
匹配代价融合与分层迭代优化的半全局立体匹配
2023-09-06 04:30田家旺
小型微型计算机系统 2023年9期
陶 洋,田家旺
(重庆邮电大学 通信与信息工程学院,重庆 400065)
1 引 言
立体匹配算法是双目视觉从二维走向三维的重要途径,是双目立体视觉中核心步骤之一.立体匹配的目标是从左右视点采集到的图像中找到对应的同名点,从而求得左右视角中同名点之间的视差.结合双目测量的基础理论,可以进一步完成基于双目视觉的测量任务,例如测距、定位和三维重建等.按照匹配算法的输出结果,立体匹配可以分为稠密匹配和稀疏匹配两种.稠密匹配算法为图像中所有像素点完成匹配.而稀疏匹配算法则是只匹配提取出的部分特征点.相对来说,稠密匹配算法获得的视差信息更为丰富.稠密立体匹配算法可以分为基于深度学习、局部、全局、半全局4种类别.随着深度学习的发展,基于深度学习的立体匹配算法近年来逐渐增多,能够取得较高的视差图精度.MC-CNN[1]是基于深度学习立体匹配算法的开山之作,作者通过一个5层的卷积网络学习初始匹配代价,然后使用半全局立体匹配完成后续计算,取得了当时的最佳性能.全局立体匹配都基于如图割[2]、动态规划[3]等算法,都引入图像的全局信息,通过最小化全局能量函数求取视差图,效果较好,但与前者相同,计算量巨大,实时效果较差,难以在边缘CPU设备上部署.基于局部信息的匹配算法以像素所在的局部窗口信息作为相似性测度依据,这类方法中窗口尺寸和形状均会影响匹配效果,匹配效果较差.半全局匹配算法(Semi-Global Matching,SGM)[4]综合了全局和半全局的优点,在尽可能保留算法精度的同时大大减少了计算复杂度,在工程上得到较多的应用.
在半全局立体匹配算法匹配精度的研究方面,Zabih R[5]提出的Census变换被广泛应用于匹配代价计算,该方法结构简单,但对局部窗口中心像素的依赖较强,对噪声敏感.王阳萍[6]等人使用加速鲁棒特征(Speed Up Robust Features,SURF)检测遥感立体像对中潜在的匹配点,用来修改不同聚合方向上的路径权重,提高了在弱纹理与视差不连续区域的匹配精度,但增加SURF步骤的同时,也带来了新的计算负担.黄彬[7]等人在Census变换阶段引入权重,准确选择中心点的参考像素值,并且使用多尺度聚合策略,将引导滤波作为代价聚合核函数,匹配精度有所提高,但算法复杂度大幅增加,不利于并行实现.Zhao C[8]等用Census窗口周围像素代替中心像素进行变换,使其更加鲁棒,得到了不错的视差效果.但实际场景中的光照等因素更为复杂,基于Census变换的代价计算方式仍需改进.
在半全局立体匹配算法的效率研究方面,Hermann S[9]提出了分层迭代的半全局立体匹配算法,有了较大的速度提升.Rothermel M[10]等人与Hermann S的策略类似,并且使用先前的视差推导当前每个像素的动态视差搜索范围,进一步提高了匹配效率,但在CPU平台上的运行效率仍然很低,匹配一帧需要8秒.Li Y[11]在分层迭代算法基础上结合多线程及原生128位指令集解决摄影测量影像的立体匹配效率问题,但移植性较差,原因在于每种平台的指令集有所差别.Shrivastava S[12]扩展了传统SGM的流水线架构,通过松弛依赖约束以并行方式处理多个像素,提高了算法效率,但精度损失严重.Lu Z[13]等使用下采样及视差跳跃的策略,并且在聚合时对水平路径加权,但算法引入了一个新的路径权重参数,增加了代价聚合的计算量.
