到长成棉花幼苗。使用棉花幼苗繁殖棉蚜,用刷子将幼苗上的棉蚜刷至皿中,将每份棉蚜接种于每株棉花苗上,一株50 头。为了采集死棉蚜图片选取12 株接种后的棉花苗,做好标记,使用配置好的药剂均匀喷施在叶片表面,并做隔离培养。
2023 年3 月21 日—4 月5 日采集图像,每天定时采集一次,使用OPPO OnePlus Ace 手机拍摄棉花叶面的棉蚜图像,手持手机垂直对准棉花植株的冠层,距离约10 cm,日光灯光照环境。共采集到分辨率3 072 像素×4 096 像素的图像327 张。
2 基于YOLO 网络的蚜虫图像识别模型
2.1 棉蚜图像数据集制作
从拍摄的棉蚜图像中挑选虫害分布密度有差异且清晰的60 张图像用于算法训练,另随机选择了50张图像用于算法测试。手机拍摄的棉蚜图像分辨率远超过YOLO 模型的常规分辨率要求(640 像素×640像素)。为了提升高分辨率图像中的小目标检测精度,将手机拍摄的高分辨率图像裁剪为6 张子图像,再进行后续处理。同时,xml 标注文件也被裁剪为6 份文件,分别对应6 张子图像的标注信息。裁剪过程如图1所示。

图1 棉蚜图像的裁剪Figure 1 Image cutting for the cotton aphid images
使用LabelImg 软件对60 张训练图像手动标注。标注方式为矩形框,活棉蚜标记为“alive”,死棉蚜标记为“dead”,标注完成后生成一个与图像同名的xml 文件,包含了标注信息。60 张训练图像经过裁剪和处理,获得357 张棉蚜图片和对应的标注文件。
2.2 棉蚜识别模型
YOLO 模型是用于目标检测的神经网络,不仅可以预测对象的类别还可以检测对象的位置,相比以往的带有建议框的神经网络,速度大幅提升[25]。本文用于训练的模型包括YOLOv5 系列模型(YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x) 和YOLOv8 系列模型(YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l、YOLOv8x)。YOLOv5 模型是一款基于Acchor-Based 的目标检测模型,而YOLOv8 模型由Glenn Jocher 于2023 年发布,是一款基于YOLOv5 改进的模型[26]。模型具体参数如表1 所示。