综上所述,现阶段的半全局立体匹配算法在精度和效率方面均有较大进步,但并未将精度和效率进行很好的权衡,在边缘CPU平台上,需要高精度的同时,也需要高效的计算,尤其是在大尺寸图像和大视差搜索范围情况下.因此,本文提出一种基于改进匹配代价和分层策略的半全局立体匹配.该算法将朴素Census变换与中心对称Census变换结合,共同构成变换序列,将AD代价与两序列的汉明距离融合作为初始的匹配代价.减少对中心像素依赖的同时扩充了代价的区间,增加了代价的区分能力,可以在一定程度上提高算法在户外场景中的匹配精度.其次,算法采用分层迭代的思想进行匹配,通过上层低分辨率图像的匹配结果限制当前层高分辨率图像中像素的视差搜索范围,使得其搜索范围不至于过大从而减少大量的无效计算,既可提高精度,也可提高效率.最后使用OpenCV中提供的统一指令集以及多核并行的方式实现算法计算加速,从而进一步实现硬件资源的高效利用,提高立体匹配的计算效率.
2 算法描述
本算法的流程如图1所示,输入为极线校正后的双目立体图像对,算法根据输入的原始图像尺寸,自动确定金字塔的层数N,用于指导后续分层迭代,并且初始化第1层的视差搜索范围,然后进入到分层迭代步骤.在每一层的匹配中,首先在预处理阶段,对原始输入图像进行下采样,得到当前层待匹配的左右图像.在代价计算阶段,使用融合的Census变换结合AD变换作为初始代价,采用4路径代价聚合优化视差值,视差计算采用WTA算法选择视差空间中目标像素的最小匹配代价值所对应的视差值,对图像中全部像素点进行上述计算后,得到粗略的视差图.通过视差唯一性约束、子像素优化、左右一致性检查、空洞填充、中值滤波等步骤对视差图进行优化处理,获得较为准确的视差图.
2.1 预处理
在进行当前层的匹配之前,需要对图像进行预处理.根据当前的金字塔层号L,对原始图像进行下采样,得到用于当前层需要完成匹配的左右图像.在每一层进行下采样之前,需要完成高斯滤波预处理,去除原始图像中的噪声.
2.2 代价计算
传统的Census变换仅用锚点像素与周围邻域像素做比较,导致Census变换严重依赖于中心像素,当图像受噪声、光照等外界条件干扰时,中心像素的亮度值可能严重失真,使得该像素的Census变换结果难以准确反映该点处的真实情况,影响最终精度.因此,本文在预处理阶段使用高斯滤波消除噪声,并且使用中心对称Census变换[14](Center-Symmetric Census Transform,CSCT)中8组像素的比较结果作为补充,中心对称Census变换能够减少对中心像素的依赖,捕获窗口内距离较远像素点之间的亮度关系.
融合的Census变换首先在局部5×5窗口内进行朴素Census变换,得到变换的描述序列CensusStr(r,c),该序列一共24位.其次,采用CSCT的思想,选取如图2所示的8个位置,为朴素Census变换序列补充8个变换代价位,使得变换的结果增长至32位,加强变换的鲁棒性.

图2 p1-p8位置图Fig.2 p1-p8 Position map
p1~p8每个位置的像素均与其关于(r,c)中心对称位置的像素比较亮度值大小关系,8个像素按序计算后得到字符串CSCTStr(r,c),此步骤可以用式(1)表示:
(1)
式中:⊗表示按位连接;pi为图2中8个位置中的第i个位置的像素亮度值;p′i为pi关于位置(r,c)的中心对称点的像素亮度值;ξ(pi,p′i)为比较函数;CSCTStr(r,c)为变换结果.综上,融合的Census变换序列定义如式(2)所示:
MergeStr(r,c)=(CensusStr(r,c)≪8)+CSCTStr(r,c)
(2)
式中:≪为左移运算符;MergeStr(r,c)为对点(r,c)位置的像素做融合Census变换的结果序列.则两个像素点之间的匹配代价可以表示为式(3):
COSTCT=H(MergeStr(x),MergeStr(y))
(3)
式中:MergeStr(x)、MergeStr(y)为像素点x和y进行融合Census变换后得到变换序列;H为计算两个变换序列之间Hamming距离的函数;COSTCT是像素x和像素y之间的匹配代价值.由于CensusStr为24位,CSCTStr为8位,故MergeStr序列的长度为32位,所以对两个MergeStr序列计算Hamming距离的结果在0~32之间,包括0和32共33个数值,用1个字节即可存储该代价值.