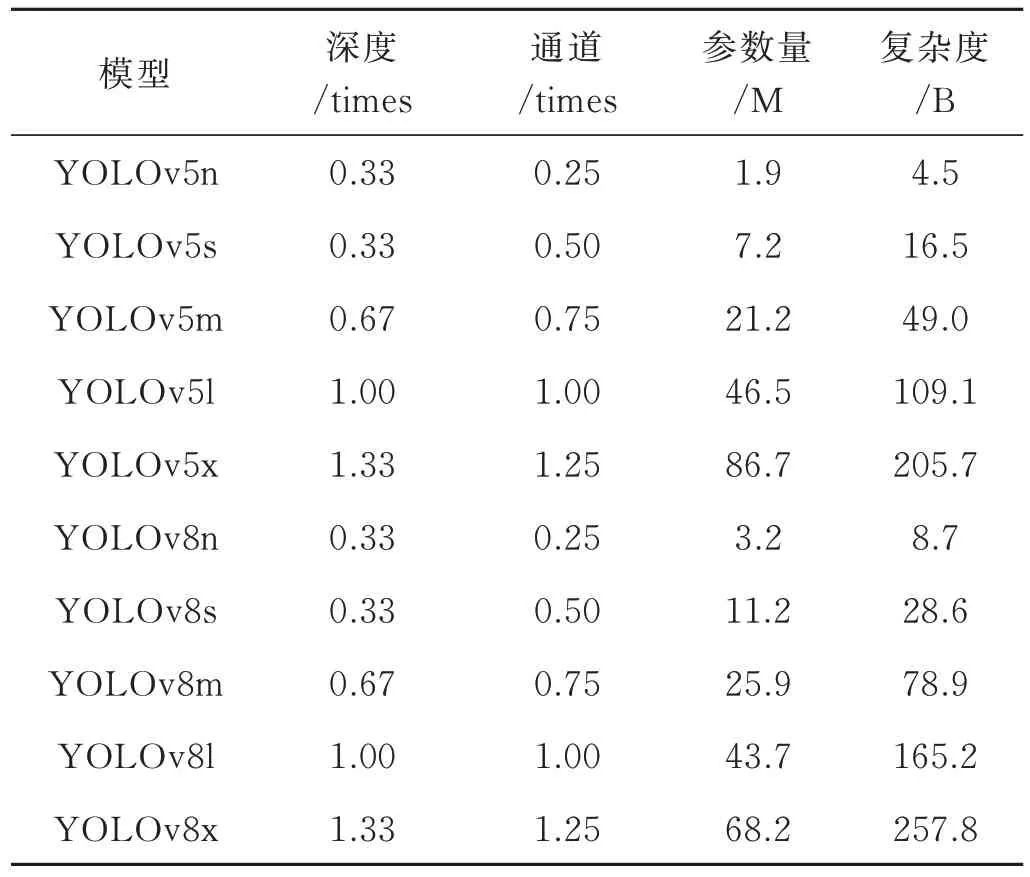
表1 模型参数Table 1 Model parameters
n(nano)、s(small)、m(medium)、l(large)、x(extra large)代表了不同大小的模型型号,模型深度与通道数均不同,因此不同型号模型的参数量和复杂度存在差异。在数据集数量充足且类别样本均衡的情况下,模型参数量越大,学习到的特征越多,模型性能越好,但数据集较小时,参数量的增大会增加过拟合风险,导致模型性能下降。
2.3 数据集划分与模型评价指标
数据集按一定比例划分为训练集(train)、测试集(validation)、验证集(test)。按照训练集:验证集:测试集=8:1:1 的方式进行随机划分,获得285 张训练集、36 张验证集、36 张测试集。使用训练好的模型对测试集进行预测,预测结果为预测框的坐标与置信度,预测框表示预测对象的位置,置信度是预测对象是某个类别的概率,范围0~1,置信度越大则概率越大。设计合理的指标评价预测框与置信度的精度是模型评价的关键。主要的模型评价指标有4 个:精度(Precision,P),召回率(Recall,R),mAP50,mAP50-95[27]。
2.4 模型参数设置与训练
模型训练采用迁移学习方法,使用在COCO 数据集预训练的权重作为训练的初始权重。使用AutoML平台租赁服务器进行深度学习训练。训练的超参数设置如下:迭代次数100 轮,批次大小32(其中x 模型为16),初始学习率0.01,周期学习率0.01。超参数设置通过控制台命令行实现。输入训练命令后模型开始训练,首先加载模型,加载完成后程序使用数据集对模型进行迭代训练,一段时间后100 轮迭代完成,模型训练结束,程序将模型保存于指定路径下。对YOLOv5 与YOLOv8 不同型号的10 种模型做上述操作,得到训练完成的模型。
2.5 YOLO 模型检测结果