Census变换可以很好的处理两张图像整体亮度不一致的情况,并且在弱纹理区域仍然鲁棒,但缺点在于难以处理重复纹理区域.中心对称Census变换减少了对中心像素的依赖,可在一定程度上抑制噪声的影响.AD代价对亮度很敏感,在弱纹理区域表现较差,但是对重复纹理区域效果较好.AD变换代价的计算方法如式(4)所示:
COSTAD=|I(x)-I(y)|
(4)
式中:I(x)、I(y)为像素x和像素y的亮度值;| |为取绝对值运算符;COSTAD为亮度差绝对值代价计算结果.
基于上述分析,本文融合匹配代价是一种结合了融合Census变换与AD变换的代价计算函数,可表达为式(5):
COST=(COSTCT+COSTAD≪3)≫2
(5)
根据式(5)可知,本算法中匹配代价的取值范围在0至32之间,仅用1个字节即可存储,在一定程度上节约了算法的空间开销.
2.3 代价聚合
由于初始代价的计算只考虑了锚点像素局部的相关信息,对噪声非常敏感,因此仅通过代价计算得到初始代价来获取视差图,将难以取得理想的效果.为了获得较好的匹配效果,半全局立体匹配算法依旧采用全局立体匹配算法的思路,即全局能量最优的策略.定义如式(6)中所示的全局能量函数:
(6)
式中:E(D)为视差图D的能量函数;C(p,Dp)为点p的匹配代价值;q为p的邻域Np中的像素;Dp、Dq分别的p点、q点在视差图D中的视差值;T(x)为判断函数,条件x成立为1,不成立则为0;P1、P2为惩罚项,P1小于P2,用于相邻像素视差相差1个像素的情况下的惩罚,P2则用于相邻像素视差相差超过1个像素的情况下惩罚.式(6)的最优化问题是一个NP完全问题,在实际中,半全局立体匹配算法采用了动态规划的思想逼近式(6)的最优解.半全局立体匹配算法对代价空间上的每个元素都考虑从多个方向(4、8、16个方向,本文中固定为4)进行聚合,然后将所有方向的聚合结果相加得到最后的匹配代价值,像素p在视差为d时,沿着某条路径r的路径代价聚合计算方法如式(7)所示:
(7)

(8)
本文采用分层迭代的匹配策略,通过上一层的视差图限制当前层像素的搜索范围,即每个像素的视差搜索范围都是不同的.所以在式(7)中,Lr(p-r,d±k)有可能不存在,若Lr(p-r,d±k)不存在,则把该项作为正无穷处理.当k=-1,k=0,k=1均不存在时,式(7)便简化为式(9):
L′r(p,d)=C(p,d)+P2
(9)
式中:L′r(p,d)为新的聚合代价.
较小的惩罚项能够让算法更好的处理视差变化小的区域,较大的惩罚项能够让算法更好的处理视差变化大、非连续的区域,因为图像中灰度变化大的区域往往是图像边缘,其视差非连续的可能性大,所以,为了更好的处理视差非连续区域的匹配情况,P2往往根据相邻像素的灰度差值动态调整,如式(10)所示:
(10)
式中:P1_init、P2_init为初始惩罚参数;p(x)为像素x的亮度值;p(x-r)为像素x在路径r上的前一个像素的亮度值.
2.4 视差计算
经过代价聚合,使用WTA算法得到每个像素较为粗糙的视差值,即对于任意像素p,遍历像素p在三维聚合代价空间中的有效视差范围,选出其中最小聚合代价所对应的视差值,即为像素p较为粗糙的视差值.在视差计算部分,采用二次曲线内插的方法得到子像素精度,对刚刚选出的粗糙视差值所对应的代价值及其前后两个视差代价值进行二次曲线拟合,二次曲线底部极值点所对应的视差值即确定为子像素的视差值.
2.5 视差优化
经过视差计算步骤得到的视差图仍然存在较大的误差,因此需要进一步优化视差图以提高其精度,本文的视差优化步骤包括左右一致性检查、视差空洞填充以及中值滤波.
左右一致性检查的作用是找出视差图中的误匹配点、遮挡点等异常匹配点.通常先计算得到右侧视差图,如果左右视差图对应像素点视差值的差值小于给定的阈值,则认为该点的视差是正确的,反之则认为该点视差是异常的,并予以剔除.计算右侧视差图常采用的办法是交换左右图像,重新进行一次立体匹配,这种方法运行效率不高.实际上,右侧代价空间的每个代价值可以通过左侧对应位置像素点的视差情况推导得到,推导关系如式(11)所示:
dispRight(r,c,d)=dispLeft(r,c+d,d)
(11)
式中:dispRight(r,c,d)为右侧代价空间中坐标为(r,c)视差为d时的代价值;dispLeft(r,c+d,d)为左侧代价空间中坐标为(r,c+d)视差为d时的代价值.但这种方法适用于固定视差搜索范围的情况,本算法中每一层匹配的每一个视差的视差搜索范围都不相同,所以本文采用如下策略:先根据左侧视差图全部像素的视差搜索范围更新得到右侧视差图中每个像素位置的视差搜索范围,并限制右侧每个像素的视差搜索范围在0至64之间,以保证不会出现较高的搜索时间开销.得到右图每个像素的视差搜索范围后,再用式(11)计算得到右视差图,同时使用二次曲线拟合,得到更为精细的子像素视差,最后完成左右一致性检查.得到当前层视差图后,根据当前层视差图估计下层待匹配像素的视差搜索范围,开始下一层的匹配.
2.6 CPU平台优化加速
2.6.1 分层迭代匹配策略
本文算法采用了SURE[10]算法中提出的思想,采用从粗到精的分层迭代匹配策略,通过限制每个像素的视差搜索范围,达到大幅度减少视差搜索时间,提升搜索效率的目的.但本文未固定层数,算法根据原始待匹配图像的宽度自动确定层数,高层的匹配结果不仅能为下层像素的搜索提供粗略的位置,而且能够限制下层像素的搜索范围,提高算法整体效率和结果的可靠性.在处理最上层的匹配时,由于没有更上层的视差结果提供初值,所以,将最上层的初始视差搜索范围设置为最上层的图像宽度.
在视差填充过程中,采用标志位标记像素点.估计下层视差范围时,根据像素点的标志位进行估计:若像素点是由填充算法估计得到的,则将其下层的搜索范围扩至最大为64个像素,否则,在以其为中心的5×5局部窗口中,搜索最大视差值和最小视差值对下层搜索范围进行估计,并限制下层像素的视差搜索范围最大为64.
2.6.2 多核并行策略
本文所提算法在4核4线程的Intel(R)Core(TM)i3-9100T CPU @ 3.10GHz所支持的硬件平台上开发,算法任务与算法数据均并行处理,在算法任务的并行实现中,将待处理任务按行和视差进行分块,4个线程并行处理.
在算法的数据并行实现环节,使用OpenCV中的统一指令集.OpenCV统一指令集旨在提供一个各类计算架构的统一编程模型,将程序开发与计算机底层的SIMD指令集相分离.OpenCV统一指令集对外提供相同的调用接口,但在程序编译期会自动选择目标硬件平台最优的SIMD指令.本文中具体的硬件平台支持AVX256指令集,可支持256位的向量化运算.
需要注意的是,在视差计算函数的向量化设计中,主要问题是要找到向量中的最小值及其下标,在OpenCV统一指令集中,没有集成相关方法,所以使用SSE原生指令集中的_mm_minpos_epu16函数,该函数只能进行128位的向量运算,返回向量中的最小值及其下标.所以,视差计算部分,一次可以同时进行8个视差值的处理.
其次,在进行左右一致性检查时,本文算法并非交换左右图像重新进行匹配,而是先根据左侧视差图的视差搜索范围推算出右侧像素点的视差搜索范围,然后右侧全部像素点根据自身的搜索范围及视差关系,在左图的三维代价空间中确定对应代价值,填充右图的三维代价空间.最后在三维代价空间内使用WTA、子像素优化确定右图像素点的视差值.