使用2.3 节中的评价指标,10 种YOLO 模型的检测结果如表2 所示。可以看出YOLOv8l 在mAP50 指标表现最好,YOLOv8x 在mAP50-95 指标表现最好,且两种模型在两个指标上差异极小,因此认为YOLOv8l 与YOLOv8x 为最佳的棉蚜检测模型。
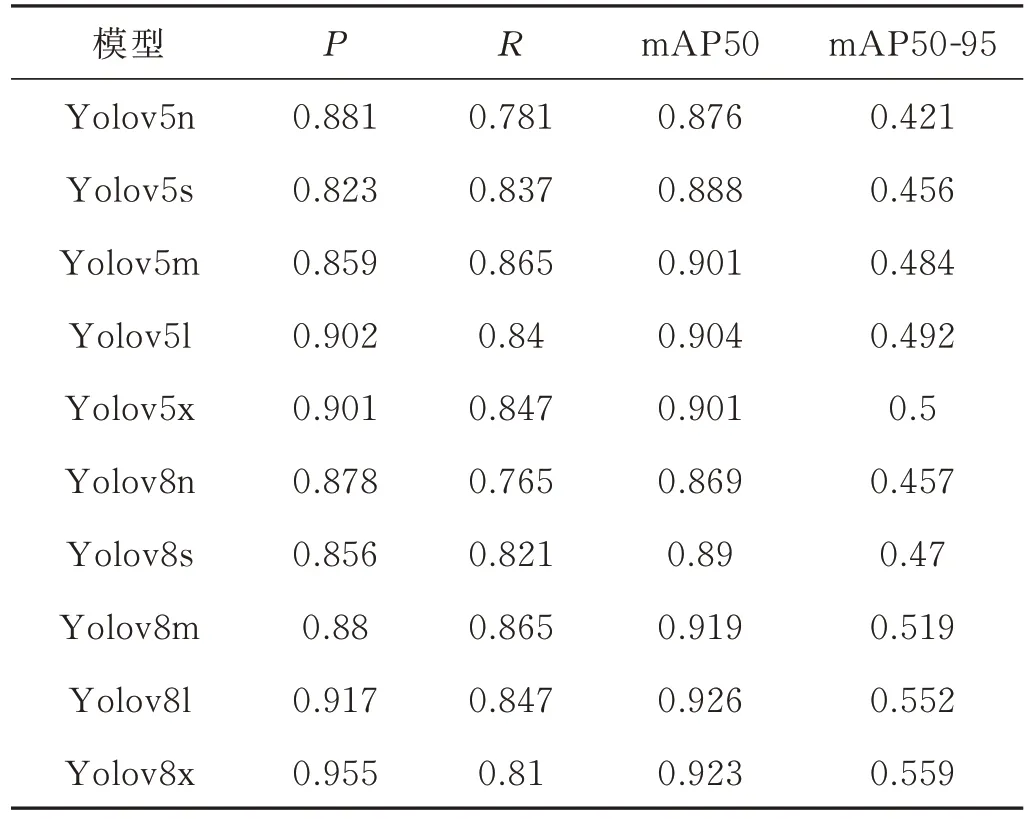
表2 评价指标量化结果Table 1 Quantitative results of evaluation indicators using the models
YOLOv8l 的检测结果如图2 所示,给出了棉蚜不同繁殖期的3 组图片。图2(a)是在棉蚜密度较小的叶片上两个不同时期的检测结果,图2(b)是在棉蚜密度较大的叶片上两个不同时期的检测结果,图2(c)是在蜕皮、叶片交叉等干扰因素较多且棉蚜密度较大时的检测结果。

图2 使用YOLOv8l 的检测结果Figure 2 Detection results with YOLOv8l model
从试验结果可以观察到,随着棉蚜的繁殖,棉蚜密度越来越大、蜕皮等干扰越来越多,YOLOv81 的检测效果稳定可靠。考虑到YOLOv8l 模型复杂度更小,预测速度更快,后续采用了该模型进行软件开发。
3 棉蚜计数软件开发
3.1 软件前端开发
软件前端(用户界面)使用python 语言结合pyQT5 模块开发。在界面中用户可以设定待检测棉蚜图片的文件夹路径和检测结果保存文件夹路径,开始检测后软件实时显示检测进度,完成检测后用户能够查看不同图片的棉蚜数量,计数结果可以导出为Excel表格。如图3(a)所示软件界面,图3(b)为保存检测结果的Excel 表格。
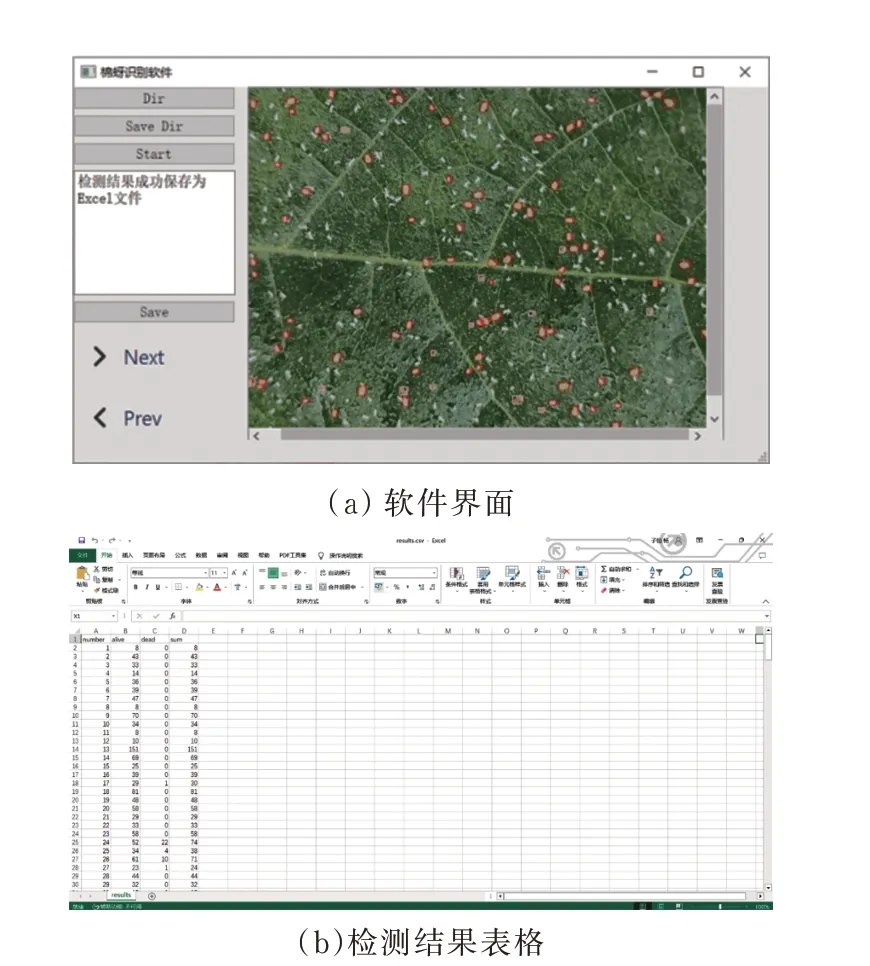
图3 人机软件与检测结果Figure 3 Interface of the detection software and the excel document of detection results
3.2 软件后端开发