每个像素点的搜索范围使用有符号整型在内存中连续存储,如:像素1的最小视差,像素1的最大视差,像素2的最小视差,像素2的最大视差…像素n的最小视差,像素n的最大视差.这样的存储方式便于使用向量进行算法优化,而后续的填充右图三维代价空间步骤中,计算时所需的数据在内存中并不连续,即使强行进行向量化运算,性能也难以提升.所以,本文仅对第一步(根据左侧视差图的视差搜索范围推算出右侧像素点的视差搜索范围)进行加速.
先将右图视差搜索范围中的最小值初始化为32767,最大值初始化为-32768.后续的向量化运算只需取出左侧像素的当前视差,与右图的最大最小范围进行对比,取最小值、最大值再存入右图的视差范围即可.由于视差范围在内存中是小大视差交叉存储,所以取出小大视差时,需要解交叉取出,此步骤可以使用cv::v_load_deinterleave方法完成,该方法接受一个16位的指针p及向量a和b,该方法从p处取出16个整数值,奇数位元素依次放入向量a,偶数位元素依次放入向量b.在向量化计算完毕后,使用cv::v_store_interleave交叉存入内存,该方法接受一个16位的指针p以及向量a和b,a和b中的元素交叉存入地址p开始的内存中.
3 实验与分析
本文算法在Visual Studio 2017环境下,使用C++语言开发,使用了OpenCV4.5.2 开源图像处理库,操作系统为Windows10×64,内存为12GB,所使用的处理器为4核4线程的Intel(R)Core(TM)i3-9100T CPU @ 3.10GHz.
首先对算法的改进部分进行消融实验,验证各部分的有效性;其次,在KITTI 2012[15]和KITTI 2015[16]两个公开的基准数据集上评估所提算法的误匹配率,并且与一些基于SGM的立体匹配算法进行对比,最后把不同优化程度的本文算法在实验平台上进行运行效率测试.
3.1 消融实验
在消融实验中,基准算法采用Census-SGM,实验变量为高斯滤波预处理、代价计算方式、分层迭代匹配3个条件,为防止“视差填充”方法对上述3个条件产生视差图的影响,在有视差填充和无视差填充时分别做了实验.实验评价指标采用非遮挡区域误匹配率(Percentage of erroneous pixels in non-occluded areas,Out_Noc)和全部区域误匹配率(Percentage of erroneous pixels in total,Out_All),误匹配率阈值设为3Pixels,在KITTI 2012训练集和KITTI 2015训练集上分别评估,结果如表1所示.
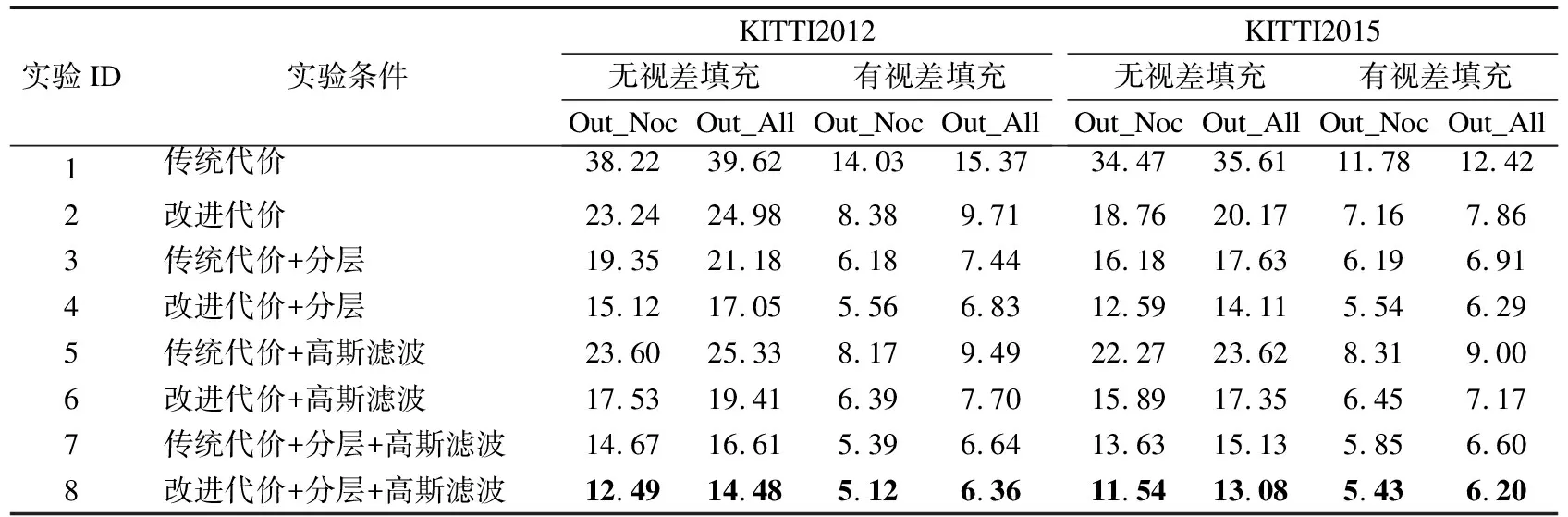
表1 消融实验数据表Table 1 Ablation experiment data table
实验1、2,实验3、4,实验5、6,实验7、8,这4组对照,每组内两个实验只有代价计算方式不同,其他条件均相同,本文改进的代价计算方式都比传统代价计算方式的误匹配率低.尤其在实验1、2中,无视差填充时,在KITTI 2015上的Out_Noc最大差值为15.71个百分点.在有视差填充时,实验7、8的误匹配率相差虽然不大,但使用改进代价计算的实验8仍然效果较好.
实验1、3,实验2、4,实验5、7,实验6、8,在这4组对照内,前者不使用分层迭代匹配方式,后者使用分层迭代匹配,其余条件均相同.使用了分层迭代匹配的算法精度均明显高于直接匹配的精度.
实验1、5,实验2、6,实验3、7,实验4、8,这4组对照,组内两个实验分别不采用和采用高斯滤波进行预处理,有高斯滤波预处理的算法误匹配率要明显低于同组无高斯滤波预处理的结果,说明在预处理步骤中,加入高斯滤波可以有效提升匹配精度.
综合来看,实验8的误匹配率比其他实验均低,说明将改进的代价计算结合高斯滤波预处理及分层迭代的匹配方式,可以有效提高算法的匹配精度.
3.2 对比实验
在KITTI 2012和KITTI 2015数据集上与最新的一些基于SGM的立体匹配算法进行对比,评价指标使用Out_Noc与Out_All,误匹配率阈值使用3Pixels,在KITTI 2012测试集和KITTI 2015测试集上的对比结果如表2、表3所示.
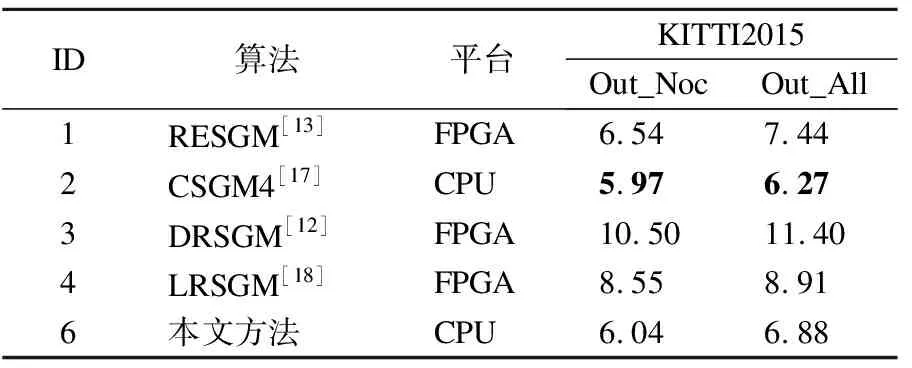
表3 KITTI 2015对比实验数据表Table 3 KITTI 2015 comparative experiment data table
RSSGM(Road Scene SGM)、RESGM(Resource Efficient SGM)和LRSGM(Low Resource SGM)侧重于降低SGM算法的复杂度和内存开销,使其能够实时计算.为了节省硬件资源,LRSGM提出了一个多阶段的四周期分时流水线架构,采用图像降采样和视差跳跃策略,RESGM同样使用降采样和视差跳跃.同时增加了路径加权、亚像素插值等进一步提升了匹配精度.然而,RESGM算法在KITTI 2012非遮挡区域和全部区域的误匹配率分别为6.66%和7.60%,分别比本文方法高1.94和1.55个百分点.RSSGM提出了一种Census变换的变体,并在SGM中引入图像的边缘信息来处理真实道路场景的复杂光照变化,该方法在KITTI 2012非遮挡和全部区域的误匹配率分别比本文方法高了3.99和4个百分点.DRSGM(Dependency Relaxation SGM )扩展了传统SGM的流水线架构,通过松弛依赖约束以并行方式处理多个像素,提高了算法效率,但精度损失严重.CSGM4采用4路径聚合,递归地执行一维双边滤波来建立各路径之间的信息交互,在两个数据集中都获得了较低的误匹配率.