软件后端使用python 语言开发。软件设计流程图如图4 所示。后端从前端的输入中获取待检测棉蚜图片的文件夹路径和检测结果保存路径,从图片路径读取待检测的图片,采取“拆分—检测—合并”的方法对图片依次进行检测,在检测基础上进行计数,并将计数结果以Excel 表格的形式保存在保存路径中。后端首先借助os 库从前端输入的图片路径中读取待检测的图片,之后依次对图片做以下处理。
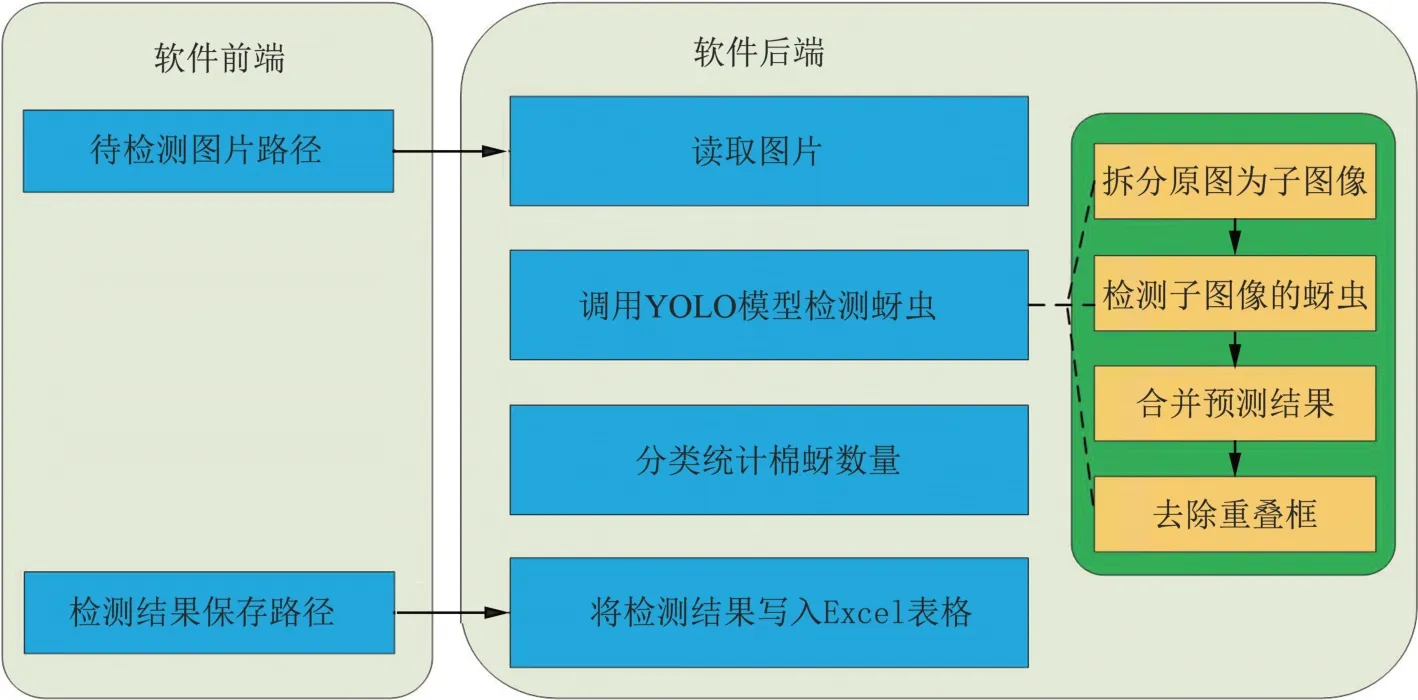
图4 软件设计流程图Figure 4 Flowchart of the software design
1)拆分原图为子图像。
将3 072 像素×4 096 像素大小的原图按照2 行3列拆分为6 张子图像,相邻的子图像间有300 像素宽的重叠,这是为了确保相邻子图像间的棉蚜不会被子图像间的分界线切割。拆分后的子图像大小为1 686 像素×1 566 像素。
2)将子图像输入模型中获得预测结果。
这里的模型是指2.4 节中使用棉蚜数据集训练的YOLOv8l 模型。借助YOLOv8 配套的Ultralytics 框架将6 张子图像输入该模型,获得输出的预测框坐标与类别。
3)预测结果合并。
首先将子图像坐标下的预测框坐标转化为原图坐标,再将6 张子图像的预测框与类别合并。
4)使用NMS 算法去除重叠框。
NMS(non-maximum suppression,非极大值抑制)算法,以预测框的置信度排序作为处理顺序,通过判断两个框之间的IoU 大小确定是否保留置信度较小的预测框。该算法能够有效去除部分重叠的预测框。由于相邻子图像间有300 像素宽的重叠部分,重叠部分会因为相邻子图像的重复检测而产生重叠框。NMS 算法可以有效消除这些重叠框,确保检测精度。
3.3 软件功能测试
使用平均绝对误差(MAE)、均方根误差(RMSE)和平均精度(Accuracy)作为评估软件计数能力的指标。
式中:N——待检测棉蚜图片的数量;
ti——第i张图片中棉蚜的真实数目(通过人工计数得到);
ci——使用软件预测的第i张图片棉蚜数目。
MAE和Accuracy衡量了棉蚜识别的准确性,RMSE衡量了识别的鲁棒性。MAE与RMSE越低,识别性能越优异,Accuracy越高识别性能越优异。Accuracy指标的范围为0~1,但由于|ti-ci|可能大于ti,导致Accuracy计算结果为负数,因此规定,若Accuracy结果为负数,令Accuracy=0。当ti=0 时,如果ci=0,Accuracy=1,否则Accuracy=0。