在KITTI2012数据集的非遮挡区域和全部区域上,本文方法比CSGM4的误匹配率分别低了0.46和0.57个百分点.而在KITTI2015数据集上,本文方法比CSGM4的误匹配率分别高出了0.07和0.61个百分点.在代价计算阶段,CSGM4采用了9×9窗口大小的Census变换,生成了81位的比特串,而本文使用的代价计算方法仅用了32位的比特串,代价的区分度比CSGM4低,并且空间开销更小.非遮挡区域的视差点全部由匹配算法得出,无视差填充方法的影响,在非遮挡区域,二者误匹配率仅相差0.07个百分点,更能说明本文算法生成的视差图质量较高.
可以看出,RSSGM、RESGM、LRSGM以及DRSGM虽然提高了SGM的效率,但以准确性为代价.CSGM4在KITTI 2015数据集上的误匹配率虽然比本文算法低,但在代价计算阶段采用了更大的窗口尺寸,带来更大的空间开销.本文方法采用了改进的代价计算方式以及分层迭代匹配策略,在KITTI 2012和KITTI 2015两个公开的基准数据集上都获得了较理想的误匹配率.图3展示了本文方法在KITTI 2015训练集上的部分视差图和相应的误差图,从上至下依次为原图(左)、本文算法生成的视差图和误差图,从图3(a)~图3(d)依次为KITTI 2015训练集中编号71、128、142、171的图像.
本文还在KITTI 2015训练集上和其他基于SGM的改进算法进行了比较,评价指标依然采用Out_Noc与Out_All,即视差图在非遮挡区域误匹配率和全部区域误匹配率,对比结果如表4所示.
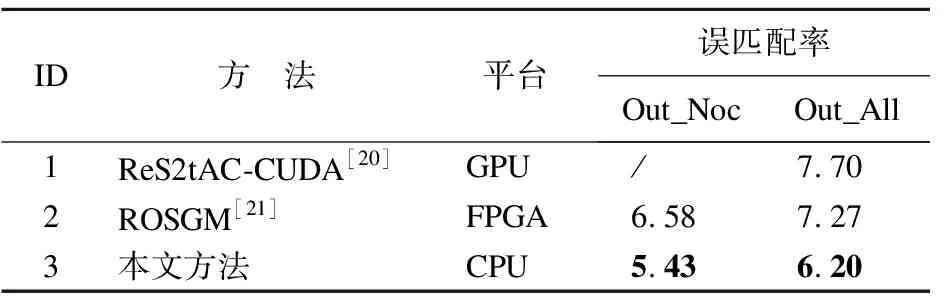
表4 KITTI 2015训练集对比数据表Table 4 KITTI 2015 training set comparison data table
ReS2tAC-CUDA方法基于GPU实现,有较高的并行度,采用窗口大小为9×7的Census变换结合汉明距离作为初始代价,但在全部区域上的误匹配率比本文高1.5个百分点.ROSGM(Region Optimized SGM,ROSGM)采用优化策略,在局部范围内搜索最小代价作为代表,仅对这些最小代价进行2路径的聚合,运行效率大大提高,但在最终视差图的误匹配率上比本文高了1.15和1.07个百分点.
3.3 运行效率验证
根据优化程度,分为未经优化的本文算法、仅使用并行优化的本文算法以及完全加速的本文算法(并行+分层)3种进行算法效率的验证.实验使用Middlebury 2014立体匹配数据集中的全尺寸Teddy图像进行算法效率评估,该图片的分辨率为1800×1500,最大视差为256个像素.在实验中,3种算法除效率优化程度不同以外,其他参数均保持一致;视差图后处理采用左右一致性检查、小连通域剔除以及3×3中值滤波;最大视差搜索范围分别设置为64、128、256,以验证算法在不同视差下的运行效率.
实验中计时方式为:算法完成100次匹配操作,计算平均耗时.为了得到较为准确的对比结果,实验中仅统计各算法在匹配阶段的时间消耗,如内存空间的申请、释放以及对象初始化等时间消耗均未进行统计.时间、空间效率测试结果如表5、图4和图5所示.

表5 效率实验数据表Table 5 Efficiency test data table

图4 时间开销Fig.4 Running time
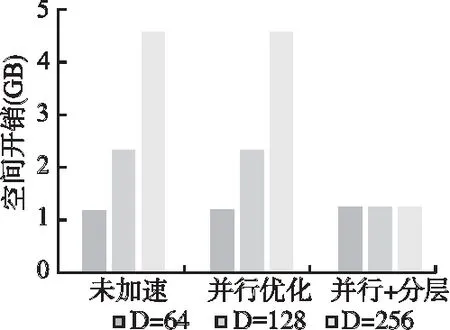
图5 空间开销Fig. 5 Memory requirement
需要说明的是,完全加速的本文算法的视差搜索范围会根据输入图像尺寸自动调整,所以虽然指定了3种视差搜索范围,但实际匹配时不会使用.
从表5可以看出,在搜索范围为64时,完全加速的本文算法较未经优化的本文算法,效率提升6.5倍左右,在搜索范围为128时,效率提升12.2倍左右,在搜索范围为256时,效率提升23.6倍左右,提升的倍数与视差范围有关,理论上,视差搜索范围越大,本文算法的优势越明显.
表5中,仅使用并行优化的本文算法在视差为64时,时间效率比完全加速时高,但其匹配结果是不完整的.原因在于,仅使用并行优化时,其搜索范围最大只有64,而测试图片Teddy的最大搜索范围是256,所以算法没有对视差大于64的区域进行处理.在视差64、128与256这3种情况下得到的视差图如图6所示.

图6 3种视差得到的视差图Fig.6 Disparity map obtained by three kinds of disparity
从空间开销来看,未经优化的算法与仅使用并行优化的算法,空间开销相同,与视差范围成正相关,完全优化(并行+分层)的本文算法由于与视差范围无关,仅与图像宽度有关,所以内存开销无变化,并且明显小于其他两种算法.
4 结 论
利用融合的代价作为立体匹配的初始代价,提高了代价的区分能力;在预处理阶段使用高斯滤波处理待匹配图像,可有效提高后续计算准确度;采用分层迭代匹配、多核并行及AVX256指令集的计算策略,可以有效提高边缘CPU设备执行立体匹配算法的效率,并且可以在一定程度上降低内存开销.实验结果表明,本文所提的匹配算法在KITTI 2012和KITTI 2015基准数据集上的误匹配率可以达到4.72%和6.04%.使用Middlebury数据集中的全尺寸图像测试效率,在256视差条件下,所提算法在完全优化时的运行效率是未优化时算的23.6倍,并且在视差图的误匹配率方面可以达到主流经典算法的水平.这对立体匹配算法在边缘CPU设备上的应用具有现实意义.
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
海峡姐妹(2017年12期)2018-01-31
测绘科学与工程(2017年3期)2017-08-16
测绘科学与工程(2017年1期)2017-05-04
作文与考试·初中版(2017年12期)2017-04-19
现代计算机(2016年3期)2016-09-23
浙江大学学报(工学版)(2016年11期)2016-06-05
西部广播电视(2015年5期)2016-01-16
中学生(2015年12期)2015-03-01