从267 张棉蚜图片中随机选择50 张用于软件测试。首先使用软件获取50 张图片的检测结果与软件计数结果,之后在检测结果的基础上进行人工计数,最后将软件计数结果与人工计数结果进行比较。针对活棉蚜、死棉蚜和总数分别计算MAE、RMSE、Accuracy3 种指标。测试结果如表3 所示。
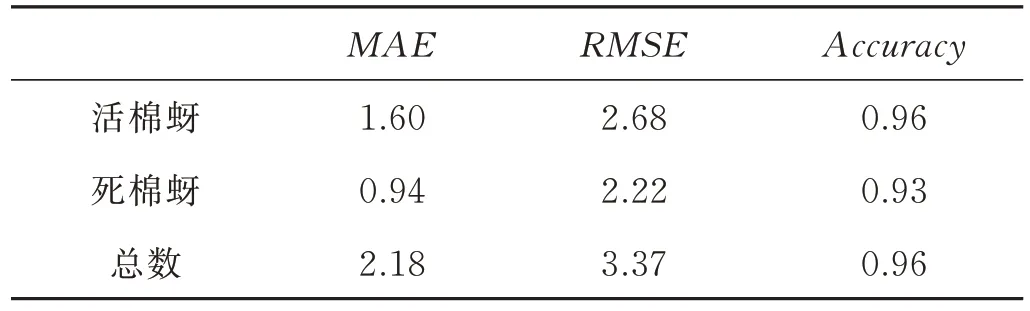
表3 软件测试结果Table 3 Testing results with the software
检测软件展现出良好的性能。50 张棉蚜图片检测总用时206 s,平均每张图片用时4.1 s,速度远超人工计数。活棉蚜与死棉蚜的计数精度(Accuracy)均超过0.93。
4 讨论
从3.3 节的测试结果看,软件对活棉蚜与死棉蚜的平均检测精度已经达到0.945,但仍然有提升的空间。MAE能够反映软件检测出的棉蚜数量与真实值的平均误差,结果表明测试图像中活棉蚜与死棉蚜平均存在1~2 个计数误差。以下是误差产生的原因。
1)棉蚜体积过小导致检测失败。
在3.3 节人工计数的过程中发现,一些体积过小的棉蚜(像素小于20×20)一般难以被检测出来。尽管针对棉蚜体积较小的问题,本文提出了将原图拆成6(2×3)张子图像进行检测,如果想进一步提升精度,拆分的子图像越多则精度越高。但拆分图像过多会导致单张图片的运算时间延长,不仅是输入模型预测的时间会延长,对预测结果进行拼接、使用NMS 算法消除重叠框的时间也会延长。试验结果表明,拆分为12(3×4)张子图像检测的时间超过10 s,检测精度基本不变。因此,在本文图像分辨率下,没有必要进一步提高裁剪数量。
2)数据集的样本不平衡。
当图像中死棉蚜的数量达到40 以上时(此时死棉蚜较为密集,检测难度增大),软件计数的精度大约只有70%~80%。由于数据集中活棉蚜与死棉蚜的数量比大约为6:1,样本数量不平衡,导致训练出的模型死棉蚜的识别能力不及活棉蚜。由于棉蚜图像标注代价高昂,应开发一种合理的数据增强(data augmentation)算法解决该问题。本文模型训练仅使用了YOLO 模型自带的Mosaic 算法进行数据增强,没有进行人工数据增强。因此,有必要对数据集进行旋转、缩放、添加噪声,使增强后的数据集中活棉蚜与死棉蚜的比例趋近于1:1,可以有效提升检测的鲁棒性。
5 结论与展望
针对棉蚜防治科研实验中的棉蚜人工计数困难的问题,研究了一种深度学习识别网络并集成为软件。针对YOLO 网络不适应于高分辨率图像中的小目标检测需求,对原图像进行裁剪再训练并将检测结果拼接,有效提升了检测精度。测试了YOLO 系列网络,最终测试结果表明YOLOv8l 在mAP50 和mAP50-95指标上取得了0.926、0.552 的分数,综合性能在所有模型中表现最佳。基于PYQT5 模块开发了软件前端,实现了对棉蚜图片的读取、检测、结果可视化、导出为Excel 表格等操作。基于python 语言开发软件后端,能够在获取前端输入信息后对棉蚜图像进行“拆分—检测—合并”操作,并统计棉蚜数量。软件经过随机图片测试,平均精度达到0.945,能够胜任棉蚜计数任务。可以继续面向大田的、多种昆虫混杂的棉蚜图像对算法进行优化,将算法部署到手机或者云端并开发App实现移动式检测,以提升技术的实用价值。
猜你喜欢
植物保护(2023年1期)2023-02-03 10:22:08
农药学学报(2022年6期)2022-12-27 12:00:28
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
好孩子画报(2021年9期)2021-09-26 12:26:31
今日农业(2020年23期)2020-12-15 03:48:26
中等数学(2020年8期)2020-11-26 08:05:58
新疆农业科学(2020年11期)2020-10-27 09:05:32
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
现代园艺(2017年21期)2018-01-03 06:42:15
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
